Running a distributed application is HARD! You have to deal with unreliable remote services, network partitions, request timeouts, slow responses... the sources of possible failures are endless. There are patterns that you can apply in your service to save the day and make sure it's not your status page that goes red.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![from tenacity import retry @retry(stop=stop_after_attempt(5)) def never_gonna_give_you_up(): if random.choice([True, False]):](https://files.speakerdeck.com/presentations/1a8b86d70fc546809b2c4b5c608ae481/slide_19.jpg){kind=link}
![from tenacity import retry @retry(stop=stop_after_attempt(5)) def never_gonna_give_you_up(): if random.choice([True, False]):](https://files.speakerdeck.com/presentations/1a8b86d70fc546809b2c4b5c608ae481/slide_20.jpg){kind=link}
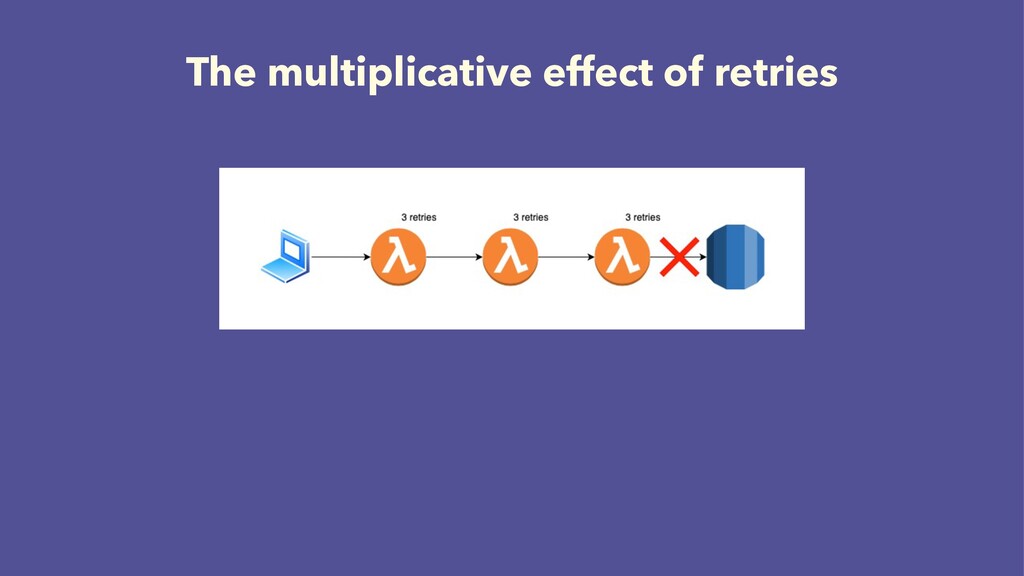{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
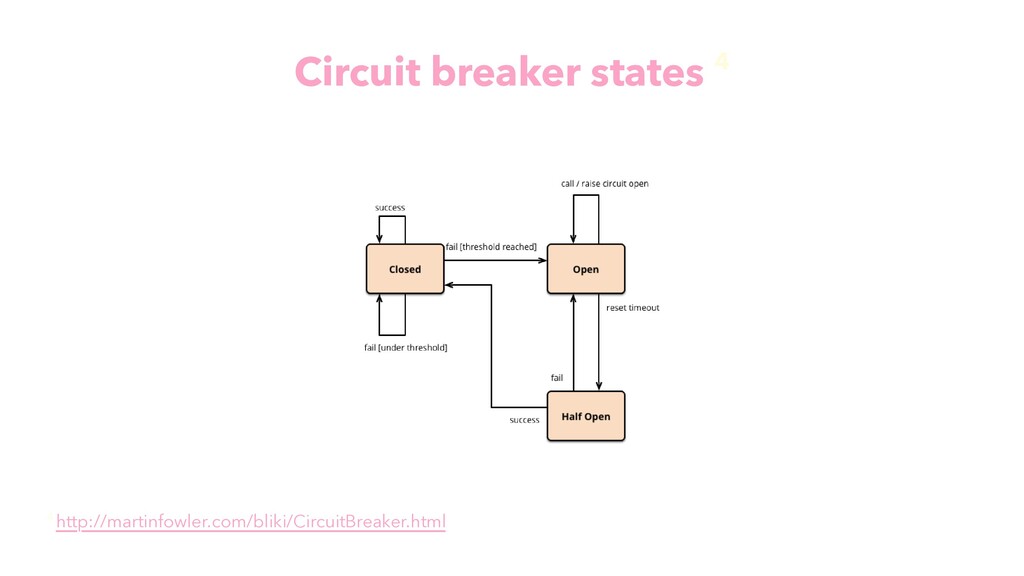{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
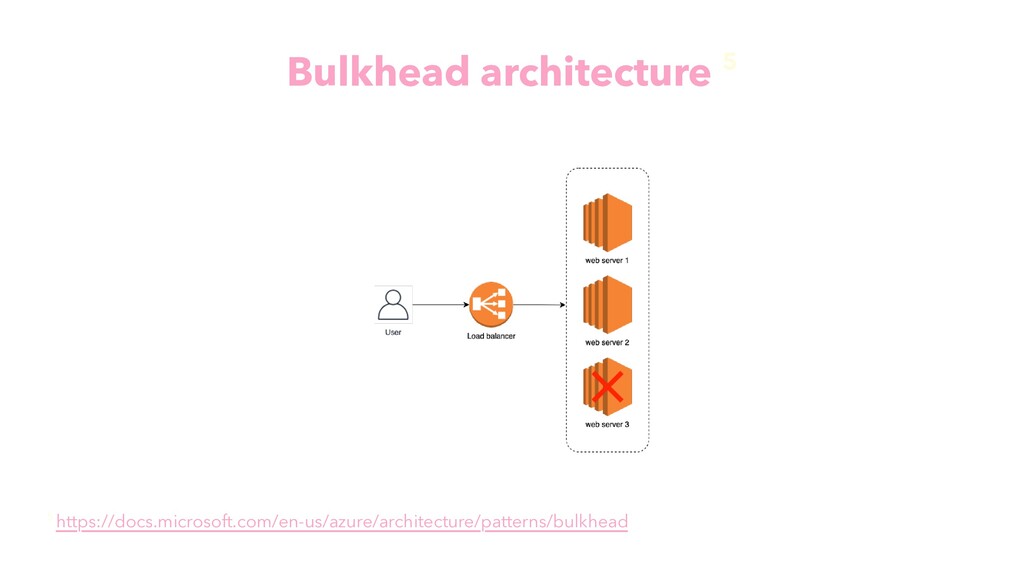{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}