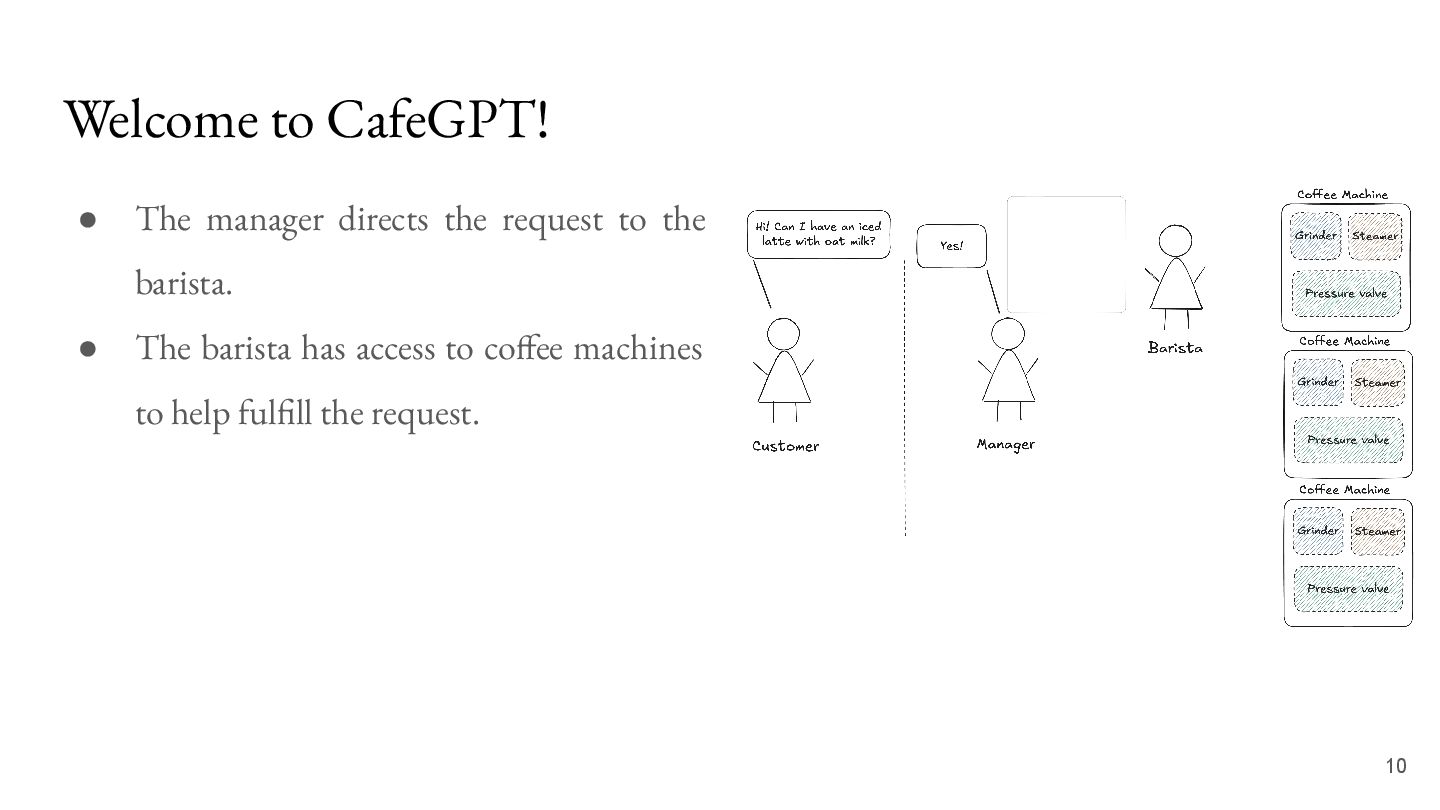
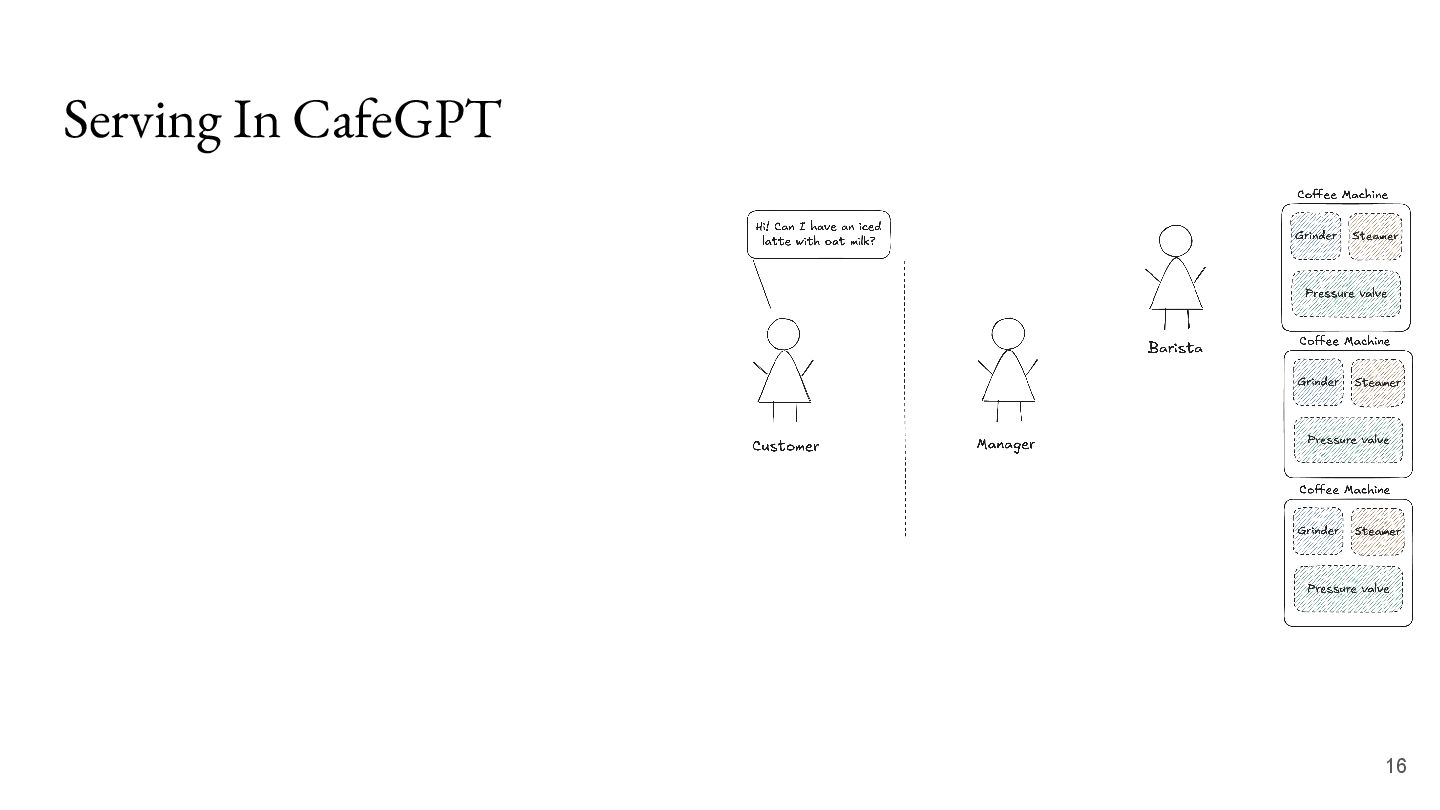
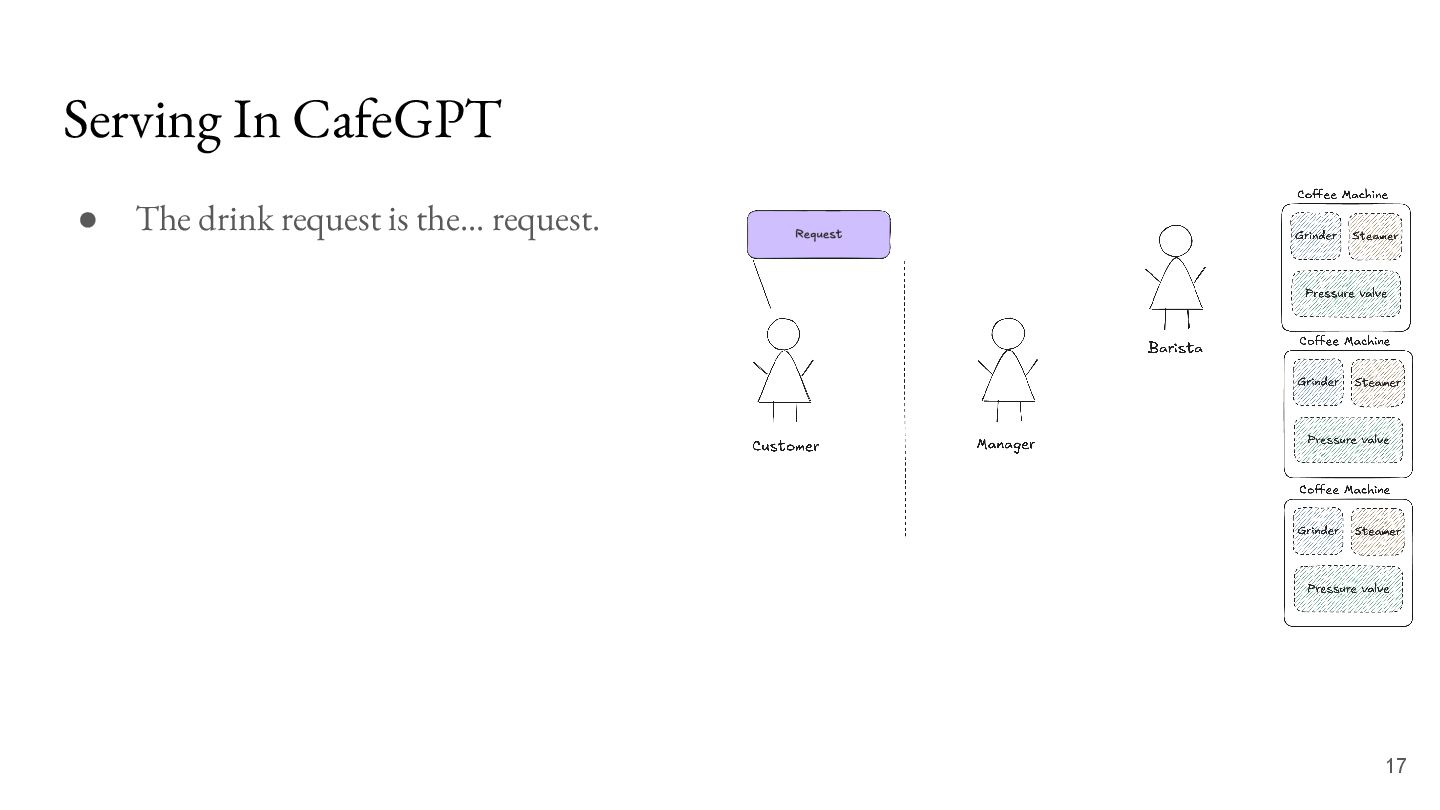
the barista. • The barista has access to coffee machines to help fulfill the request. • Each coffee machine has many moving parts: the grinder, the steamer and the pressure valve. 11
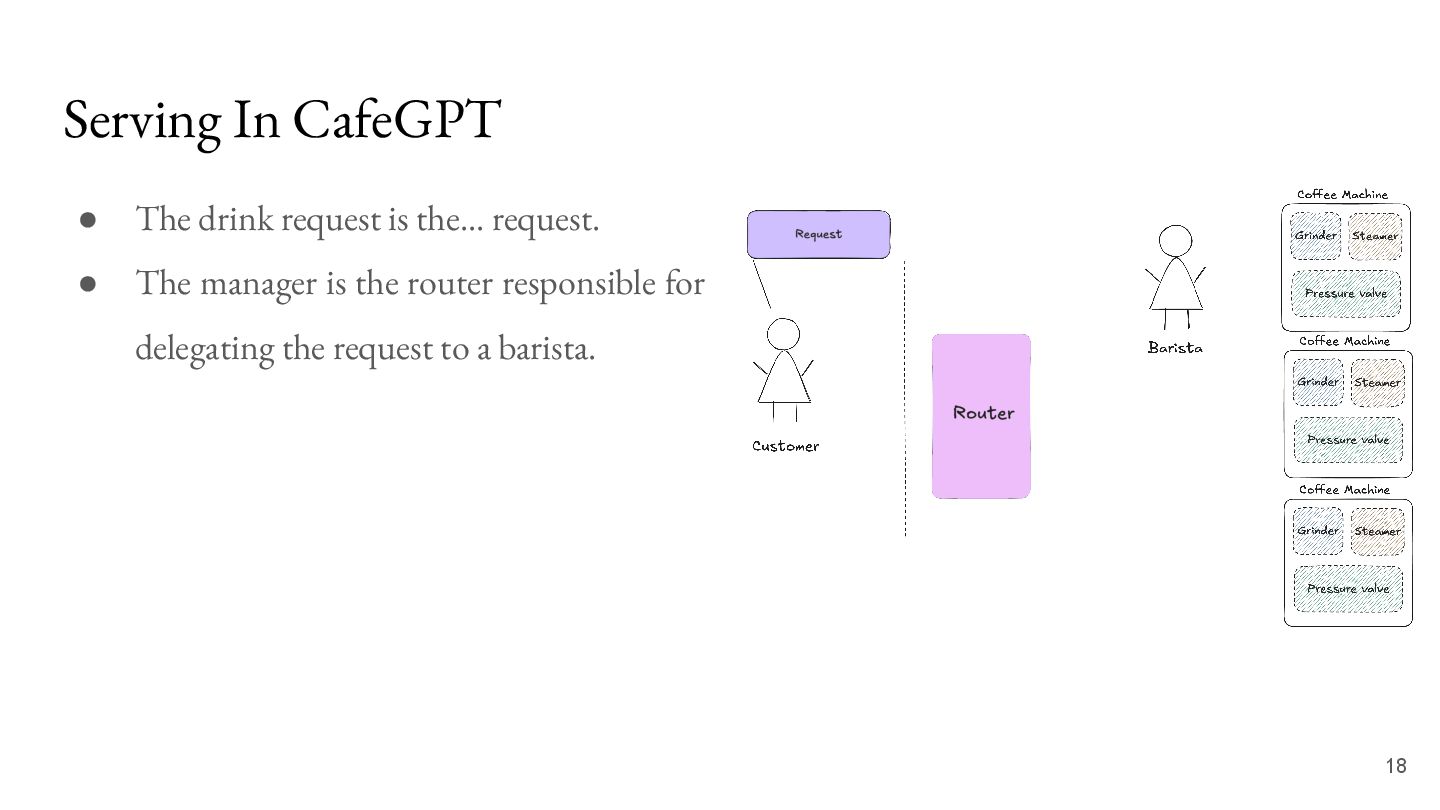
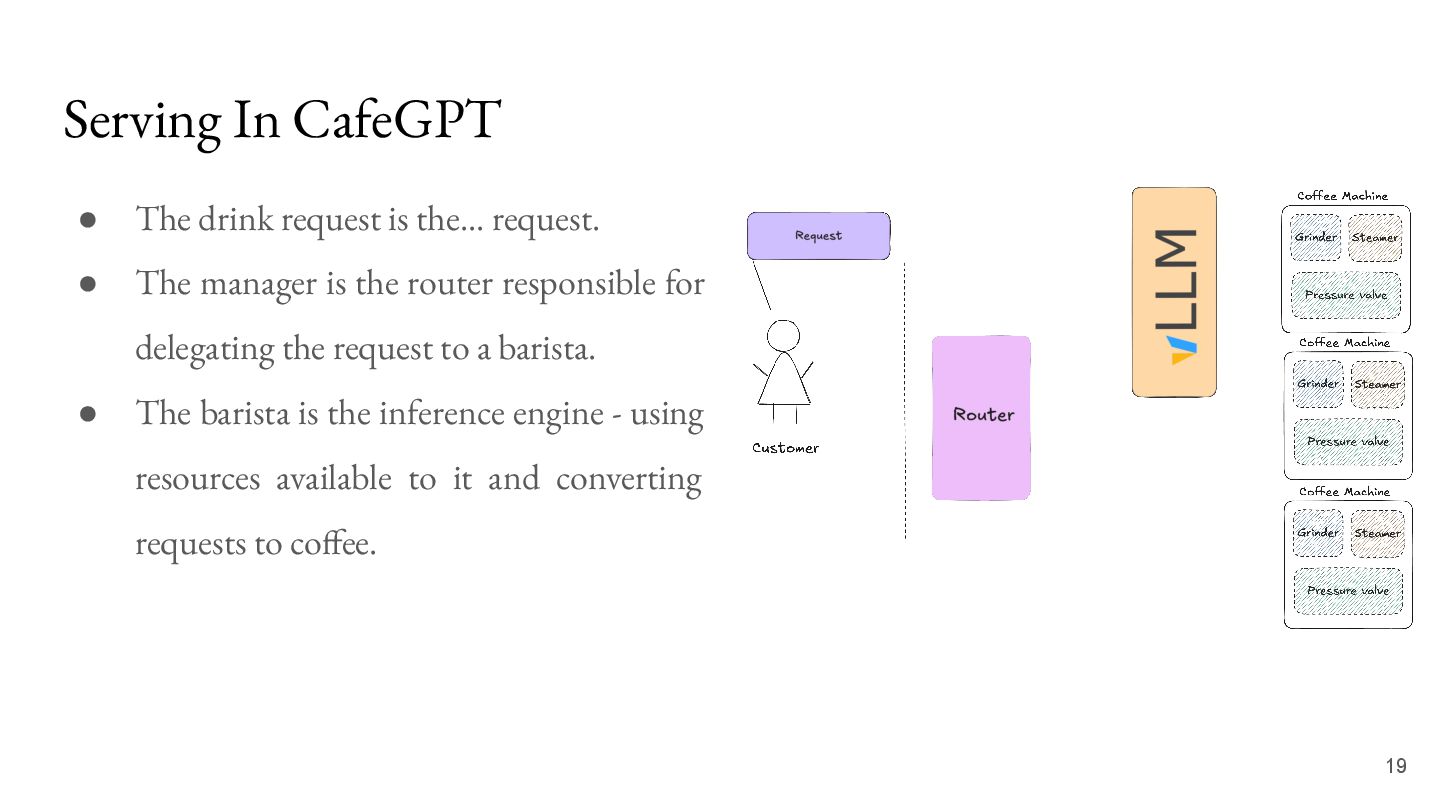
request. • The manager is the router responsible for delegating the request to a barista. • The barista is the inference engine - using resources available to it and converting requests to coffee.
