Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GCPUG女子会#9 BigQueryでSQL入門
Search
Megumi Takahira
July 05, 2020
Technology
830
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GCPUG女子会#9 BigQueryでSQL入門
Megumi Takahira
July 05, 2020
More Decks by Megumi Takahira
See All by Megumi Takahira
JTUGスピンオフ_Google_BigQueryのデータをTableauでビジュアライズしてみよう.pdf
megumit
1
390
第4回 前向きデータ整備人 もう一度、表計算ソフトを愛でる
megumit
2
3.3k
Notebookを比較する_MLforBegginers
megumit
0
140
第5回GCPUG女子会_Tableauコラボ
megumit
0
82
はじめてみよう_BigQuery_in_GCPUG女子会
megumit
0
170
Other Decks in Technology
See All in Technology
AI-DLCを “そのまま導入しなかった”話 ~組織に合わせてアジャストした 私たちの実践共有~
hiroramos4
PRO
1
480
「ビジネスがわかるエンジニア」とは何か?
ryooob
0
430
製造現場での生成AIの活用、およびエージェントAIの実装のあり方、AVEVAの取り組み
iotcomjpadmin
0
210
toB プロダクトから見たWAF
tokai235
0
270
技術・能力を向上する原理原則 #きのこセッションa #きのこ2026
bash0c7
0
