Algorithmic Differentiation (AD) enables automatic computation of the derivatives of a function implemented as a computer program. It's distinct from the numerical differentiation approximation methods (like finite differences), as it's exact to the maximum extent allowed by the machine precision. At the same time, it's free from the limitations of symbolic differentiation, since it works with actual computer programs (with branches, loops, allocations, and mutation) and not only pure, algebraic expressions.
AD is useful to a wide range of applications – in particular, fitting models via extremum estimators (i.e., estimators obtained as extrema of the given cost functions). This includes calibrating financial models, training machine learning models, or estimating statistical (or econometric) models. Numerical optimization algorithms necessary for model fitting benefit greatly from the high precision of the gradient obtained using AD – with a direct impact on the ultimate results’ precision (more precise and stable parameter estimates, standard errors, confidence intervals).
This talk shows how to use AD from R – making the use of RcppEigen. We shall motivate the problem (including the issues with finite differences), introduce AD, and demonstrate its advantages over numerical approximations with a likelihood estimation example. We end by speeding up the gradient computation via parallelization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
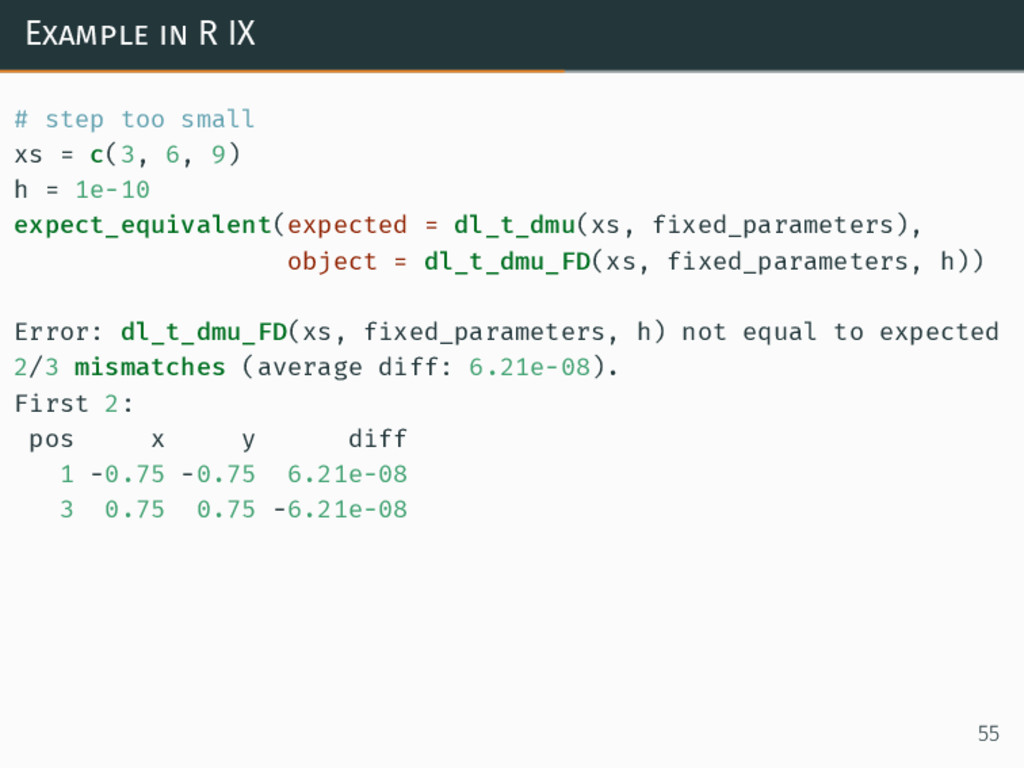{kind=link}
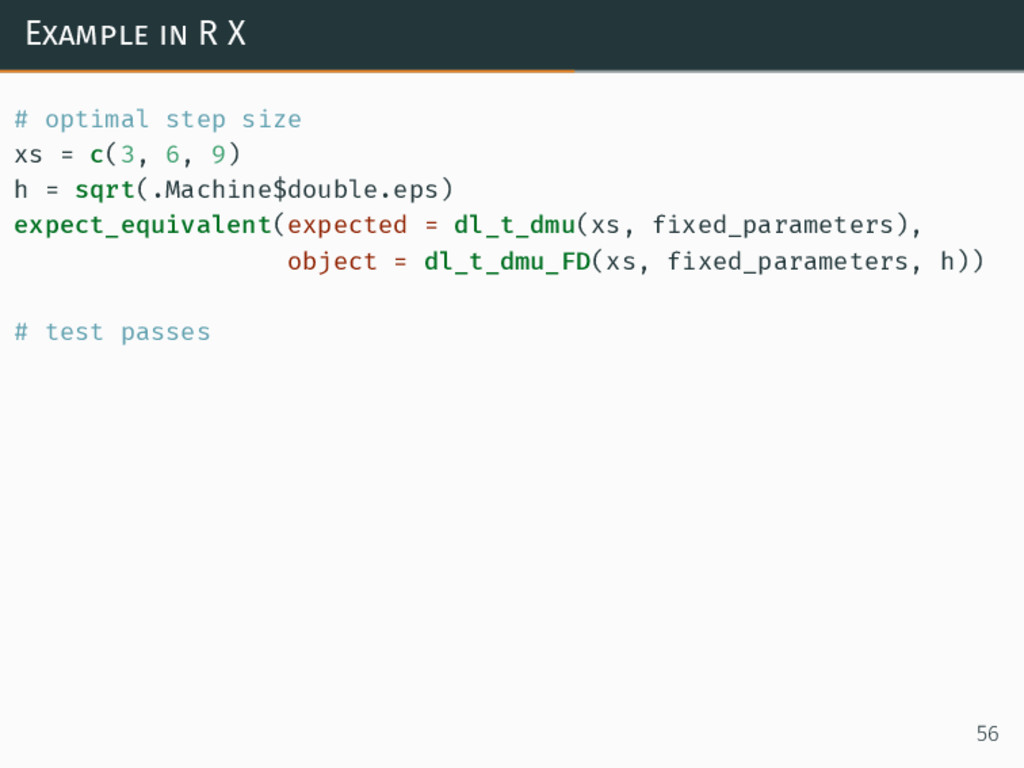{kind=link}
{kind=link}
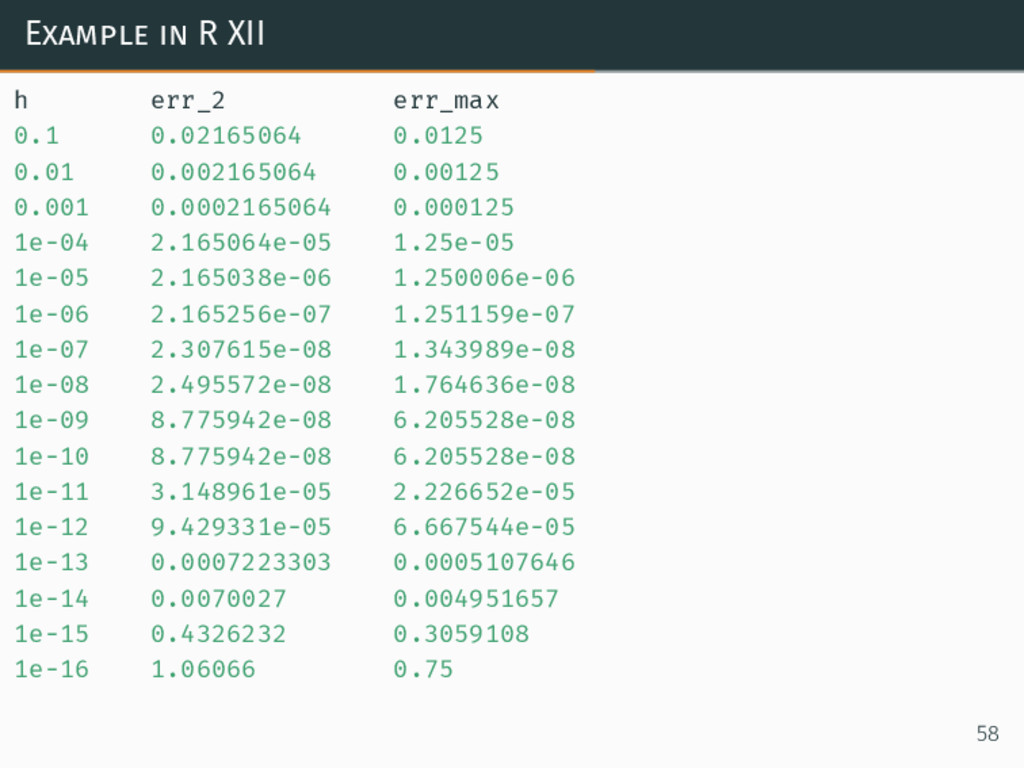{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example in R XVIII > head(err_AD) [1] 0 0 0](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_251.jpg){kind=link}
{kind=link}
