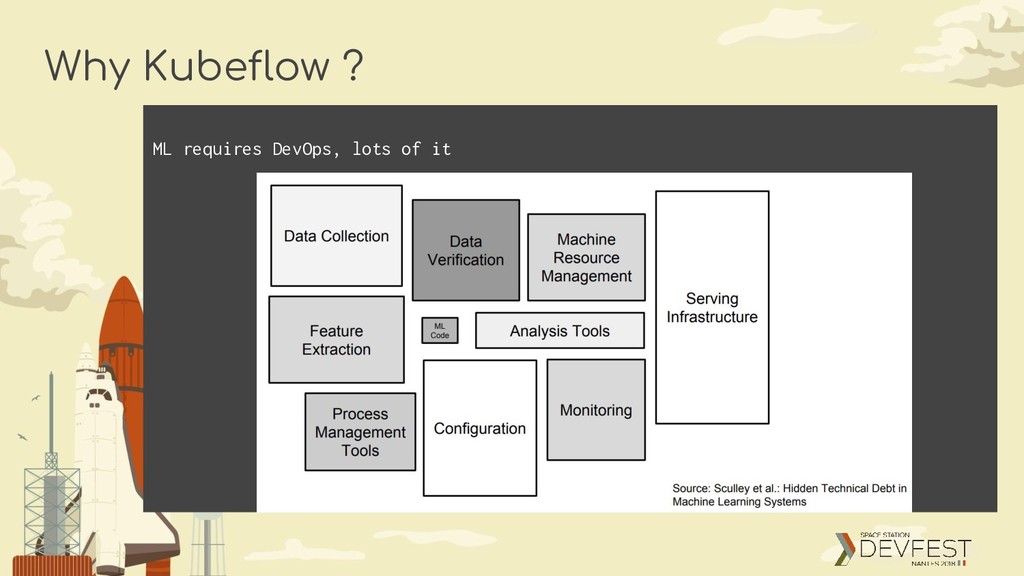
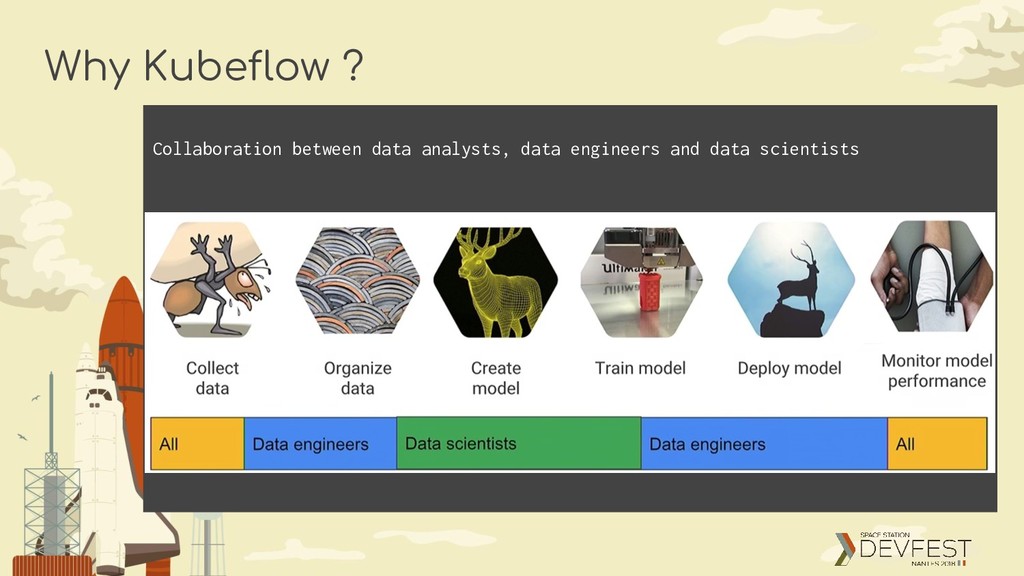
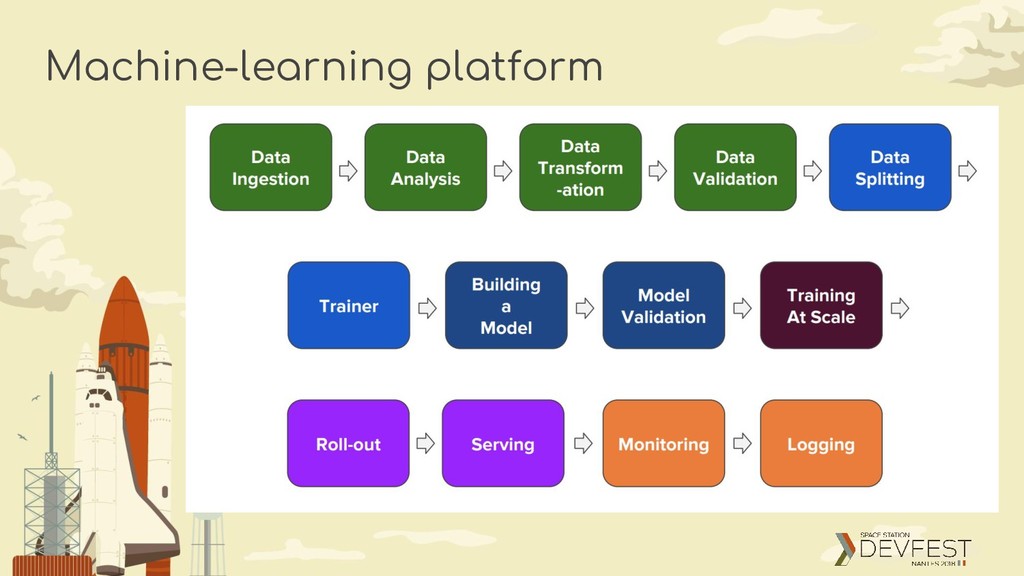
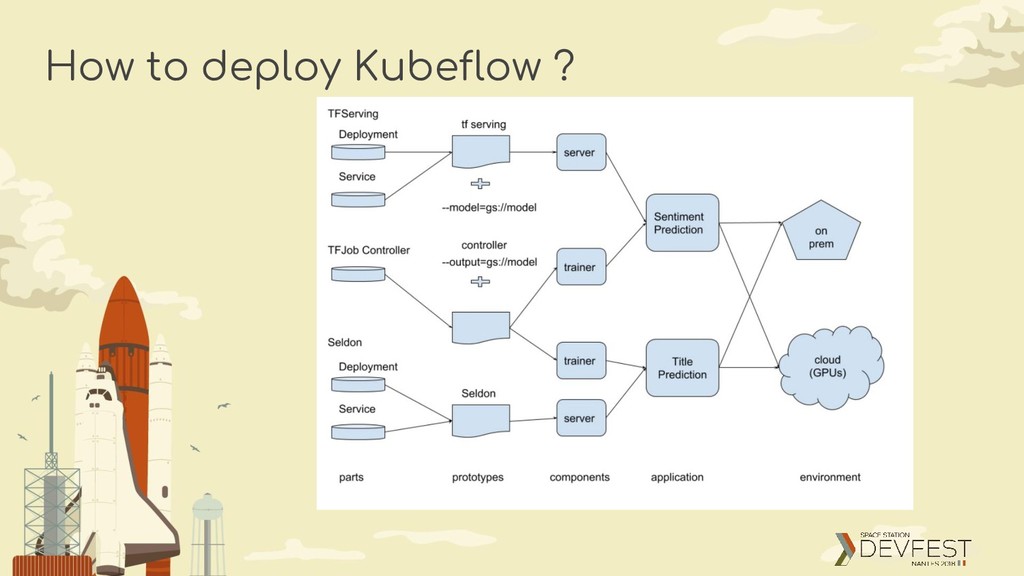
making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. Our goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.
• Jupyterhub ◦ Multi server for Jupyter notebooks • Katib ◦ Hyperparameter tuning system Clone of Vizier (Google's HP Tuning System) • KVC ◦ Kubernetes Volume Controller • CRDs for various ML frameworks ◦ tf-operator, PyTorch operator, caffe-2, etc.
