hbz-Infrastruktur für Bibliotheksdaten Programmbereich Linked Open Data, hbz NRW Fabian Steeg, Pascal Christoph ULB Münster 8. November 2013 Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Bibliotheksinformationen Indexierung und Auffindbarkeit (z.B. durch Google) Interoperabilität Einfache Wiederverwendung das alles: durch Verwendung von Web-Standards Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Grundidee: Interoperabilität durch gemeinsames, flexibles Datenmodell und einheitliche Identifier Datenmodell: Subjekt–Prädikat–Objekt, z.B. <Faust> <geschrieben von> <Goethe> Identifier: Was genau ist Faust, was heisst geschrieben von, wer ist Goethe? → Einheitliche Identifier <http :// lobid .org/resource/HT010460356> <http :// purl.org/dc/elements/1.1/creator> <http :// d−nb.info/gnd/118540238> . Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
des hbz, seit 2010 (lobid: linking open bibliographic data) Titeldaten (lobid-resources), Normdaten (lobid-organisations) bis vor Kurzem: Dumps und Triple-Store Verschiedene Probleme und neue Anforderungen (z.B. Auto-Suggest für Normdaten) → ab 2012 neues Backend entwickelt Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Web-APIs Semantic-Web-Community sehr akademisch LOD sollte das ändern, hat nur bedingt geklappt Linked Open Data für viele uninteressant Aber: Web 2.0 und HTTP APIs sind erfolgreich Um APIs entsteht App-Ökosystem Nutzung von APIs ist für Webentwickler normal Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Performanzprobleme (z.B. durch komplexe Queries gegen den Triple-Store) lösen Neue Anwendungen ermöglichen (z.B. Auto-Suggest auf Personen-Normdaten) Web und Webentwickler im Fokus, weniger akademisch (quasi: back to the roots) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Programming Interfaces sind ein essentieller Bestandteil von wiederverwendbaren Modulen Module kommunizieren über API, kennen keine Implementierungsdetails Implementierung so austauschbar und veränderbar – ohne dass alle API-Clients (=Anwendungen) angepasst werden müssen → erst dadurch tatsächlich wiederverwendbar Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
