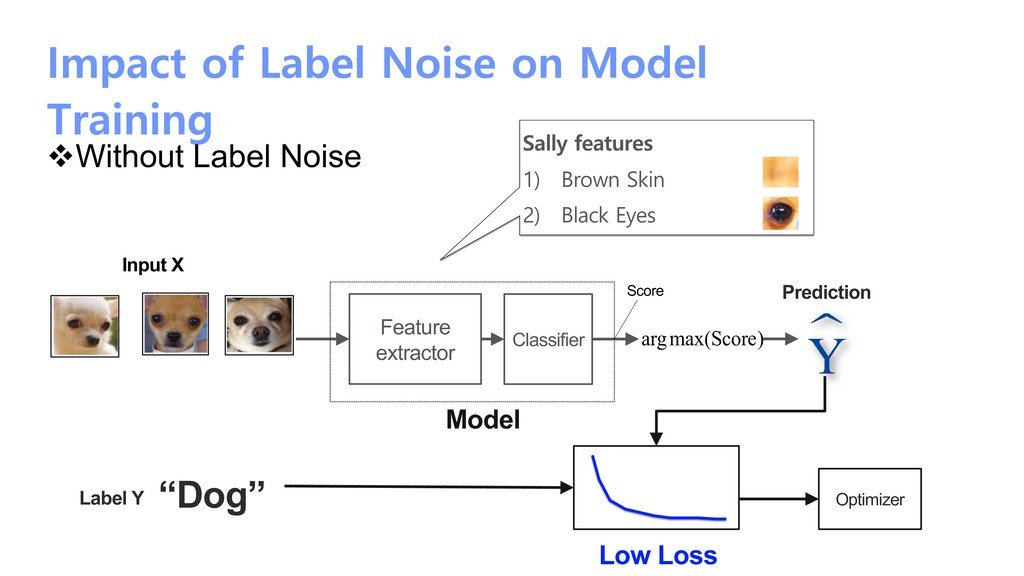
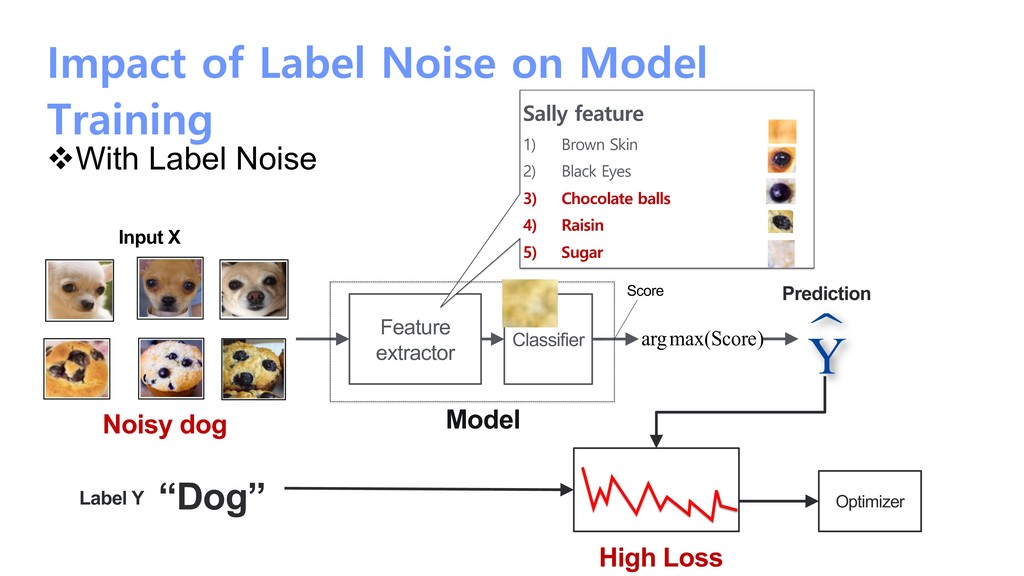
Feature extractor Classifier Prediction Score Label Y Optimizer “Dog” Sally feature 1) Brown Skin 2) Black Eyes 3) Chocolate balls 4) Raisin 5) Sugar Input X High Loss Noisy dog Model
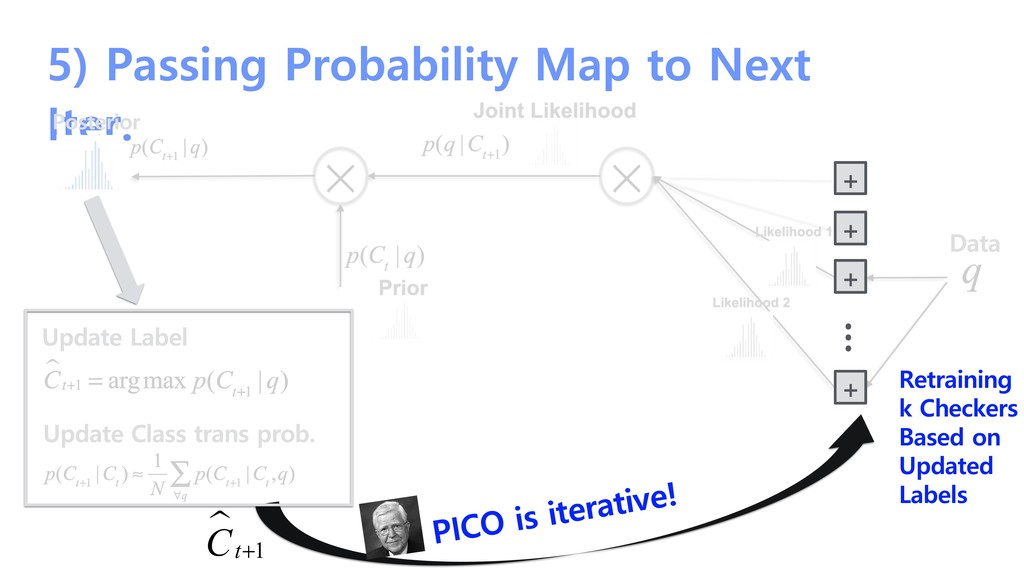
Bayes 1701-1761 Hidden Markov Modeling of labeling history over iterations Andrey A. Markov 1856–1922 Iterative Probabilistic correction for labeling update Robert G. Gallager 1931-present
