we experts in the history and implementation of the Go runtime? ◦ No. • Are we experts in the Linux Kernel? ◦ No. • Why attend this talk? ◦ Minimum takeaway: internals of the performance of the Go scheduler + what is eBPF and how it works. ◦ If you’re feeling dangerously adventurous: some ideas around optimising latency at the OS scheduler level. ◦ More of “let’s look for solutions searching for a problem”.
Extremely complex codebase, but that isn’t the only problem • Come up with approach • Develop it, have it accepted into the Linux kernel (months!) • Long time before the kernel with your patch is even adopted by all linux distros.
Extremely complex codebase, but that isn’t the only problem • Come up with approach • Develop it, have it accepted into the Linux kernel (months!) • Long time before the kernel with your patch is even adopted by all linux distros. • Oops, the requirements changed!
Is it safe to run? The eBPF Verifier! • Makes sure the program exits safely • Only access memory that it is supposed to access Still, only run eBPF programs from verifiable sources
programs can be loaded and removed dynamically, doesn’t matter if your application was running before. • Instantly gets visibility over everything that's happening in the machine
programs can be loaded and removed dynamically, doesn’t matter if your application was running before. • Instantly gets visibility over everything that's happening in the machine • Create new functionality very quickly without all Linux users having to accept the changes.
in bytecode format (Object file) • eBPF programs can't be written in high level languages, why? 1. The compiler needs to emit bytecode format, not languages support this
in bytecode format (Object file) • eBPF programs can't be written in high level languages, why? 1. The compiler needs to emit bytecode format, not languages support this 2. Can’t have runtime features (Garbage Collection, Scheduling, etc)
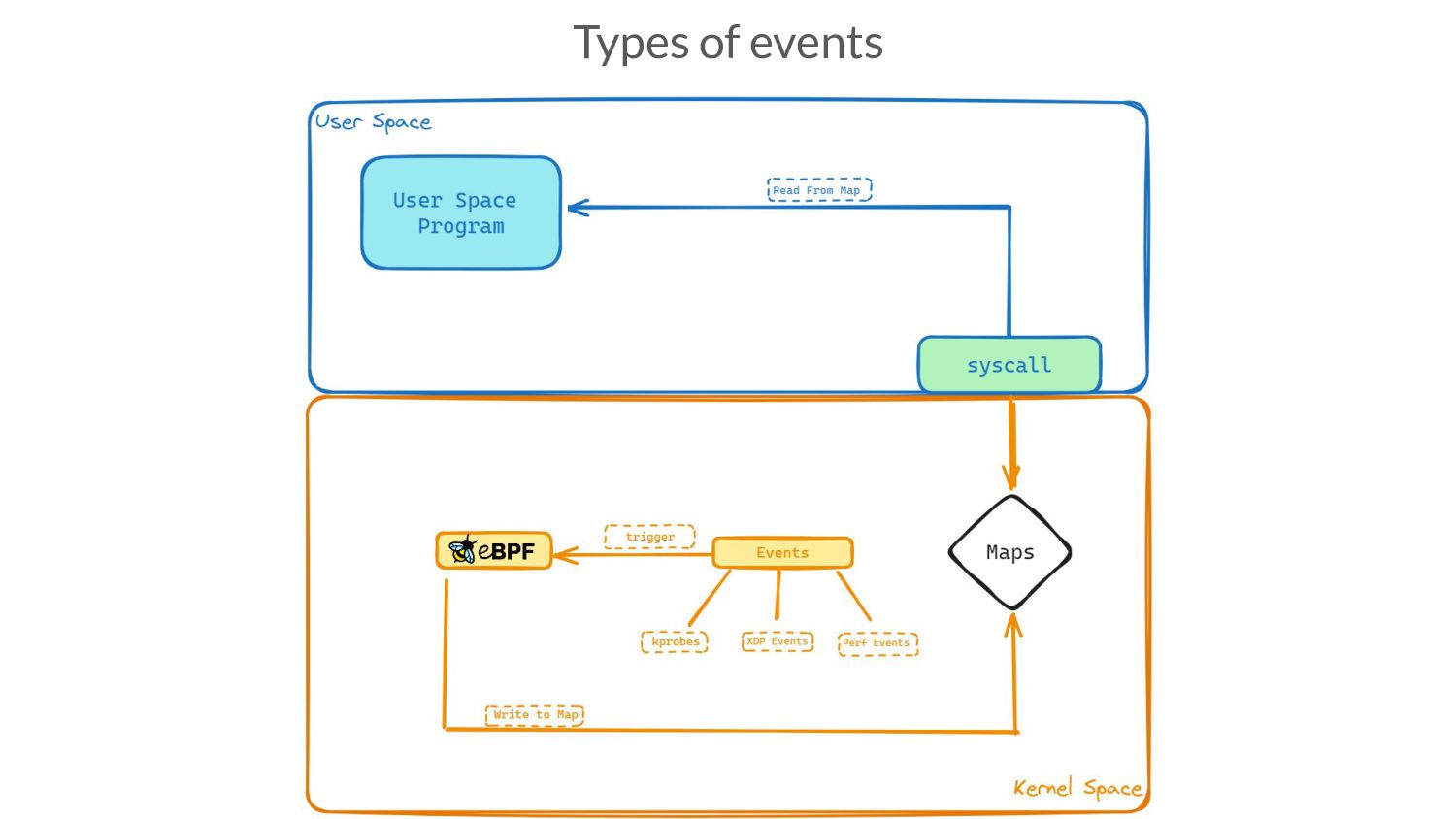
version. • There are also kernel function “entry” and “exit” points (name explains what that means). These are called kprobes and kretprobes (newer kernel versions call this fentry/fexit) • Can also be hooked to userspace functions called uprobes/uretprobes
version. • There are also kernel function “entry” and “exit” points (name explains what that means). These are called kprobes and kretprobes (newer kernel versions call this fentry/fexit) • Can also be hooked to userspace functions called uprobes/uretprobes • Network interface hooks, XDP
version. • There are also kernel function “entry” and “exit” points (name explains what that means). These are called kprobes and kretprobes (newer kernel versions call this fentry/fexit) • Can also be hooked to userspace functions called uprobes/uretprobes • Network interface hooks, XDP • Perf Events, tracepoints, etc (ie, a vast variety/amount of places to hook your eBPF program to!)
