Herausforderungen Johann-Mattis List DFG Nachwuchsstipendiat Centre des recherches linguistiques sur l’Asie Orientale Team Adaptation, Integration, Reticulation, Evolution EHESS and UPMC, Paris 2016/11/09 1 / 45
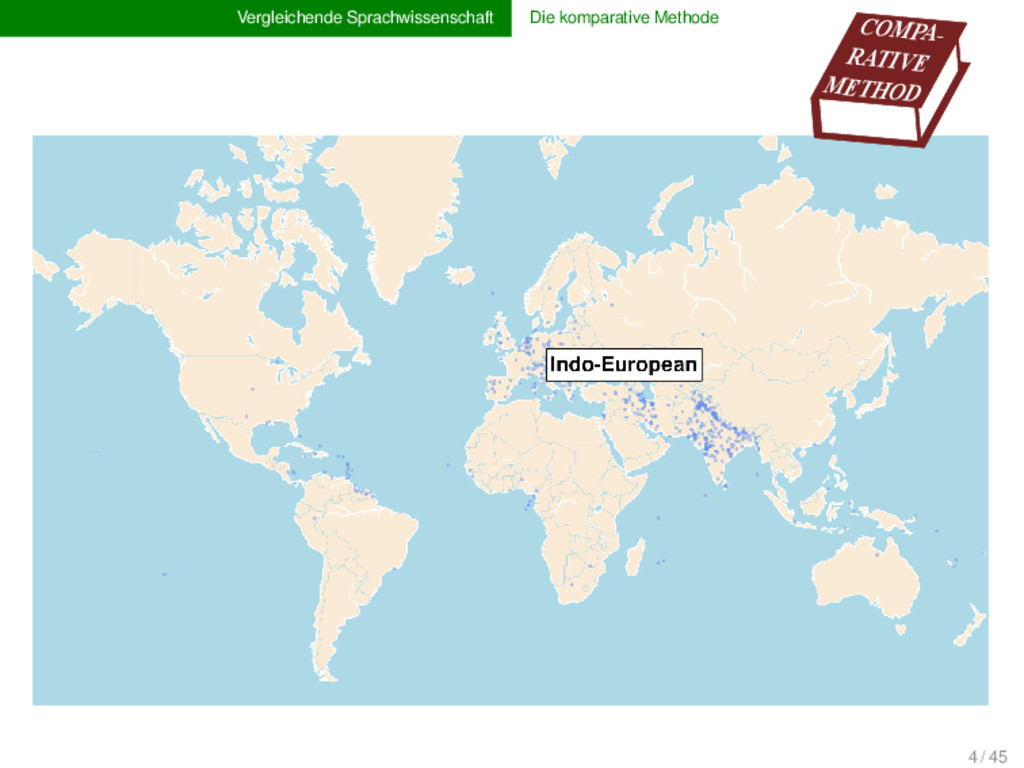
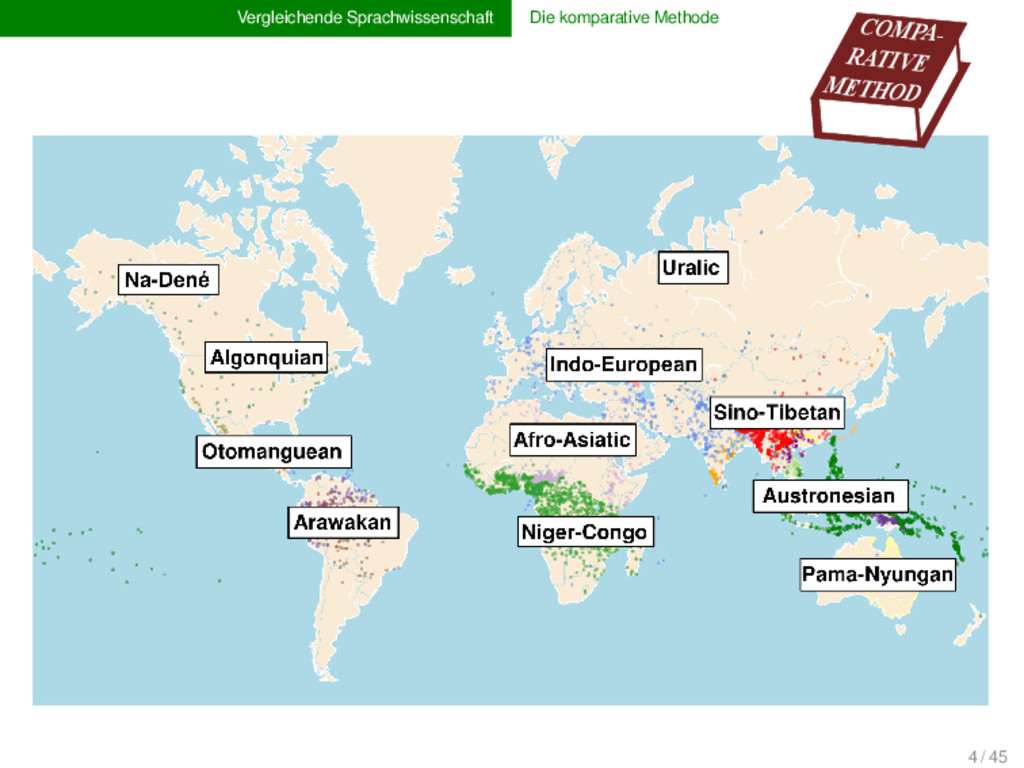
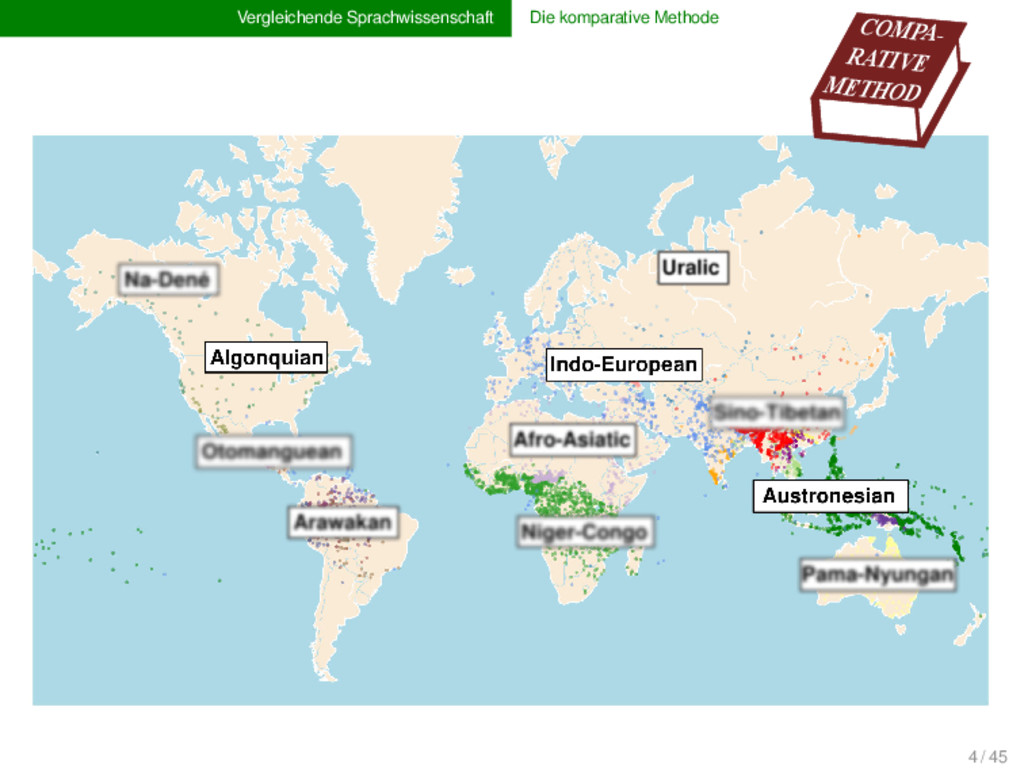
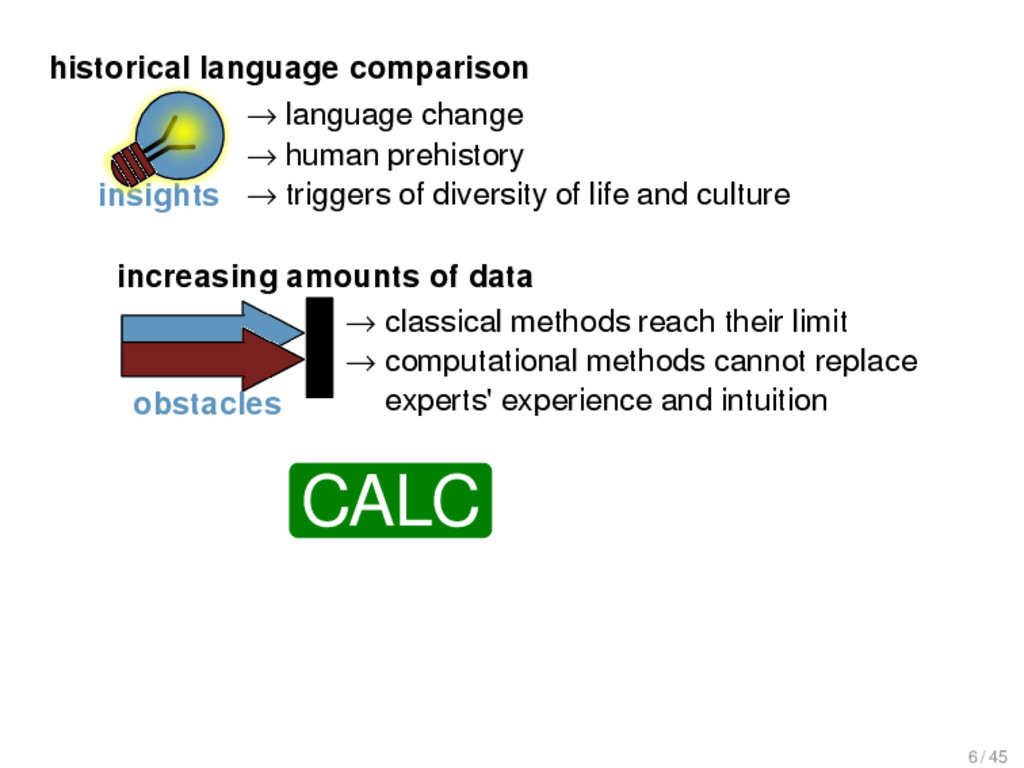
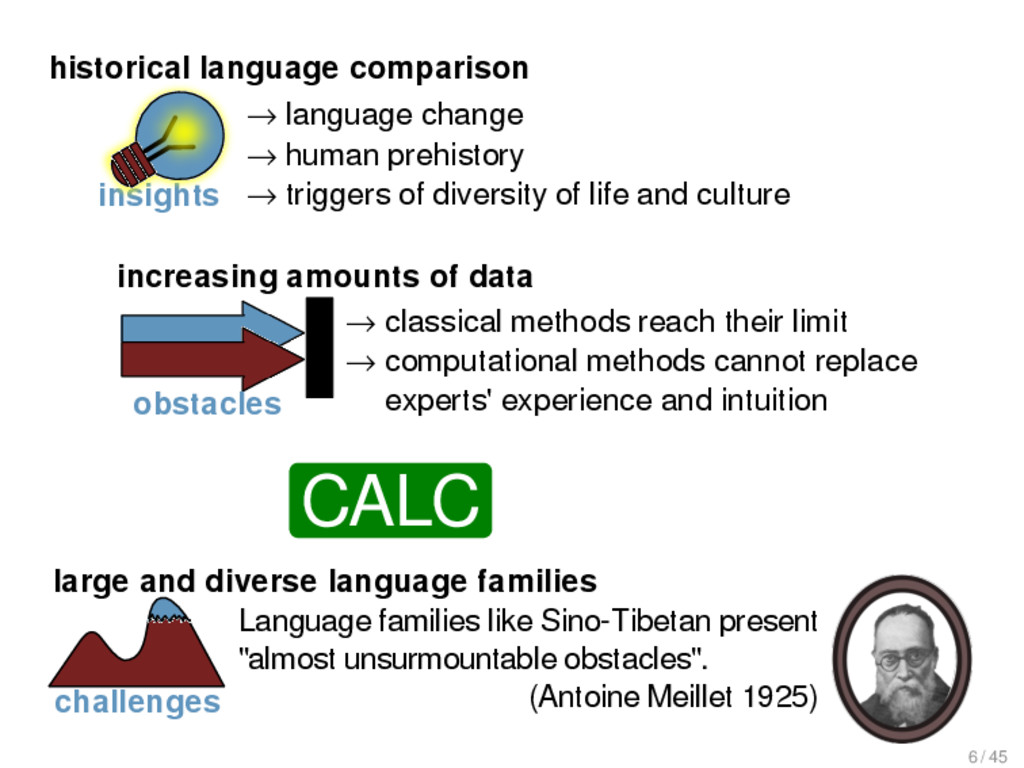
1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges CALC 6 / 45
1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges CALC 6 / 45
1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges CALC 6 / 45
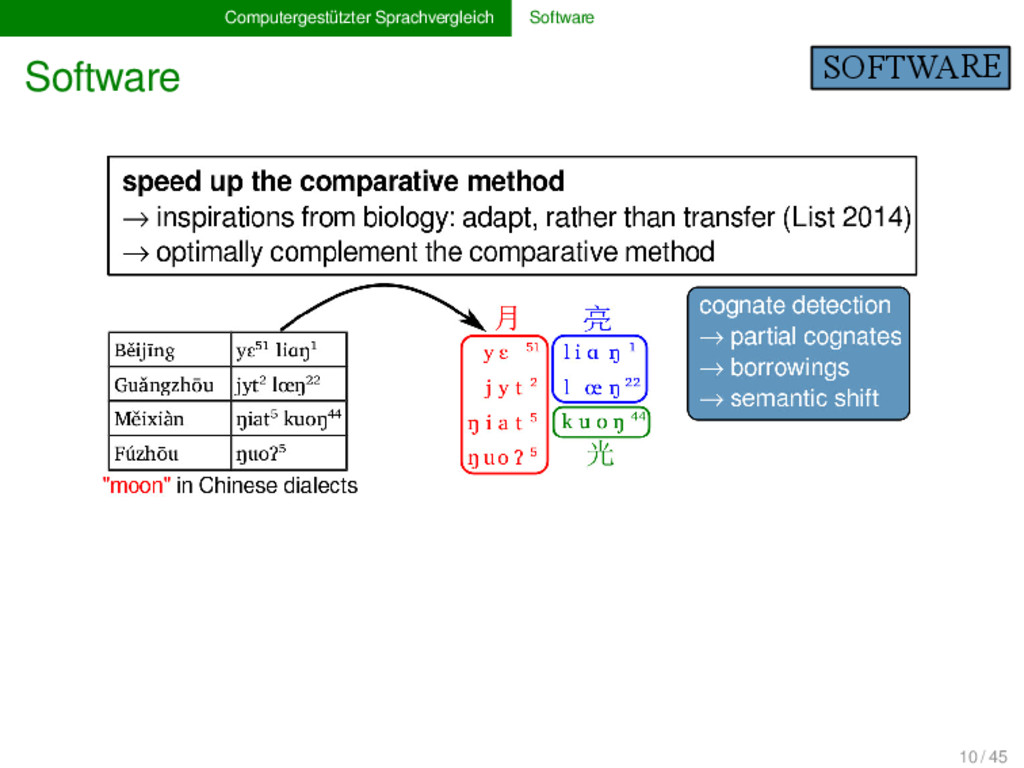
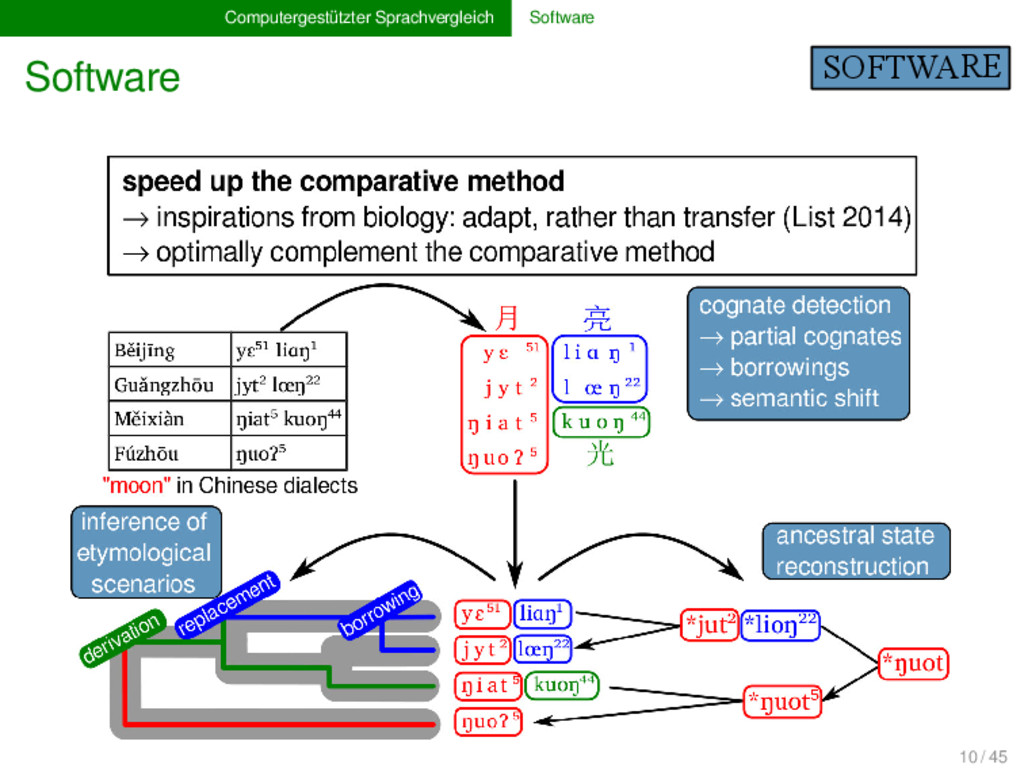
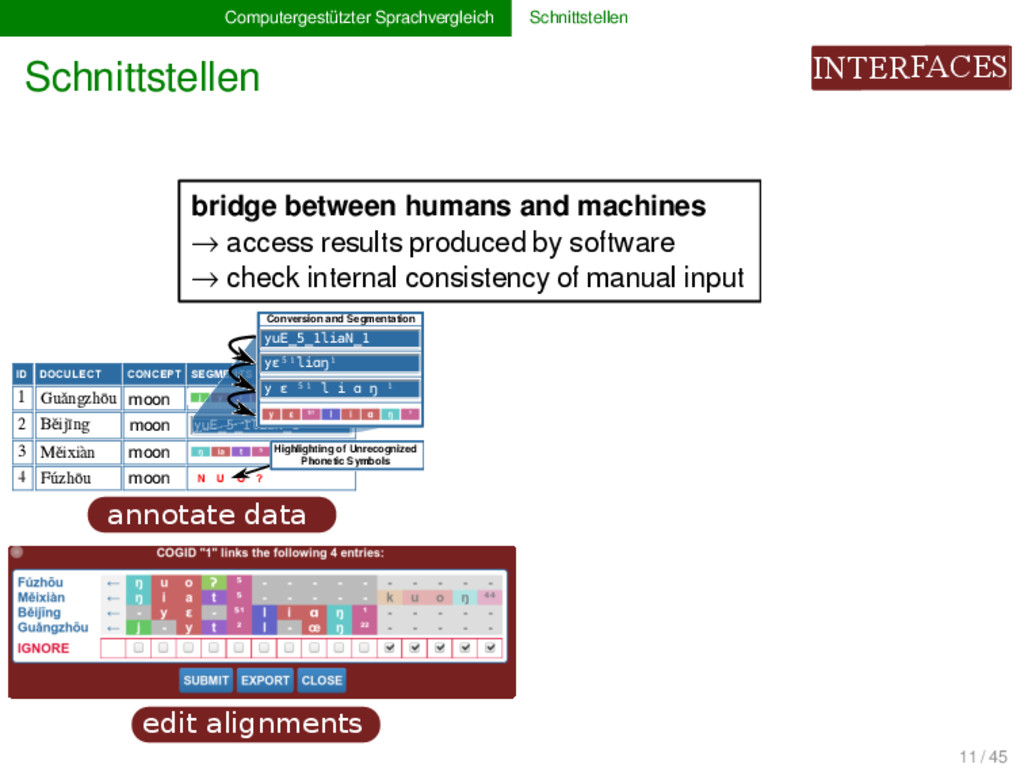
U O ? wOld yuE_5_1liaN_1 moon moon moon moon Běijīng Guǎngzhōu Měixiàn Fúzhōu 1 2 3 4 Conversion and Segmentation Highlighting of Unrecognized Phonetic Symbols yuE_5_1liaN_1 yɛ⁵¹liɑŋ¹ y ɛ ⁵¹ l i ɑ ŋ ¹ annotate data analyze data edit alignments bridge between humans and machines → access results produced by software → check internal consistency of manual input 11 / 45
U O ? wOld yuE_5_1liaN_1 moon moon moon moon Běijīng Guǎngzhōu Měixiàn Fúzhōu 1 2 3 4 Conversion and Segmentation Highlighting of Unrecognized Phonetic Symbols yuE_5_1liaN_1 yɛ⁵¹liɑŋ¹ y ɛ ⁵¹ l i ɑ ŋ ¹ annotate data analyze data edit alignments bridge between humans and machines → access results produced by software → check internal consistency of manual input 11 / 45