• SeldonIO ◦ CRD & tooling for serving and deploying models • Argo ◦ CRD for workflow • Pachyderm ◦ deploy and manage multi-stage data pipelines while maintaining complete reproducibility and provenance • Tensor2tensor ◦ Library of TensorFlow models and datasets for a variety of applications
We want to be portable across different environments ksonnet is used to move ML applications between environments • local -> cloud • dev -> test -> prod Environments in ksonnet is a first-class citizen • It generates the various manifests for Kubernetes
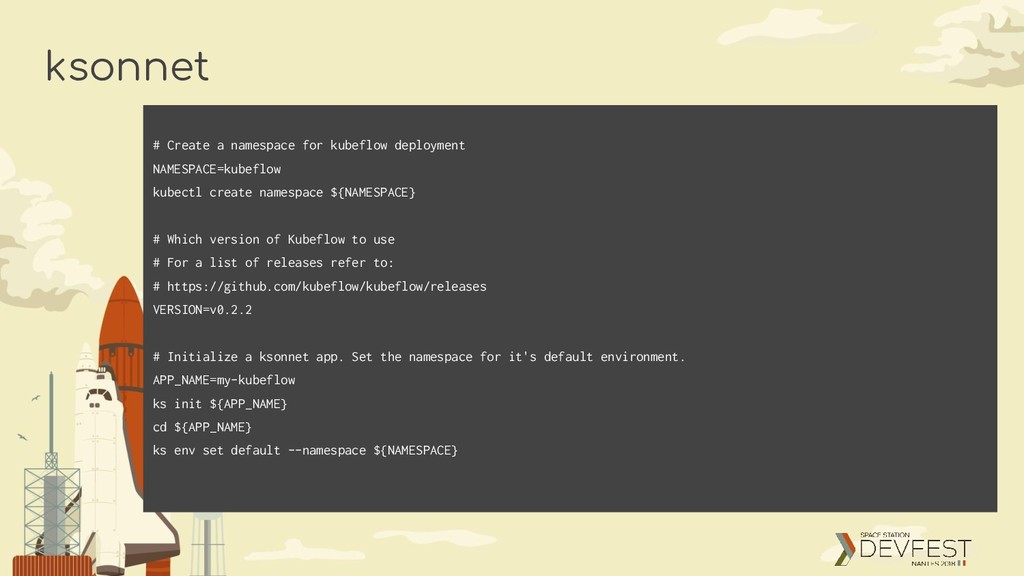
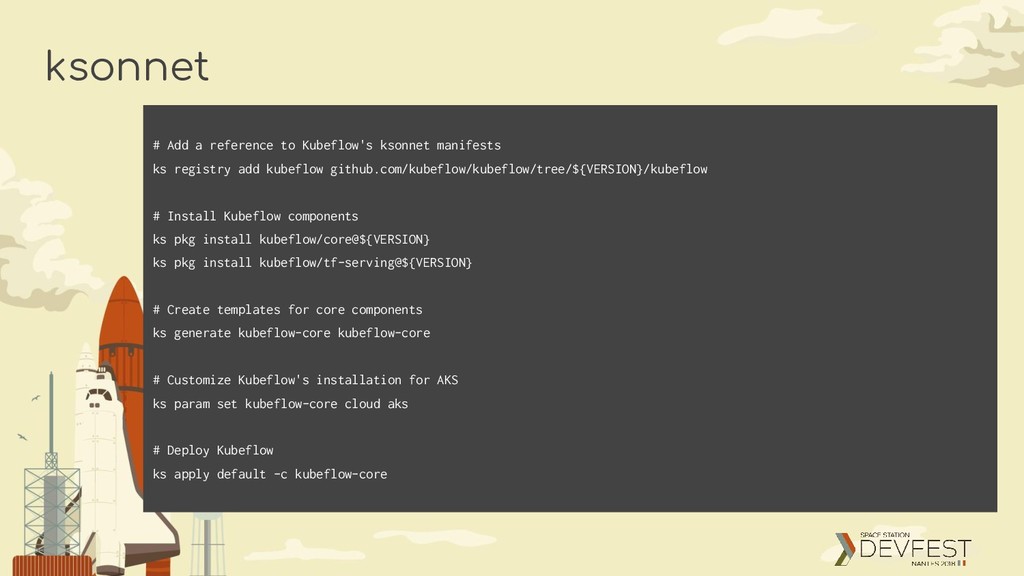
