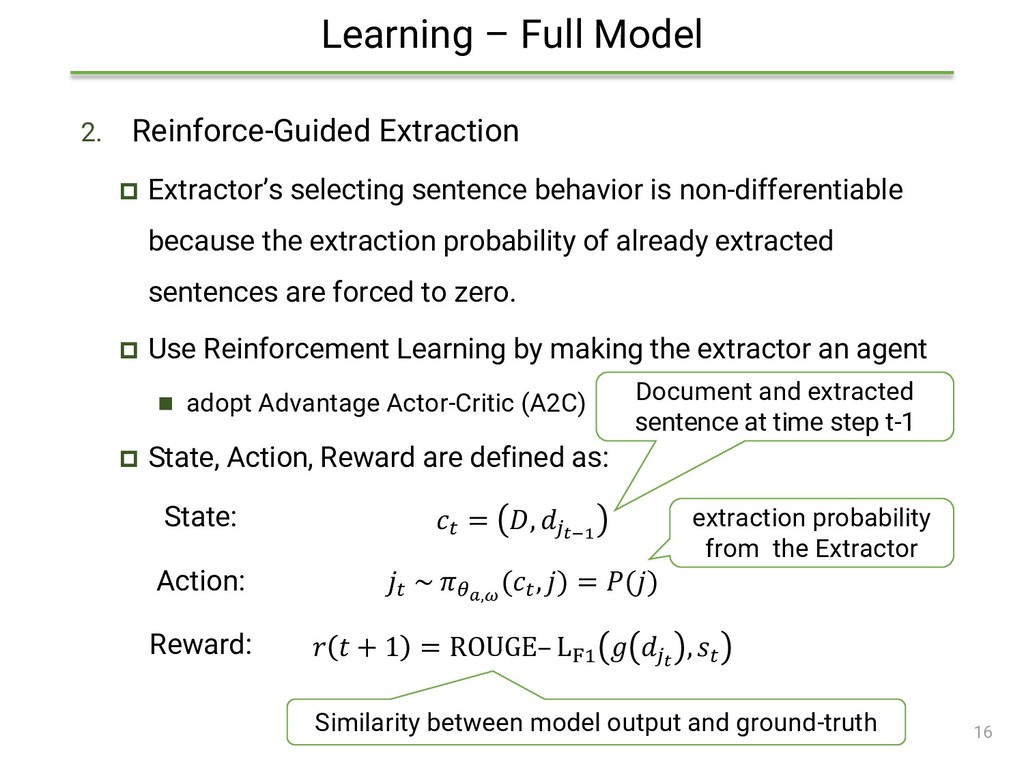
sentence behavior is non-differentiable because the extraction probability of already extracted sentences are