Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggleで勝つ データ分析の技術 輪読&勉強会 #3 〜第4章 モデル作成〜
Search
Kazuki Yokoi
April 01, 2020
Programming
0
510
Kaggleで勝つ データ分析の技術 輪読&勉強会 #3 〜第4章 モデル作成〜
Kazuki Yokoi
April 01, 2020
Tweet
Share
More Decks by Kazuki Yokoi
See All by Kazuki Yokoi
ディスカッションメダル荒稼ぎ!君もDiscussionMasterになろう!
kyokoi
0
250
ゼロから始める環境構築~Kaggle編~
kyokoi
0
590
Other Decks in Programming
See All in Programming
Unicodeどうしてる? PHPから見たUnicode対応と他言語での対応についてのお伺い
youkidearitai
PRO
1
2.6k
izumin5210のプロポーザルのネタ探し #tskaigi_msup
izumin5210
1
150
AI巻き込み型コードレビューのススメ
nealle
2
1.5k
そのAIレビュー、レビューしてますか? / Are you reviewing those AI reviews?
rkaga
6
4.6k
Package Management Learnings from Homebrew
mikemcquaid
0
230
Oxlint JS plugins
kazupon
1
1k
Python’s True Superpower
hynek
0
110
CSC307 Lecture 08
javiergs
PRO
0
670
要求定義・仕様記述・設計・検証の手引き - 理論から学ぶ明確で統一された成果物定義
orgachem
PRO
1
250
React 19でつくる「気持ちいいUI」- 楽観的UIのすすめ
himorishige
11
7.5k
dchart: charts from deck markup
ajstarks
3
1k
フロントエンド開発の勘所 -複数事業を経験して見えた判断軸の違い-
heimusu
7
2.8k
