Slide of the talk presented at IEEE ICSM 2012 (International Conference on Software Maintenance), held in Riva del Garda (TN), Italy on Sept. 2012
**Abstract**:
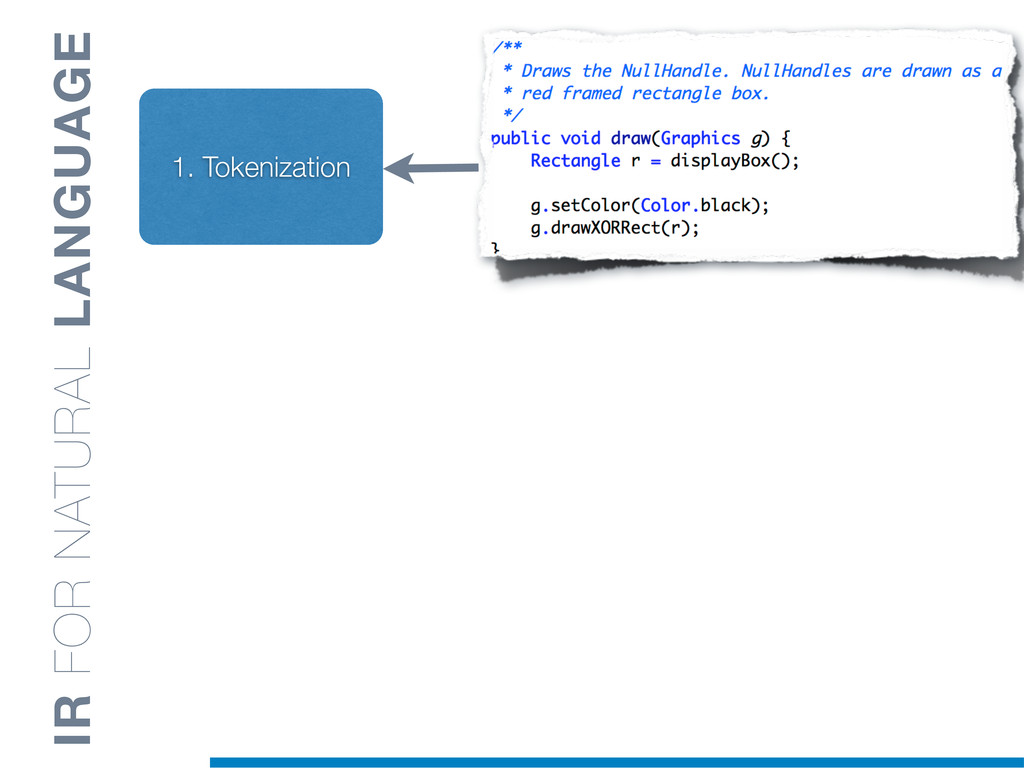
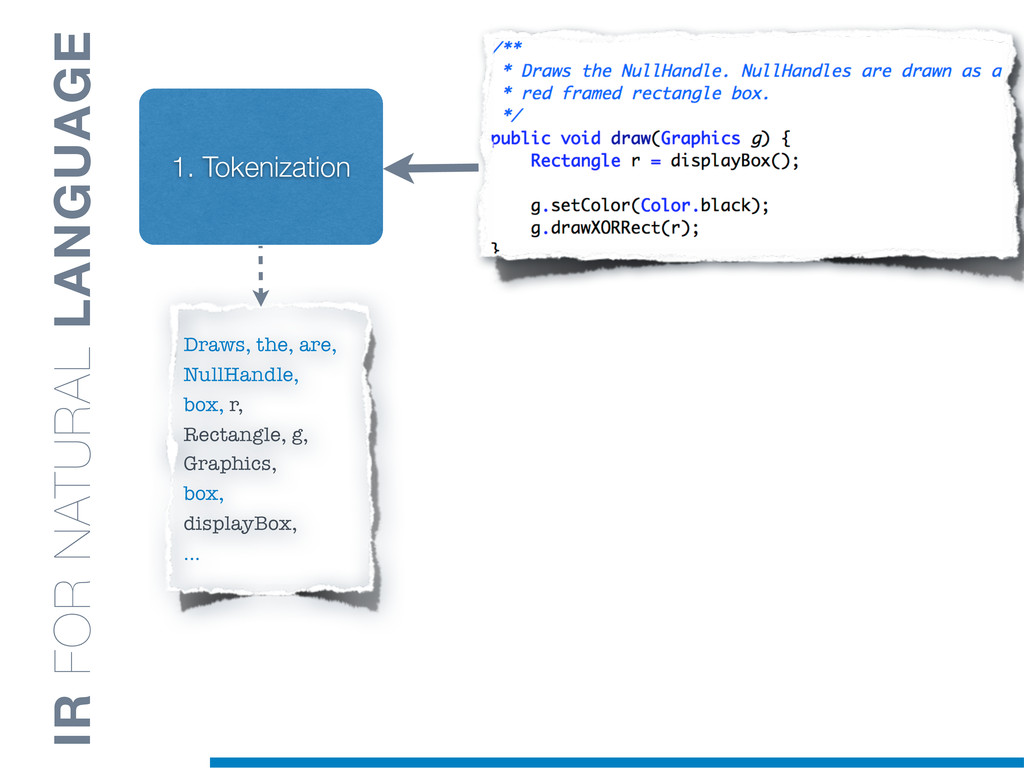
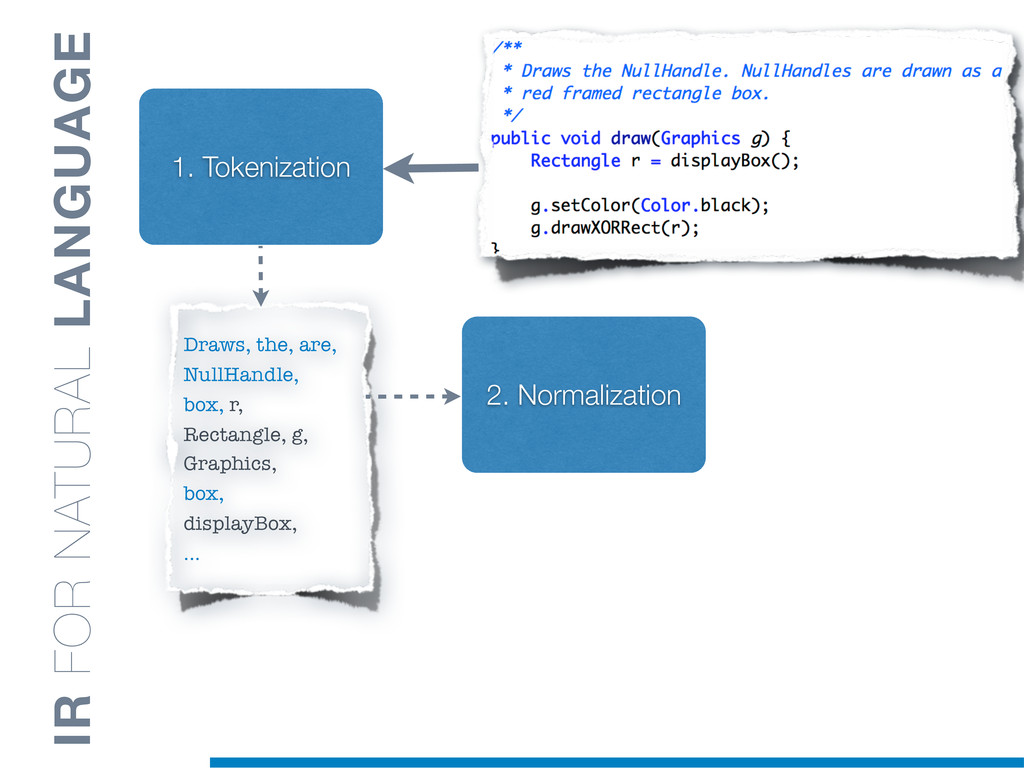
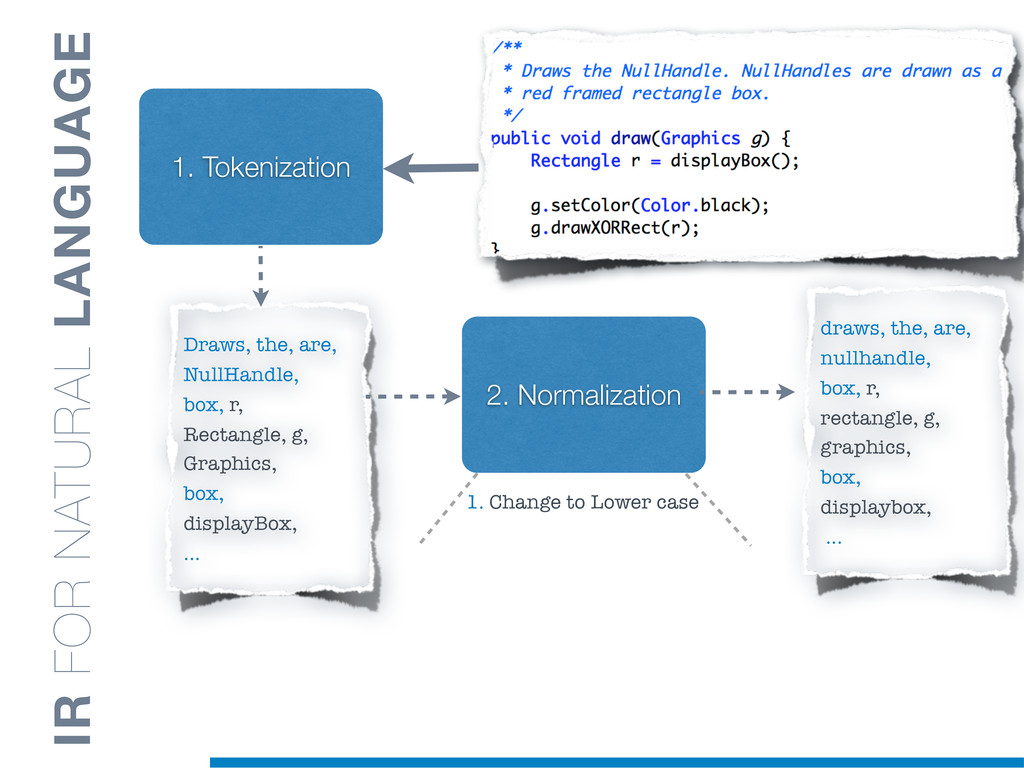
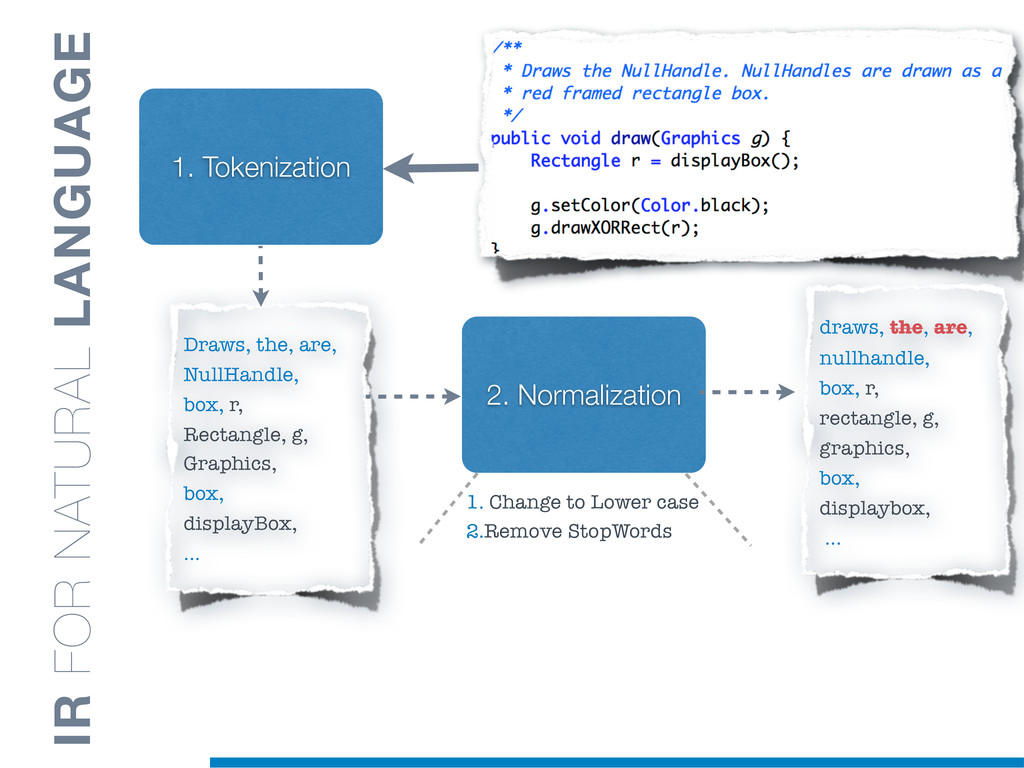
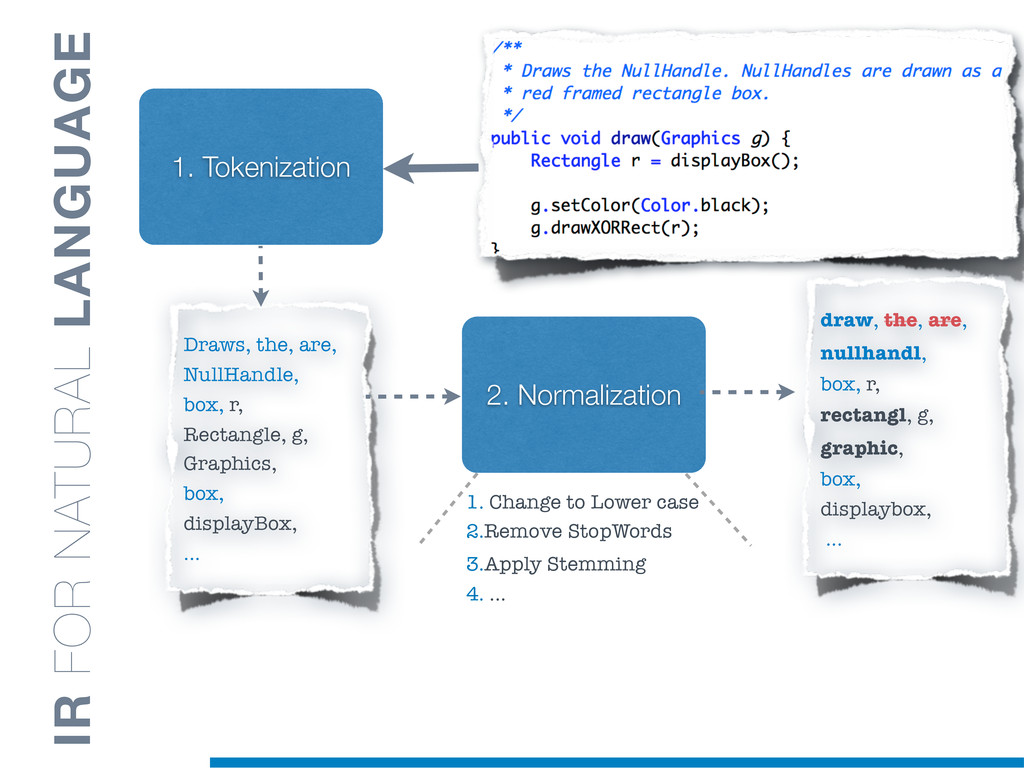
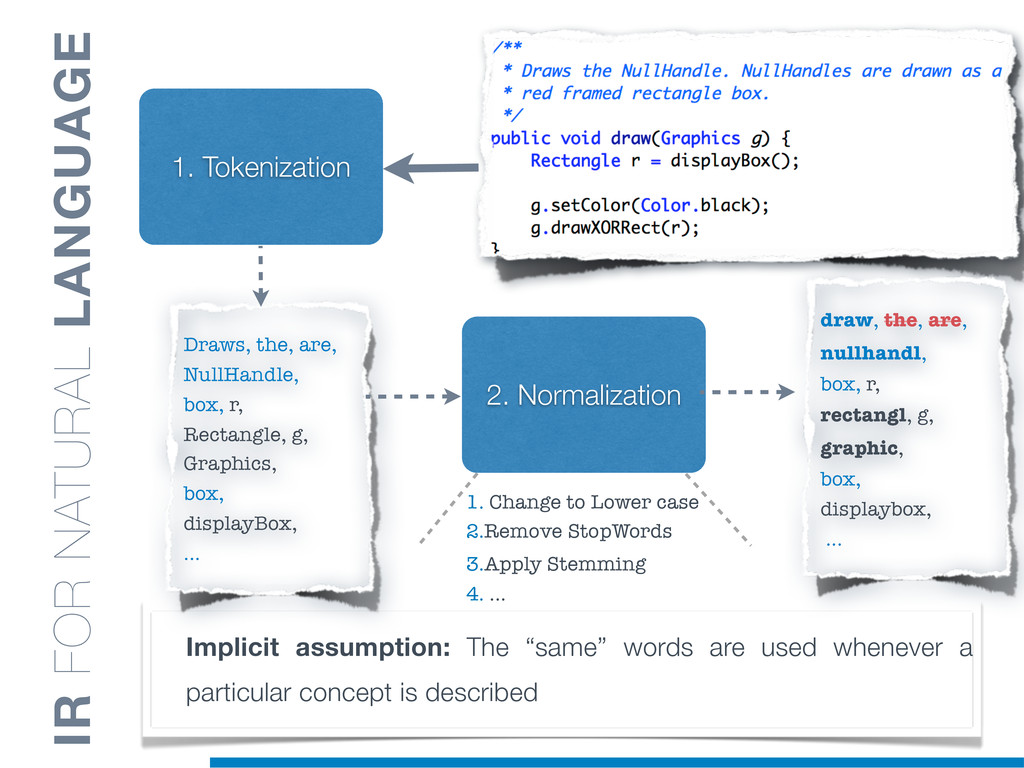
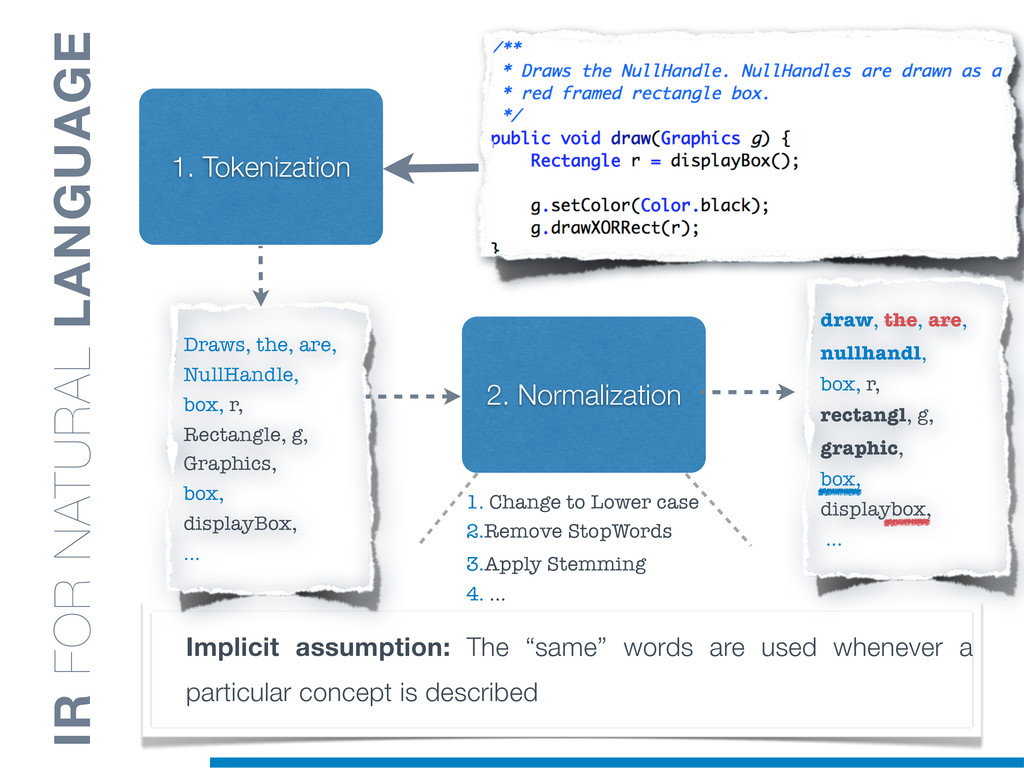
