On parle beaucoup d’IA, mais rarement de ce qu’on peut *vraiment* en faire dans un projet PHP.
Avec Symfony AI, il devient enfin possible de manipuler des modèles d’embeddings, de génération ou de classification sans quitter son écosystème habituel.
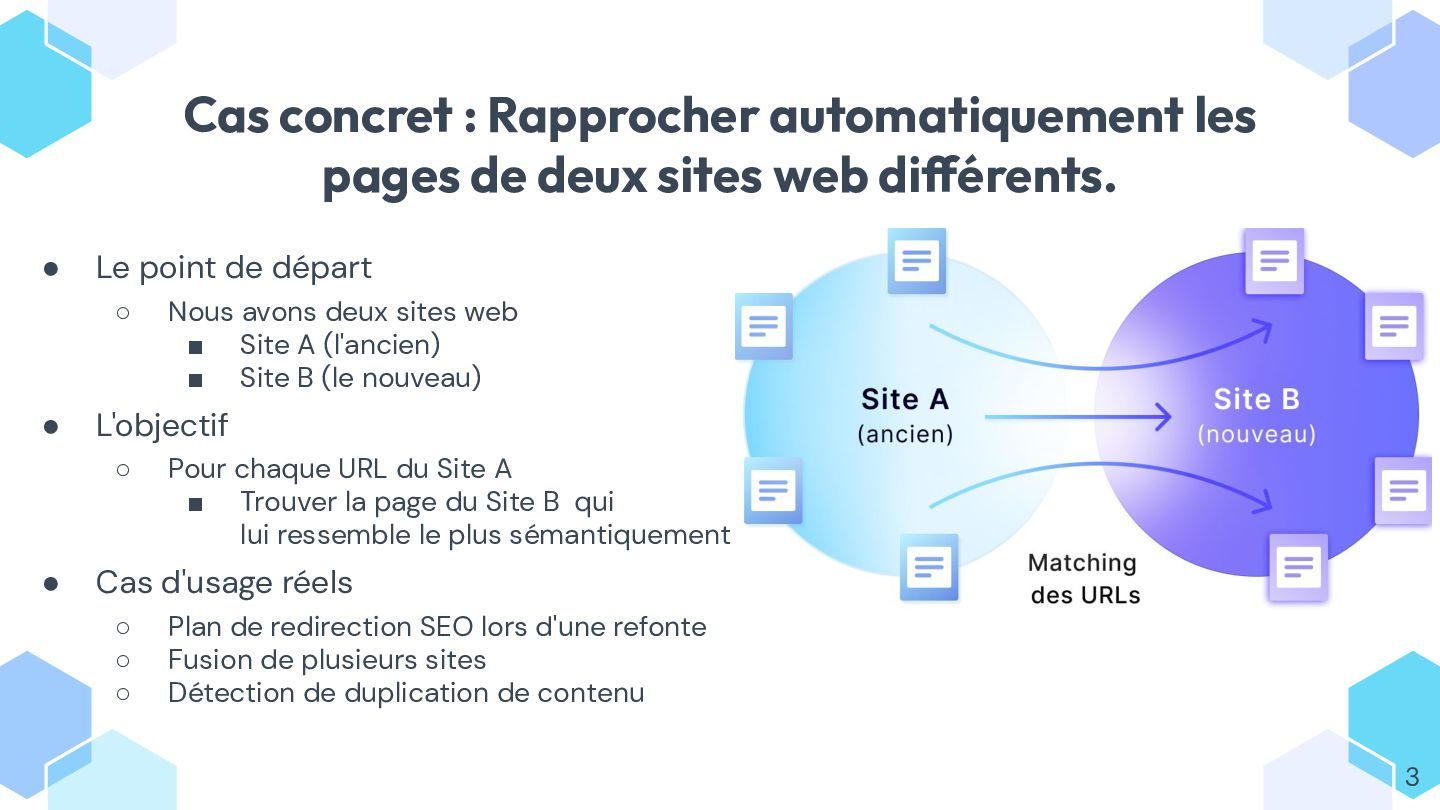
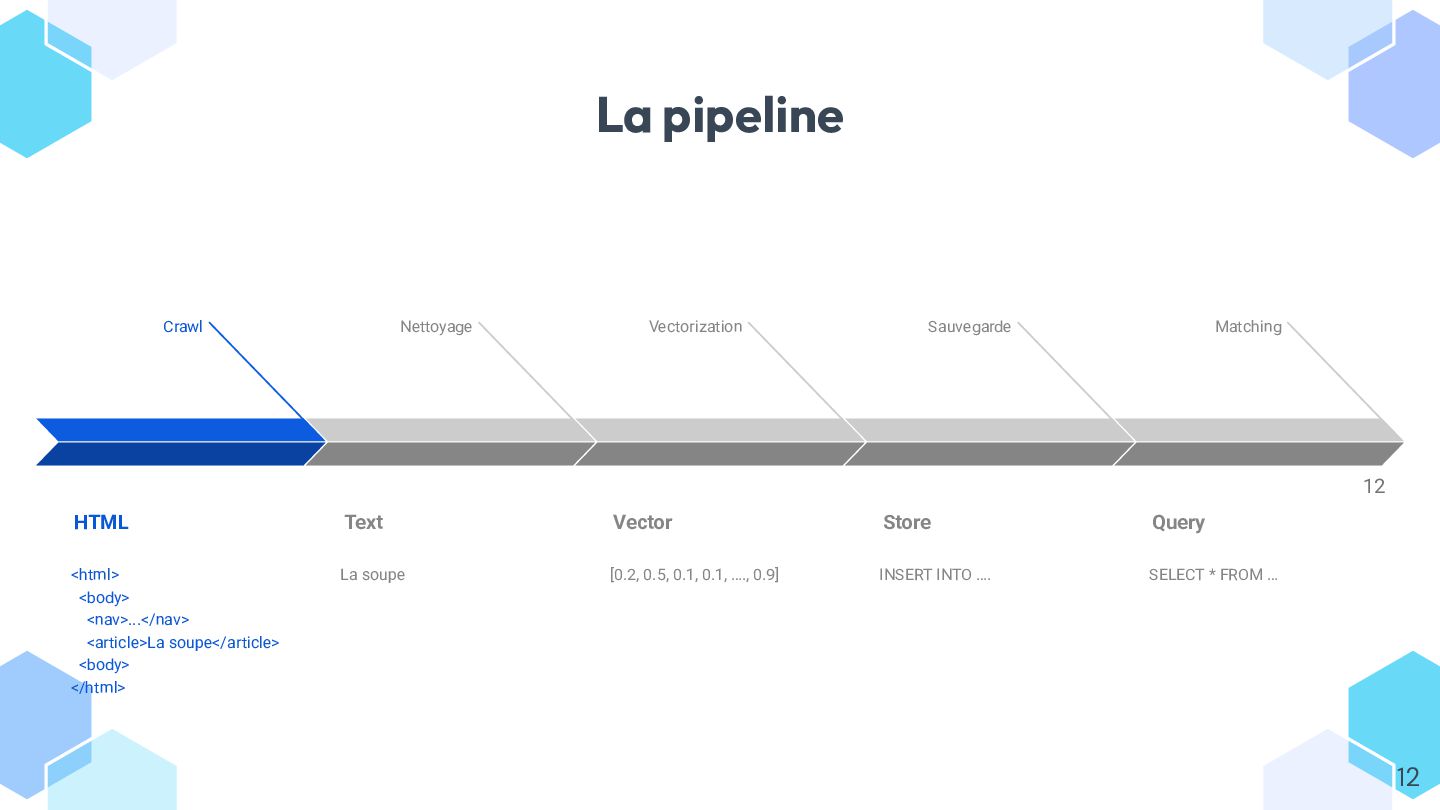
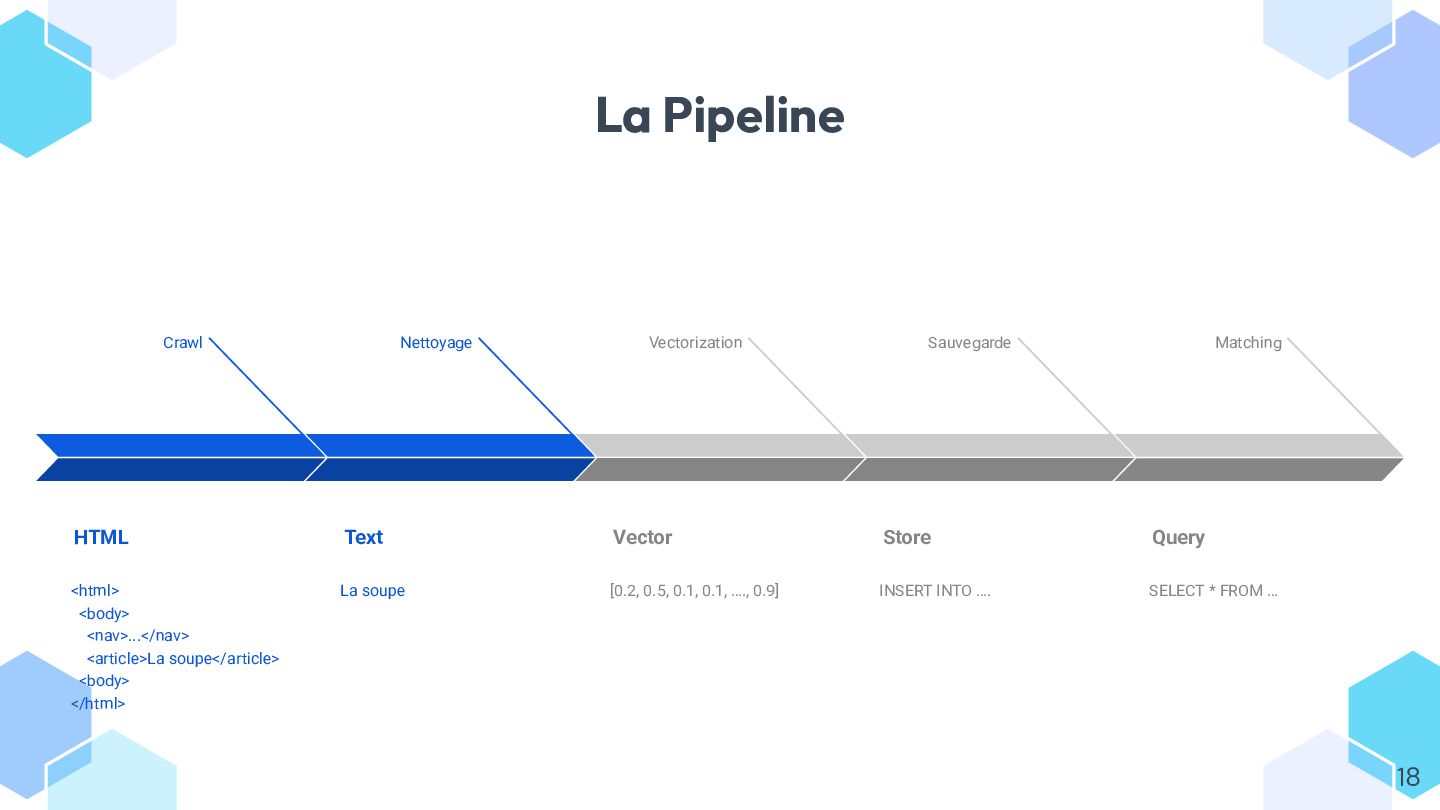
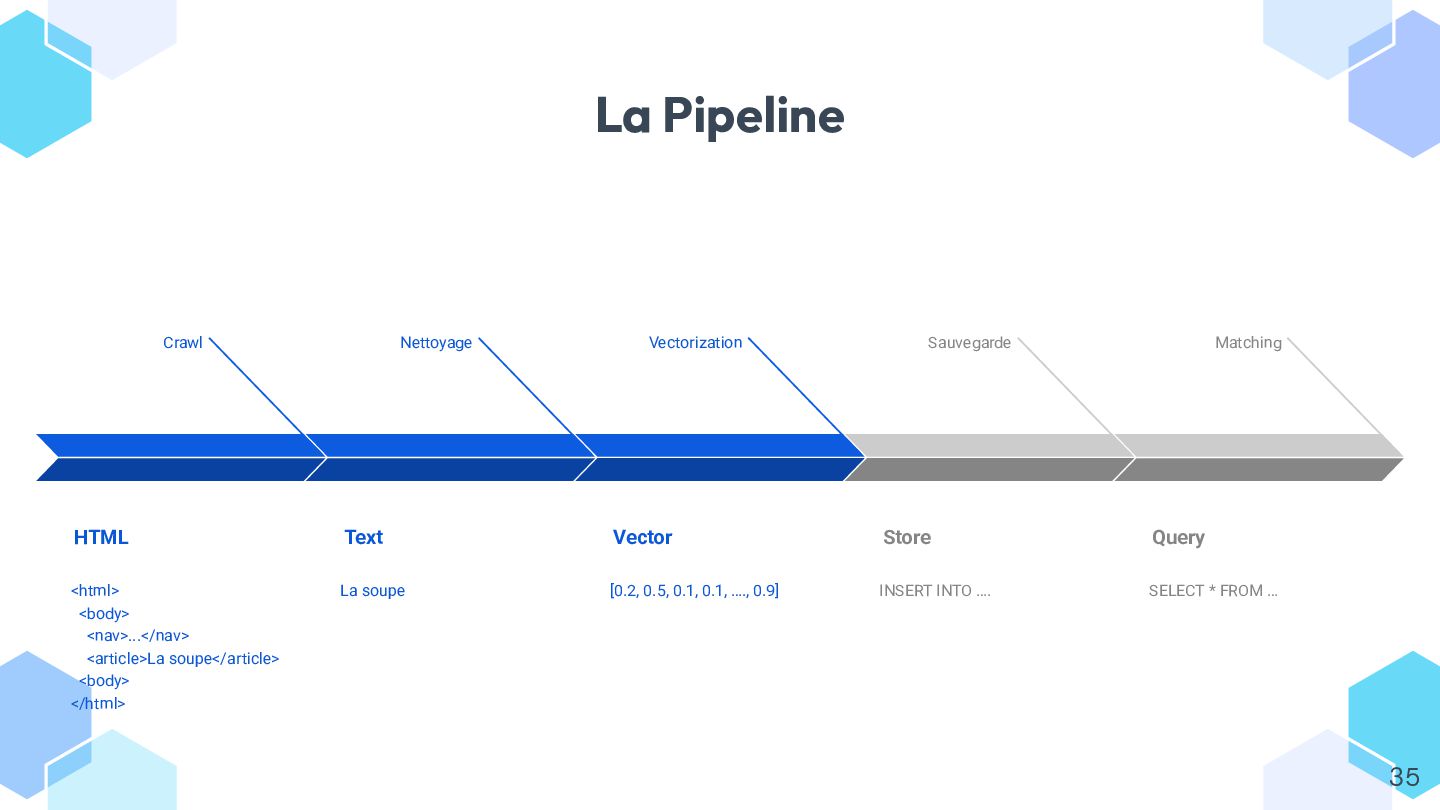
