EuroPython 2012 Talk.
**Abstract**:
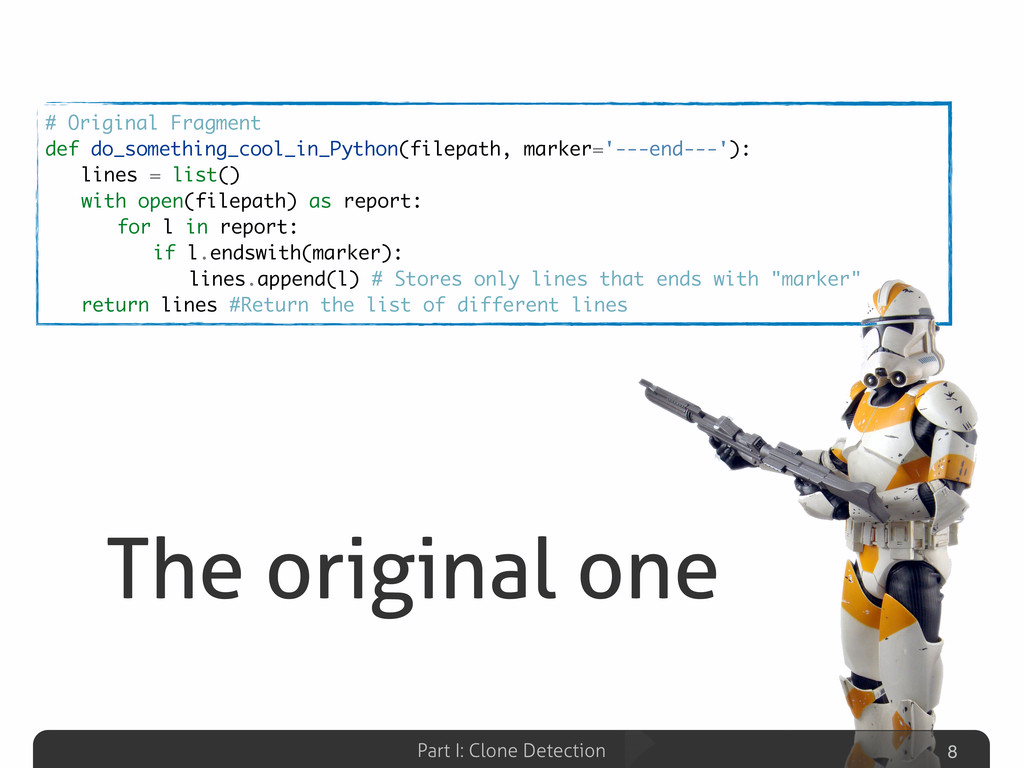
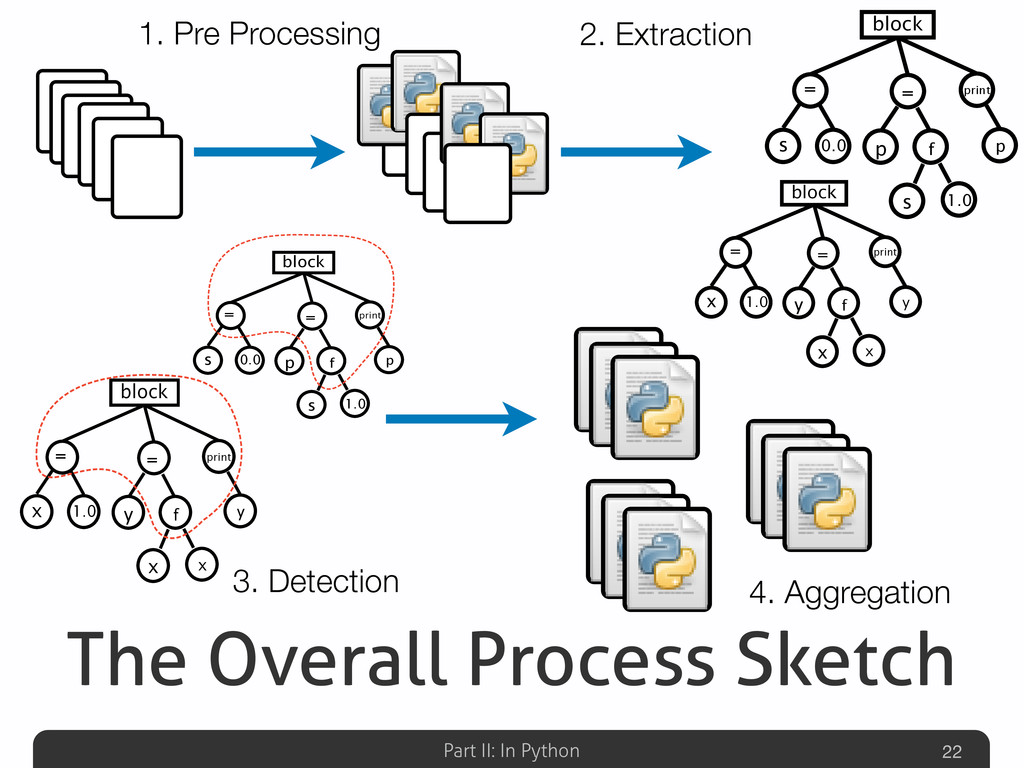
The clone detection is a longstanding and very active research area in the field of Software Maintenance aimed at identifying duplications in source code. The presence of clones may affect maintenance activities. For example, errors in the “original” fragment of code have to be fixed in every clone. To make things worse, code clones are usually not documented and so their location in the source code is not known. In case of small-size software systems the clone detection may be manually performed, but on large software systems it can be accomplished only by means of automatic techniques.