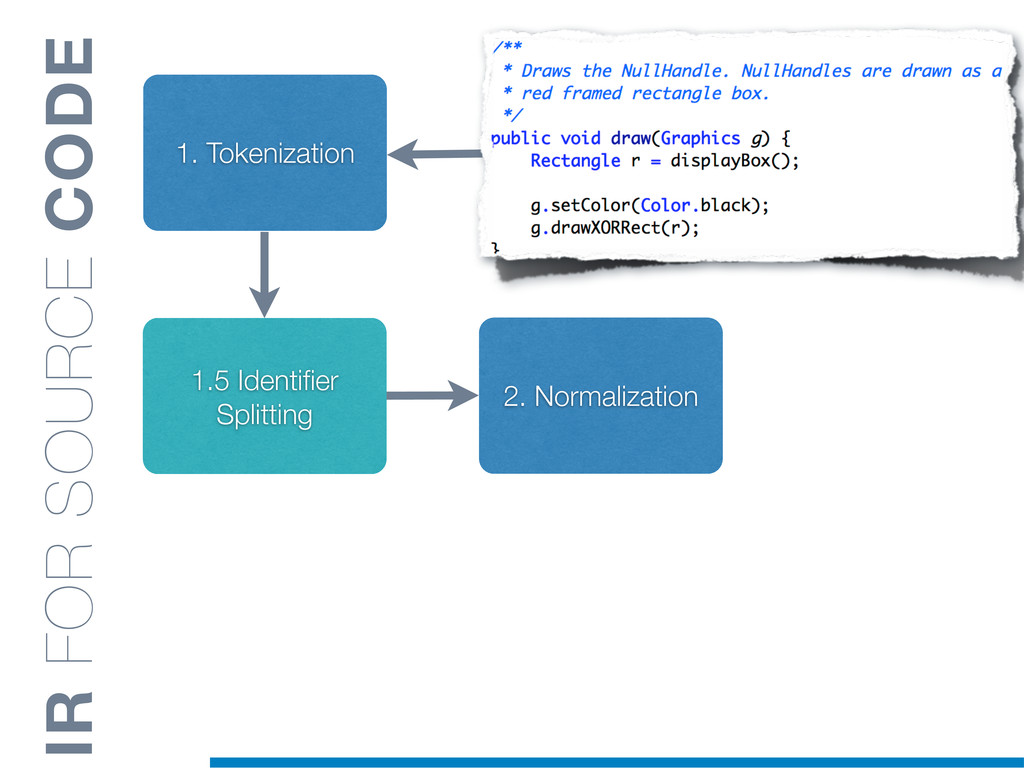
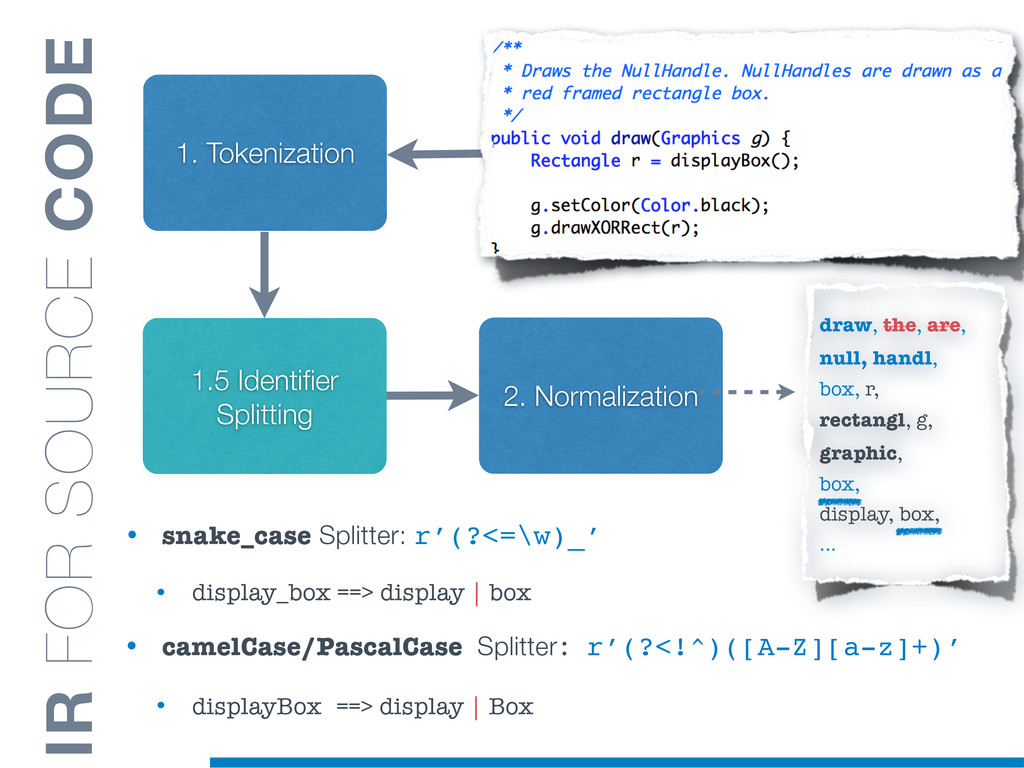
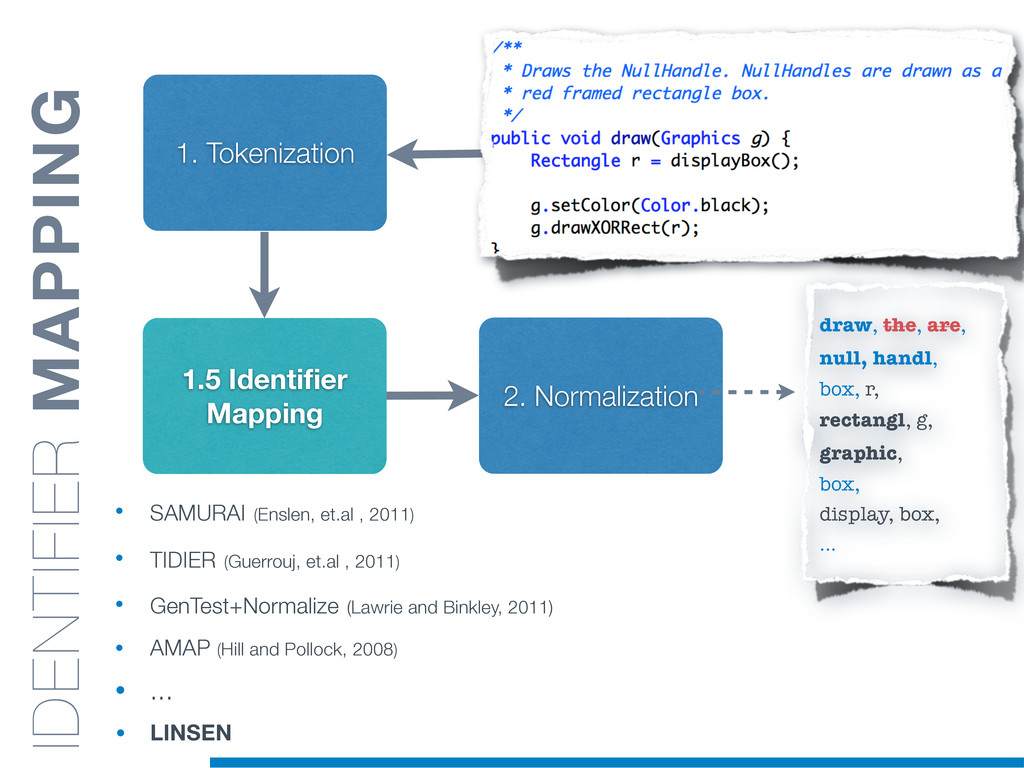
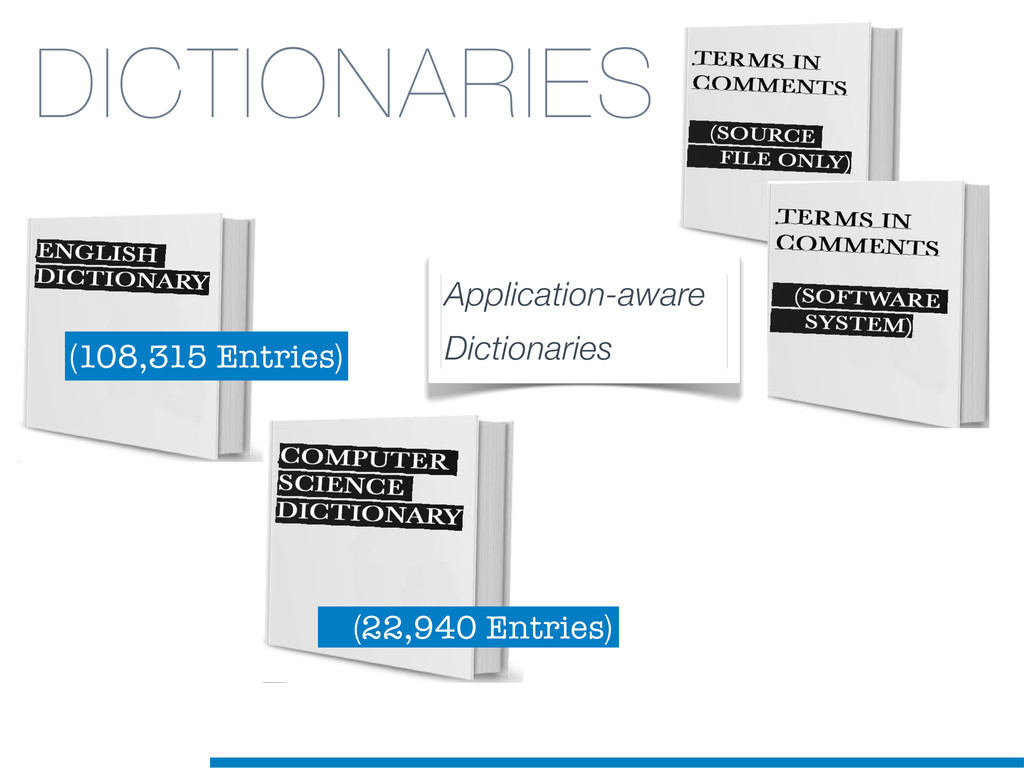
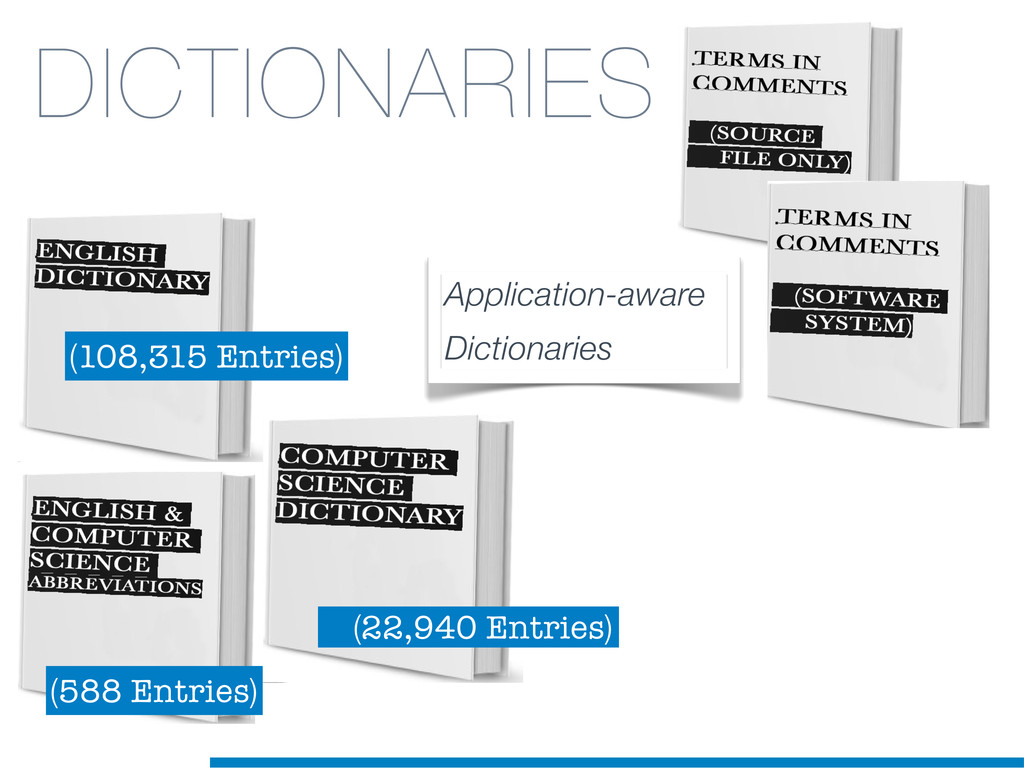
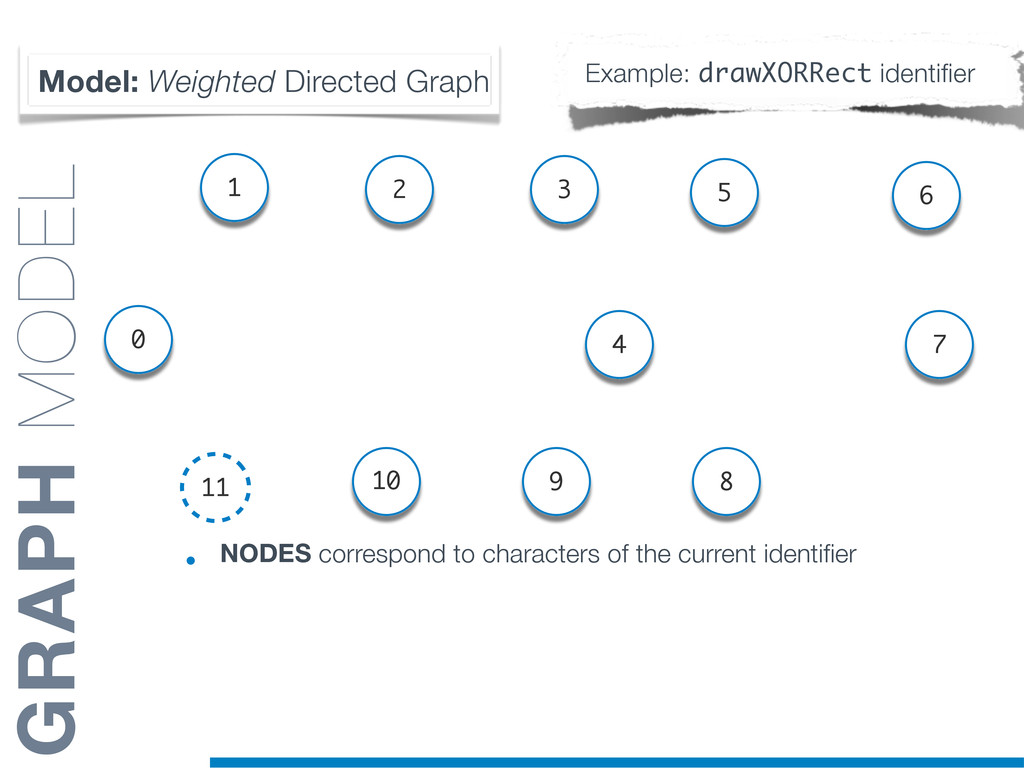
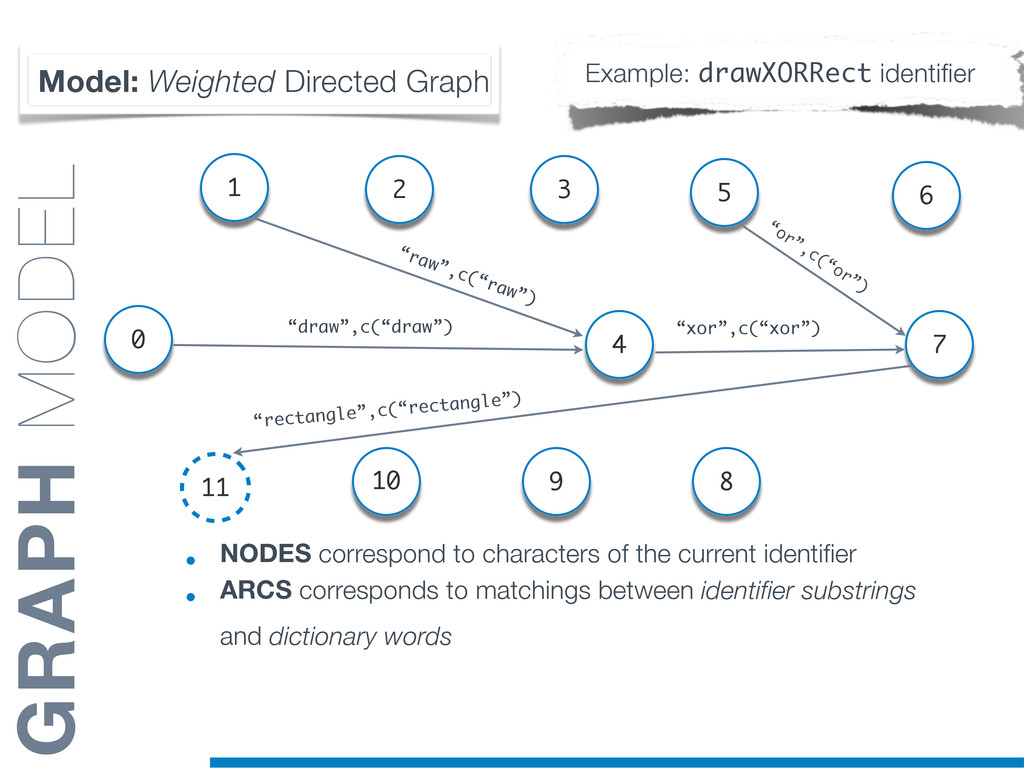
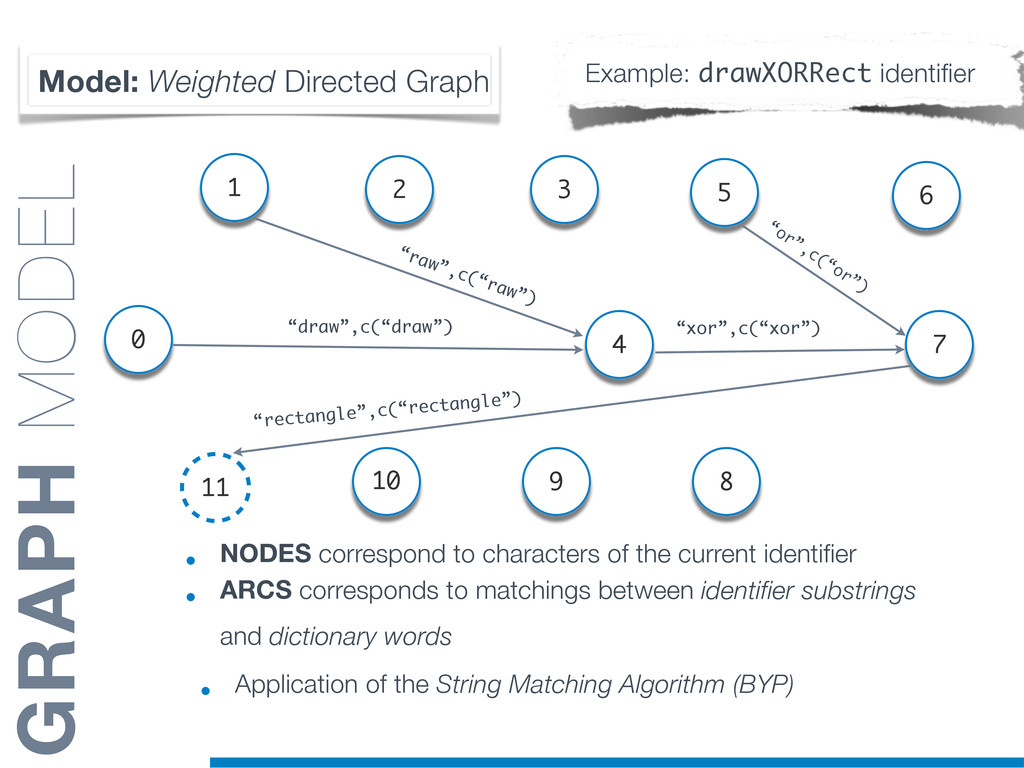
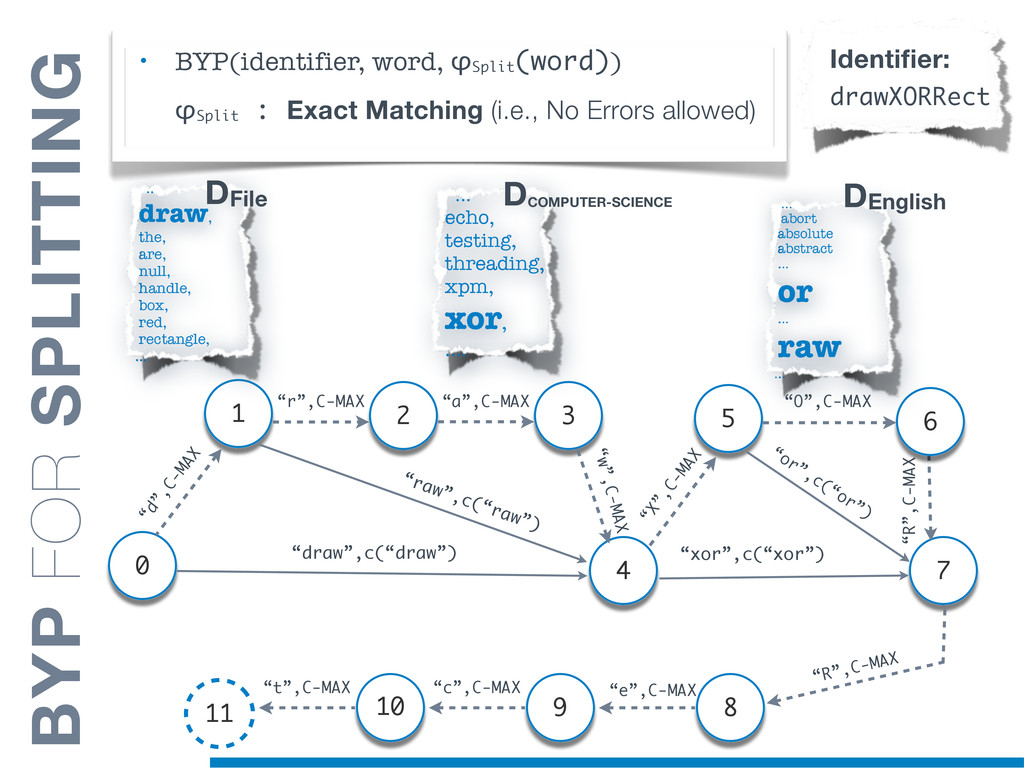
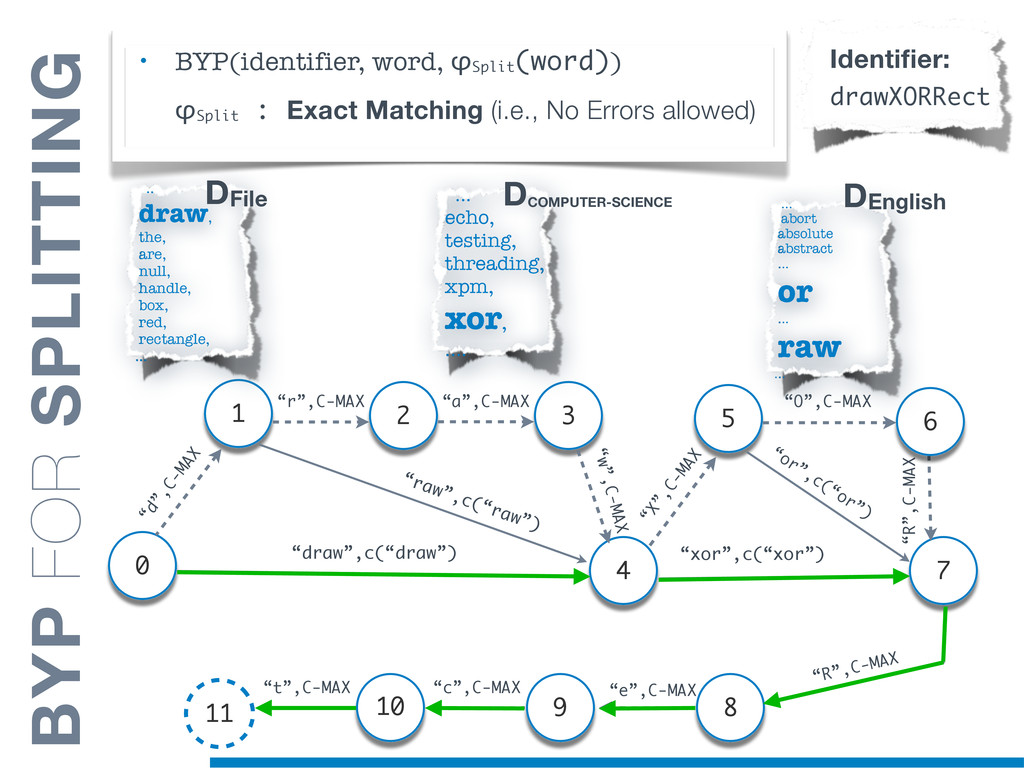
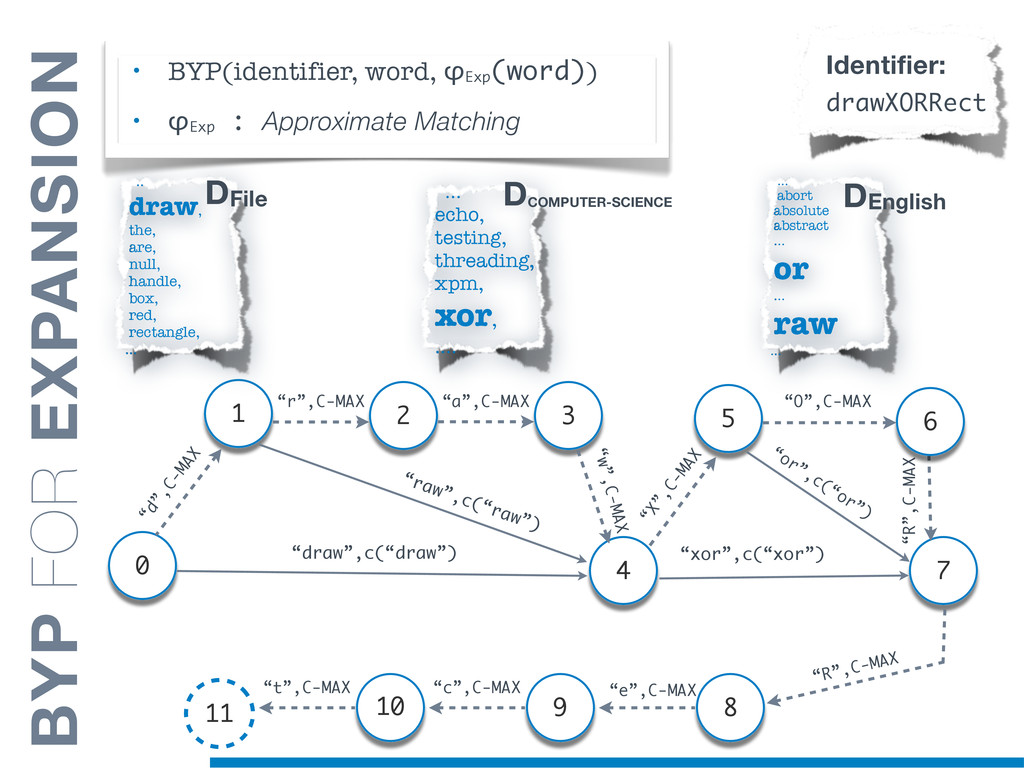
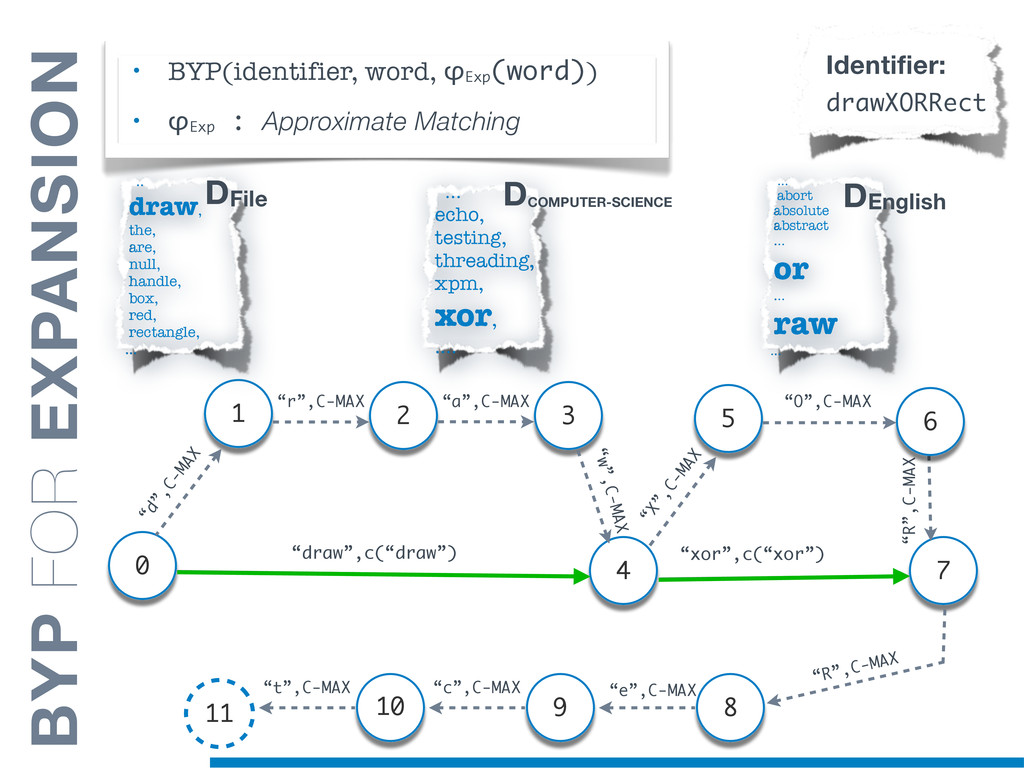