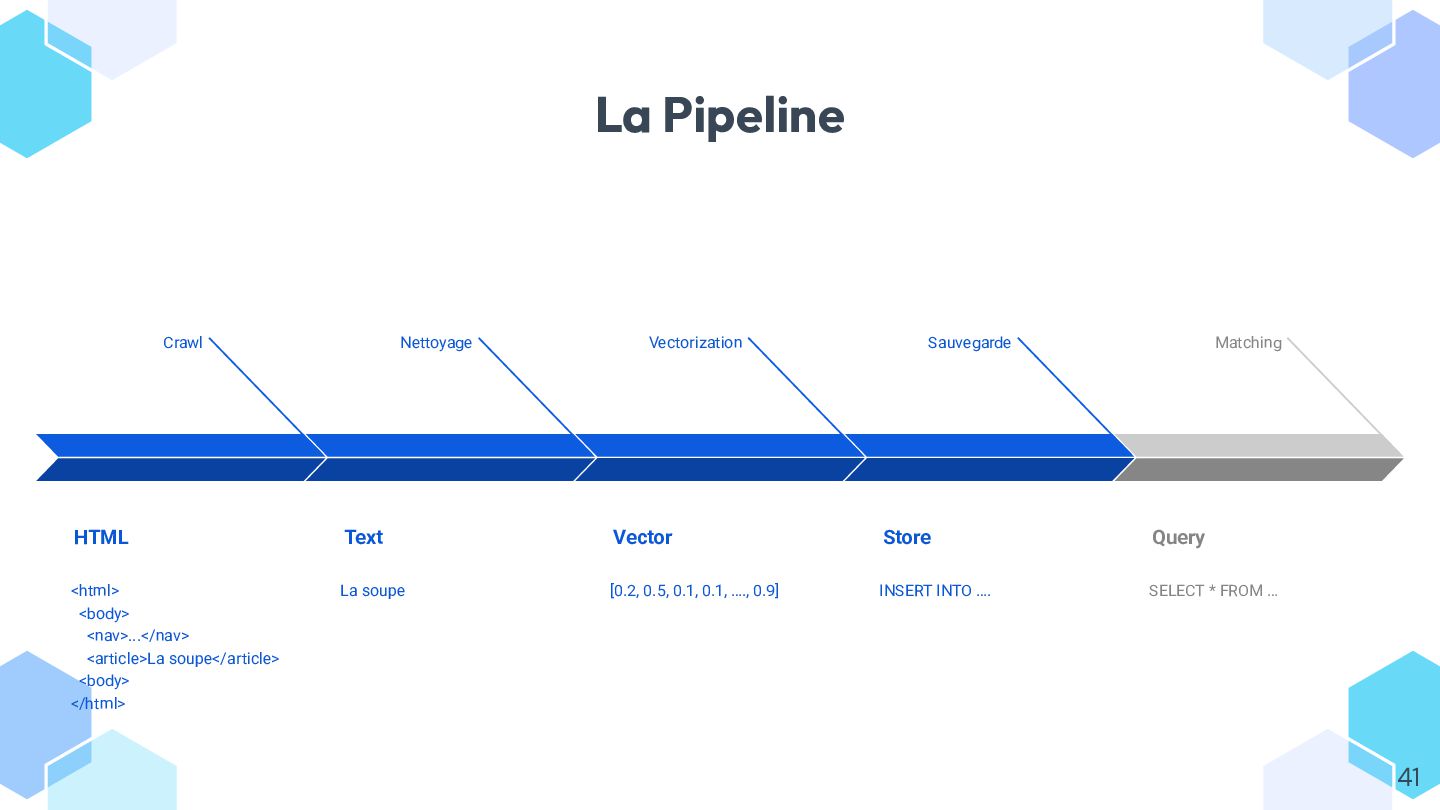
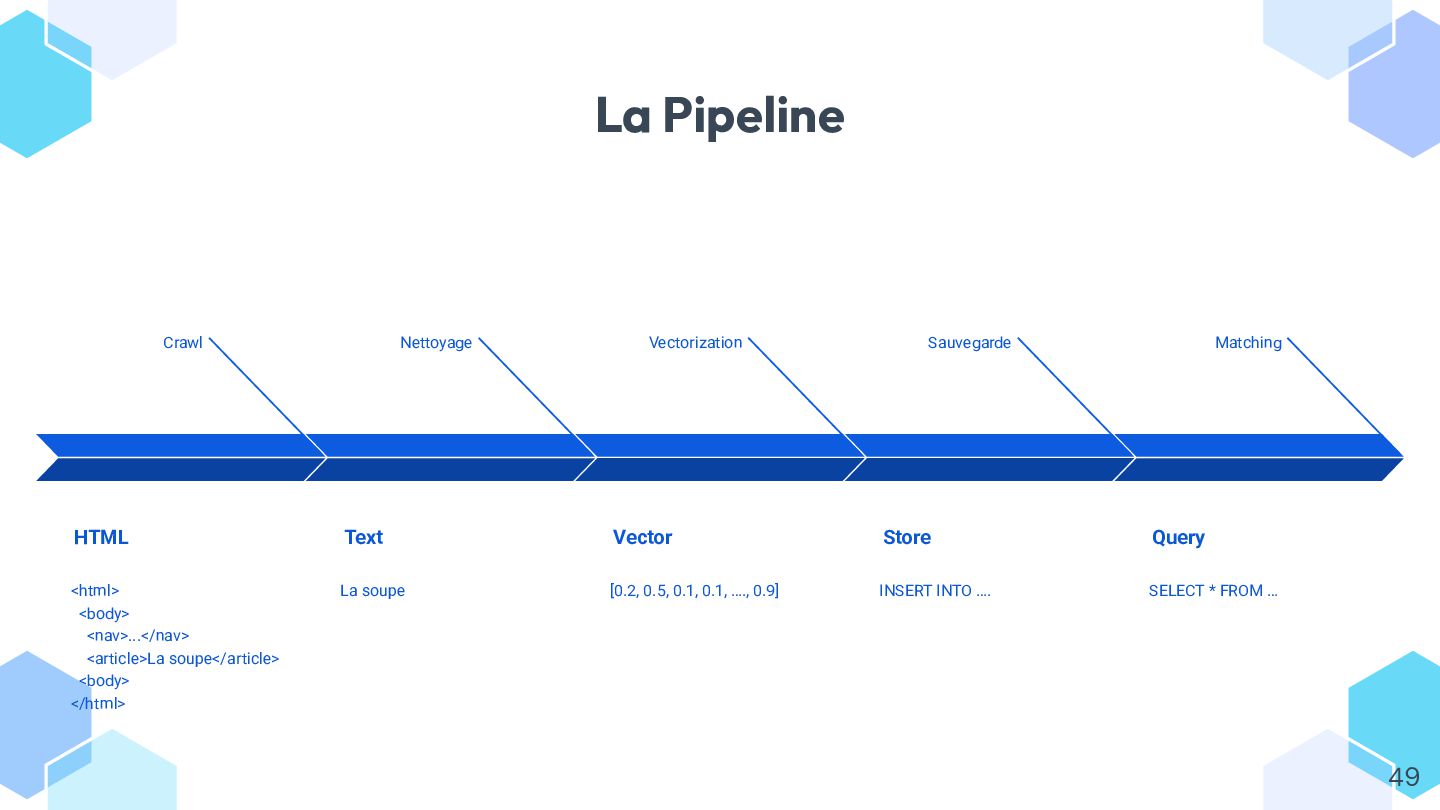
Dans ce talk, on explore concrètement l’usage des **embeddings** avec Symfony AI, à travers un exemple simple : rapprocher automatiquement