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
1.9k
Being A Developer After 40
akosma
91
590k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
760
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
359
30k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
54k
Reality Check: Gamification 10 Years Later
codingconduct
0
2k
Designing Experiences People Love
moore
144
24k
Fireside Chat
paigeccino
41
3.8k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
780
エンジニアに許された特別な時間の終わり
watany
106
230k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
170
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.7k
Transcript
Kaggleで勝つ データ分析の技術 輪読&勉強会 #3 〜第4章 モデル作成〜 2020年4月1日 横井 一輝
目次 1. モデルとは何か 2. 分析コンペで使われるモデル 1. GBDT(勾配ブースティング木) 2. ニューラルネット 3.
線形モデル 3. モデルのその他ポイントとテクニック
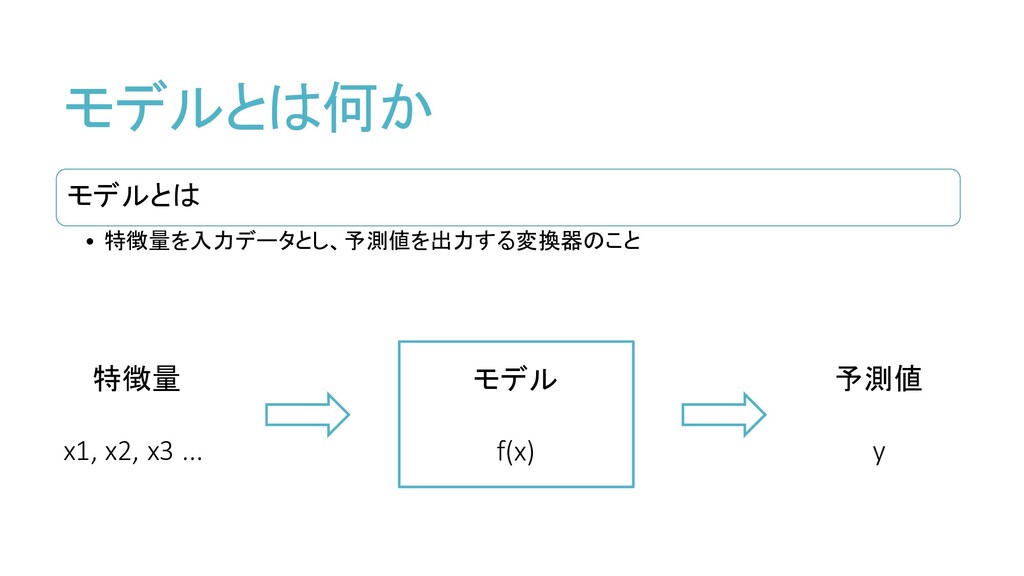
モデルとは何か
モデルとは • 特徴量を入力データとし、予測値を出力する変換器のこと モデルとは何か モデル f(x) 特徴量 x1, x2, x3
... 予測値 y
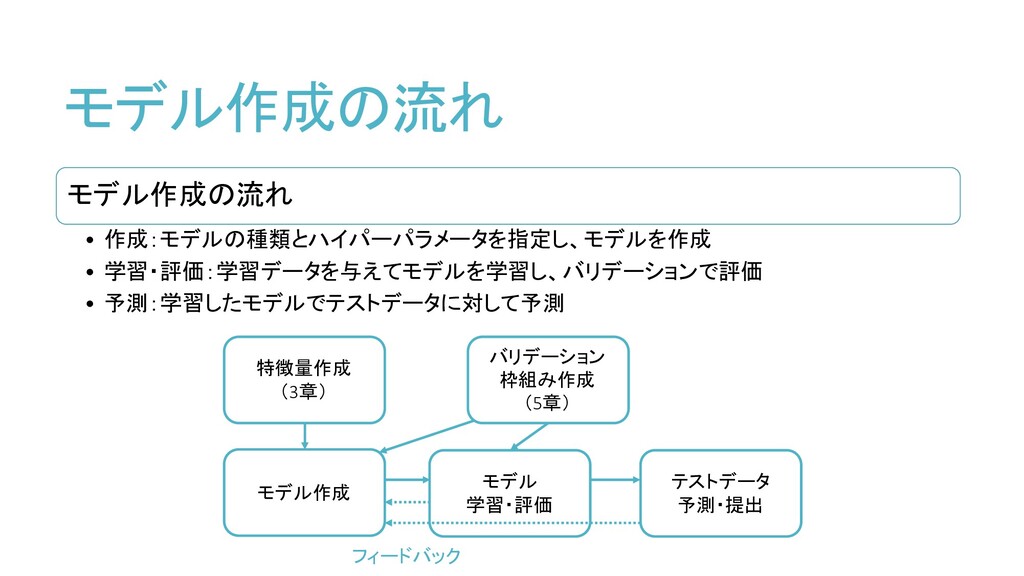
モデル作成の流れ モデル作成の流れ • 作成:モデルの種類とハイパーパラメータを指定し、モデルを作成 • 学習・評価:学習データを与えてモデルを学習し、バリデーションで評価 • 予測:学習したモデルでテストデータに対して予測 特徴量作成 (3章)