190
フルAIで個人開発して学んだあれこれ / yuruai vol.1
isaoshimizu
0
160
そこにあるから地図ができる~位置を示す"モノ"を愉しむ~ - Interface 2026年6月号GPS特集オフ会 / interface_202606_GPS_offline
sakaik
1
160
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
210
データレイクの「見えない問題」を可視化する
sansantech
PRO
1
250
GitHub Copilot運用のリアル ~AI Credit時代にどう向き合うか~
takafumisu2uk1
0
580
背中から、背中へ /paying forward to community
naitosatoshi
0
190
サイバーエージェントにおけるAI推進戦略と変革への取り組み
shotatsuge
0
640
Featured
See All Featured
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
WCS-LA-2024
lcolladotor
0
660
A designer walks into a library…
pauljervisheath
211
24k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
330
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
450
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
250
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Designing Experiences People Love
moore
143
24k
Transcript
BigQueryでSQL入門 2020/07/05 GCPUG女子会 #9
Hello! たかひらめぐみ と申します ・駆け出しデータ系コンサルタント ・前職ではデータエンジニア?整備人? ・GCP 特にBigQuery大好き ※本資料はあくまで個人の見解であり、所属組織の公式的な見解ではありません @megumi_takahira 2
突然ですが・・・ この中でBigQuery 使ったことある方 コメントで挙手 ノシ してください
申し訳ありません。今日の私の話は BQ使った事ある方には簡単すぎて きっとつまらないので twitterハッシュタグ #GCPUGjoshi #BQへの愛を叫ぶ で愛を叫んでお待ちください!
このお話の対象者 ・BigQueryって聞いた事あるかも ・SQLいっこもわからん ※非エンジニアの人でもOK! 簡単なハンズオンを用意しています 一緒にやっても、資料をみながら後で やってみても良いので ぜひ一度触ってみてください!
BigQuery 概要(ざっくりと) ・フルマネージドサービス ・標準SQLでビッグデータにアクセスできる ・ものすごくはやい
BigQuery 概要(ざっくりと) ・基本は従量課金 課金対象: データのスキャン量 ストレージ ※ネットワークやCPUの使用量に関しては課金されない ※プレビューとメタ情報に関しては課金されない 詳細は公式ドキュメントを参照 https://cloud.google.com/bigquery/pricing
BigQuery 概要(ざっくりと) ・BigQuery サンドボックス サンドボックスを使用すると クレジット カード情報を入力することなく、 Cloud Console でウェブ
UI を使用できます。 環境構築・課金設定なしではじめられる ↓ これからSQLを勉強する場合にピッタリ!