des pages web par similarité.
Au programme :
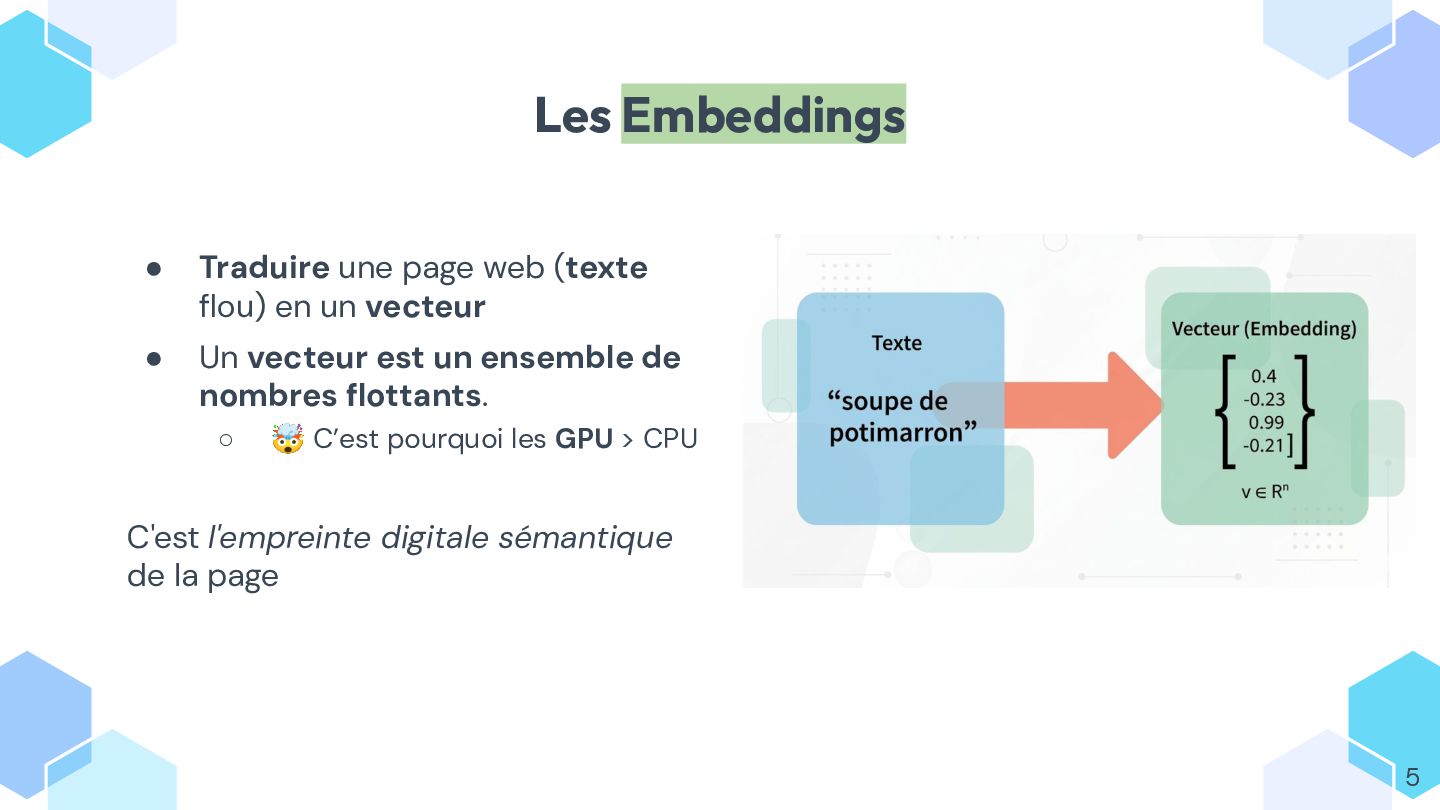
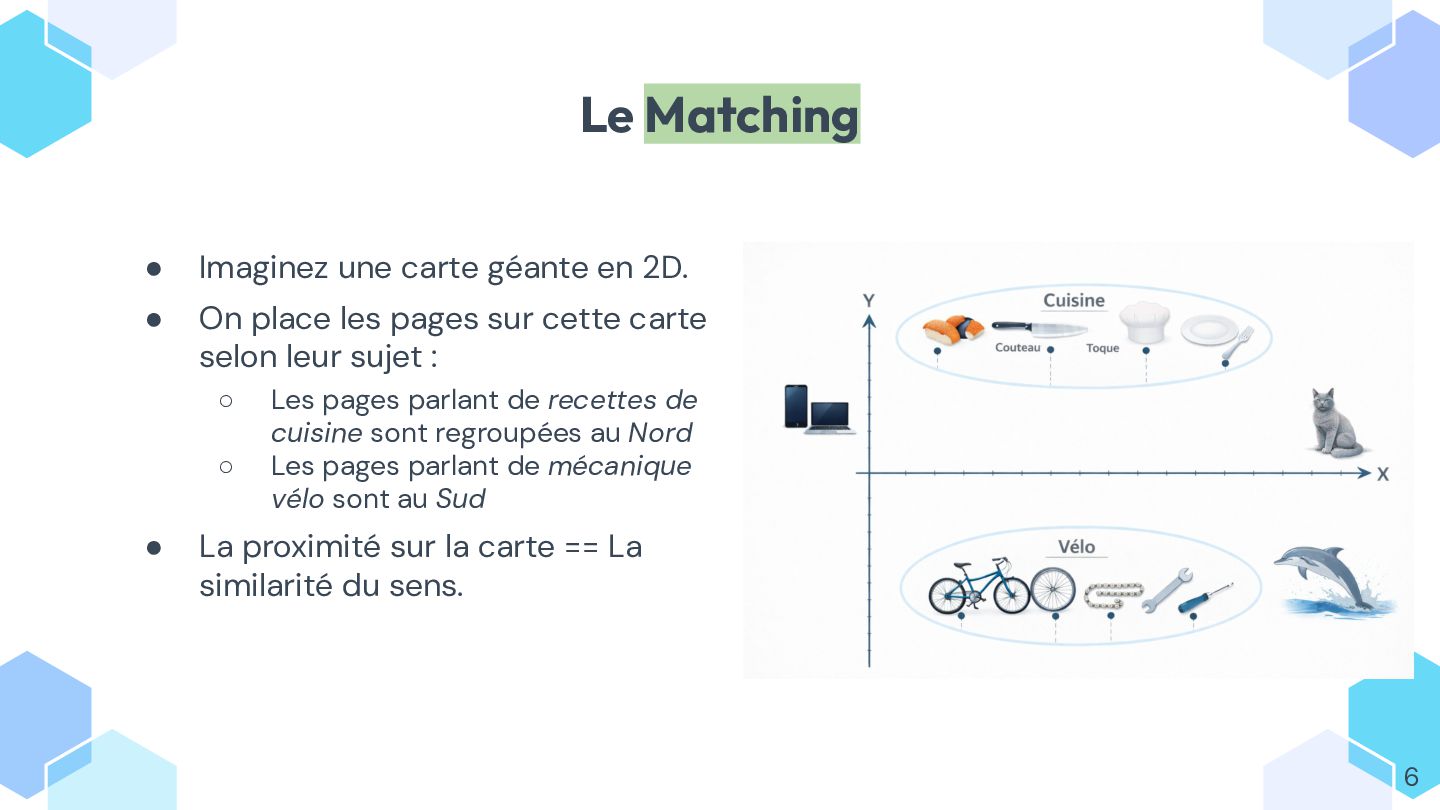
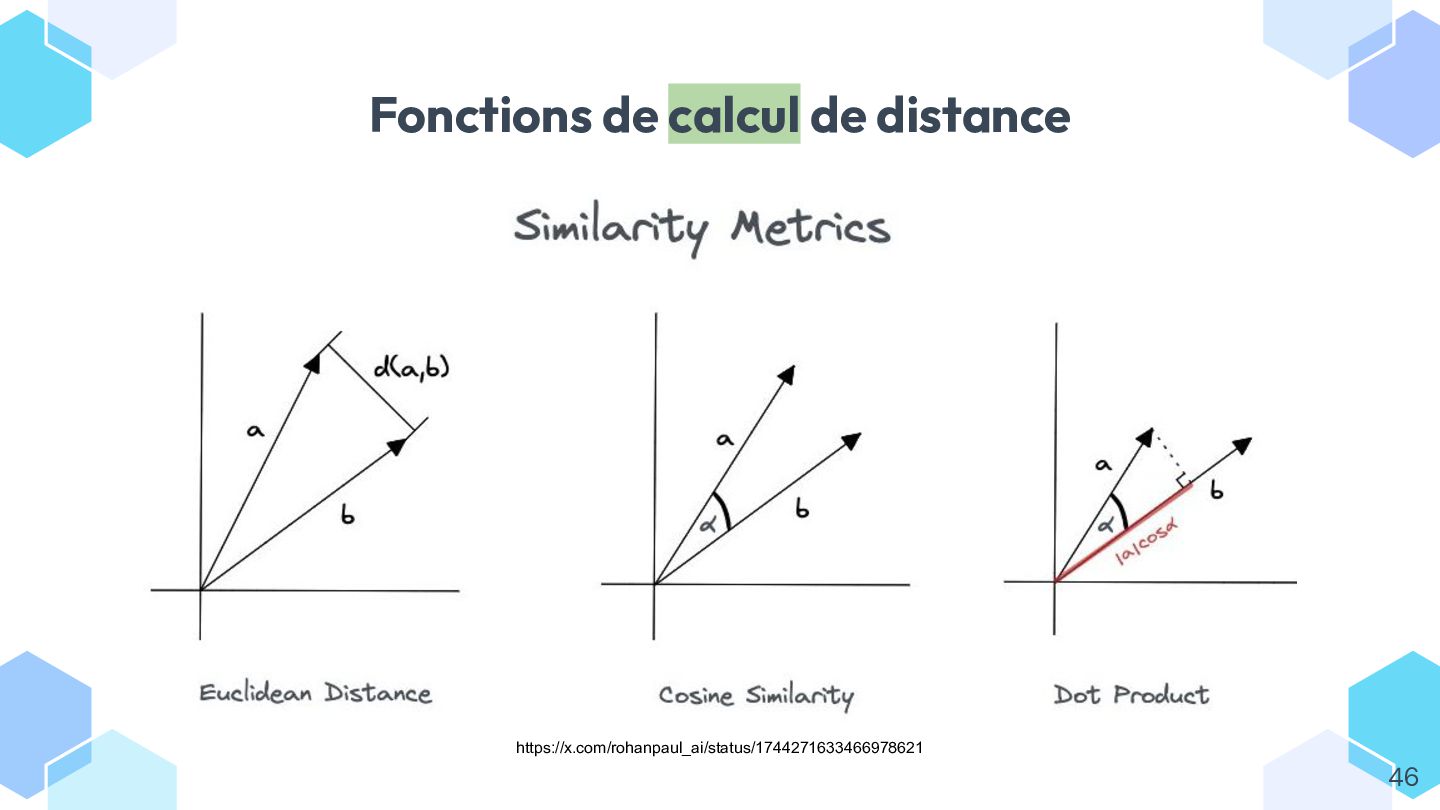
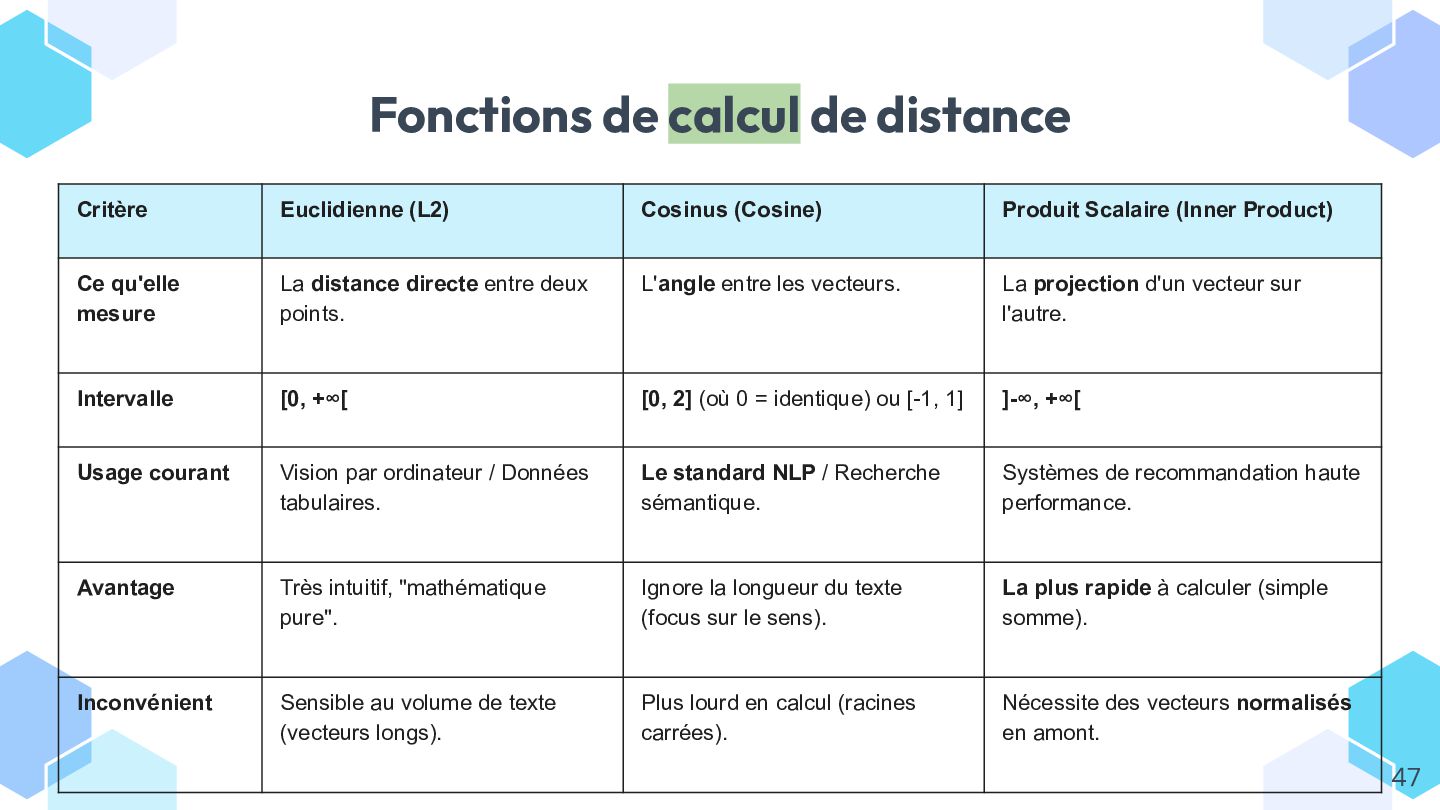