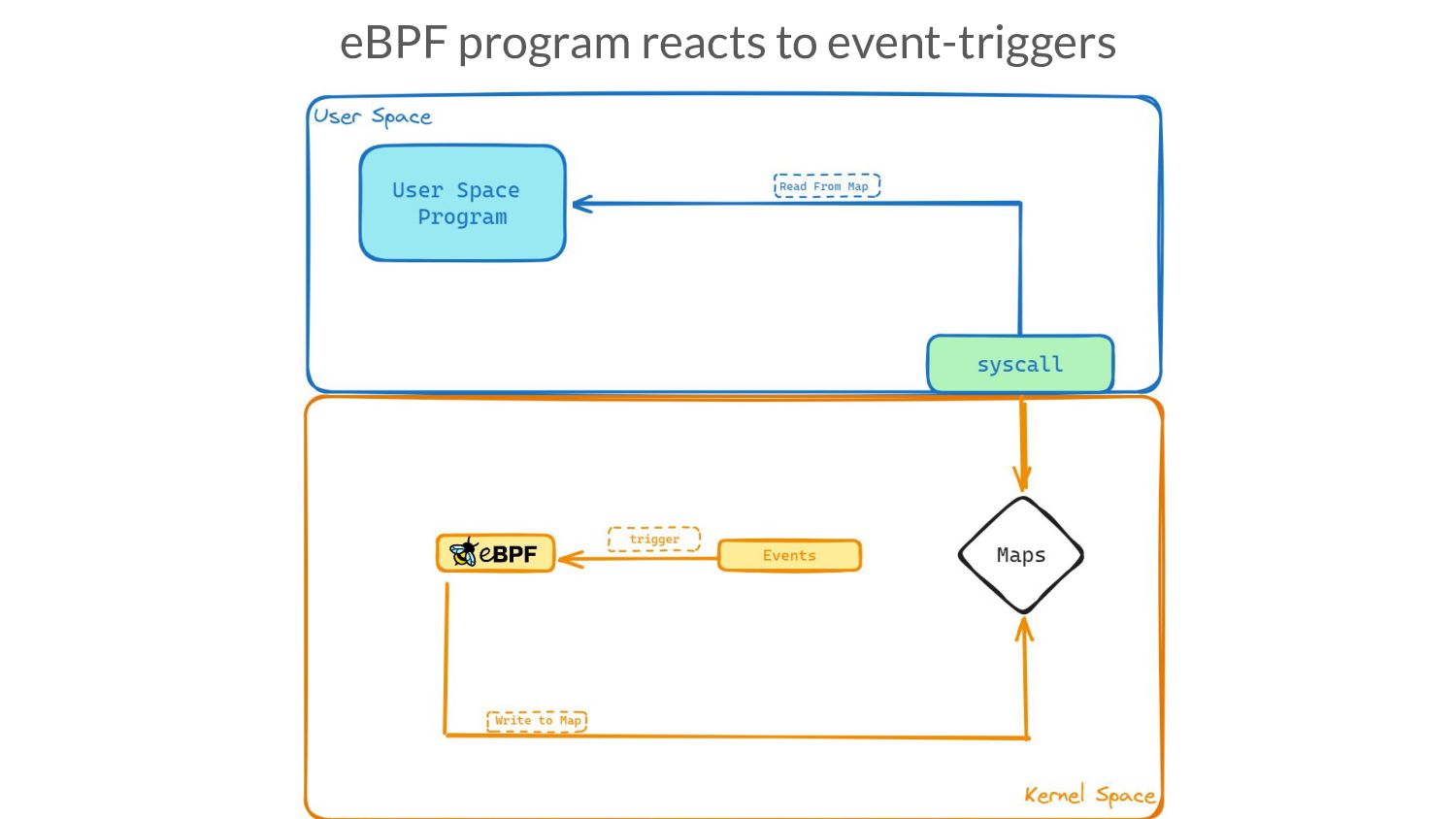
and eBPF program running in the kernel • Defined alongside ebpf programs, then loaded into kernel • Userspace program writes config info like event-registration, into them, read by eBPF
and eBPF program running in the kernel • Defined alongside ebpf programs, then loaded into kernel • Userspace program writes config info like event-registration, into them, read by eBPF • Userspace and kernel-space programs need a common understanding of data-structures stored in the map
that have a ton of eBPF programs written already for you to tinker with • Helper functions that already exist that can capture events when they occur in the kernel
that have a ton of eBPF programs written already for you to tinker with • Helper functions that already exist that can capture events when they occur in the kernel • How eBPF solves portability (Compile Once-Run Everywhere)
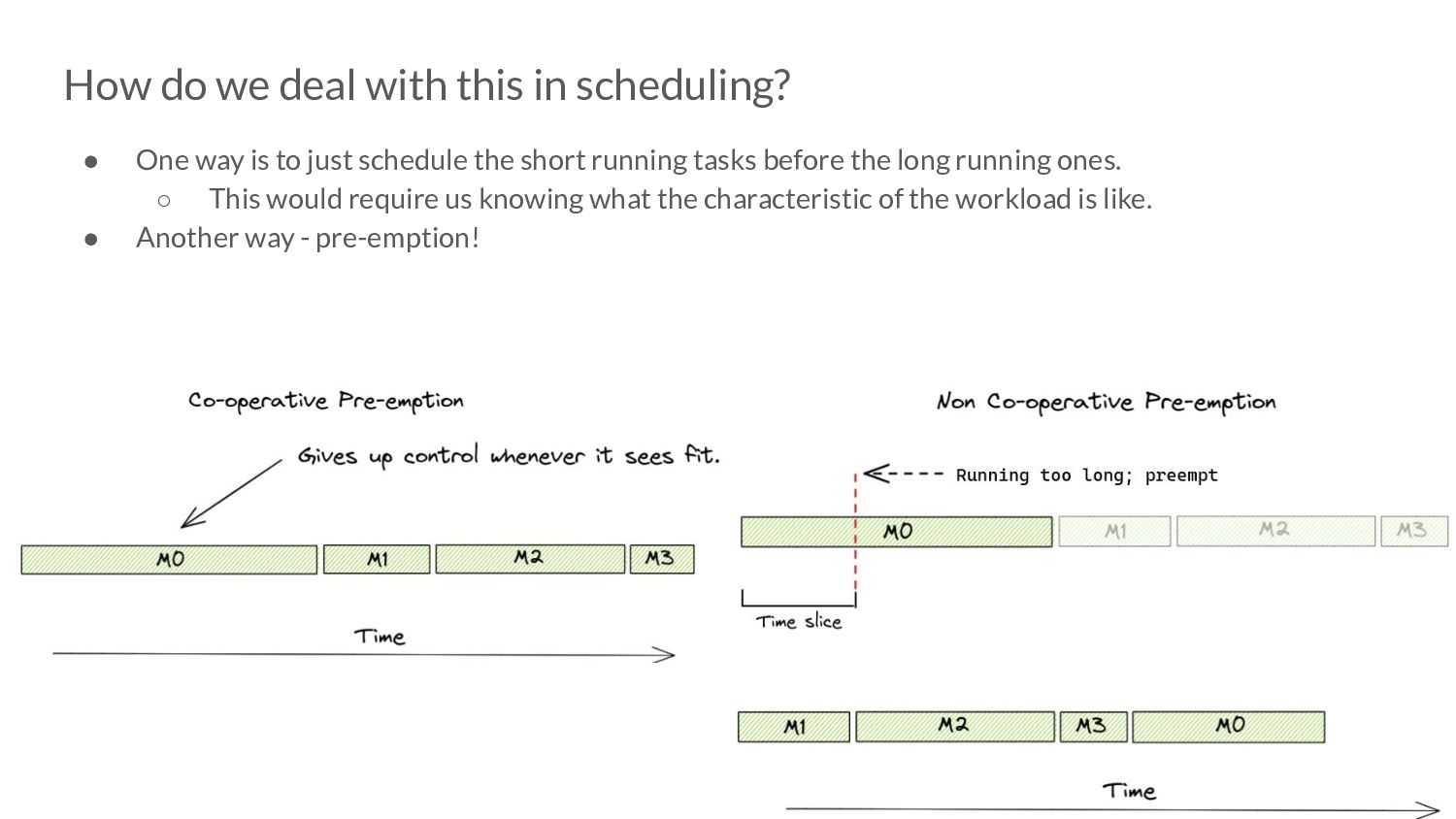
way is to just schedule the short running tasks before the long running ones. ◦ This would require us knowing what the characteristic of the workload is like. • Another way - pre-emption!