モデル作成 モデル 学習・評価 テストデータ 予測・提出 バリデーション 枠組み作成 (5章) フィードバック
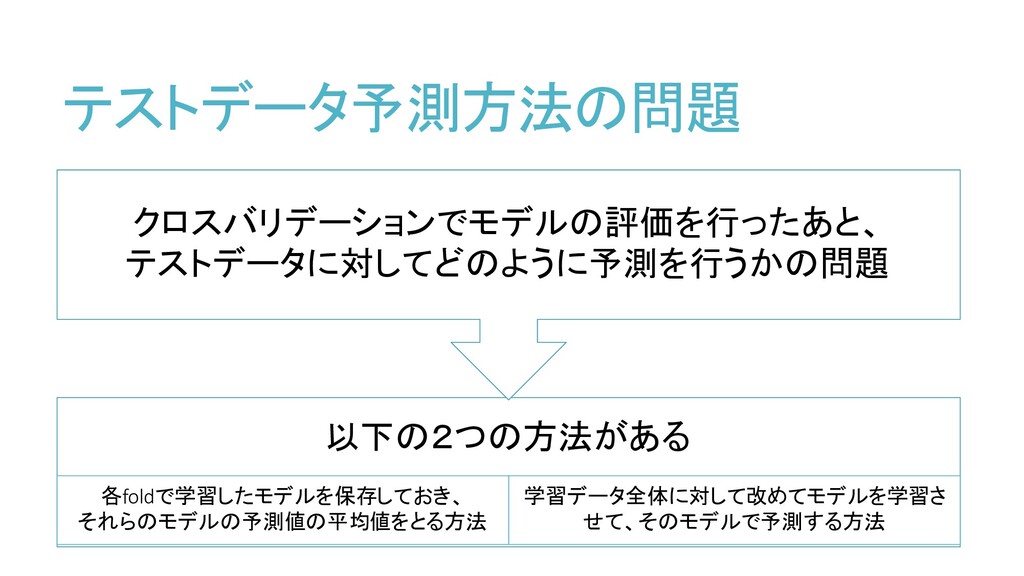
テストデータ予測方法の問題 以下の2つの方法がある 各foldで学習したモデルを保存しておき、 それらのモデルの予測値の平均値をとる方法 学習データ全体に対して改めてモデルを学習さ せて、そのモデルで予測する方法 クロスバリデーションでモデルの評価を行ったあと、 テストデータに対してどのように予測を行うかの問題
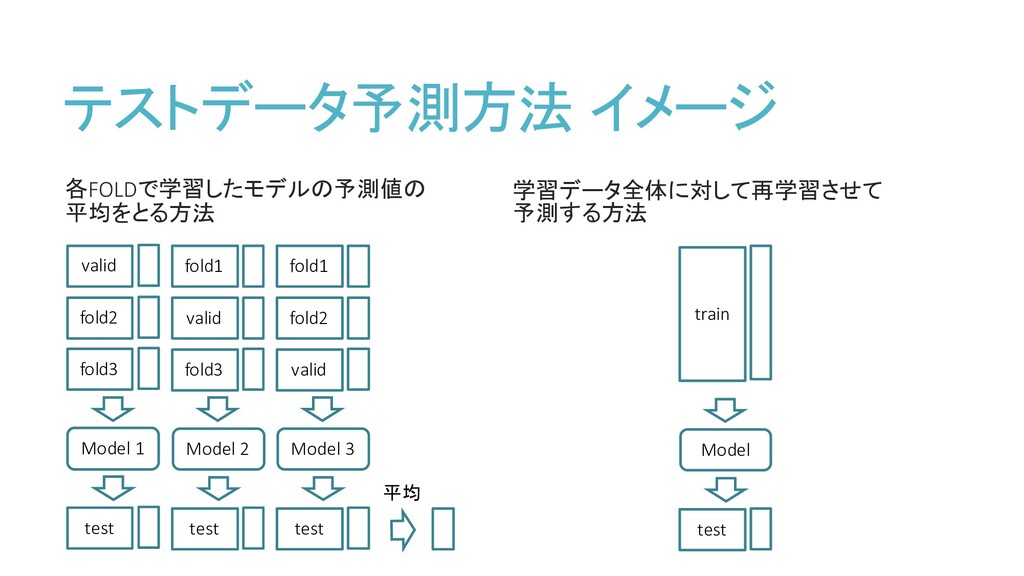
テストデータ予測方法 イメージ 各FOLDで学習したモデルの予測値の 平均をとる方法 学習データ全体に対して再学習させて 予測する方法 valid fold2 fold3 test
Model 1 fold1 valid fold3 test Model 2 fold1 fold2 valid test Model 3 平均 train test Model
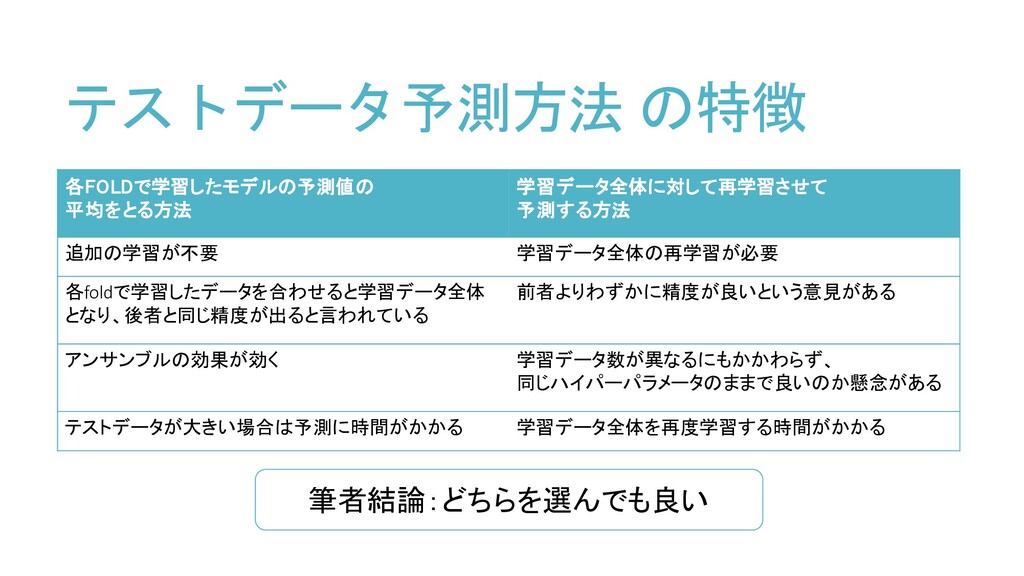
テストデータ予測方法 の特徴 各FOLDで学習したモデルの予測値の 平均をとる方法 学習データ全体に対して再学習させて 予測する方法 追加の学習が不要 学習データ全体の再学習が必要 各foldで学習したデータを合わせると学習データ全体 となり、後者と同じ精度が出ると言われている
前者よりわずかに精度が良いという意見がある アンサンブルの効果が効く 学習データ数が異なるにもかかわらず、 同じハイパーパラメータのままで良いのか懸念がある テストデータが大きい場合は予測に時間がかかる 学習データ全体を再度学習する時間がかかる 筆者結論:どちらを選んでも良い
分析コンペで 使われるモデル
分析コンペでのモデルの選び方 とりあえず初手 • GBDT(勾配ブースティング木) タスクによって次を検討 • ニューラルネット • 線形モデル 多様性を求める
• K近傍法 • ランダムフォレスト/ERT • RFG • FFM
GBDT(勾配ブースティング木) 特徴 • 特徴量は数値 • 欠損値を扱うことができる • 特徴量間の相互作用が反映される 経験則での特徴 •
