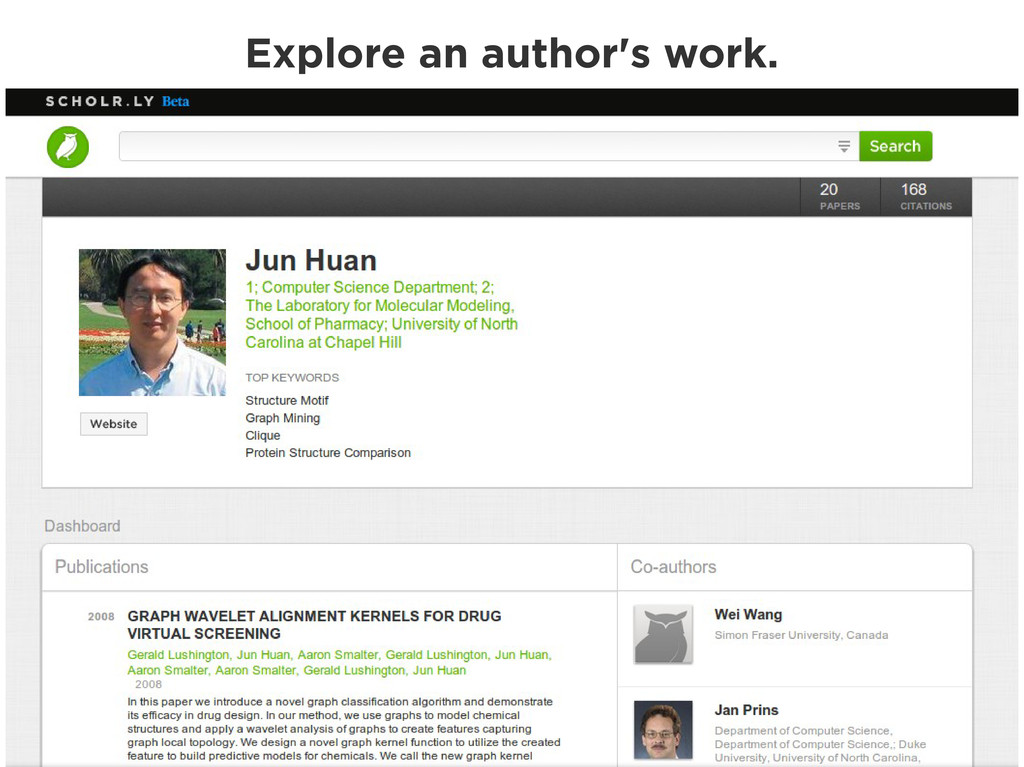
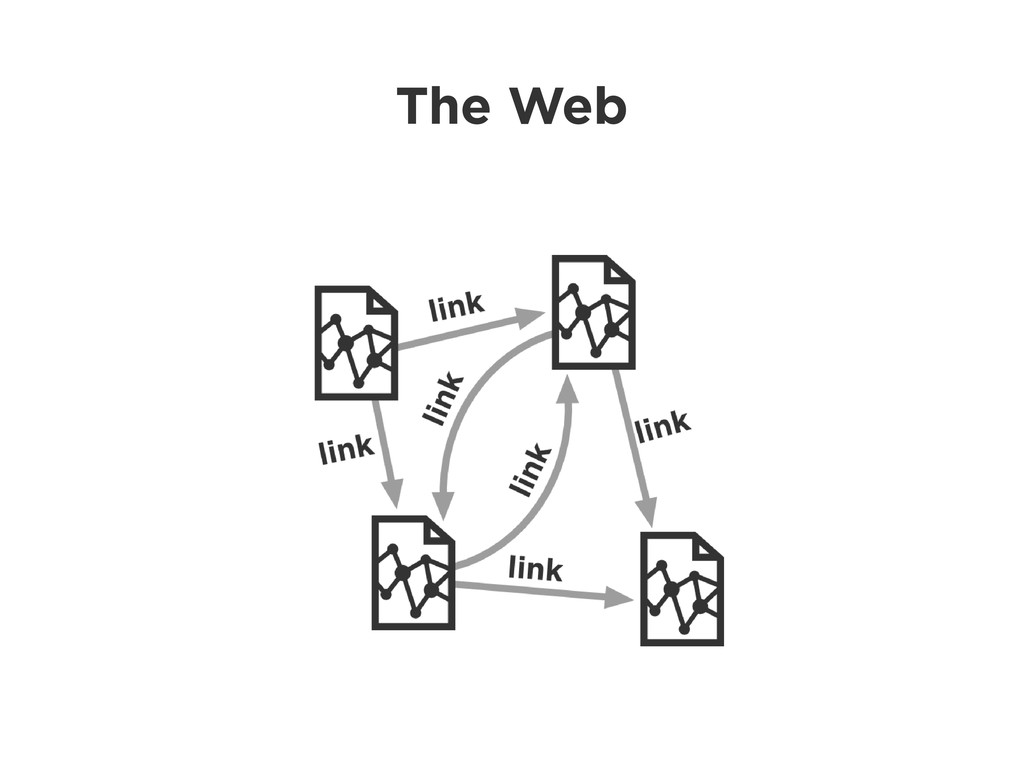
