Presented at: http://www.meetup.com/Montreal-R-User-Group/events/88570532/
We will give you a fly over of a few of the packages Hadley Wickham and his collaborators have created. Many of us now use these packages in every project we tackle and they have become an essential tool of the R enthusiast tool box. A brief tutorial providing the key features and how to implement them will be presented for each package, each followed by a hands on application exercise. Tips and trick for super users will also be provided.
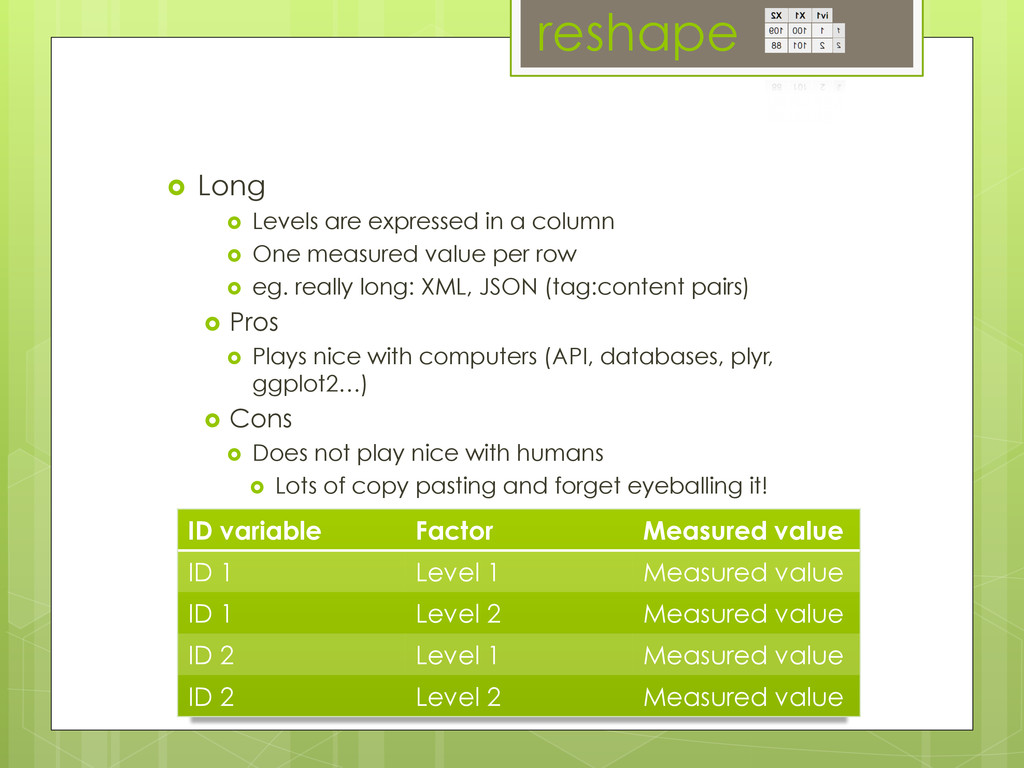
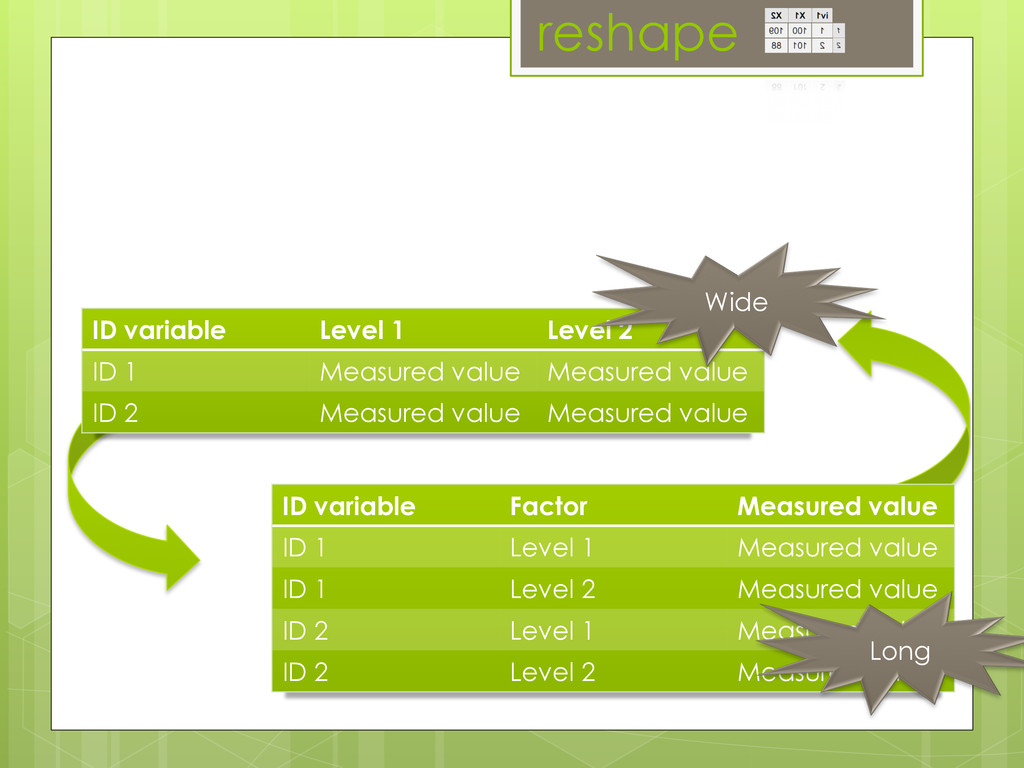