精度が高い • ハイパーパラメータチューニングをしなくても精度が出やすい • 不要な特徴量を追加しても精度が落ちにくい
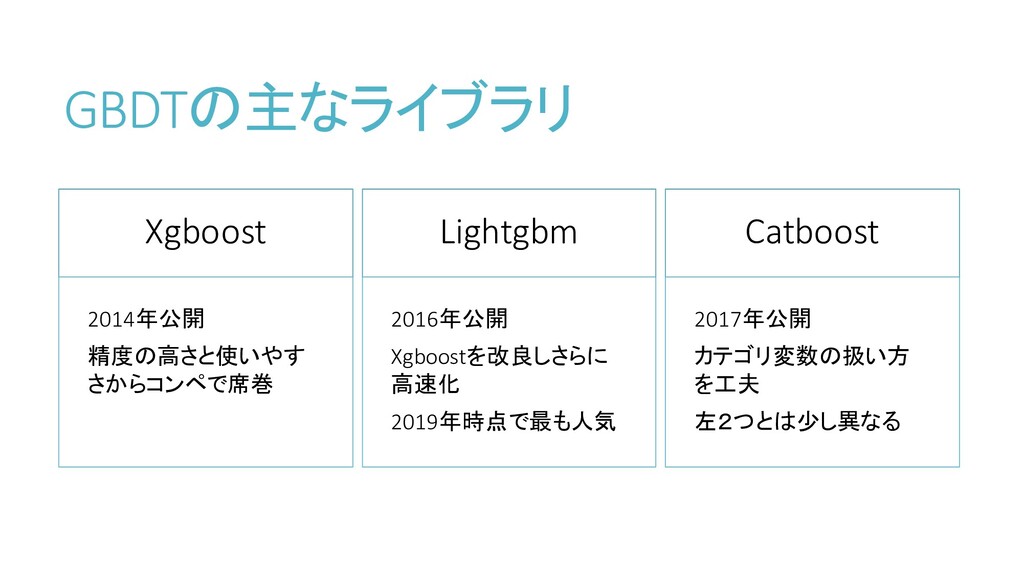
GBDTの主なライブラリ Xgboost 2014年公開 精度の高さと使いやす さからコンペで席巻 Lightgbm 2016年公開 Xgboostを改良しさらに 高速化 2019年時点で最も人気
Catboost 2017年公開 カテゴリ変数の扱い方 を工夫 左2つとは少し異なる
ニューラルネット 特徴 • 特徴量は数値 • 欠損値を扱うことができない • 非線形性や特徴量間の相互作用が反映される • 特徴量を標準化するなどスケーリングする必要がある
経験則での特徴 • ハイパーパラメータ次第で精度が出ないことがある • 他クラス分類に比較的強い
ニューラルネットの主なライブラリ Keras Google社員が作成 TensorflowなどのAPI をラップして、簡単に 使えることが特徴 Tensorflow Google製 最も知名度が高い 産業界でも人気
Pytorch Facebook製 新興のライブラリ 研究分野を中心に 近年人気上昇中 Chainer Preferred Networks 製 今後はPytorchに移 行することを発表 「Define-by-Run」とい うデファクトスタン ダードを生み出した
線形モデル 特徴 • 特徴量は数値 • 欠損値を扱うことはできない • GBDTやニューラルネットと比較して精度はよくない • 非線形性を表現するためには、明示的に特徴量を作成する必要がある
• 相互作用を表現するためには、明示的に特徴量を作成する必要がある • 基本的に標準化が必要 • 特徴量を作るときに丁寧な処理が必要 主なライブラリ • Scikit-learnのlinear_modelモジュール • Vowpal wabbit
モデルの その他のポイントと テクニック
バリデーションとテストのスコアが違う場合 過学習(オーバーフィッティング)を疑う • 過学習とは、学習データの性質やノイズに過剰に適合してしまっている状態 過学習の対策 • バリデーション方法を再検討する(5章参照) • アーリーストッピング機能を使用する •
一定の間バリデーションスコアが上がらない場合、途中で学習を打ち切る機能 • ハイパーパラメータを調整する 以下の可能性も検討する • 学習データとテストデータの分布が異なっている • テストデータのレコード数が少なすぎる
