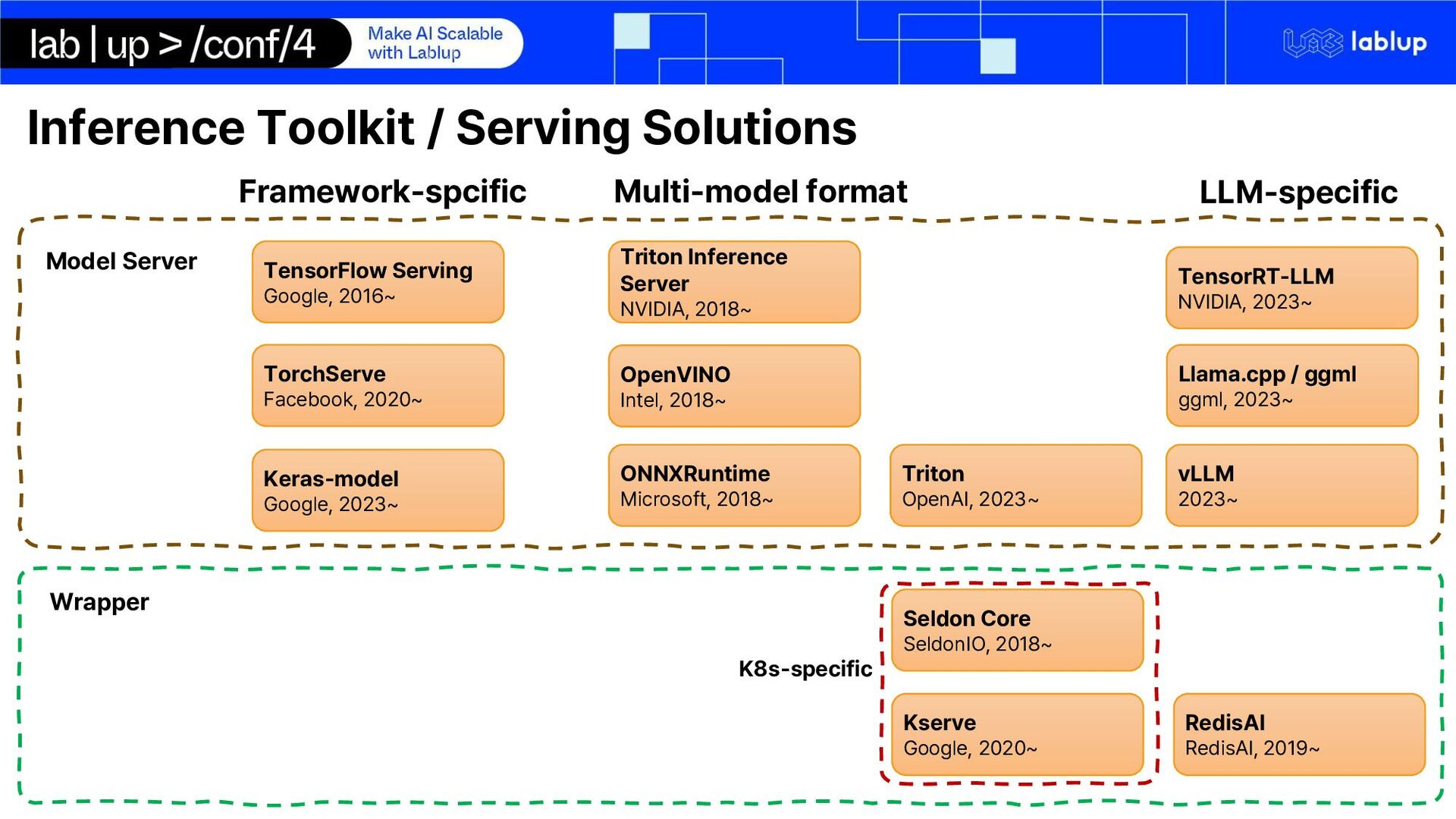
Inference Server NVIDIA, 2018~ OpenVINO Intel, 2018~ ONNXRuntime Microsoft, 2018~ RedisAI RedisAI, 2019~ TorchServe Facebook, 2020~ Seldon Core SeldonIO, 2018~ Kserve Google, 2020~ Framework-spcific Multi-model format Model Server Wrapper K8s-specific Triton OpenAI, 2023~ TensorRT-LLM NVIDIA, 2023~ Llama.cpp / ggml ggml, 2023~ LLM-specific vLLM 2023~ Keras-model Google, 2023~
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}