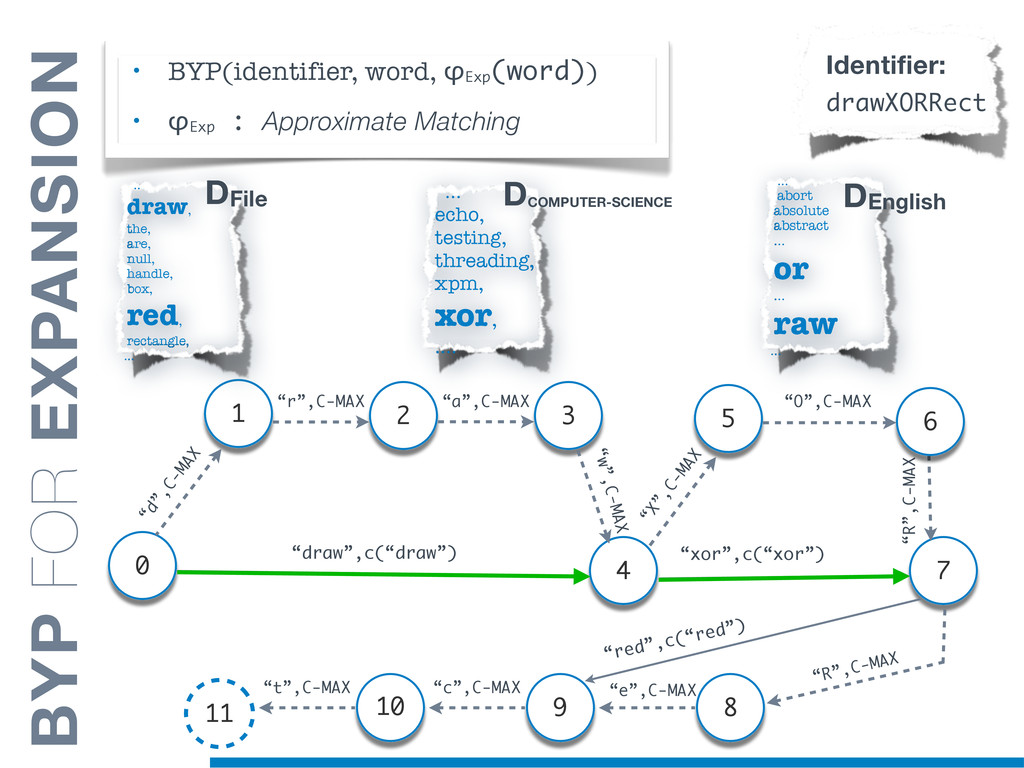
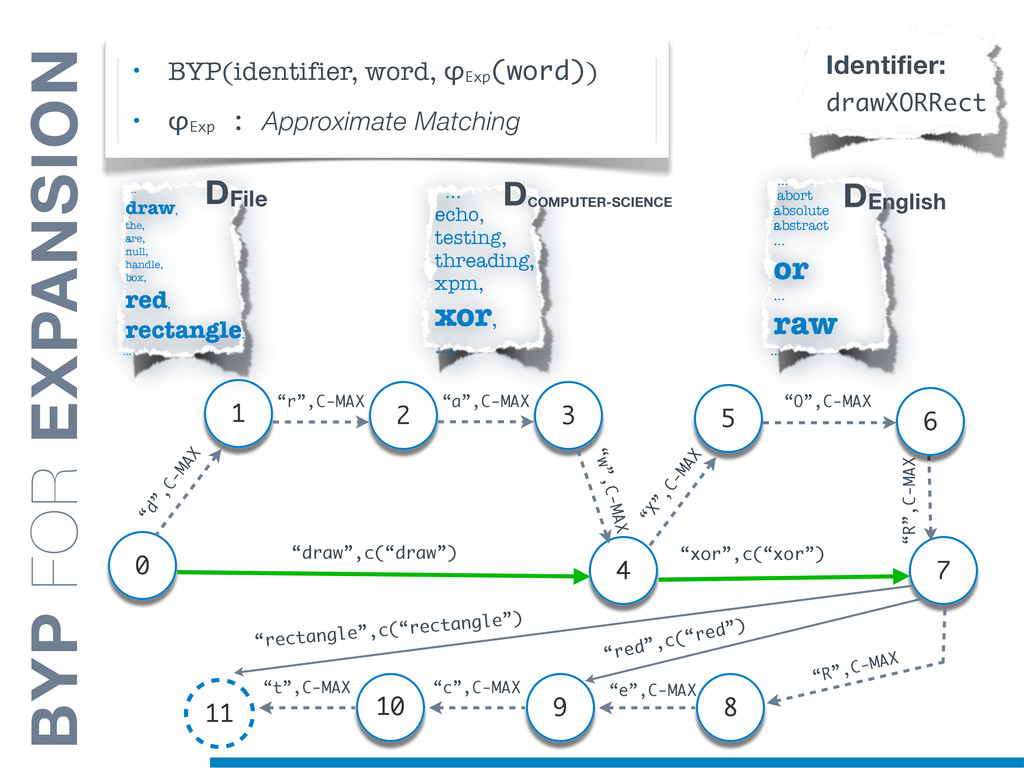
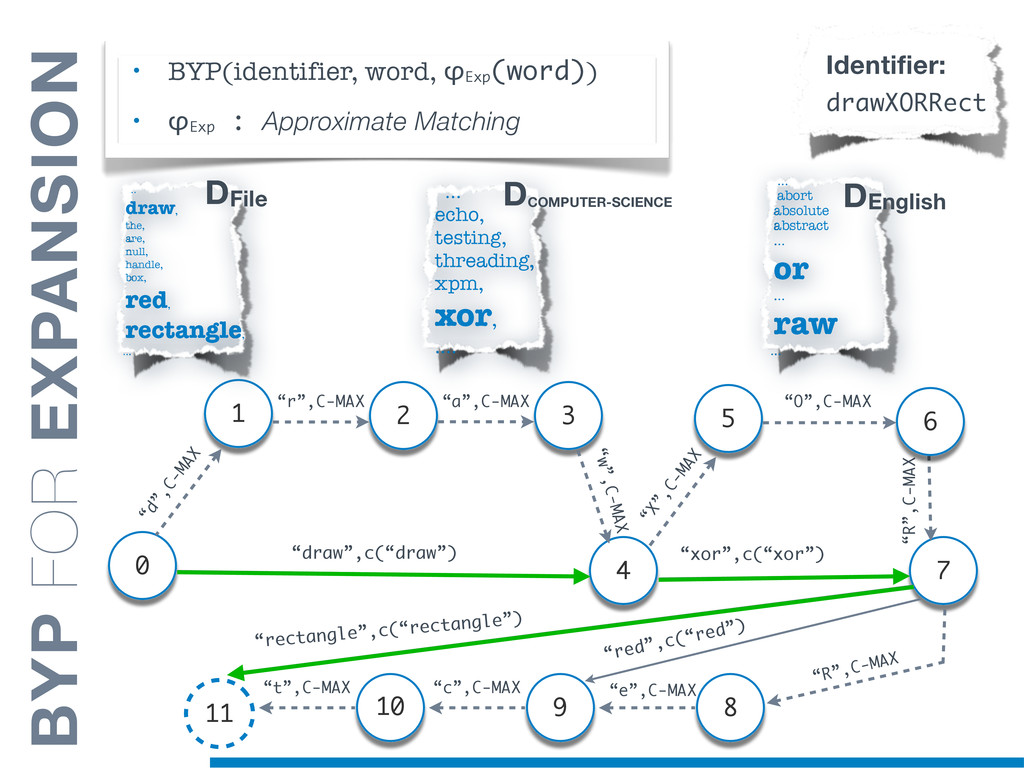
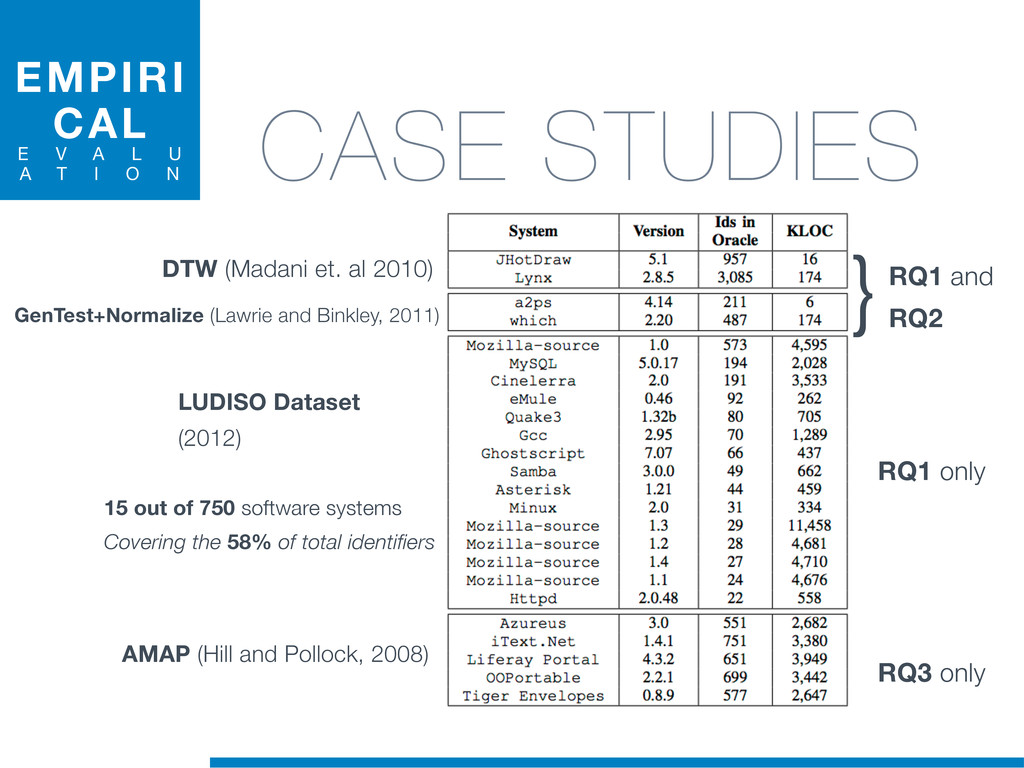
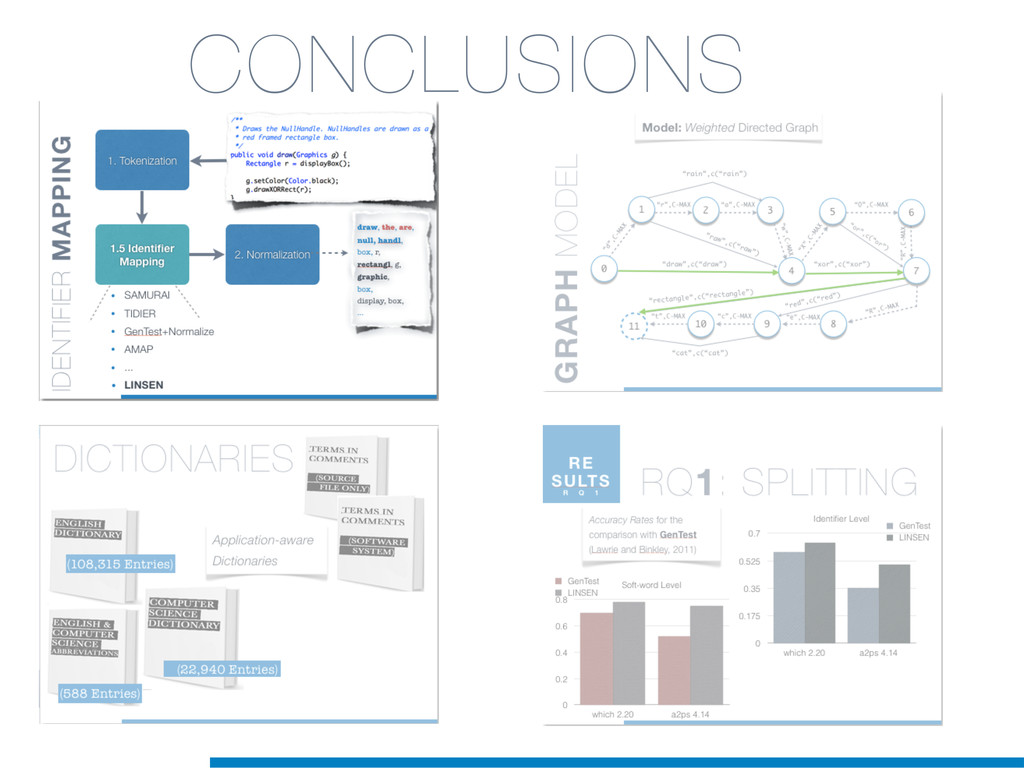
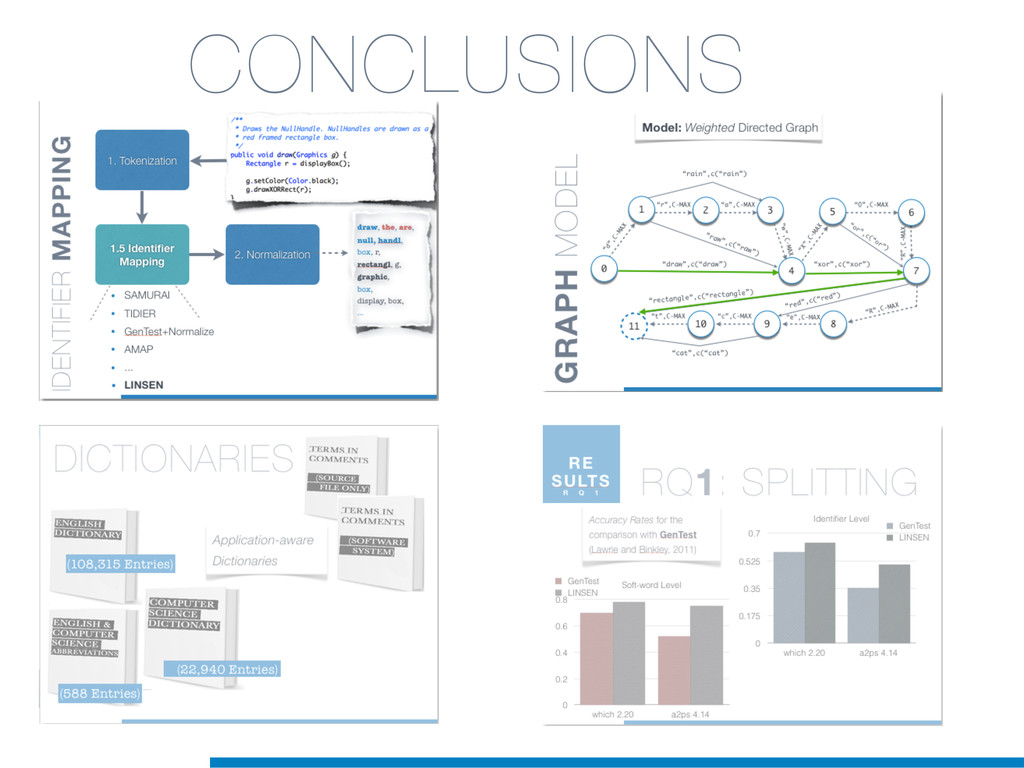
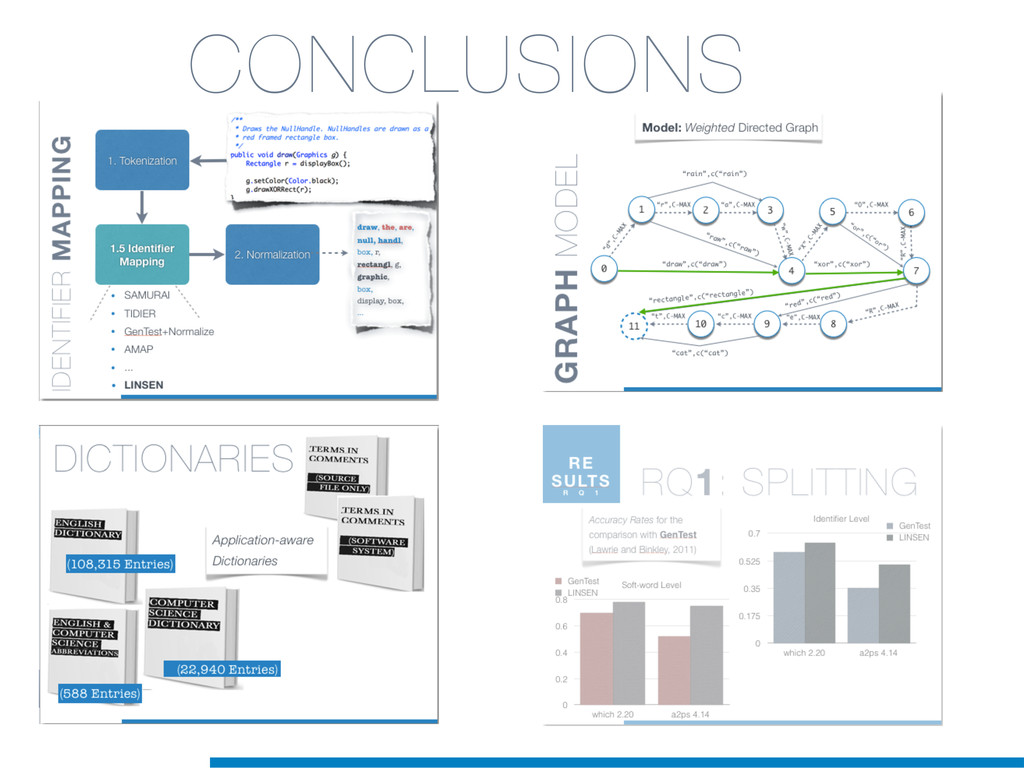
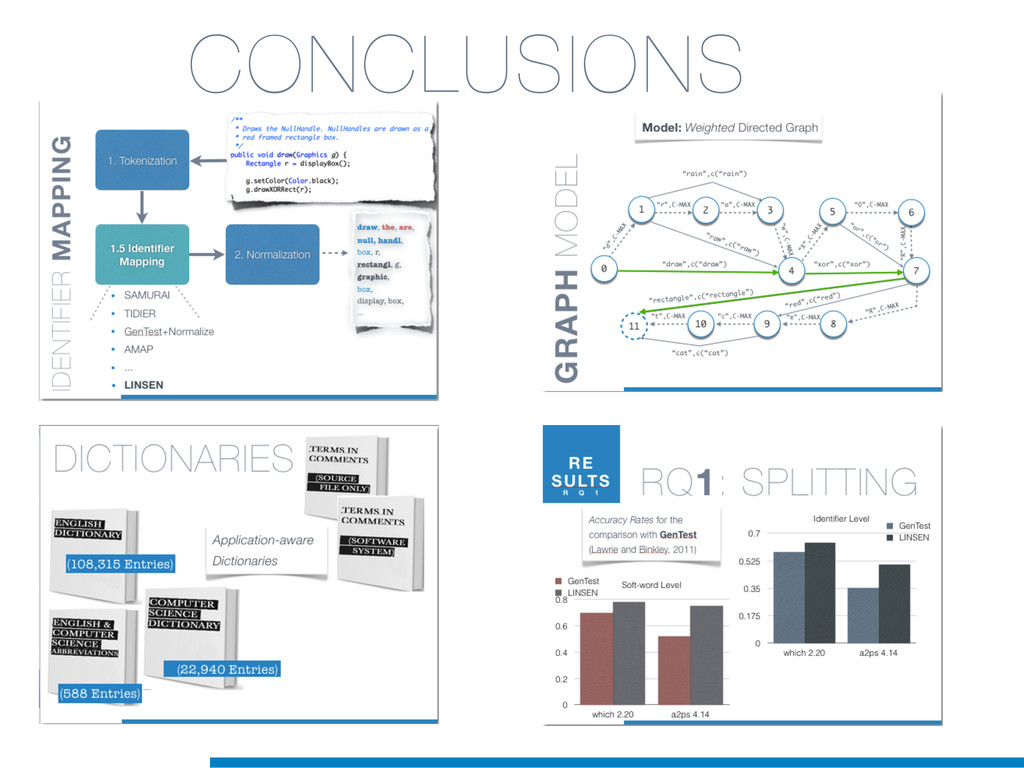
Information Retrieval (IR) techniques are being exploited by an increasing number of tools supporting Software Maintenance activities. Indeed the lexical