create namespace ${NAMESPACE} # Which version of Kubeflow to use # For a list of releases refer to: # https://github.com/kubeflow/kubeflow/releases VERSION=v0.2.2 # Initialize a ksonnet app. Set the namespace for it's default environment. APP_NAME=my-kubeflow ks init ${APP_NAME} cd ${APP_NAME} ks env set default --namespace ${NAMESPACE}
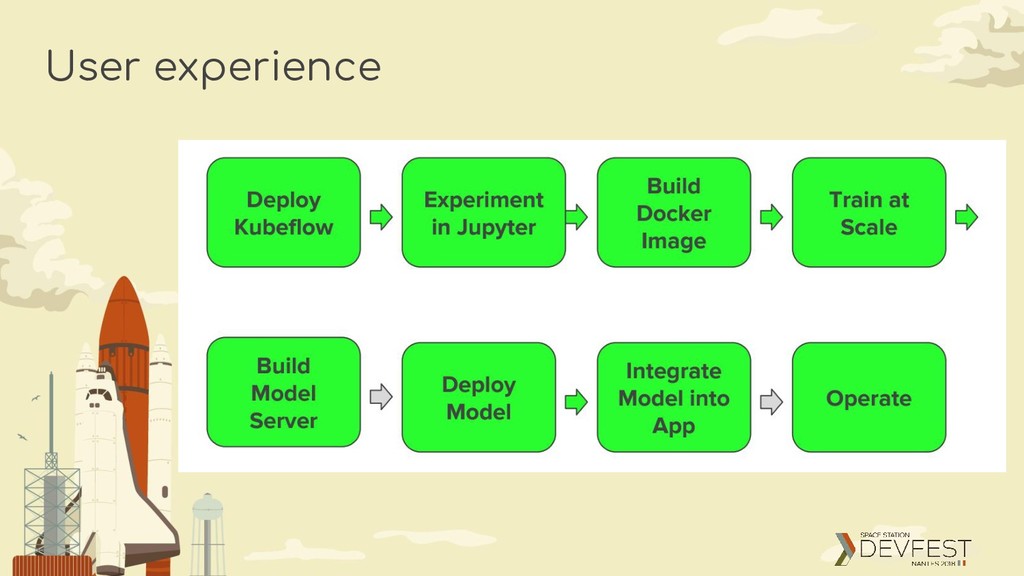
allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more
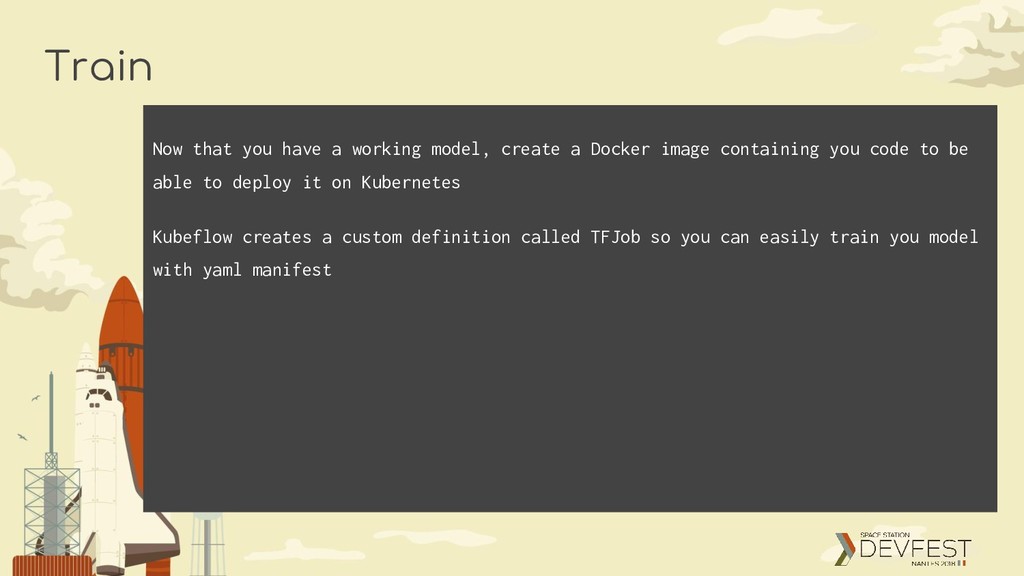
Docker image containing you code to be able to deploy it on Kubernetes Kubeflow creates a custom definition called TFJob so you can easily train you model with yaml manifest
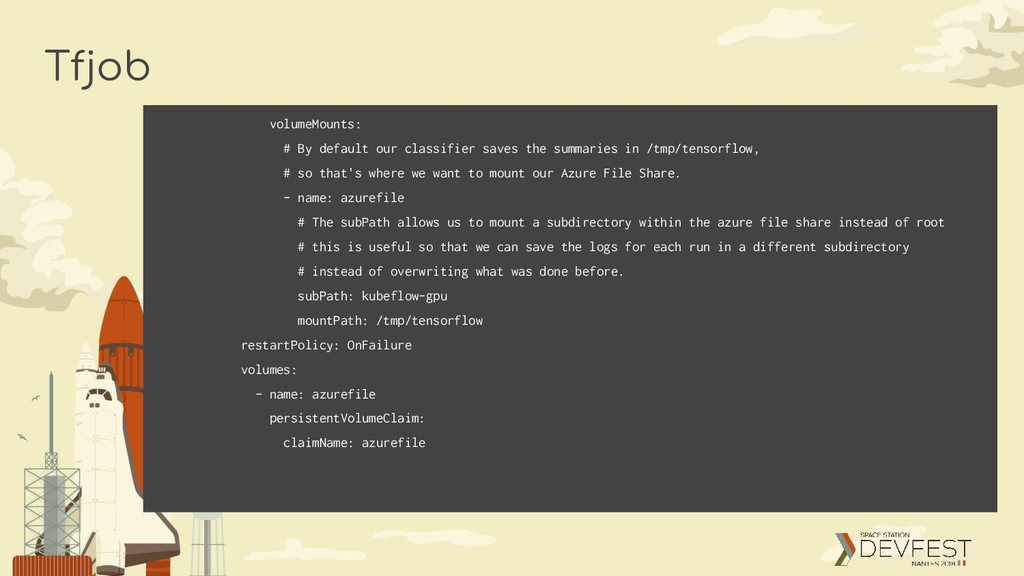
in /tmp/tensorflow, # so that's where we want to mount our Azure File Share. - name: azurefile # The subPath allows us to mount a subdirectory within the azure file share instead of root # this is useful so that we can save the logs for each run in a different subdirectory # instead of overwriting what was done before. subPath: kubeflow-gpu mountPath: /tmp/tensorflow restartPolicy: OnFailure volumes: - name: azurefile persistentVolumeClaim: claimName: azurefile
GPU computing) • Set the network (VMs have to talk to each others) • Upload the TF code in every machine • Modify the model to add distributed training cluster = tf.train.ClusterSpec({"worker": ["<IP_GPU_VM_1>:2222", "<IP_GPU_VM_2>:2222"], "ps": ["<IP_CPU_VM_1>:2222", "<IP_CPU_VM_2>:2222"]}) • Lots of other things to do (splitting operation across devices, getting the master session etc.)