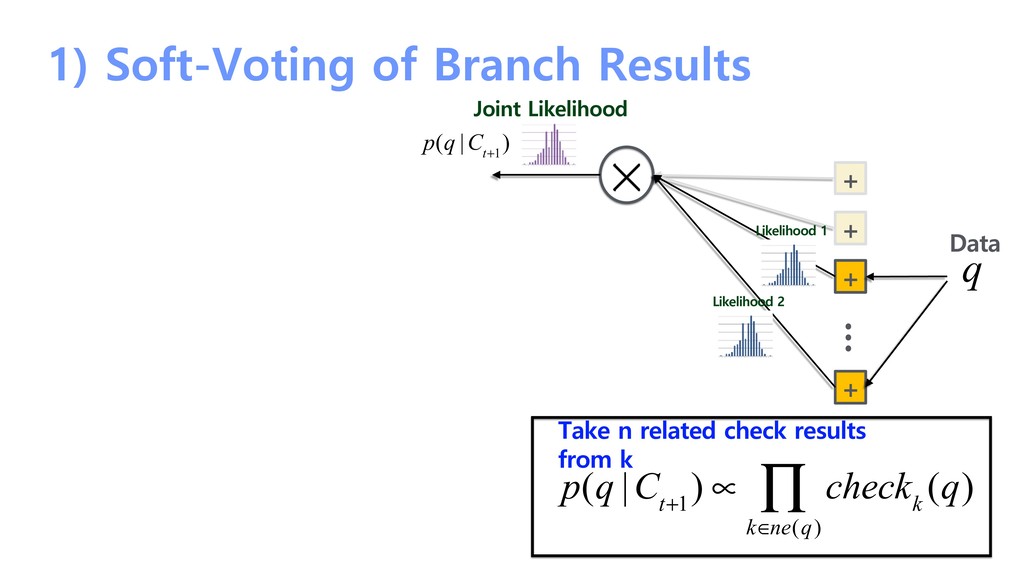
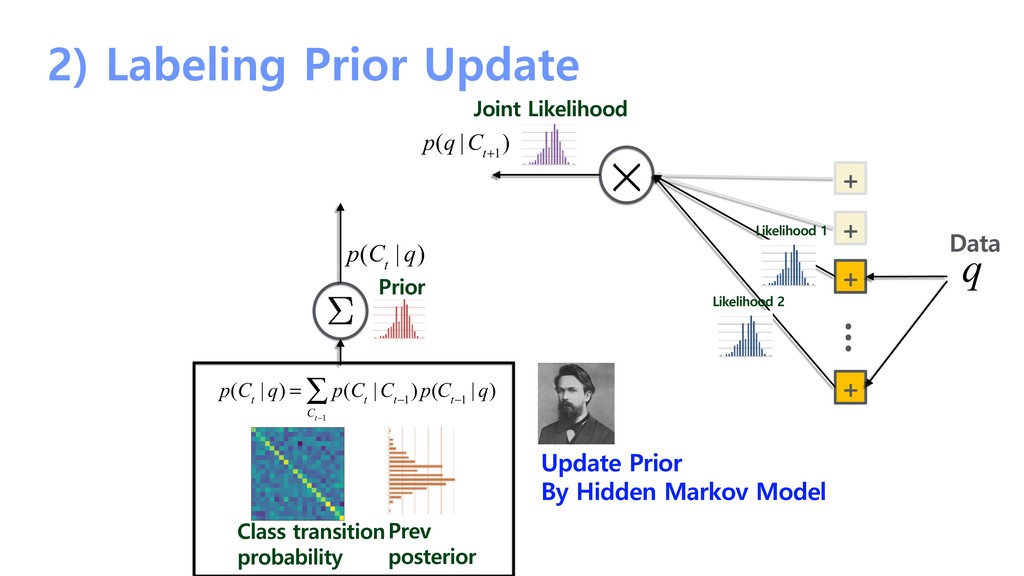
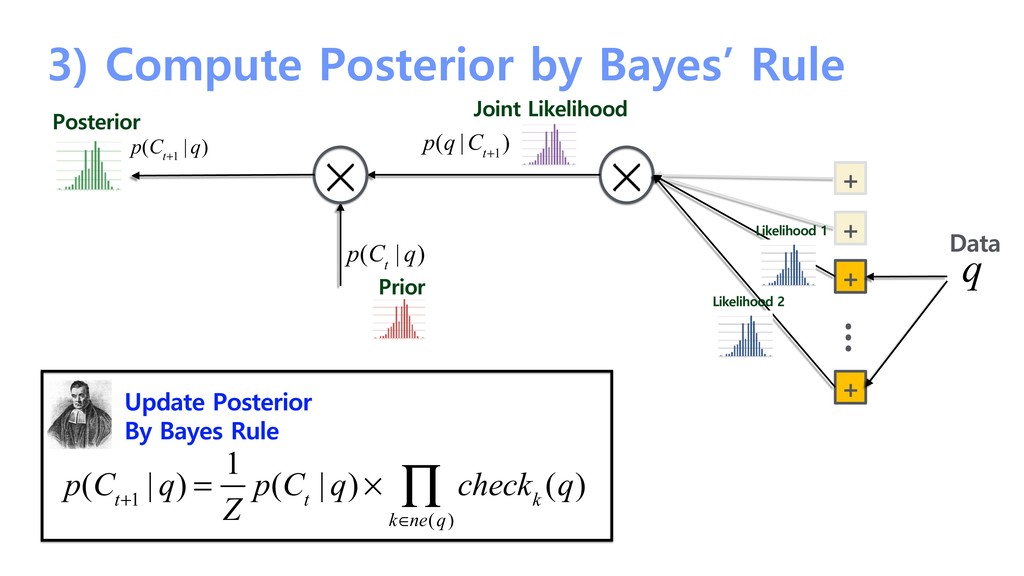
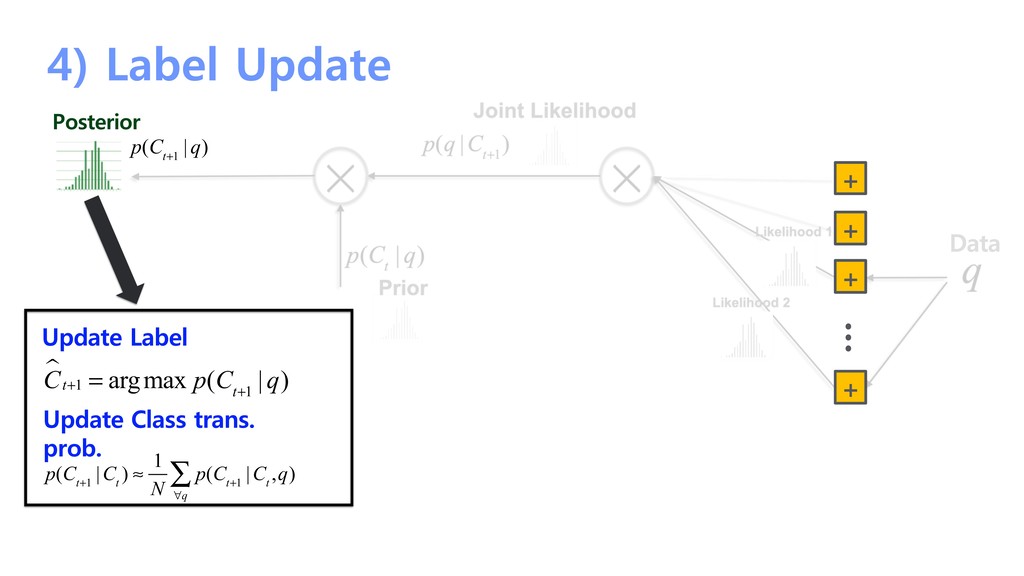
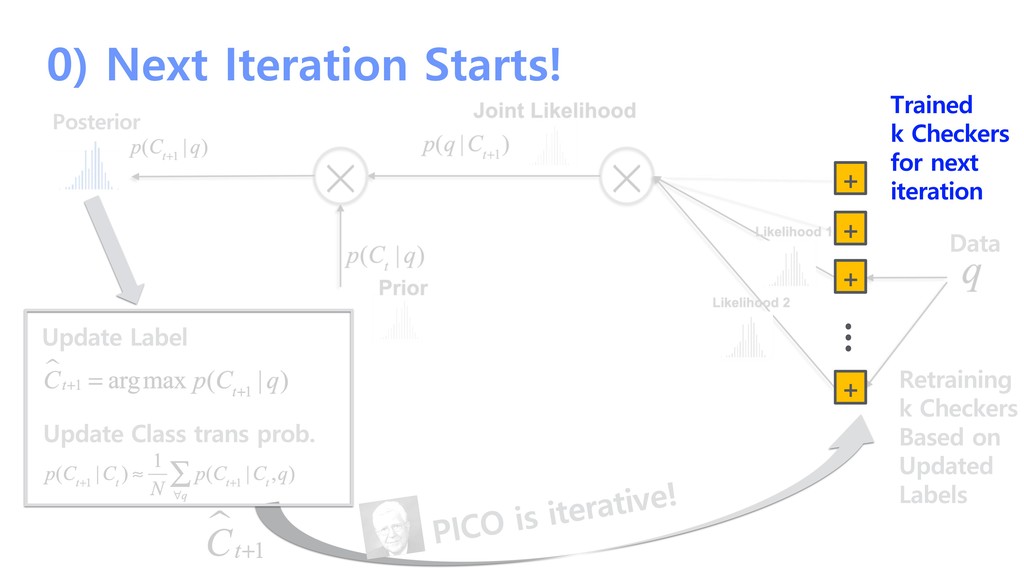
probability + + + + … Likelihood 1 Likelihood 2 Update Prior By Hidden Markov Model p(C t | q) = p(C t |C t−1 )p( C t−1 ∑ C t−1 | q) p(q |C t+1 ) Prior p(C t | q) q Data
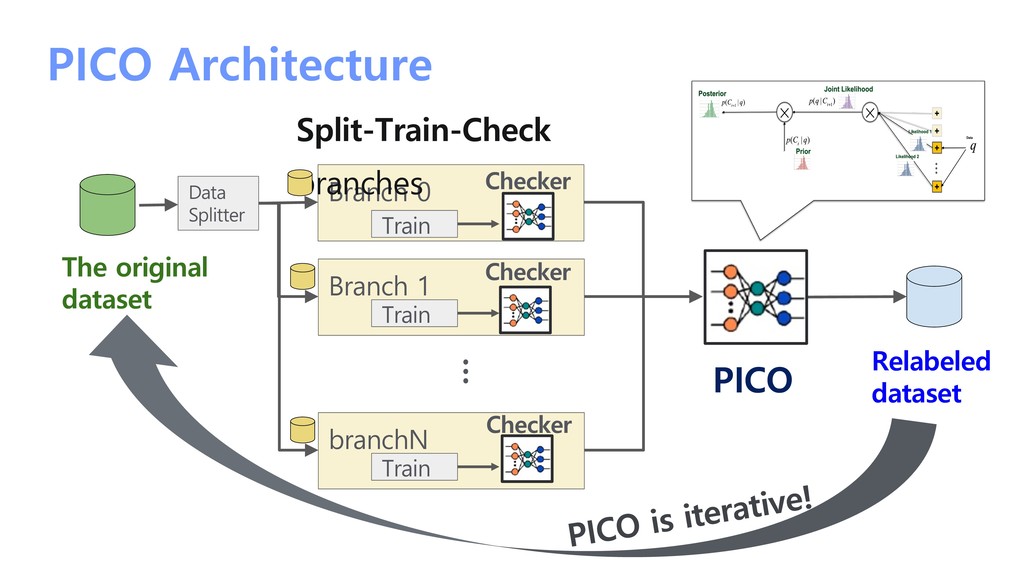