* comprendre ce qu’est un embedding et comment il permet de mesurer la similarité entre textes ;
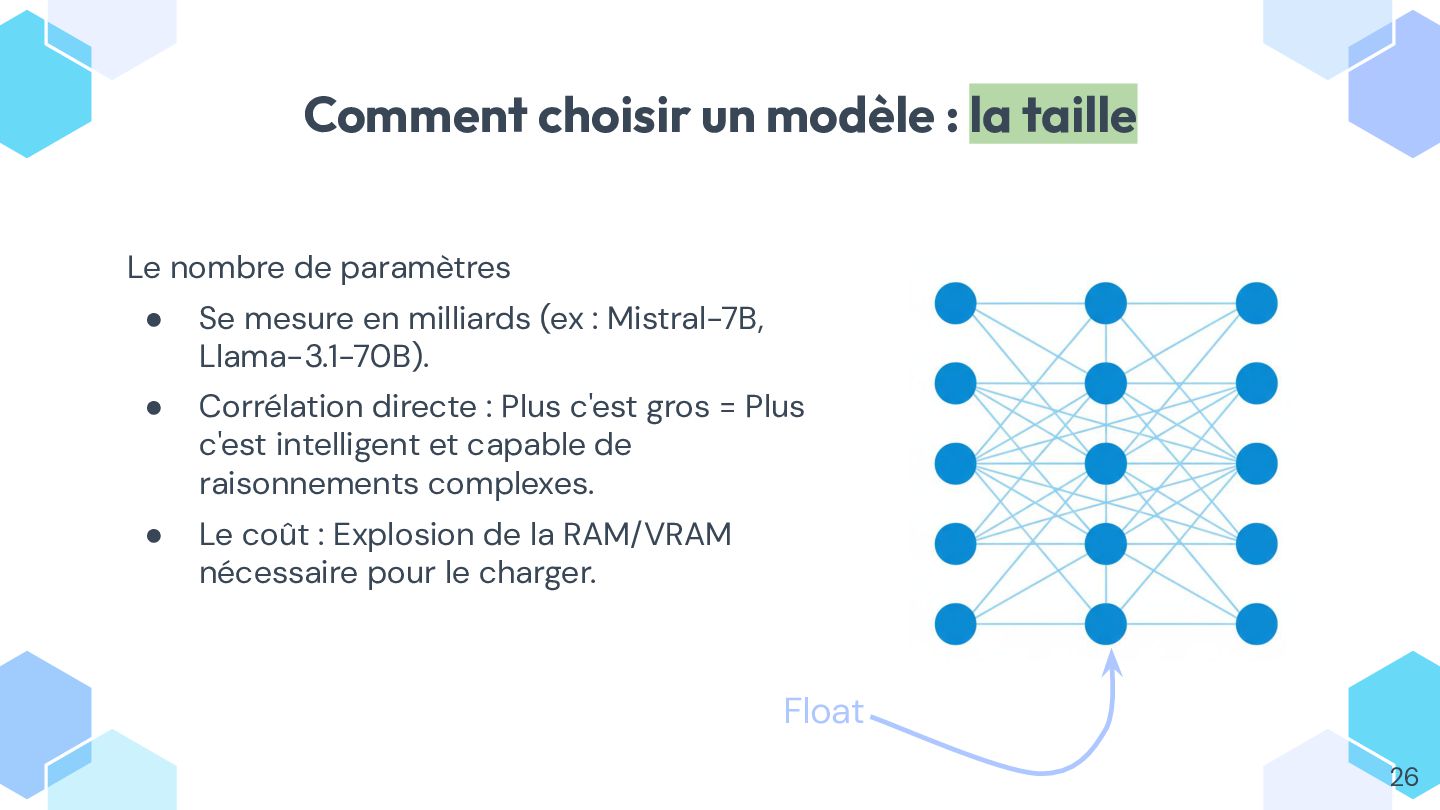
* découvrir les **plateformes et modèles** disponibles, et apprendre