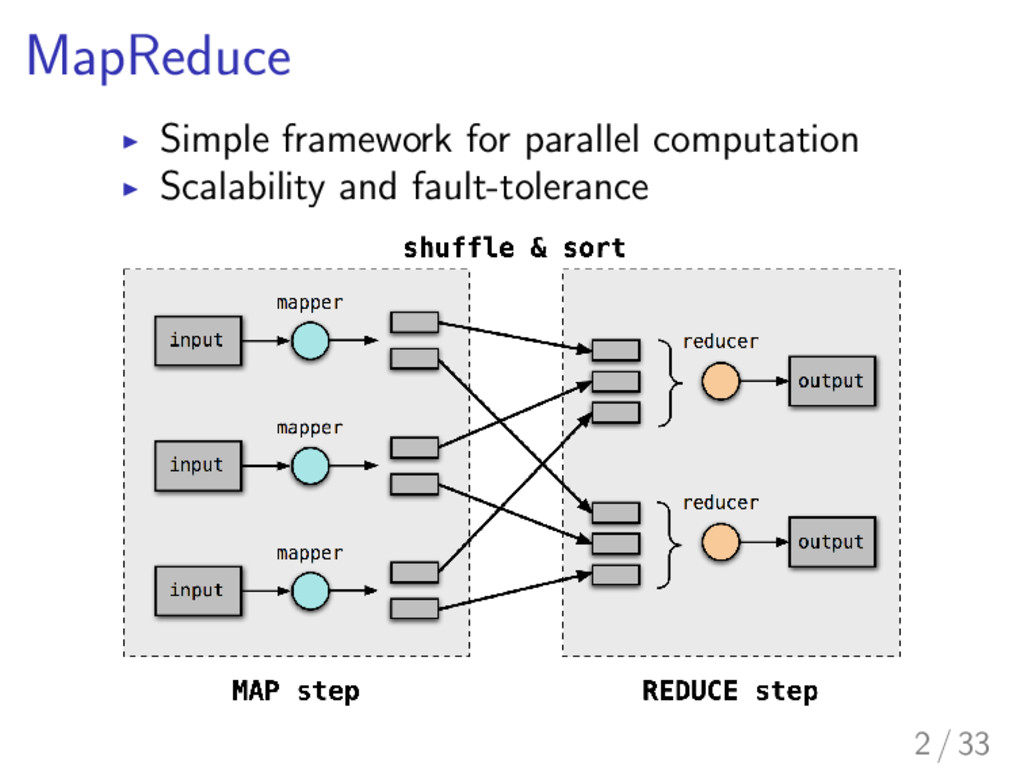
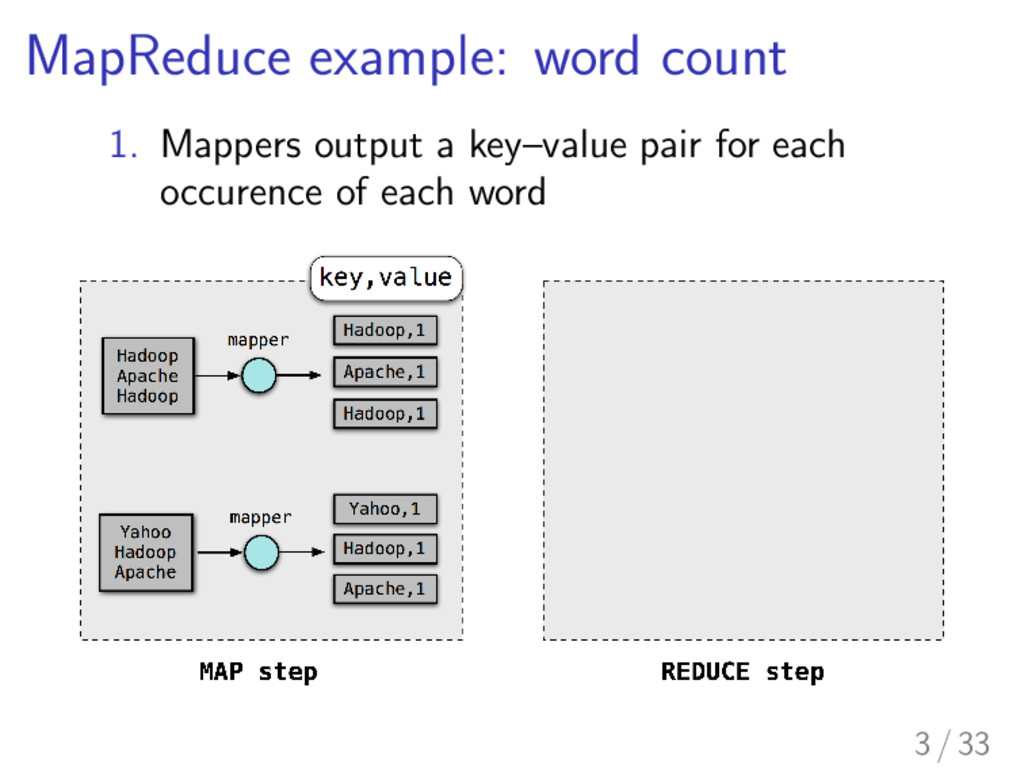
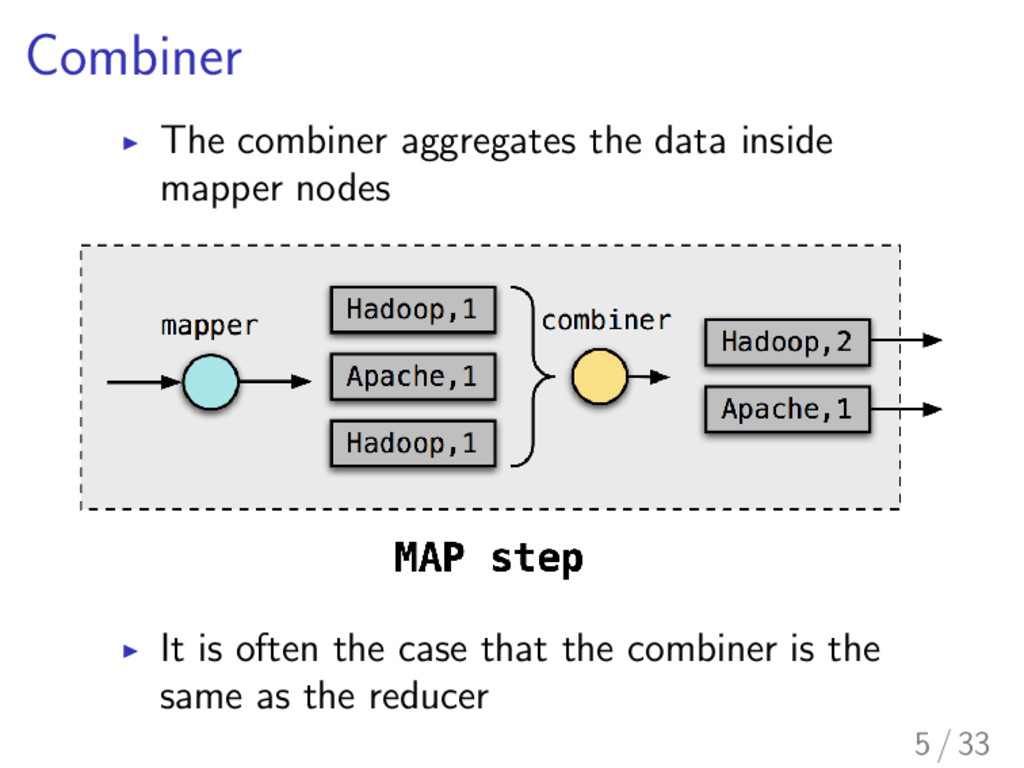
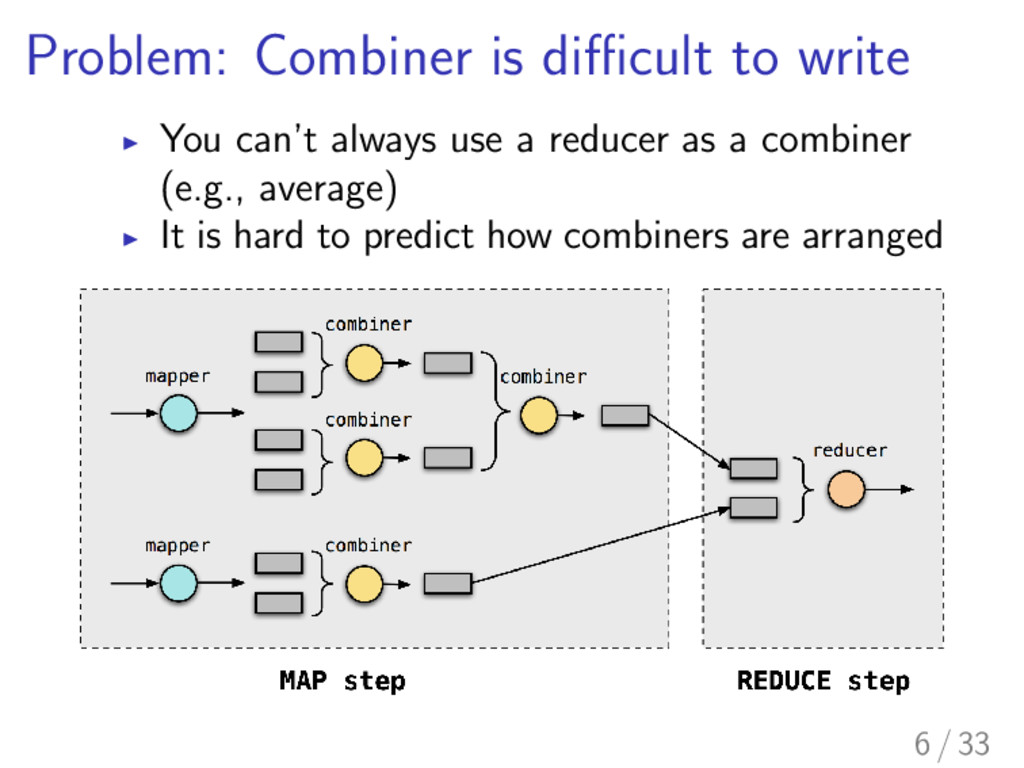
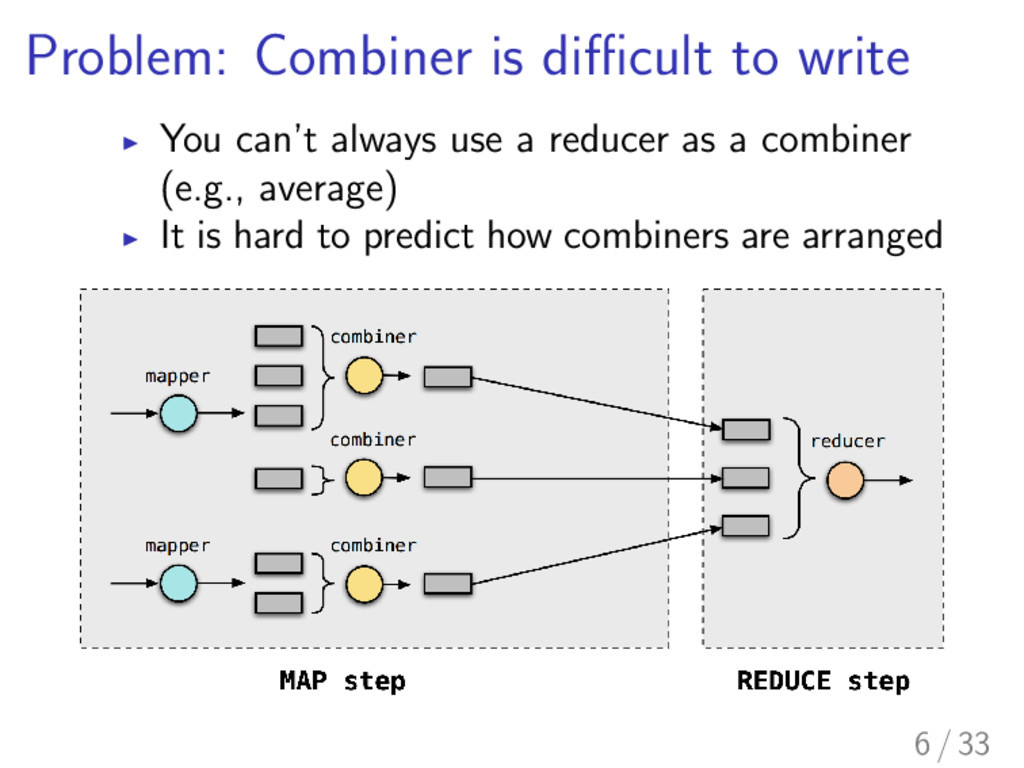
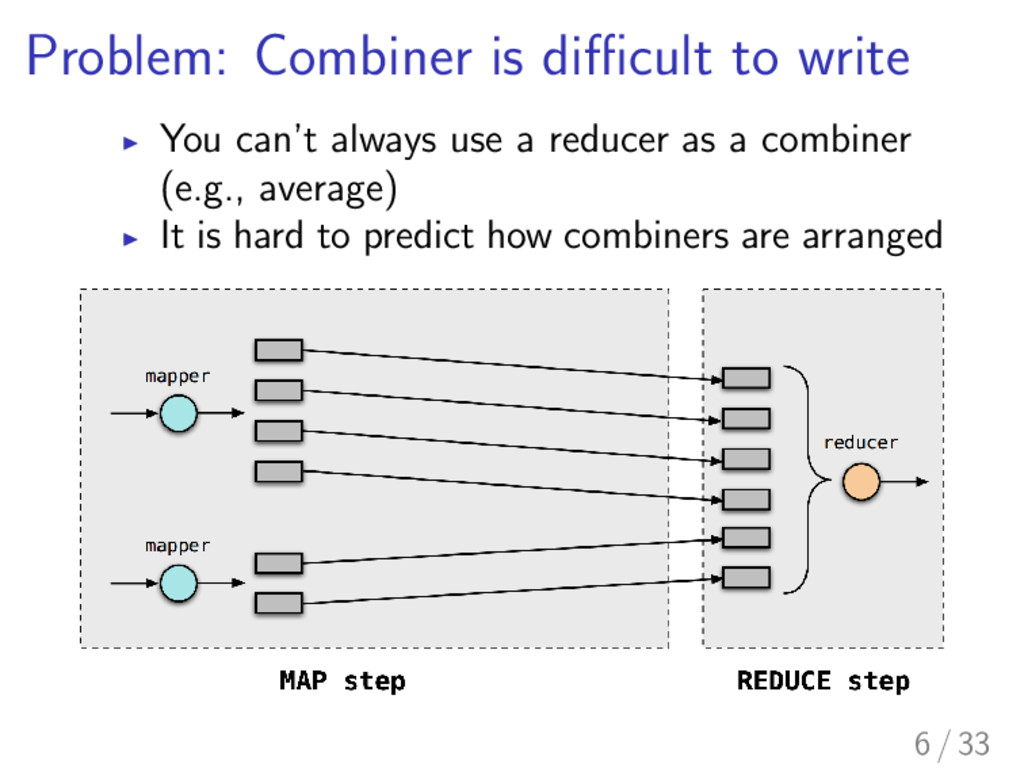
communication between nodes is huge I Reduction of the amount of transferred data leads to reduction of the time of whole computation I Combiners are one of the solutions provided by MapReduce 4 / 33
correctly input mapper, list-homomorphic reducer output mapper, combiner, reducer Benefit I Derived combiner is guaranteed to be correct by construction I Code duplication between combiner and reducer is avoided 7 / 33