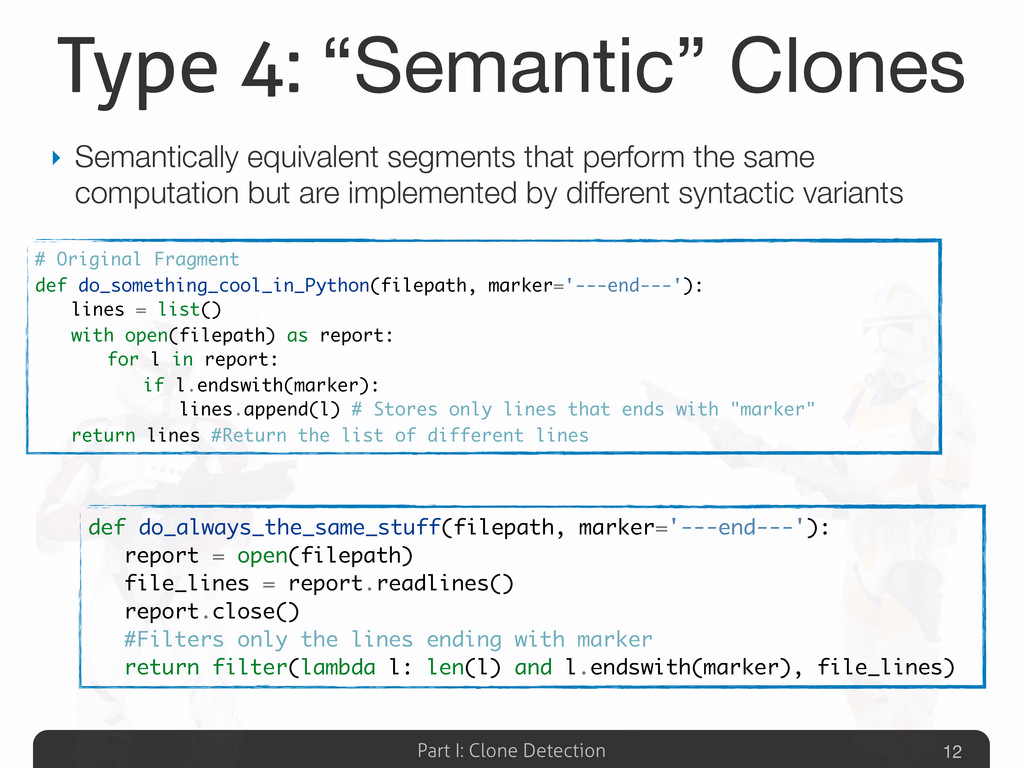
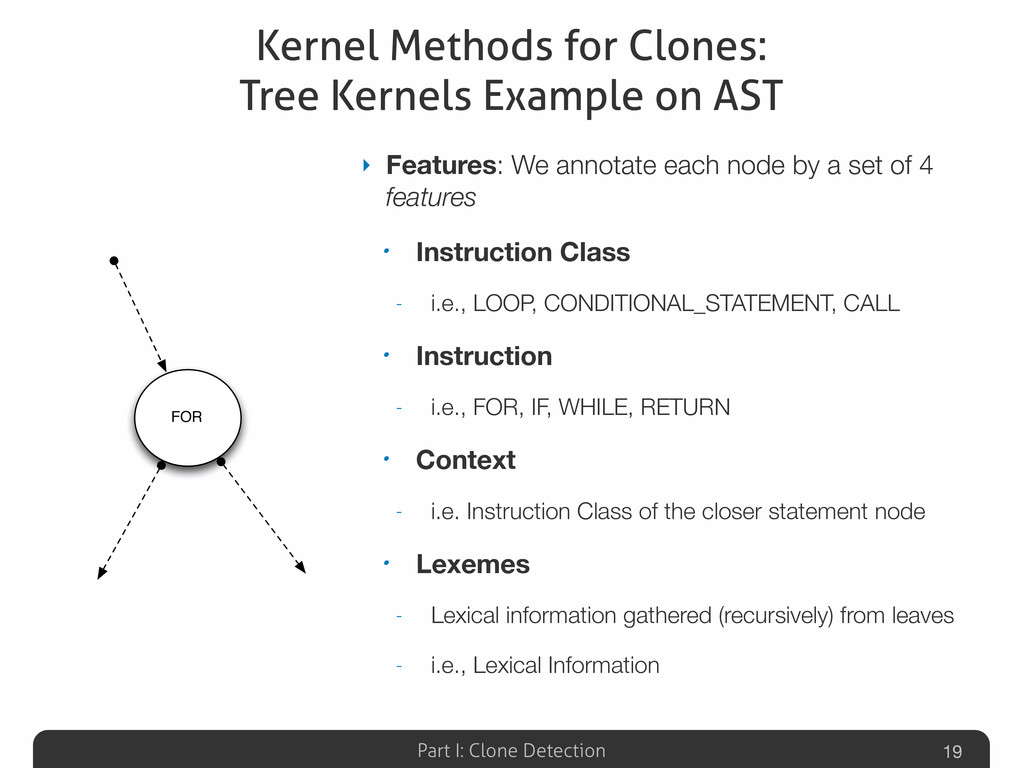
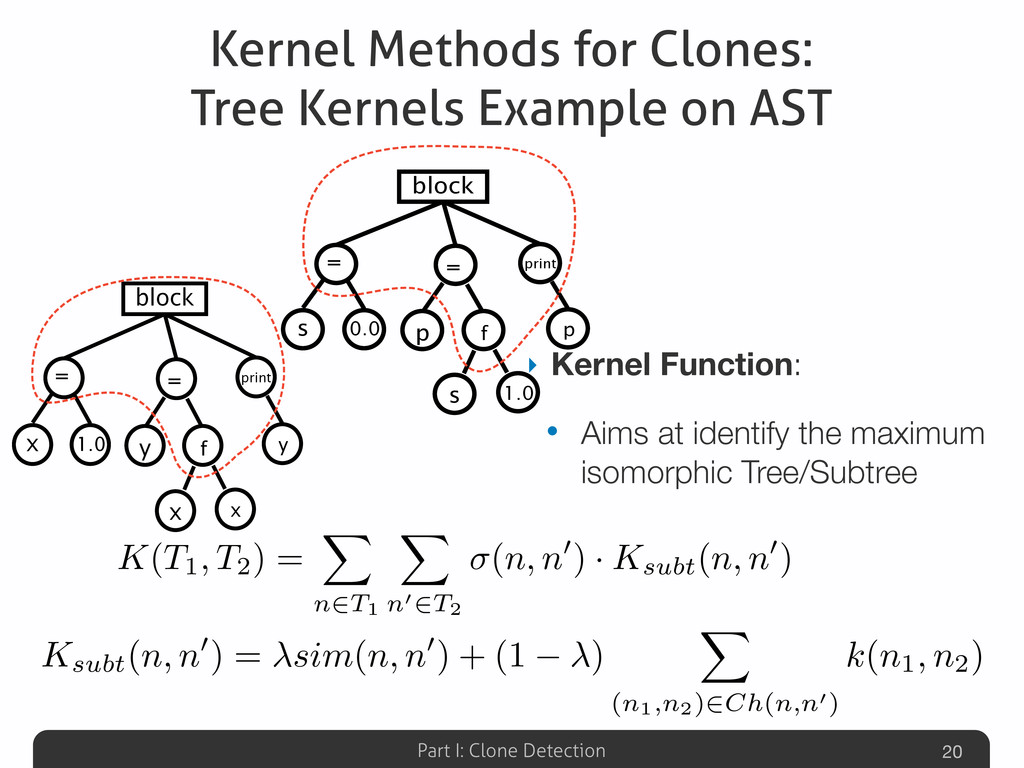
In this talk an approach that exploits structural (i.e., AST) and lexical information of the code (e.g., name of methods, variables) for the identification of clones will be presented. The main innovation of such approach is represented by the adoption of a Machine Learning technique based on (Tree) Kernel functions. Some insights on mathematical properties of these Kernel-based method along with its corresponding (efficient) Python implementation (Numpy, Scipy) will be presented.