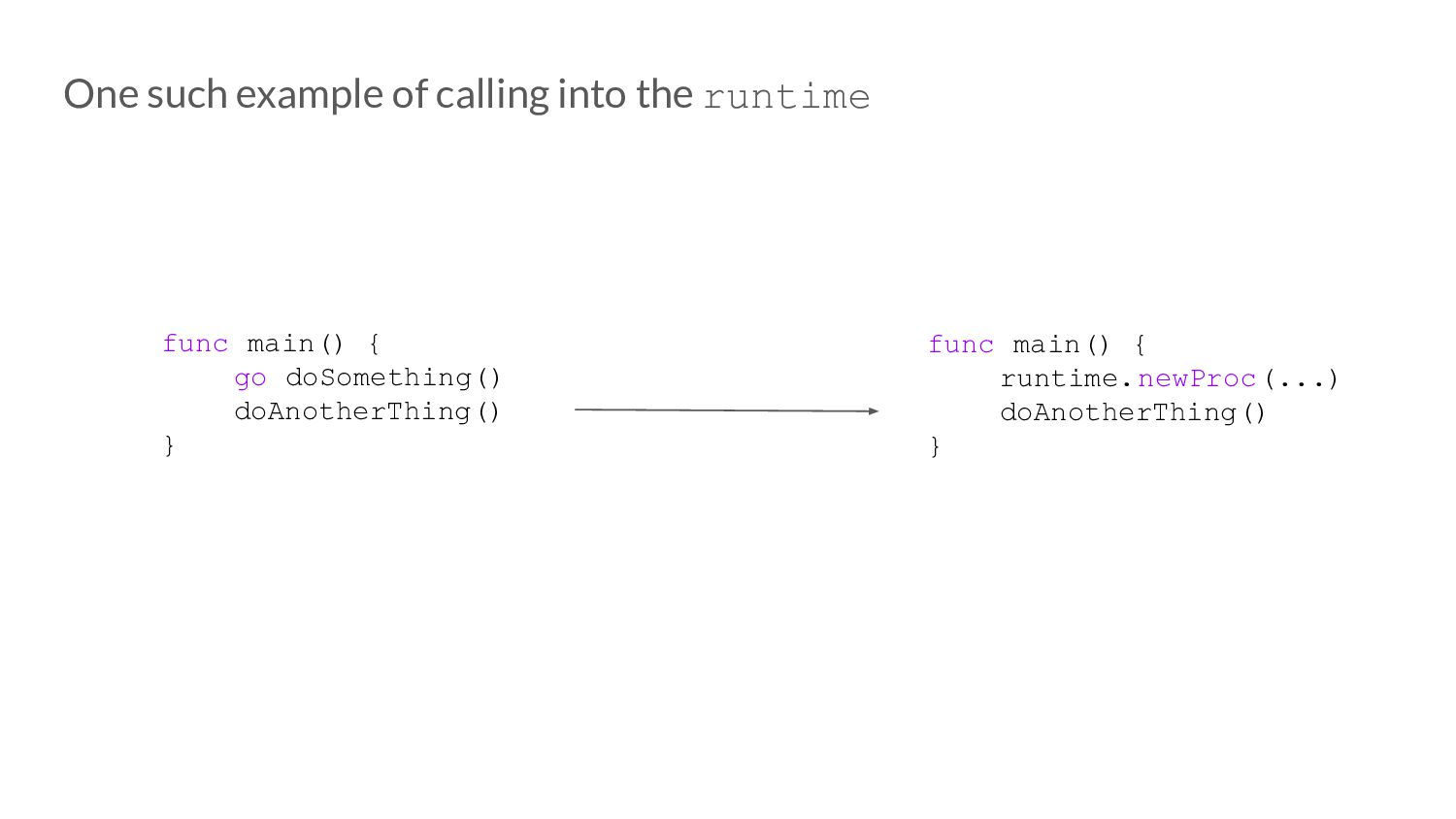
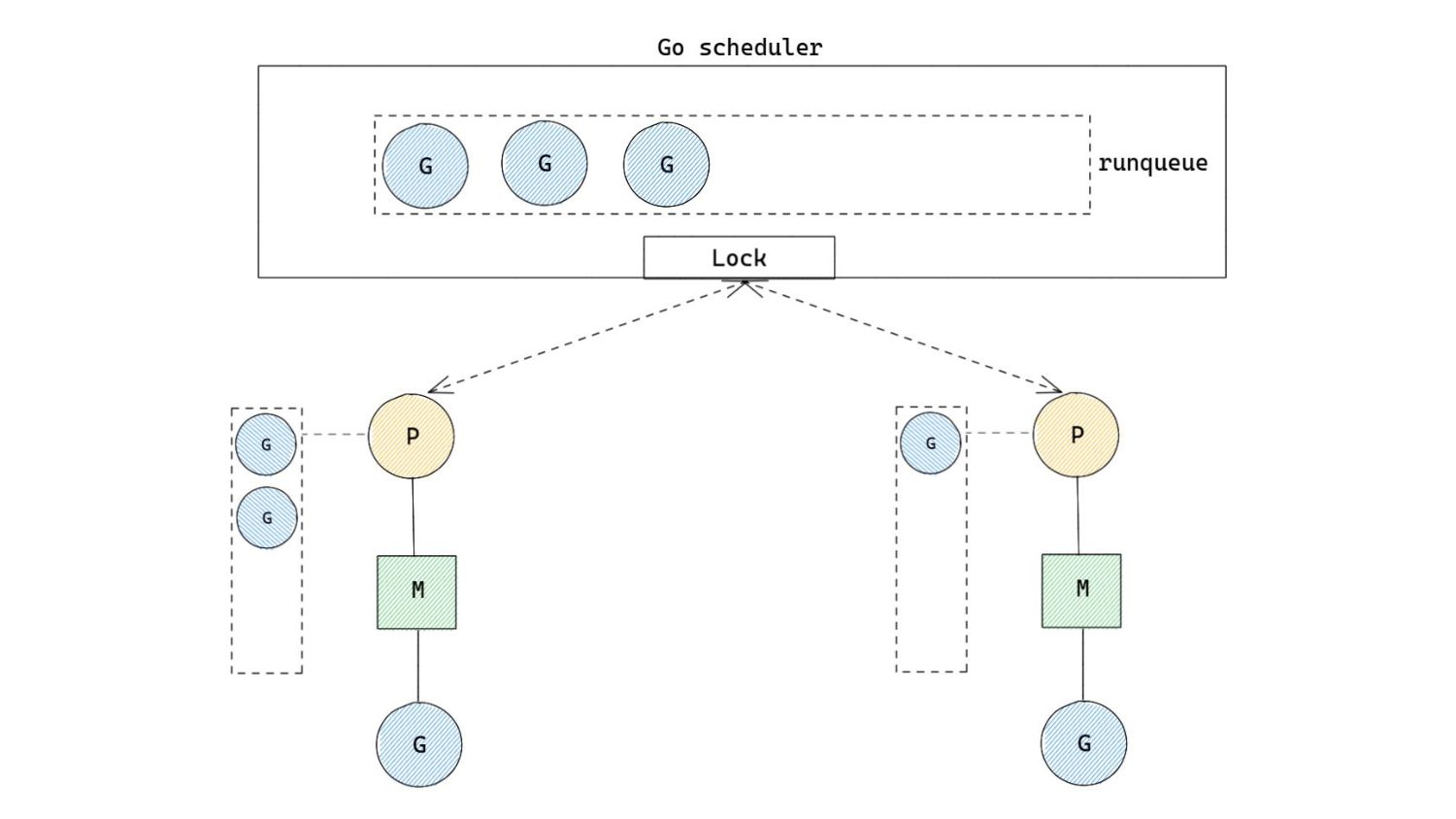
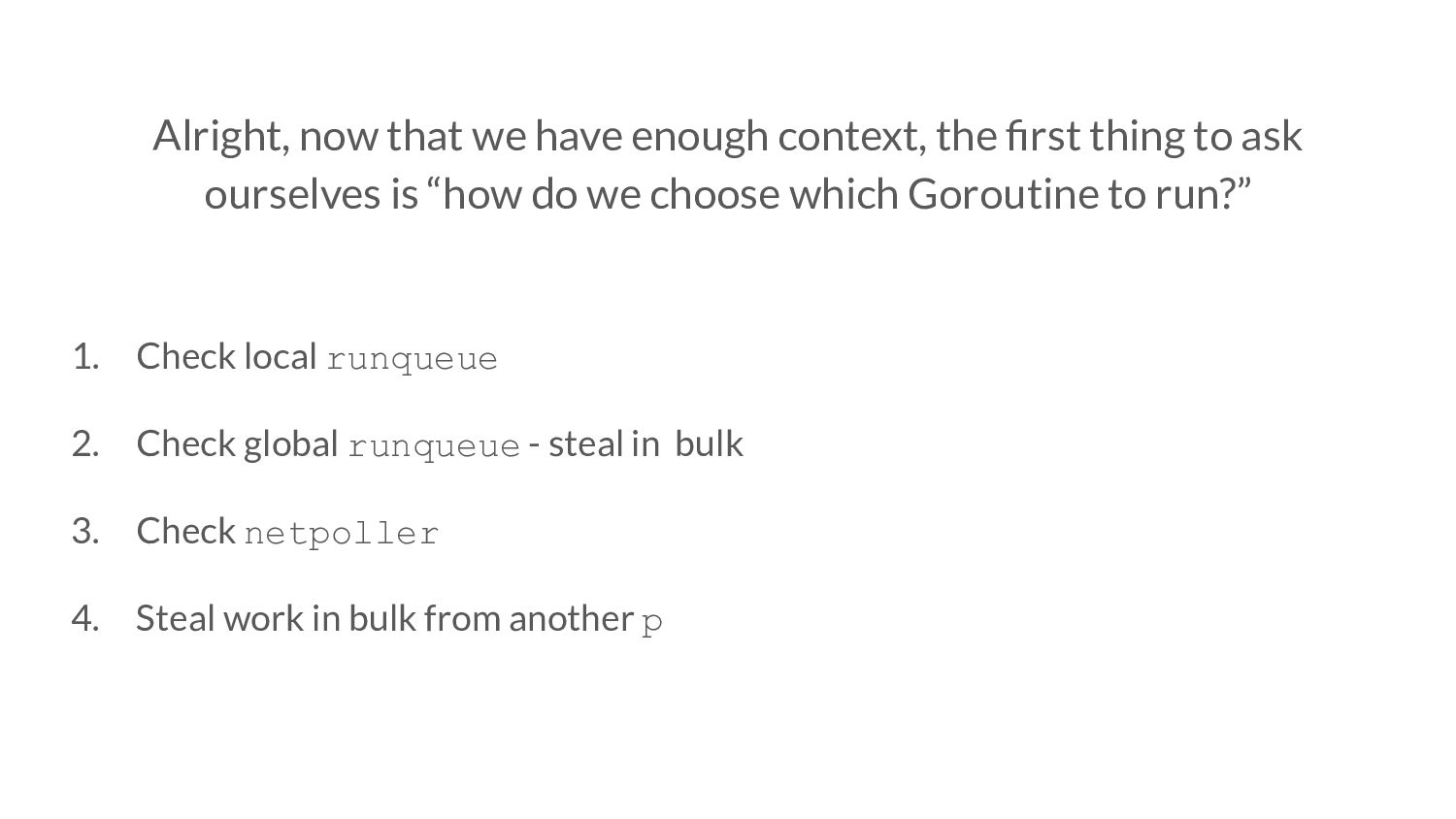
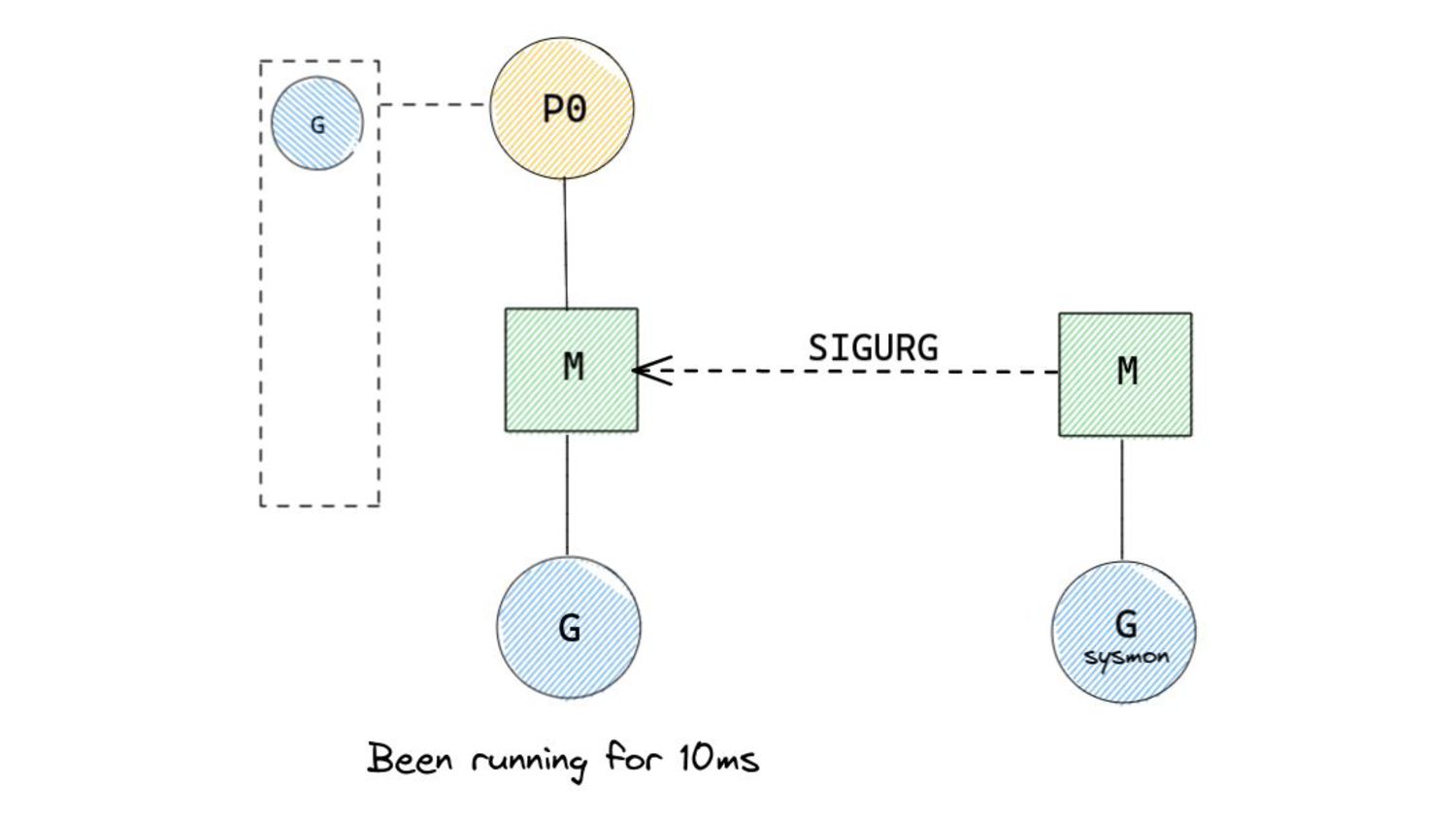
to ask ourselves is “how do we choose which Goroutine to run?” 1. Check local runqueue 2. Check global runqueue - steal in bulk 3. Check netpoller 4. Steal work in bulk from another p
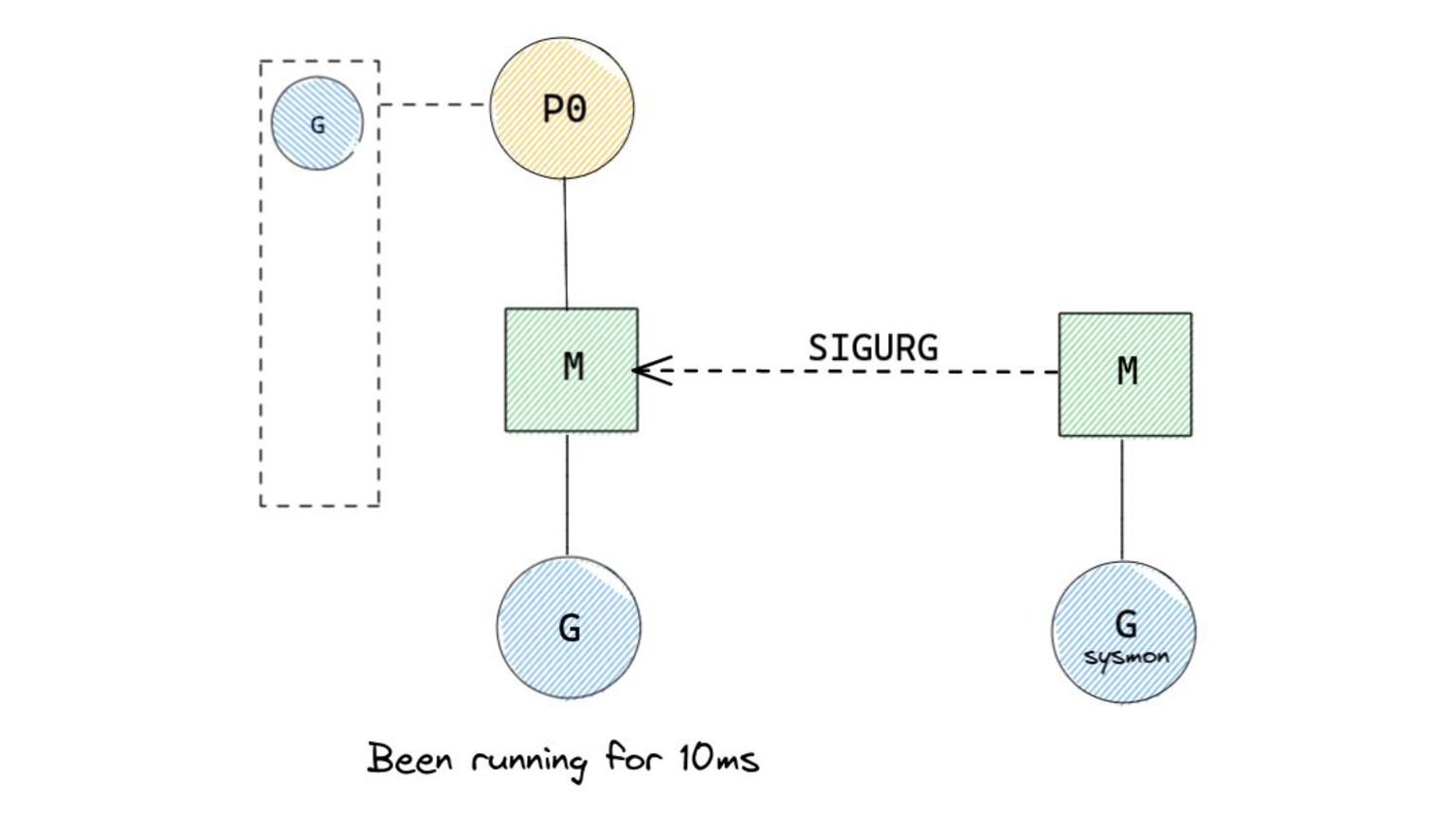
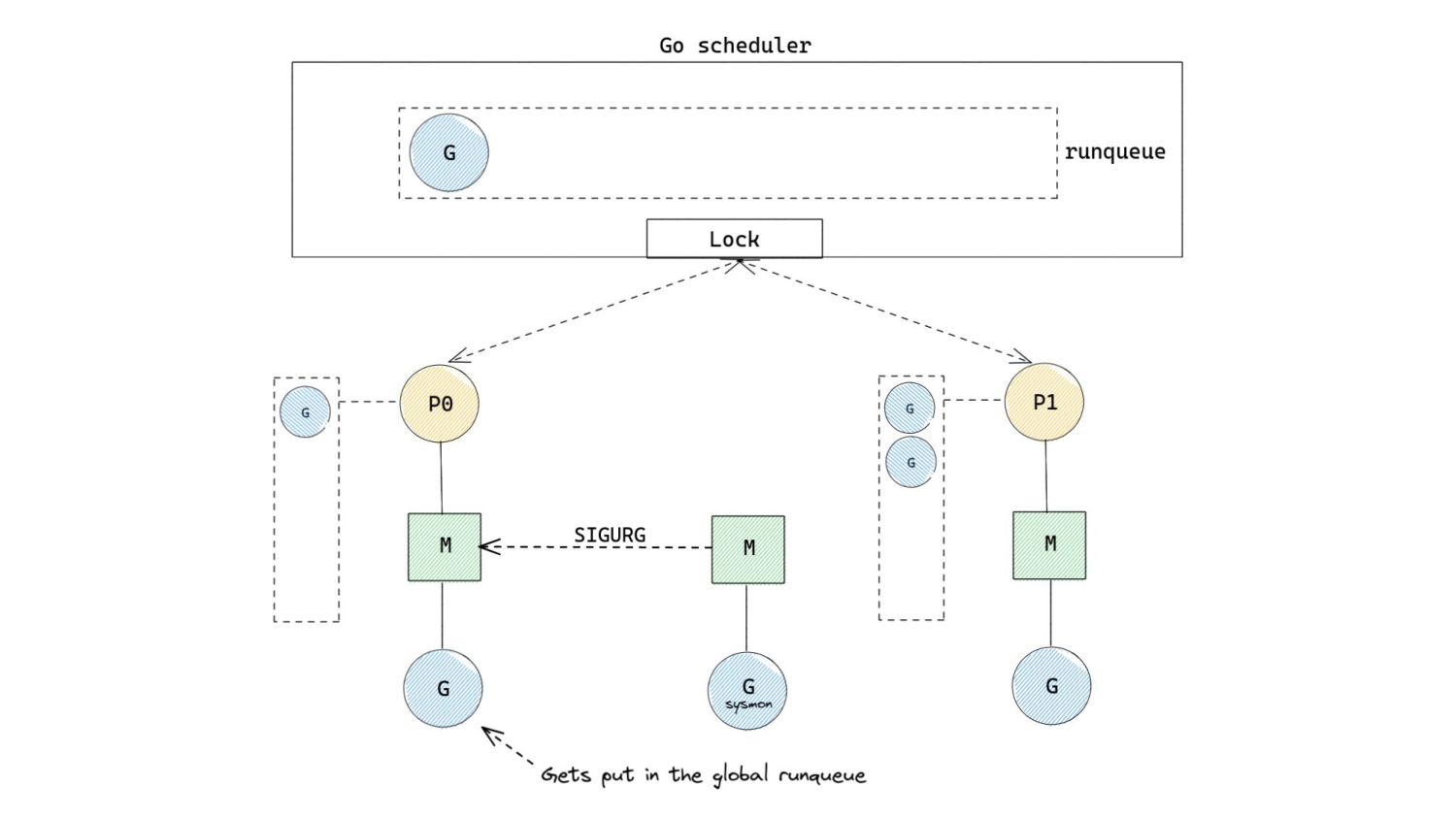
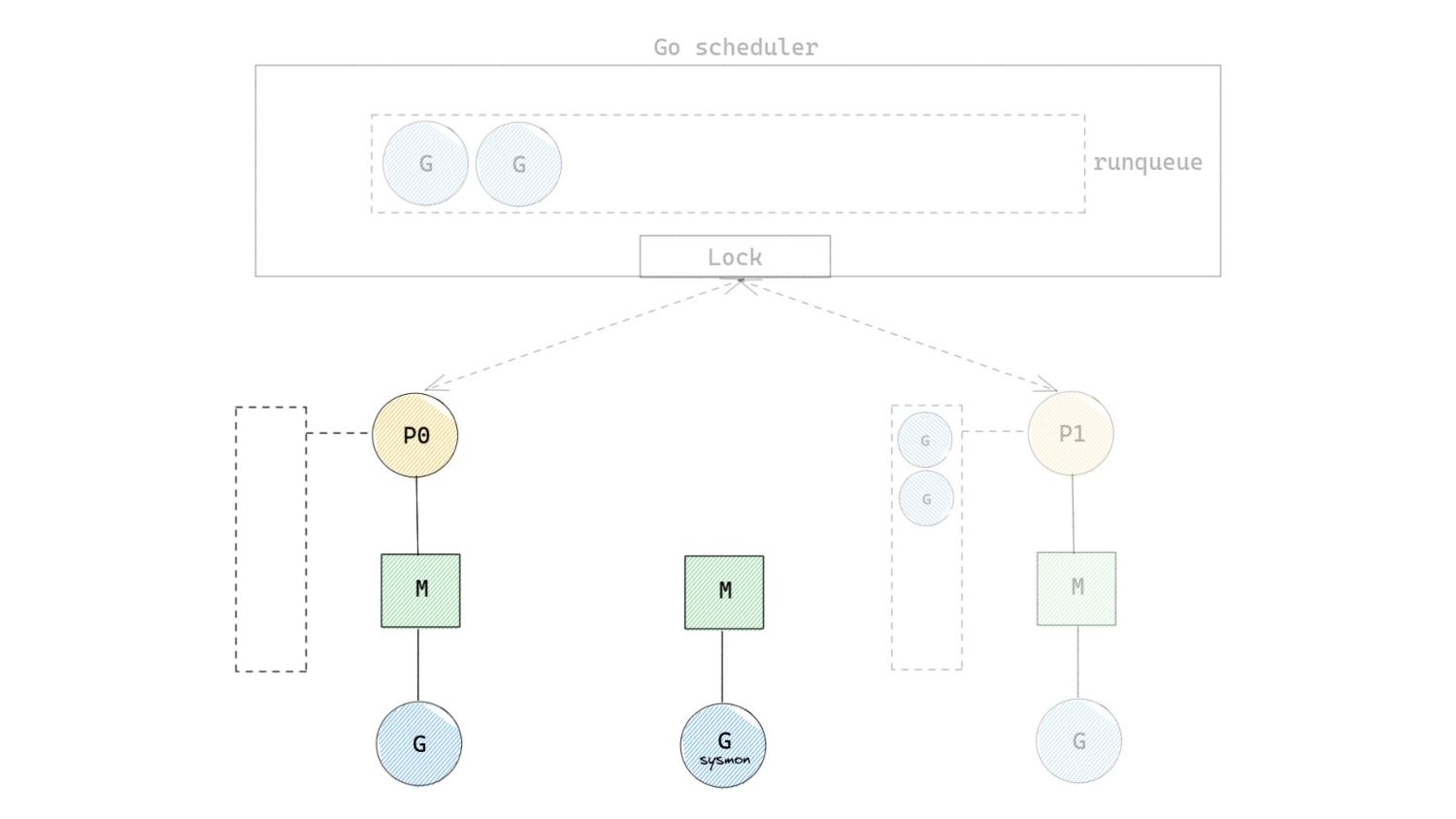