U O ? wOld yuE_5_1liaN_1 moon moon moon moon Běijīng Guǎngzhōu Měixiàn Fúzhōu 1 2 3 4 Conversion and Segmentation Highlighting of Unrecognized Phonetic Symbols yuE_5_1liaN_1 yɛ⁵¹liɑŋ¹ y ɛ ⁵¹ l i ɑ ŋ ¹ annotate data analyze data edit alignments bridge between humans and machines → access results produced by software → check internal consistency of manual input 11 / 45
U O ? wOld yuE_5_1liaN_1 moon moon moon moon Běijīng Guǎngzhōu Měixiàn Fúzhōu 1 2 3 4 Conversion and Segmentation Highlighting of Unrecognized Phonetic Symbols yuE_5_1liaN_1 yɛ⁵¹liɑŋ¹ y ɛ ⁵¹ l i ɑ ŋ ¹ annotate data analyse data edit alignments bridge between humans and machines → access results produced by software → check internal consistency of manual input 11 / 45
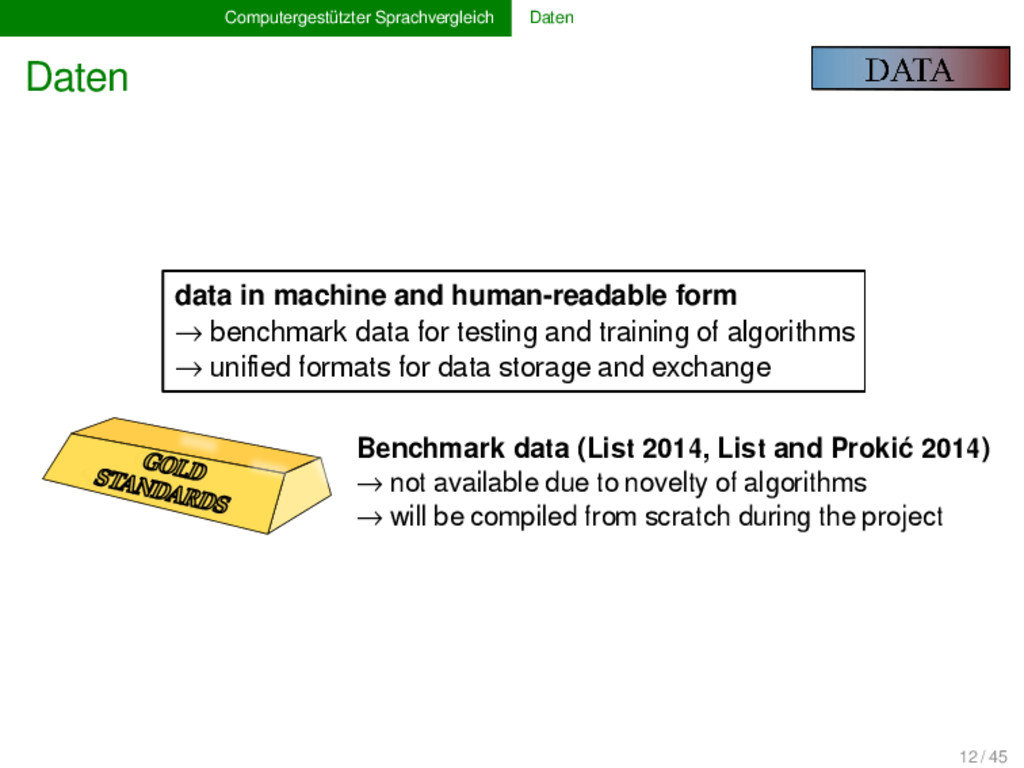
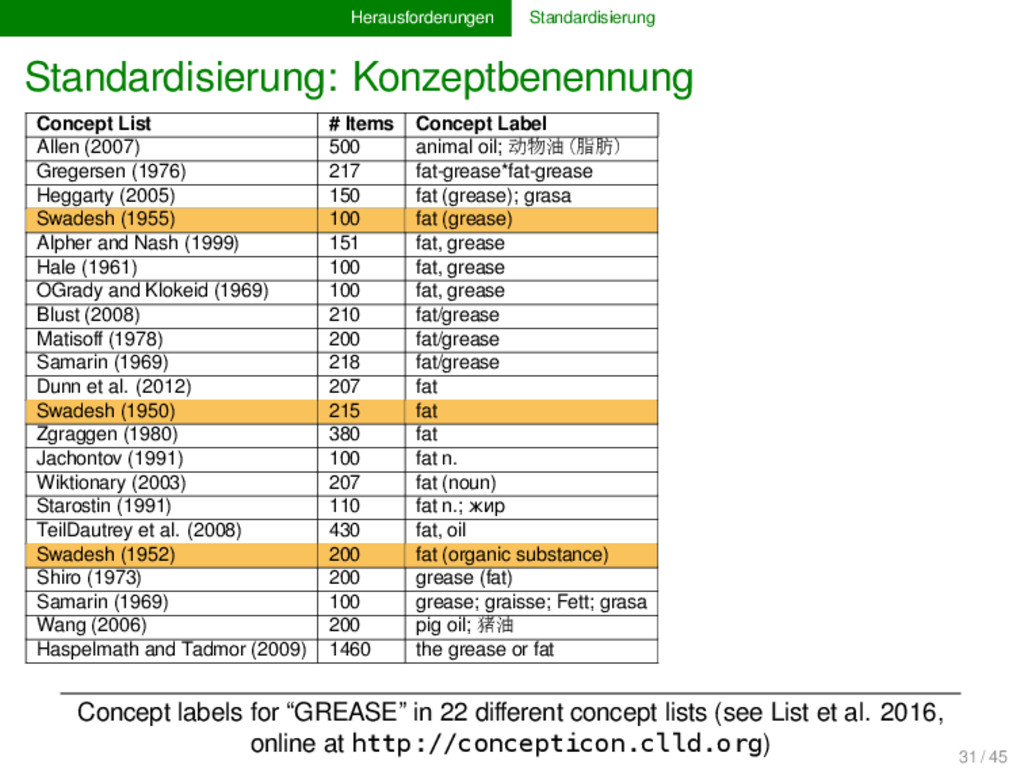
(gold standards, List 2014) → not available due to novelty of algorithms → will be compiled from scratch during the project Unified formats for data storated and exchange → phonetic transcription → comparison concepts (Concepticon, List et al. 2016) → etymological representation (borrowings, cognates) data in machine and human-readable form → benchmark data for testing and training of algorithms → unified formats for data storage and exchange 12 / 45
(List 2014, List and Prokić 2014) → not available due to novelty of algorithms → will be compiled from scratch during the project Unified formats for data storage and exchange → phonetic transcription → comparison concepts (Concepticon, List et al. 2016) → etymological representation (borrowings, cognates) data in machine and human-readable form → benchmark data for testing and training of algorithms → unified formats for data storage and exchange 12 / 45