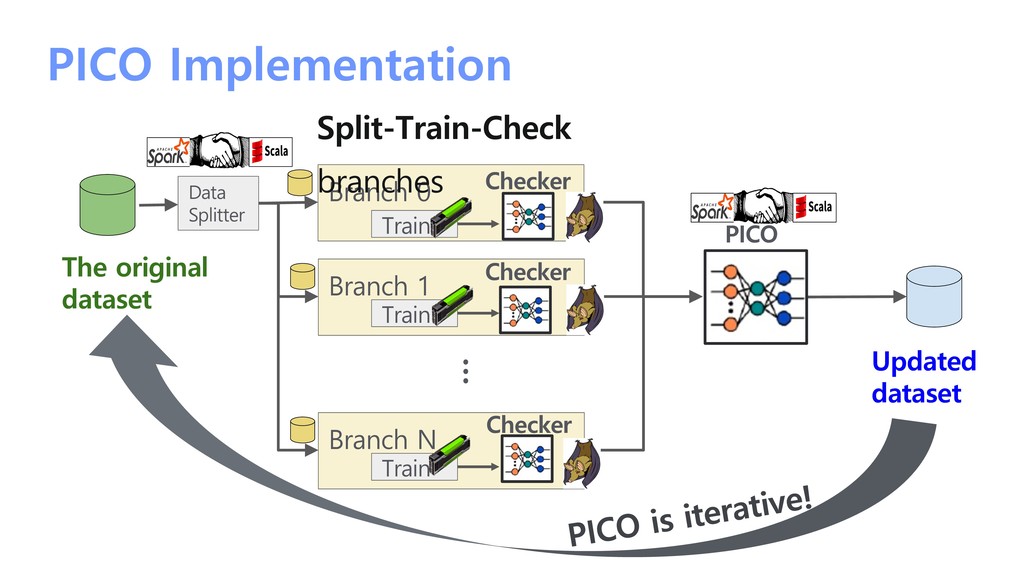
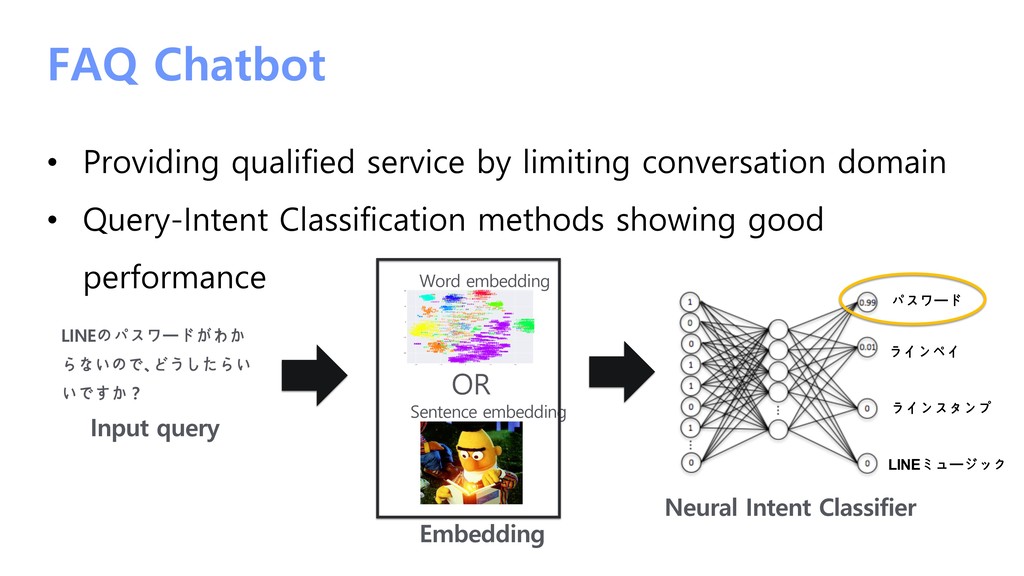
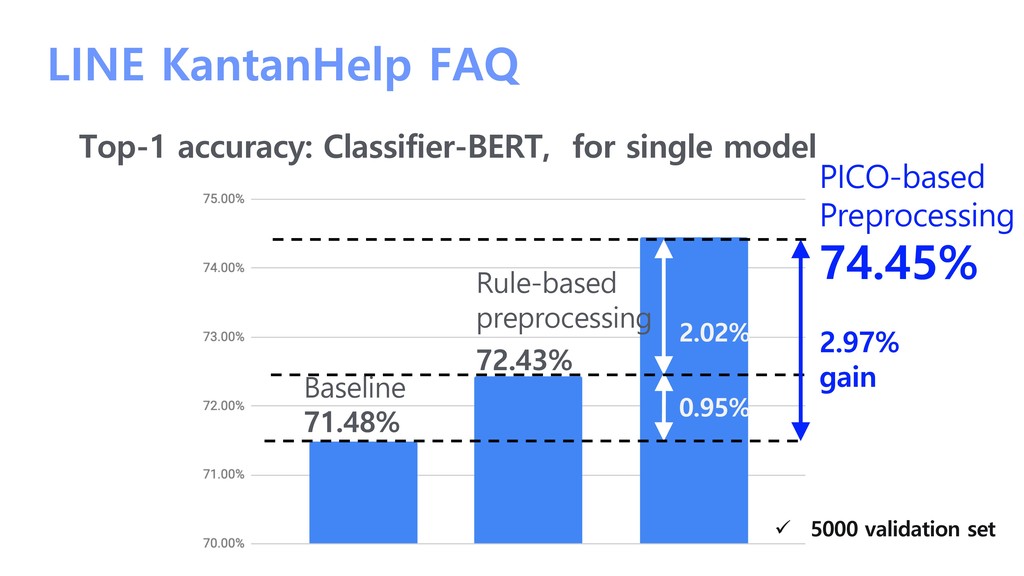
/ 1000 intent classes • Checker model: classifier-BERT • Characteristic LINE KantanHelp FAQ ü Train “classifier” only for the checkers in PICO ü Imbalance class problem ü Query-intent mapping ambiguity problem ü Some noisy queries
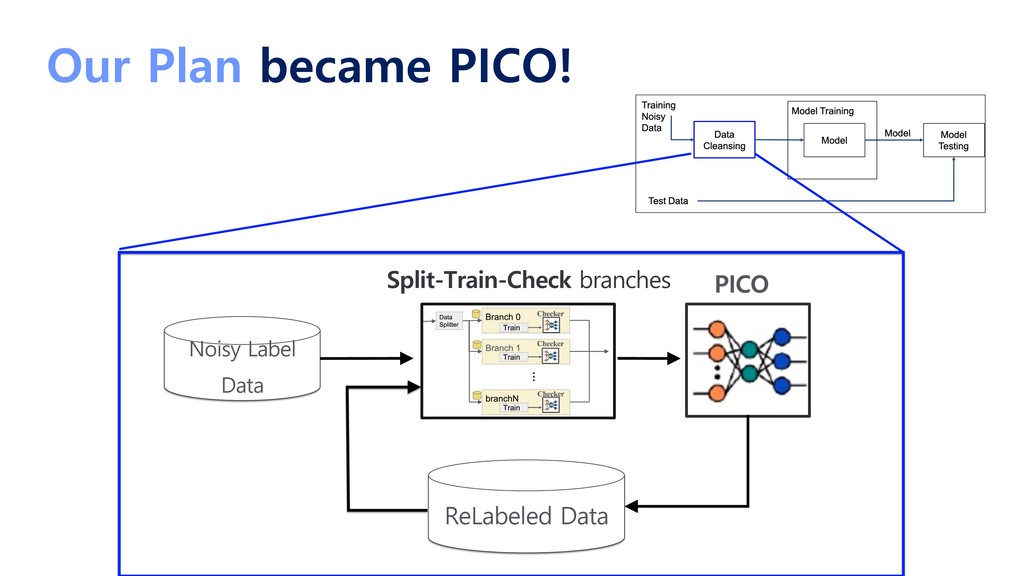