information embedded in the source code can be valuable for tasks such as concept location, clustering or recovery of traceability links. The application of such IR-based techniques relies on the consistency of the lexicon available in the different artifacts, and their effectiveness can worsen if programmers introduce abbreviations (e.g: rect) and/or do not strictly follow naming conventions such as Camel Case (e.g: UTFtoASCII). In this paper we propose an approach to automatically split identifiers in their composing words, and expand abbreviations. The solution is based on a graph model and performs in linear time with respect to the size of the dictionary, taking advantage of an approximate string matching technique. The proposed technique exploits a number of different dictionaries, referring to increasingly broader contexts, in order to achieve a disam- biguation strategy based on the knowledge gathered from the most appropriate domain. The approach has been compared to other splitting and expansion techniques, using freely available oracles for the identifiers extracted from 24 C/C++ and Java open source systems. Results show an improvement in both splitting and expanding performance, in addition to a strong enhancement in the computational efficiency.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’ • drawXORRect ==> drawXOR | Rect](https://files.speakerdeck.com/presentations/1feec81052d401313e9c266f7d371ab3/slide_16.jpg){kind=link}
![• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’ • drawXORRect ==> drawXOR | Rect](https://files.speakerdeck.com/presentations/1feec81052d401313e9c266f7d371ab3/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
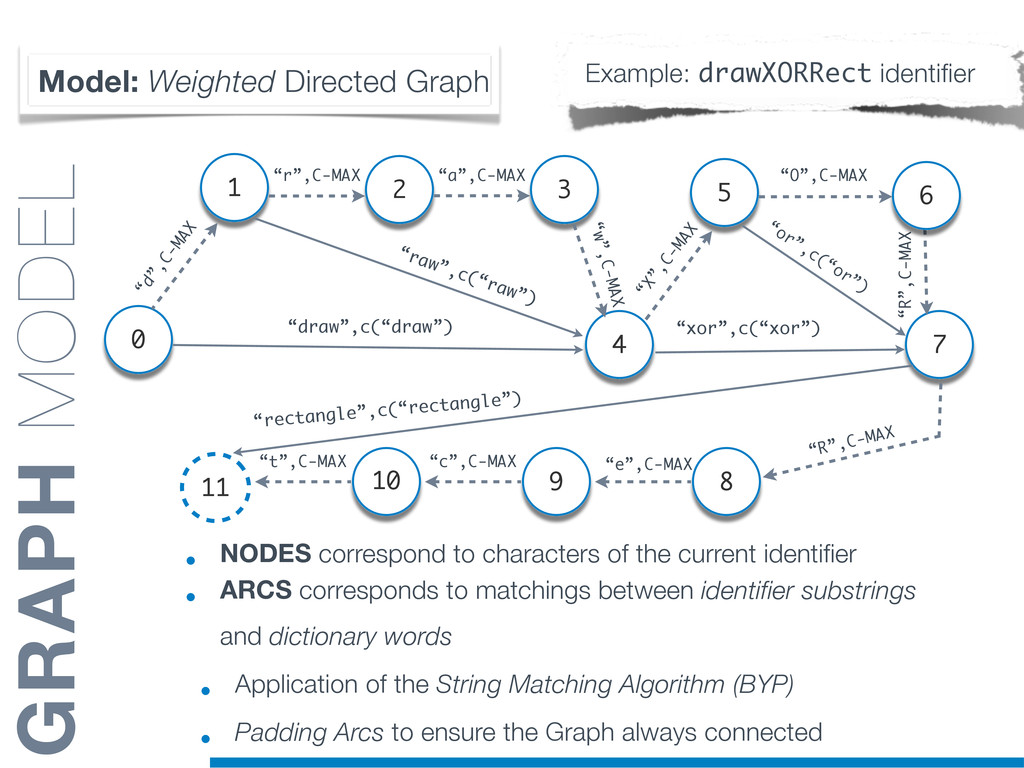{kind=link}
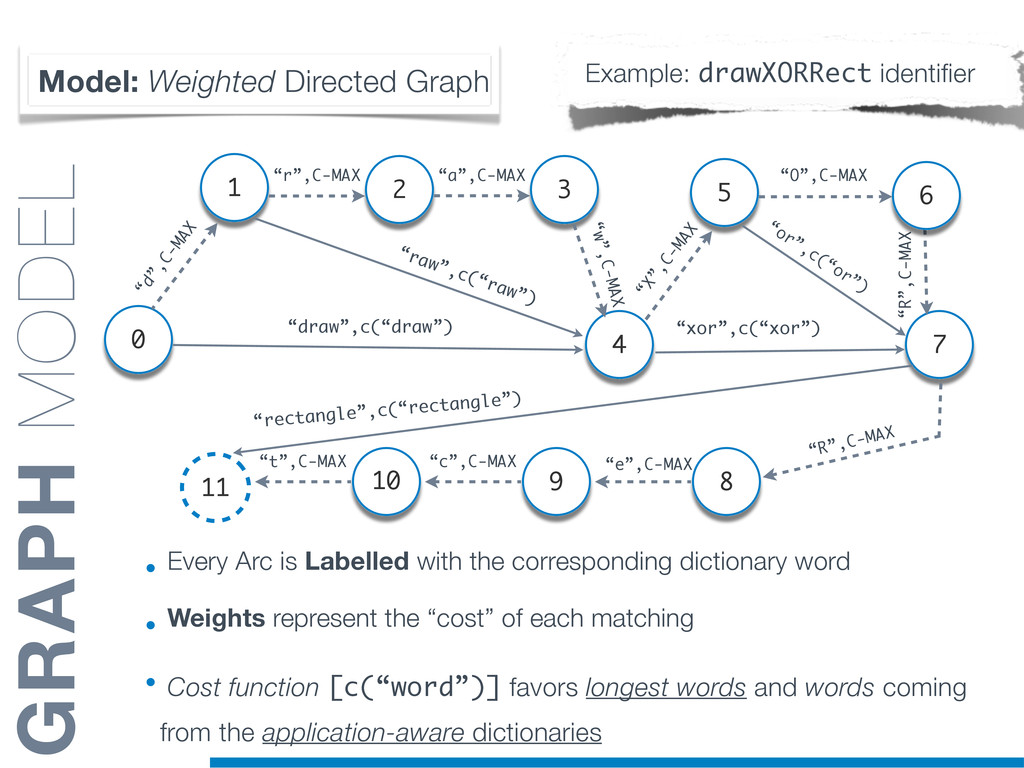{kind=link}
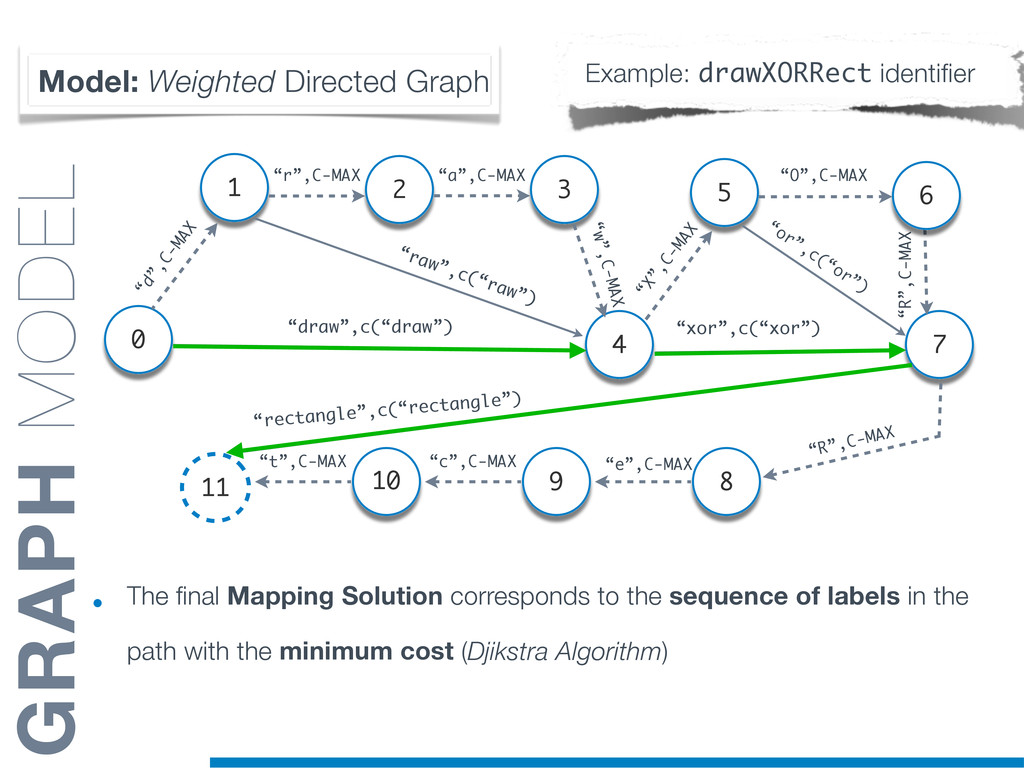{kind=link}
{kind=link}
{kind=link}
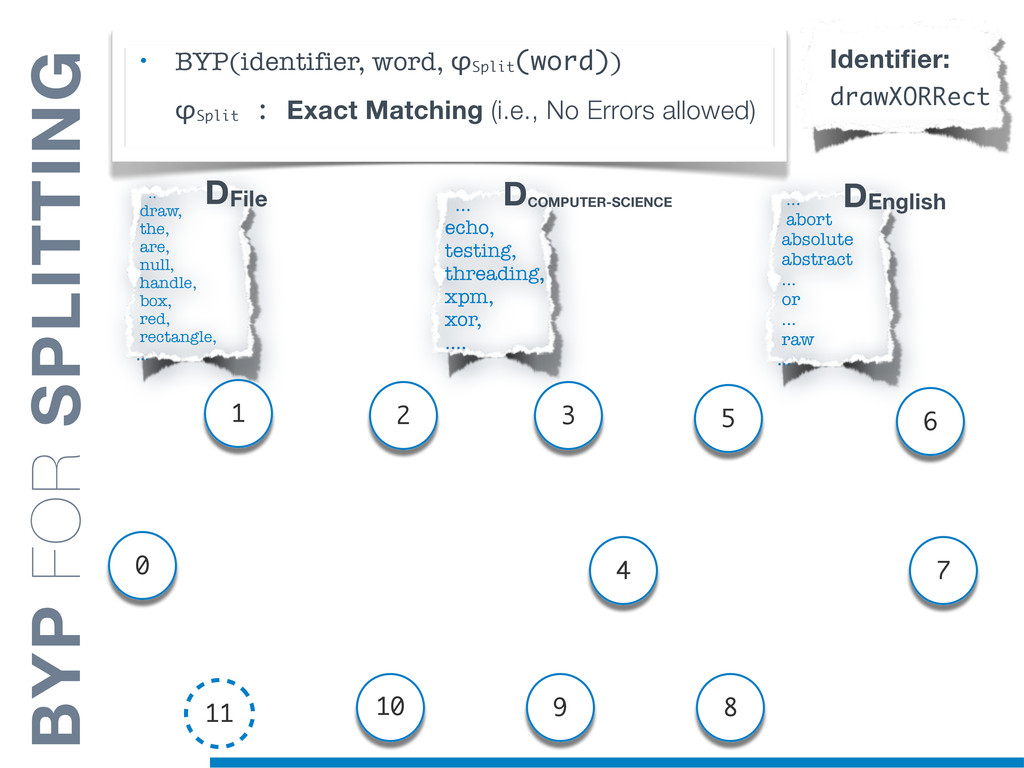{kind=link}
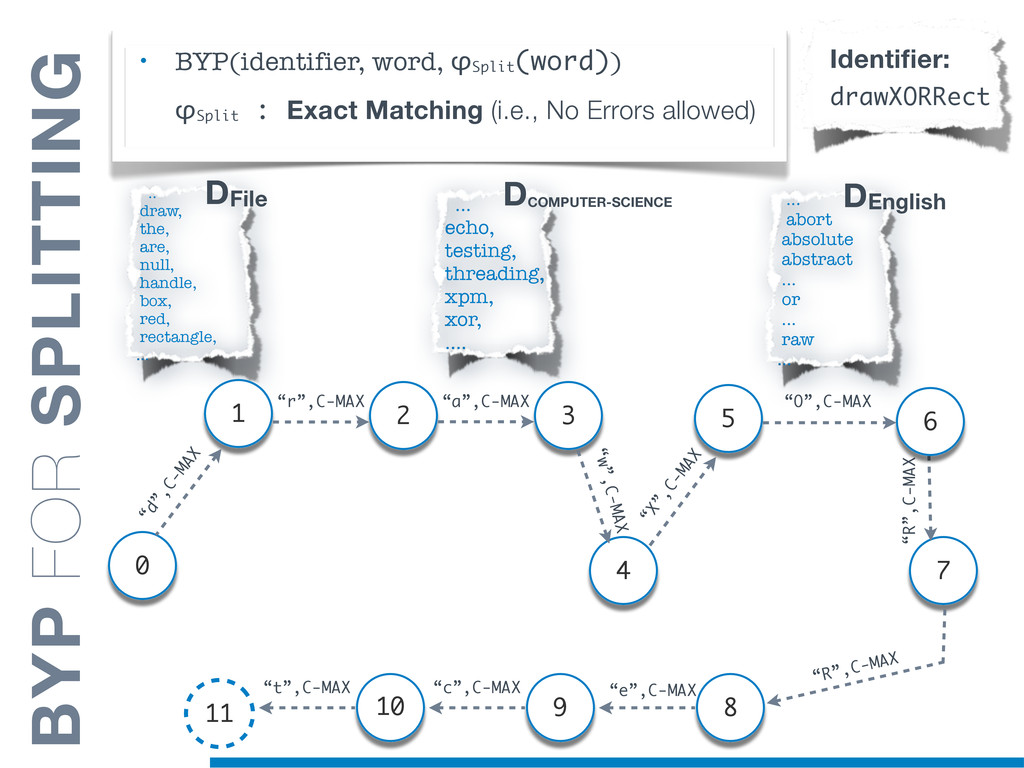{kind=link}