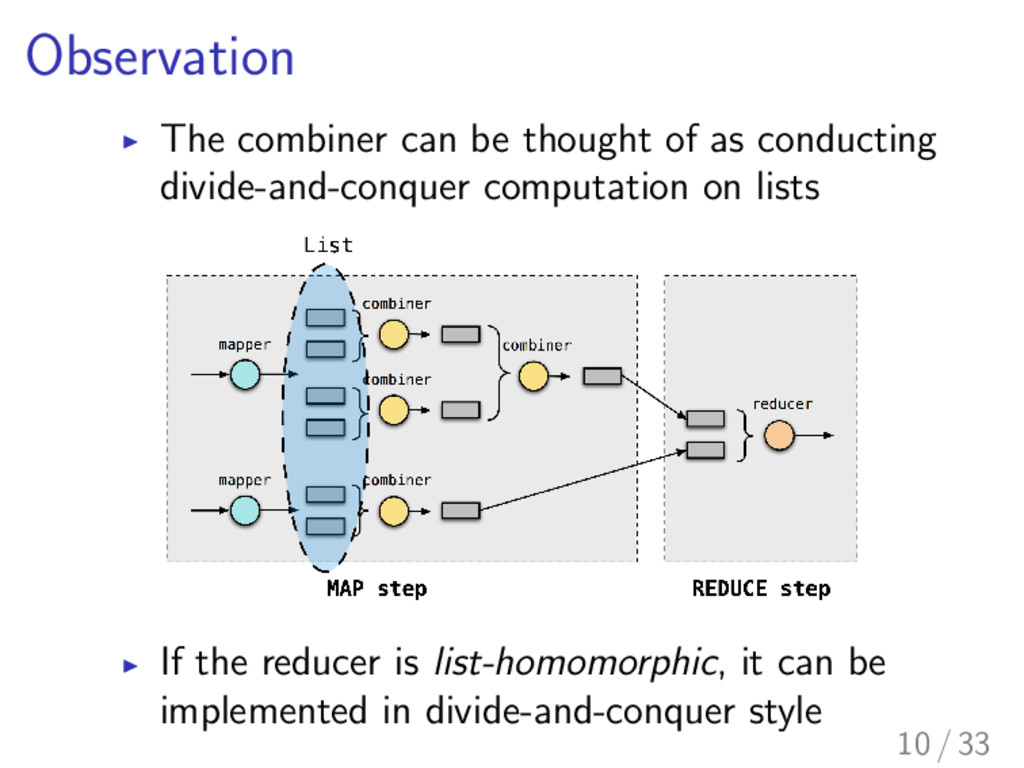
, 8 x, y : list , h ( x + + y ) = h x h y I The answer can be obtained from the values for sublists I The list can be split in an arbitrary position I We will take as a combiner 11 / 33
sum sum 1 (x) = [x] I sum(sum 1 (x)) = sum([x]) = x mapper v = sum [m v] = m v combiner vs = sum (concat (map sum 1 vs)) = sum vs reducer vs = sum vs 15 / 33
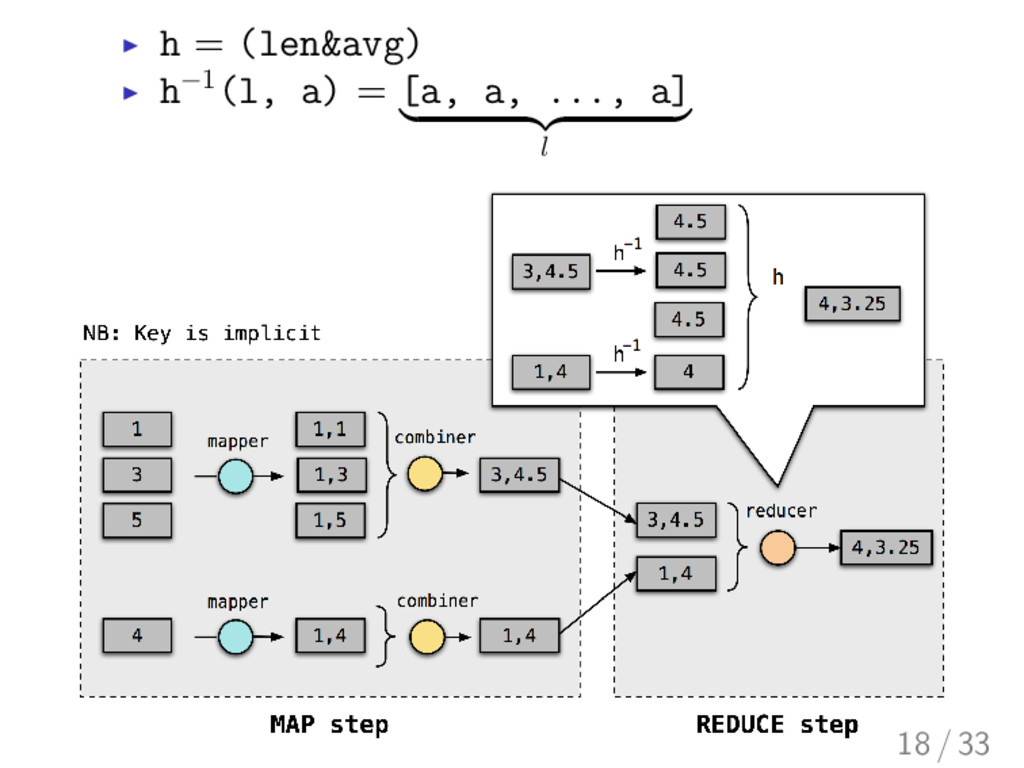
list-homomorphic input a list output a pair of length & average I h 1 (l, a) = [a, a, ..., a] | {z } l mapper v = h [m v] = [(1, m v)] combiner vs = h (concat (map h 1 vs)) 17 / 33