(List 2014, List and Prokić 2014) → not available due to novelty of algorithms → will be compiled from scratch during the project Unified formats for data storage and exchange → phonetic transcription → comparison concepts (Concepticon, List et al. 2016) → etymological representation (borrowings, cognates) data in machine and human-readable form → benchmark data for testing and training of algorithms → unified formats for data storage and exchange 12 / 45
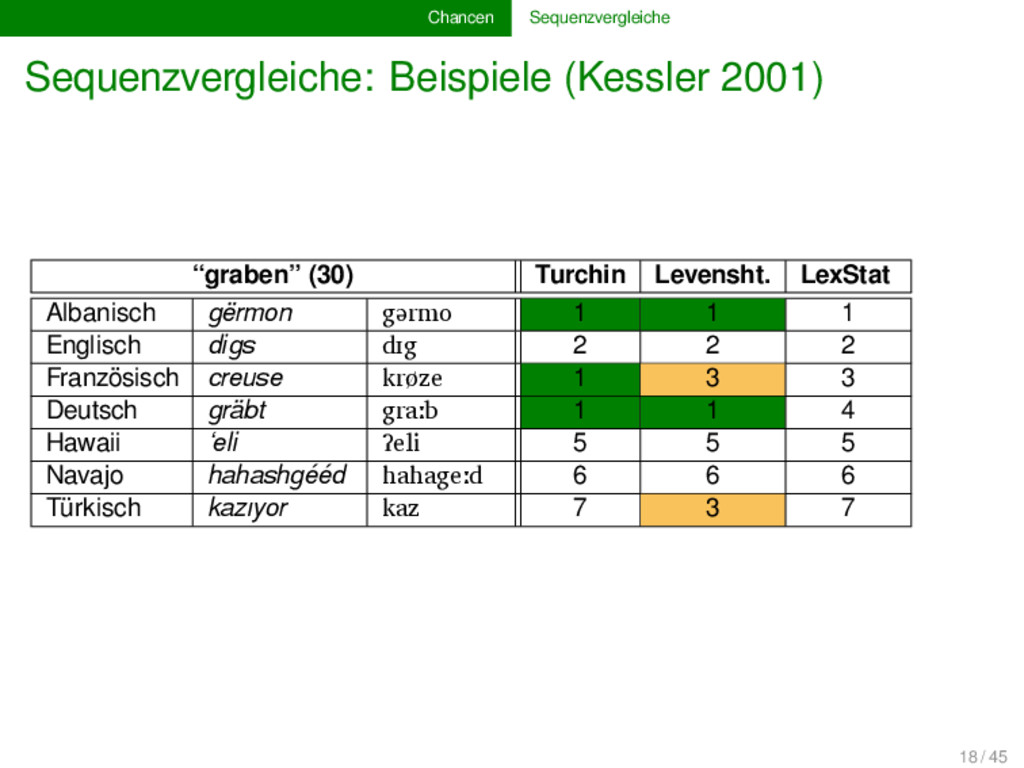
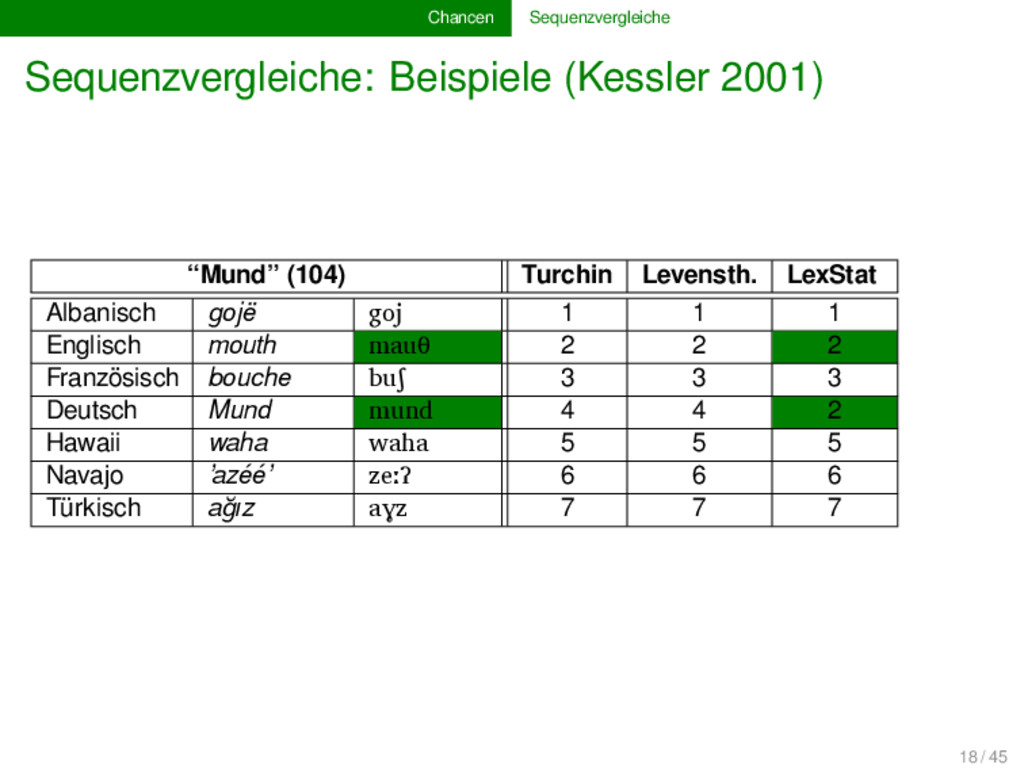
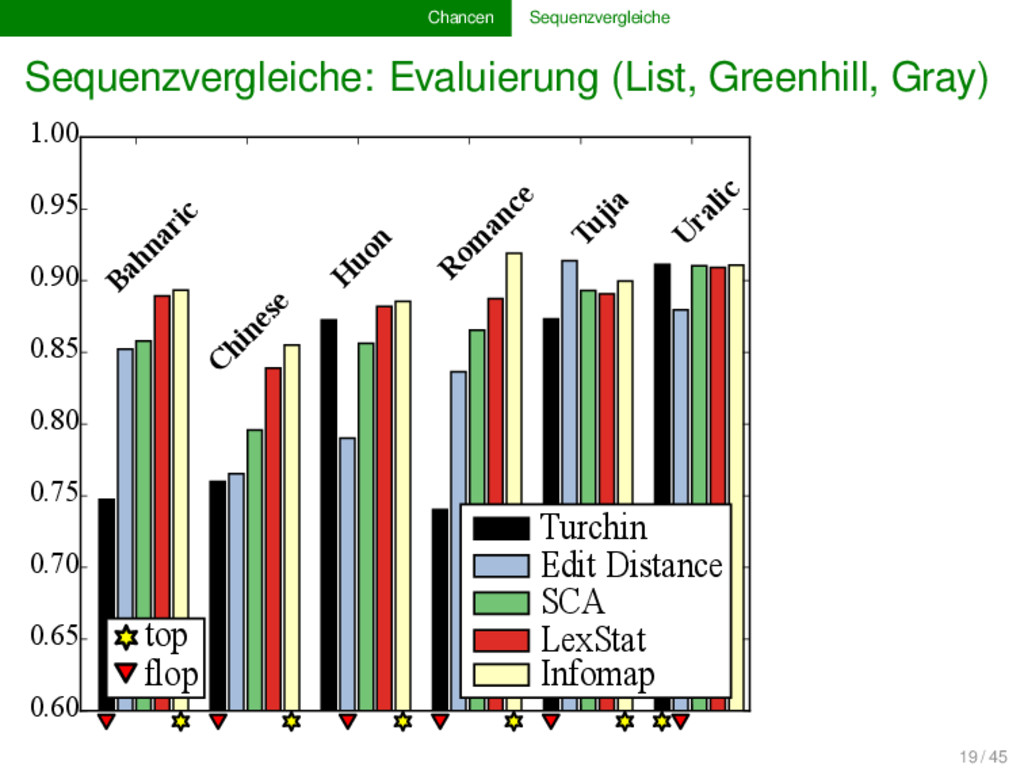
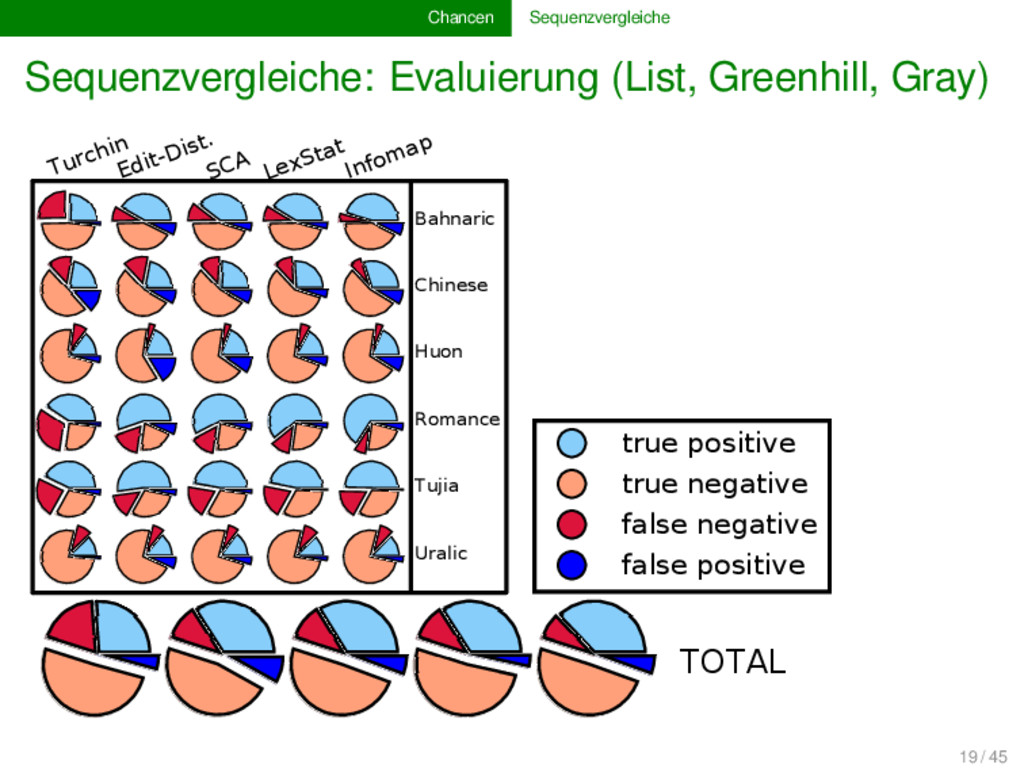
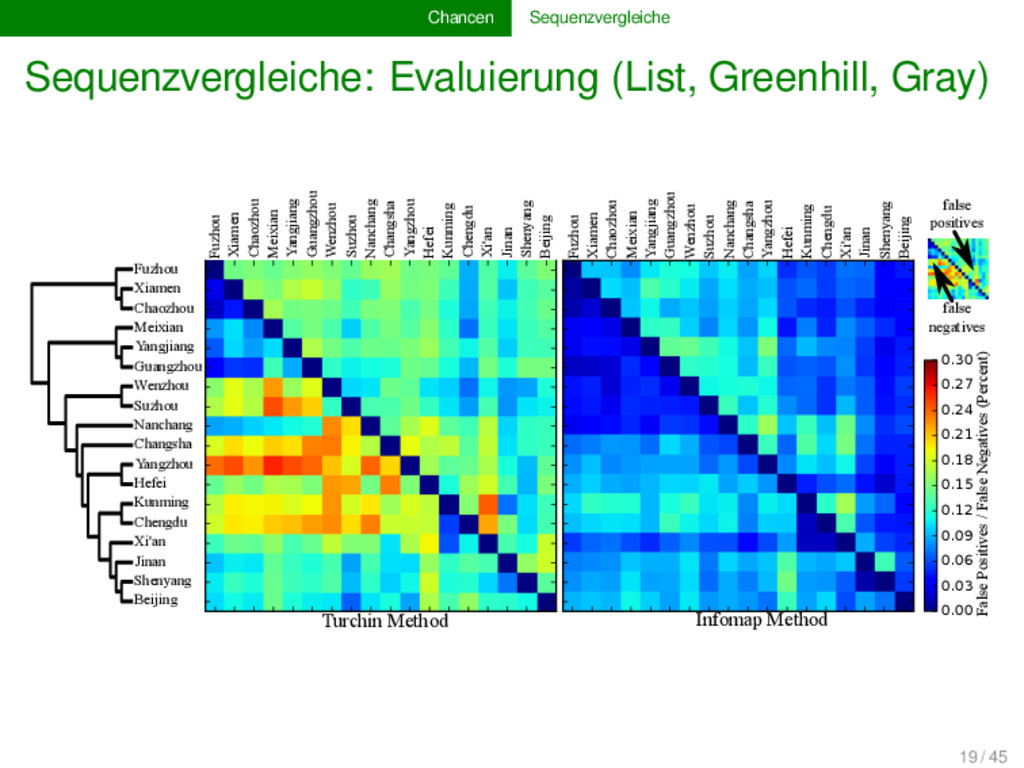
komparative Methode basiert, können als Sequenzen (“Lautketten”) modelliert werden Evolutionsbiologie und Computerwissenschaft stellen uns ein reiches Arsenal an Methoden für automatische Sequenzvergleiche zur Verfügung beim Erstellen von Software für den computergestützten Sprachvergleich dürfen wir aber nicht vergessen, dass wir die Methoden an die spezifischen linguistischen Bedürfnisse anpassen müssen, da es grundlegende Unterschiede zwischen biologischen und linguistischen Sequenzen gibt 15 / 45
genug, um Hilfe beim Erstellen neuer Datensätze zu bieten. Sie können Linguisten nicht ersetzen, aber das ist ja auch nicht das Ziel von CALC. Sie können das Leben der Linguisten allerdings erleichtern, und das Ausmaß dieser Erleichterung kann enorm sein, inbesondere, wenn man die Möglichkeit von interaktiven Annotationstools zur Hilfe nimmt. 20 / 45
