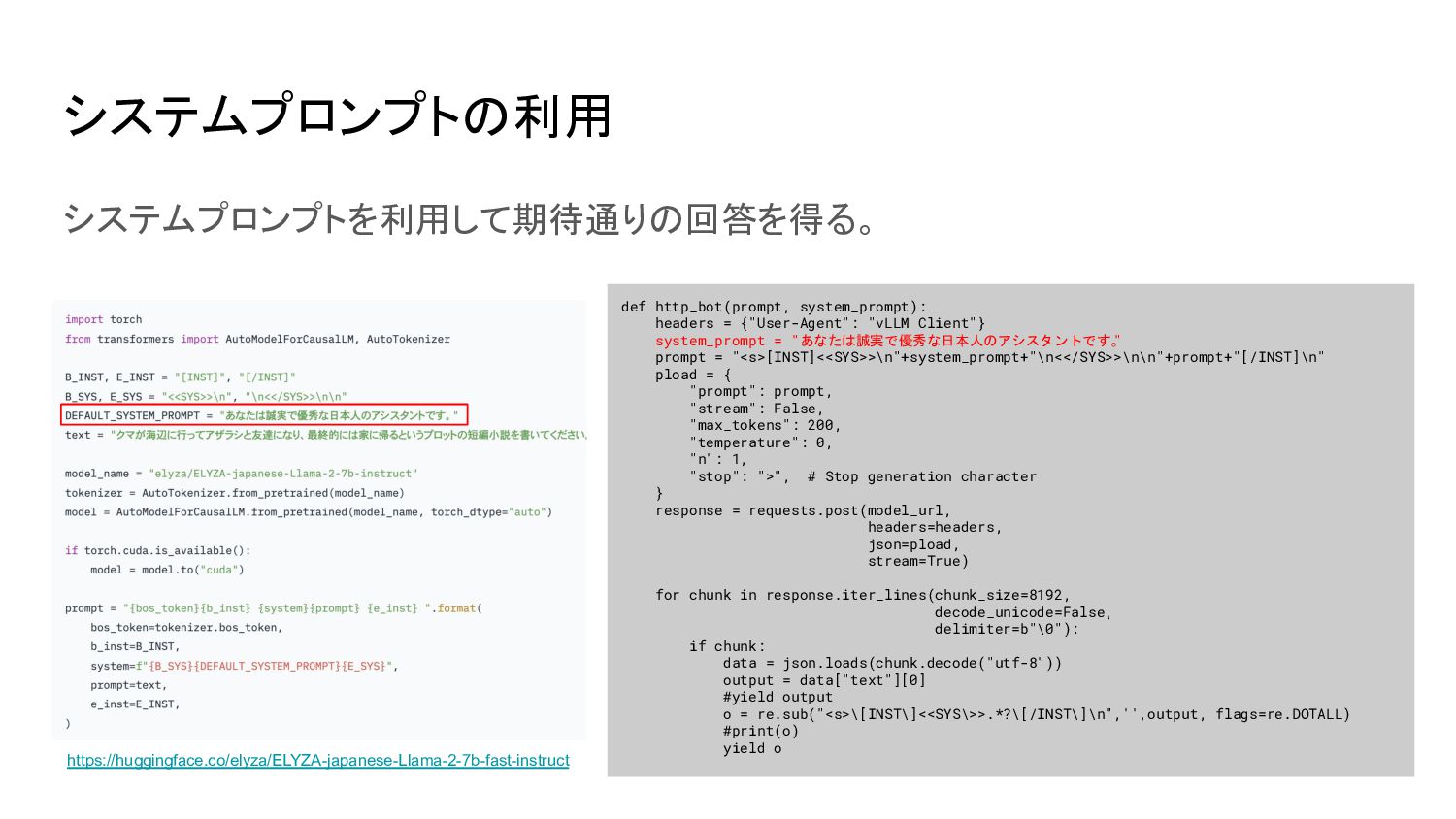
system_prompt = "あなたは誠実で優秀な日本人のアシスタントです。 " prompt = "<s>[INST]<<SYS>>\n"+system_prompt+"\n<</SYS>>\n\n"+prompt+"[/INST]\n" pload = { "prompt": prompt, "stream": False, "max_tokens": 200, "temperature": 0, "n": 1, "stop": ">", # Stop generation character } response = requests.post(model_url, headers=headers, json=pload, stream=True) for chunk in