, MR new t = MR old (flatten t ) I MR simulates the computation of MapReduce according to a given tree I flatten models the computation without combiner I Proof: Induction on the structure of t 21 / 33
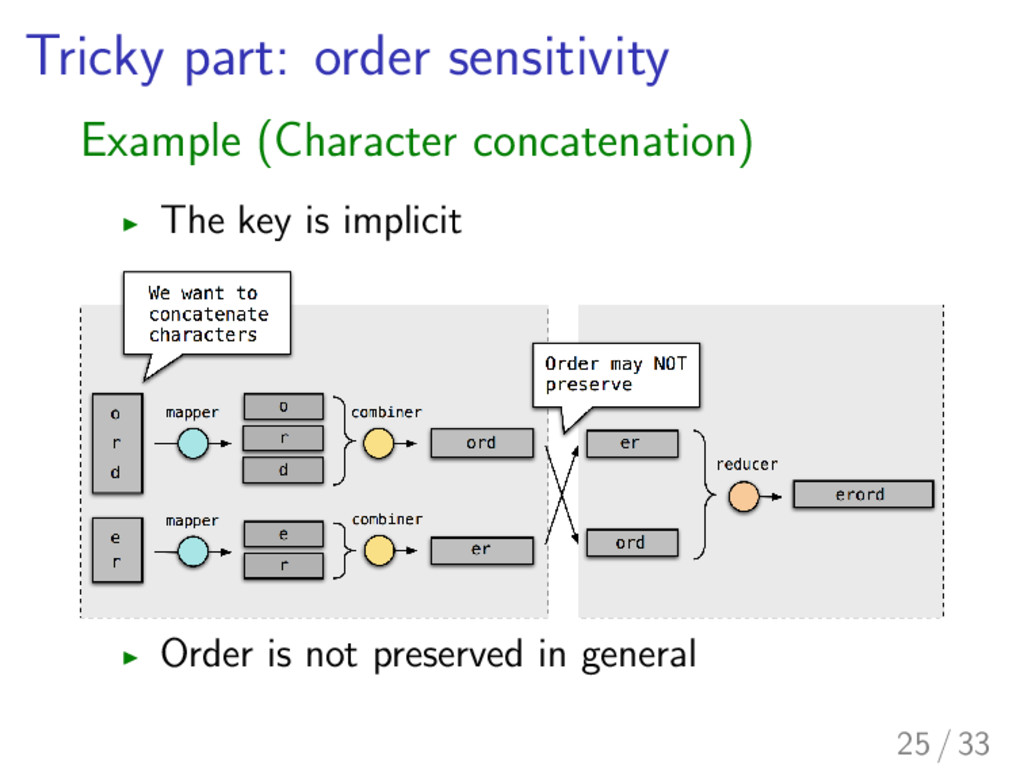
input data matters in many MapReduce computation [Xiao et al. ICSE 2014] I although MapReduce doesn’t preserve the order of key–value pairs! [Xiao et al. ICSE 2014] 22 / 33
a list-homomorphic reducer, and a right inverse of the reducer output Hadoop classes Although an automatic