HANDSON 9
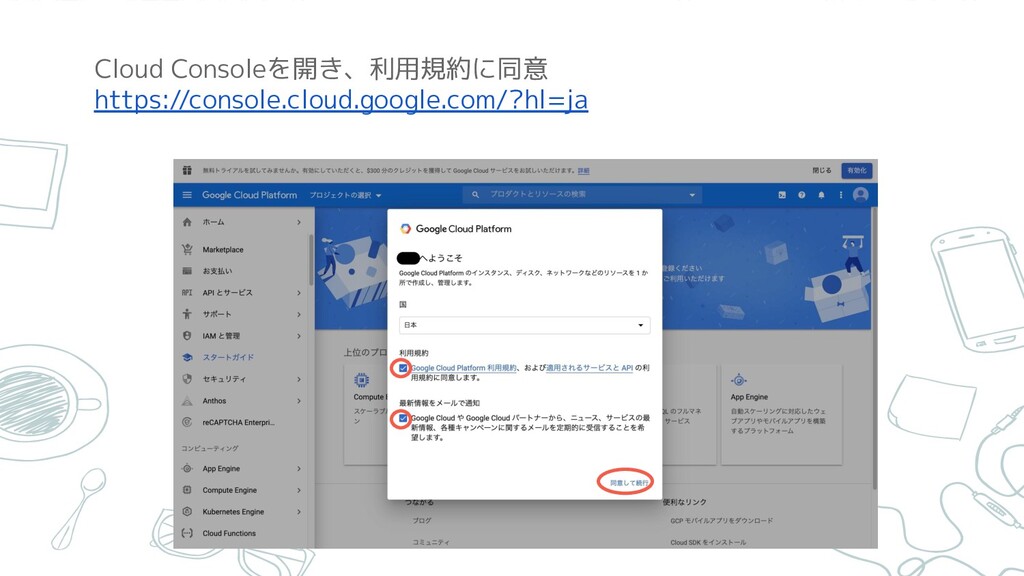
Cloud Consoleを開き、利用規約に同意 https://console.cloud.google.com/?hl=ja
ナビゲーション ペインで [BigQuery] をクリック
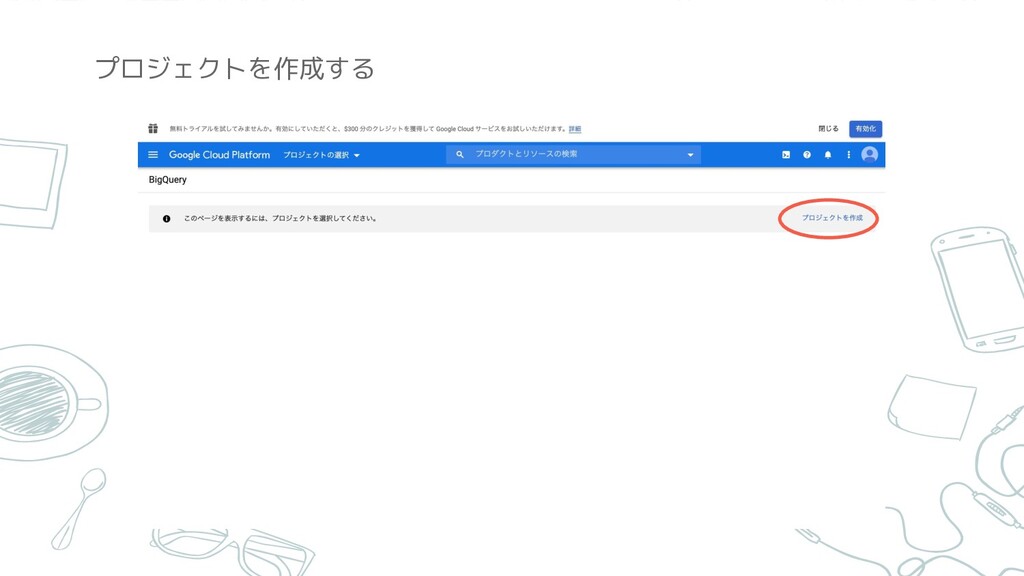
プロジェクトを作成する
プロジェクト名を入力して[作成]をクリック 任意のプロジェクト名(デフォル トのままでもOK)
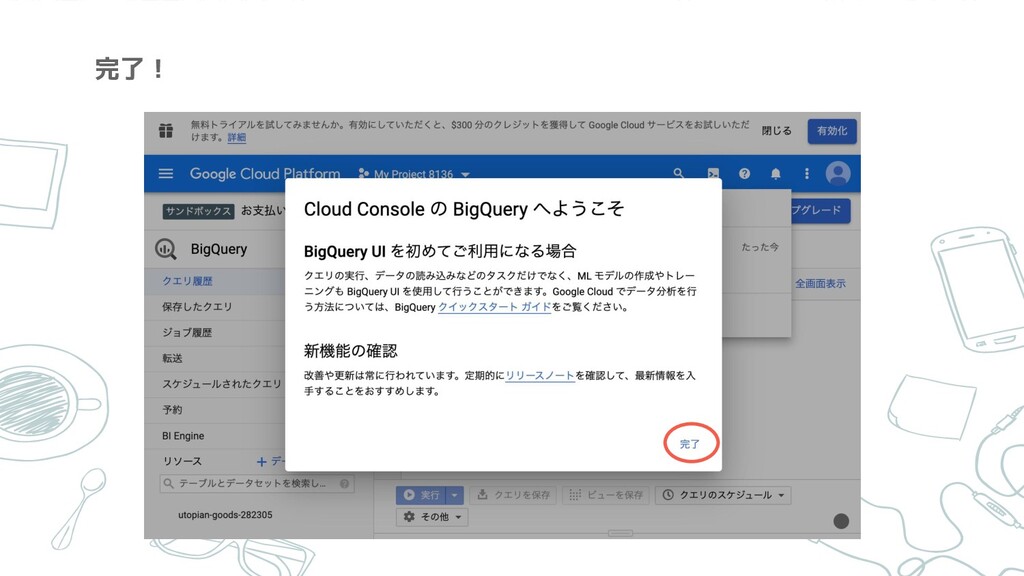
完了!
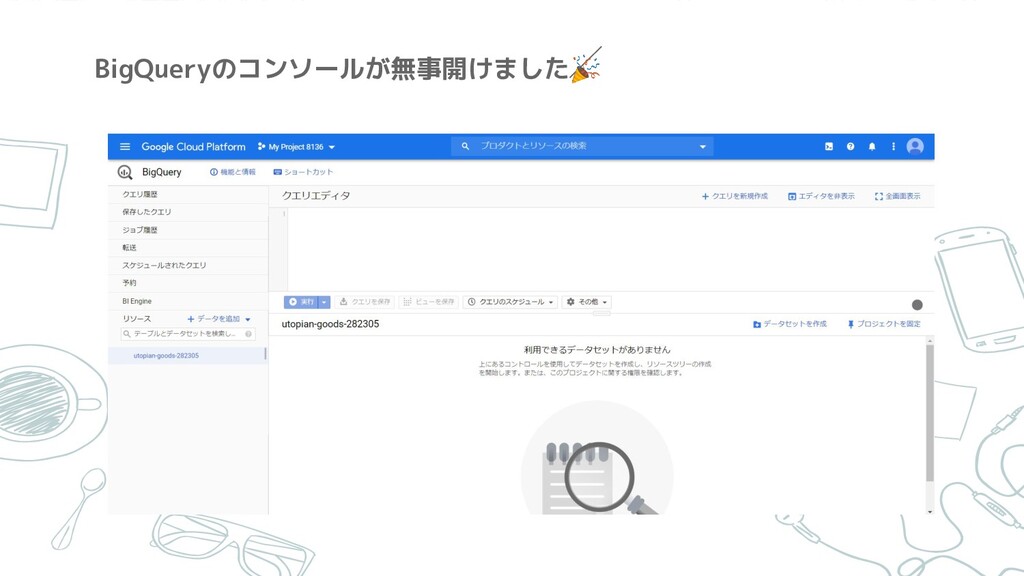
再びナビゲーション ペインで [BigQuery] をクリック
BigQueryのコンソールが無事開けました
以下よりCSVをダウンロード pageviews_20200704_050000_over10requests.csv https://bit.ly/3dZ28Cj
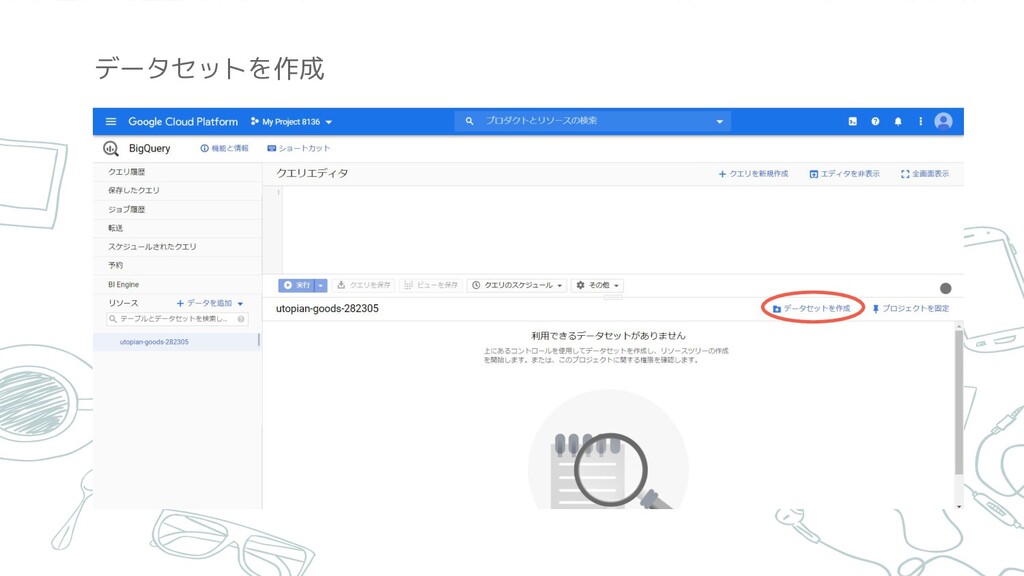
データセットを作成
データセットIDを入力して(なんでもOK) [データセットを作成]をクリック
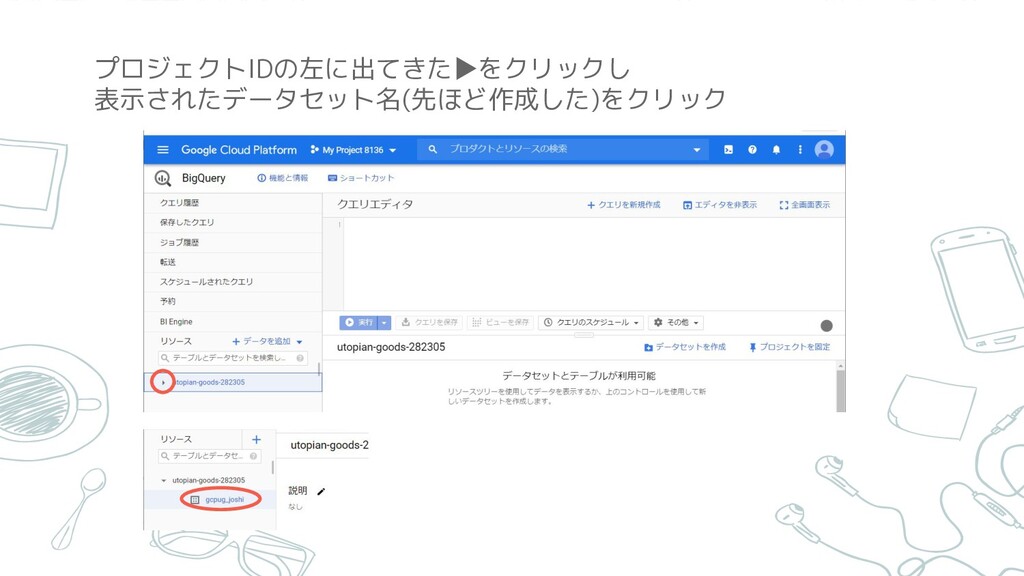
プロジェクトIDの左に出てきた▶をクリックし 表示されたデータセット名(先ほど作成した)をクリック
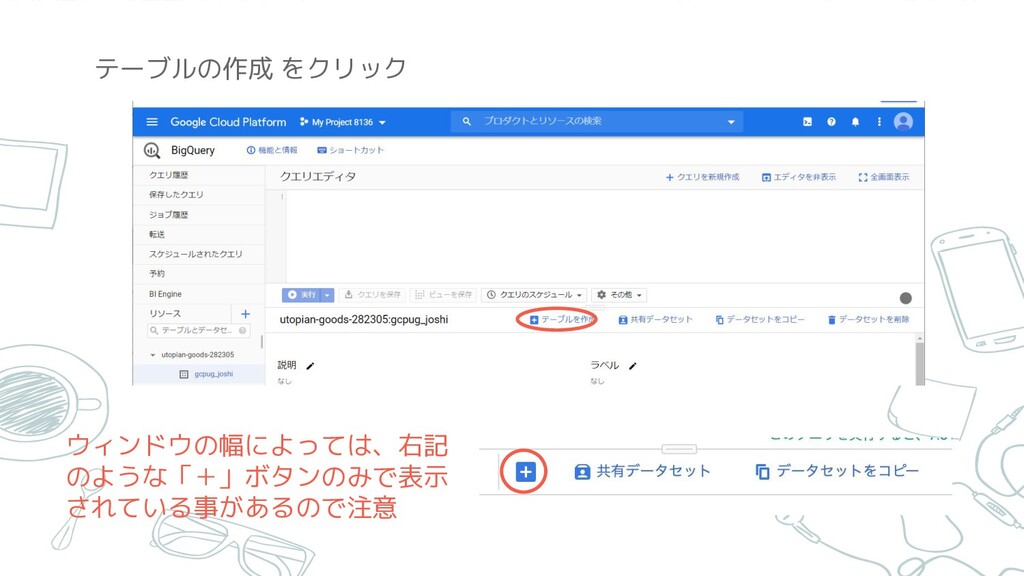
テーブルの作成 をクリック ウィンドウの幅によっては、右記 のような「+」ボタンのみで表示 されている事があるので注意