forced to zero. Use Reinforcement Learning by making the extractor an agent ◼ adopt Advantage Actor-Critic (A2C) State, Action, Reward are defined as: 16 State: = , −1 Action: ~ , ( , ) = () Reward: + 1 = ROUGE– LF1 , Document and extracted sentence at time step t-1 extraction probability from the Extractor Similarity between model output and ground-truth
{kind=link}
{kind=link}
{kind=link}
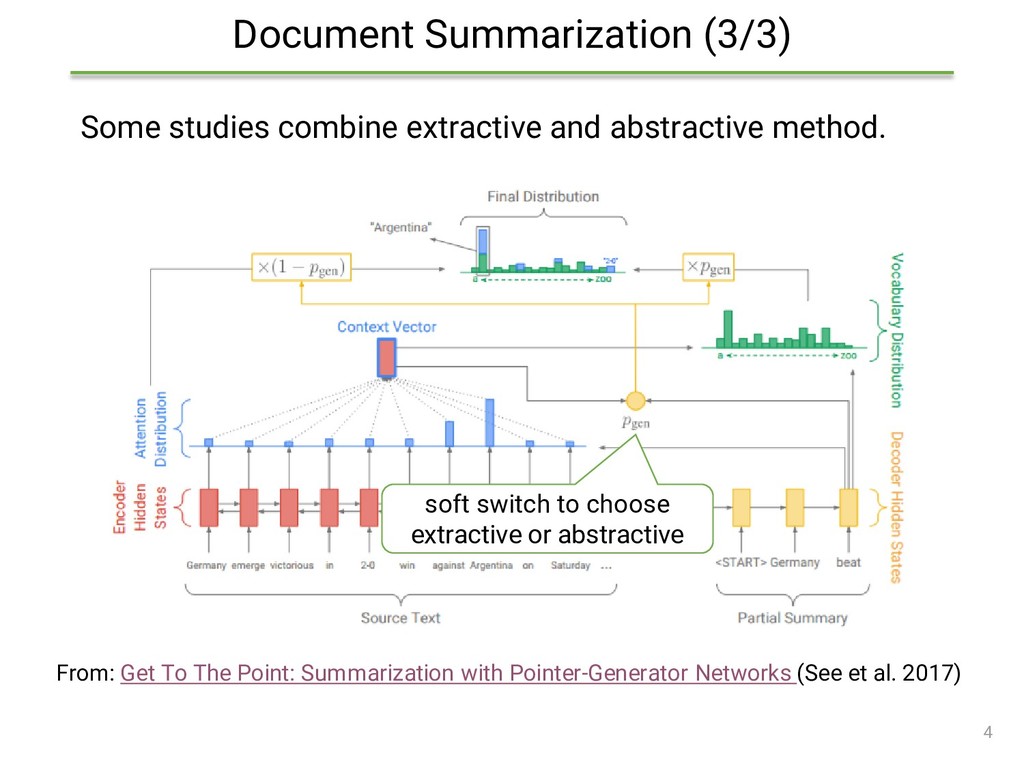{kind=link}
{kind=link}