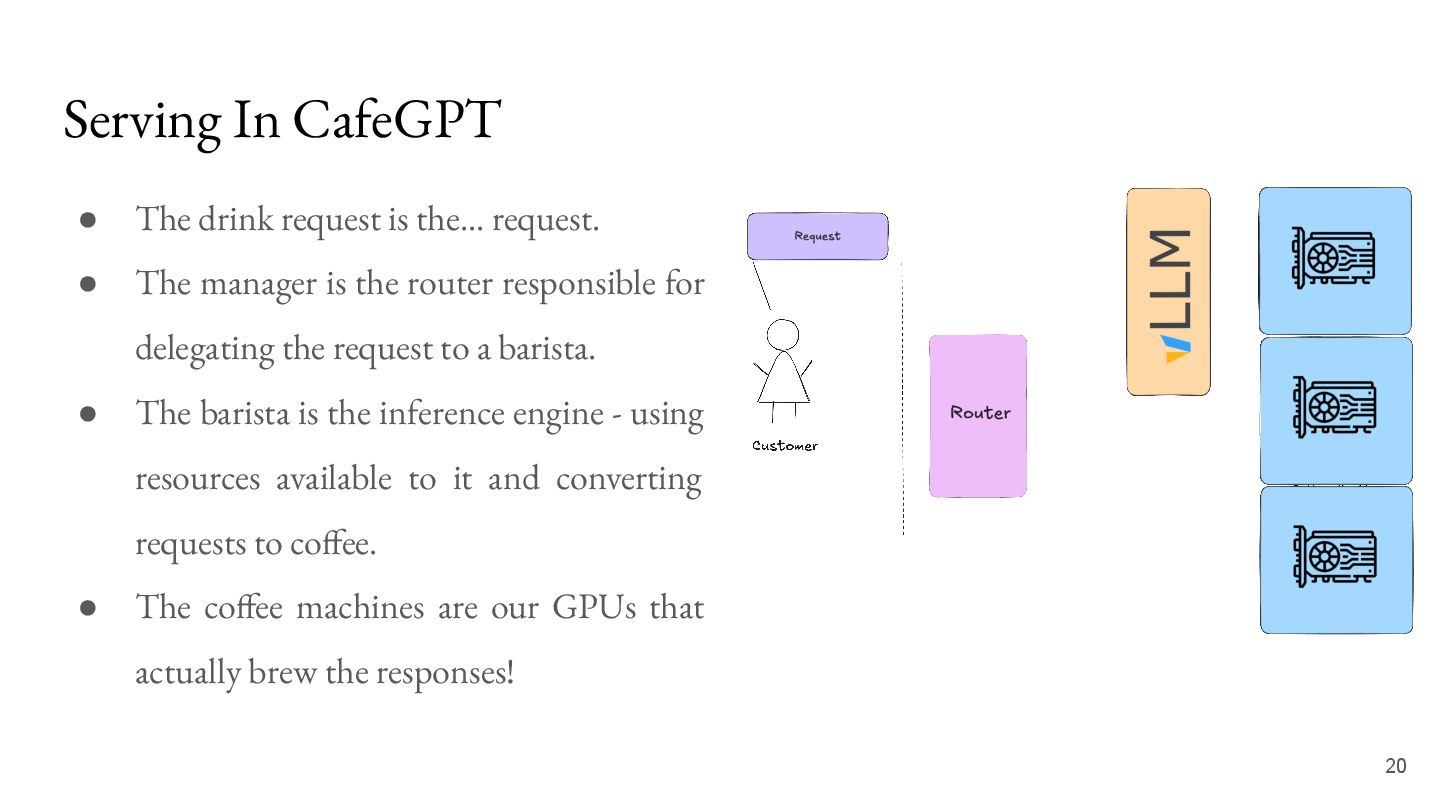
request. • The manager is the router responsible for delegating the request to a barista. • The barista is the inference engine - using resources available to it and converting requests to coffee. • The coffee machines are our GPUs that actually brew the responses!
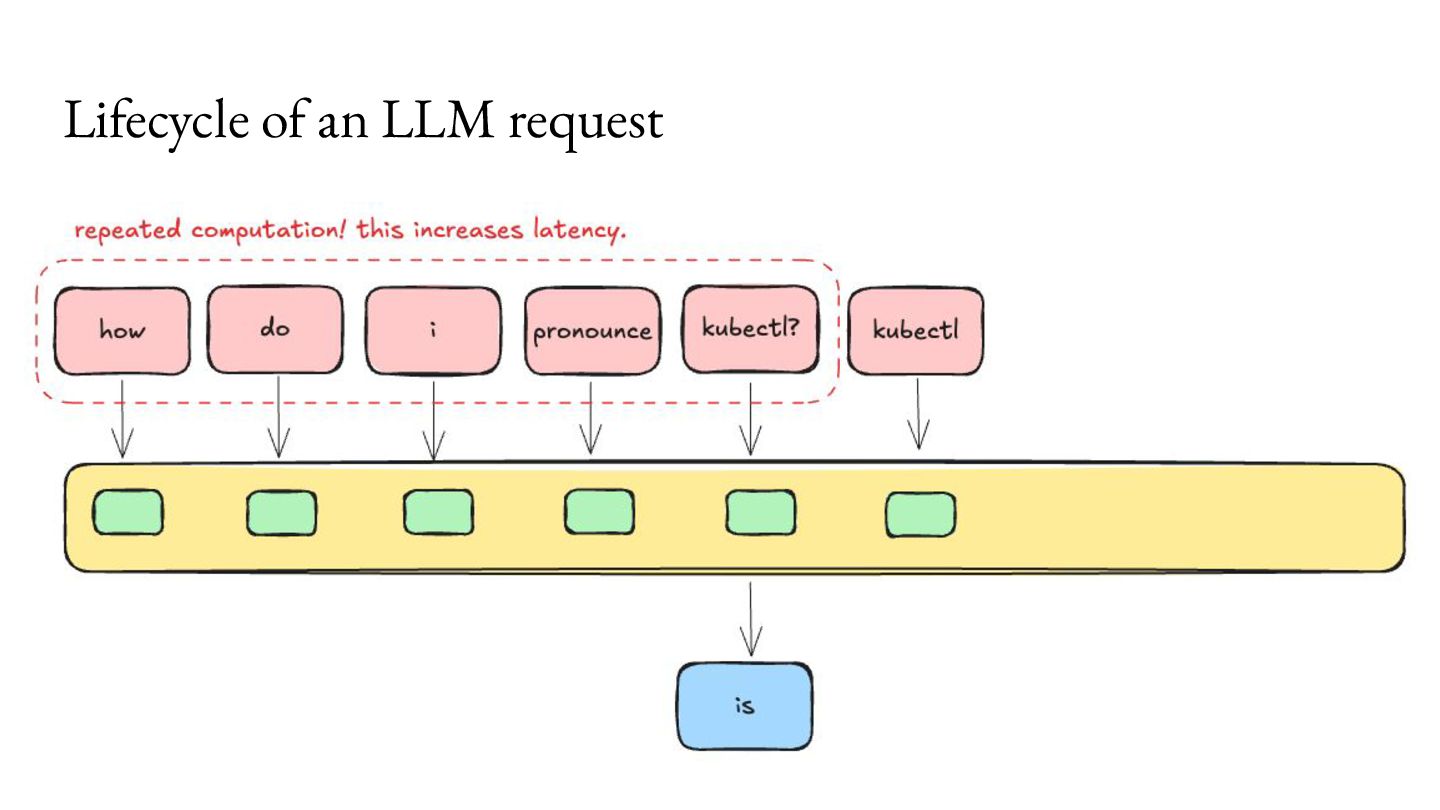
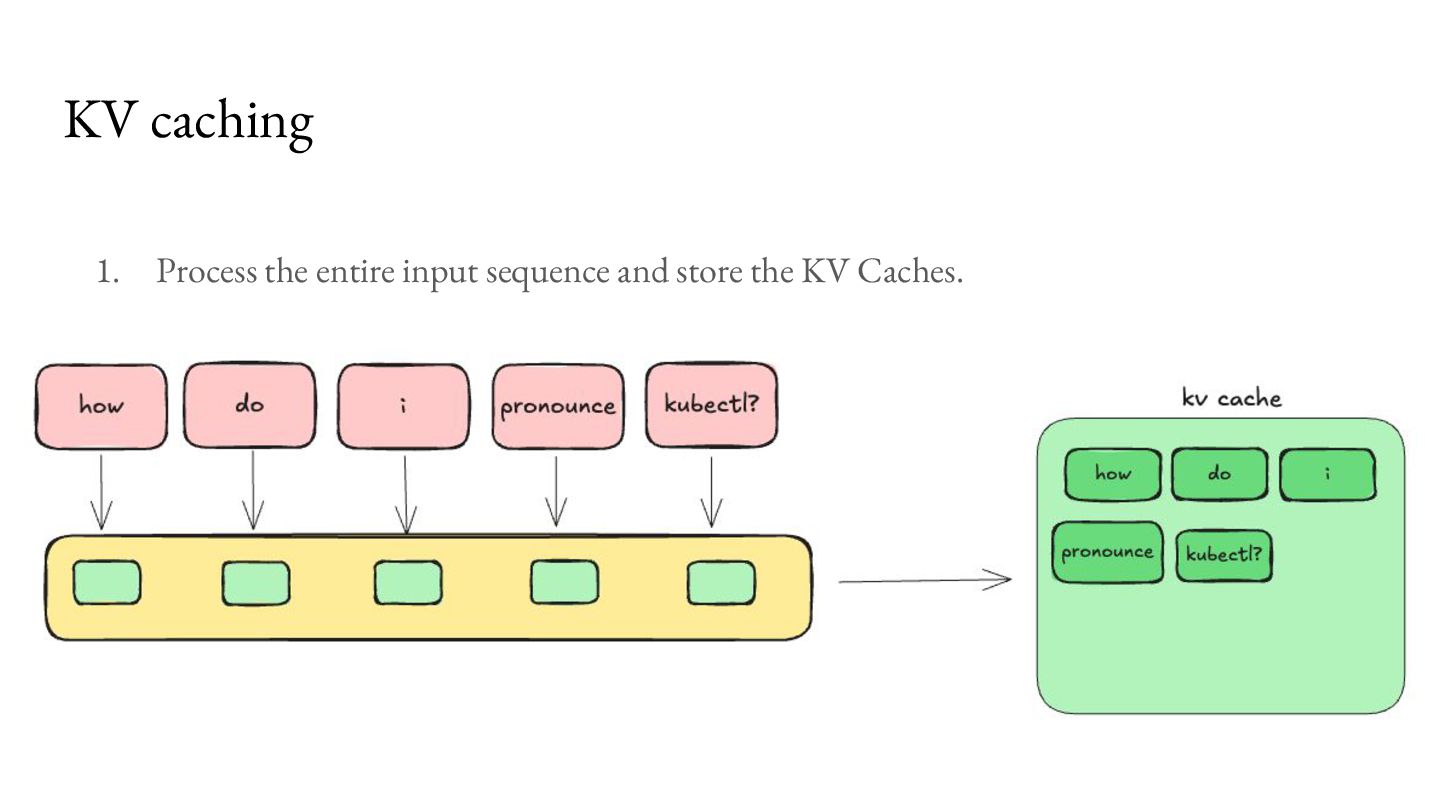
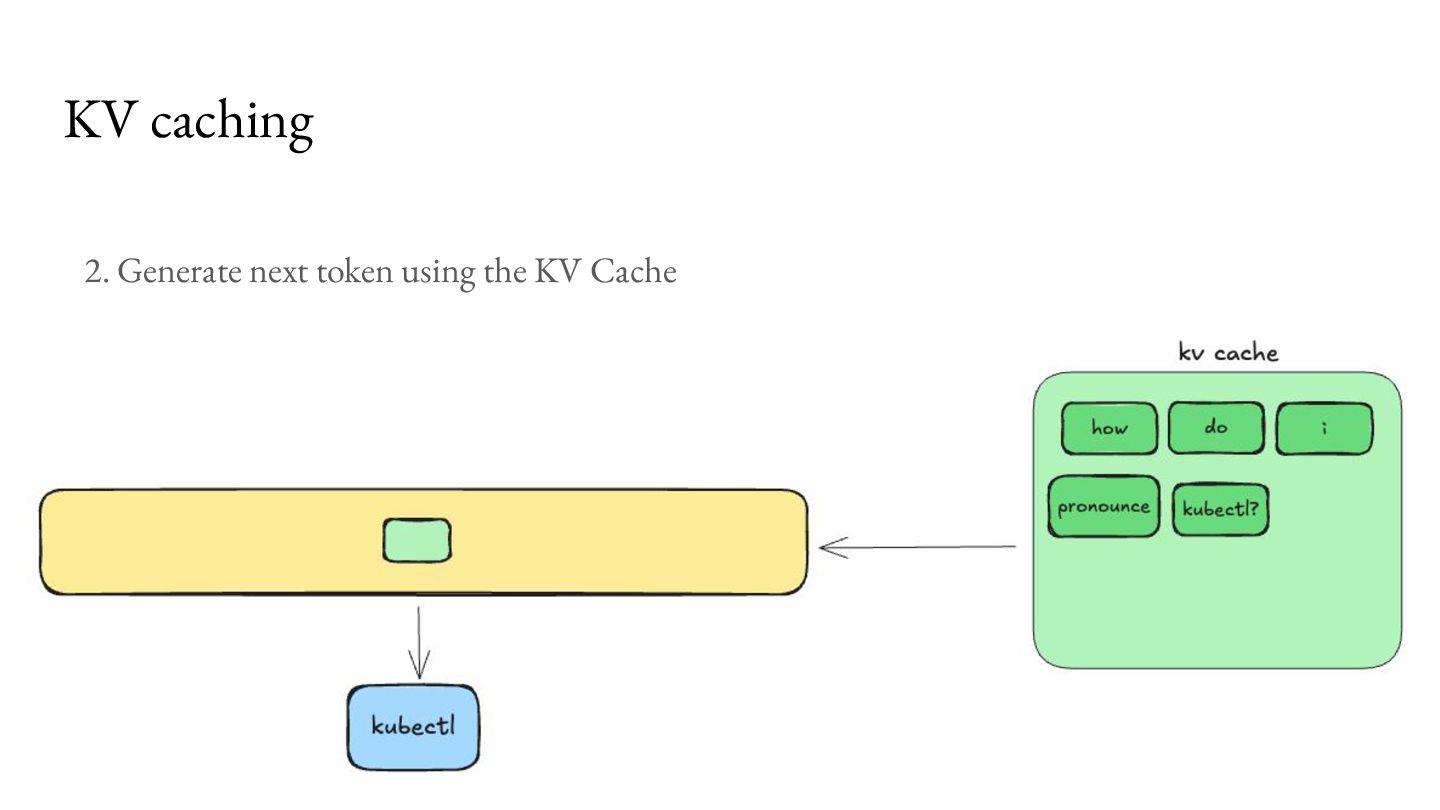
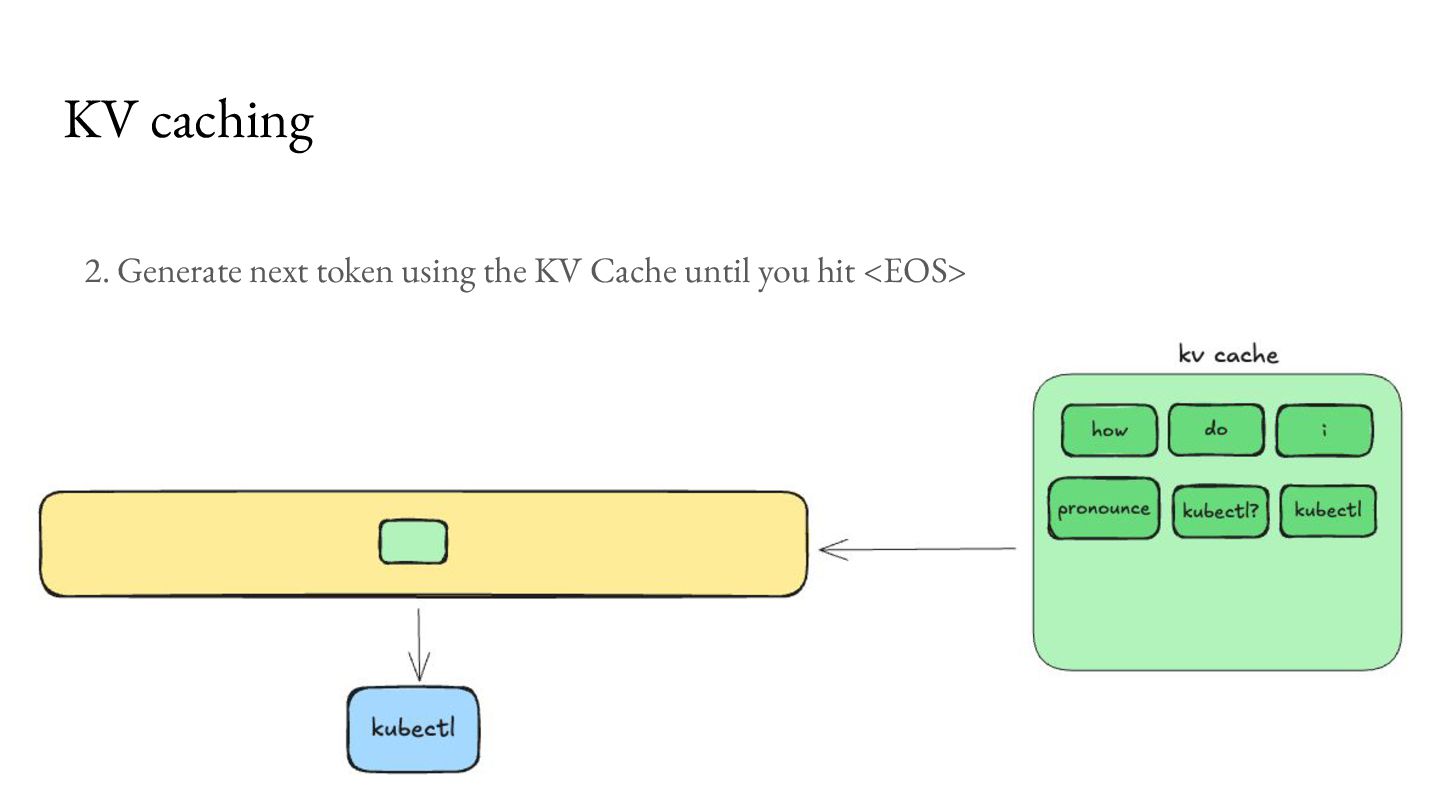
comes at an overhead of higher memory use, which becomes a bottleneck for concurrent processing of requests. For Llama 3.1 8B, with 8K context length on an NVIDIA A100 GPU, you can only serve about 