enrich, analyse} and retrieve; •Real-time: retrieve is not a batch process; •App: something your mother could use: SELECT attendees FROM NoSQLMatters WHERE password = '1234';
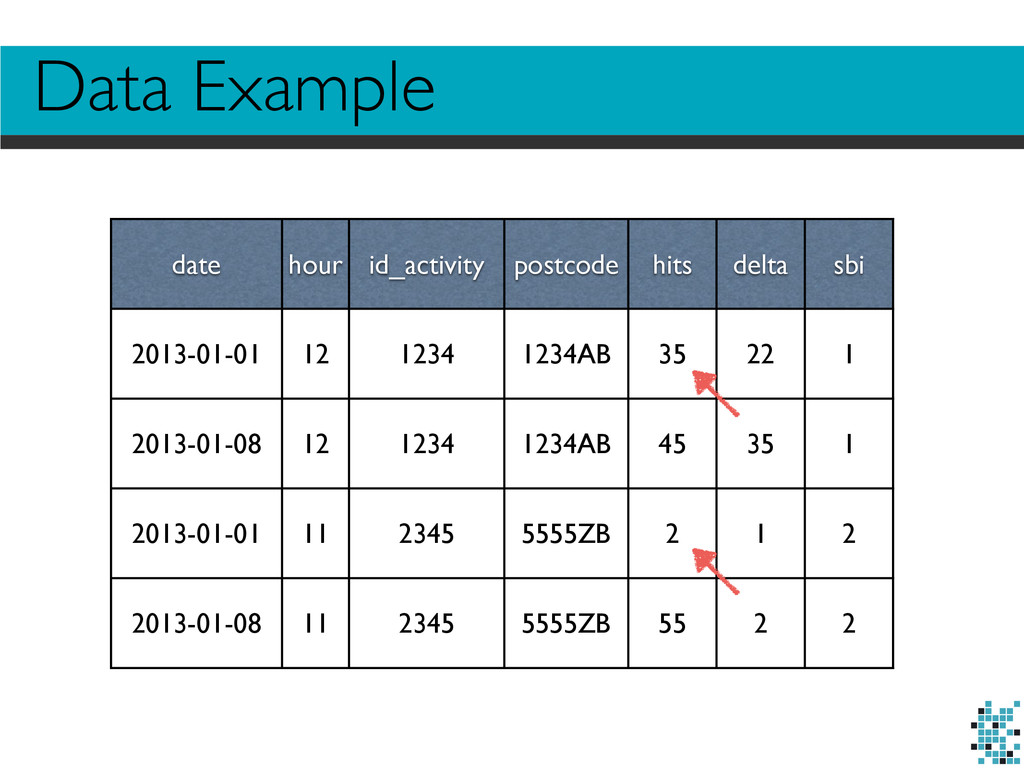
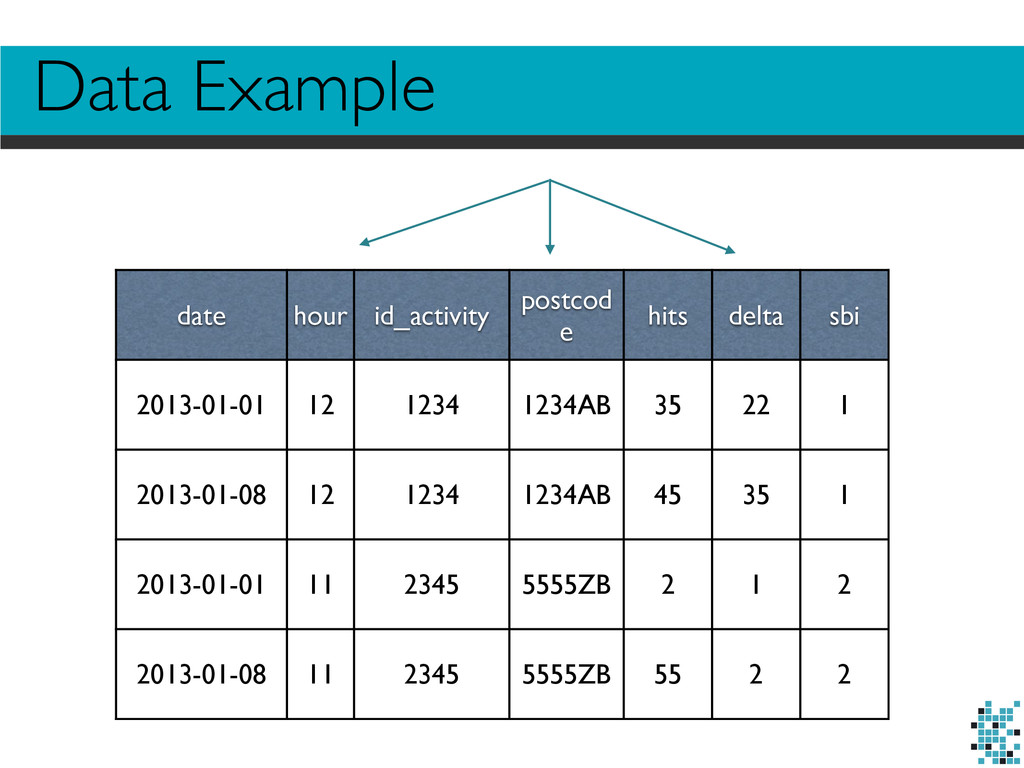
10k postcodes. You need to do this in your SQL: •Index on date and postcode, but single queries running more than 20 minutes. SELECT * FROM datapoints WHERE date IN date_array AND postcode IN postcode_array;
objects allowing location queries: SELECT * FROM datapoints WHERE ST_DWithin(lon, lat, 1500) AND dates IN ('2013-02-30', '2013-02-31'); -- every point within 1.5km -- from (lat, lon) on imaginary dates Postgres + Postgis (2.x)
date; 2. Use the temporary table trick: 3. Lose precision: 1234AB→1234 CREATE TEMPORARY TABLE tmp (postcodes STRING NOT NULL PRIMARY KEY); INSERT INTO tmp (postcodes) VALUES postcode_array; SELECT * FROM tmp JOIN datapoints d ON d.postcode = tmp.postcodes WHERE d.dt IN dates_array;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![helper.py example def get_statistics(data, sbi): sbi_df = data[data.sbi == sbi]](https://files.speakerdeck.com/presentations/c49f5fa0546a01321b06524ec95472fc/slide_19.jpg){kind=link}
![helper.py example def get_timeline(data, sbi): df_sbi = data.groupby([“date”, “hour", “sbi"]).aggregate(sum)](https://files.speakerdeck.com/presentations/c49f5fa0546a01321b06524ec95472fc/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GoDataDriven We’re hiring / Questions? / Thank you! @gglanzani [email protected]](https://files.speakerdeck.com/presentations/c49f5fa0546a01321b06524ec95472fc/slide_35.jpg){kind=link}