{kind=link}
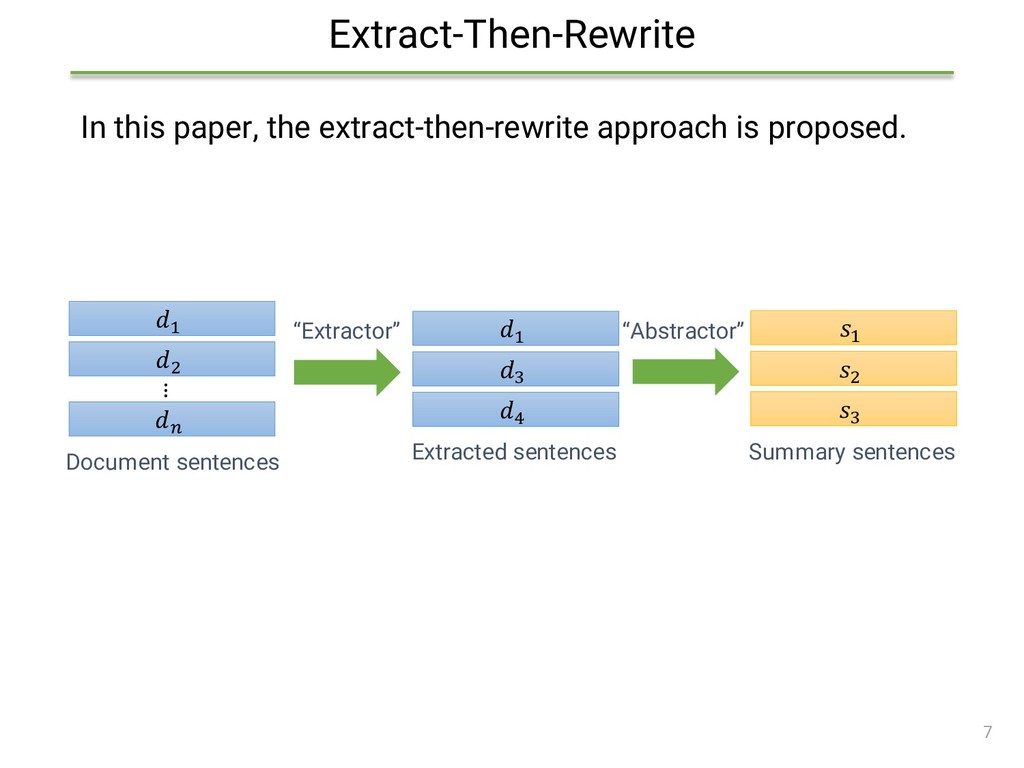{kind=link}
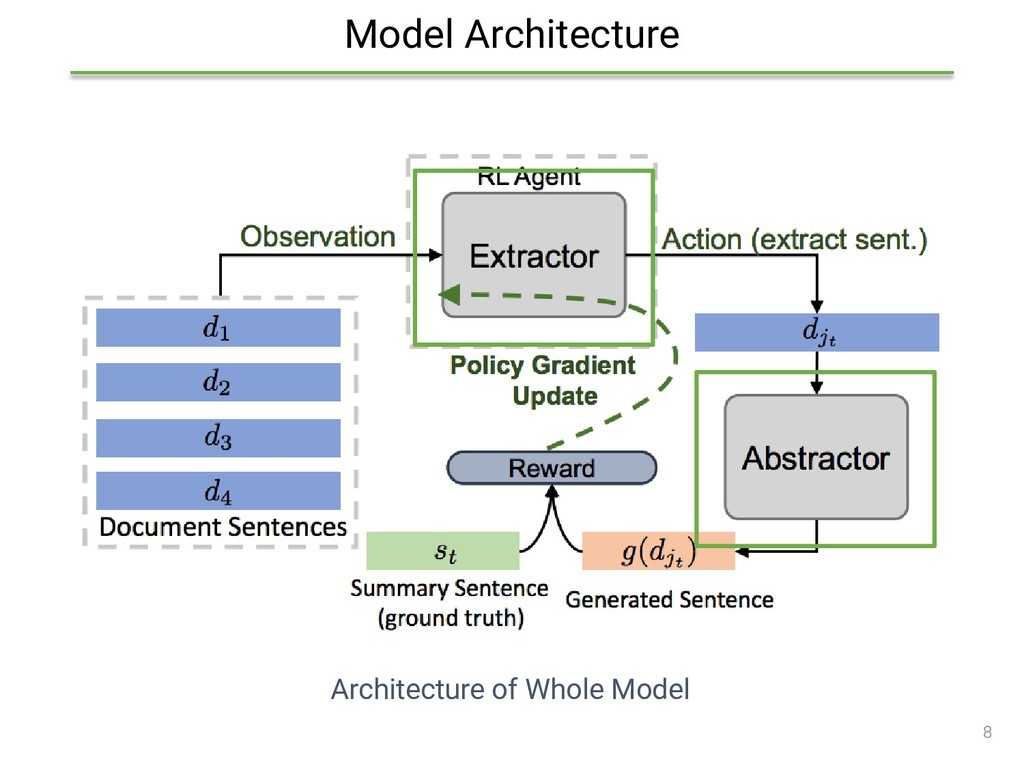{kind=link}
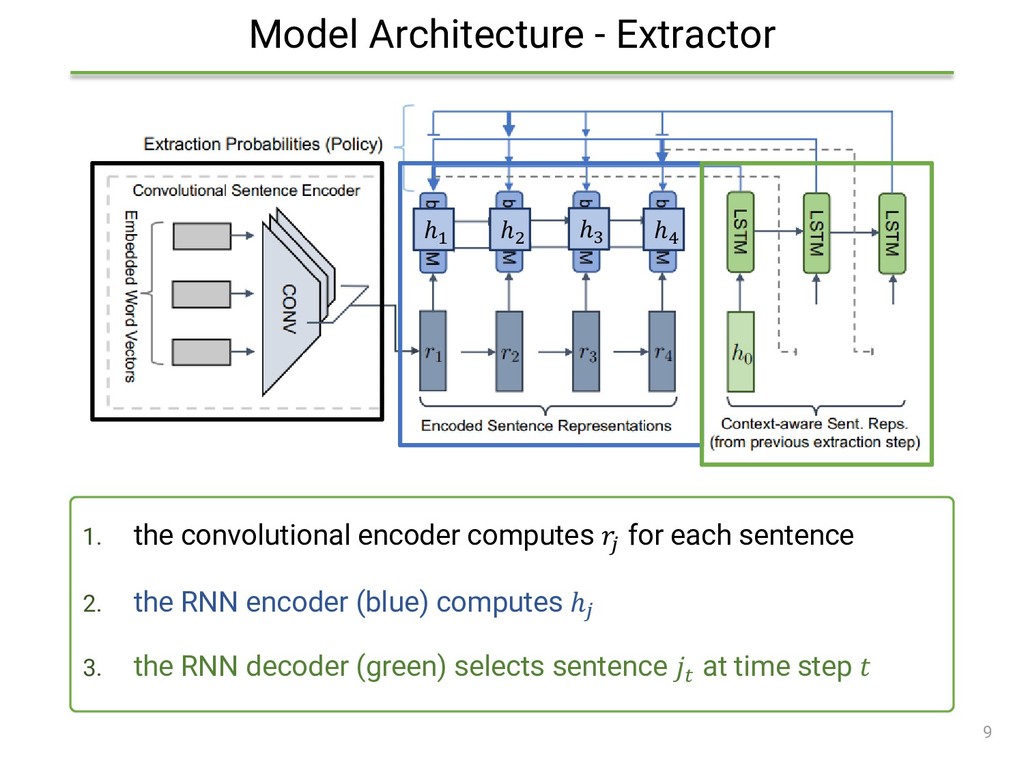{kind=link}