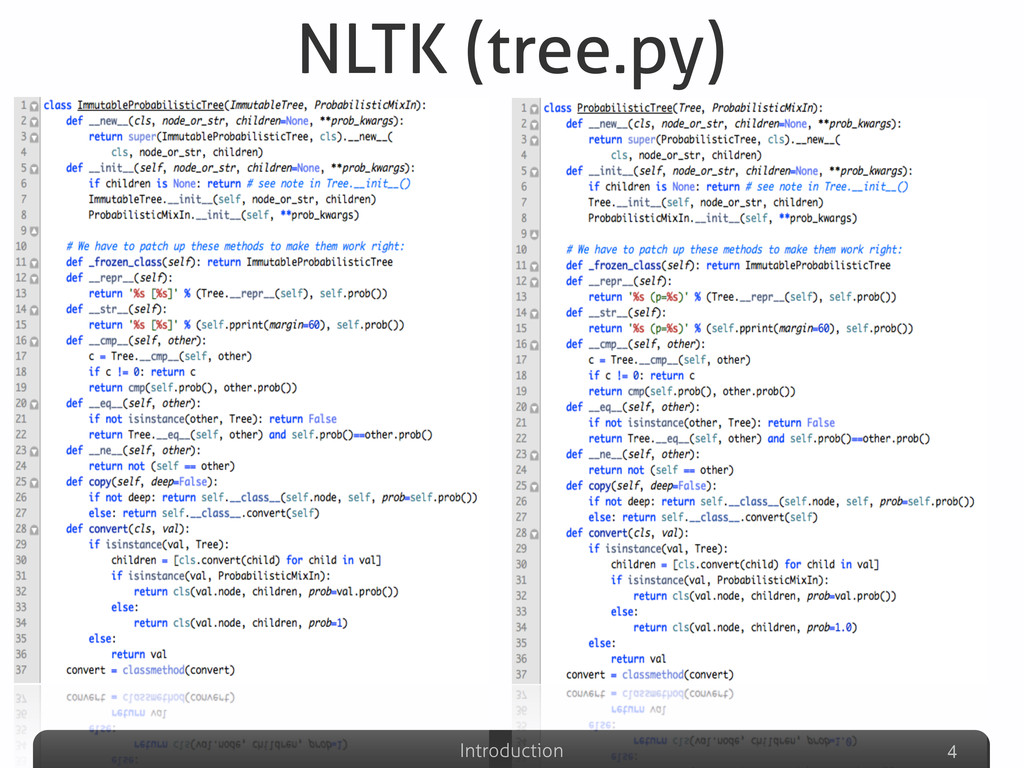
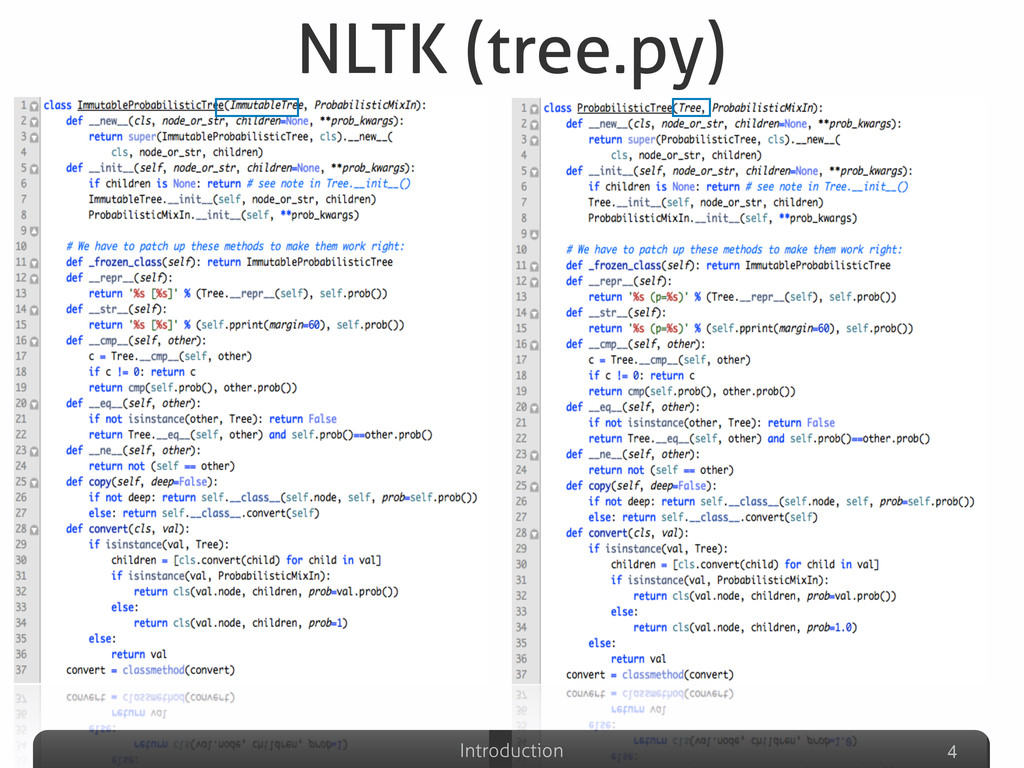
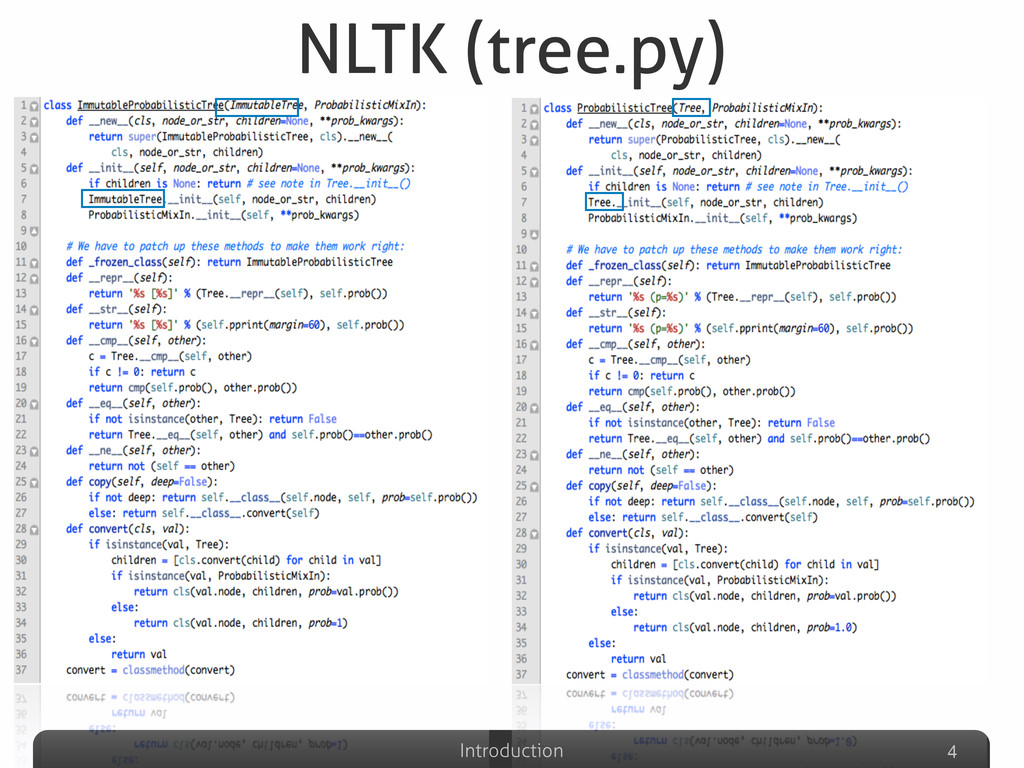
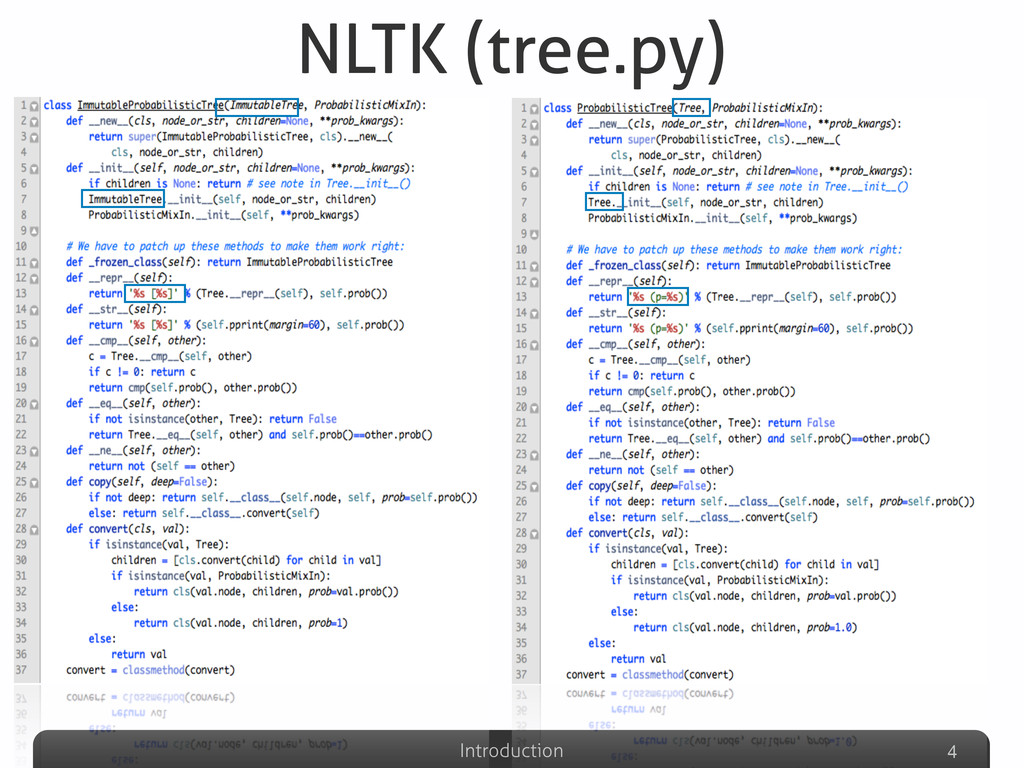
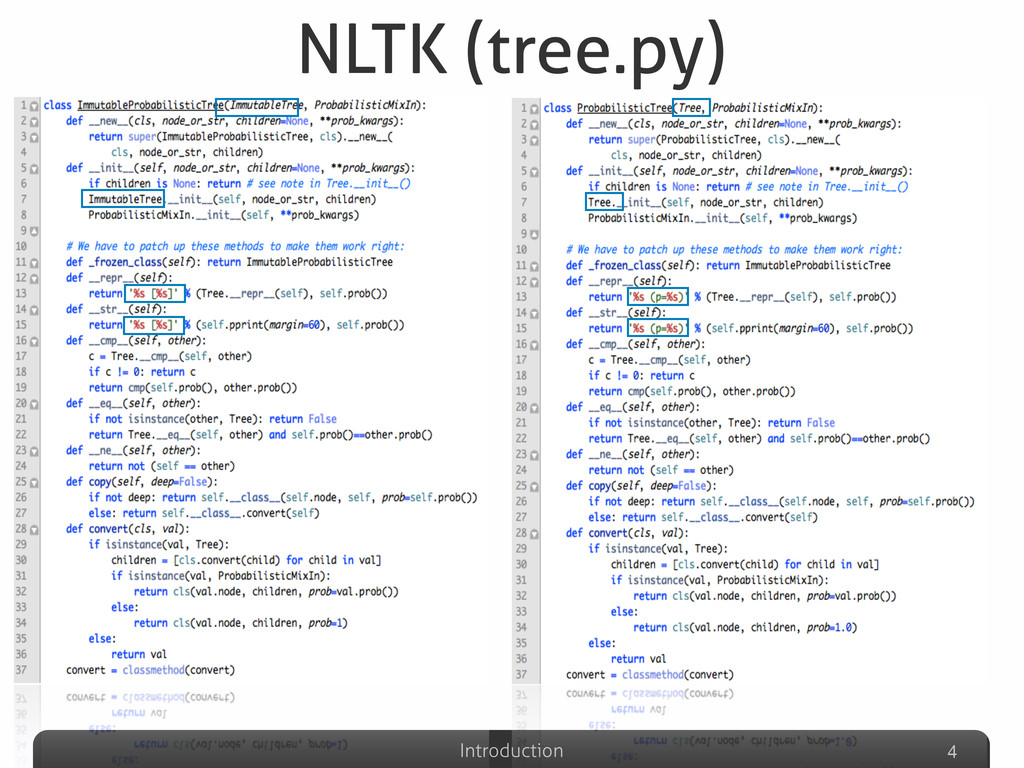