haben inzwischen eine Menge Material: CC-BY-2.0 Angela Montillon, Wikimedia Commons, File:Colourful_wool_2.jpg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
etwas mehr Fokus auf Werkzeuge: CC-0, Scott Bauer, Wikimedia Commons, File:Flügelspinnmaschine.jpeg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
als API? – Triple-Store cool, mächtig, aber als API gerade dadurch problematisch (z.B. Performance) Wegen Performance (z.B. Auto-Suggest) anderer Ansatz: Suchmaschinentechnologie – Suchmaschine als API? API unabhängig von Implementierung! API als stabile Abstraktion über Daten! Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Revolution wird in erster Linie von Technologiefirmen und Web-2.0-Gemeinde vorangetrieben” (Antragstext Datenmanagement-Plattform SLUB Dresden) Linked Open Data nur Teil der Lösung! Muss ein Webentwickler sich für LOD interessieren um von LOD zu profitieren? – Ziel: LOD für Webentwickler, nicht (nur) für LOD-Experten → JSON über HTTP Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
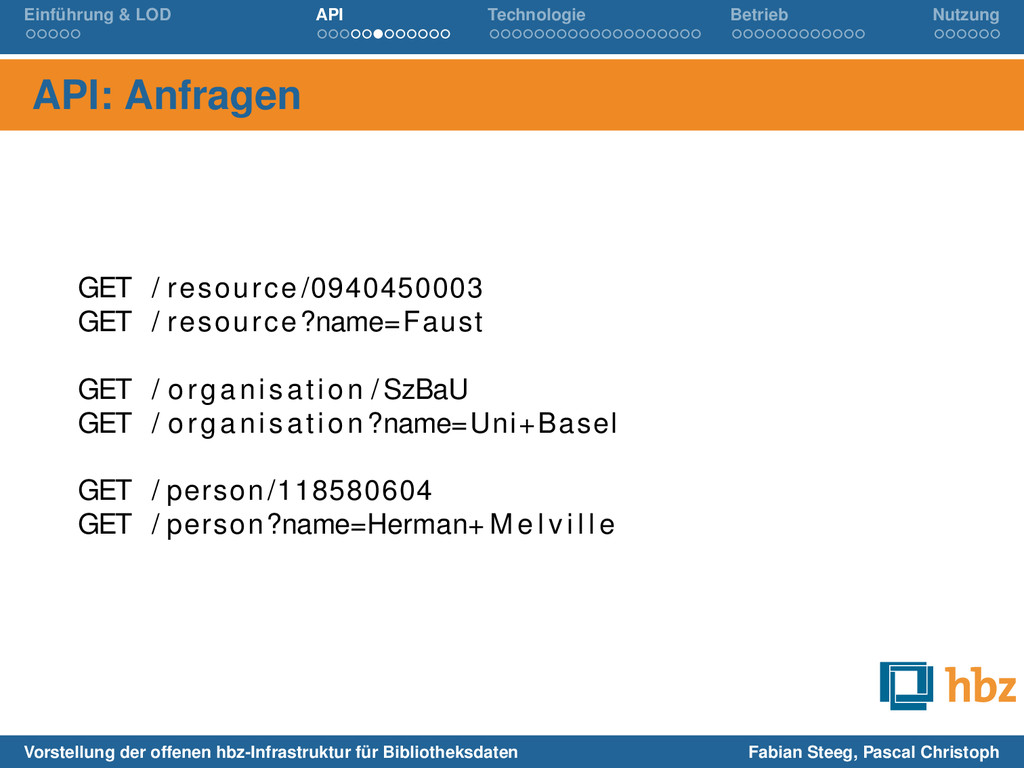
/ resource /0940450003 GET / resource?name=Faust GET / organisation /SzBaU GET / organisation ?name=Uni+Basel GET / person/118580604 GET / person?name=Herman+ M e l v i l l e Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
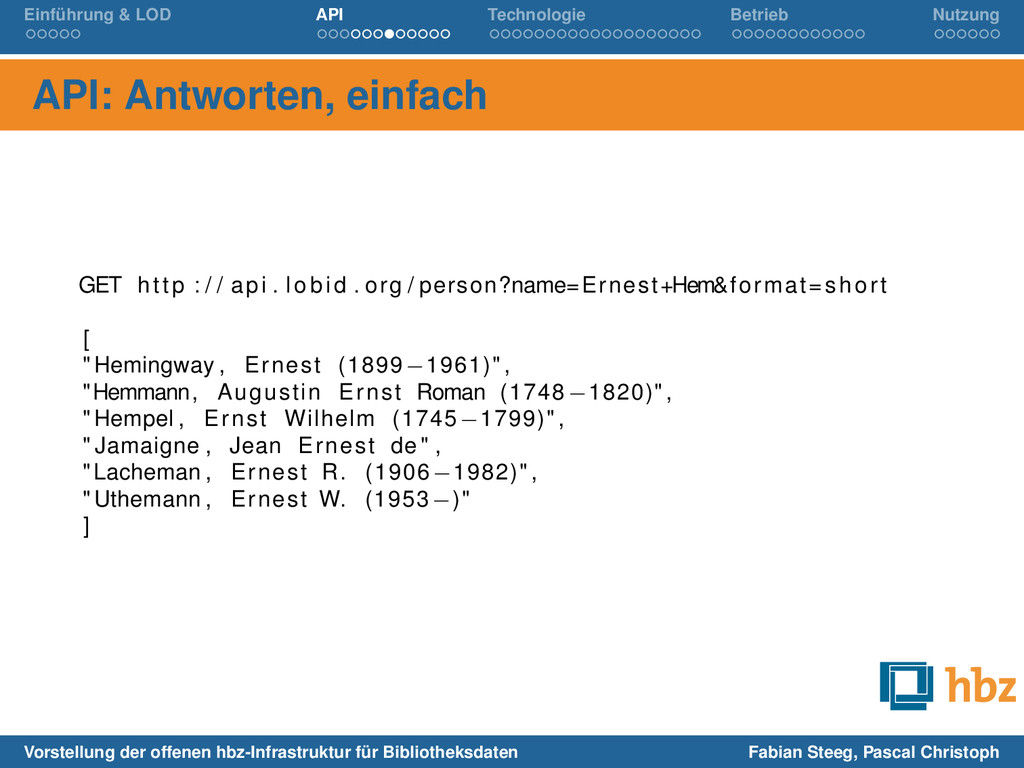
GET http : / / api . lobid . org / person?name=Ernest+Hem&format=short [ "Hemingway , Ernest (1899 −1961)" , "Hemmann, Augustin Ernst Roman (1748 −1820)" , "Hempel , Ernst Wilhelm (1745 −1799)" , " Jamaigne , Jean Ernest de " , "Lacheman , Ernest R. (1906 −1982)" , "Uthemann , Ernest W. (1953−)" ] Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
So gezielt Daten rausziehen und effizient nutzen: CC-0, Wikimedia Commons, File:Flügelspinnmaschine.jpeg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
GET http : / / api . lobid . org / person?name=Loki+Schmidt&format= f u l l [ { " g n d I d e n t i f i e r " : "118836617" " preferredNameForThePerson " : " Schmidt , Hannelore " , " variantNameForThePerson " : [ " Glaser , Hannelore " , " Schmidt , Loki " ] , " dateOfBirth " : "1919" , " dateOfDeath " : "2010" , . . . @context : " http : / / api . lobid . org / context / gnd . json " } ] Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