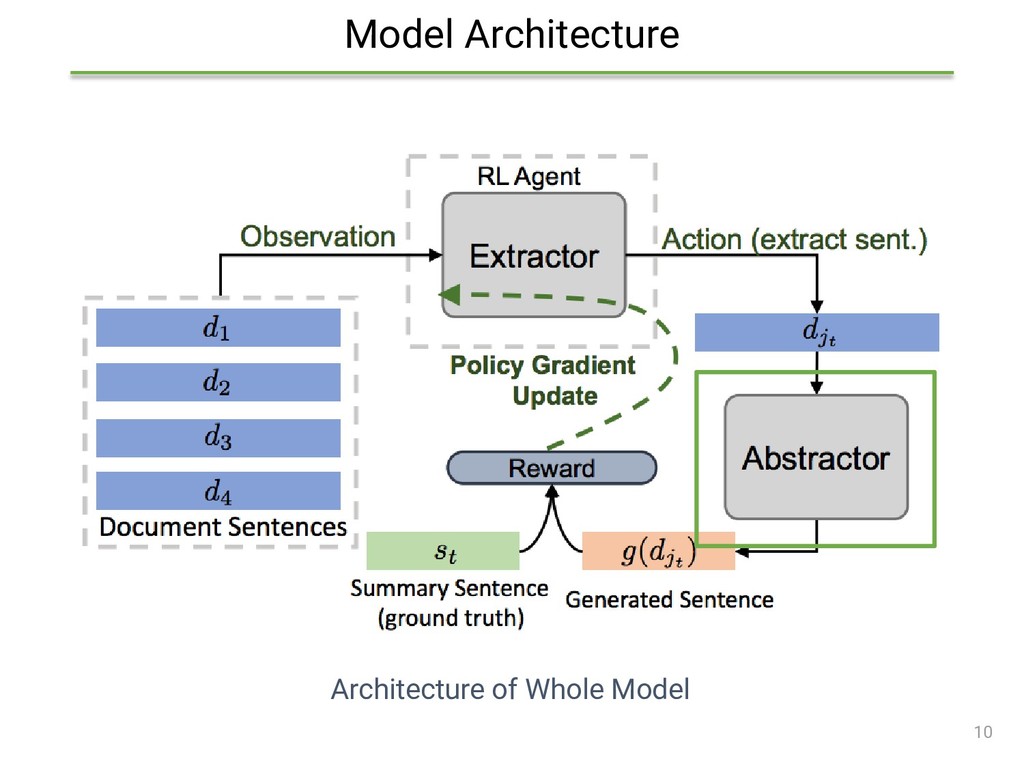{kind=link}
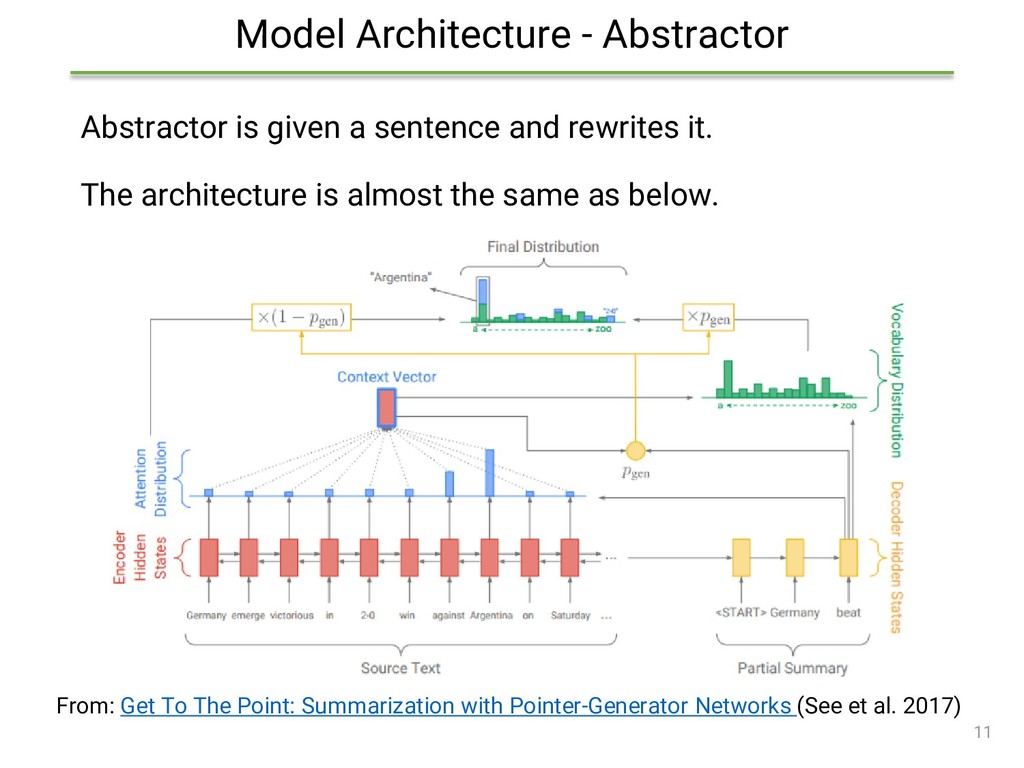{kind=link}
{kind=link}
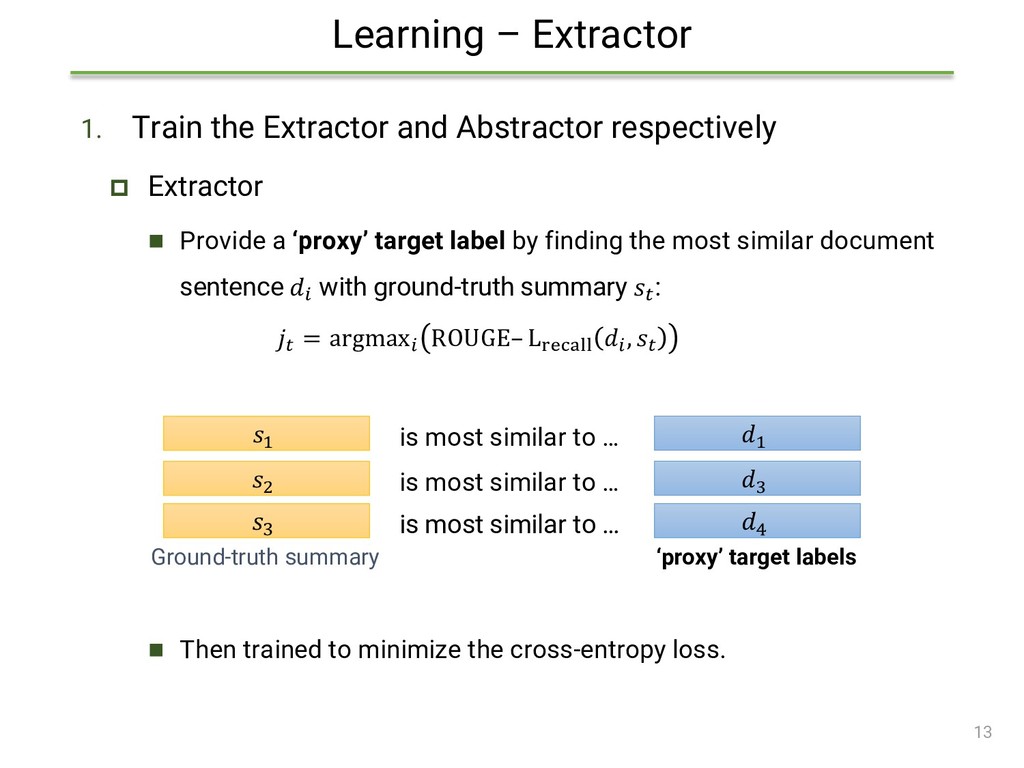