テーブルの作成元のプルダウンから[アップロード]を選択し、 [参照]をクリックして、先ほどローカルにダウンロードした CSVファイル(pageviews_20200704_050000_over10requests.csv)を指定する アップロードするファイルを選択すると ファイル形式は自動で認識される
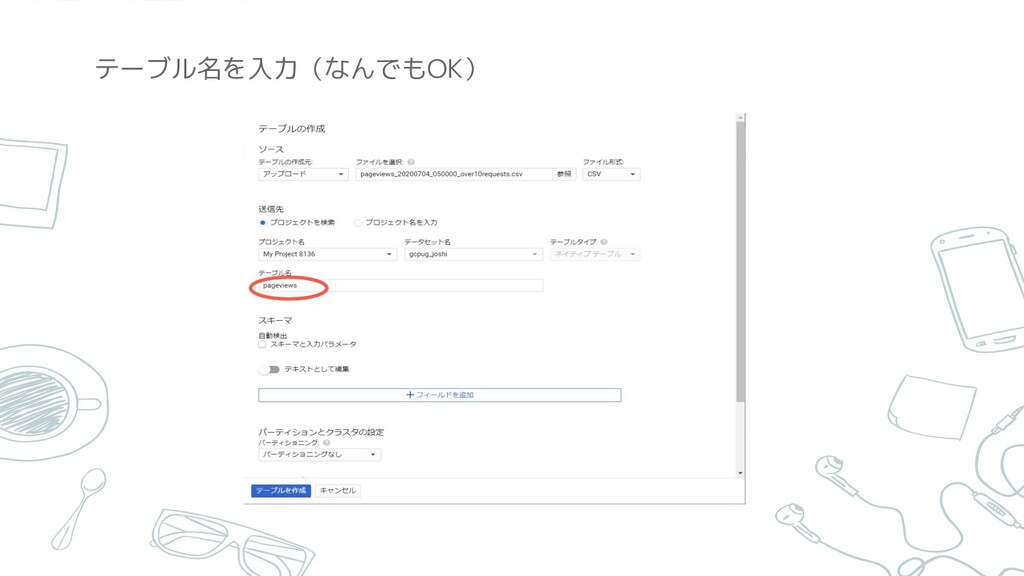
テーブル名を入力(なんでもOK)
自動検出 スキーマと入力パラメータ をチェック
[テーブル作成]をクリック
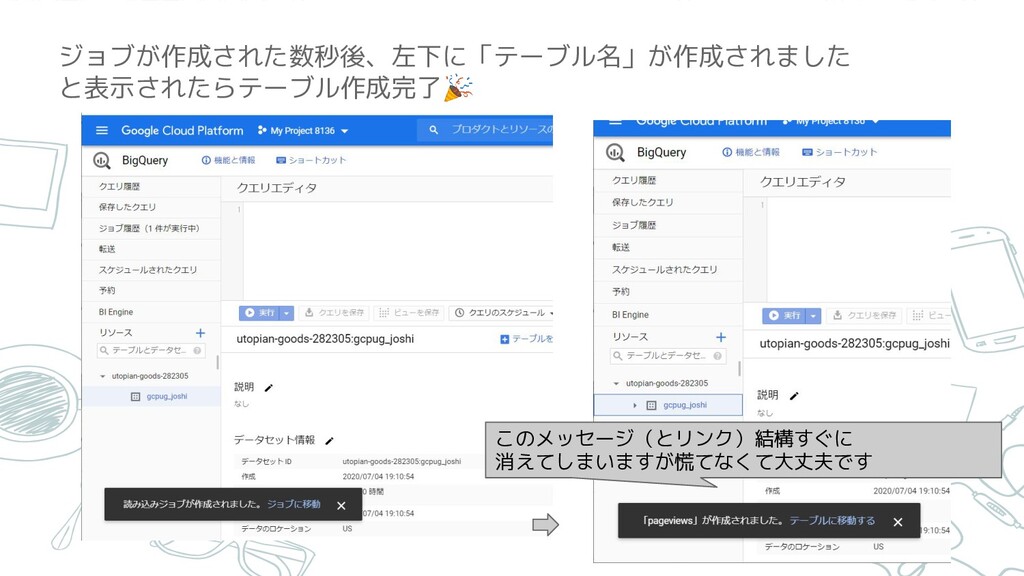
ジョブが作成された数秒後、左下に「テーブル名」が作成されました と表示されたらテーブル作成完了 このメッセージ(とリンク)結構すぐに 消えてしまいますが慌てなくて大丈夫です
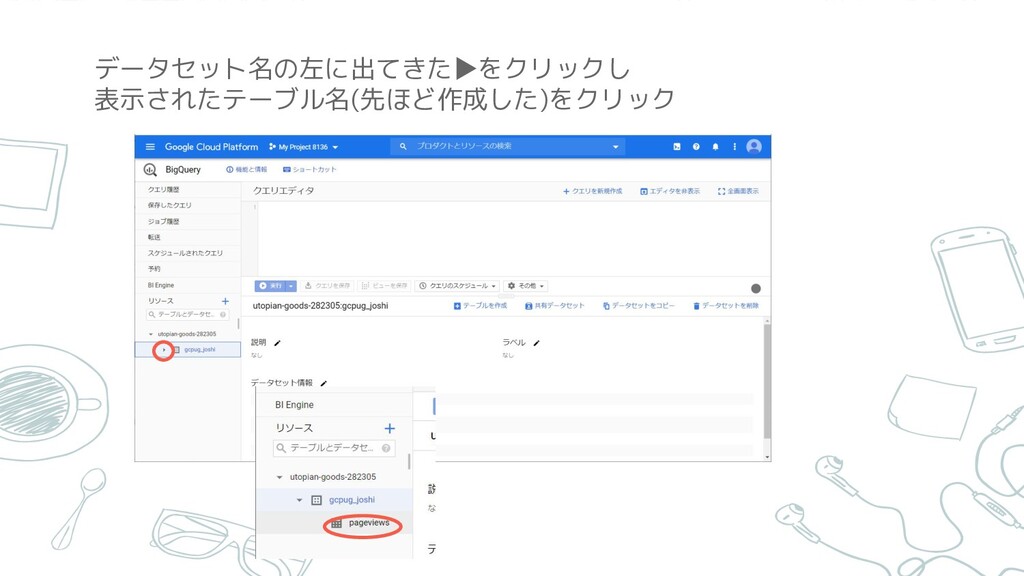
データセット名の左に出てきた▶をクリックし 表示されたテーブル名(先ほど作成した)をクリック
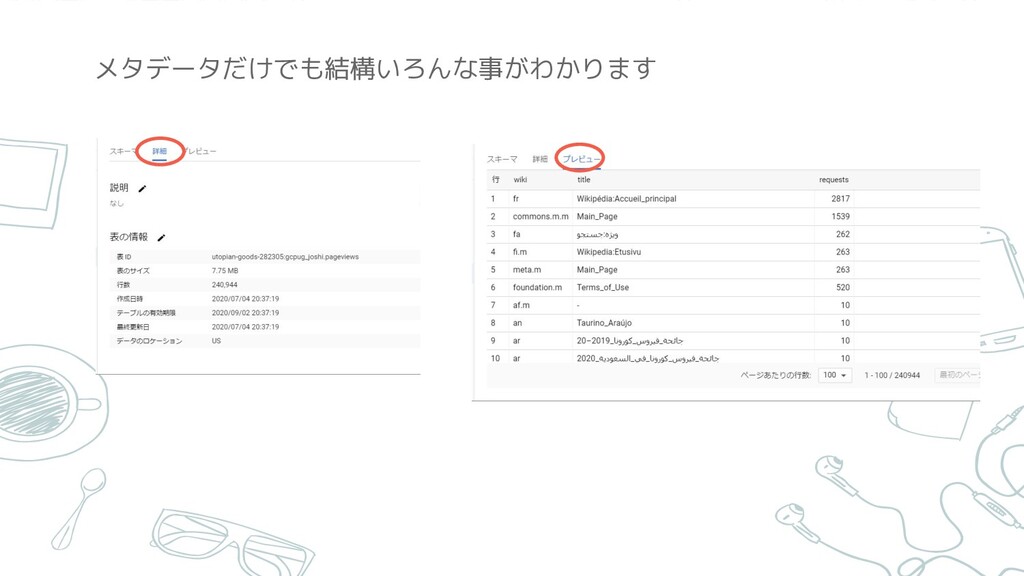
クエリを実行する前に、メタデータ(テーブルについての説明等) をみていきます
メタデータだけでも結構いろんな事がわかります
いよいよSQLを書きます! [テーブルをクエリ]をクリック ウィンドウの幅によっては、右記 のような「 」ボタンのみで表示 されている事があるので注意
SELECT と FROMの間に * (アスタリスク、前後にスペースが必要) を追記してドライランを確認 さきほど作成した [プロジェクト名].[データセット名].[テーブル名] を使った基本のSELECT句が自動生成されている ここに
* (アスタリスク前後スペース)を追記 USの場合$5.00 per TBなのでこのクエリの課金は $0.00003(サンドボックスの場合は無料)
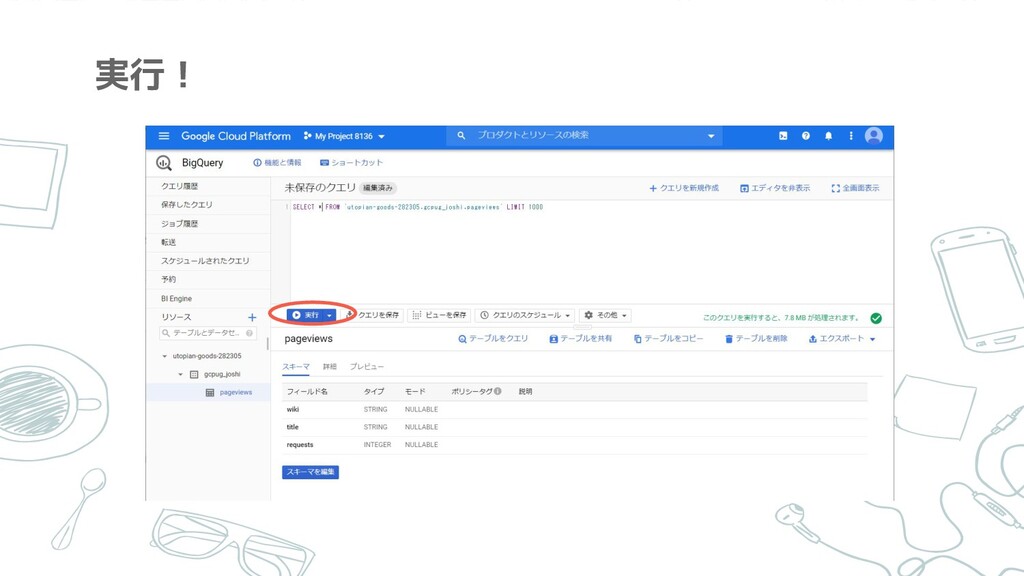
実行!