24 requests per second.2 KV caching Memory available 40GB Model Weights (FP16) 16GB KV Cache per request 1GB
comes at an overhead of higher memory use, which becomes a bottleneck for concurrent processing of requests. For Llama 3.1 8B, with 8K context length on an NVIDIA A100 GPU, you can only serve about 24 requests per second.2 As a result, a lot of research has emerged to make better use of this bottleneck.3 KV caching Memory available 40GB Model Weights (FP16) 16GB KV Cache per request 1GB 1. https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms 2. https://lmcache.ai/kv_cache_calculator.html 3. https://arxiv.org/abs/2309.06180, https://lmcache.ai/tech_report.pdf
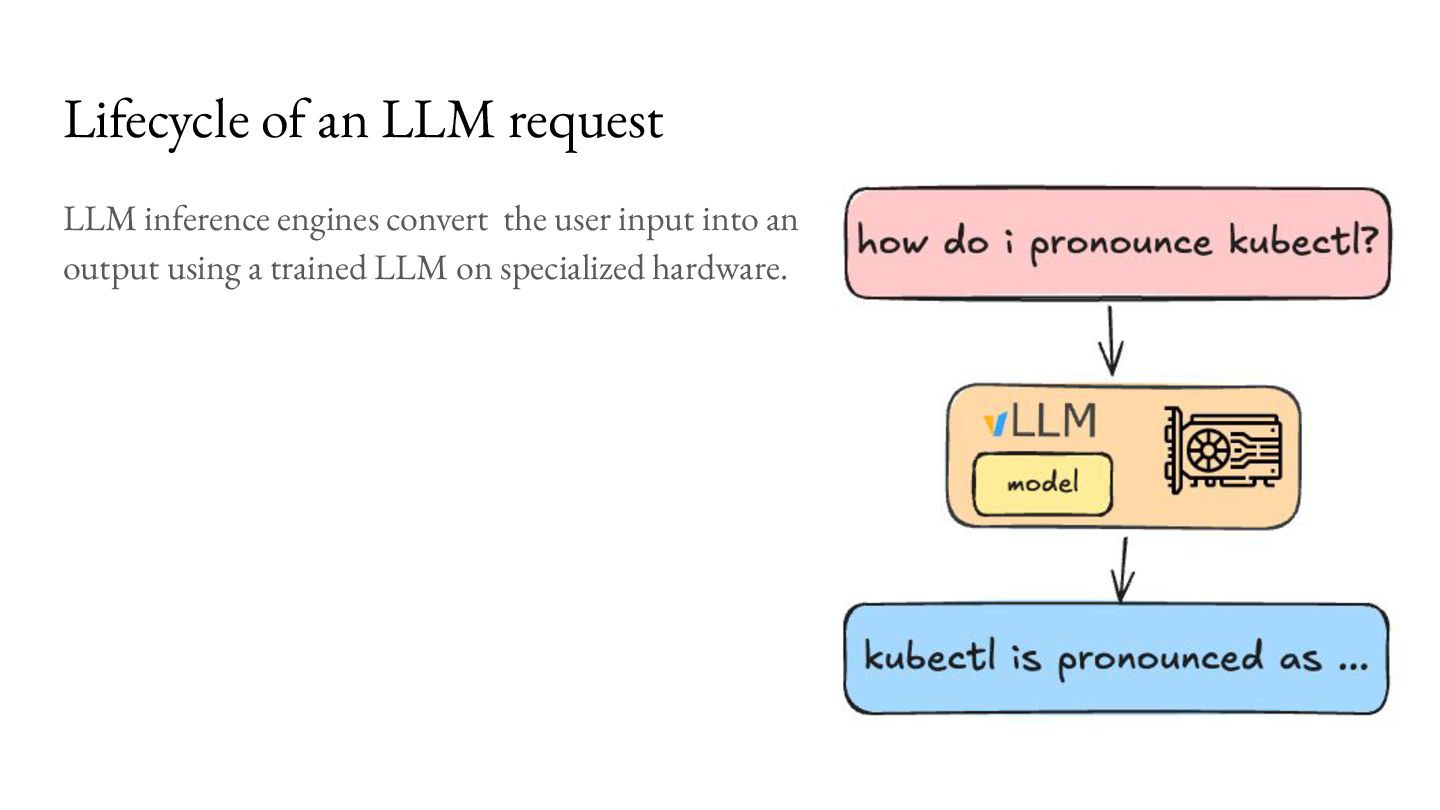
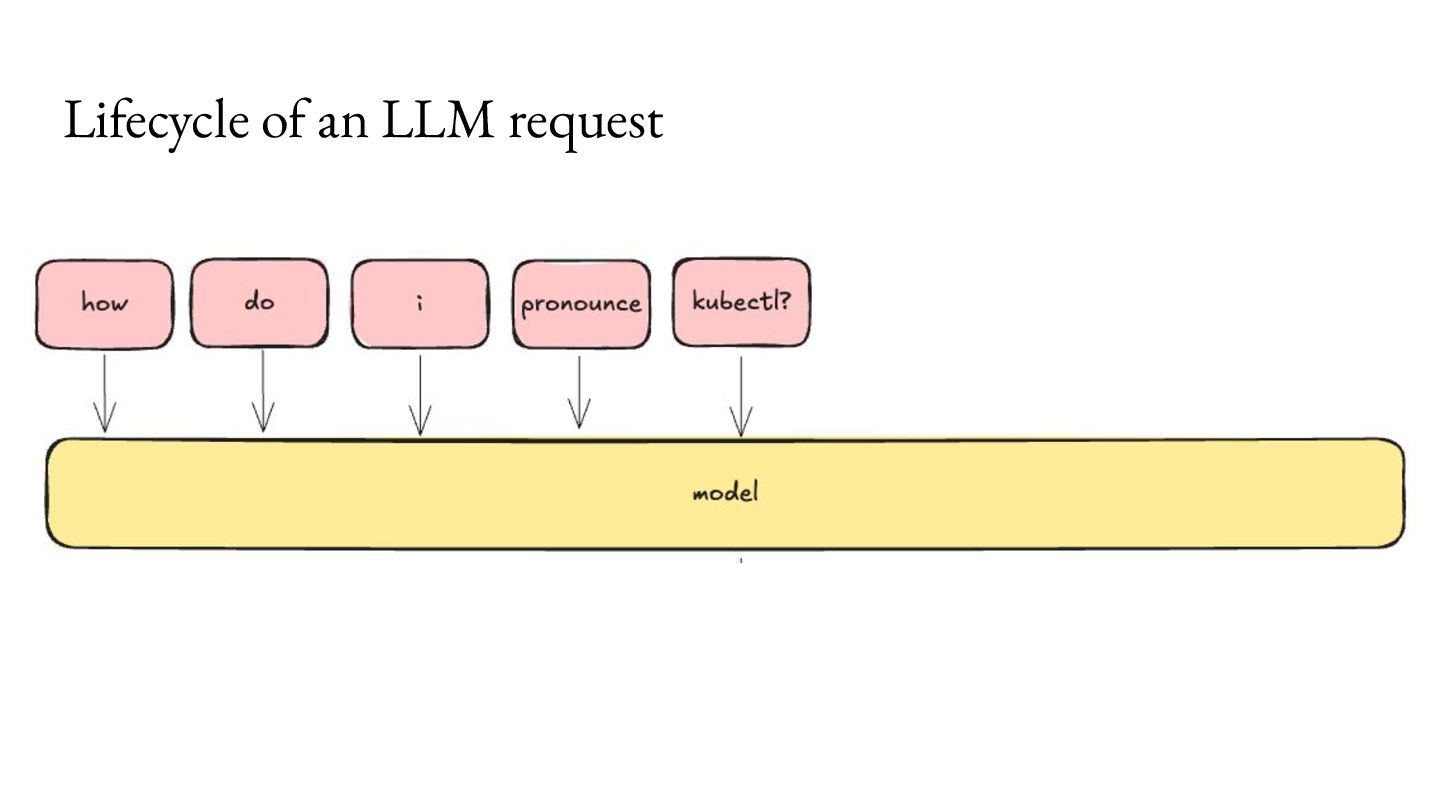
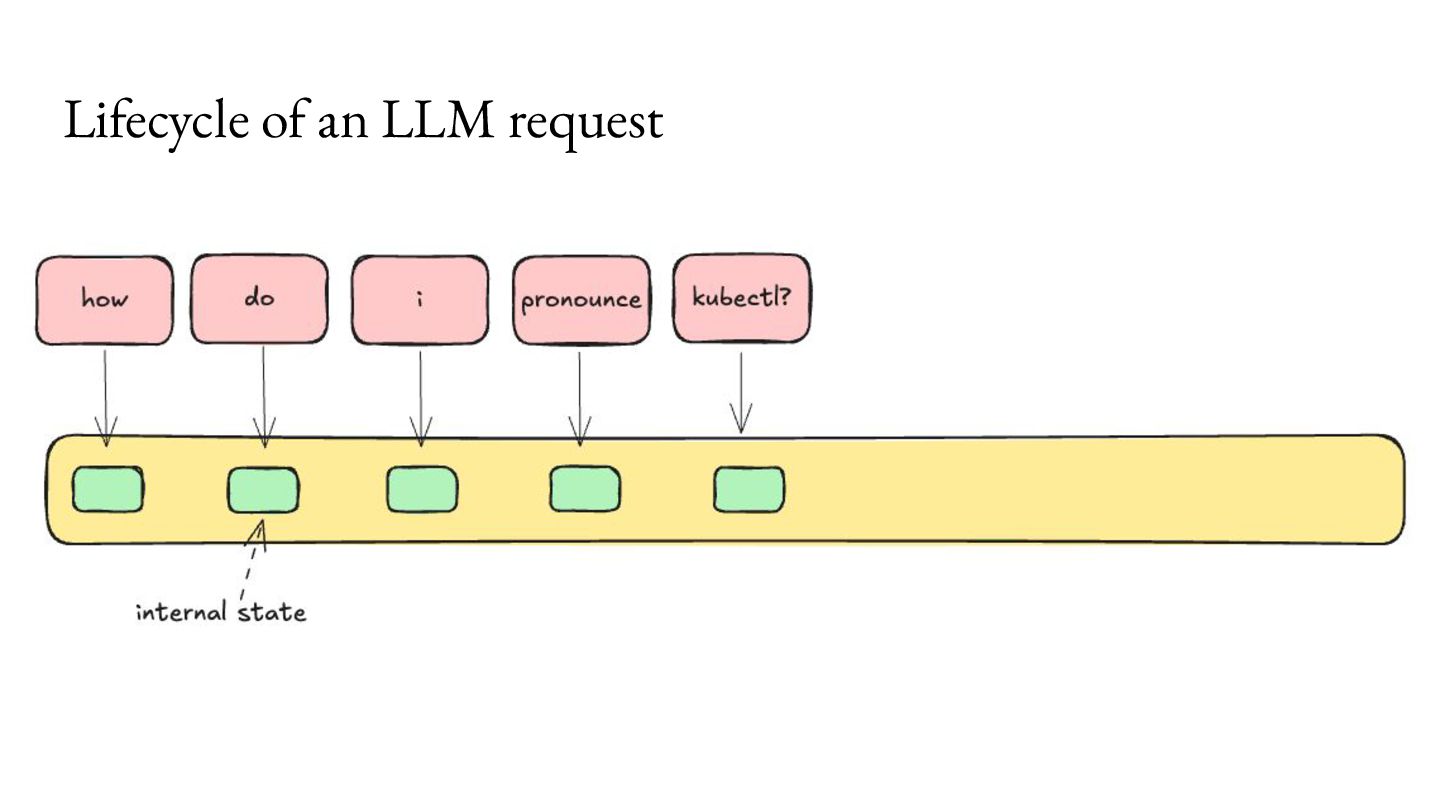
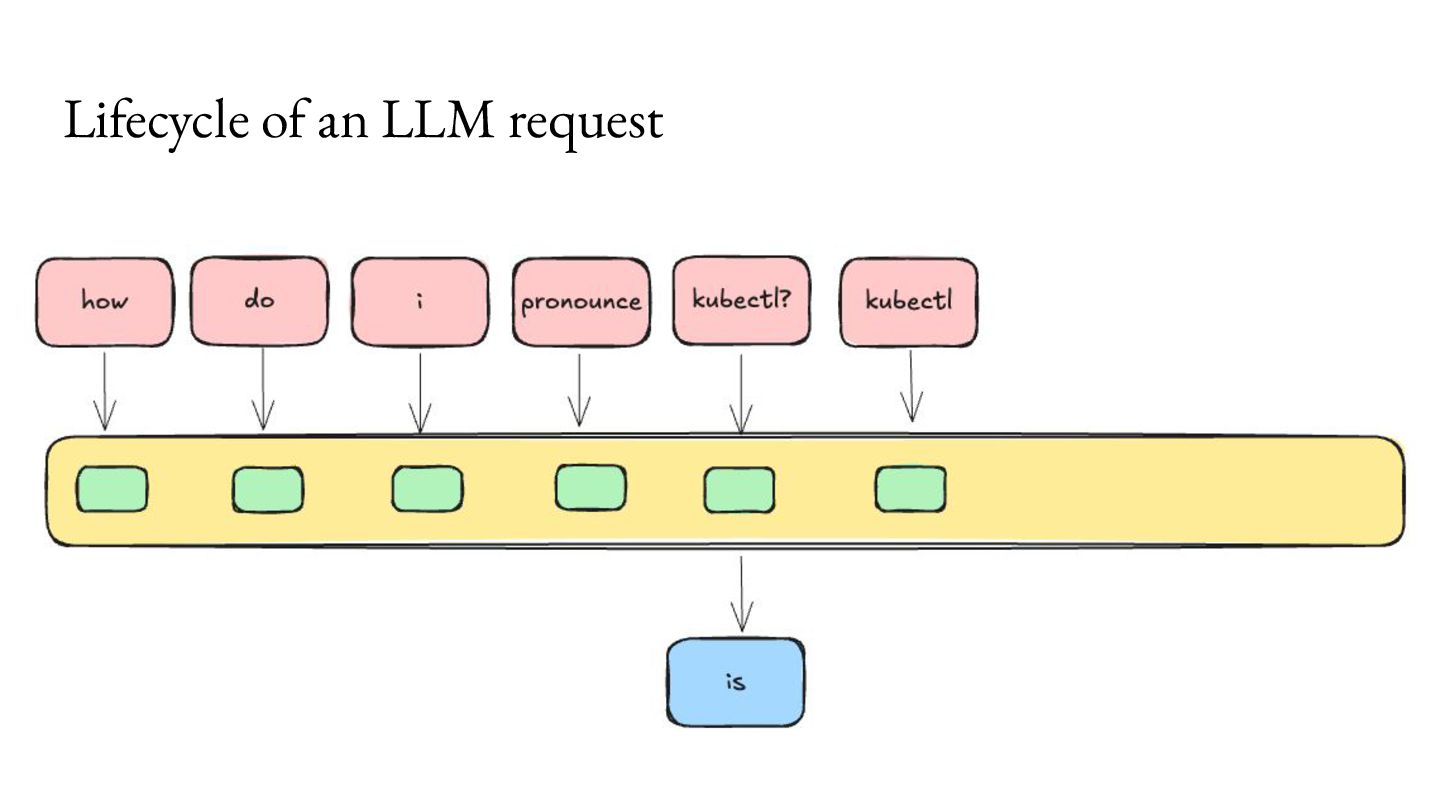
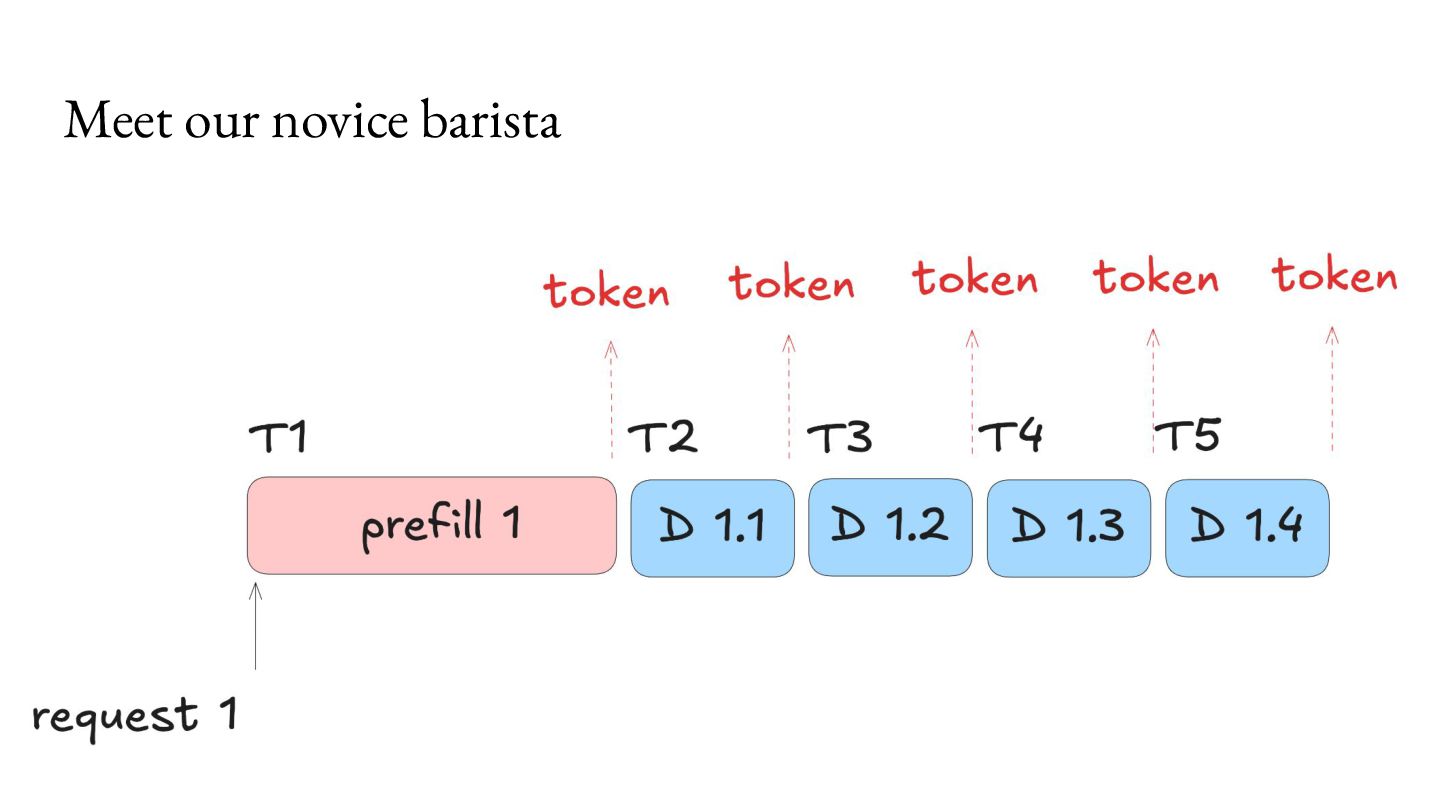
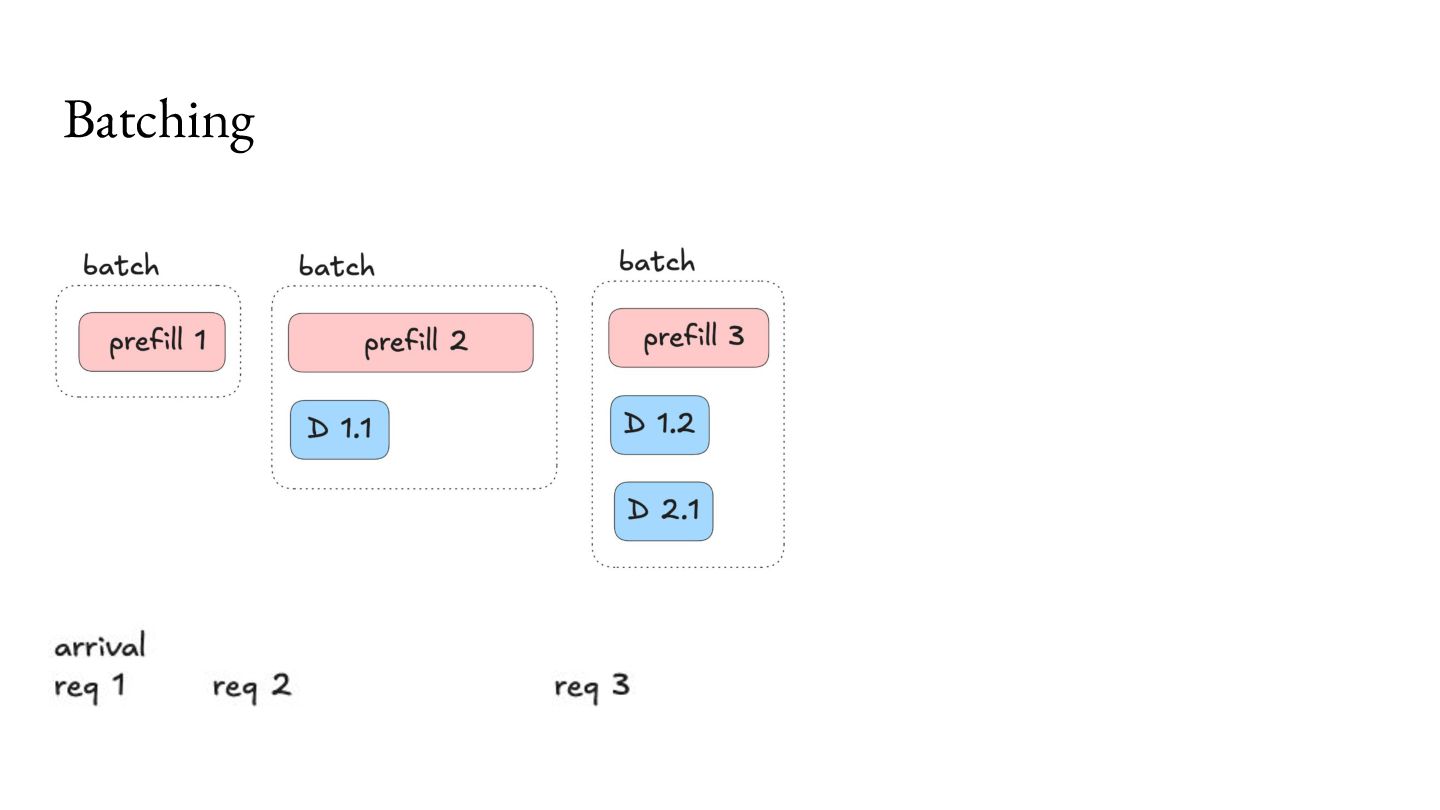
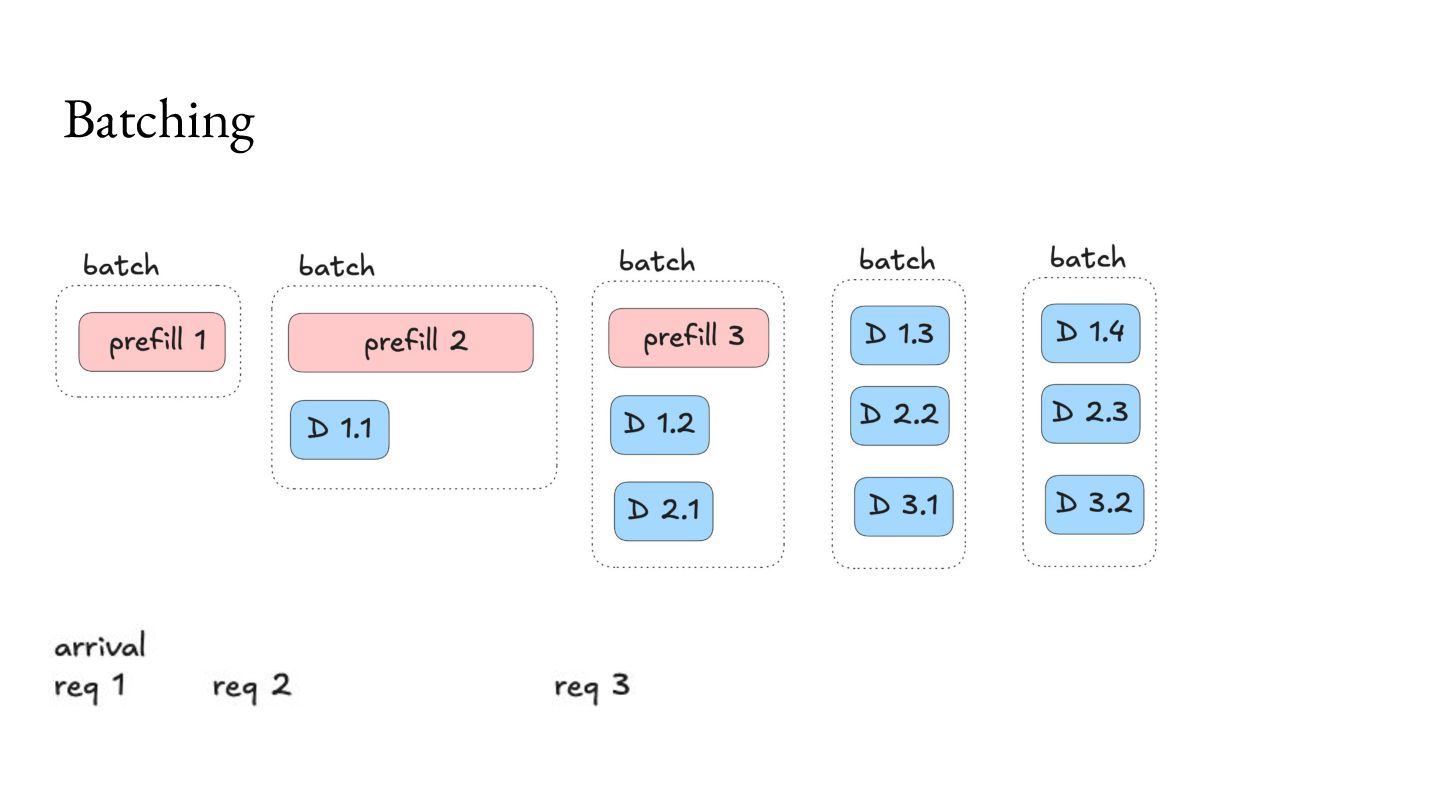
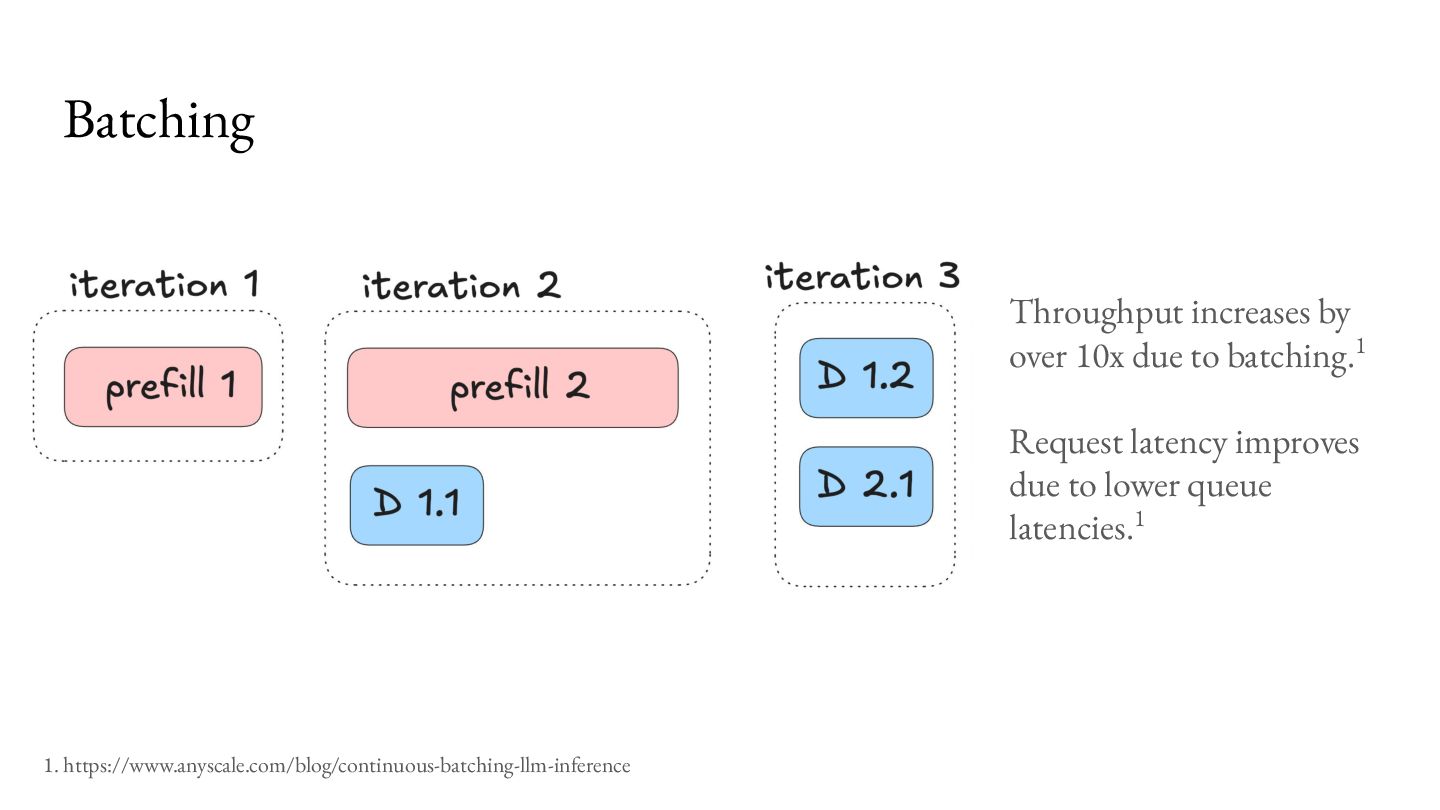
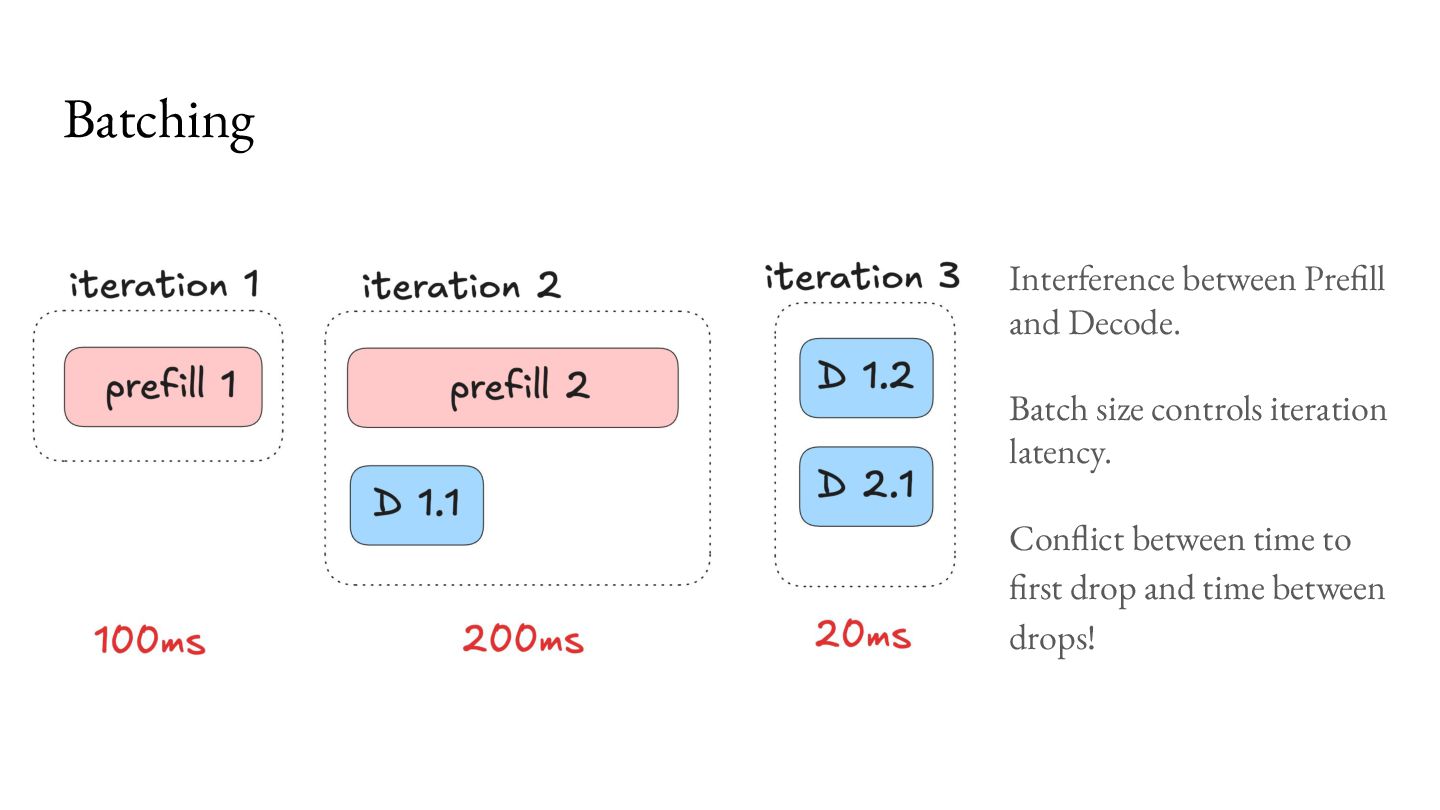
Prefill - Do the prep work. 2. Decode - Multiple iterations of small units of work. Important workload characteristics: 1. Prefill is computationally intensive, but lasts a short duration. 2. Decode is memory intensive, and lasts a long duration. 3. You don’t know when the Decode will end.