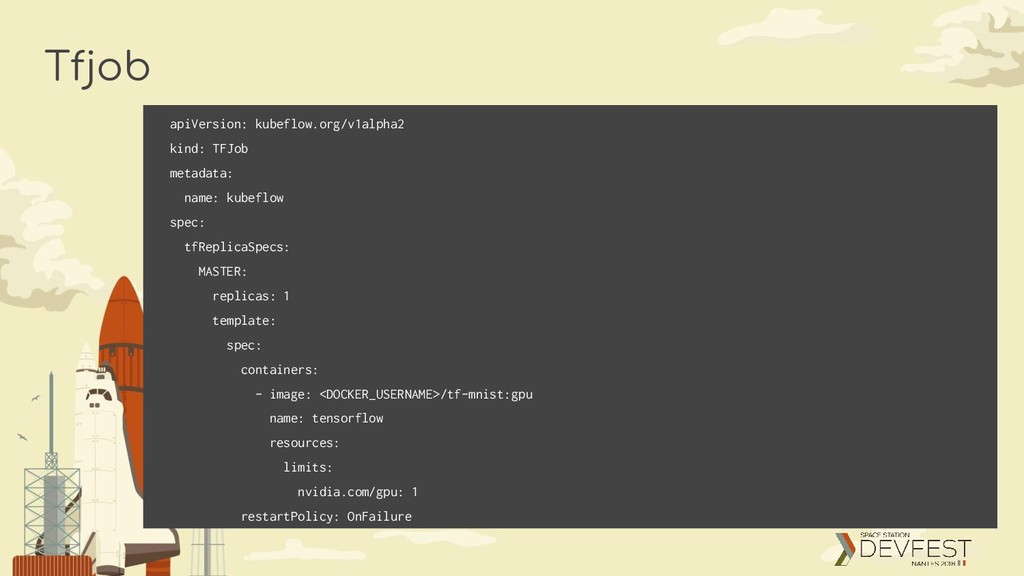
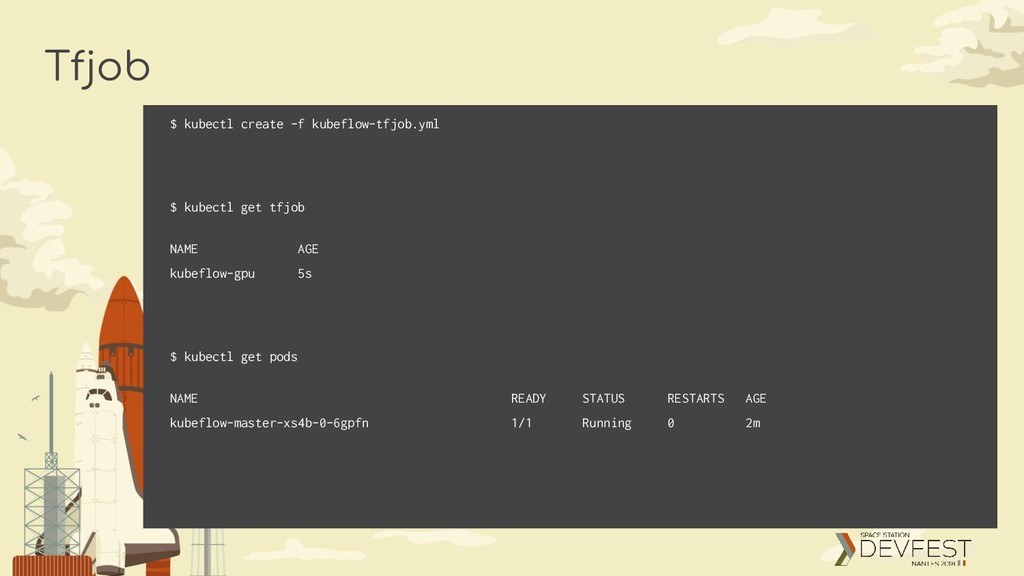
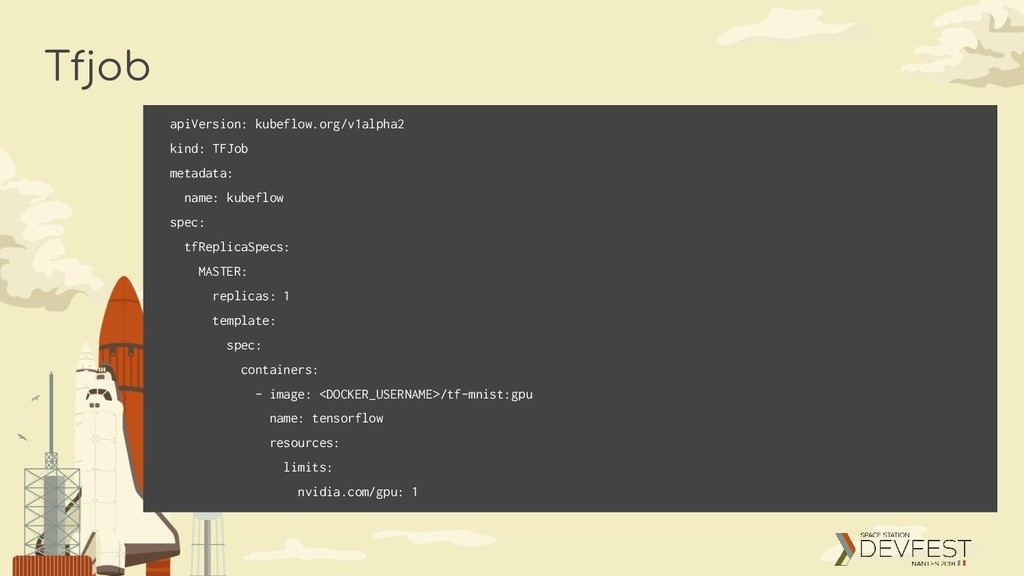
a “spec” section of type “TFJobSpec” TFJobSpec Defines a “TFReplicaSet” of type “TFReplicaSetSpec” TFReplicaSetSpec Defines a TFReplicaType, which can be MASTER, WORKER or PS
= os.environ.get("TF_CONFIG", "{}") # Deserialize to a python object tf_config = json.loads(tf_config_json) # Grab the cluster specification from tf_config and create a new tf.train.ClusterSpec instance with it cluster_spec = tf_config.get("cluster", {}) cluster_spec_object = tf.train.ClusterSpec(cluster_spec) # Grab the task assigned to this specific process from the config. job_name might be "worker" and task_id might be 1 for example task = tf_config.get("task", {}) job_name = task["type"] task_id = task["index"]
tf.train.ServerDef( cluster=cluster_spec_object.as_cluster_def(), protocol="grpc", job_name=job_name, task_index=task_id) server = tf.train.Server(server_def) # checking if this process is the chief (also called master). The master has the responsibility of creating the session, saving the summaries etc. is_chief = (job_name == 'master') # Notice that we are not handling the case where job_name == 'ps'. That is because `TFJob` will take care of the parameter servers for us by default.
for job master -> {0 -> localhost:2222} Initialize GrpcChannelCache for job ps -> {0 -> kubeflow-ps-m8vi-0:2222} Initialize GrpcChannelCache for job worker -> {0 -> kubeflow-worker-m8vi-0:2222, 1 -> kubeflow-worker-m8vi-1:2222} 2018-04-30 22:45:28.963803: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:333] Started server with target: grpc://localhost:2222 ... Accuracy at step 970: 0.9784 Accuracy at step 980: 0.9791 Accuracy at step 990: 0.9796 Adding run metadata for 999