are difficult to succeed. • AI data automatic cleaning pipeline is very competitive • CLOVA/LINE Chatbot Builder improves service quality by automatically purifying data through PICO • PICO architecture can be applied to other data sets
al.,“Co-teaching: Robust training of deep neural networks with extremely noisy labels,” in NIPS, pp. 8536-8546, 2018. • [Konyushkova’2017] K. Konyushkova, et al., “Learning active learning from real and synthetic data,” in NIPS, 2017. • [Lu Jiang, et al.:2018] Jiang, Lu et al., “Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels.” in ICML, pp. 2309-2318, 2018. • [Y. Bengio: 2009] Bengio, Yoshua et al, “Curriculum learning,” in ICML, pp. 41–48, 2009 • [Yoo’2019] D. Yoo et al., “Learning loss for Active learning,” in CVPR, 2019
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Approach 2-1:Curriculum Learning [Y. Bengio: 2009]](https://files.speakerdeck.com/presentations/bc6d42edaa564a59a0765d5135a59cfe/slide_16.jpg){kind=link}
![Approach 2-2: MentorNet [Lu Jiang, et al.:2018],[Bo Han, et al.:](https://files.speakerdeck.com/presentations/bc6d42edaa564a59a0765d5135a59cfe/slide_17.jpg){kind=link}
{kind=link}
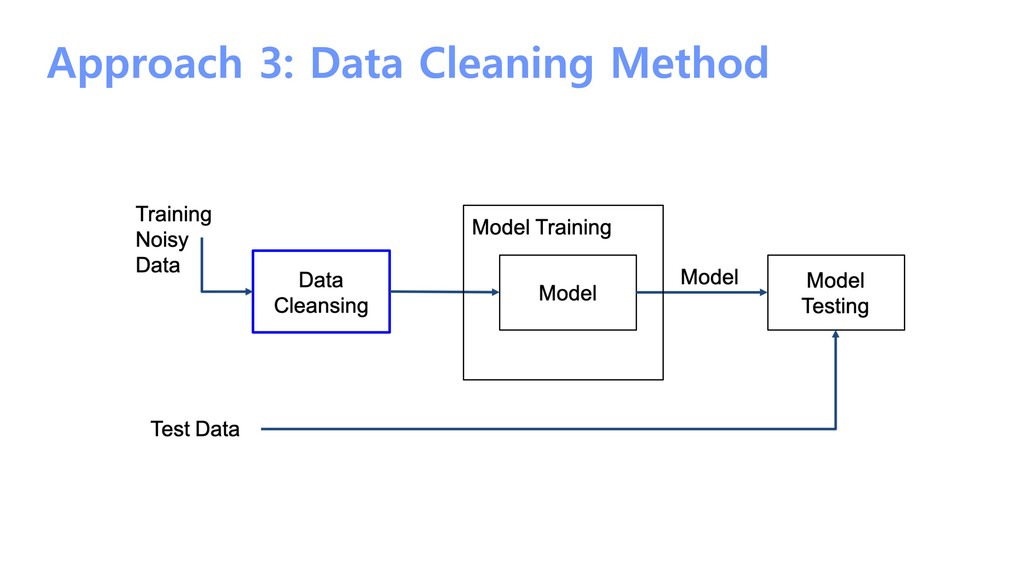{kind=link}
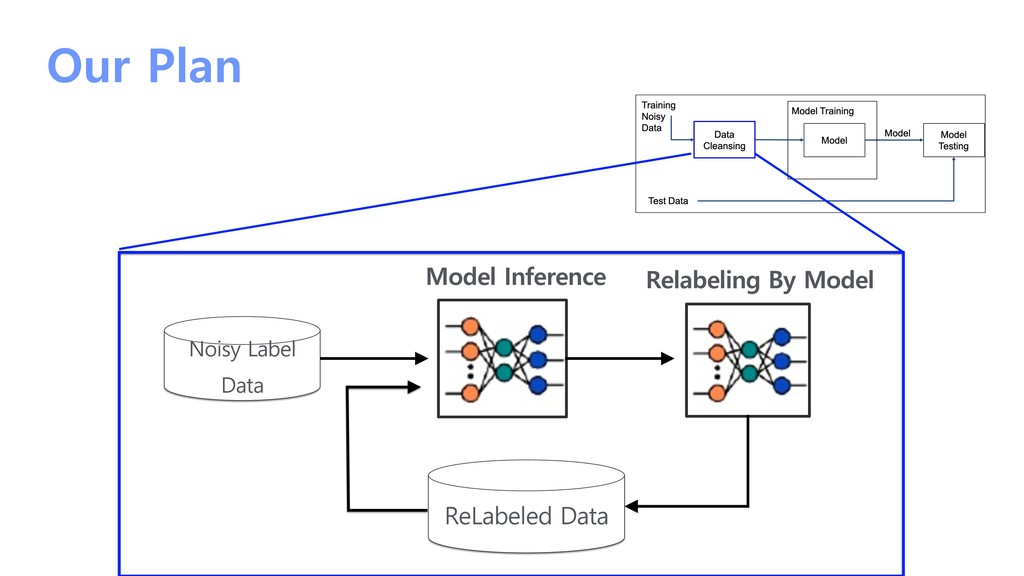
![Active Learning for Label Cleaning [Konyushkova’2017],[Yoo’2019] Noisy Label Data ReLabeled](https://files.speakerdeck.com/presentations/bc6d42edaa564a59a0765d5135a59cfe/slide_20.jpg){kind=link}