1. Low Time to Coffee <-> Request latency 2. Low Time between drops <-> Inter Token Latency 3. Low Time to first drop <-> Time to first token From a provider point of view we want: 1. More Coffee per second <-> Throughput 2. High machine utilization Different customers might have different SLAs.
choice for a large percentage of companies to build their platforms on. • Inference is an interesting new workload with unique characteristics that can be served very well* without having to reinvent the wheel.
choice for a large percentage of companies to build their platforms on. • Inference is an interesting new workload with unique characteristics that can be served very well* without having to reinvent the wheel. • In fact, the community has been relentlessly evolving the core and ecosystem projects to better support this workload.
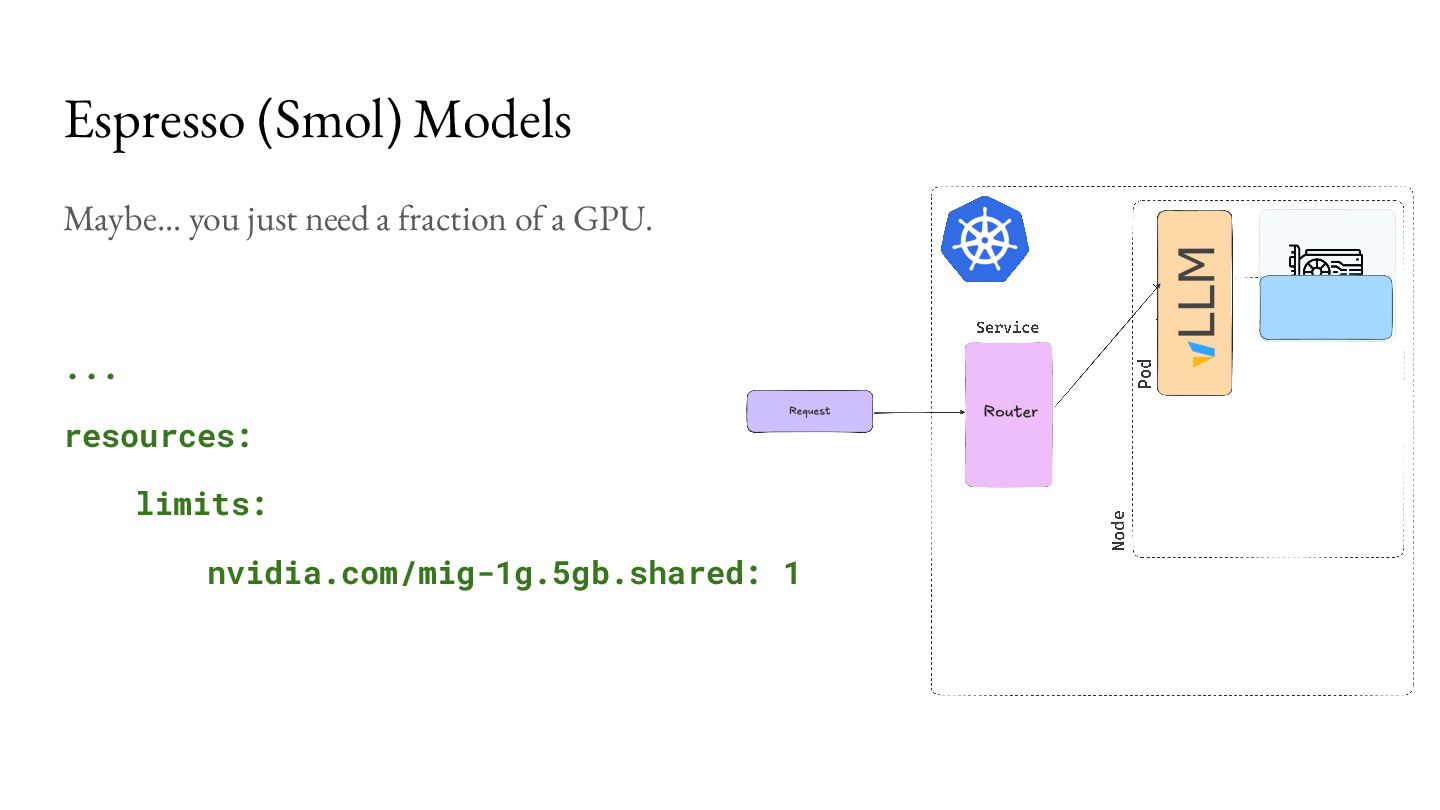
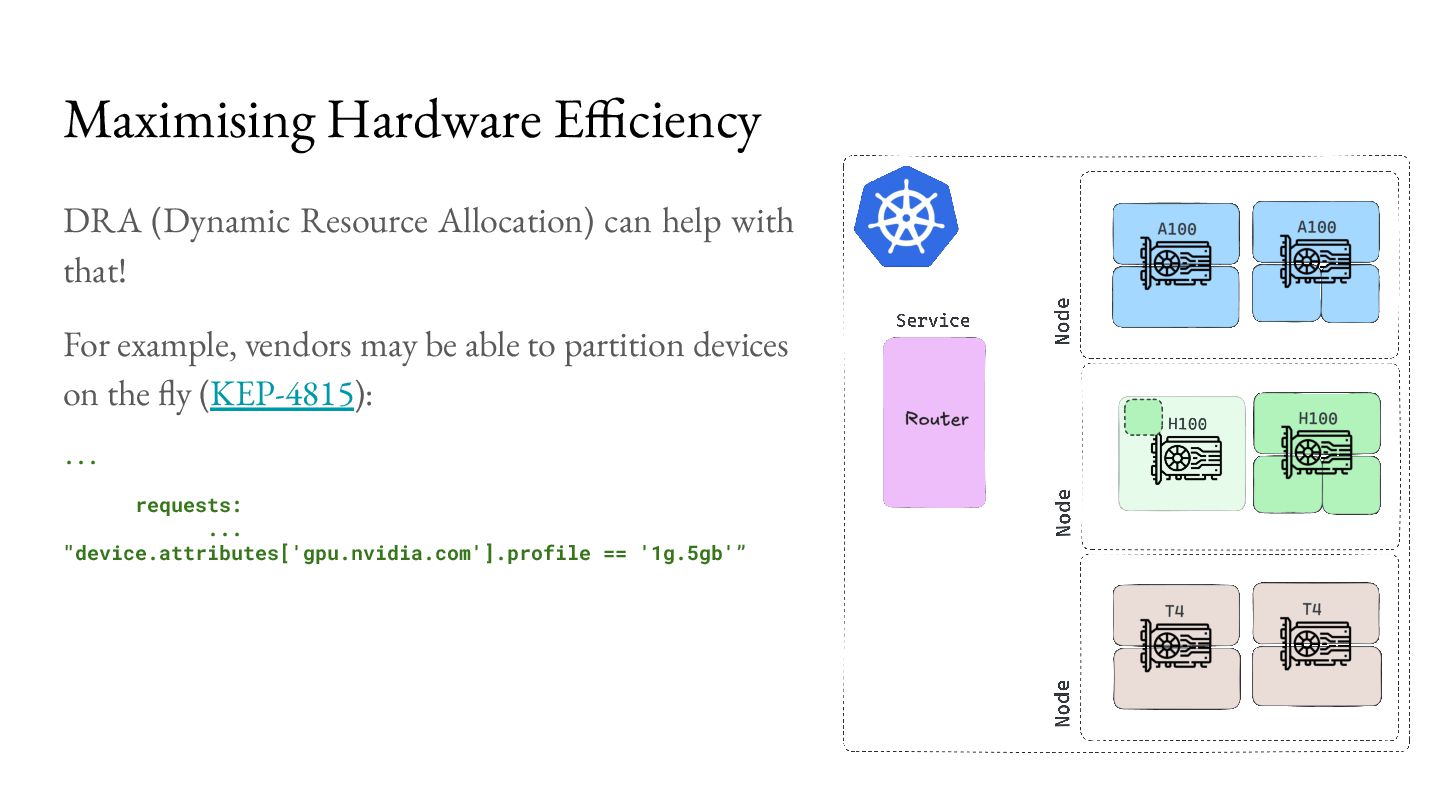
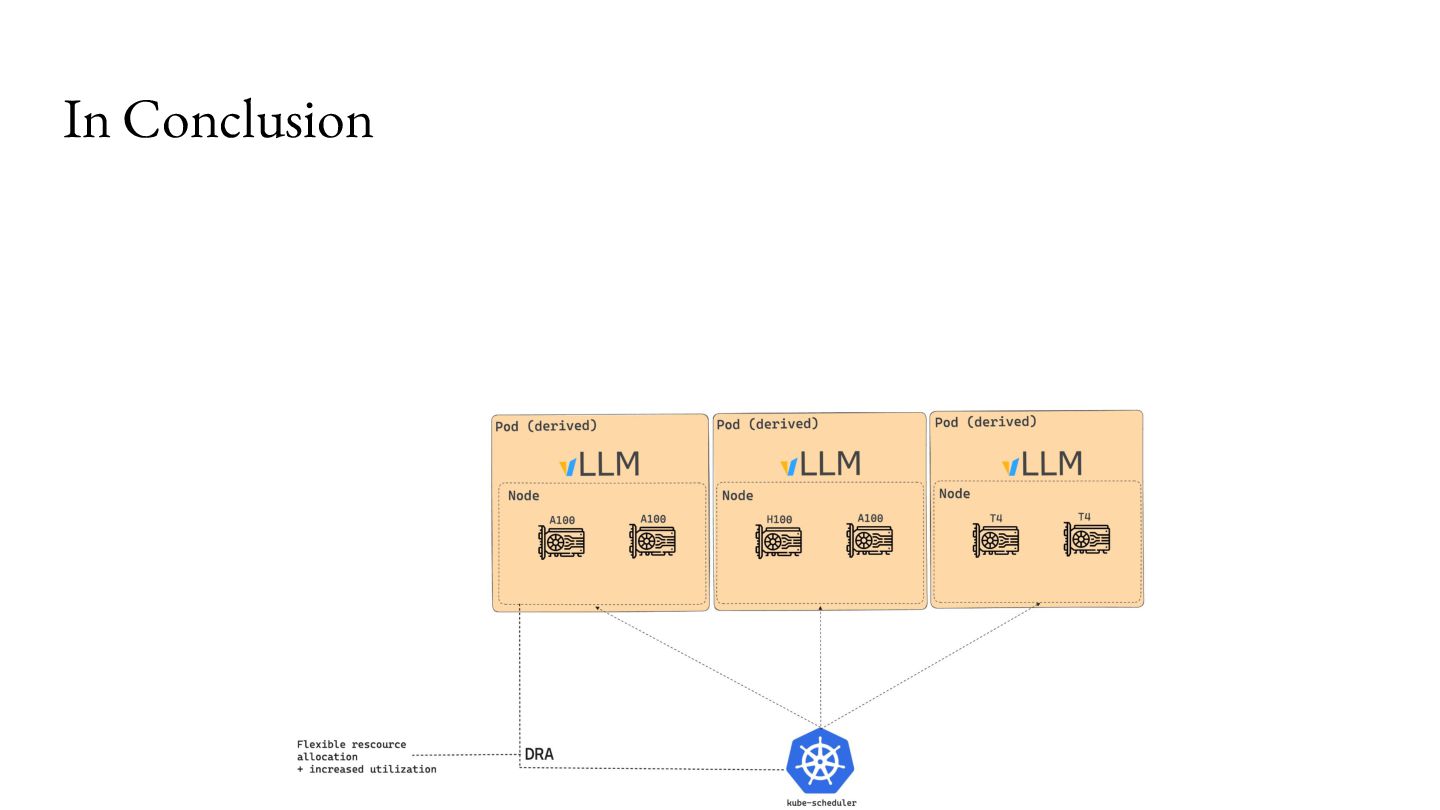
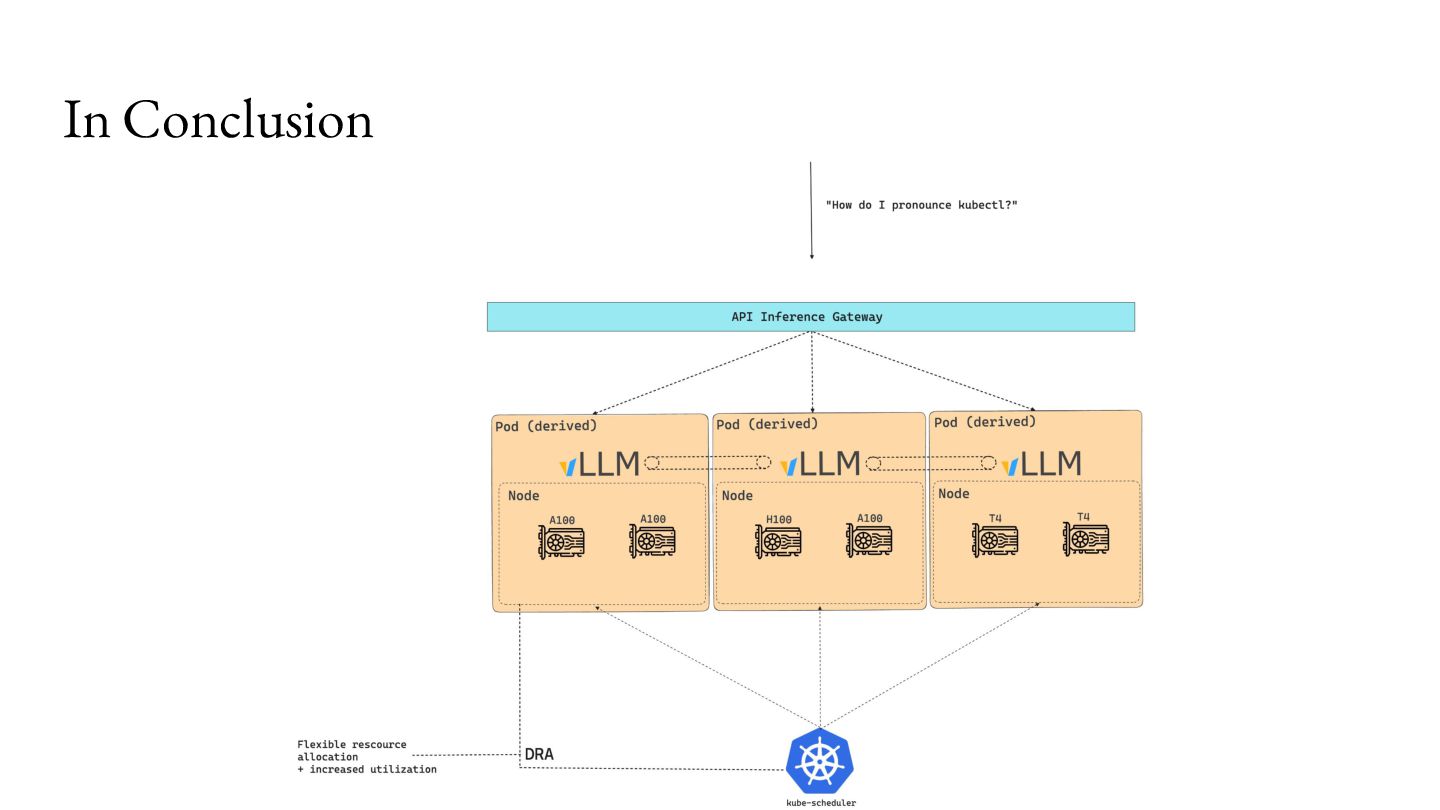
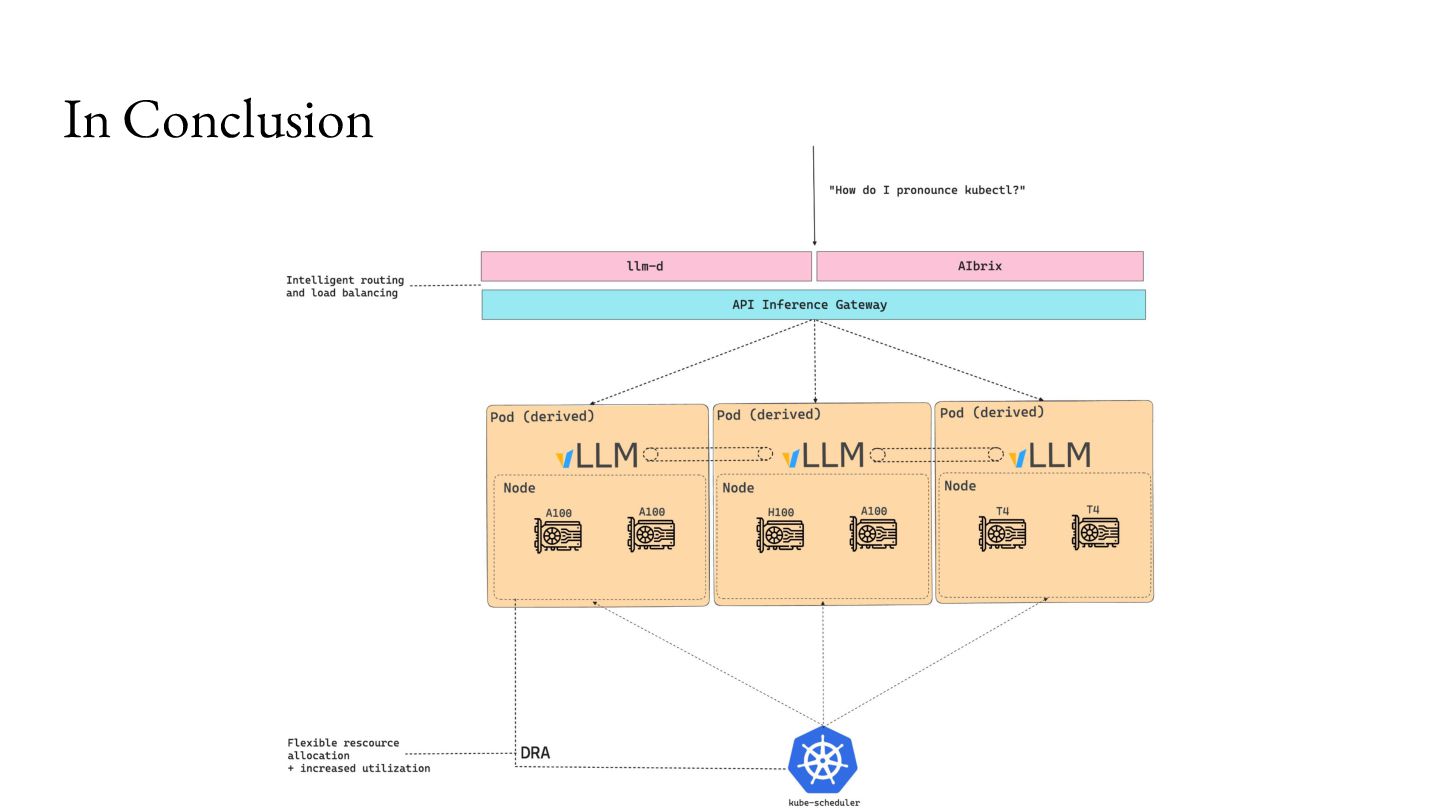