{kind=link}
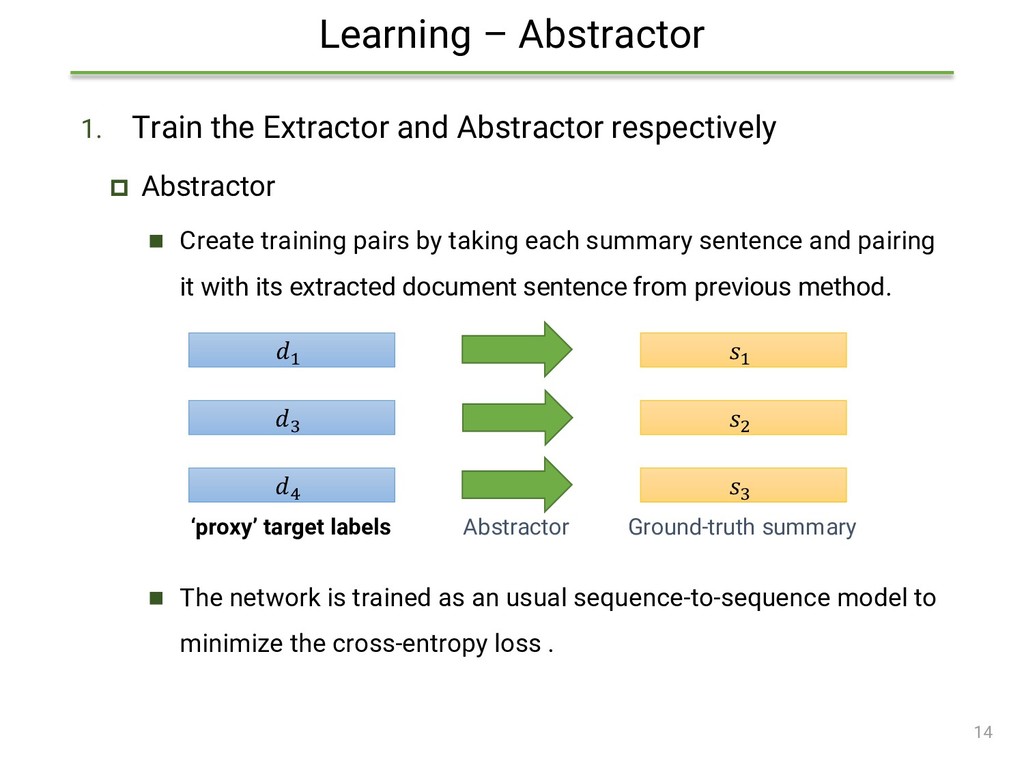{kind=link}
{kind=link}
{kind=link}
{kind=link}
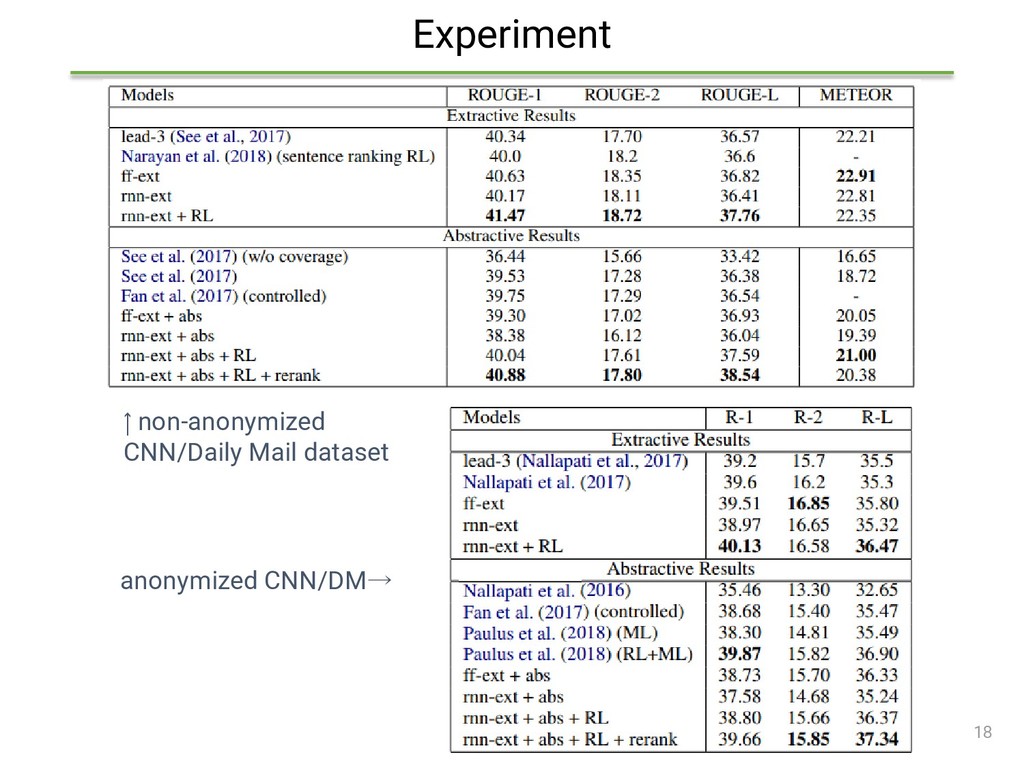{kind=link}