{kind=link}
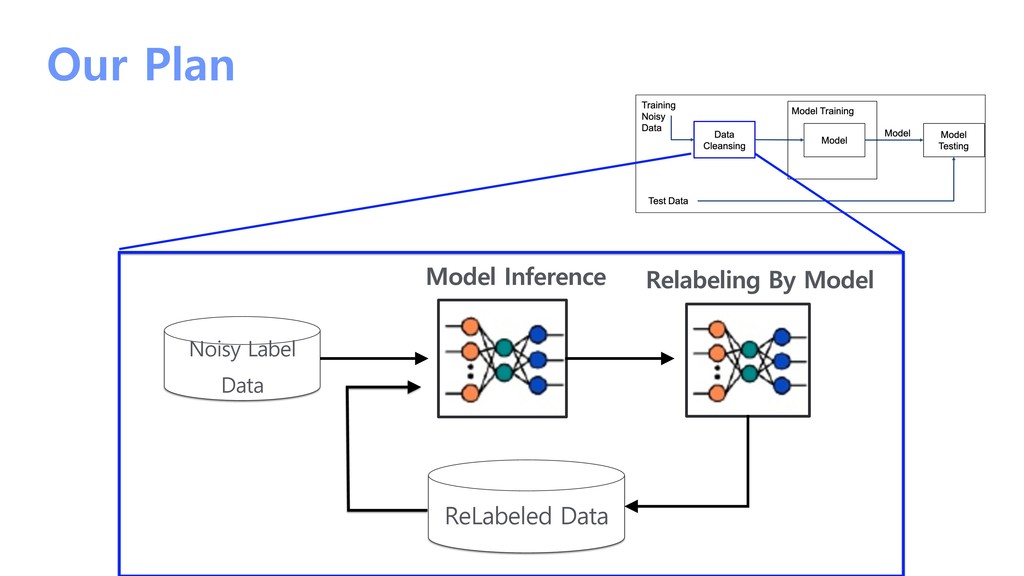{kind=link}
{kind=link}
{kind=link}
{kind=link}
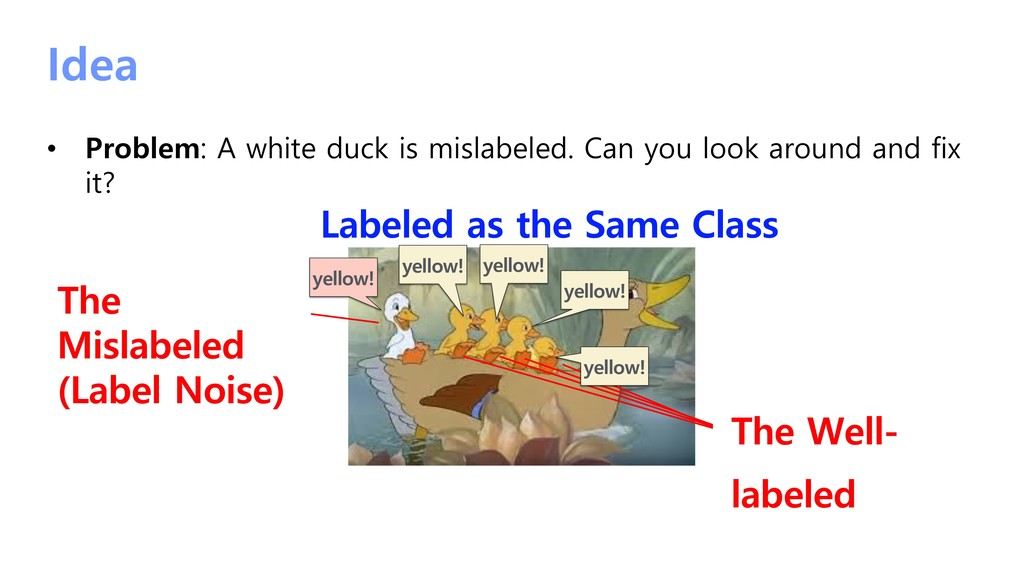{kind=link}
{kind=link}
{kind=link}
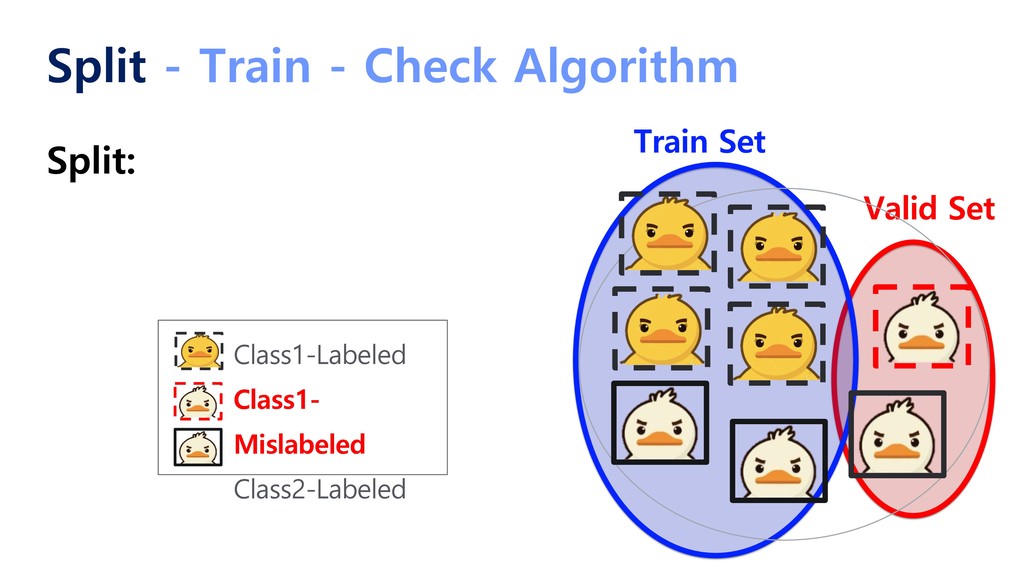{kind=link}
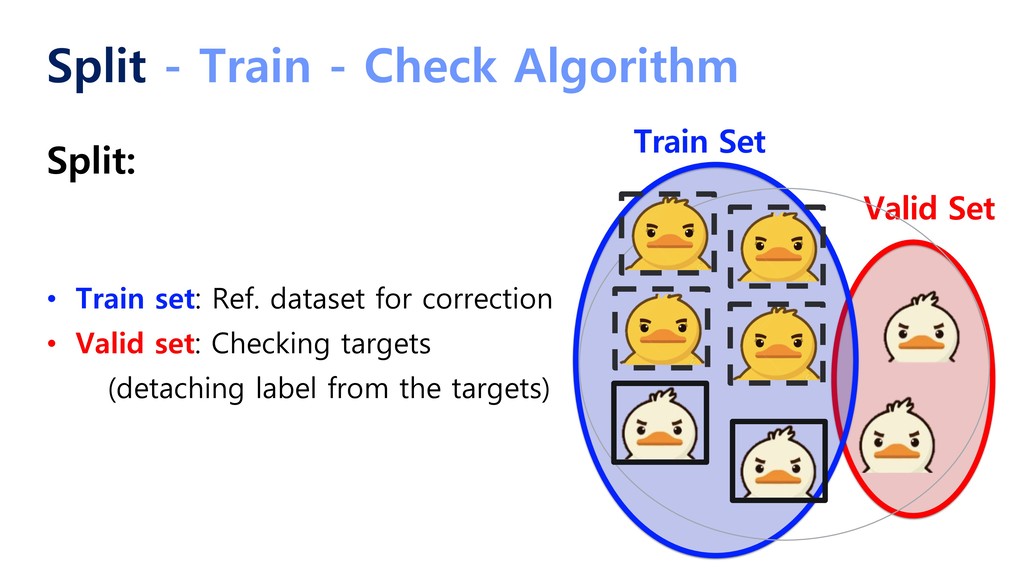{kind=link}
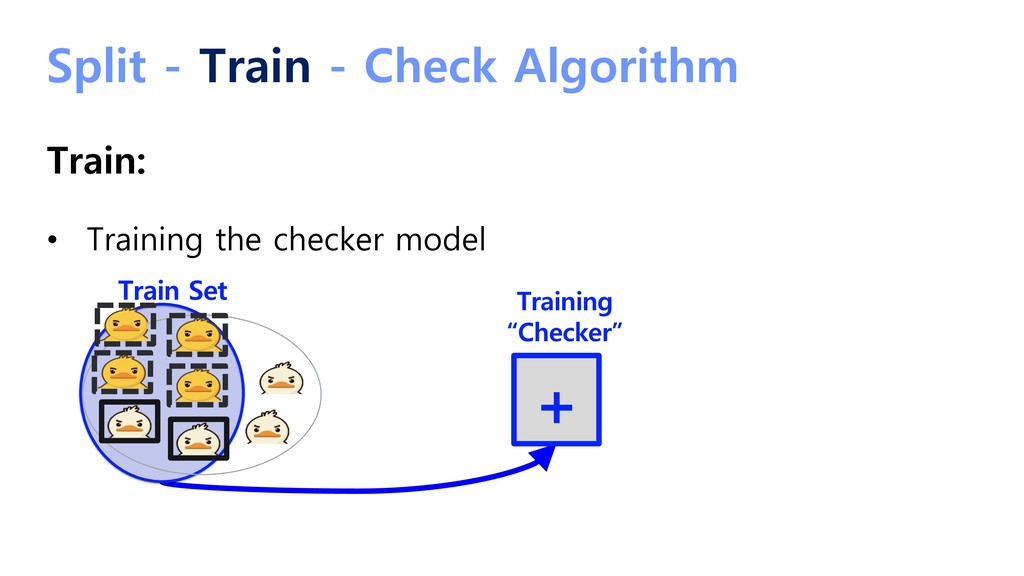{kind=link}
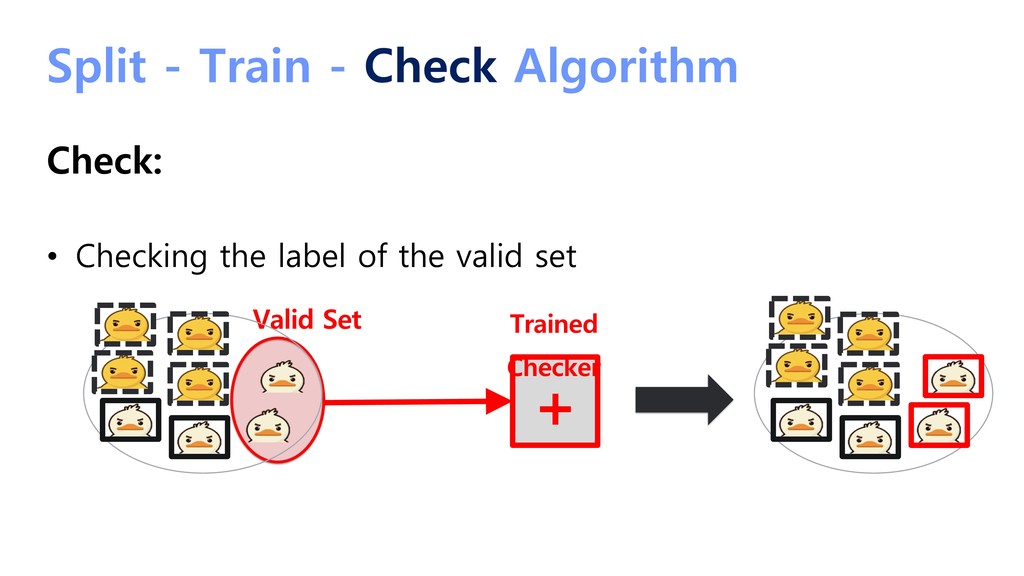{kind=link}