that! For example, vendors may be able to partition devices on the fly (KEP-4815): ... requests: ... "device.attributes['gpu.nvidia.com'].profile == '1g.5gb'”
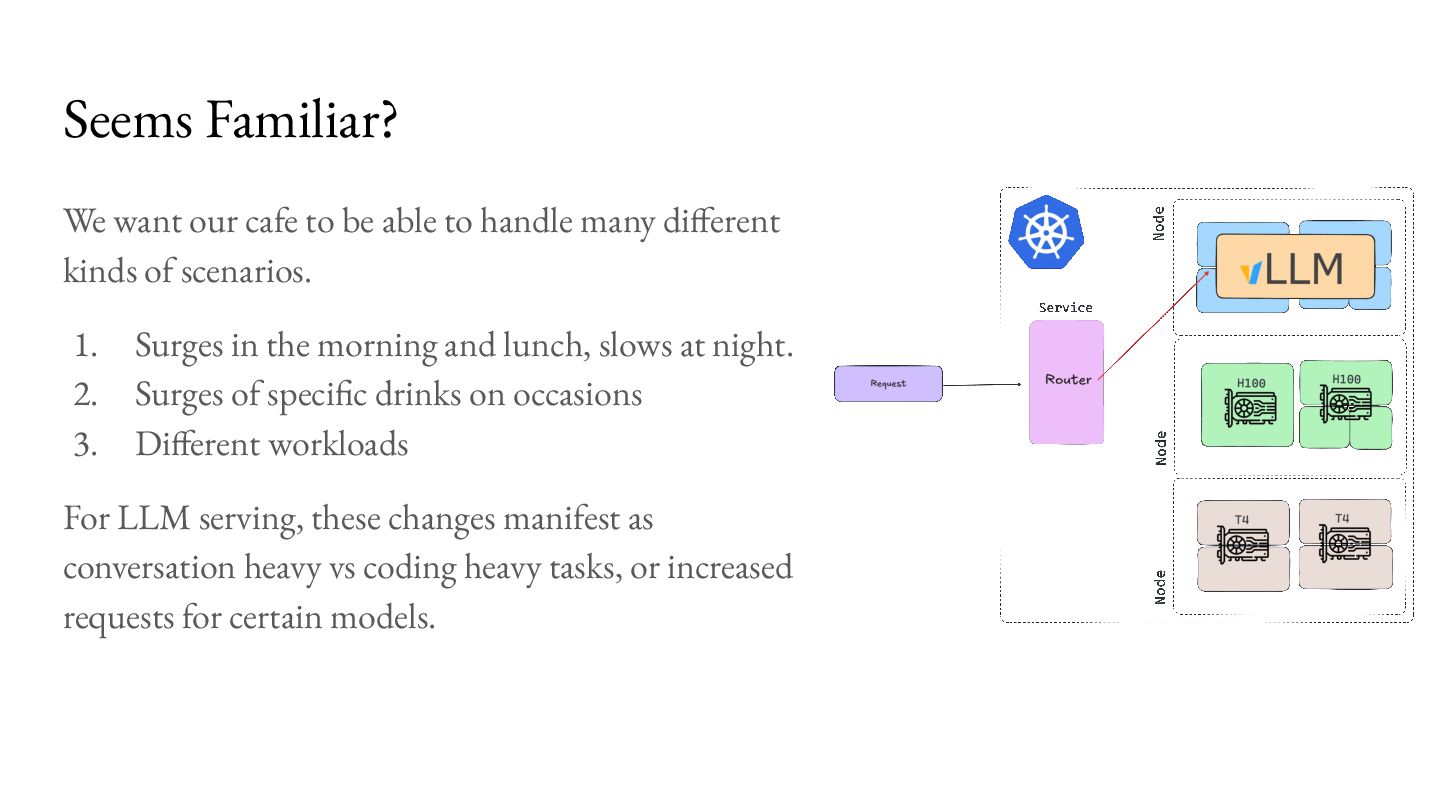
handle many different kinds of scenarios. 1. Surges in the morning and lunch, slows at night. 2. Surges of specific drinks on occasions 3. Different workloads For LLM serving, these changes manifest as conversation heavy vs coding heavy tasks, or increased requests for certain models.
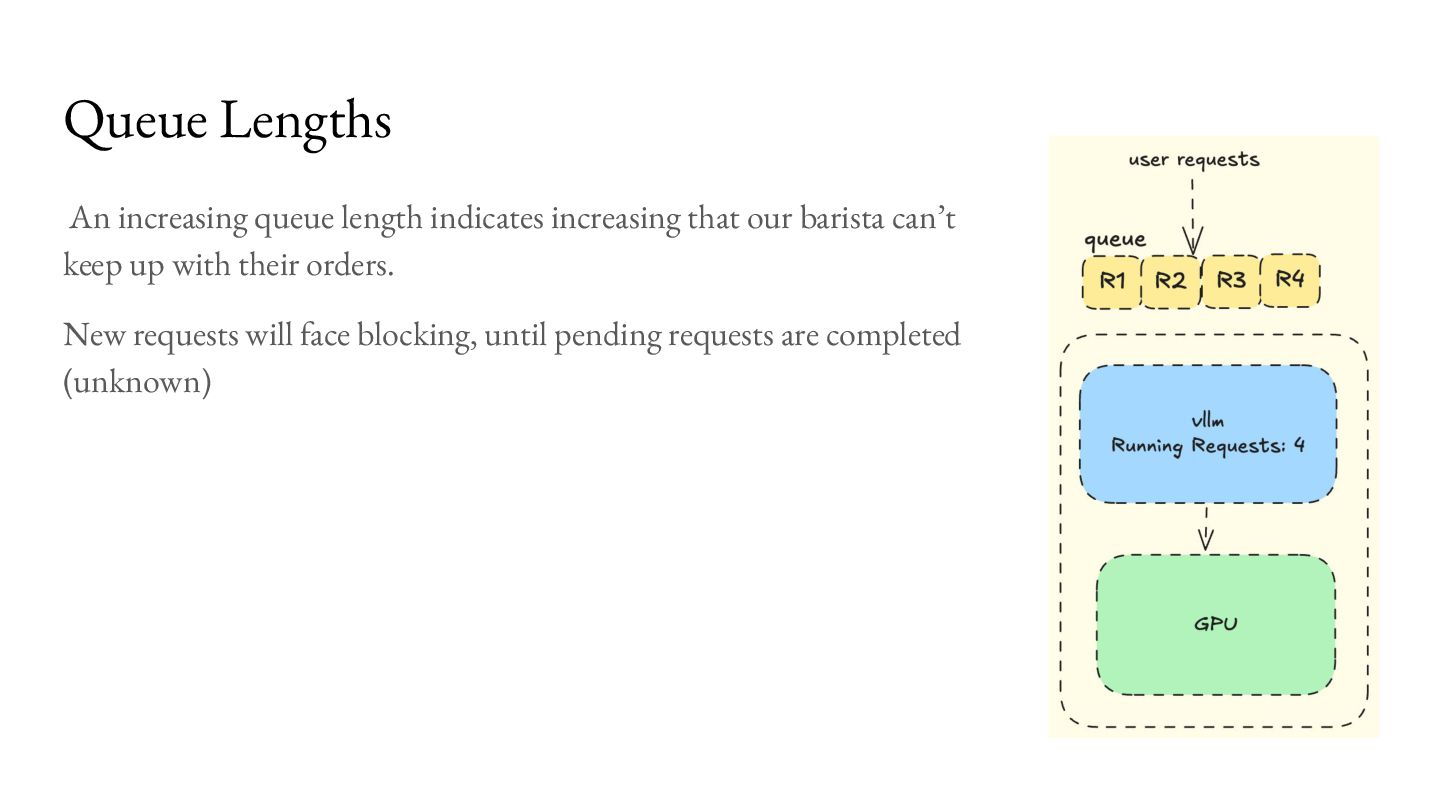
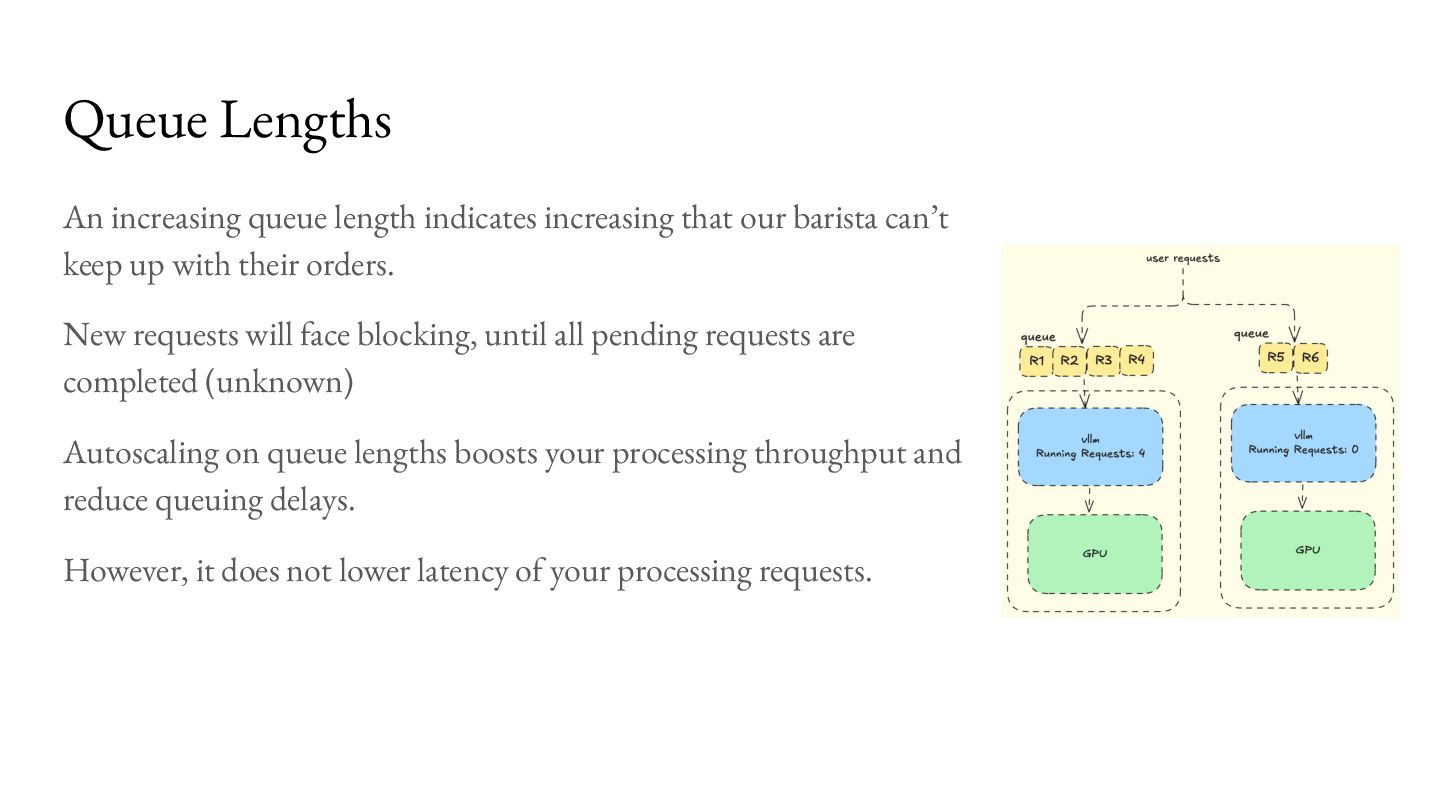
keep up with their orders. New requests will face blocking, until all pending requests are completed (unknown) Autoscaling on queue lengths boosts your processing throughput and reduce queuing delays. However, it does not lower latency of your processing requests. Queue Lengths
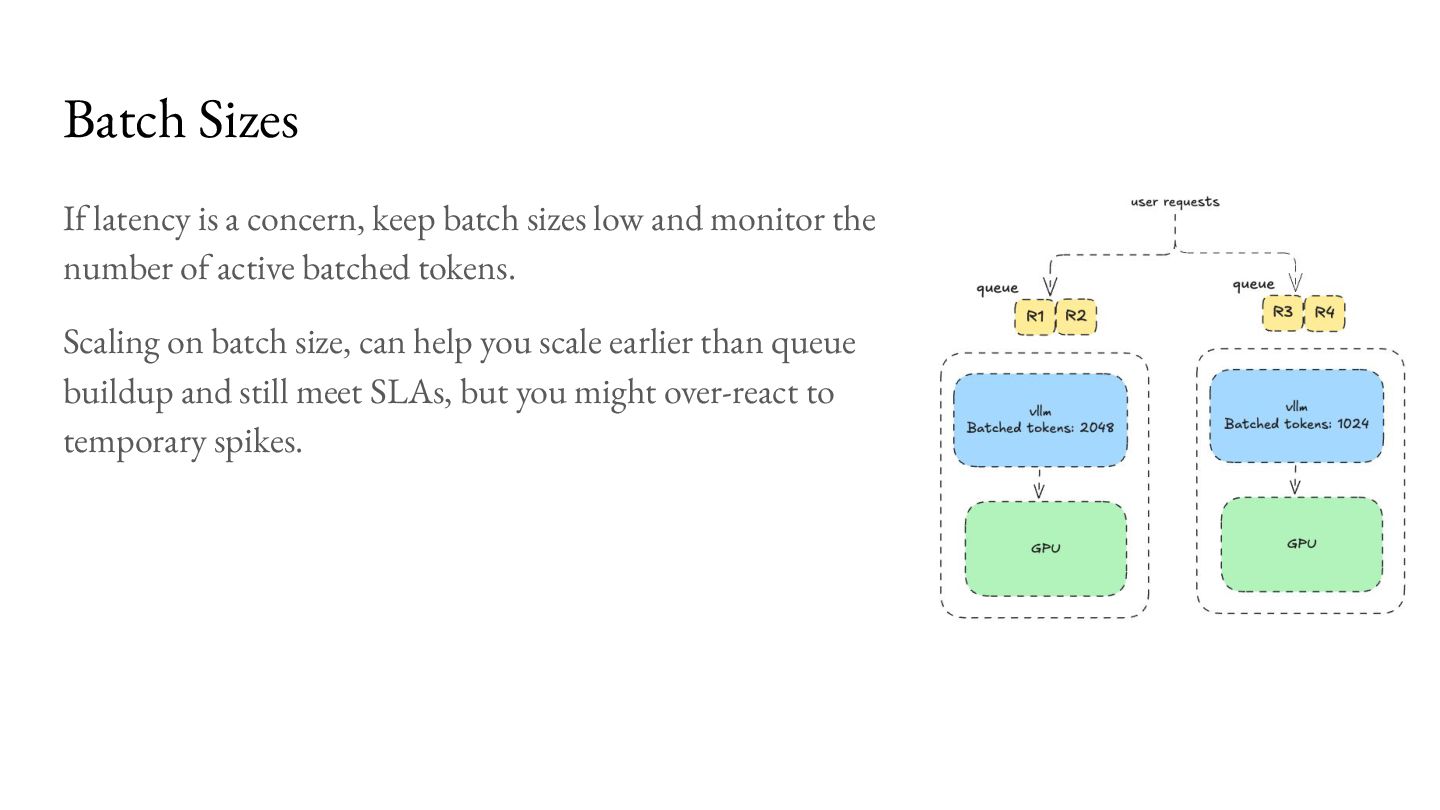
low and monitor the number of active batched tokens. Scaling on batch size, can help you scale earlier than queue buildup and still meet SLAs, but you might over-react to temporary spikes.