à choisir le bon selon vos besoins ;
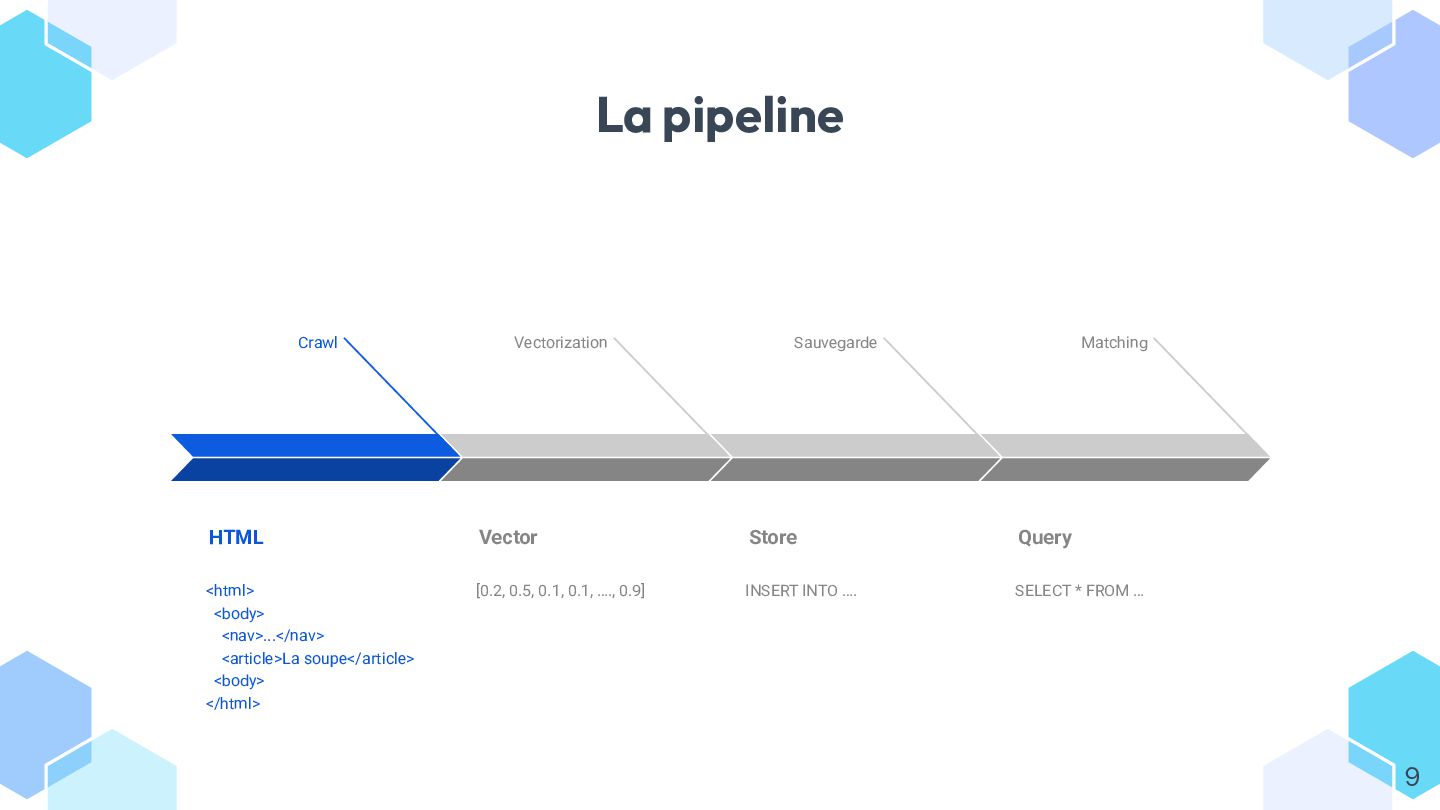
* vectoriser du contenu depuis Symfony et communiquer efficacement avec votre modèle ;
* stocker et requêter les vecteurs dans