![ExampleGaussianRcpp.cpp I // [[Rcpp::plugins("cpp11")]] #include <cstddef> // [[Rcpp::depends(BH)]] #include <boost/math/constants/constants.hpp>](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_253.jpg){kind=link}
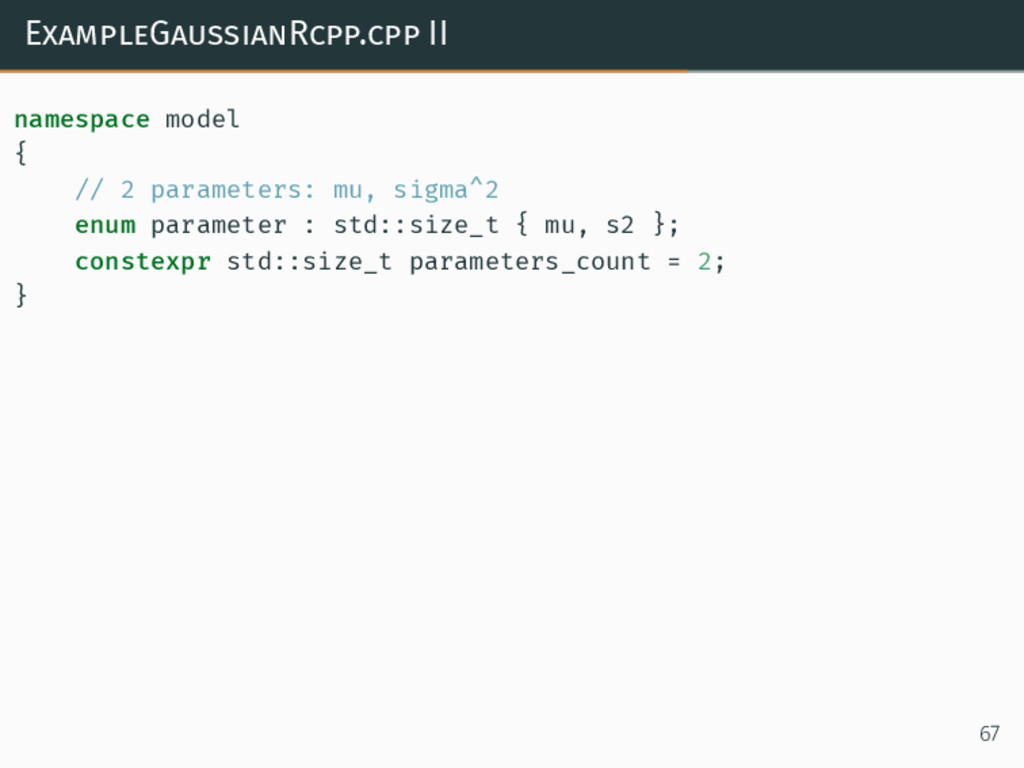{kind=link}
![ExampleGaussianRcpp.cpp III // [[Rcpp::export]] double l_t_cpp(double xt, const Eigen::Map<Eigen::VectorXd> parameters)](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_255.jpg){kind=link}
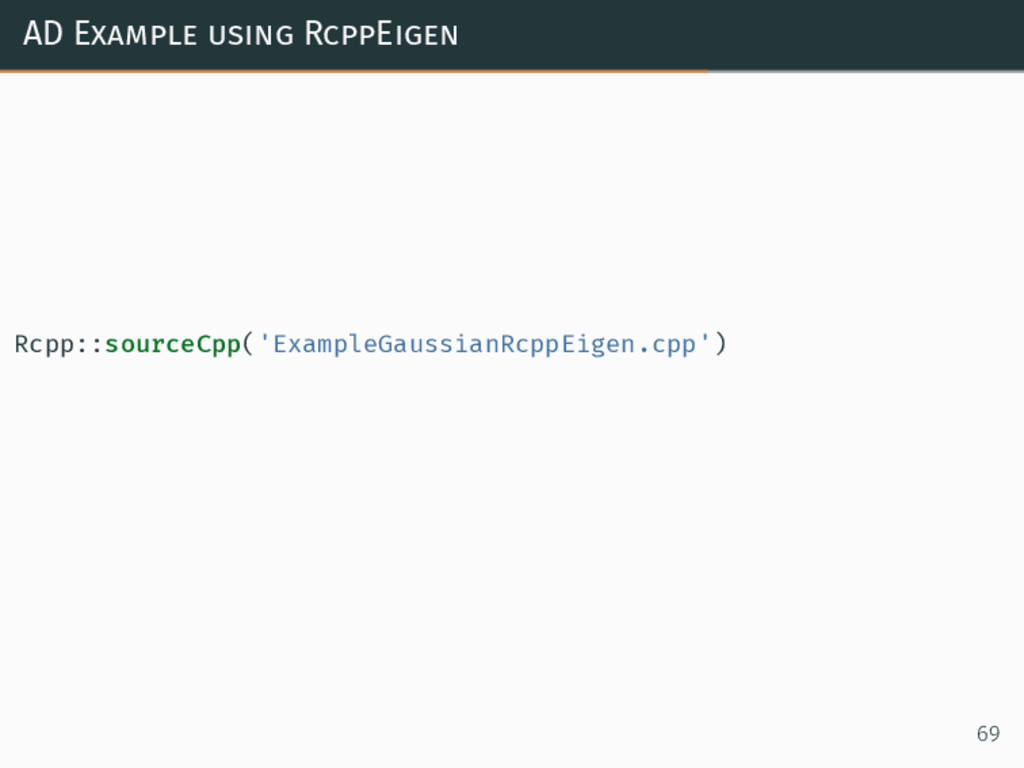{kind=link}
![ExampleGaussianRcppEigen.cpp I // [[Rcpp::plugins("cpp11")]] #include <cstddef> // [[Rcpp::depends(BH)]] #include <boost/math/constants/constants.hpp>](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_257.jpg){kind=link}