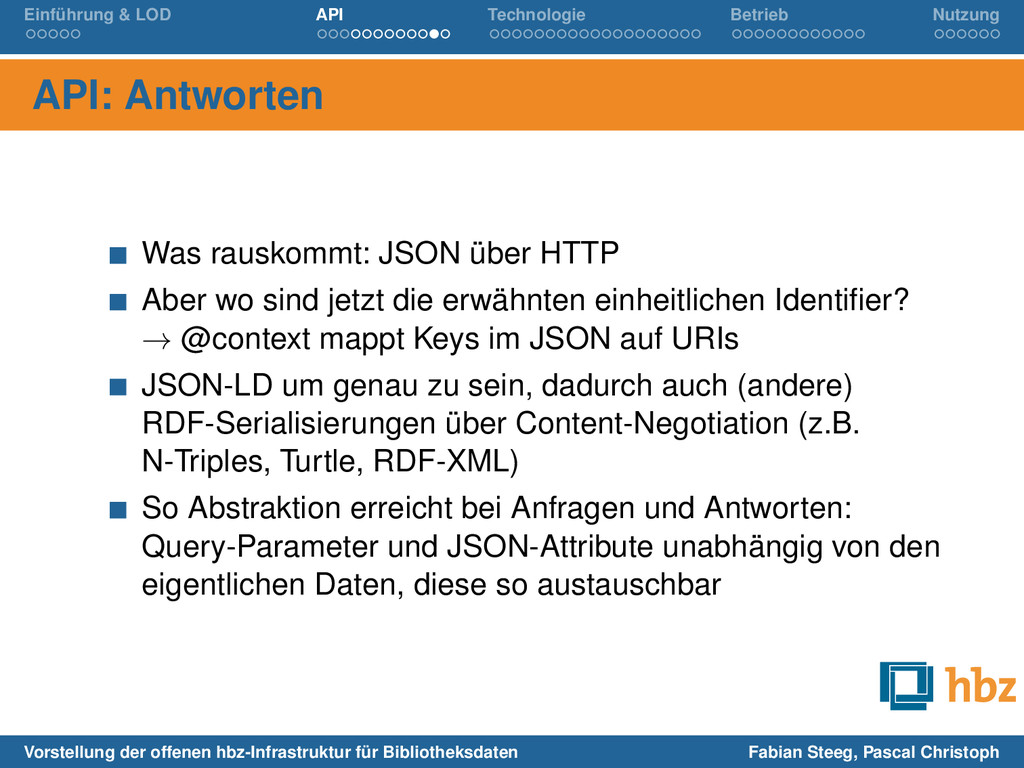
rauskommt: JSON über HTTP Aber wo sind jetzt die erwähnten einheitlichen Identifier? → @context mappt Keys im JSON auf URIs JSON-LD um genau zu sein, dadurch auch (andere) RDF-Serialisierungen über Content-Negotiation (z.B. N-Triples, Turtle, RDF-XML) So Abstraktion erreicht bei Anfragen und Antworten: Query-Parameter und JSON-Attribute unabhängig von den eigentlichen Daten, diese so austauschbar Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Dokumentation zu Content-Negotiation, Auto-Suggest use-cases, etc: http://api.lobid.org Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
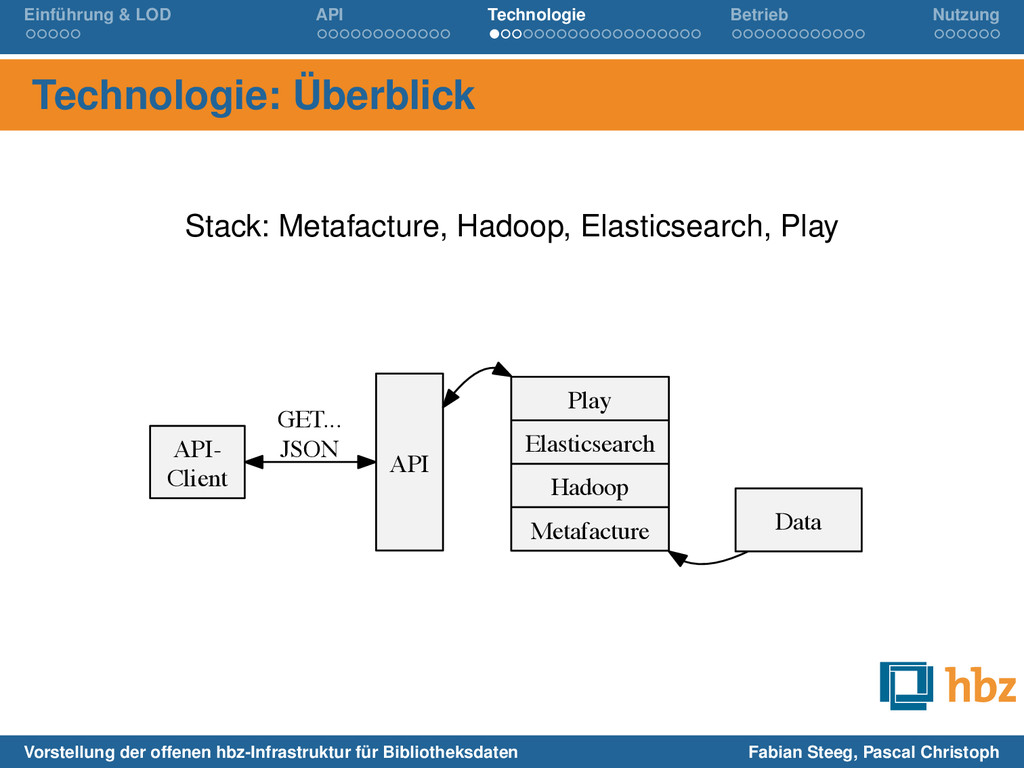
Metafacture, Hadoop, Elasticsearch, Play API- Client API GET... JSON Play Elasticsearch Hadoop Metafacture Data Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
wie, um in der Textilmetapher zu bleiben: CC-BY-2.0 Angela Montillon, Wikimedia Commons, File:Colourful_wool_2.jpg CC-BY-SA-3.0 Ryj, derivative: Derwok, Wikimedia Commons, File:Kette_und_Schuß_num_col.png CC-BY-2.0 Tony Hisgett, Wikimedia Commons, File:Coloured_cloth_2_(3539454254).jpg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
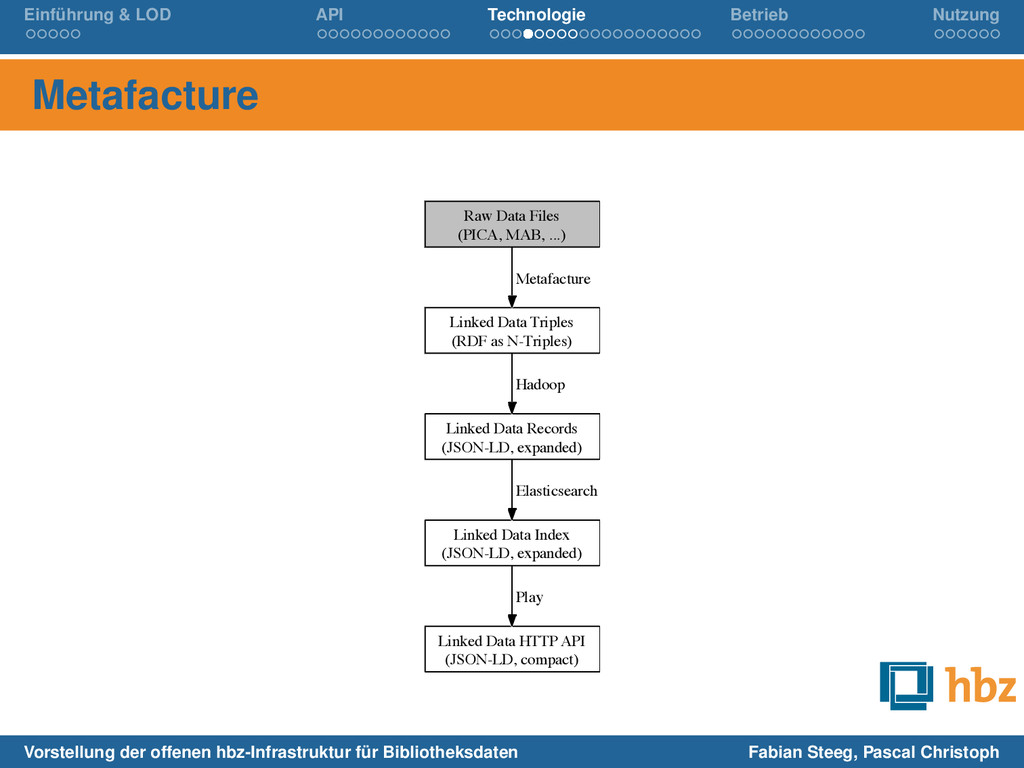
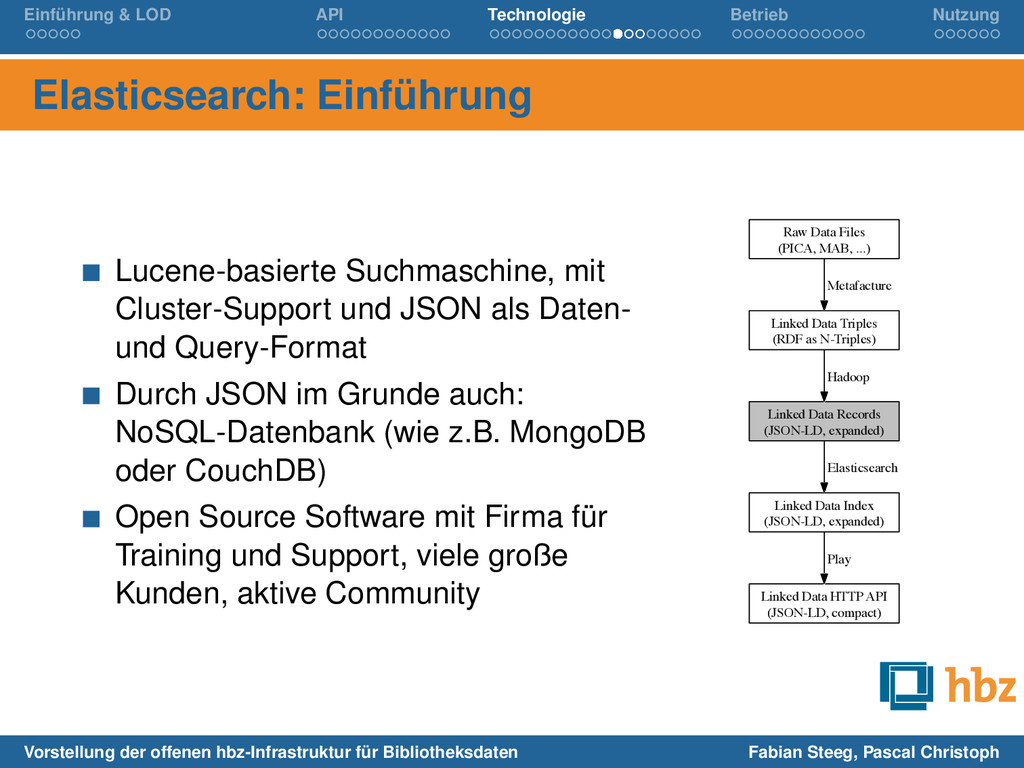
Rohdaten zu N-Triples: Metafacture & IDE (Java, XML, Workflow-DSL) Auflösung, Anreicherung und JSON-LD-Konvertierung mit Hadoop Indexierung in Elasticsearch (Lucene/Java, JSON für Queries und Daten) HTTP-API mit Play-Framework (Java, Scala als Template-Sprache) Raw Data Files (PICA, MAB, ...) Linked Data Triples (RDF as N-Triples) Metafacture Linked Data Records (JSON-LD, expanded) Hadoop Linked Data Index (JSON-LD, expanded) Elasticsearch Linked Data HTTP API (JSON-LD, compact) Play Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Files (PICA, MAB, ...) Linked Data Triples (RDF as N-Triples) Metafacture Linked Data Records (JSON-LD, expanded) Hadoop Linked Data Index (JSON-LD, expanded) Elasticsearch Linked Data HTTP API (JSON-LD, compact) Play Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Metadaten-Transformation (im Culturegraph-Projekt entstanden) Ein Kerngedanke: Mapping ist nur ein Arbeitsschritt von vielen (z.B. Einlesen, Rausschreiben) Mapping getrennt von Eingabe- und Ausgabeformat: Attribut-Wert-Paare werden zu Attribut-Wert-Paaren (’Morph-Datei’, XML) Verschiedene Input-Formate unterstützt (MAB, MARC, METS, etc.) und um eigene erweiterbar Verschiedene Output-Formate unterstützt und um eigene erweiterbar (wir haben z.B. einen N-Triple-Encoder geschrieben) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
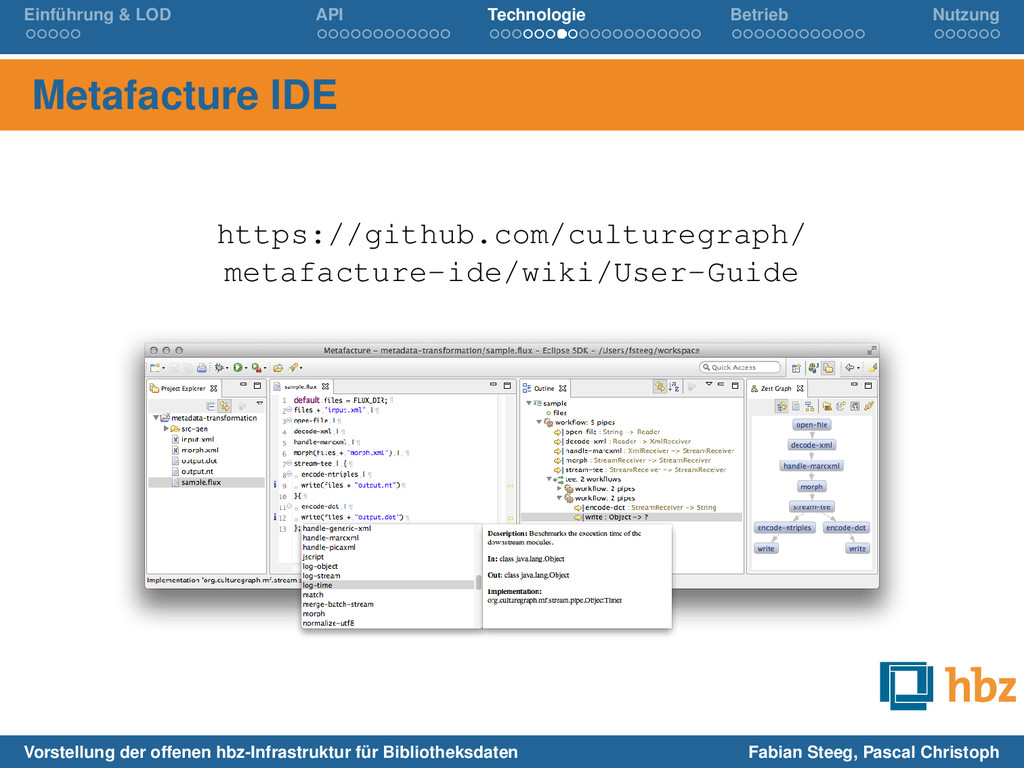
von Eingabe, Transformationsregeln und Ausgabe bildet den Workflow der Transformation Der Workflow wird mit Flux, einer einfachen domänenspezifischen Sprache (DSL) deklariert Wir arbeiten an Tools zum einfachen Editieren und Ausführen der Flux-Dateien (Metafacture IDE) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
von Eingabe- und Ausgabeformat getrennt (so z.B. Input von MARC-21 und MARC-XML austauschbar) Stream-basiert und dadurch sehr schnell Flexibles, komplett erweiterbares Framework Nachvollziehbare, deklarative Definition der Transformation in Morph- und Flux-Dateien (z.B. für Doku, Veröffentlichung, Austausch) http://culturegraph.github.com Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
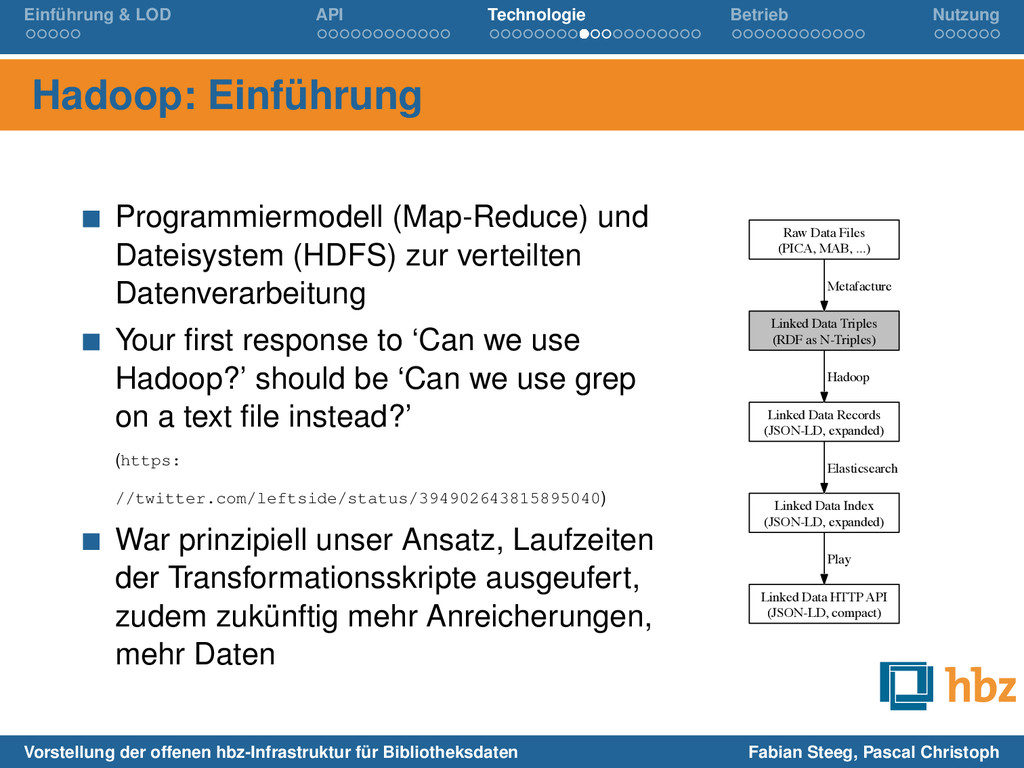
(Map-Reduce) und Dateisystem (HDFS) zur verteilten Datenverarbeitung Your first response to ‘Can we use Hadoop?’ should be ‘Can we use grep on a text file instead?’ (https: //twitter.com/leftside/status/394902643815895040) War prinzipiell unser Ansatz, Laufzeiten der Transformationsskripte ausgeufert, zudem zukünftig mehr Anreicherungen, mehr Daten Raw Data Files (PICA, MAB, ...) Linked Data Triples (RDF as N-Triples) Metafacture Linked Data Records (JSON-LD, expanded) Hadoop Linked Data Index (JSON-LD, expanded) Elasticsearch Linked Data HTTP API (JSON-LD, compact) Play Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
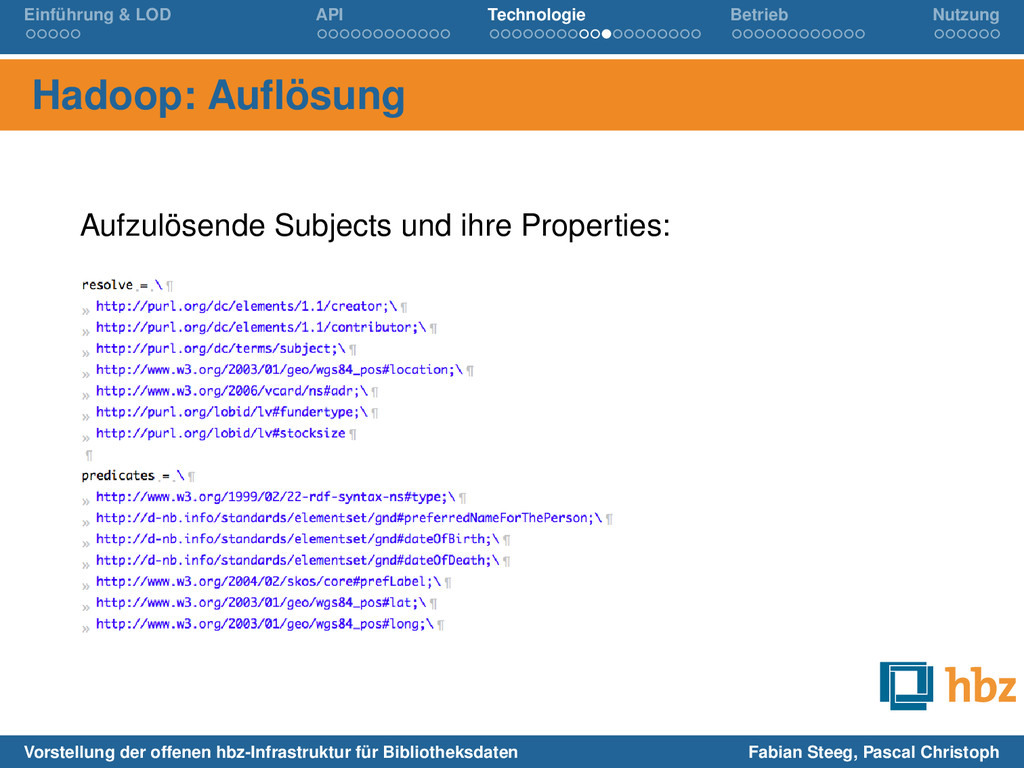