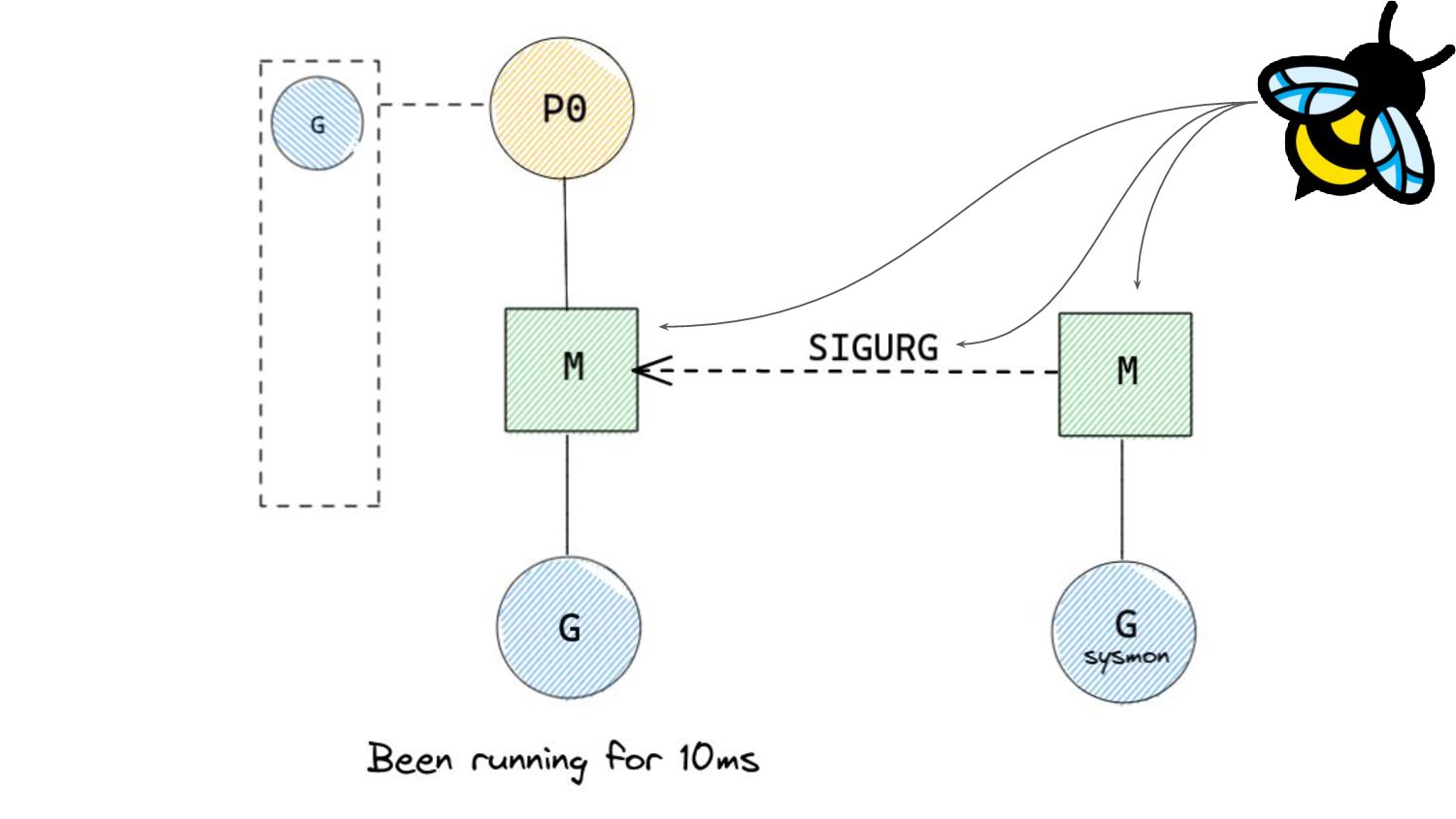
of 10ms after which, pre-emption is attempted. ◦ 10ms is a soft limit. • Pre-emption occurs by sending a userspace signal to the thread running the Goroutine that needs to be pre-empted. ◦ Similar to interruption based pre-emption in the kernel. • The SIGURG signal is sent to the thread whose Goroutine needs to be pre-empted. “Pardon the Interruption: Loop Preemption in Go 1.14” by Austin Clements