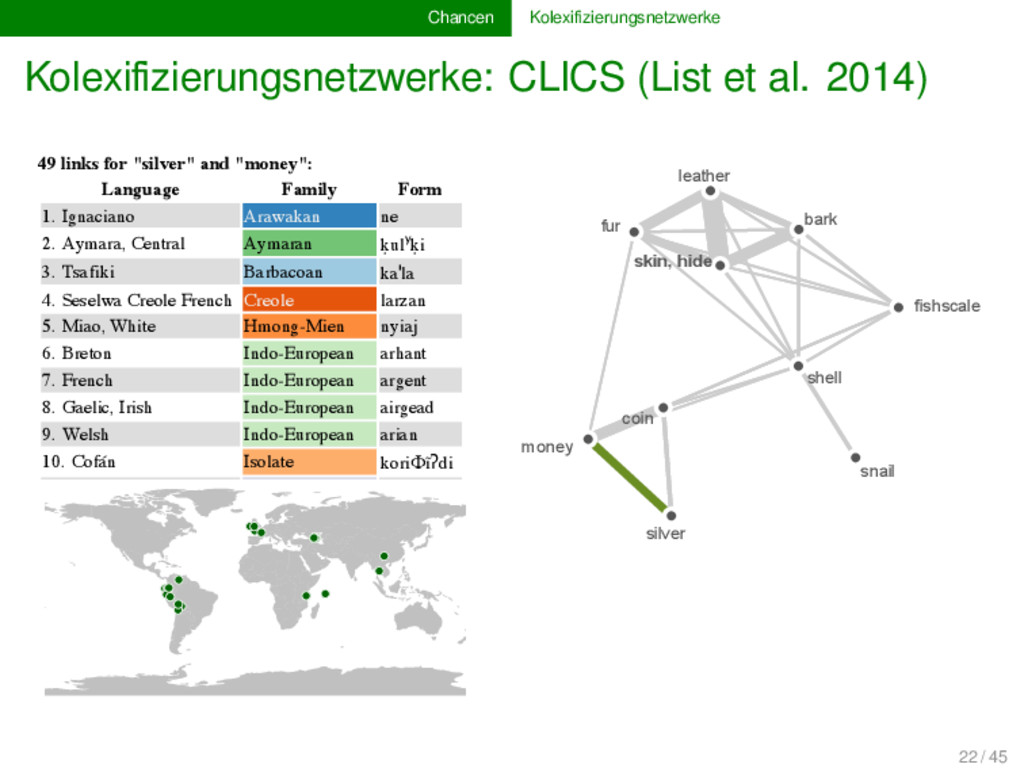
historischen Linguistik behandelt worden die Tatsache, dass die meisten Prozesse sich jedoch synchron in Form von Polysemie äußern, ermöglicht es, über die Idee der Kolexifizierungsnetzwerke, die von Haspelmaths “semantischen Karten” inspiriert sind (Haspelmath 2003, Cysouw 2010), die Diachronie über die Synchronie zu erforschen Netzwerkansätze, die erfolgreich in der Bioinformatik verwendet werden, ermöglichen es, die relativ großen Datenmengen nach wiederkehrenden Mustern zu durchsuchen (List et al. 2013) 21 / 45
is part of a cluster with the central concept "fishscale" with a total of 10 nodes. Hover over forms for each link. Click on the forms to check their sources. Click HERE to export the current network. ty: Line weights: Coloring: Family silver leather fishscale bark coin fur snail skin, hide money shell 49 links for "silver" and "money": Language Family Form 1. Ignaciano Arawakan ne 2. Aymara, Central Aymaran ḳulʸḳi 3. Tsafiki Barbacoan kaˈla 4. Seselwa Creole French Creole larzan 5. Miao, White Hmong-Mien nyiaj 6. Breton Indo-European arhant 7. French Indo-European argent 8. Gaelic, Irish Indo-European airgead 9. Welsh Indo-European arian 10. Cofán Isolate koriΦĩʔdi 22 / 45
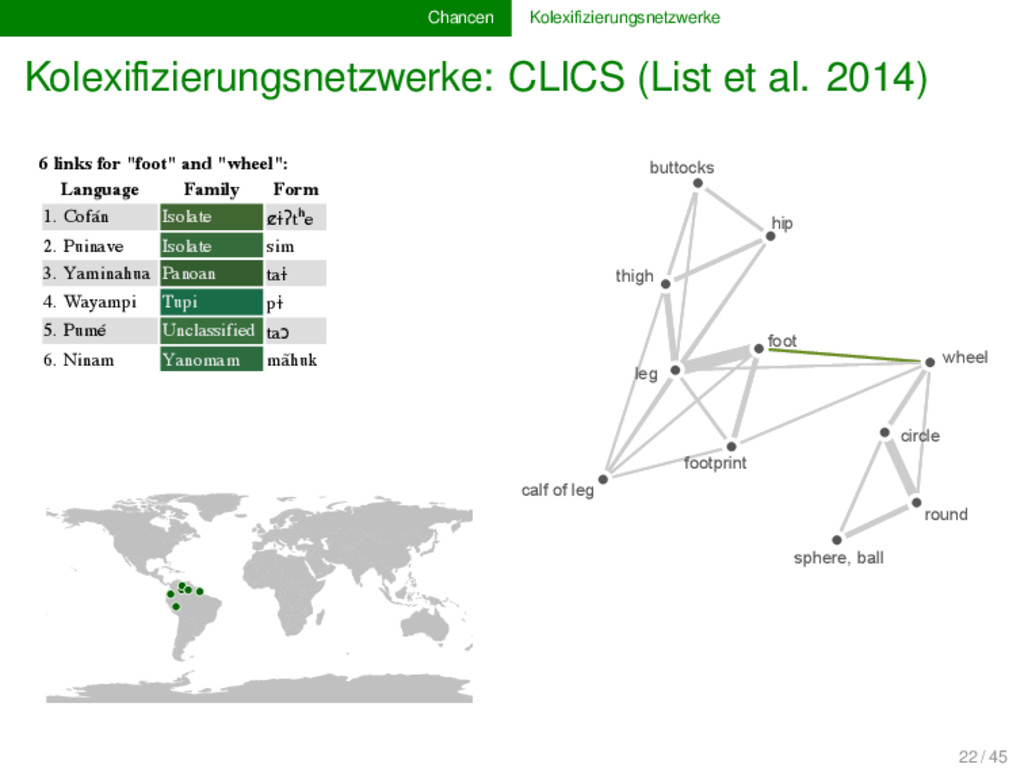