im Prinzip zeilenbasiert → N-Triples als Input Startpunkt: N-Triples im HDFS (unsere und alle externe, z.B. GND, Dewey) Ziel: von LD Triples zu LD Records (JSON-LD) d.h. Triples sammeln und mit Normdaten zu sinnvollen Records zusammenführen (z.B. Autorennamen integrieren) Details: https://github.com/lobid/lodmill Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Suchmaschine, mit Cluster-Support und JSON als Daten- und Query-Format Durch JSON im Grunde auch: NoSQL-Datenbank (wie z.B. MongoDB oder CouchDB) Open Source Software mit Firma für Training und Support, viele große Kunden, aktive Community Raw Data Files (PICA, MAB, ...) Linked Data Triples (RDF as N-Triples) Metafacture Linked Data Records (JSON-LD, expanded) Hadoop Linked Data Index (JSON-LD, expanded) Elasticsearch Linked Data HTTP API (JSON-LD, compact) Play Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
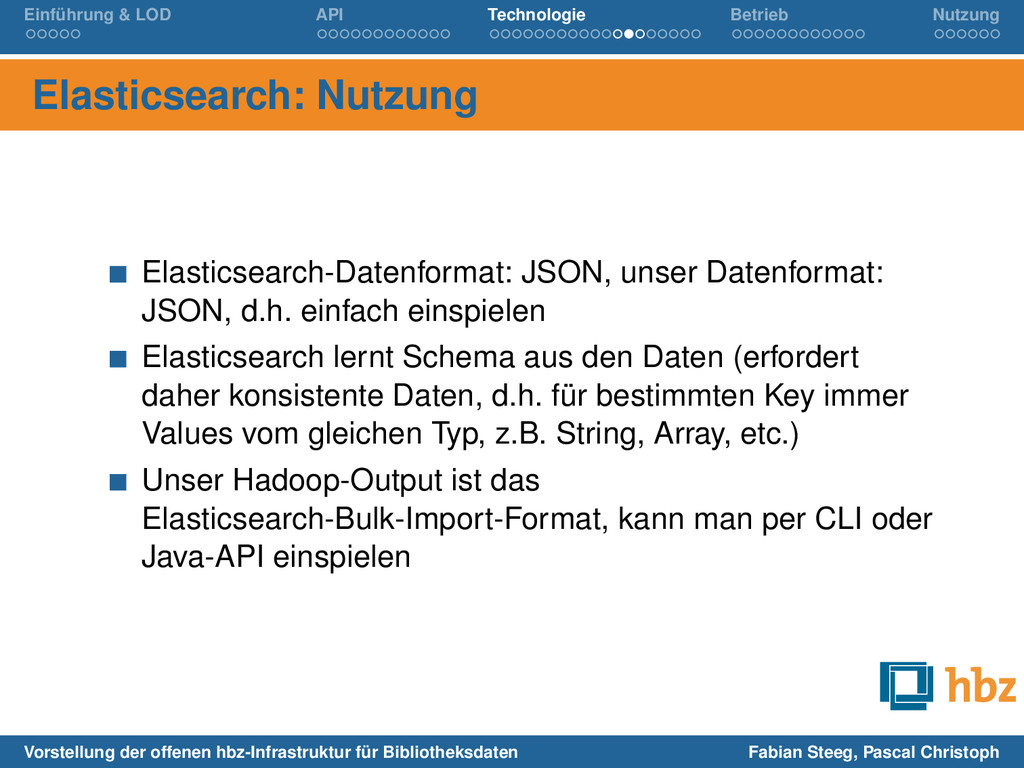
JSON, unser Datenformat: JSON, d.h. einfach einspielen Elasticsearch lernt Schema aus den Daten (erfordert daher konsistente Daten, d.h. für bestimmten Key immer Values vom gleichen Typ, z.B. String, Array, etc.) Unser Hadoop-Output ist das Elasticsearch-Bulk-Import-Format, kann man per CLI oder Java-API einspielen Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
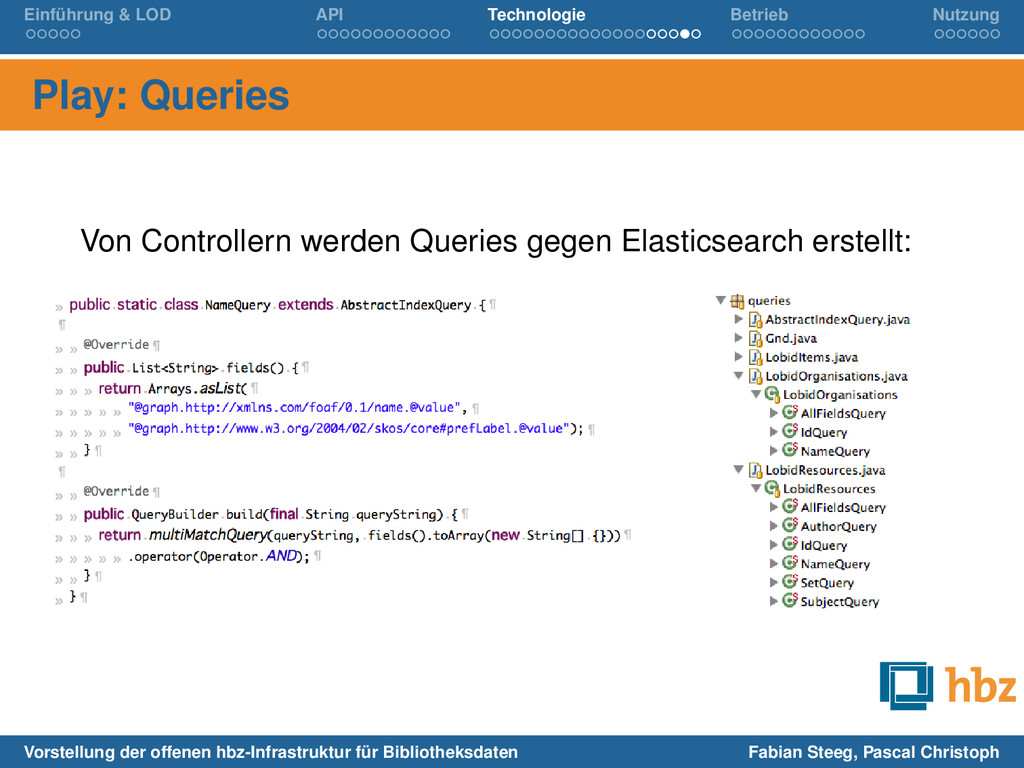
Analyzer (für Auto-Suggest) Such-DSL für flexible Anfragen (Wildcards, Fuzzy, spezifische Felder, etc.) Weitere interessante Features: Geosuche mit Ranking nach Entfernung, Facettierung, Datenanalyse, etc. Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
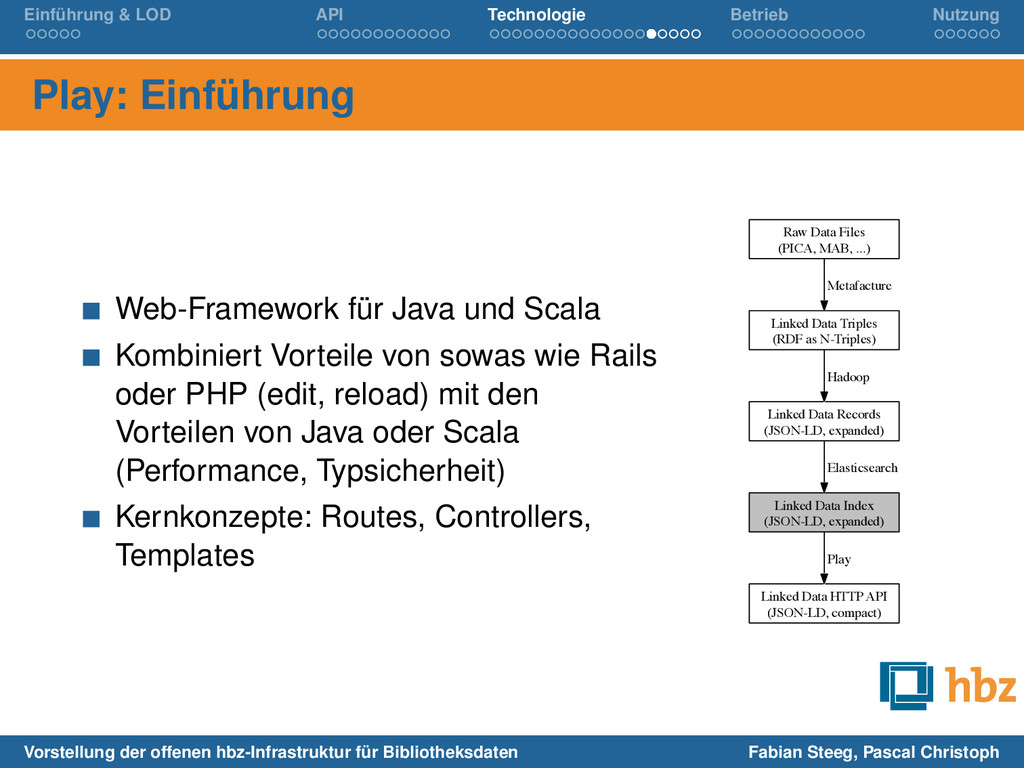
für Java und Scala Kombiniert Vorteile von sowas wie Rails oder PHP (edit, reload) mit den Vorteilen von Java oder Scala (Performance, Typsicherheit) Kernkonzepte: Routes, Controllers, Templates Raw Data Files (PICA, MAB, ...) Linked Data Triples (RDF as N-Triples) Metafacture Linked Data Records (JSON-LD, expanded) Hadoop Linked Data Index (JSON-LD, expanded) Elasticsearch Linked Data HTTP API (JSON-LD, compact) Play Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
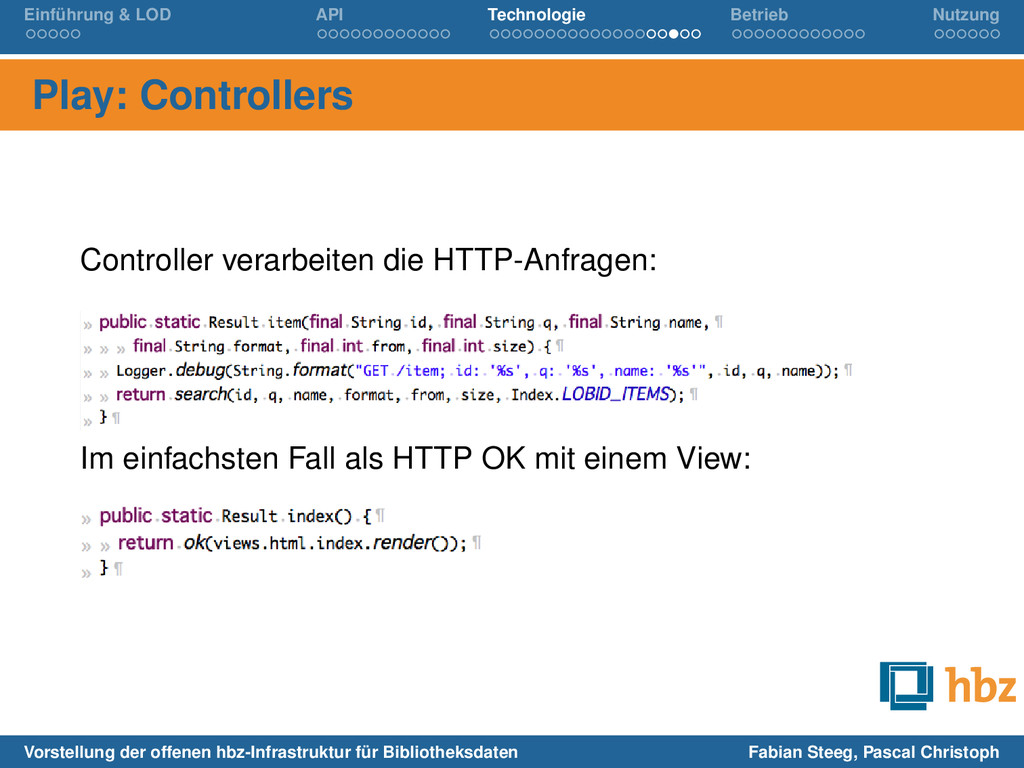
verarbeiten die HTTP-Anfragen: Im einfachsten Fall als HTTP OK mit einem View: Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