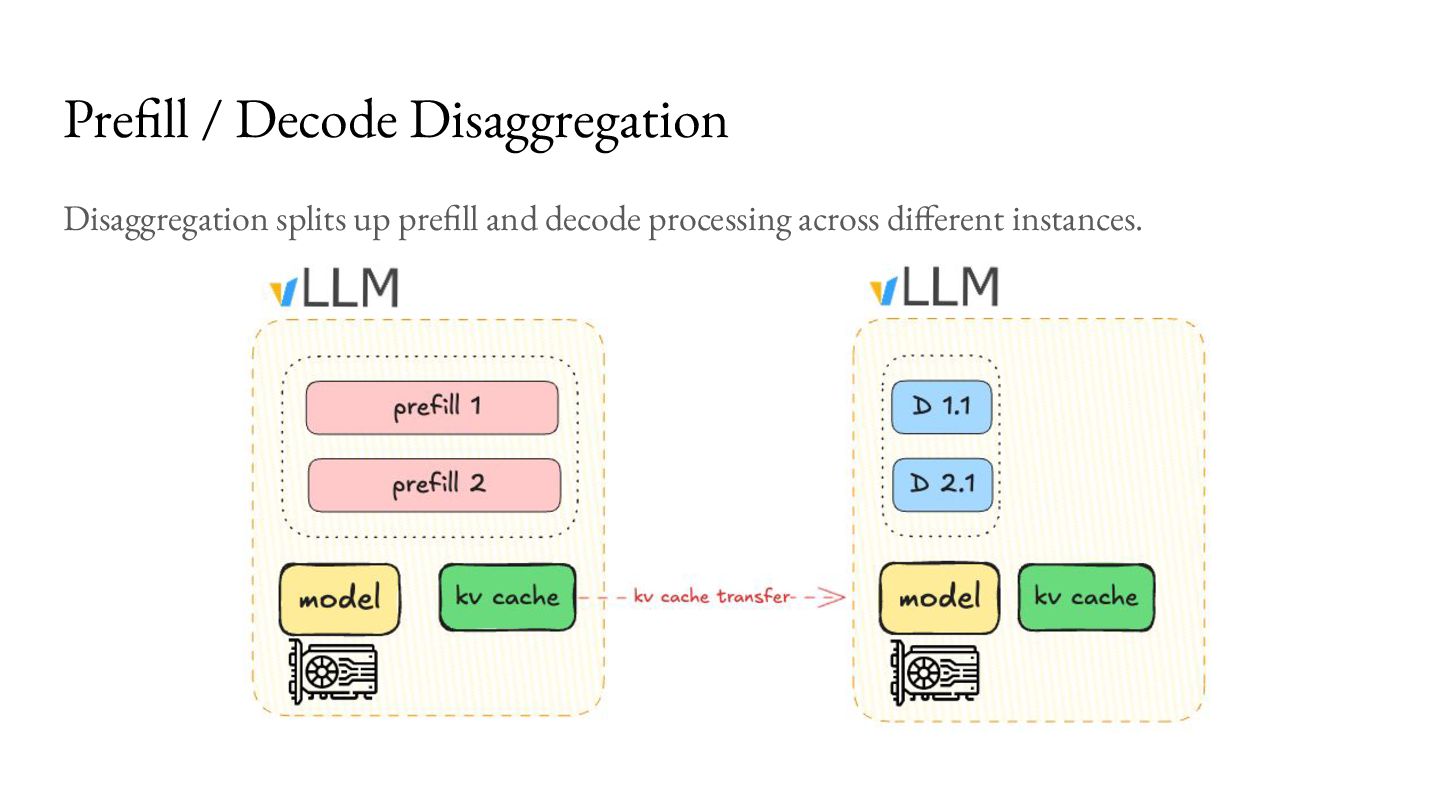
options for scaling: 1. Scale up P:D instances keeping the ratio constant a. Good for increased requests for constant workload 2. Scale up individual P or D instances a. Good if you don’t have a lot of GPUs, or if you workload has shifted. Prefill Decode Disaggregation
main bottleneck. 1. Reactive: Monitor Scale if KV cache utilization exceeds a threshold. 2. Proactive: Use your workload to estimate how much KV cache you need to serve requests while meeting SLAs Memory available 40GB Model Weights (FP16) 16GB KV Cache per request 1GB
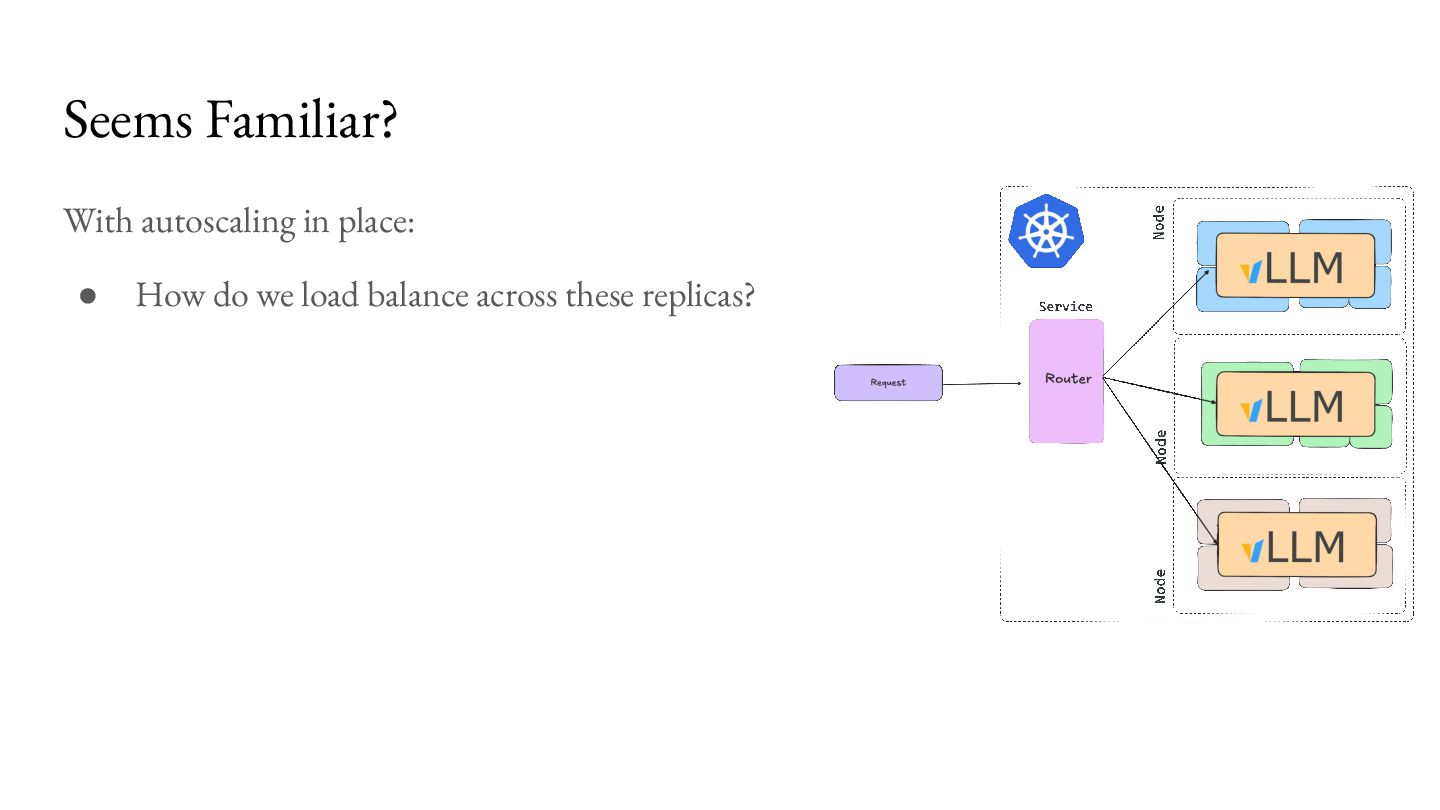
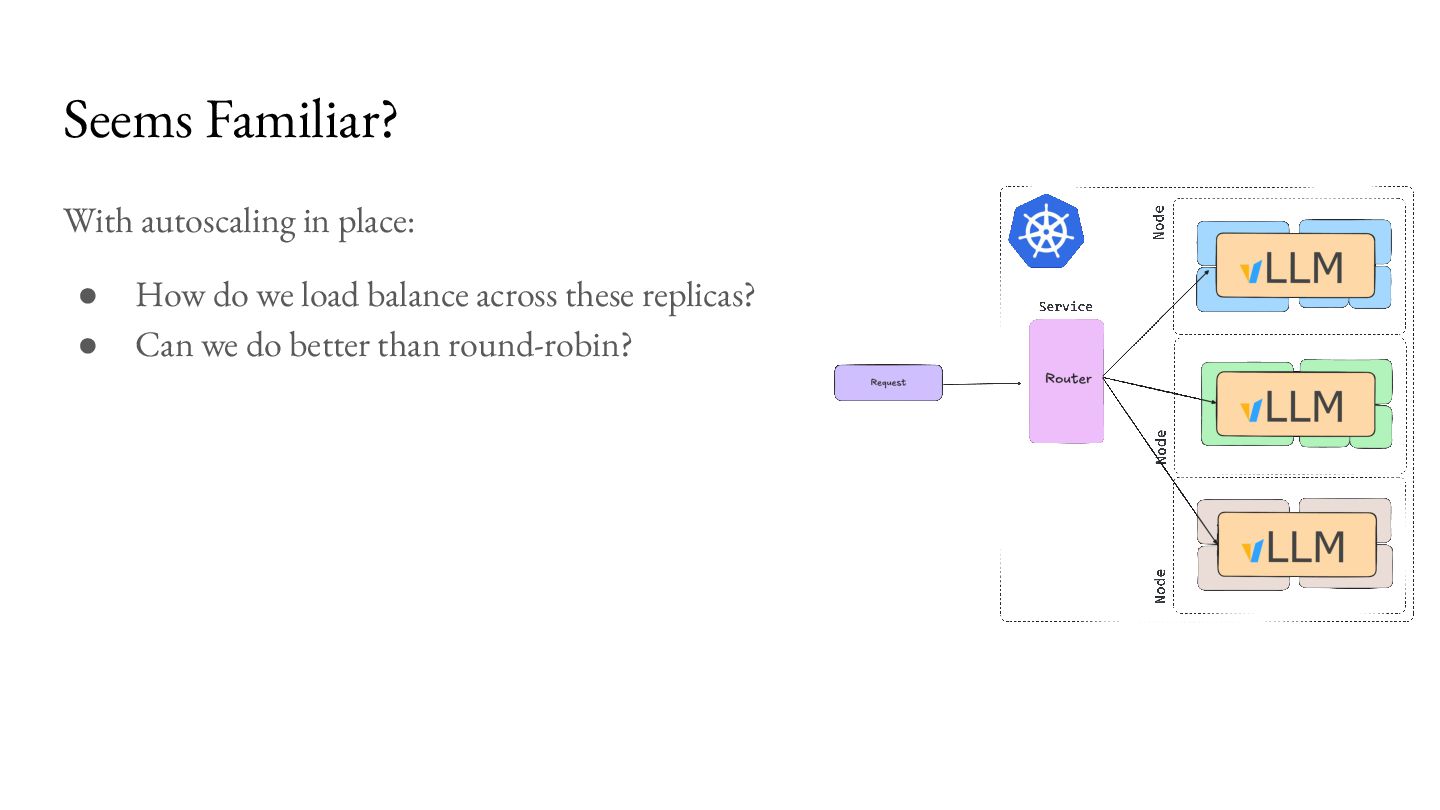
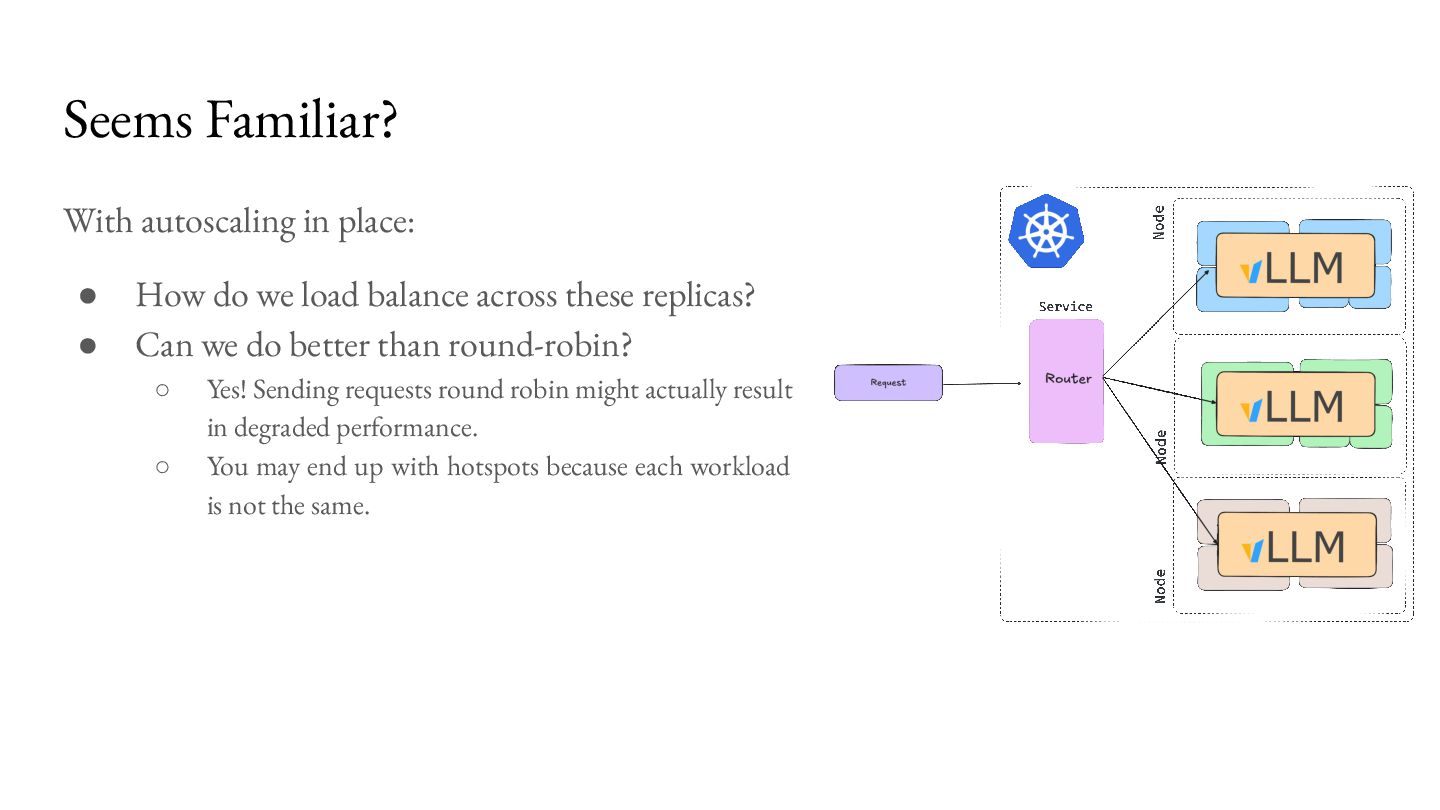
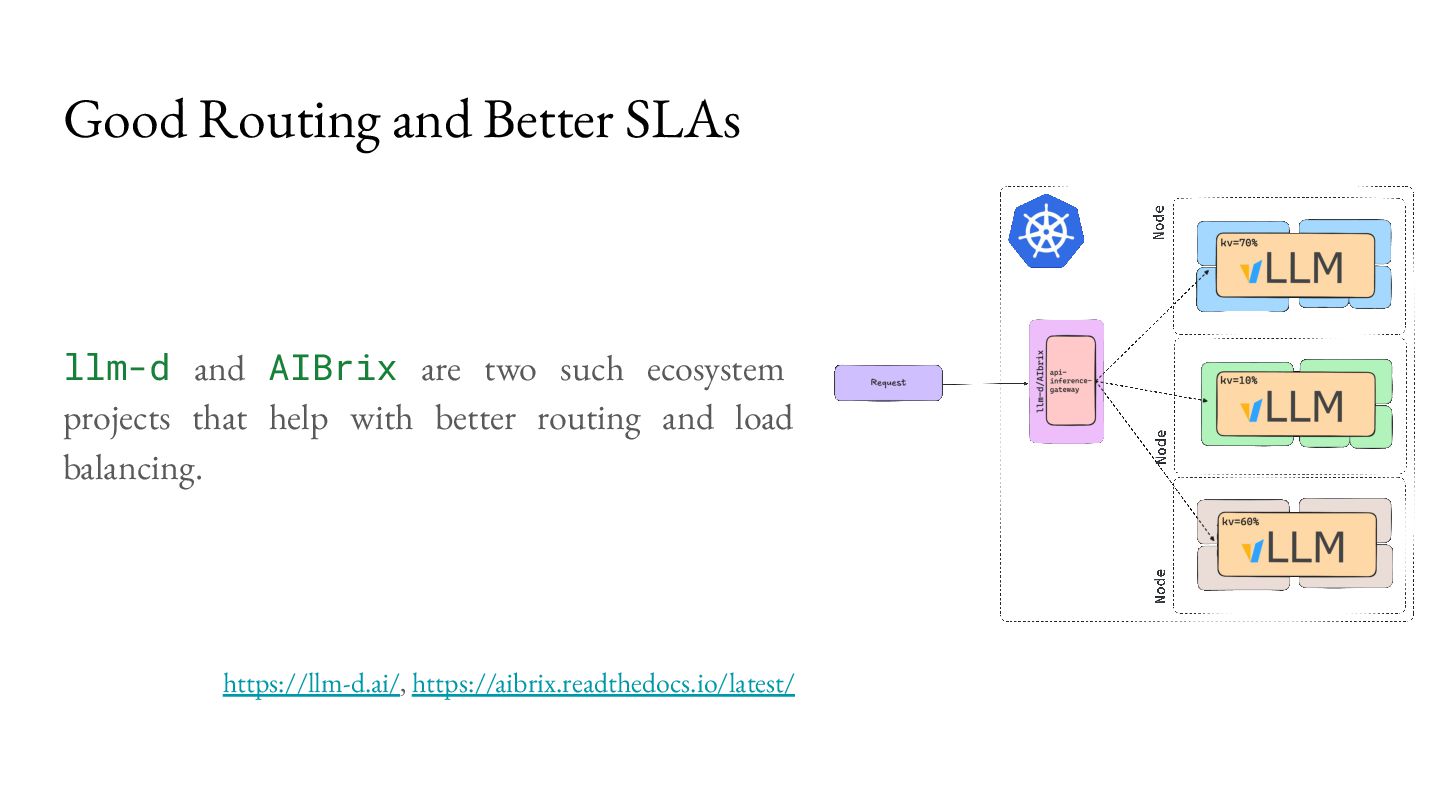
load balance across these replicas? • Can we do better than round-robin? ◦ Yes! Sending requests round robin might actually result in degraded performance. ◦ You may end up with hotspots because each workload is not the same.