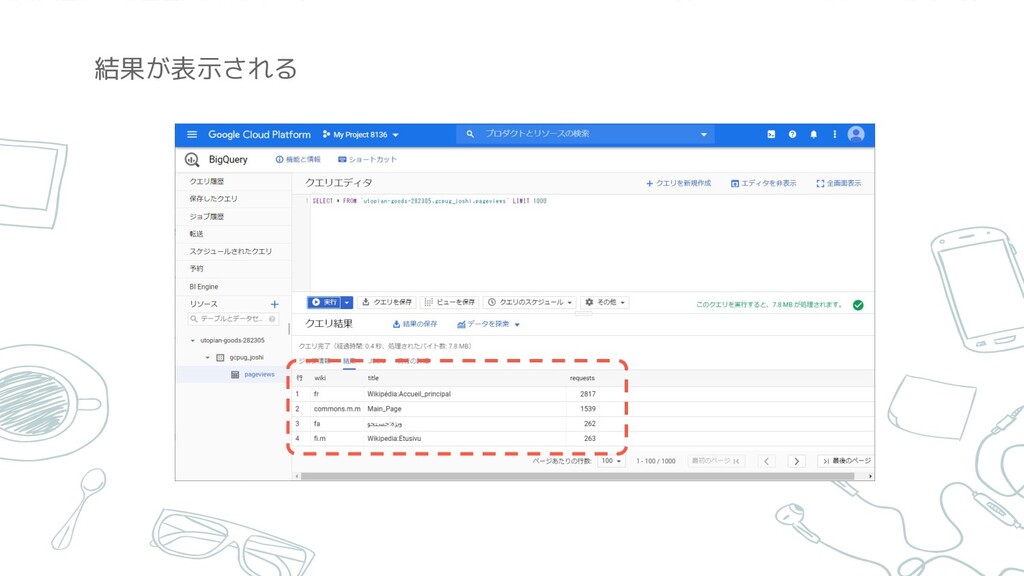
結果が表示される
SELECT*で確認したい内容はたいていプレビューで確認できる (ちなみに LIMIT は表示行数を減らすだけでスキャン量削減には効果なし) 大きめのテーブルを検索する際には、必要な項目(列)のみ指定する事を推奨 Limit1000 を消してもスキャン量は 変化しない事を確認してみてください
SQLの基本 SELECT: どの項目(列)のデータを検索するか FROM: どのテーブルから検索するか WHERE: どのような条件で行を検索するか 今さらだけど
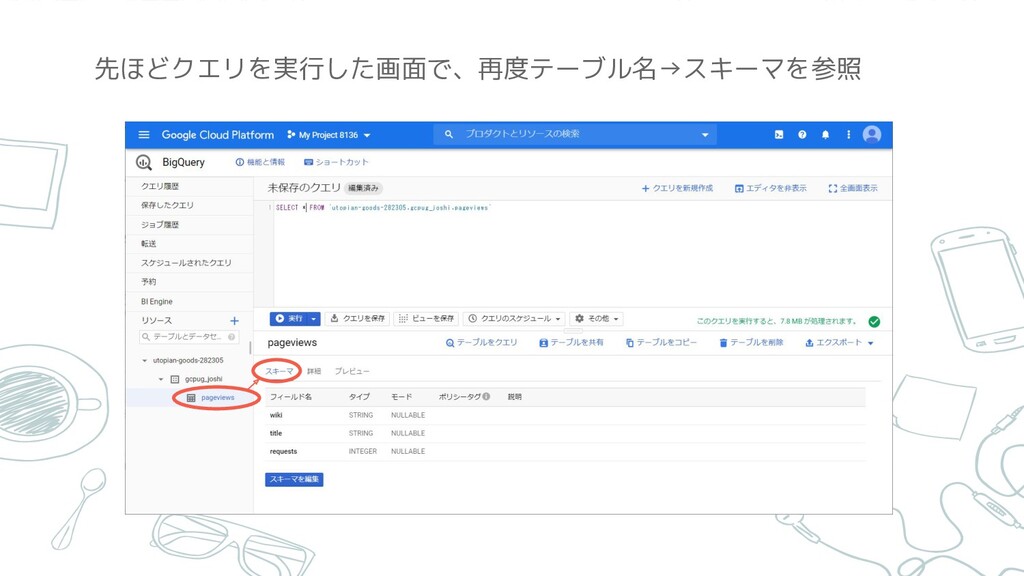
先ほどクエリを実行した画面で、再度テーブル名→スキーマを参照
先ほどの*を消し、スキーマのフィールド名[title][requests]クリック 末尾に WHERE wiki = 'ja' を追記 *を消す 末尾に WHERE wiki =
'ja' を追記 フィールド名をクリックすると 自動で必要な部分に,(カンマ)を つけて入力してくれる
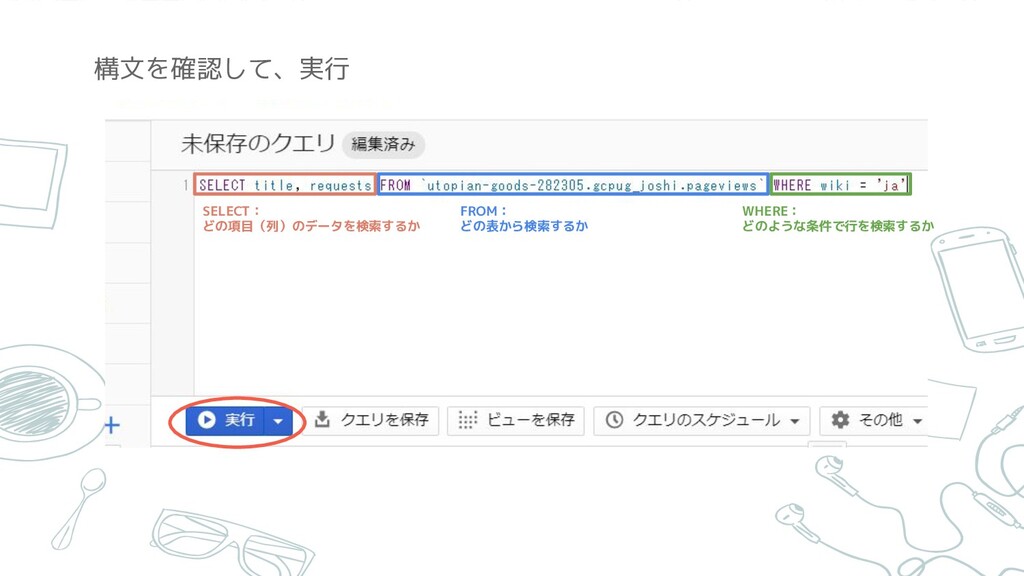
構文を確認して、実行 SELECT: どの項目(列)のデータを検索するか FROM: どの表から検索するか WHERE: どのような条件で行を検索するか
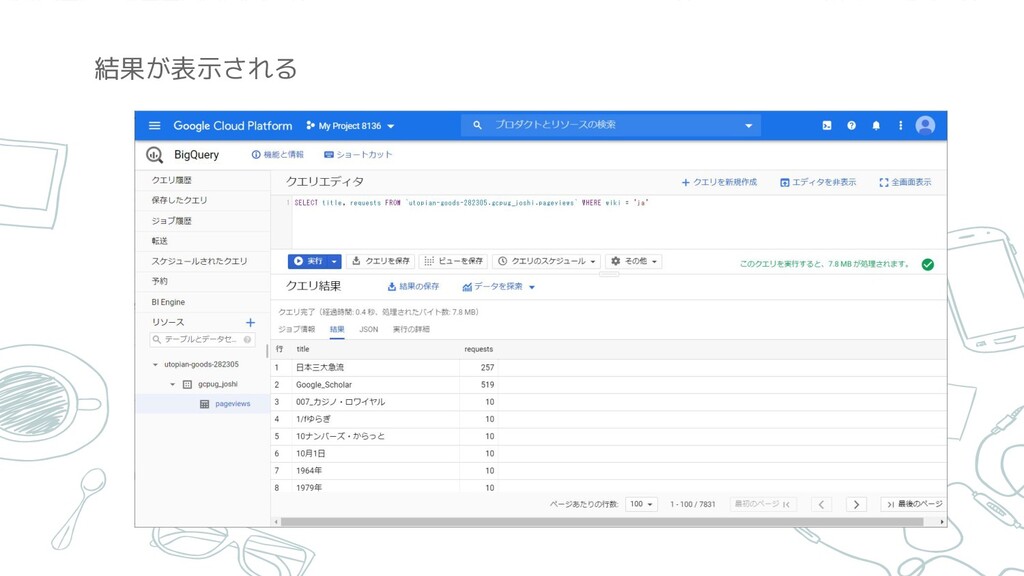
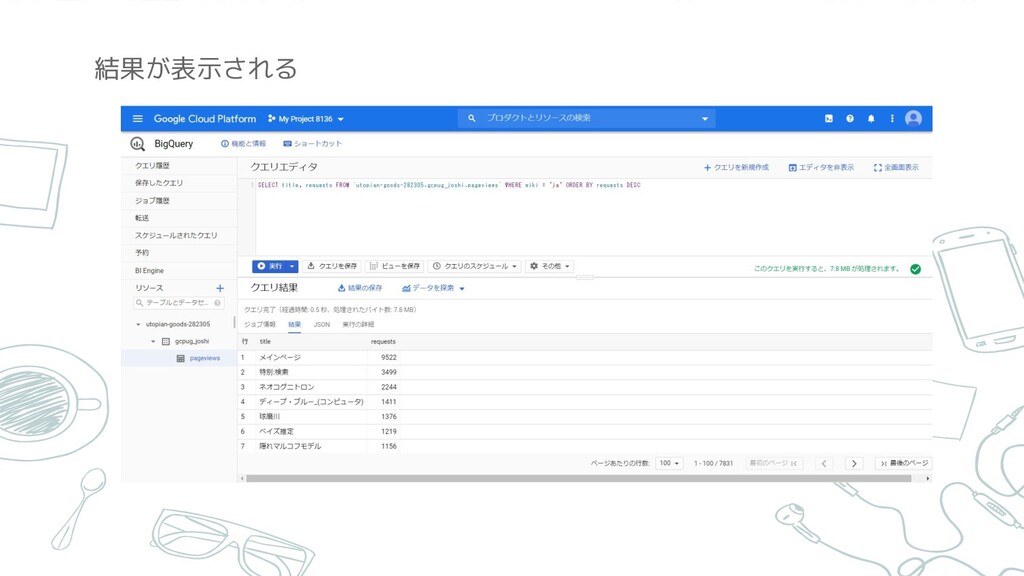
結果が表示される
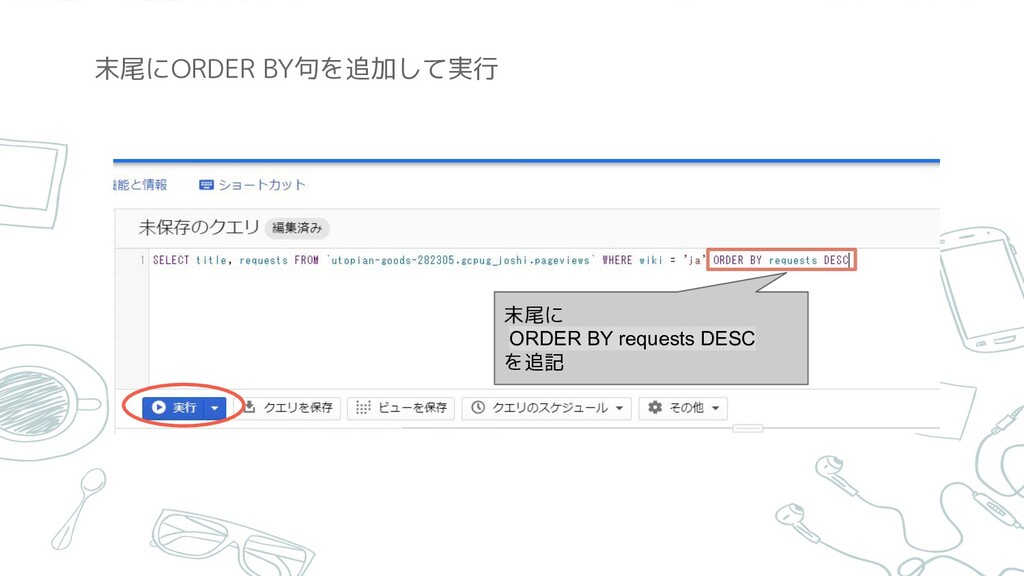
SQLの基本 ORDER BY: 特定のカラムの値に応じて行を並び変える ※昇順、降順について 未指定またはASC→昇順 DESC→降順 今さらだけど
末尾にORDER BY句を追加して実行 末尾に ORDER BY requests DESC を追記
結果が表示される
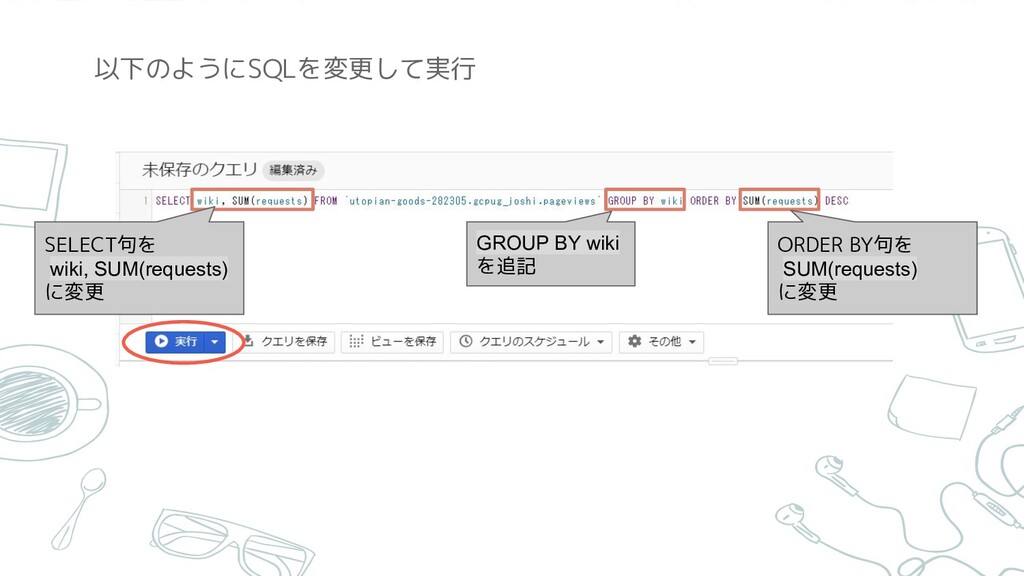