generieren HTML-Views: Erlauben selbst definierte Module (hier: ‘@rdfa‘) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
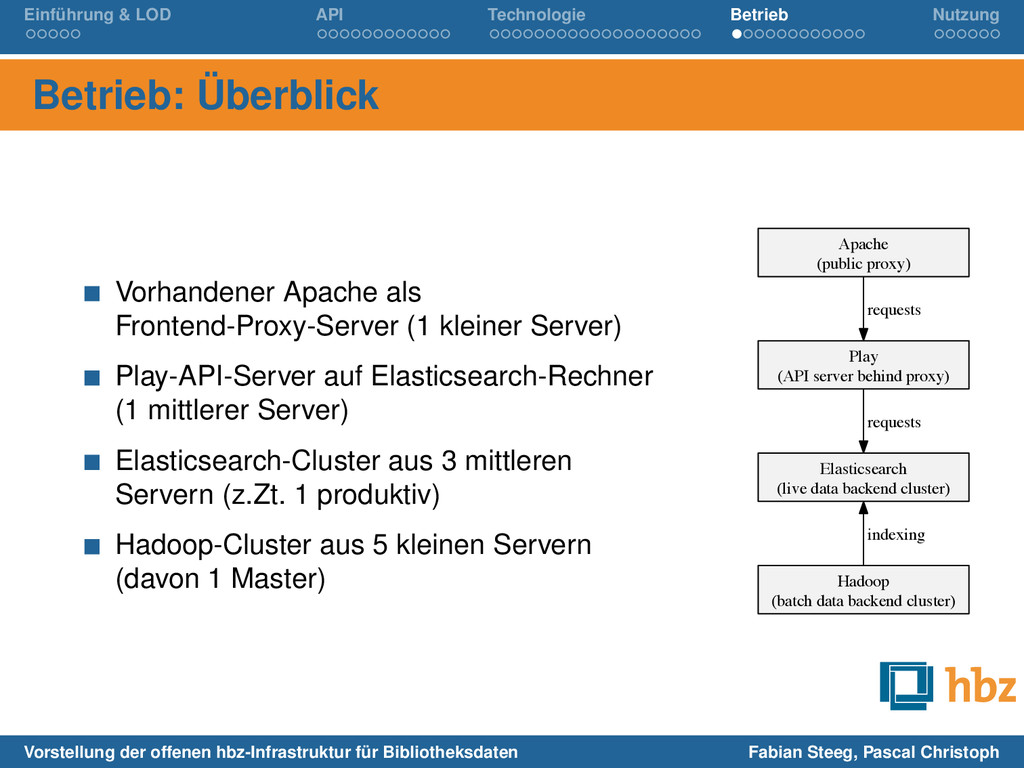
Apache als Frontend-Proxy-Server (1 kleiner Server) Play-API-Server auf Elasticsearch-Rechner (1 mittlerer Server) Elasticsearch-Cluster aus 3 mittleren Servern (z.Zt. 1 produktiv) Hadoop-Cluster aus 5 kleinen Servern (davon 1 Master) Apache (public proxy) Play (API server behind proxy) requests Elasticsearch (live data backend cluster) requests Hadoop (batch data backend cluster) indexing Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Aleph-Verbundkatalog bekommen wir jährliche Volldumps (18 M Datensätze) und tägliche Updates (bis zu 100k Datensätze) Hatten deshalb auch als LOD: Base-Dump + Updates → alles in einen Topf (in Hadoop): doppelte Records Ziel: vereinfachen, immer einen aktuellen Vollabzug als vollständiger, aktueller Stand Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
1 File pro Record im Dateisystem, alte Dateien werden durch neue überspielt Pro: Tagesaktueller Volldump, direkter Zugriff auf aktuelle Datensätze, Grundlage für zukünftige Versionierung Contra: recht langsam, da viele kleine einzelne Dateien, sollten wir langfristig anders speichern Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
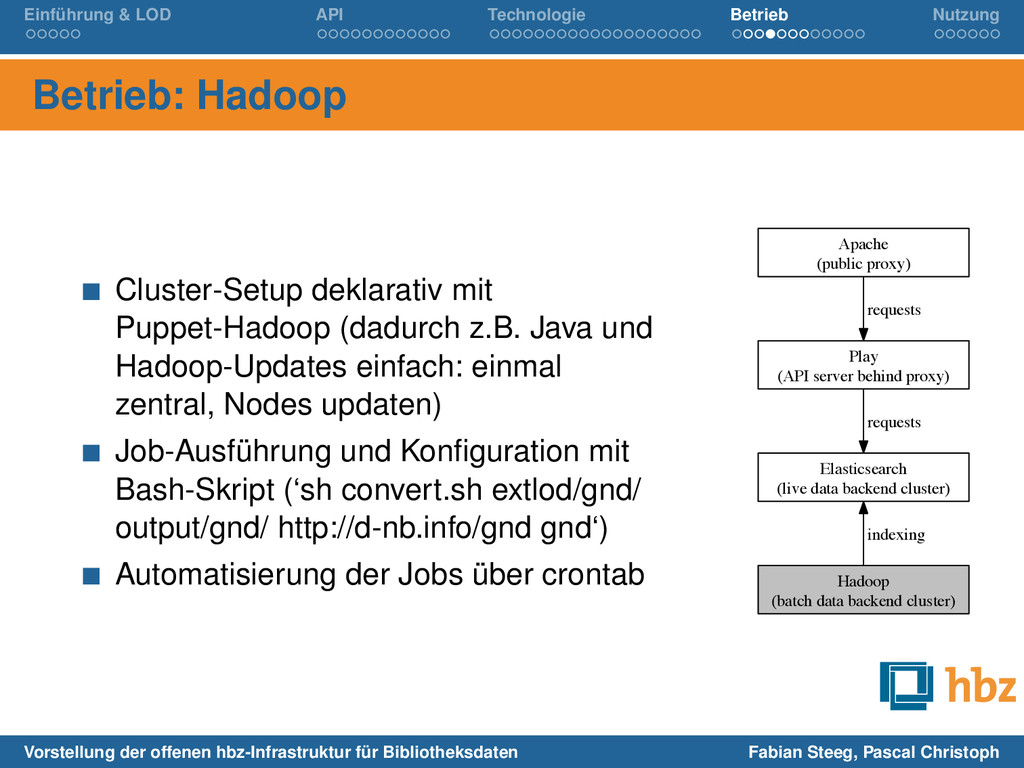
deklarativ mit Puppet-Hadoop (dadurch z.B. Java und Hadoop-Updates einfach: einmal zentral, Nodes updaten) Job-Ausführung und Konfiguration mit Bash-Skript (‘sh convert.sh extlod/gnd/ output/gnd/ http://d-nb.info/gnd gnd‘) Automatisierung der Jobs über crontab Apache (public proxy) Play (API server behind proxy) requests Elasticsearch (live data backend cluster) requests Hadoop (batch data backend cluster) indexing Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
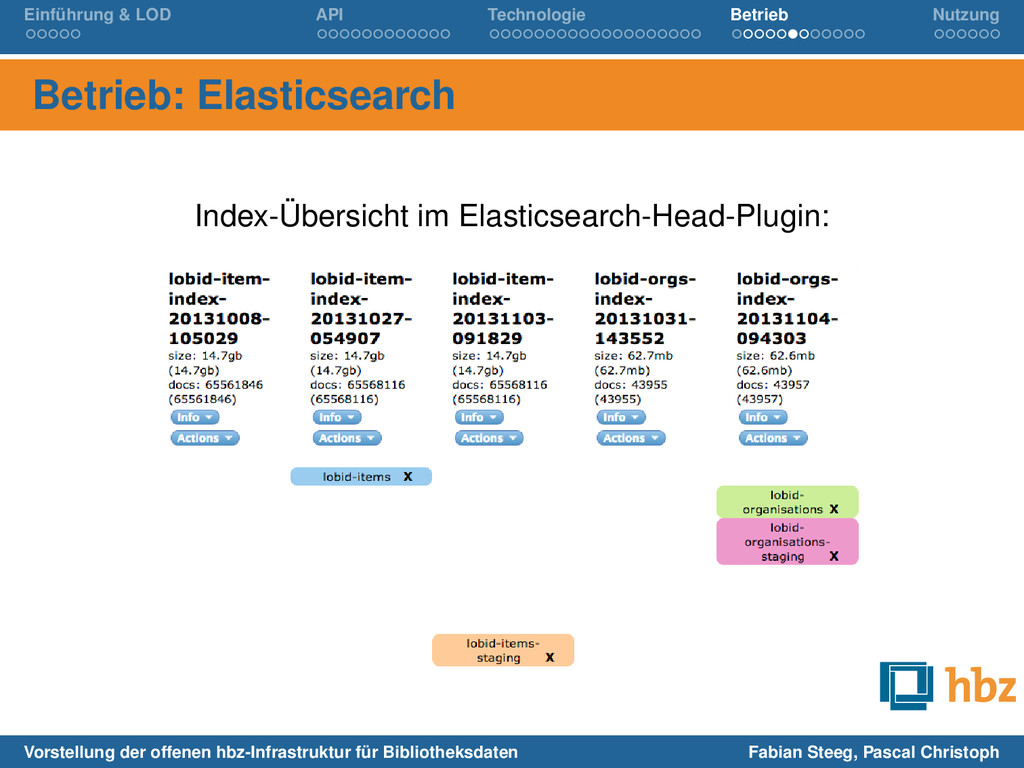
mit Bash-Skript (‘sh index.sh output/gnd/ 193.30.112.170 quaoar‘) Alter Index unverändert, erzeugen immer neuen Index, testen erst mit Staging-System Index-Wechsel (Staging, Production) ohne Restart über Index-Alias in Elasticsearch head-plugin Behalten immer einen alten Index für einfachen Revert bei Problemen mit neuem Index Apache (public proxy) Play (API server behind proxy) requests Elasticsearch (live data backend cluster) requests Hadoop (batch data backend cluster) indexing Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
