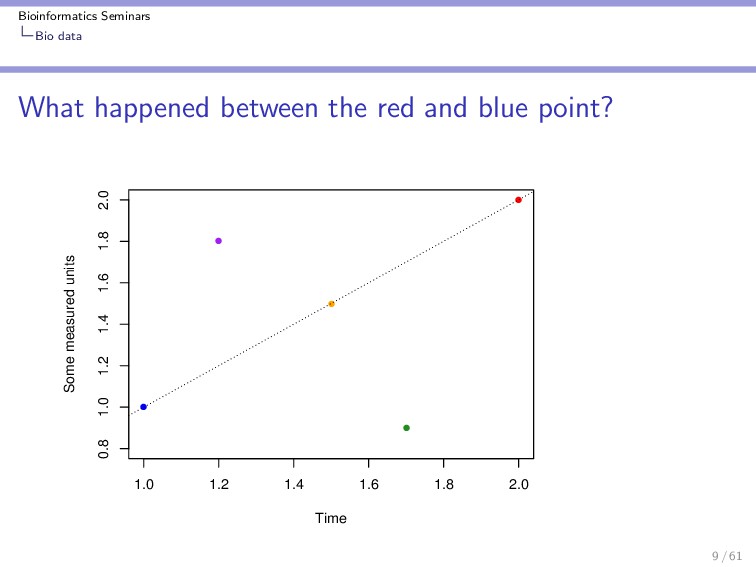
blue point? > plot(c(1, 2), c(1, 2), pch = 16, + col = c("blue", "red"), xlab = "Time", + ylab = "Some measured units", + ylim = c(0.8, 2)) > points(1.5, 1.5, col = "orange", + pch = 16) > points(1.2, 1.8, col = "purple", + pch = 16) > points(1.7, 0.9, col = "forest green", + pch = 16) > abline(0, 1, lty = 3) 8 / 61
![Bioinformatics Seminars Bioinformatics Seminars Leonardo Collado Torres [email protected] November 18th,](https://files.speakerdeck.com/presentations/464d2cce929a4682adddccf1d4560ce8/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
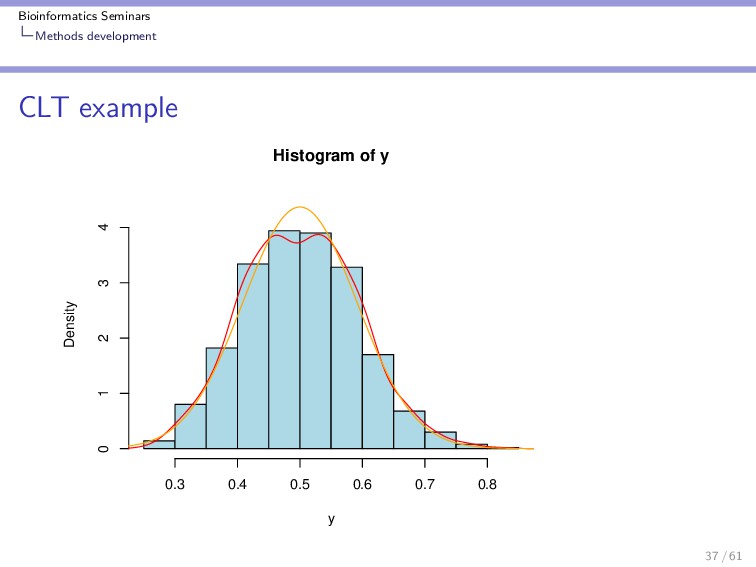{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
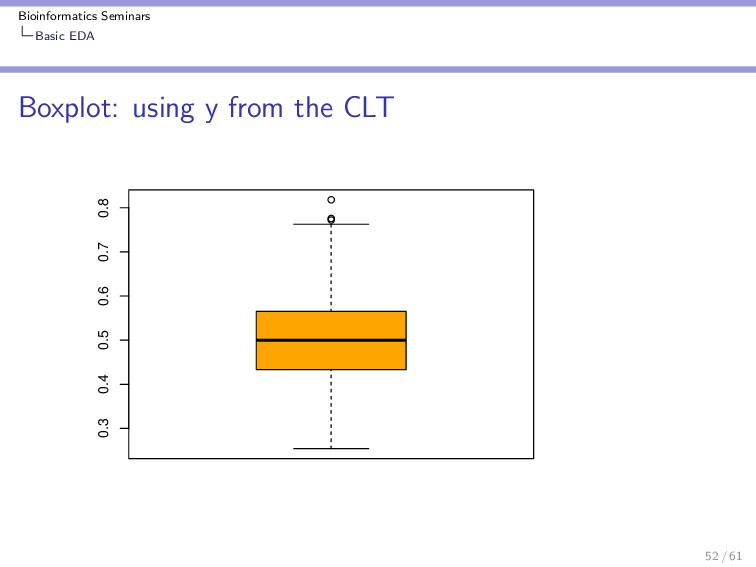{kind=link}
{kind=link}
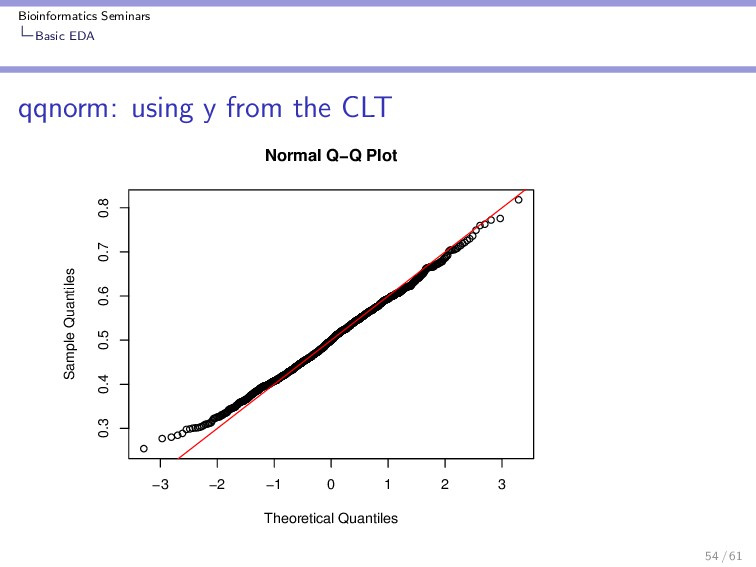{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}