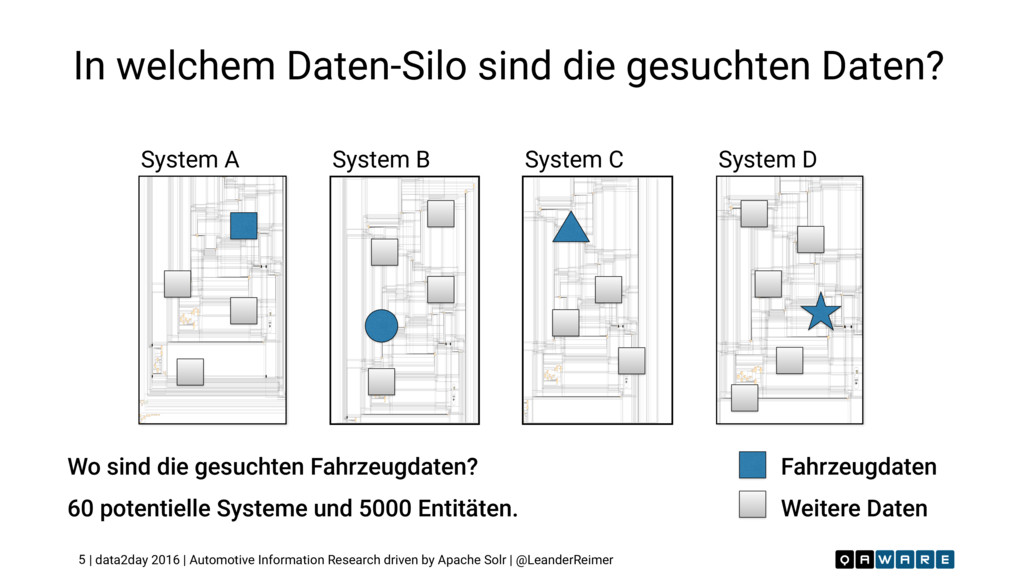
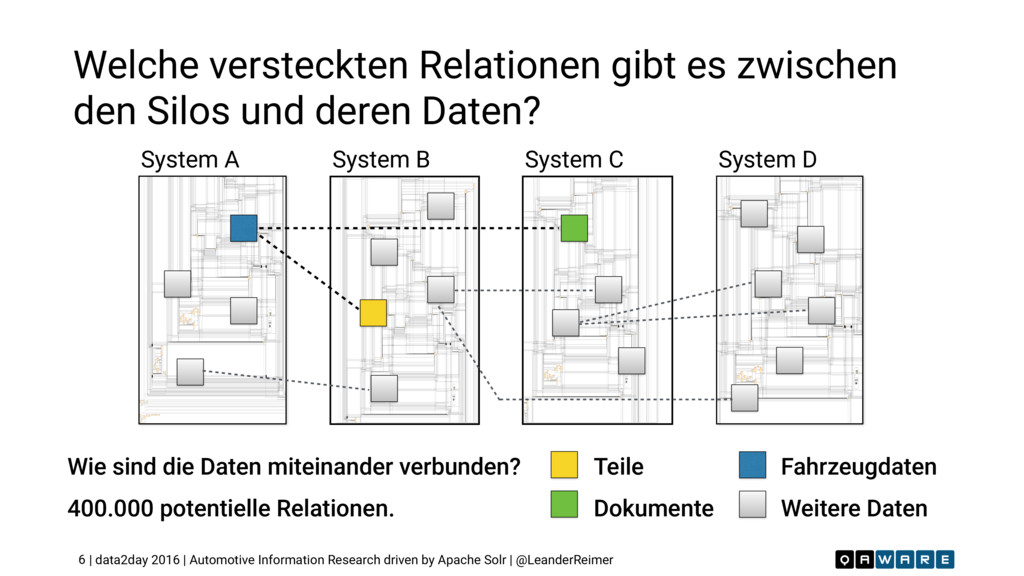
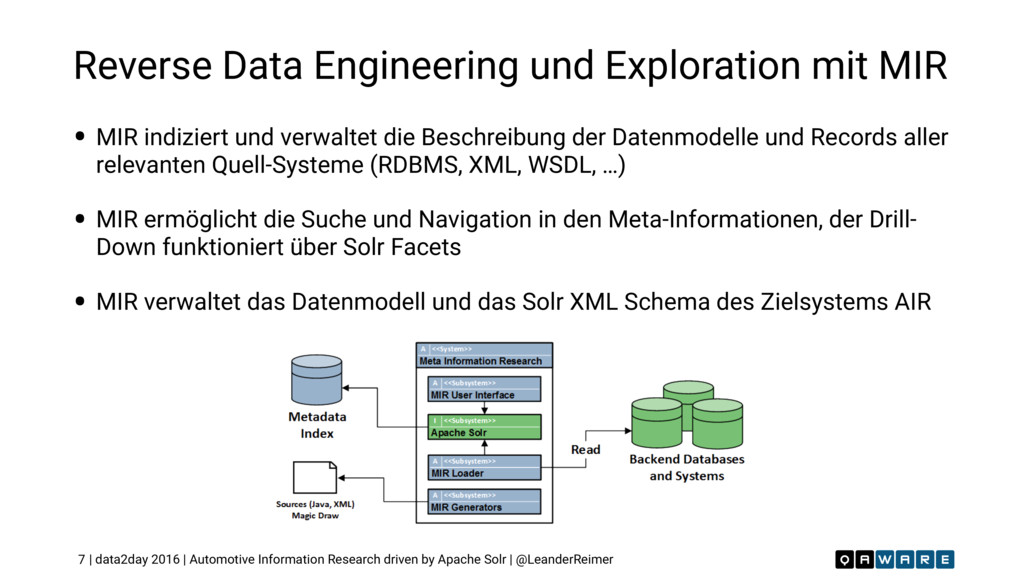
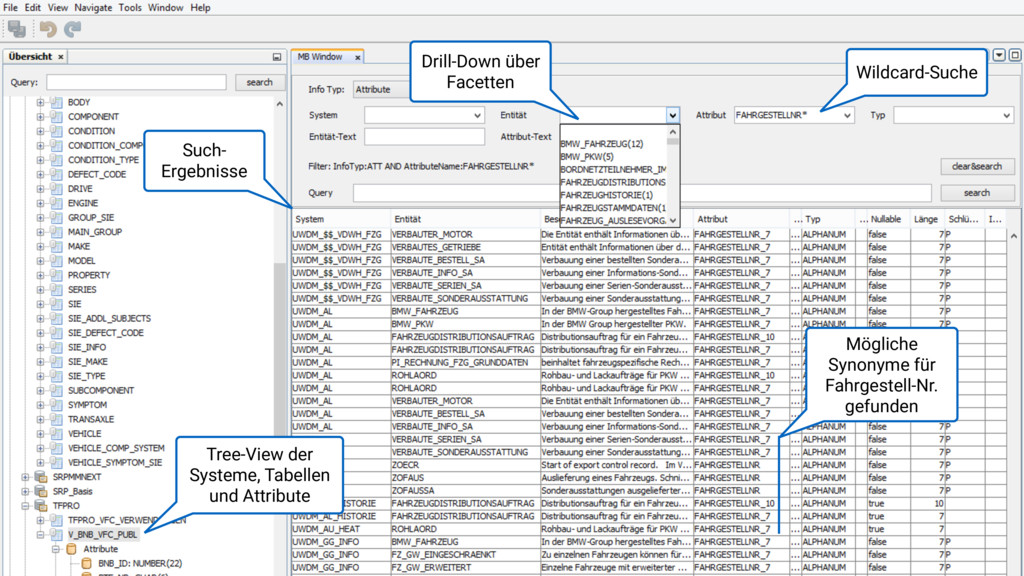
Wir suchen das Unbekannte in den unendlichen Weiten relationaler Datensilos. Wie findet man versteckte und bisher unbekannte Entitäten mit deren Beziehungen? Wie sucht man die relevanten Informationen in einem 10^56 dimensionalen Datenraum? Welche Vorteile bietet hier der Einsatz von Apache Solr als Index-Maschine und NoSQL Storage gegenüber traditionellen, relationalen Ansätzen? Wie erzeugt man ein konsistentes, täglich aktuelles Informationsnetz in über 20 Sprachen? Dieser Vortrag gibt die Antworten und präsentiert eine detaillierte Case Study wie auf Basis von Solr eine globale Informationsrecherche Applikation für einen führenden deutschen Automobilhersteller erfolgreich umgesetzt wurde. Dieser Vortrag wurde auf der #data2day 2016 in Karlsruhe gehalten.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mario-Leander Reimer Cheftechnologe, QAware GmbH [email protected] https://www.qaware.de https://slideshare.net/MarioLeanderReimer/ https://speakerdeck.com/lreimer/ https://twitter.com/leanderreimer/](https://files.speakerdeck.com/presentations/86f7994ea0374e33909de92972b263a8/slide_31.jpg){kind=link}