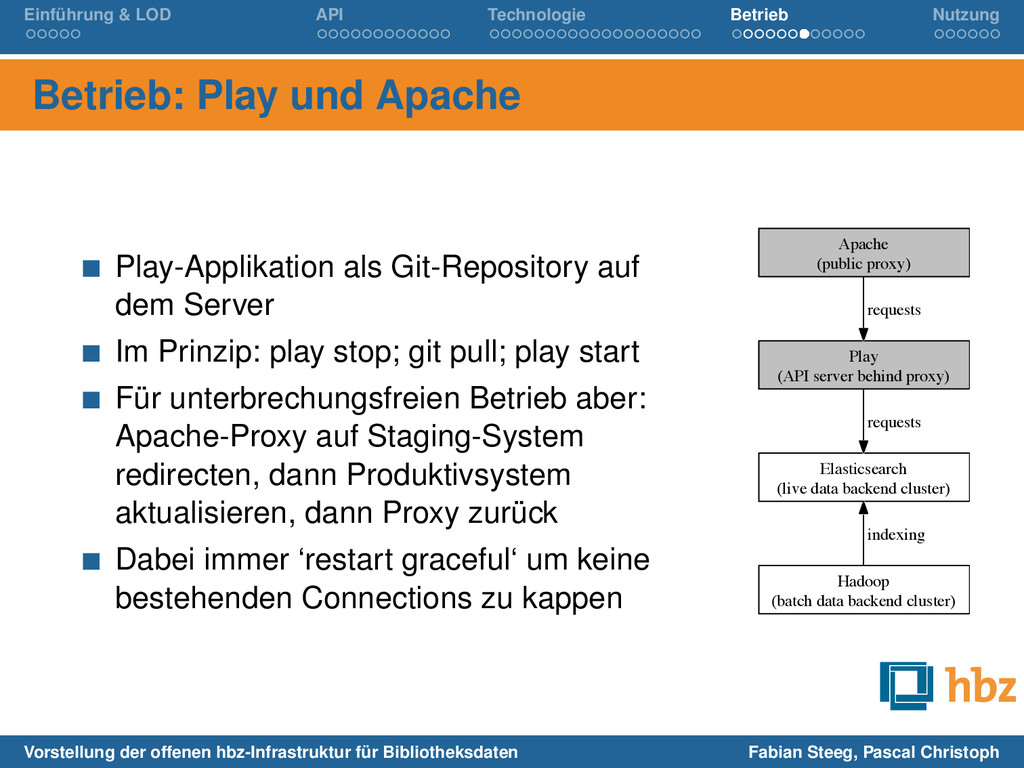
Apache Play-Applikation als Git-Repository auf dem Server Im Prinzip: play stop; git pull; play start Für unterbrechungsfreien Betrieb aber: Apache-Proxy auf Staging-System redirecten, dann Produktivsystem aktualisieren, dann Proxy zurück Dabei immer ‘restart graceful‘ um keine bestehenden Connections zu kappen Apache (public proxy) Play (API server behind proxy) requests Elasticsearch (live data backend cluster) requests Hadoop (batch data backend cluster) indexing Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
mögen Stack: Metafacture, Hadoop, Elasticsearch, Play Einfacher Ausbau und Anpassung von Auflösungen, Queries und Views JSON-LD, speziell Kontext-Dokument Daten-Updates und Index-Switching ohne System-Neustart Elasticsearch-Performance (bisher zwar wenig Last, aber auch nur 1/3 Servern in Betrieb) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
nicht so mögen Manuelles Deployment und Index-Alias-Updates Langer Feedback-Zyklus bei grösseren Transformationen (alle Daten nach JSON-LD und indexieren ca. 12 Stunden, Konvertierung der Rohdaten in N-Triples wegen vielen kleinen Files je nach Update-Größe noch länger) Alte Transformationen (alte Skripte etc.) bisher noch als parallele Schiene (stellen alles auf Metafacture um, das soll künftig auch im Hadoop-Cluster passieren) Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
sind also noch nicht ganz hier: CC-BY-3.0 Clem Rutter, Wikimedia Commons, File:Ring_spinning_frame_MOSI_Textile_Hall_6412.JPG Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
immerhin vielleicht etwa hier: CC-BY-2.0 David Wilmot, Wikimedia Commons, File:Wool_Spinning.jpg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
jeden Fall viel weiter als hier: CC-BY-2.0 Angela Montillon, Wikimedia Commons, File:Colourful_wool_2.jpg Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