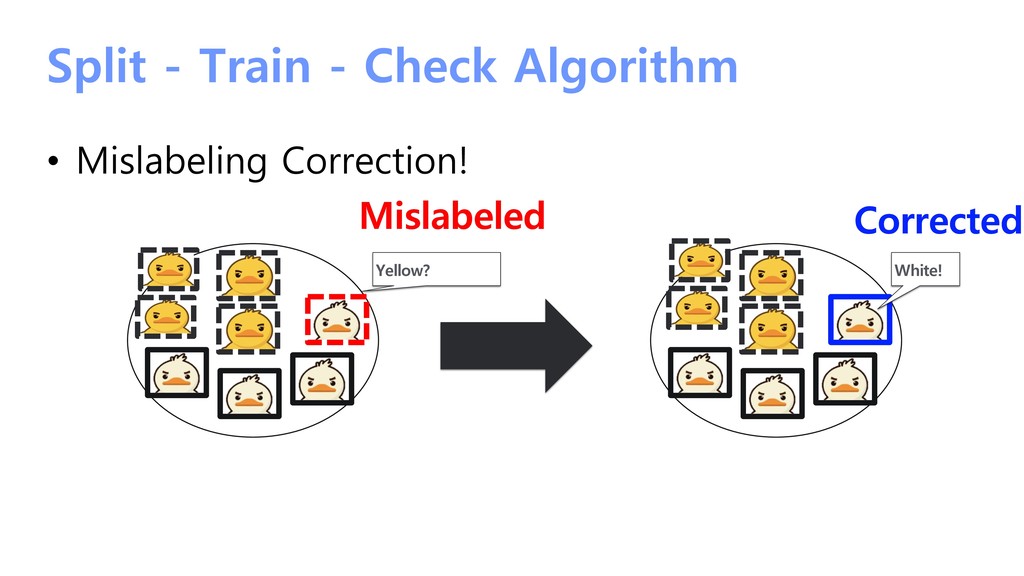{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
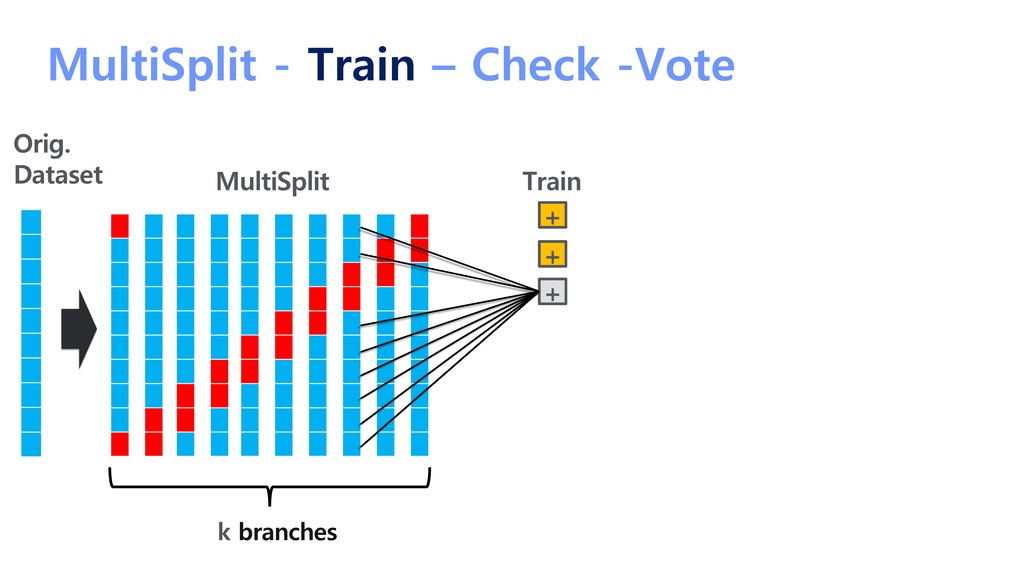{kind=link}
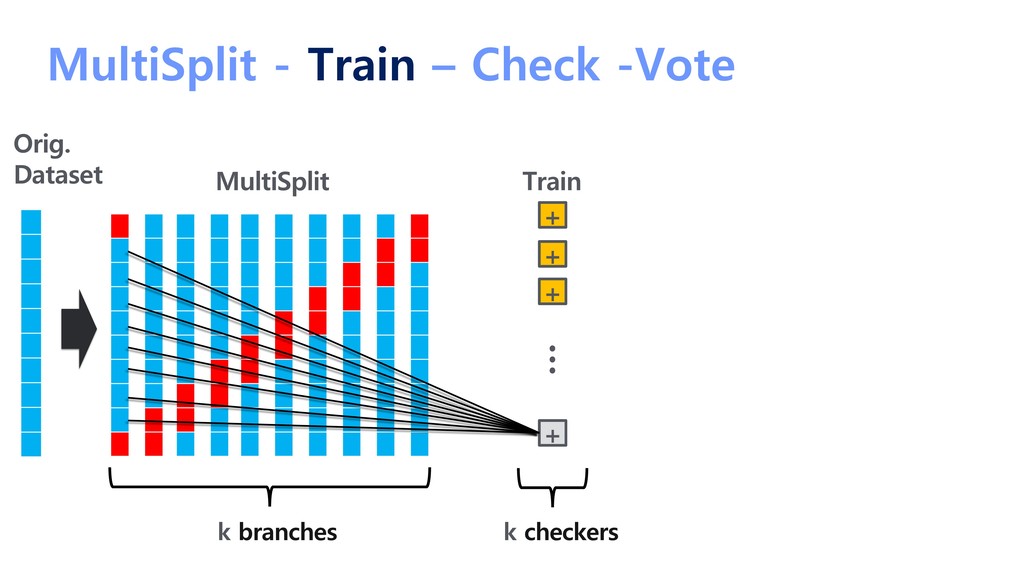{kind=link}
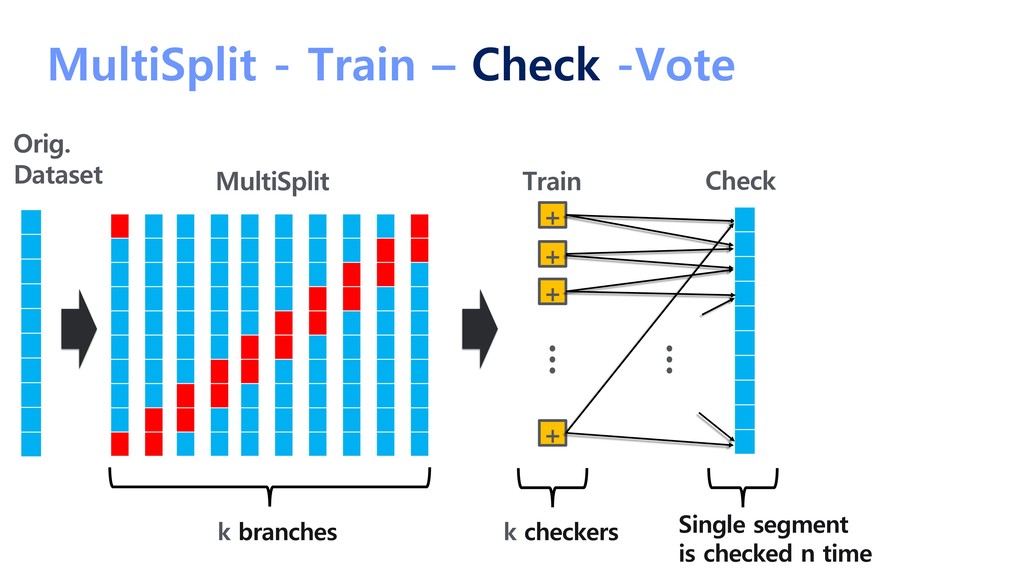{kind=link}
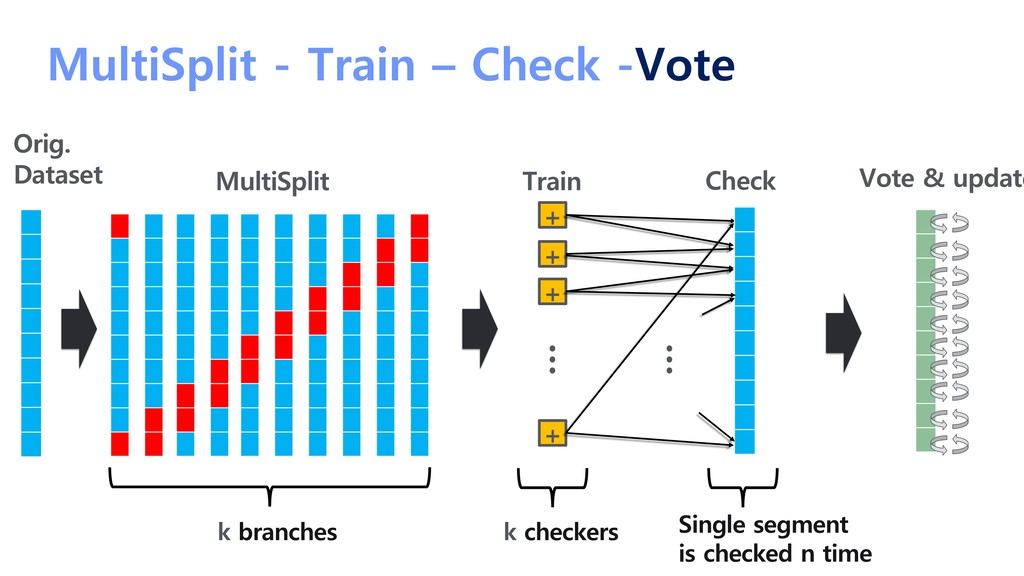{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References • [Bo Han, et al.: 2019] Han, Bo et](https://files.speakerdeck.com/presentations/bc6d42edaa564a59a0765d5135a59cfe/slide_76.jpg){kind=link}