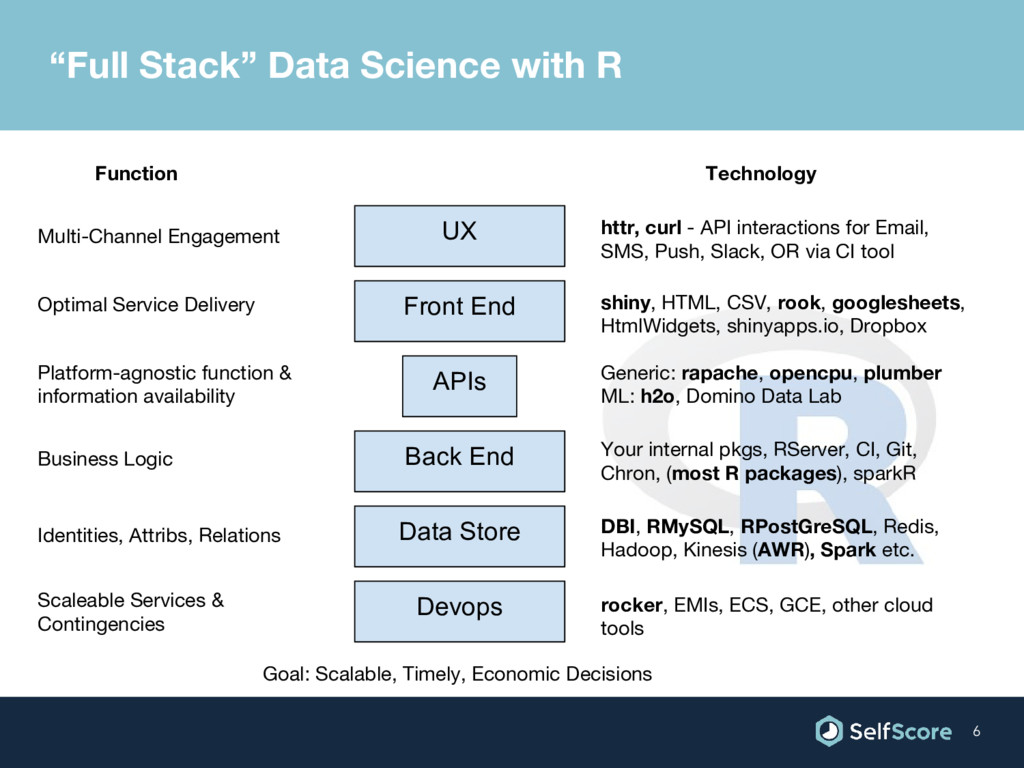
Technology rocker, EMIs, ECS, GCE, other cloud tools DBI, RMySQL, RPostGreSQL, Redis, Hadoop, Kinesis (AWR), Spark etc. Your internal pkgs, RServer, CI, Git, Chron, (most R packages), sparkR shiny, HTML, CSV, rook, googlesheets, HtmlWidgets, shinyapps.io, Dropbox httr, curl - API interactions for Email, SMS, Push, Slack, OR via CI tool Function Multi-Channel Engagement Optimal Service Delivery Platform-agnostic