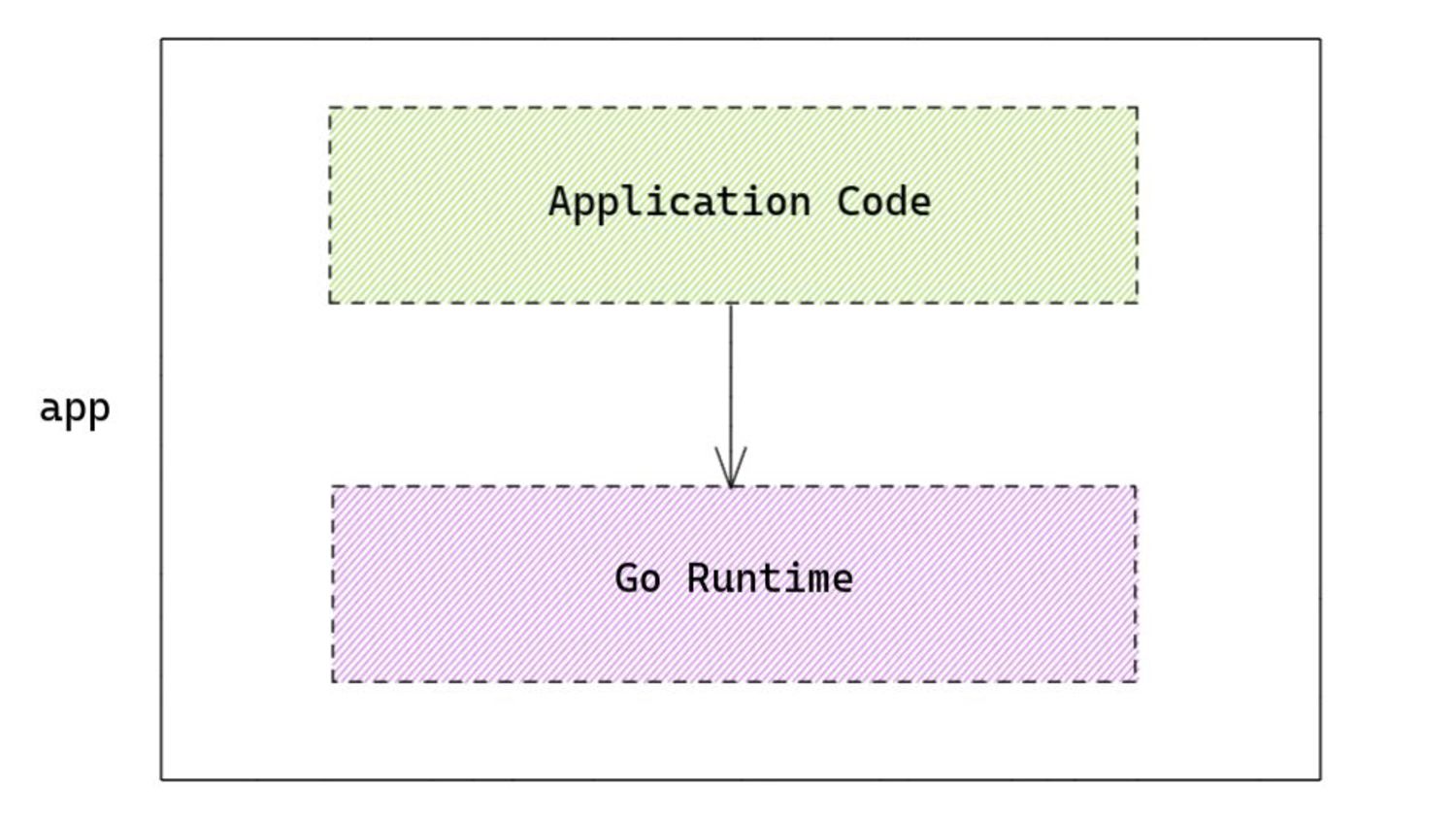
happens under the hood. Yay! But all this is taken care of by the runtime itself, are there any knobs we can turn to try and control some of this behaviour?
treat the runtime as a black-box as much as possible! • (It’s a good thing that) Not a lot of exposed knobs to control the runtime. • Whatever is available should be understood thoroughly before using in code.
https://www.weave.works/blog/linux-namespaces-and-go-don-t-mix ◦ https://www.weave.works/blog/linux-namespaces-golang-followup • Let’s look at the fineprint.
changed. • No ◦ Goroutine can be scheduled on this thread till UnlockOSThread() is called the same number of times as LockOSThread(). ◦ Thread can be created from a locked thread. • Don’t create Goroutines from a locked one that are expected to run on the modified thread state. • If a Goroutine exits before unlocking the thread, the thread is gotten rid of and is not used for scheduling anymore.
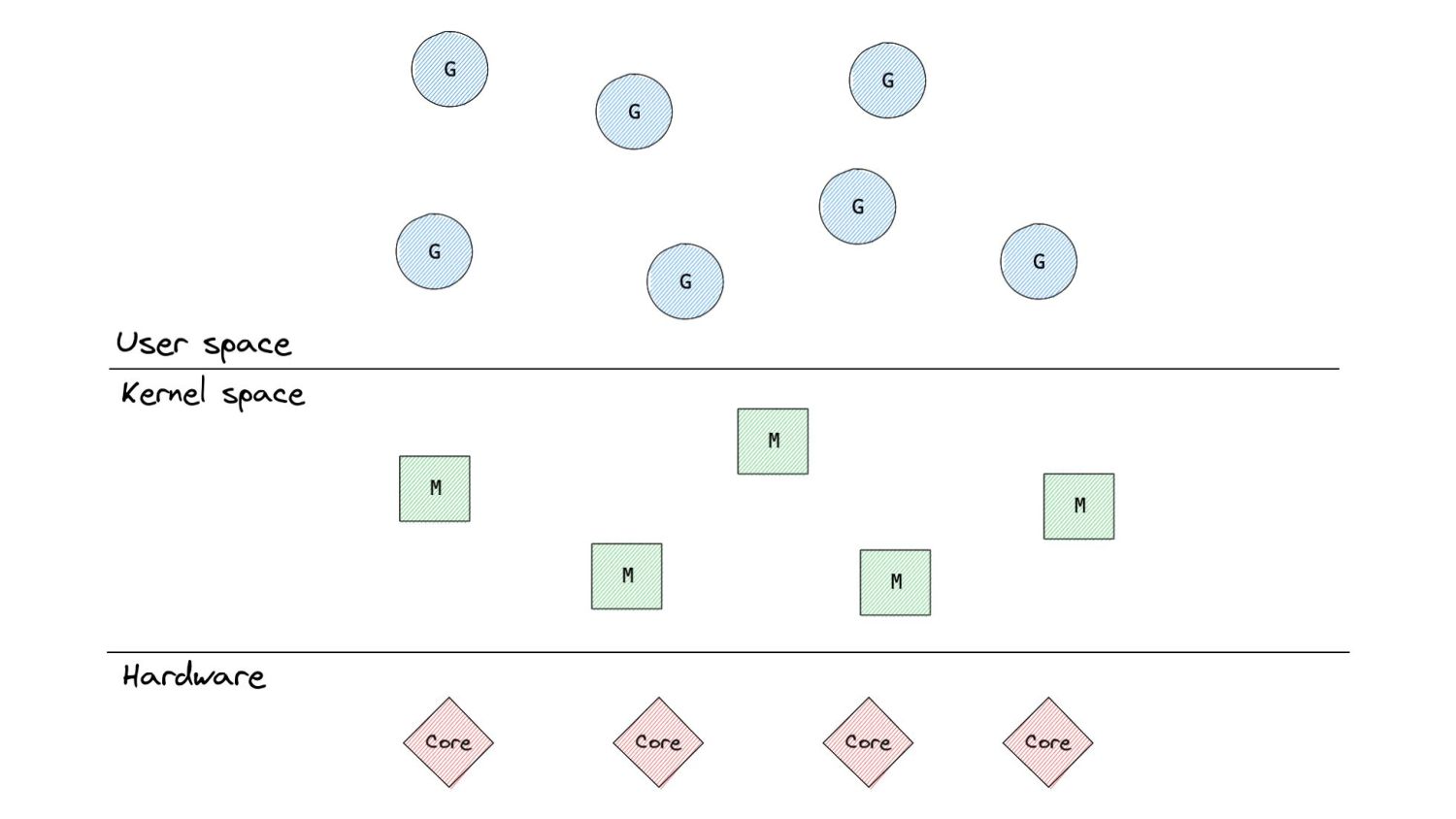
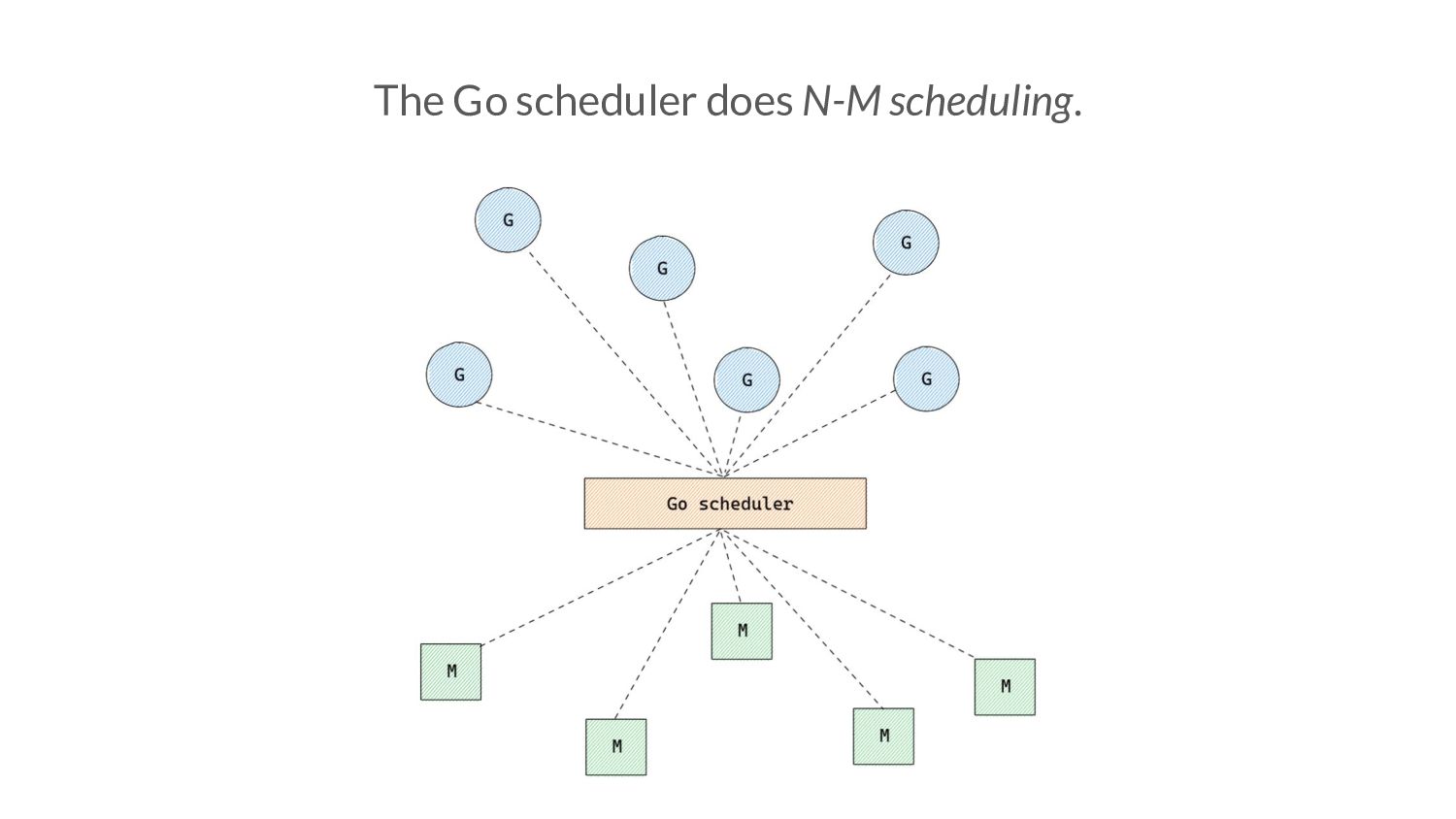
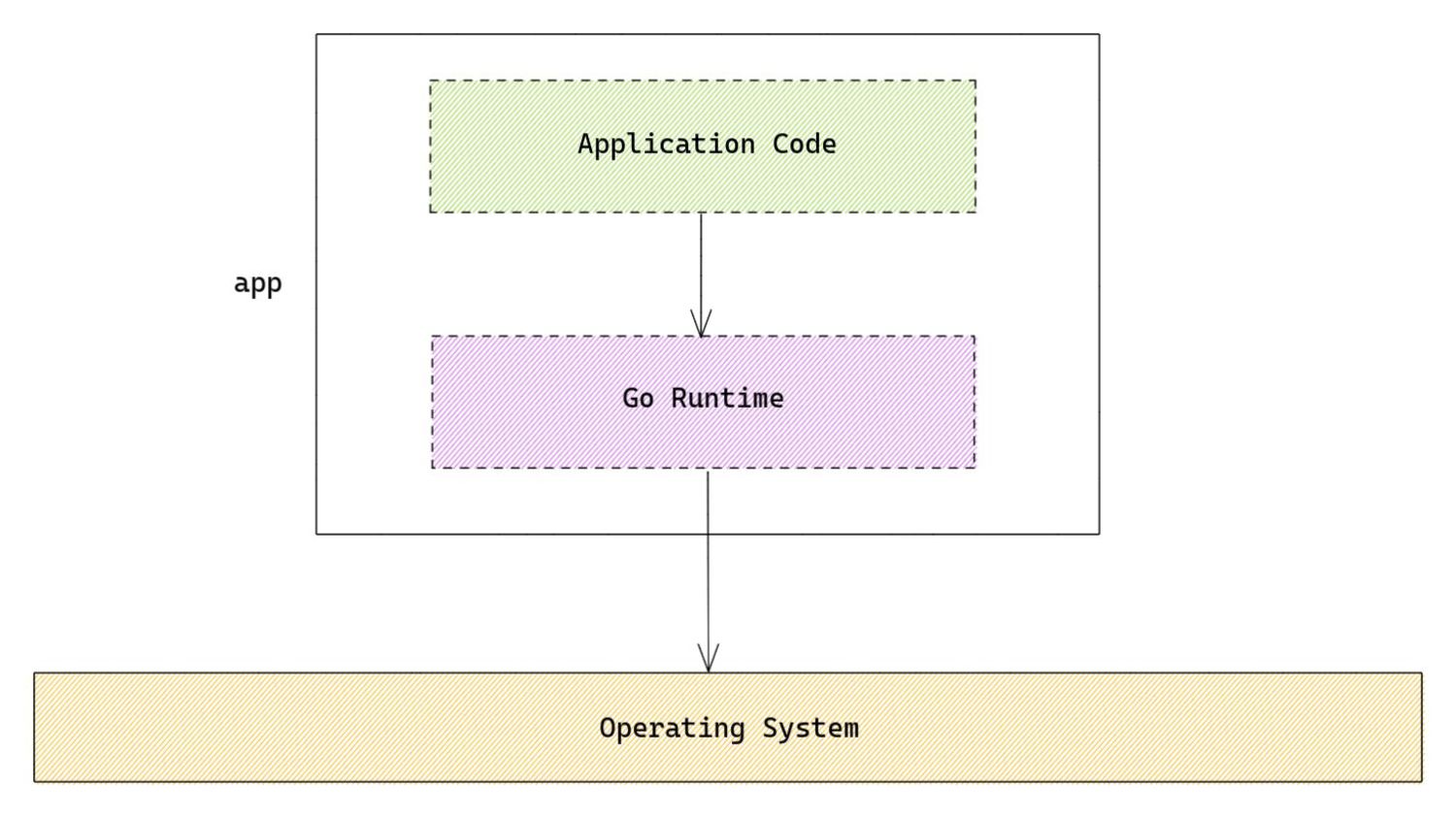
functionality of kernel • Go scheduler is a distributed, best-effort preemptive scheduler • The Go scheduler (and runtime in general) interact with the OS using syscalls • Information about the Go runtime which would otherwise not be visible can be captured through syscall being made via eBPF. • Latency sensitive, aggressive optimisations are maybe possible at the kernel level enabled by eBPF?
Implementing language with lightweight concurrency • The Scheduler Saga • Analysis of the Go runtime scheduler • Non-cooperative goroutine preemption ◦ Pardon the Interruption: Loop Preemption in Go 1.14 • go/src/runtime/{ proc.go, proc_test.go, preempt.go, runtime2.go, ...} ◦ And their corresponding git blames • Go's work-stealing scheduler
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}