SQLの基本 GROUP BY: SELECT文において特定の列の値が等しい行ごとに表 をグループ化する。SUMやCOUNTなどの、集計関数 を使用する場合は指定が必要。 今さらだけど
以下のようにSQLを変更して実行 SELECT句を wiki, SUM(requests) に変更 GROUP BY wiki を追記 ORDER
BY句を SUM(requests) に変更
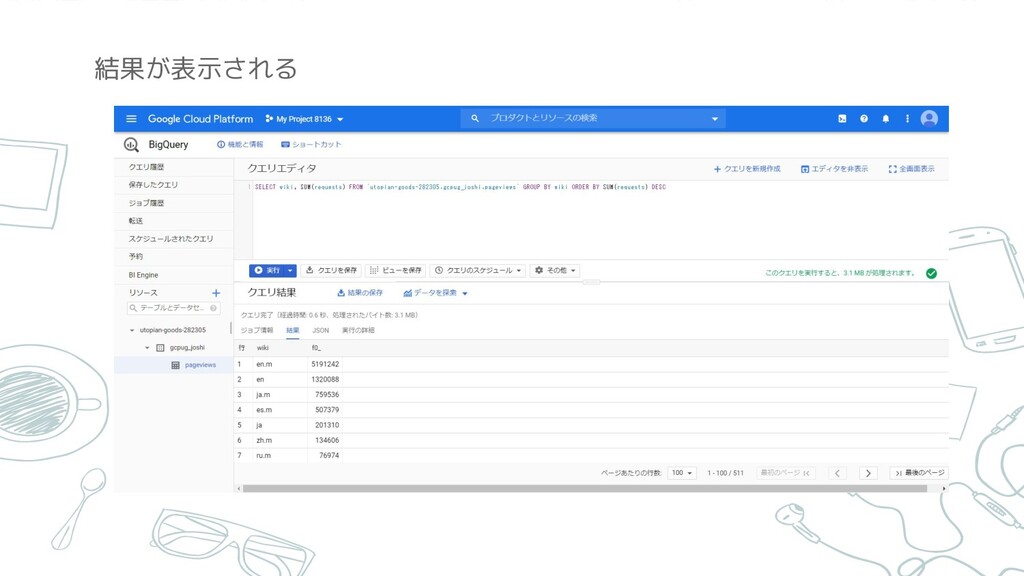
結果が表示される
本日使用したデータについて Query the Wikipedia dataset in BigQuery: https://codelabs.developers.google.com/codelabs/cloud-bigquery-wikipe dia/index.html 上記のチュートリアルを参考にして、最近のデータ(2020/7/4
050000) を取得し、ローカルからアップロード可能な10MB以内になるように requestsが10件以上のデータに絞ったものです。 Cloud Shellを使用したりと、本日のハンズオンより少しレベルアップする 内容になっているので、ぜひチャレンジしてみてください。
Thanks! 47 @megumi_takahira
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ナビゲーション ペインで [BigQuery] をクリック](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_10.jpg){kind=link}
{kind=link}
![プロジェクト名を入力して[作成]をクリック 任意のプロジェクト名(デフォル トのままでもOK)](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_12.jpg){kind=link}
{kind=link}
![再びナビゲーション ペインで [BigQuery] をクリック](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![データセットIDを入力して(なんでもOK) [データセットを作成]をクリック](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
![テーブルの作成元のプルダウンから[アップロード]を選択し、 [参照]をクリックして、先ほどローカルにダウンロードした CSVファイル(pageviews_20200704_050000_over10requests.csv)を指定する アップロードするファイルを選択すると ファイル形式は自動で認識される](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
![[テーブル作成]をクリック](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![いよいよSQLを書きます! [テーブルをクエリ]をクリック ウィンドウの幅によっては、右記 のような「 」ボタンのみで表示 されている事があるので注意](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_29.jpg){kind=link}
![SELECT と FROMの間に * (アスタリスク、前後にスペースが必要) を追記してドライランを確認 さきほど作成した [プロジェクト名].[データセット名].[テーブル名] を使った基本のSELECT句が自動生成されている ここに](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![先ほどの*を消し、スキーマのフィールド名[title][requests]クリック 末尾に WHERE wiki = 'ja' を追記 *を消す 末尾に WHERE wiki =](https://files.speakerdeck.com/presentations/970514362ff04d6ba540000f76531dca/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}