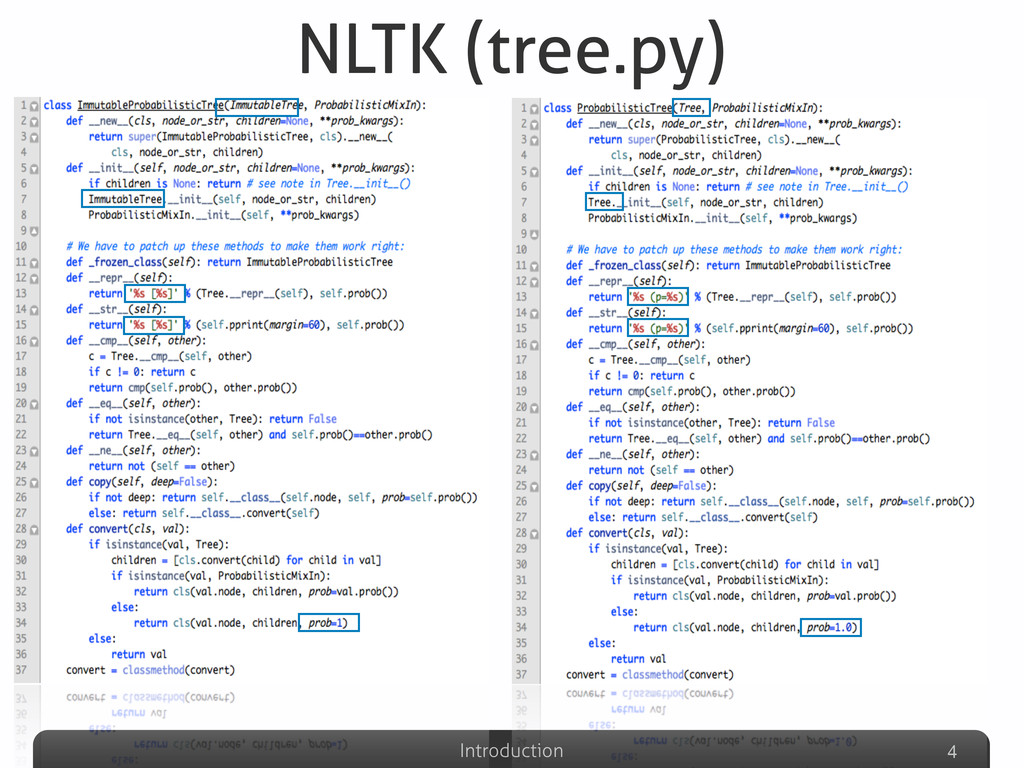
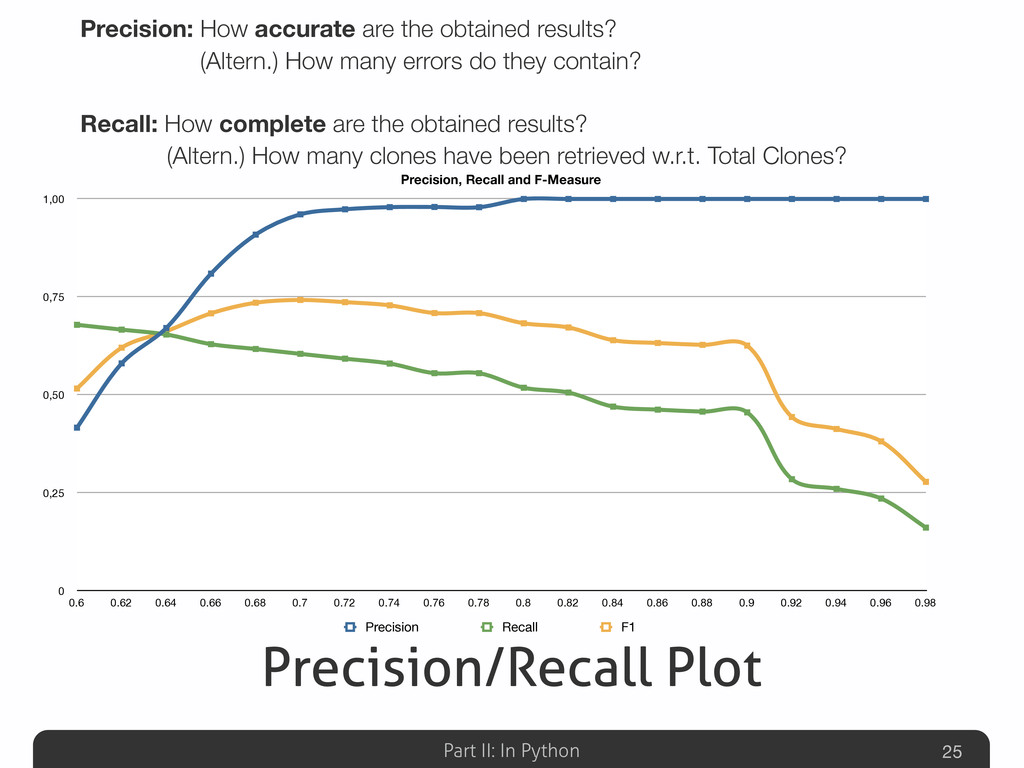
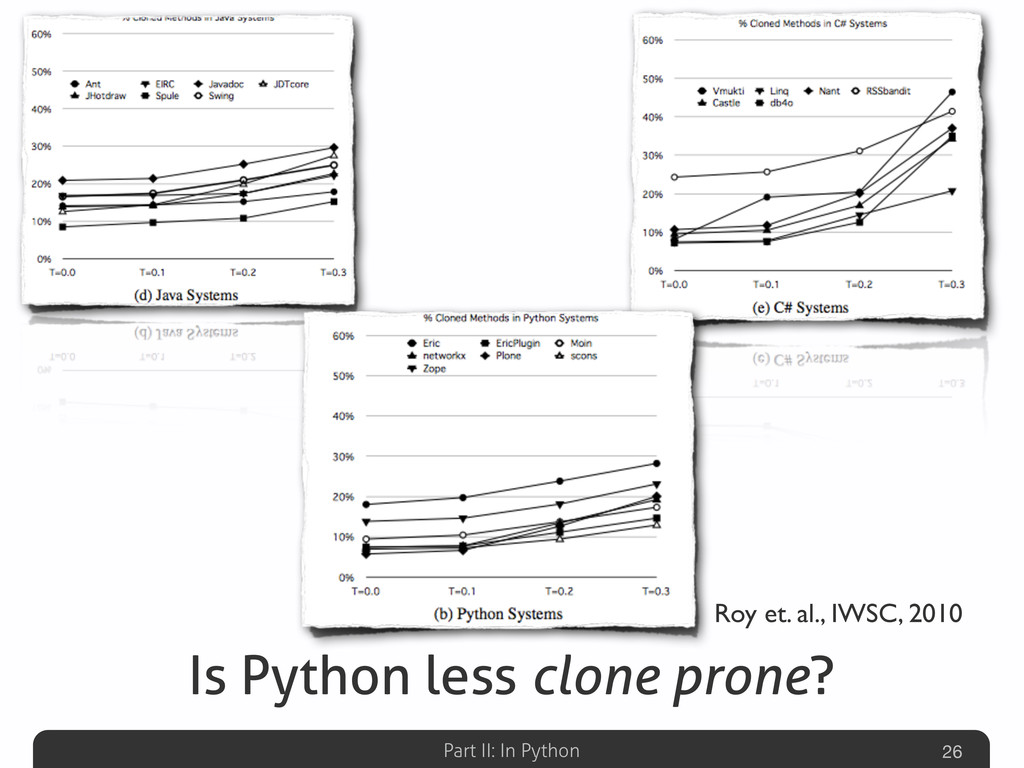
Afterwards the talk will be focused on the explanation of some detection results gathered on well-known Python systems (Eric, Plone, networkx, Zope), compared with other non-Python ones (Eclipse-Jdtcore, JHotDraw). The aim of this part will be to analyze what are the Python features that could possibly avoid (or allow) duplications w.r.t. other OO languages. Some snippets for analyzing the Python code “by itself” will be also presented, emphasizing the powerful Python built-in reflection capabilities, extremely useful in this specific code analysis task.
Basic maths skill and basic knowledge of the Python language are the only suggested prerequisites for the talk.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}