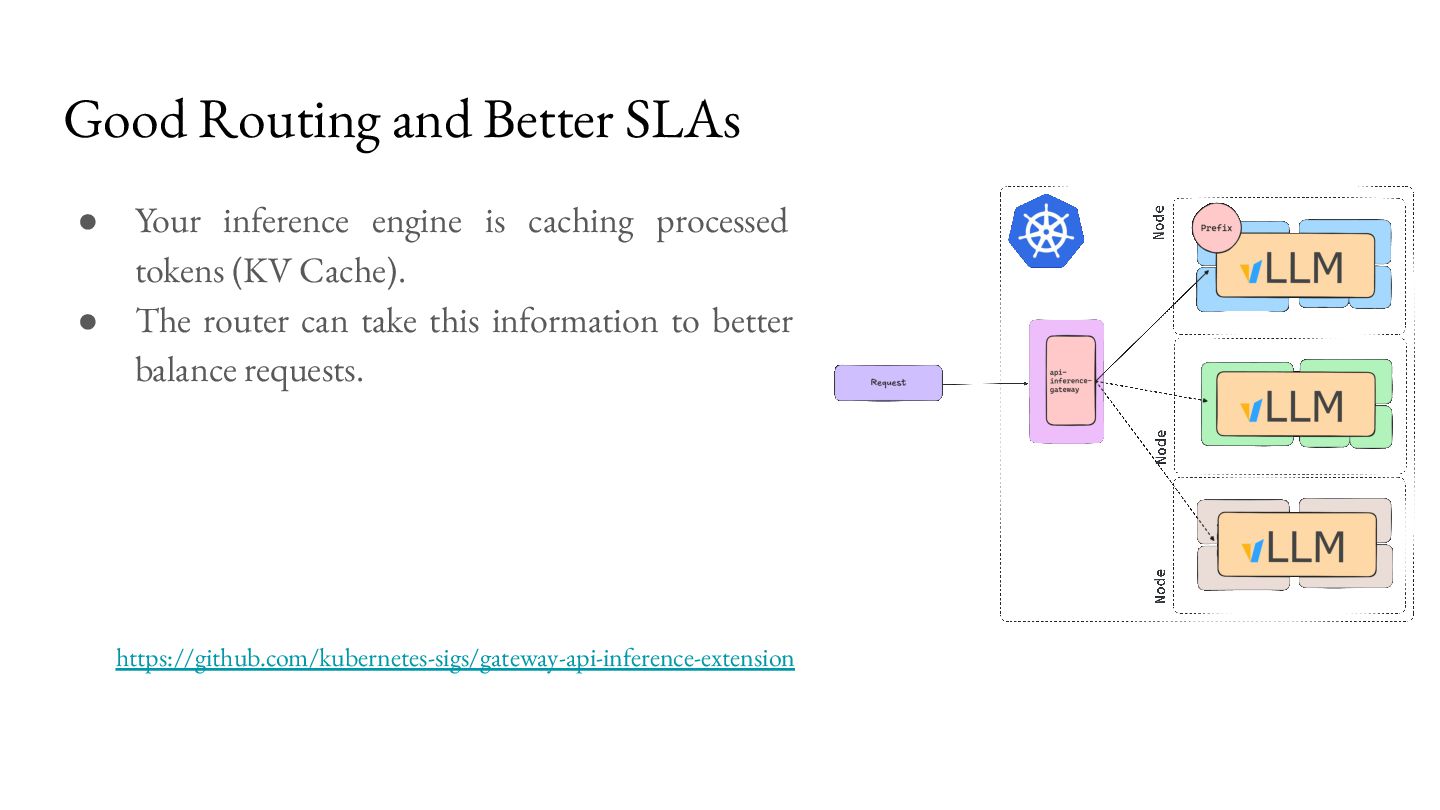
caching processed tokens (KV Cache). • The router can take this information to better balance requests. https://github.com/kubernetes-sigs/gateway-api-inference-extension
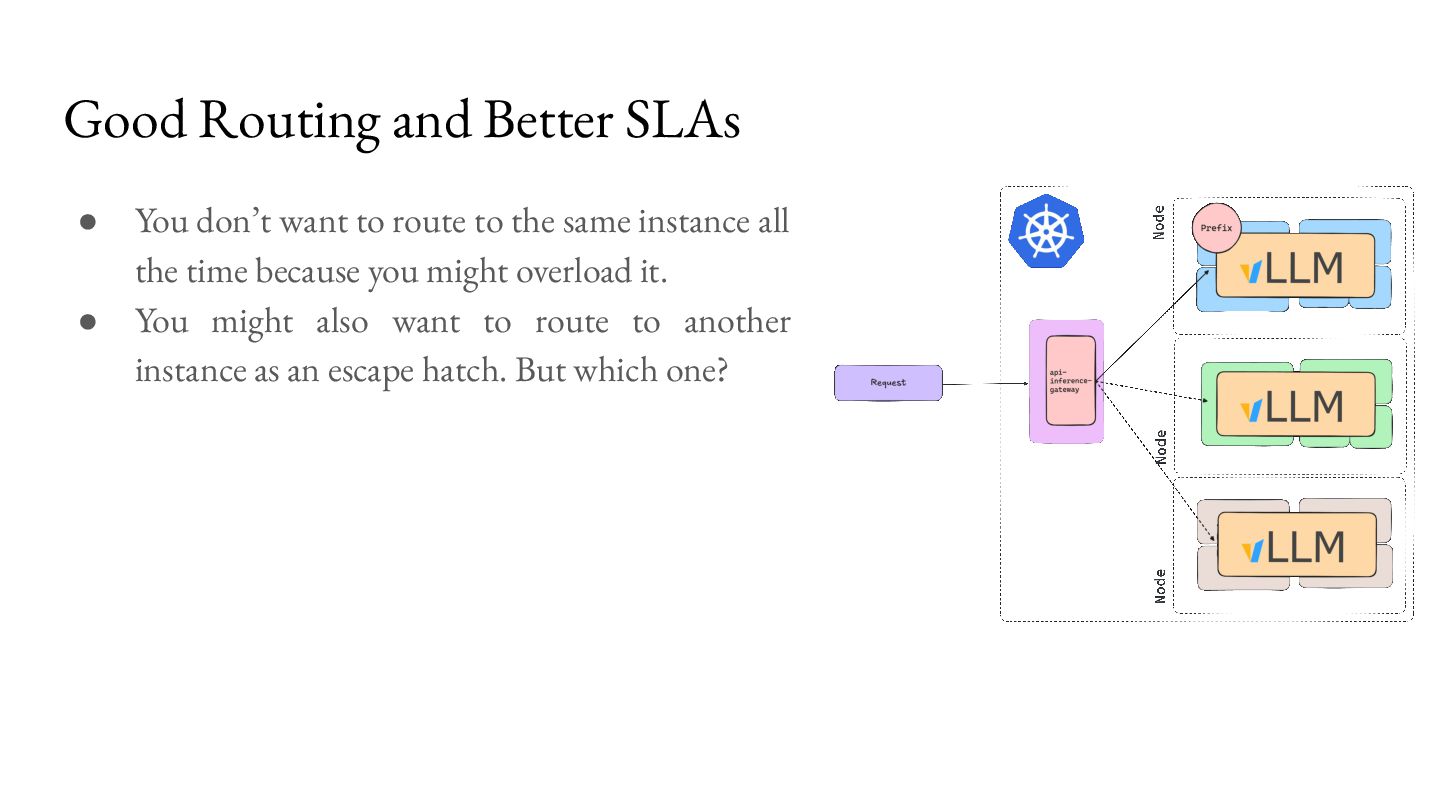
route to the same instance all the time because you might overload it. • You might also want to route to another instance as an escape hatch. But which one?
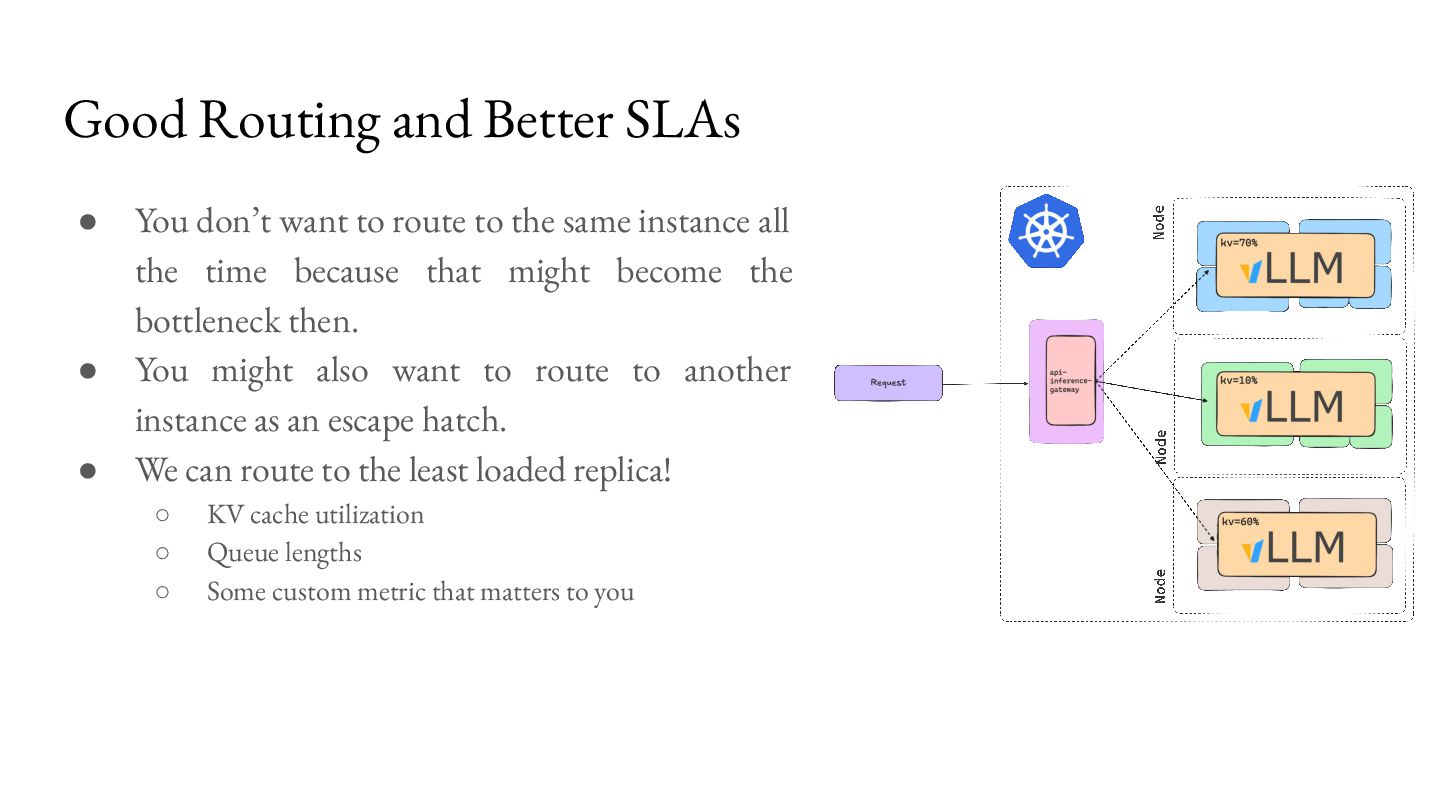
route to the same instance all the time because that might become the bottleneck then. • You might also want to route to another instance as an escape hatch. • We can route to the least loaded replica! ◦ KV cache utilization ◦ Queue lengths ◦ Some custom metric that matters to you
be proficient in language modelling and that when you try to work with these systems you can ground yourself in the fact that serving LLMs is as tractable as serving coffee!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}