-reshape: make your data play nice (Too many columns, no problem)
-plyr: split/apply/combine (extract the slope of a linear model for each of your thousand replicates)
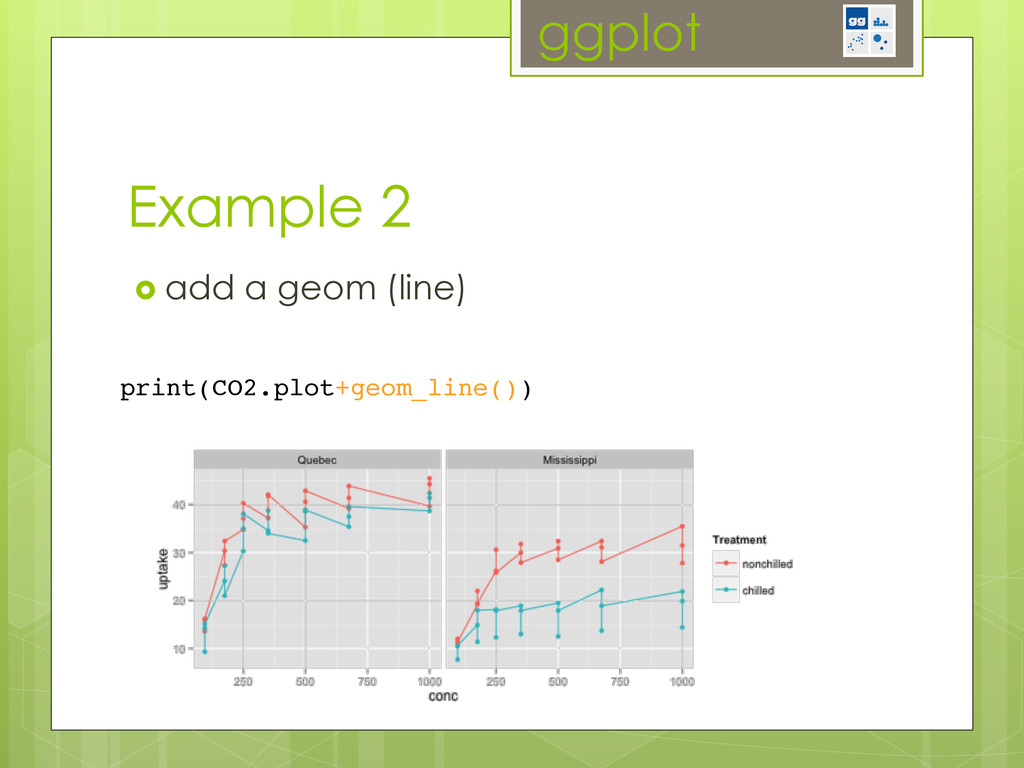
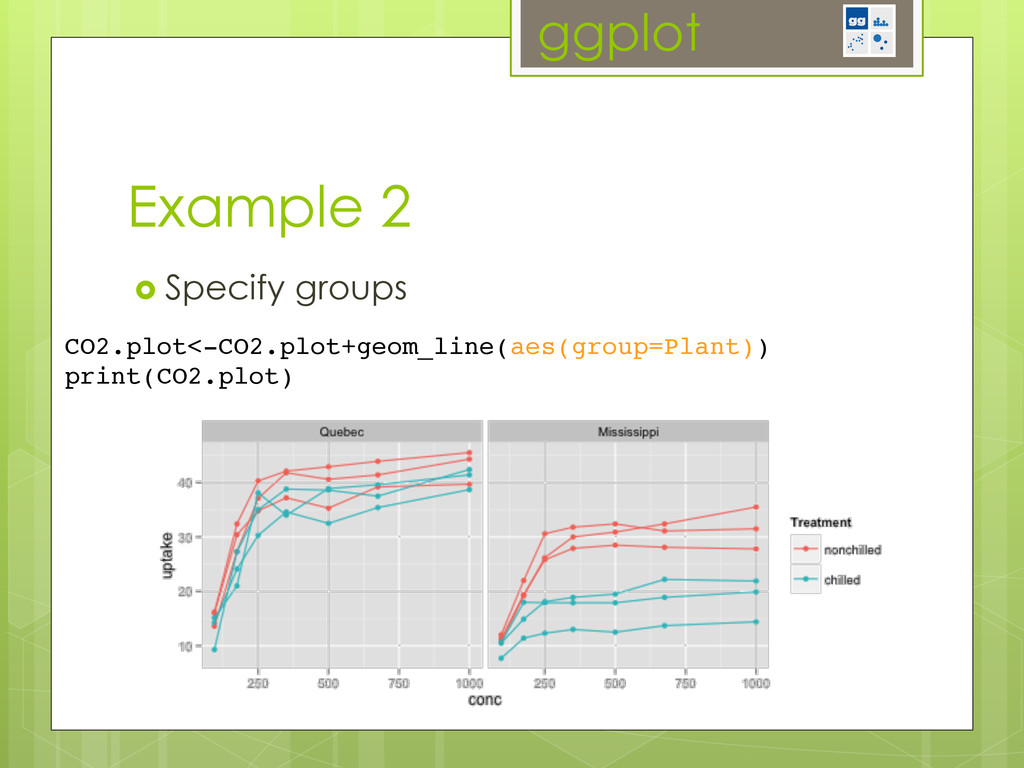
-ggplot2: the grammar of graphics (start with a basic plot and intuitively add layers of complexity)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Super user approved plyr universal plyr: coming soon dplyr data.table[,,]](https://files.speakerdeck.com/presentations/24494290115601301b3722000a9503f9/slide_52.jpg){kind=link}
{kind=link}