欠損値がある場合 GBDTなら問題なく扱うことが可能 ニューラルネットや線形モデルなどは、欠損値補間が必要 欠損値補間に関しては、第3章を参照
特徴量の数が多い場合 少しずつ特徴量を増やしていき、どのくらいまでなら学習できるのか試 す 特徴選択により、特徴量を落とす方法もある • 相関係数などの統計量から求める方法 • GBDT系のモデルから出力されるFeature Importanceから求める方法 •
特徴量の組みを変えてモデル学習を繰り返し、探索していく方法
Pseudo labeling テストデータに対する予測値を目的変数の値とみなし、 学習データに加えて再度学習するテクニック(半教師あり学習) テストデータの数が学習データの数より多い場合などに有効
コラム:分析コンペ用のクラスやフォル ダ構成 クラス構成 • Modelクラス • Runnerクラス • Utilクラス、Loggerクラス フォルダ構成
• input • code / code-analysys • model • sugmission
クラスやフォルダ構成の 参考リンク 「分析コンペ用のクラスやフォルダの構成」サンプルコード https://github.com/ghmagazine/kagglebook/tree/master/ch0 データサイエンスプロジェクトのディレクトリ構成どうするか問題 https://takuti.me/note/data-science-project-structure/ Patterns for Research in
Machine Learning http://arkitus.com/patterns-for-research-in-machine-learning/
まとめ モデルとは • 特徴量を入力データとし、予測値を出力する変換器のこと • モデルは学習・評価・予測の流れで作成する 分析コンペで使われるモデル • 初手はGBDT、特にlightgbmを使う場合が多い •
目的に応じて、ニューラルネットや線形モデルも使用する モデルのその他のポイントとテクニック • GBDTの使用。欠損値補間 • 特徴量選択 • Psudo labeling
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}