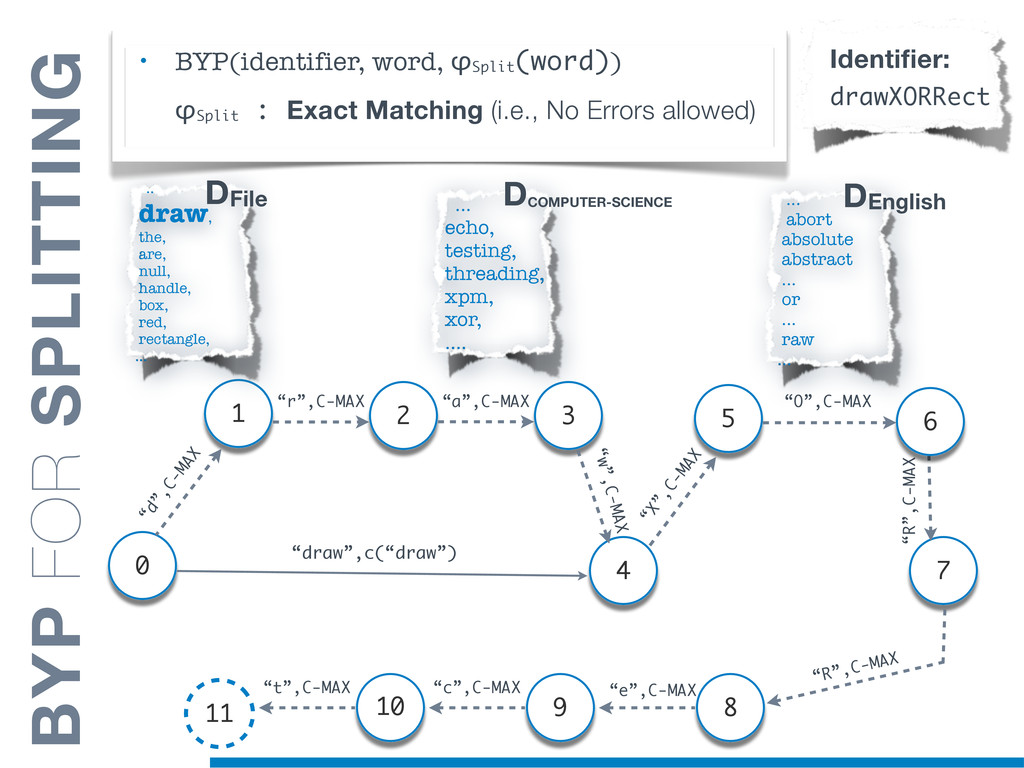{kind=link}
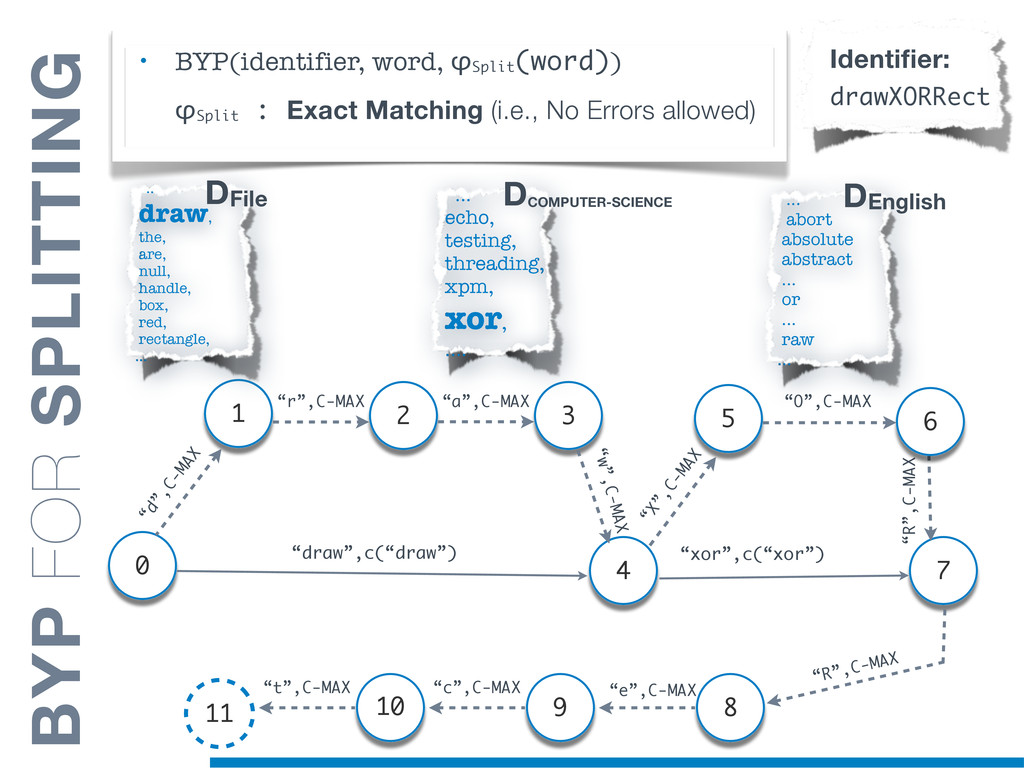{kind=link}
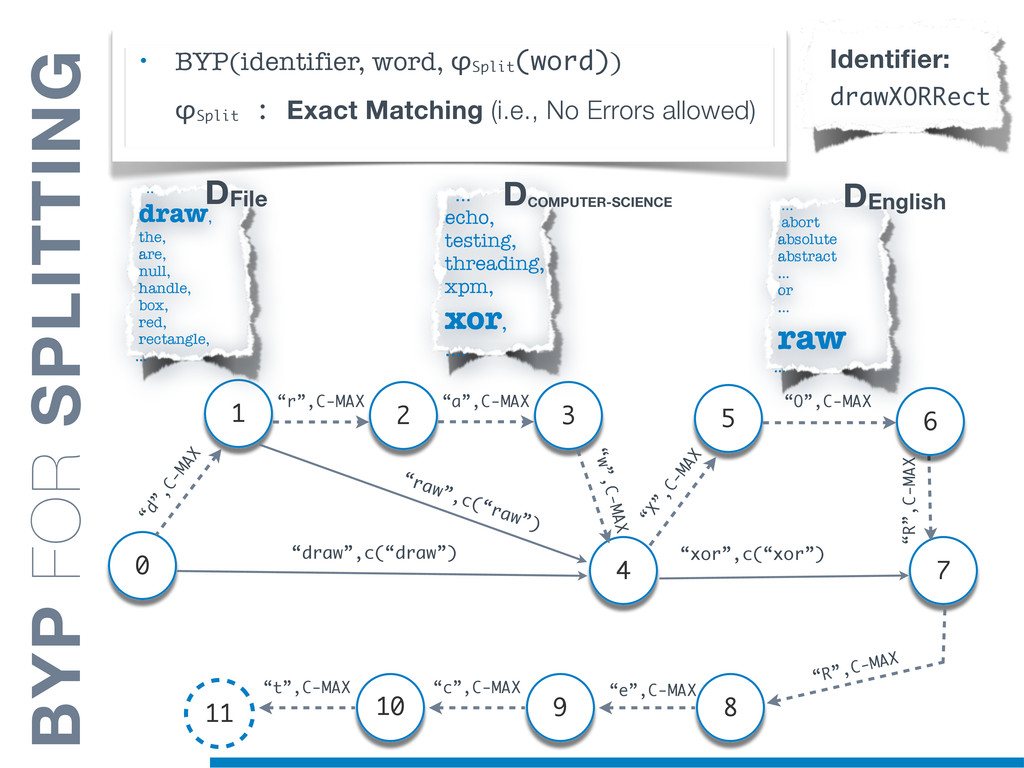{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
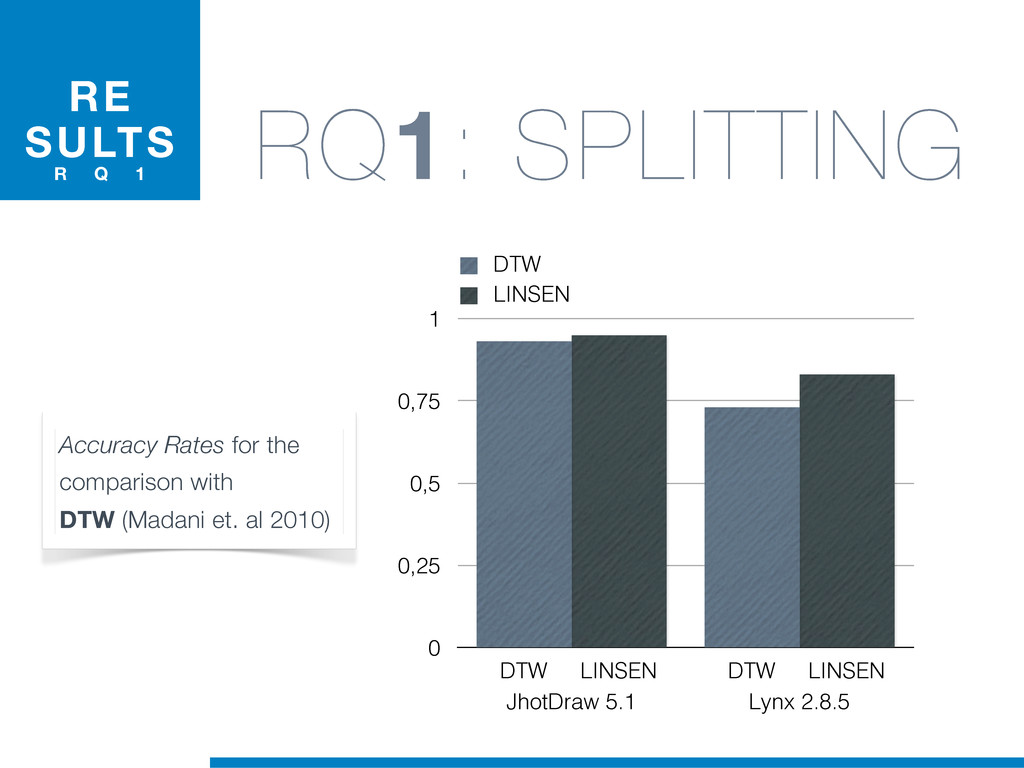{kind=link}
{kind=link}
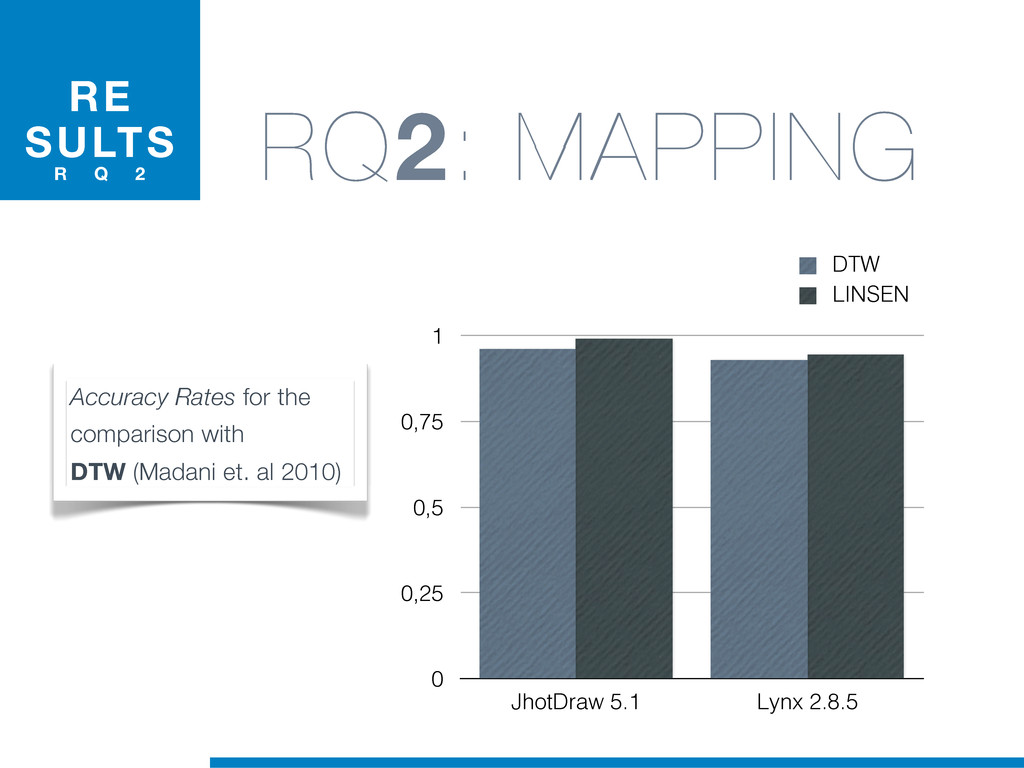{kind=link}
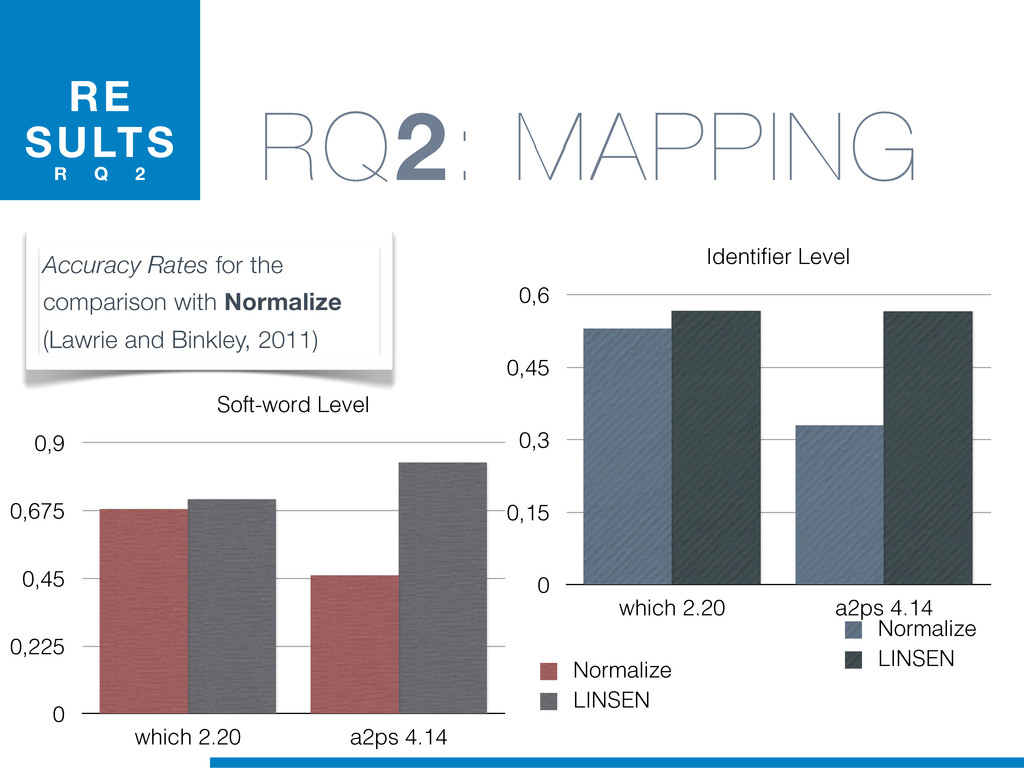{kind=link}
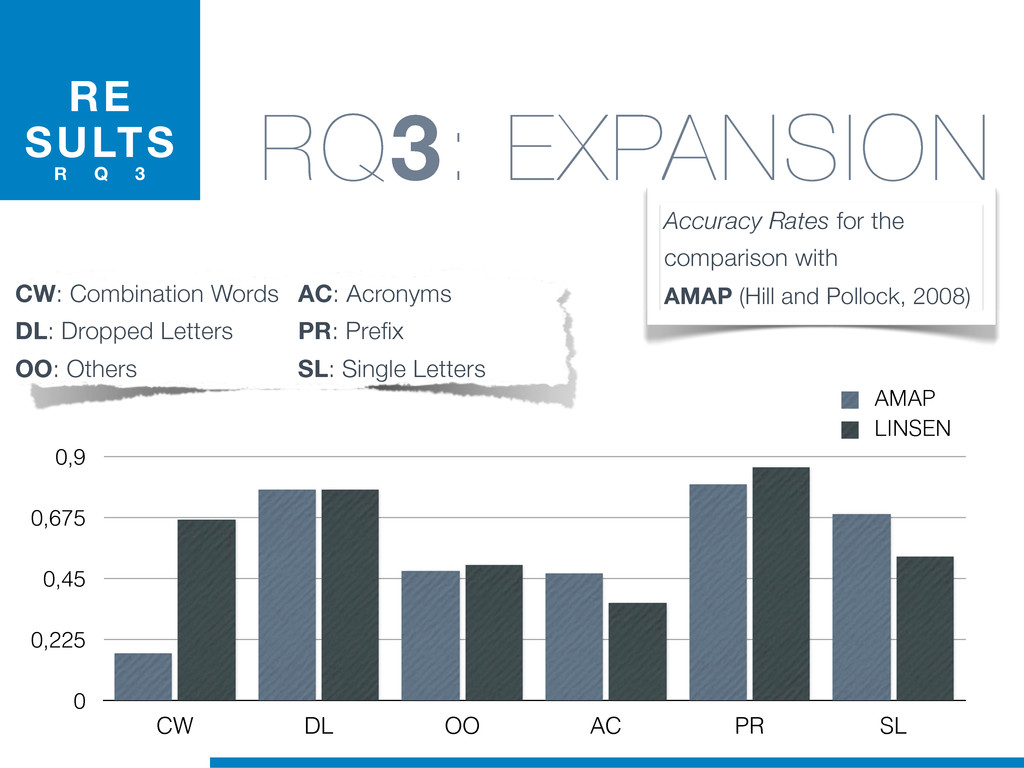{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}