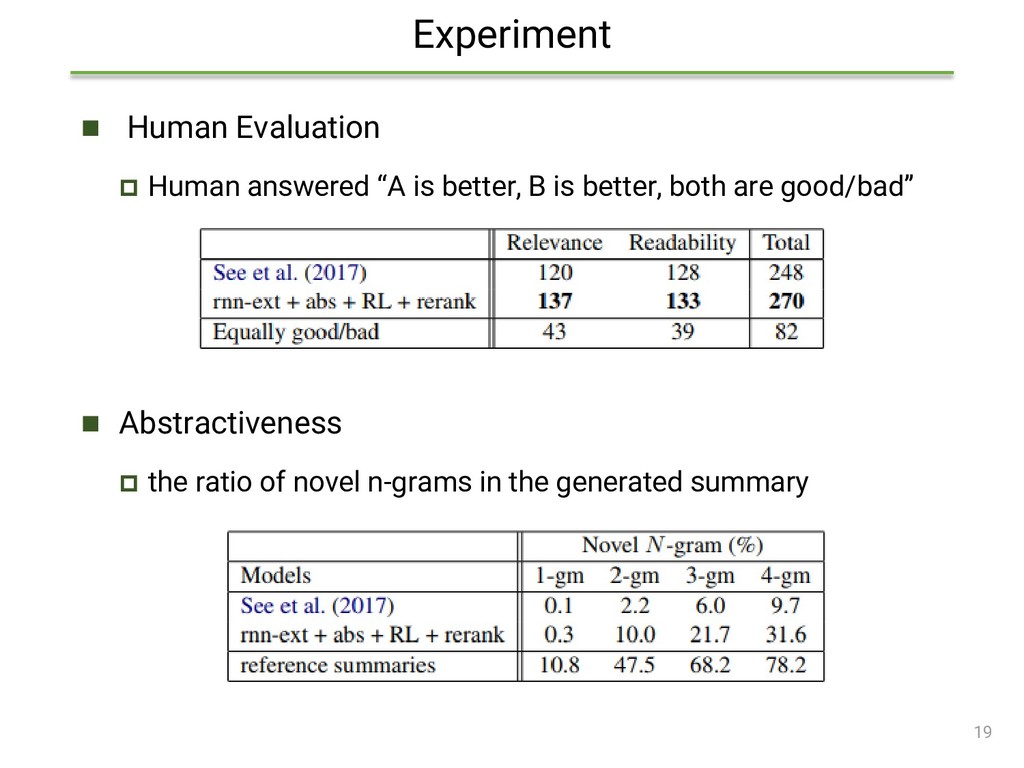{kind=link}
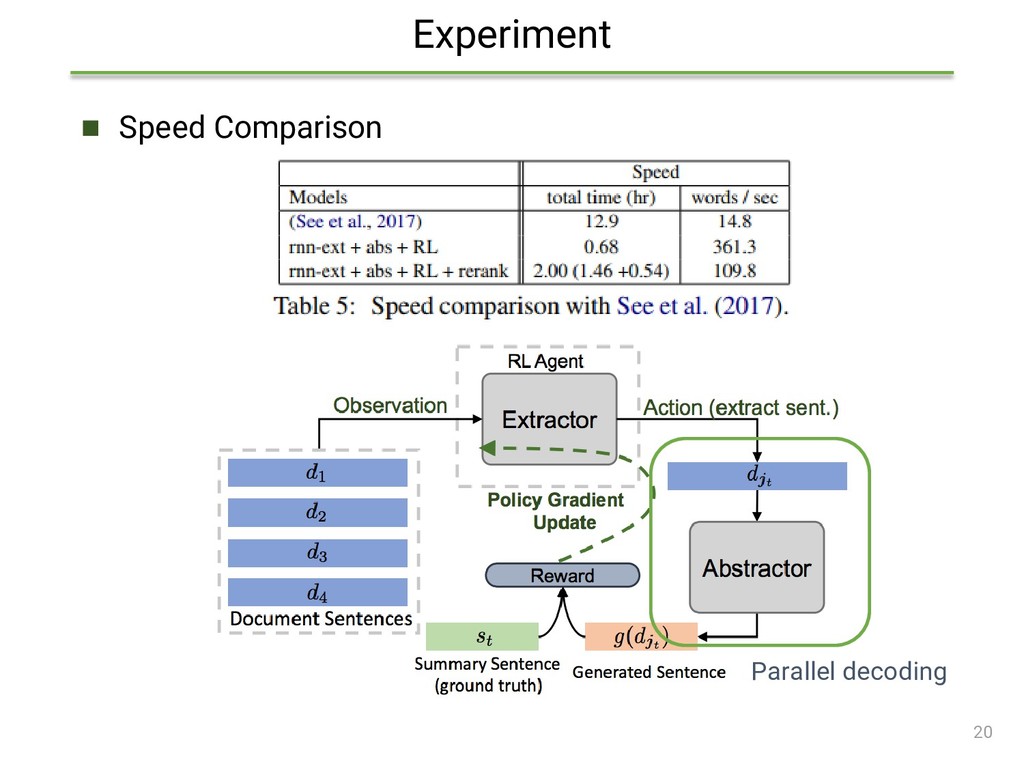{kind=link}
{kind=link}
{kind=link}
{kind=link}