is part of a cluster with the central concept "leg" with a total of 11 nodes. Hover over the e each link. Click on the forms to check their sources. Click HERE to export the current network. ity: Line weights: Coloring: Geolocation sphere, ball round footprint foot calf of leg circle thigh wheel leg hip buttocks 6 links for "foot" and "wheel": Language Family Form 1. Cofán Isolate c̷ɨʔtʰe 2. Puinave Isolate sim 3. Yaminahua Panoan taɨ 4. Wayampi Tupi pɨ 5. Pumé Unclassified taɔ 6. Ninam Yanomam mãhuk 22 / 45
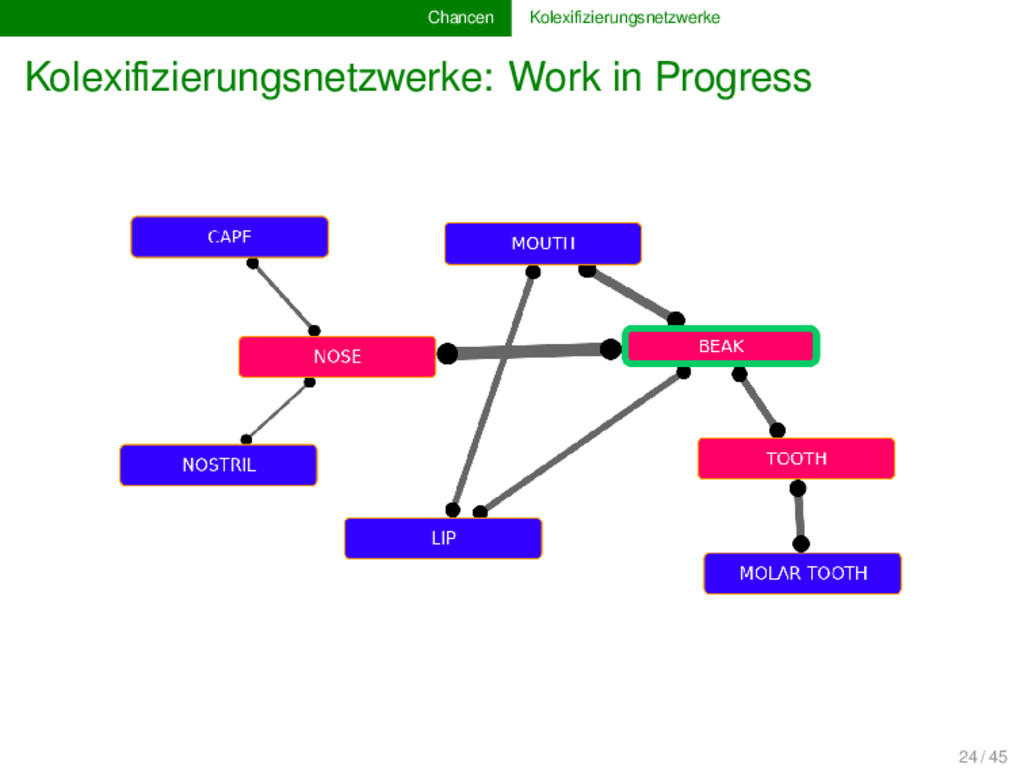
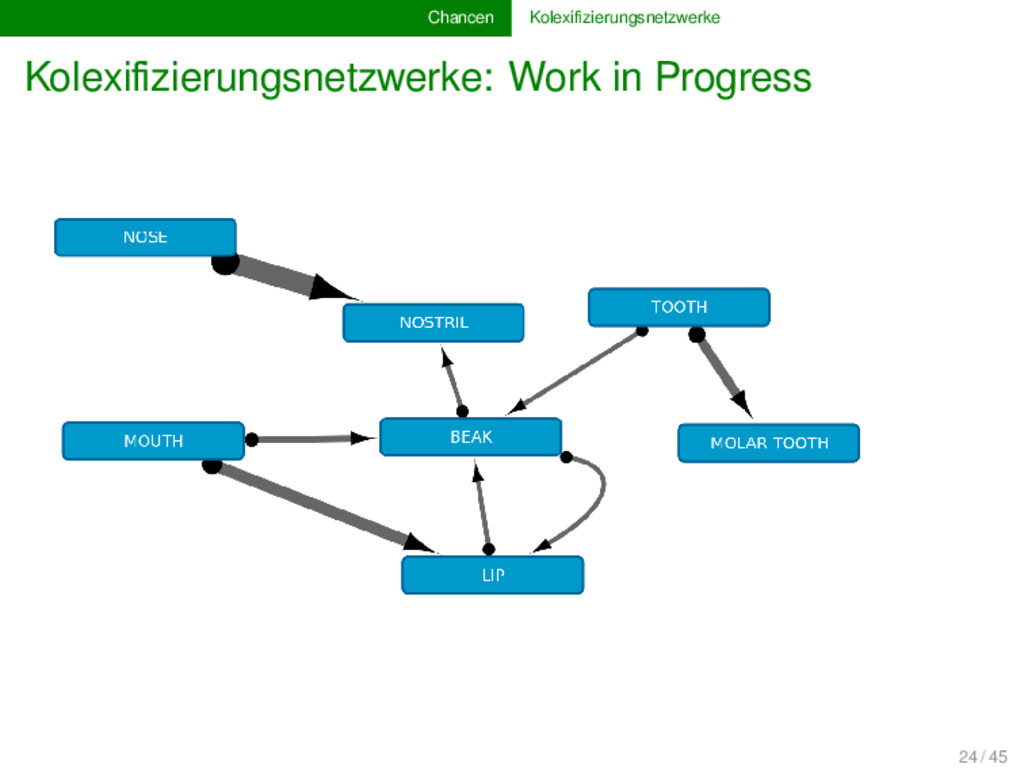
vielerlei Hinsicht erweitern. Derzeit arbeiten wir an einer Vergrößerung der Datenbasis, sowie an einer Verfeinerung der Algorithmen zur Voranalyse. Beispiele betreffen die Ermittlung von Artikulationspunkten und Schlüsselspielern in den semantischen Netzwerken, sowie die Inferenz partieller Beziehungen (inspiriert von Urban 2013), welche in gerichteten Netzwerken visualisiert und als gerichtete Prozesse interpretiert werden können. 23 / 45
erforscht worden, obwohl die Daten einen unvergleichlichen Schatz an Informationen zu sprachgeschichtlichen Tendenzen und menschlicher Kognition liefern. Für die historische Sprachwissenschaft können Kolexifizierungstendenzen in Zukunft helfen, Theorien zur tieferen Verwandtschaft von Sprachen oder entfernter Kognazität abzusichern, indem nicht nur die Korrespondenzen der Laute auf Regelmäßigkeit überprüft werden, sondern auch die Plausibilität der semantischen Entwicklung. 25 / 45