of values.yaml in variable to make it easier to access them {{- $lrlist := .Values.hyperParamValues.learningRate -}} {{- $nblayerslist := .Values.hyperParamValues.hiddenLayers -}} # Then we loop over every value of $lrlist (learning rate) and $nblayerslist (hidden layer depth) # This will result in create 1 TFJob for every pair of learning rate and hidden layer depth {{- range $i, $lr := $lrlist }} {{- range $j, $nblayers := $nblayerslist }} apiVersion: kubeflow.org/v1alpha2 kind: TFJob # Each one of our trainings will be a separate TFJob metadata: name: kubeflow-tf-mnist-{{ $i }}-{{ $j }} # We give a unique name to each training
unique learning rate and hidden layer count to each instance. # We also put the values between quotes to avoid potential formatting issues - --learning-rate - {{ $lr | quote }} - --hidden-layers - {{ $nblayers | quote }} - --logdir - /tmp/tensorflow/tf-mnist-lr{{ $lr }}-d-{{ $nblayers }} # We save the summaries in a different directory
set --env=$ENV $MODEL_COMPONENT version v2 $ ks param set --env=$ENV $MODEL_COMPONENT firstVersion false $ ks apply $ENV -c $MODEL_COMPONENT But traffic continues to go on v1 We have to update the rules
training and the operations of ML models at scale • It still a relatively young project, and not yet mature (1.0 target end of year) • Enabling Big Data and Machine Learning on Kubernetes will allow IT organizations to standardize on the same Kubernetes infrastructure, propeling adoption and reducing costs • Both Kubernetes and Kubeflow will enable IT organizations to focus more on effort on applications rather than infrastructure
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Tfjob $ kubectl logs <pod-name> [...] INFO:tensorflow:2017-11-20 20:57:22.314198: Step 480:](https://files.speakerdeck.com/presentations/4ce168281ac649ffbfdd0a0702a57c4f/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![See the logs $ kubectl logs <master-pod-name> [...] Initialize GrpcChannelCache](https://files.speakerdeck.com/presentations/4ce168281ac649ffbfdd0a0702a57c4f/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}