response.iter_lines(chunk_size=8192, decode_unicode=False, delimiter=b"\0"): if chunk: data = json.loads(chunk.decode("utf-8")) output = data["text"][0] #yield output o = re.sub("<s>\[INST\]<<SYS\>>.*?\[/INST\]\n",'',output, flags=re.DOTALL) #print(o) yield o https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
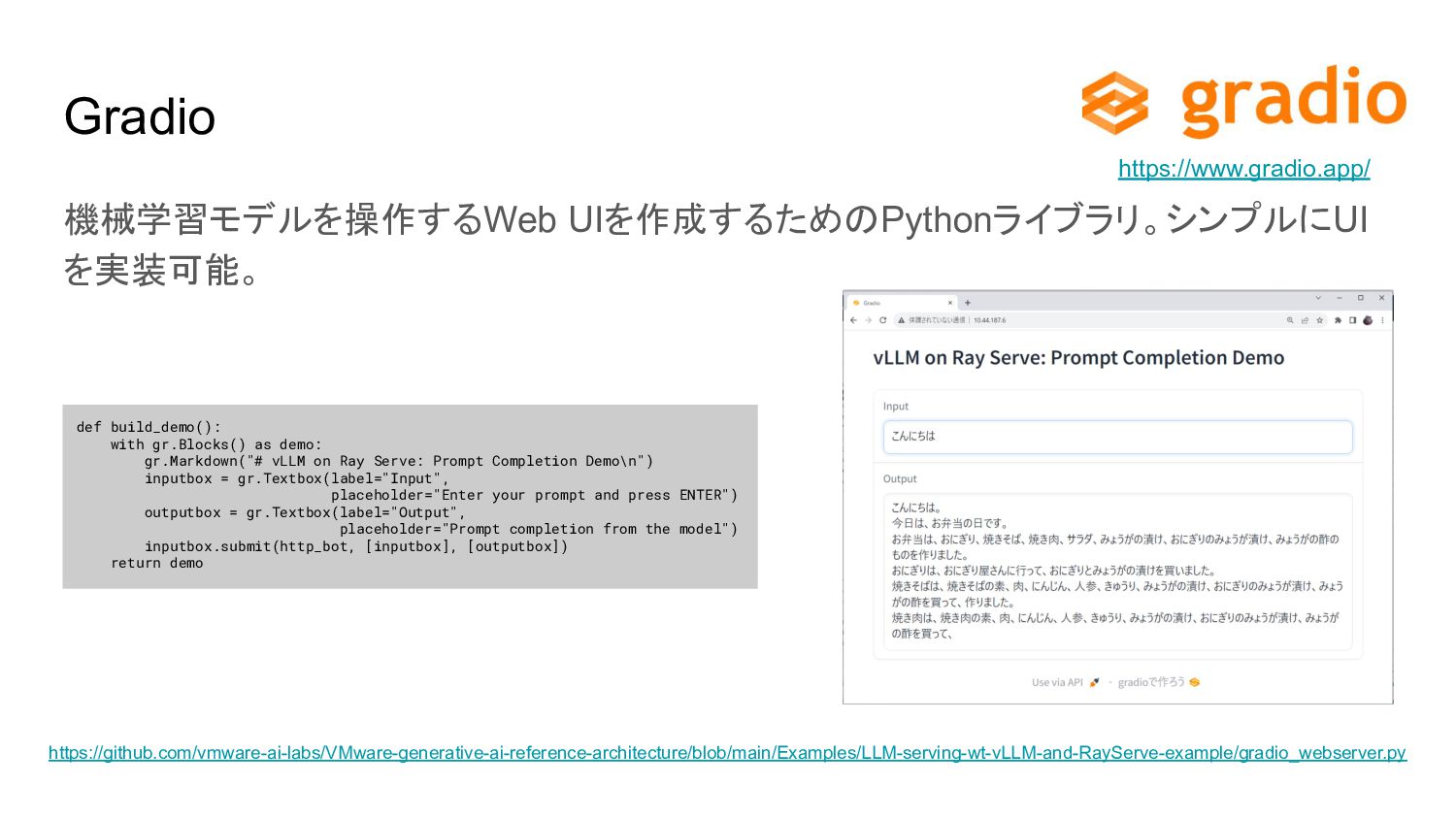{kind=link}
{kind=link}
{kind=link}