wir mit Hilfe von Netzwerkansätzen nach Mustern suchen, die uns helfen, sowohl die Qualität der Daten zu evaluieren, als auch die Prozesse, die den Daten unterliegen, zu untersuchen. Diese Art von “quantitative pattern analysis” steckt noch in ihren Kinderschuhen und wird derzeit intensiv getestet. Grundlegende Idee ist, dass die Inferenz von Cliquen in Netzwerken, die Spalten in ähnlichen prosodischen Positionen in multiplen Alinierungen zeigen, erste Rückschlüsse zu einer computer-gestützten Rekonstruktion bieten. 26 / 45
Kinderschuhen, aber ich denke, dass wir zuversichtlich sein können, dass die computergestützte Arbeit an Korrespondenzmustern sowohl der klassischen als auch der computerbasierten historischen Linguistik helfen wird. Mit der Mustererkennung können wir nicht nur Daten schneller auf Konsistenz überprüfen, sondern auch klassischen Linguisten helfen, neue Hypothesen zu entwickeln und diese dann transparent (mensch- und maschinenlesbar!) mit Kollegen zu teilen und zu diskutieren. 29 / 45
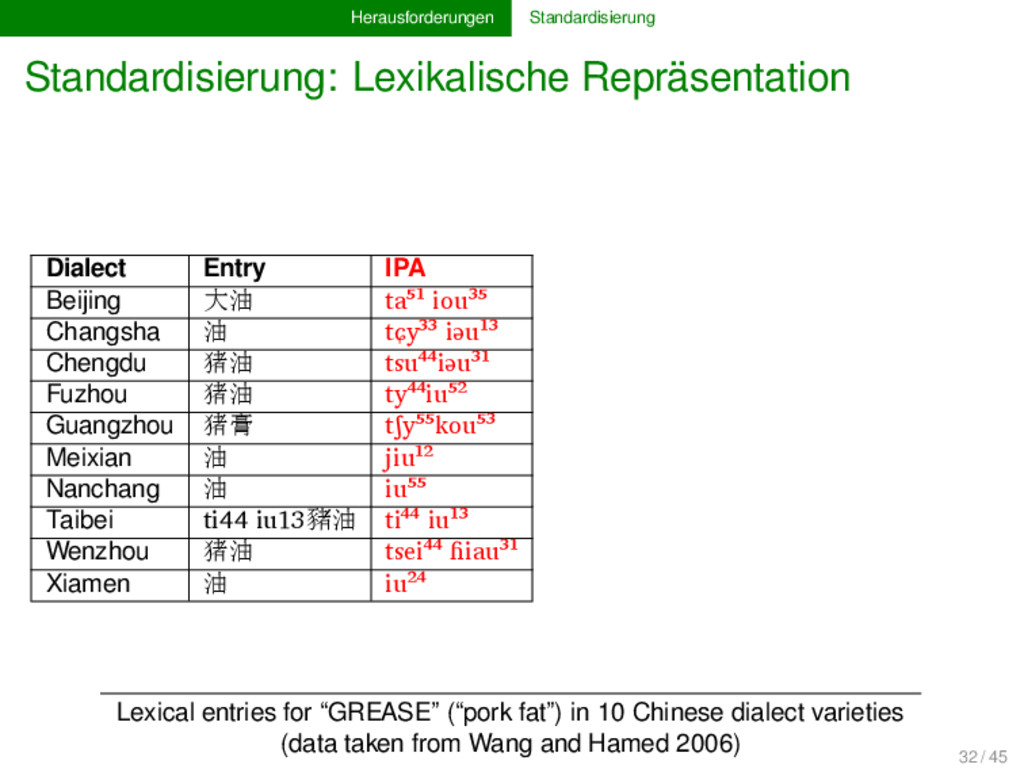
Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ Lexical entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) 32 / 45
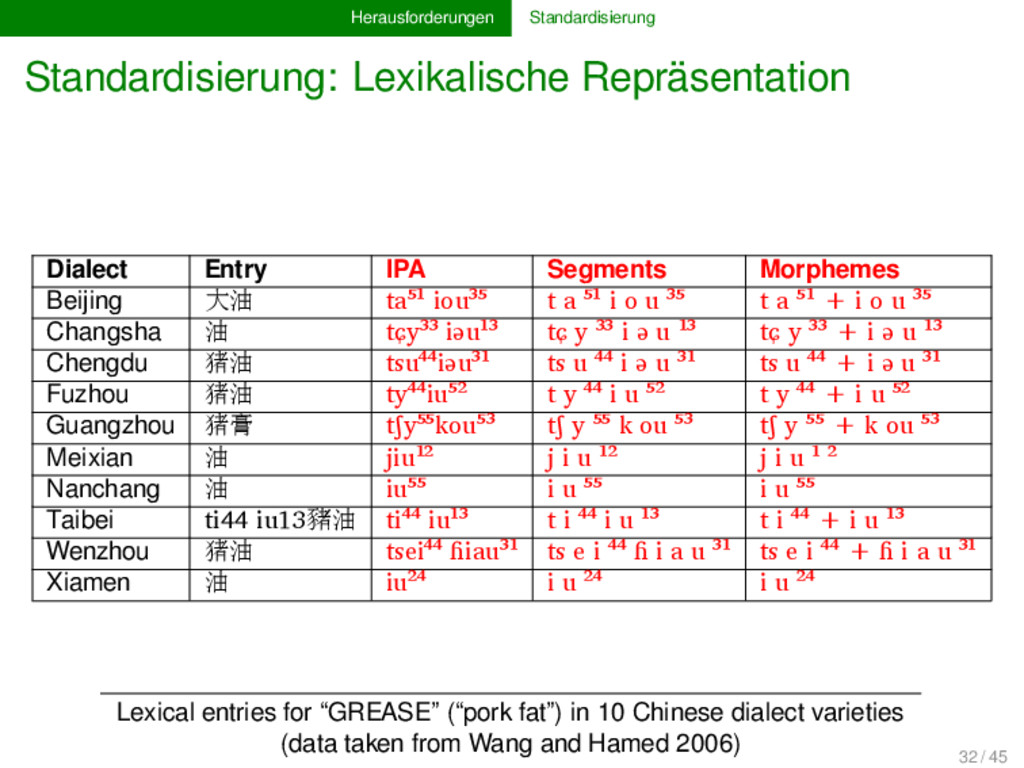
fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 32 / 45
fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 32 / 45
fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 32 / 45
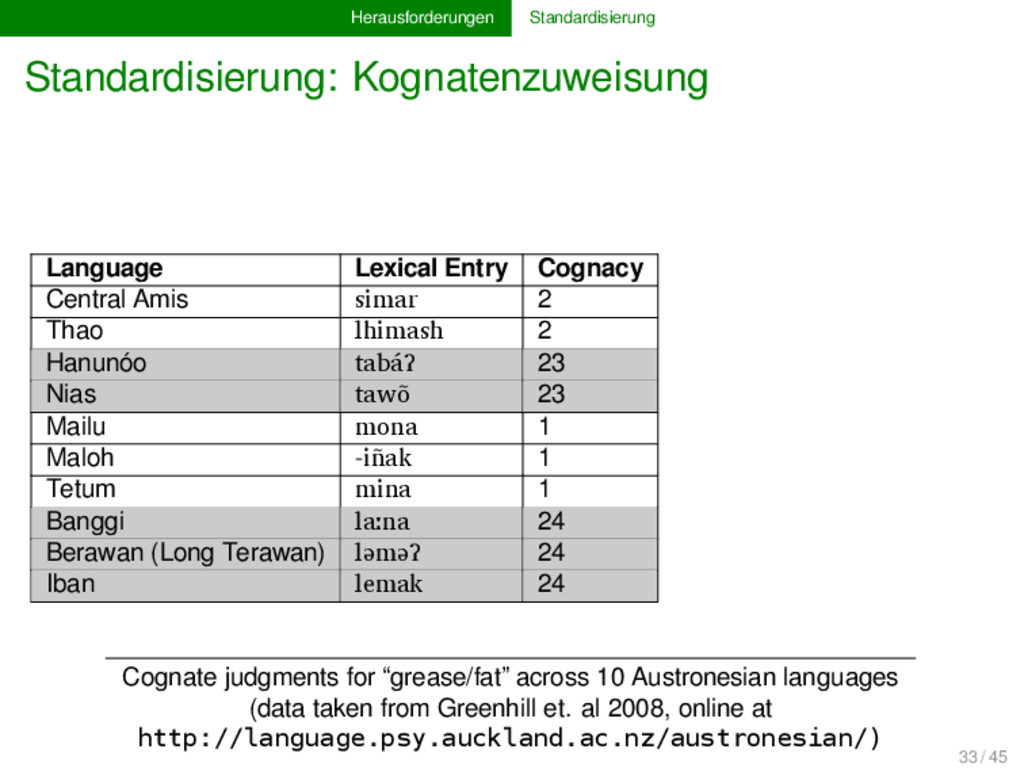
Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k Cognate judgments for “grease/fat” across 10 Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) 33 / 45
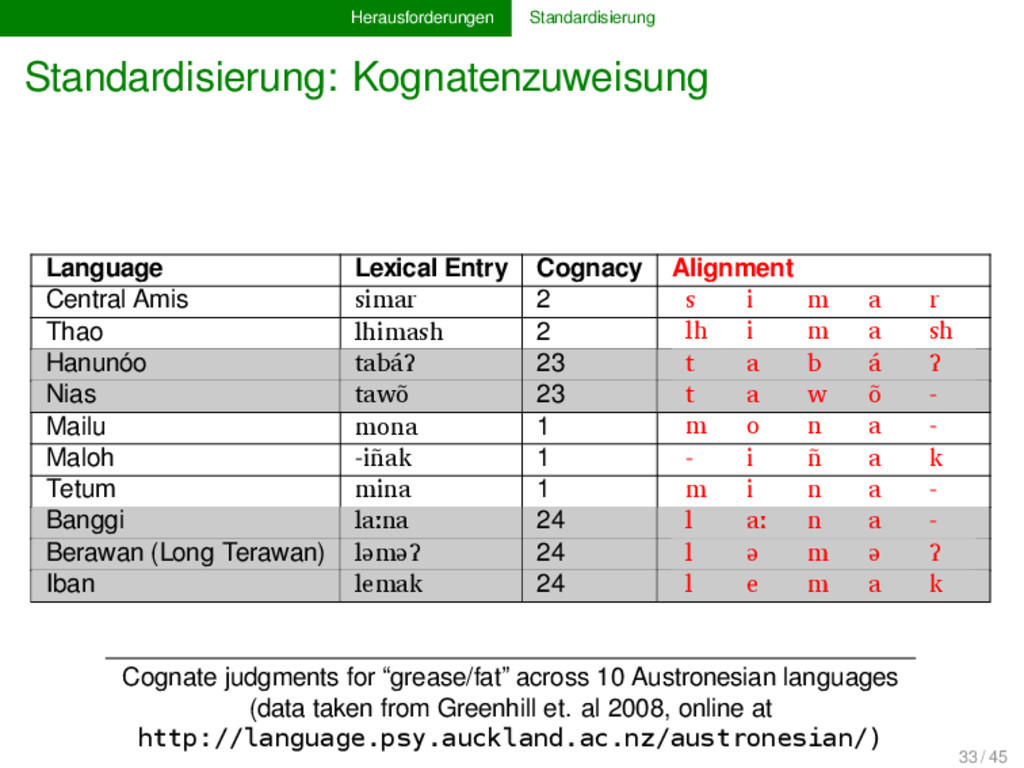
Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) Language Lexical Entry Cognacy Alignment Central Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k 33 / 45
um die Vergleichbarkeit von Daten in der historischen Linguistik zu erhöhen, sei es im Rahmen der Concepticon-Initiative, von Glottolog, eines standardisierten phonetischen Alphabets (denn IPA ist nicht standardisiert in der Form, in der es gebraucht wird), oder in Form von Vorschlägen zur besten Praktik für das Annotieren von Kognaten, und komplexeren historischen Beziehungen. Aber der Weg ist beschwerlich und wird nicht ohne eine breite Kollaboration unter Forschenden verschiedenster Bereiche möglich sein. 34 / 45
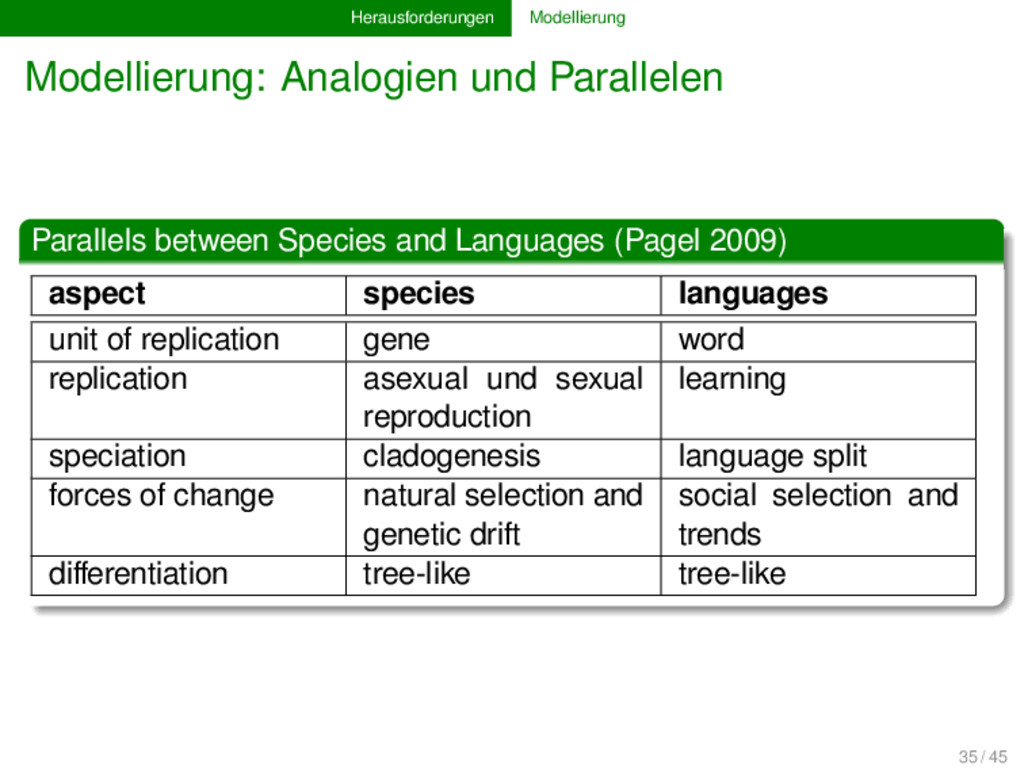
Languages (Pagel 2009) aspect species languages unit of replication gene word replication asexual und sexual reproduction learning speciation cladogenesis language split forces of change natural selection and genetic drift social selection and trends differentiation tree-like tree-like 35 / 45
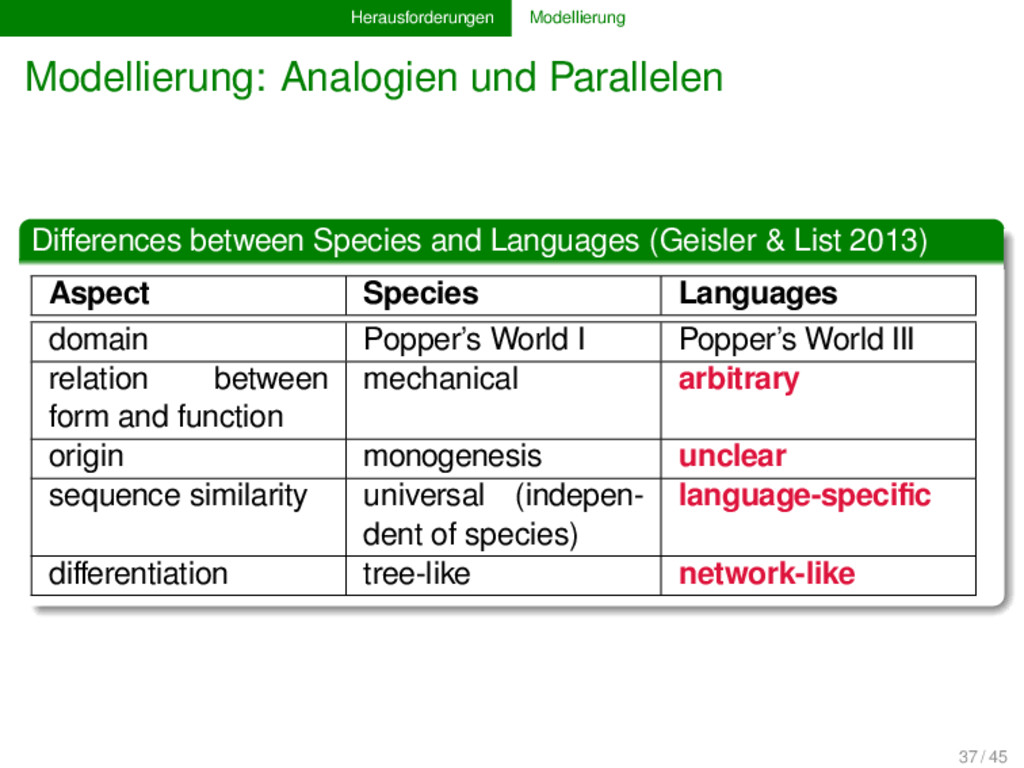
Languages (Geisler & List 2013) Aspect Species Languages domain Popper’s World I Popper’s World III relation between form and function mechanical arbitrary origin monogenesis unclear sequence similarity universal (indepen- dent of species) language-specific differentiation tree-like network-like 37 / 45
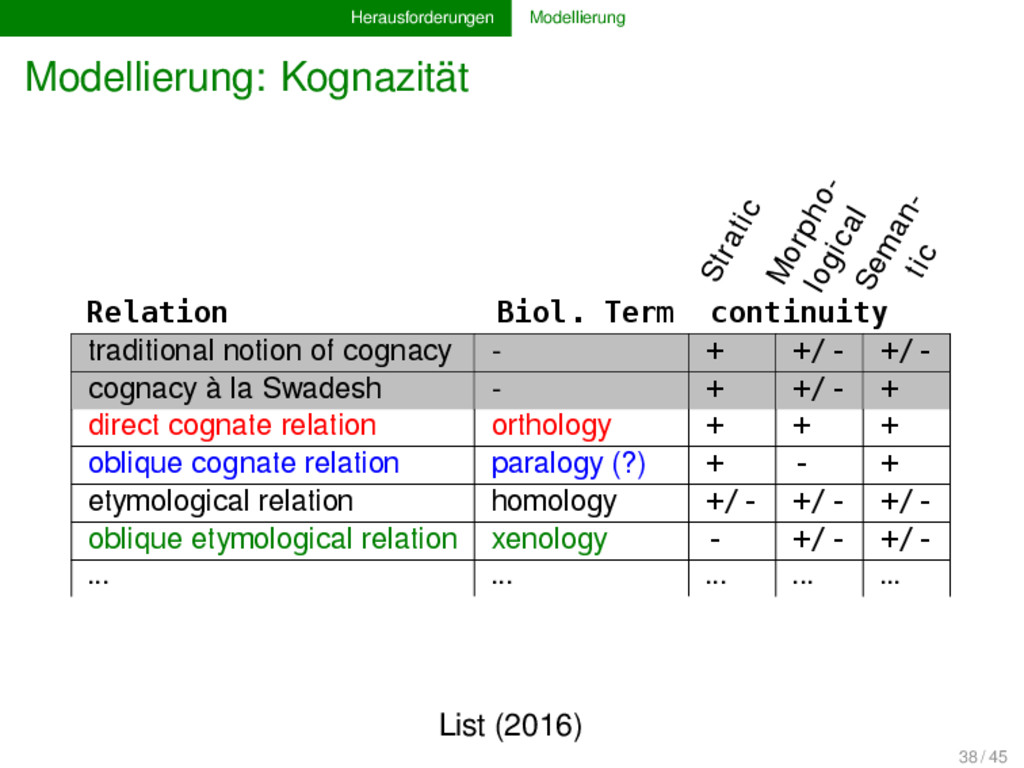
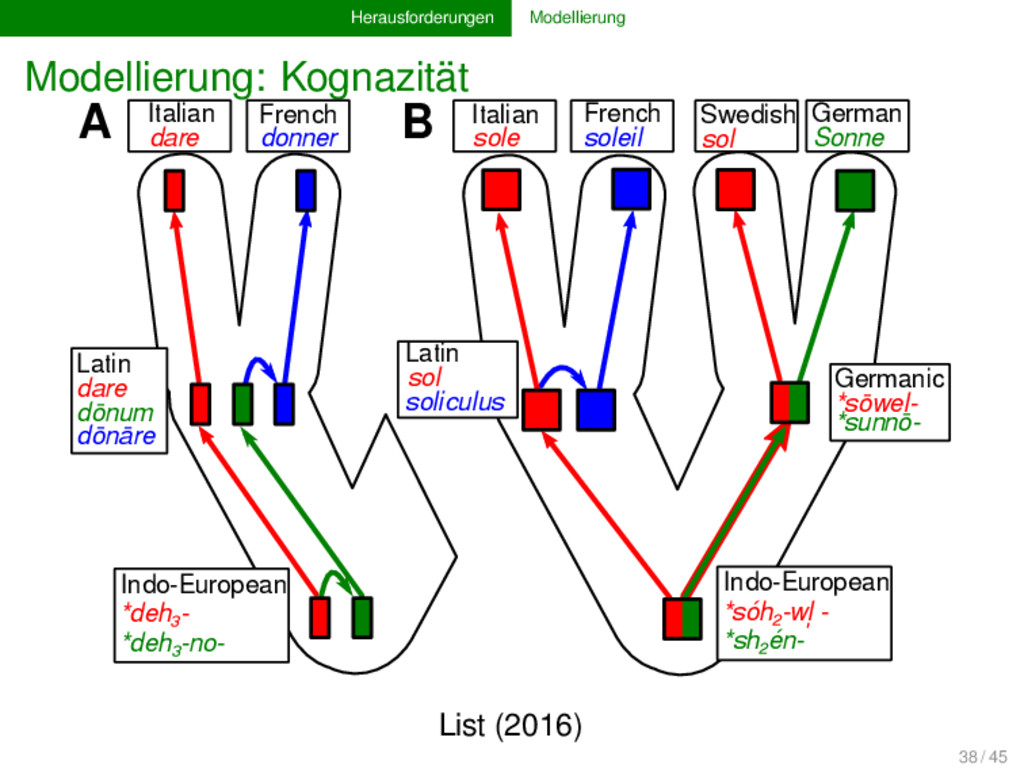
*deh₃-no- Latin dare dōnum dōnāre Italian sole French soleil Swedish sol German Sonne Germanic *sōwel- *sunnō- Latin sol soliculus Indo-European *sóh₂-wl̩ - *sh₂én- A B List (2016) 38 / 45