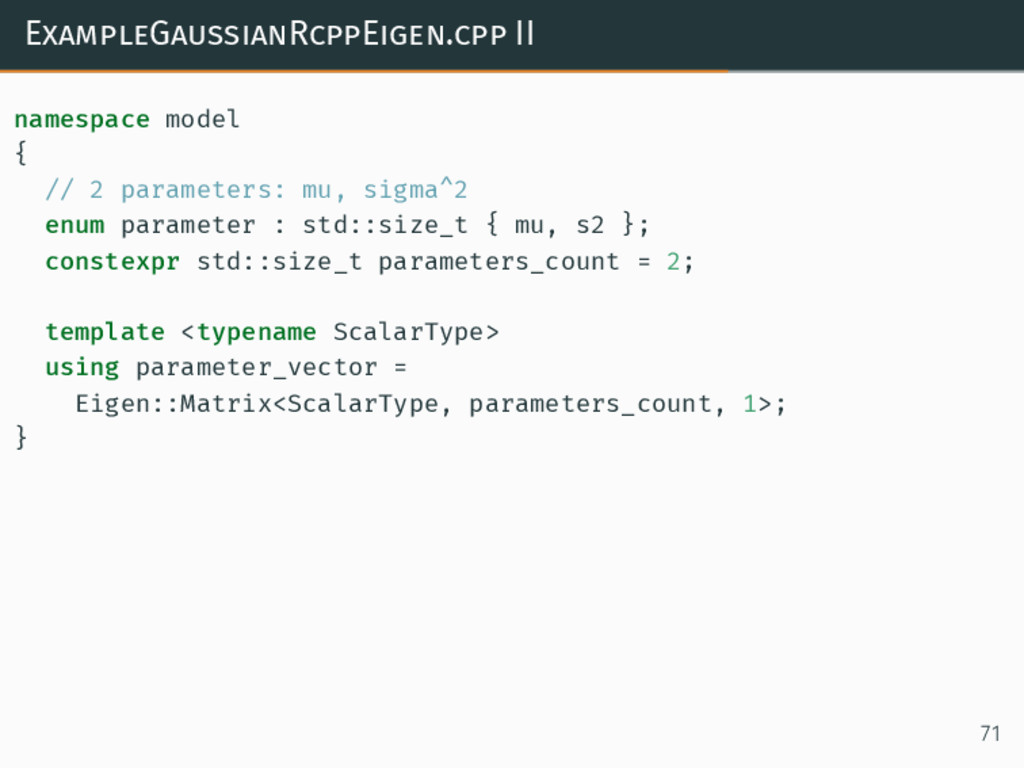{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
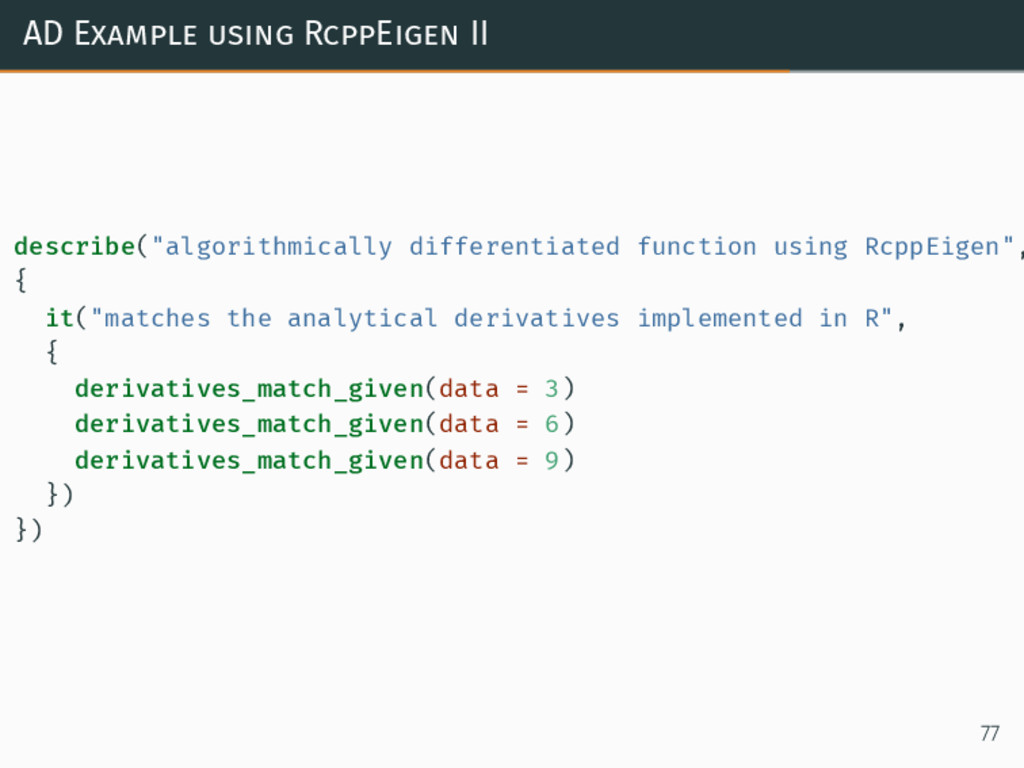{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Parallel Gradient I // [[Rcpp::export]] Eigen::VectorXd l_t_value_gradient_cppDP ( const](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_273.jpg){kind=link}
{kind=link}
![Data Parallel Gradient III // [[Rcpp::export]] Eigen::VectorXd l_t_value_gradient_cppDP_OMP ( const](https://files.speakerdeck.com/presentations/985b3f48719a431993e3c0d3d91653ea/slide_275.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}