derivation of a right inverse methods has been proposed [Morita et al. PLDI 2007], currently we specify a right inverse by hand 24 / 33
1 master node, 10 worker nodes I 7.5GB memory I 2 ⇥ 420 GB storage and measured: I the amount of transferred data I the time spent in the whole computation in 2 problems: I Sum (order-insensitive) I Maximum Prefix Sum (MPS, order-sensitive) 27 / 33
combiner 2 . 86 ⇥ 10 3 120.5 w/o combiner 6 . 98 ⇥ 102 232.4 I Data are aggregated well by combiners I This is because sum is order-insensitive 28 / 33
2 y 3 z ... Benchmark Transferred data (MB) (sec) w/ combiner 4 . 64 ⇥ 10 3 156.9 w/o combiner 1 . 40 ⇥ 103 309.4 I The trend is similar to Sum 29 / 33
9 y 2 z ... Benchmark Transferred data (MB) (sec) w/ combiner 2 . 06 ⇥ 103 510.4 w/o combiner 1 . 41 ⇥ 103 369.5 Worsened the result I Combiners can aggregate only consecutive data I Overhead of combiner (e.g., dealing with index) 30 / 33
notion of the list homomorphism to MapReduce programs I Gets list homomorphism, execute MapReduce computation I Basically the same algorithm as ours I They don’t deal with combiners 31 / 33
the third homomorphism theorem I Correctness of the method I Implementation of the method for Hadoop I Can deal with the order-sensitive combiner and reducer I Experiment I Order-insensitive: good I Order-sensitive I Sequential: good I Random: bad 32 / 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The third homomorphism theorem [Gibbons. JFP 1996] If h is](https://files.speakerdeck.com/presentations/8a1380552bb04a20af029c6d2d4bd100/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Related work [Liu et al. Euro-Par 2011] also apply the](https://files.speakerdeck.com/presentations/8a1380552bb04a20af029c6d2d4bd100/slide_38.jpg){kind=link}
{kind=link}
{kind=link}