function & information availability Business Logic Identities, Attribs, Relations Scaleable Services & Contingencies “Full Stack” Data Science with R Generic: rapache, opencpu, plumber ML: h2o, Domino Data Lab Goal: Scalable, Timely, Economic Decisions
{kind=link}
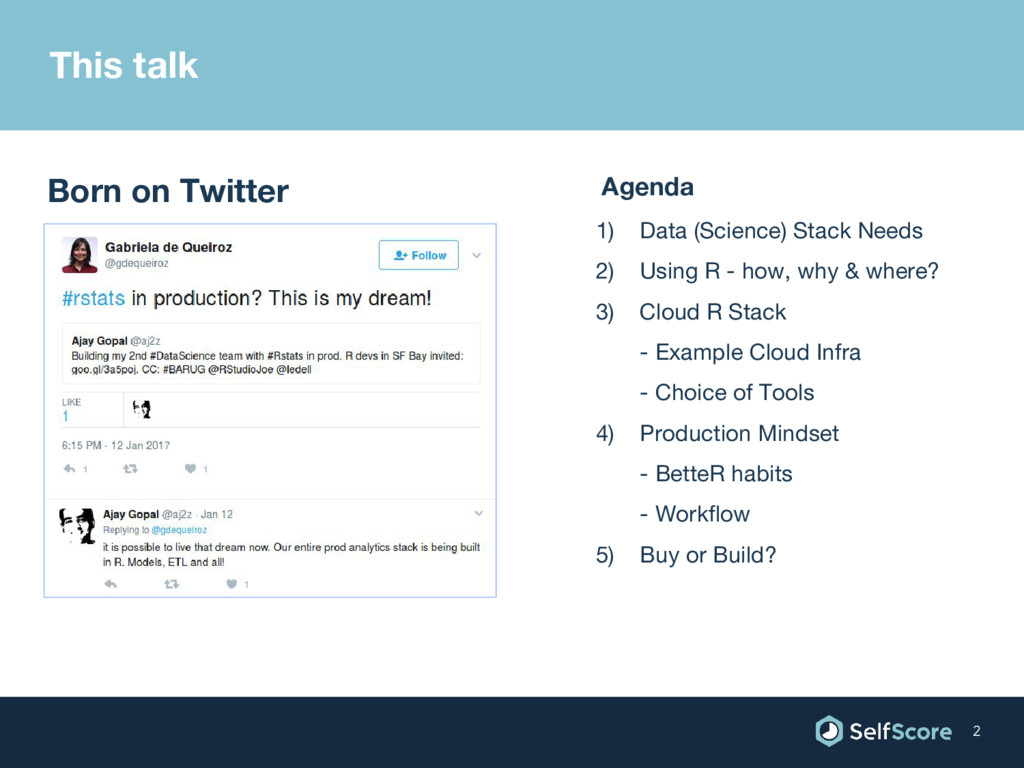{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
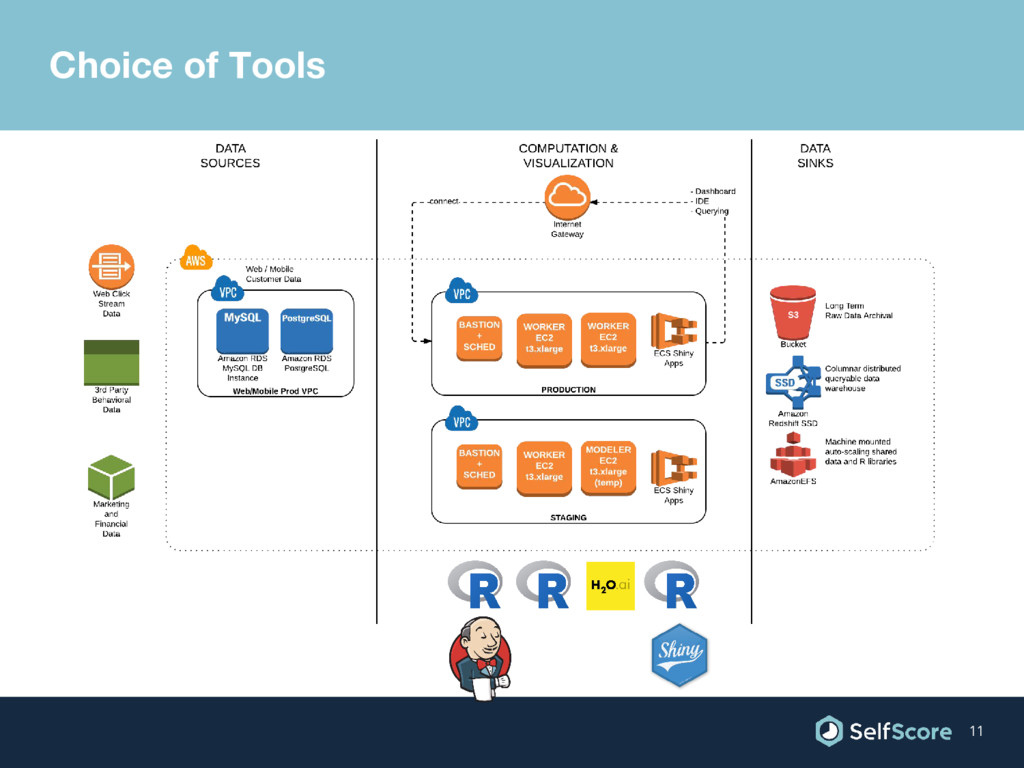{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}