différents **stores** (Redis, ClickHouse, Postgres, etc.) ;
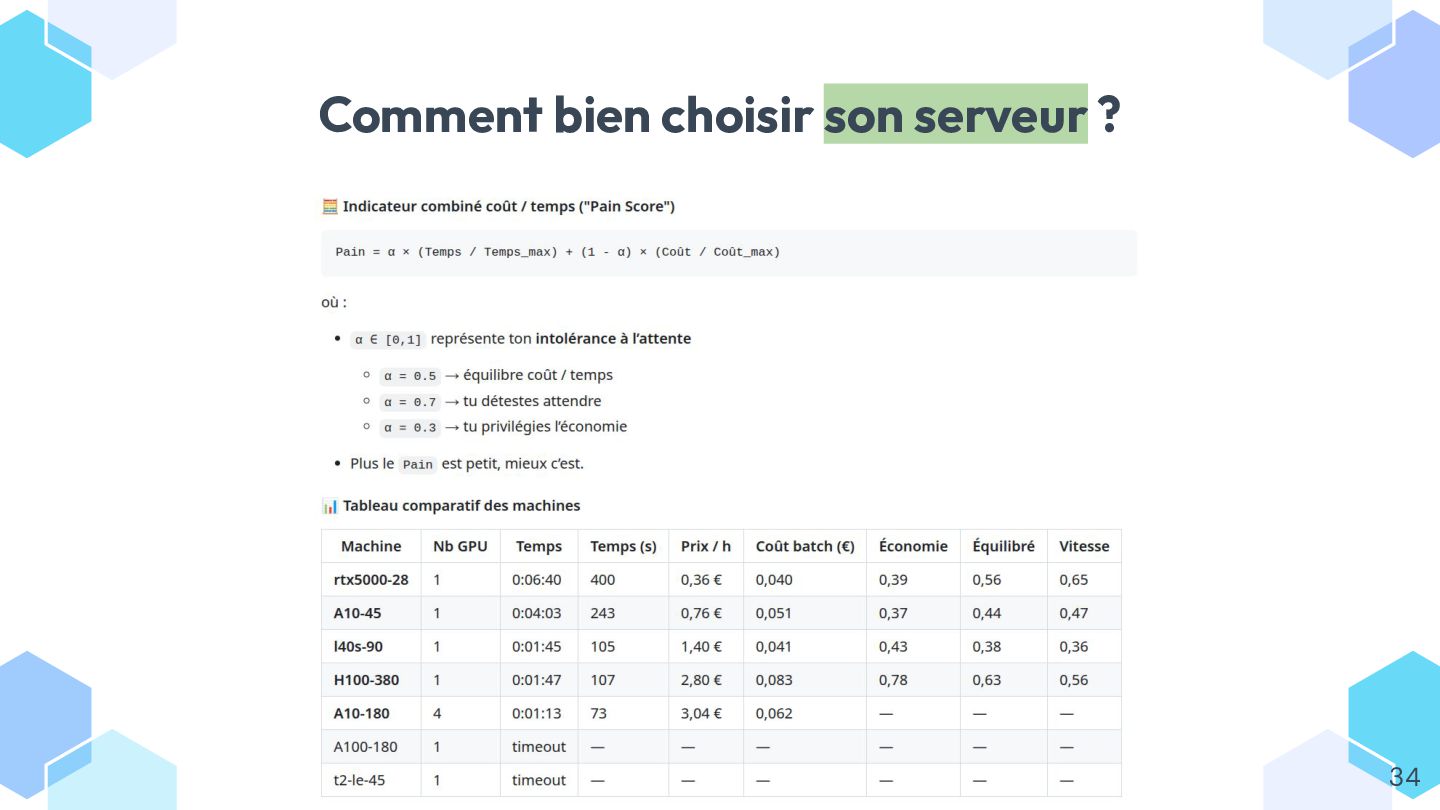
* héberger et scaler votre “vectoriseur” (Ollama, multi-GPU, RabbitMQ…).
L’objectif : comprendre les bases réelles de l’IA sémantique appliquée au PHP, et repartir avec une méthode claire pour expérimenter, comparer et mettre en production vos propres embeddings.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}