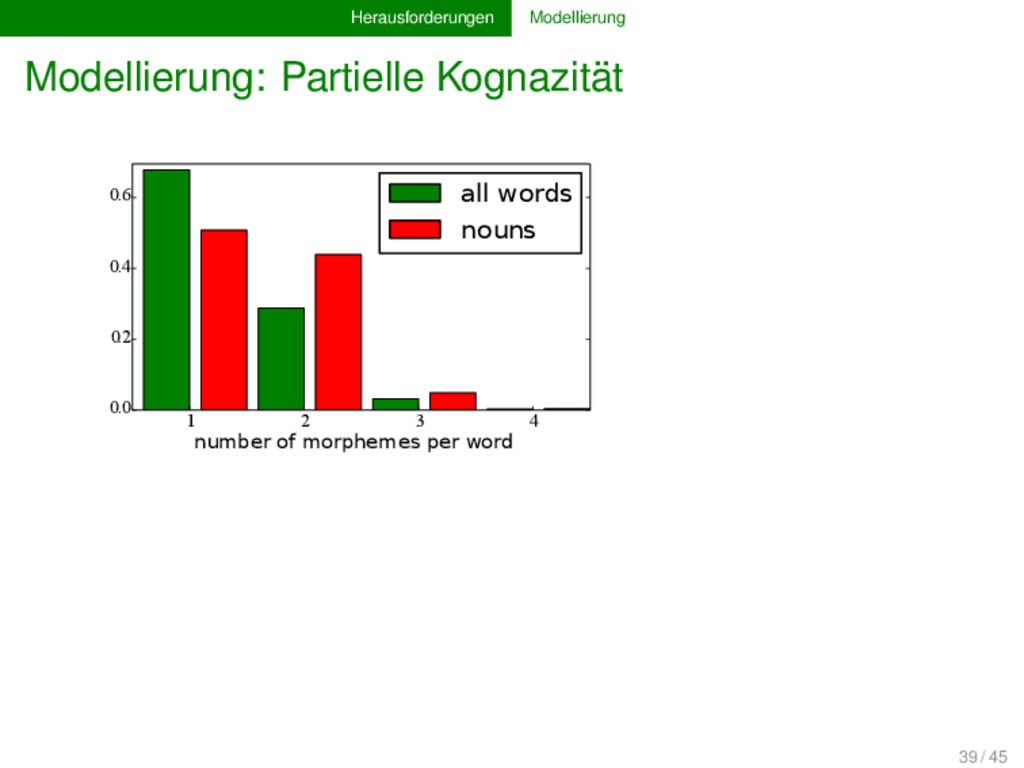
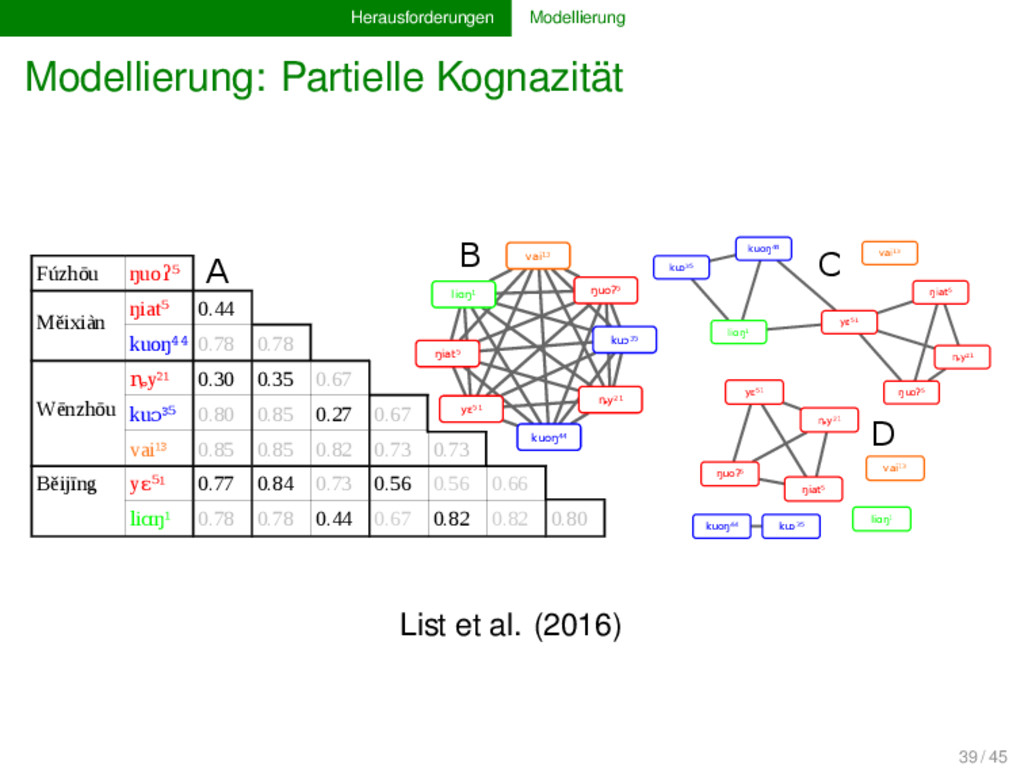
oder den statistischen Eigenschaften unserer Methoden zu arbeiten müssen wir auch insbesondere an die Prozesse denken, die wir modellieren wollen. Oftmals haben Linguisten recht gute Vorstellungen diesbezüglich, aber selten gehen diese Vorstellungen auch in die Analysen mit ein. Dies wird insbesondere an den Problemen mit der Kognazität ersichtlich, da die Annahme von einfachen Prozessen des Kognatengewinns und des Kognatenverlustes der Komplexität lexikalischen Wandels nicht gerecht werden. 40 / 45
with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 41 / 45
with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 41 / 45
with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE COMPUTER-ASSISTED LANGUAGE COMPARISON 41 / 45
Validität. Um diese zu erreichen, können wir ohne Kollaboration nicht vorankommen, sei es, dass wir in Teams kollaborieren um Methoden zu entwickeln oder Datensätze zu erstellen, oder dass wir unsere Methoden anderen Forschenden so zur Verfügung stellen, dass diese sie dann auch verwenden können. Zu oft sehen Wissenschaftler die historische Sprachwissenschaft noch als Einzelsportart. Von den Naturwissenschaftlern können wir aber lernen, dass diese Zeiten vorbei sind. So schwierig es sein kann, in Gruppen zu arbeiten (vor allem wenn diese interdisziplinär sind): Kollaboration zahlt sich am Ende meist aus. 42 / 45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}