zur Archivierung elektronischer Dokumente und Websites), u.A. zur Autovervollständigung von Autoren in Drupal-basierter Katalogisierungsobefläche lobid.org: /resource, /organisations, /item von Phresnel auf API umgestellt 2014: Neuer NWBib-Auftritt auf Basis der API In Kontakt mit: openBiblioJobs, ULB Bonn, GBV, und natürlich hier, Münster Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Leute dran gelassen, erstes Feedback zur grundsätzlichen Struktur der API Früh als public beta extern Leute dran gelassen, viel wertvolles Feedback Man kann selbst nicht antizipieren was User wollen, iterieren hat für uns gut geklappt Zwei konkrete Beispiele: Suche über alle Felder und Konfigurationsoption für Auto-Suggest-Format Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
z.B. eigene Labels für alle Auto-Suggest-Formate Mehr Integration, z.B. API als OpenRefine reconciliation service Mehr Daten, z.B. /subject analog zu /person, komplette /gnd, neue Quellen für /organisation Details und Planung: https://github.com/lobid/lodmill/issues Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
offen: Code ist Open Source, Software modular (speziell Metafacture) Organisatorisch offen: Issues, CI, Reviews, Wiki auf GitHub: http://github.com/lobid/lodmill API offen: http://api.lobid.org Wir freuen uns über Nutzung, Feedback, und Contributions Spezieller Vibe aktuell: Dresden, Münster, weitere: gemeinsam was Tolles aufbauen Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
We support the formation and development of an international library infrastructure that is: future-proof: it supports the development of sustainable solutions progressive: it enables rapid development and quick adaptation to upcoming challenges empowering: it empowers libraries to control to the maximum the infrastructure underlying their services for collection, indexing and dissemination of published knowledge Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
Openness, Transparency, Inclusion, Meritocracy, Reuse, Credit http://etherpad.lobid.org/p/LEM c Jaymi Heimbuch Vorstellung der offenen hbz-Infrastruktur für Bibliotheksdaten Fabian Steeg, Pascal Christoph
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}