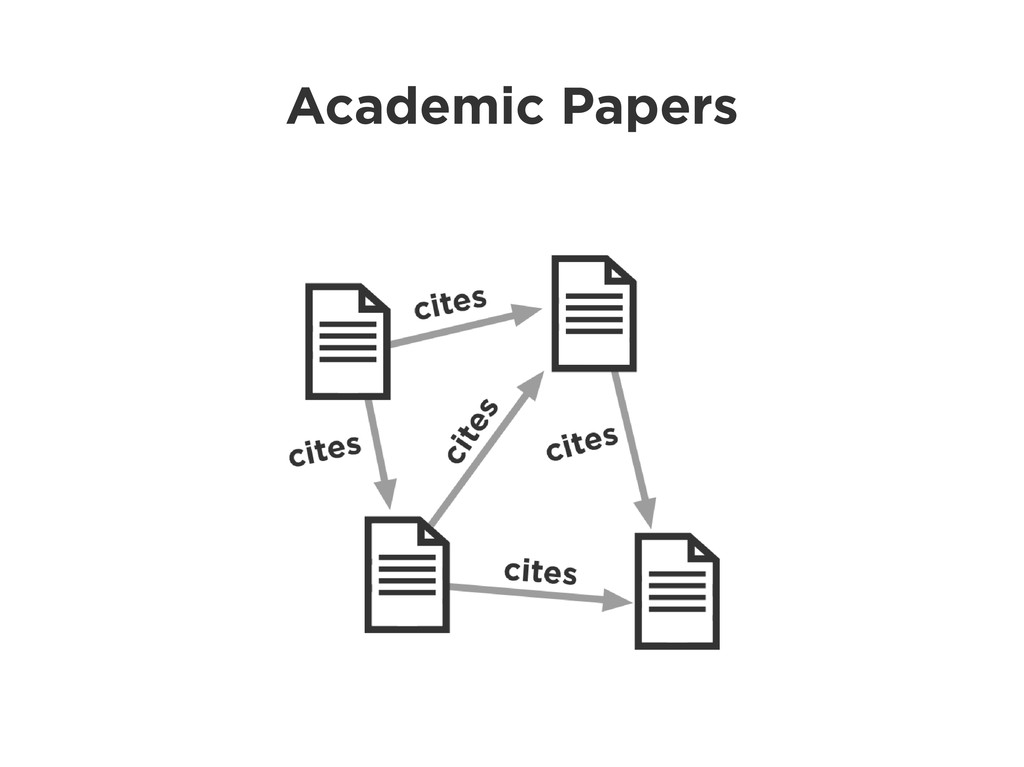
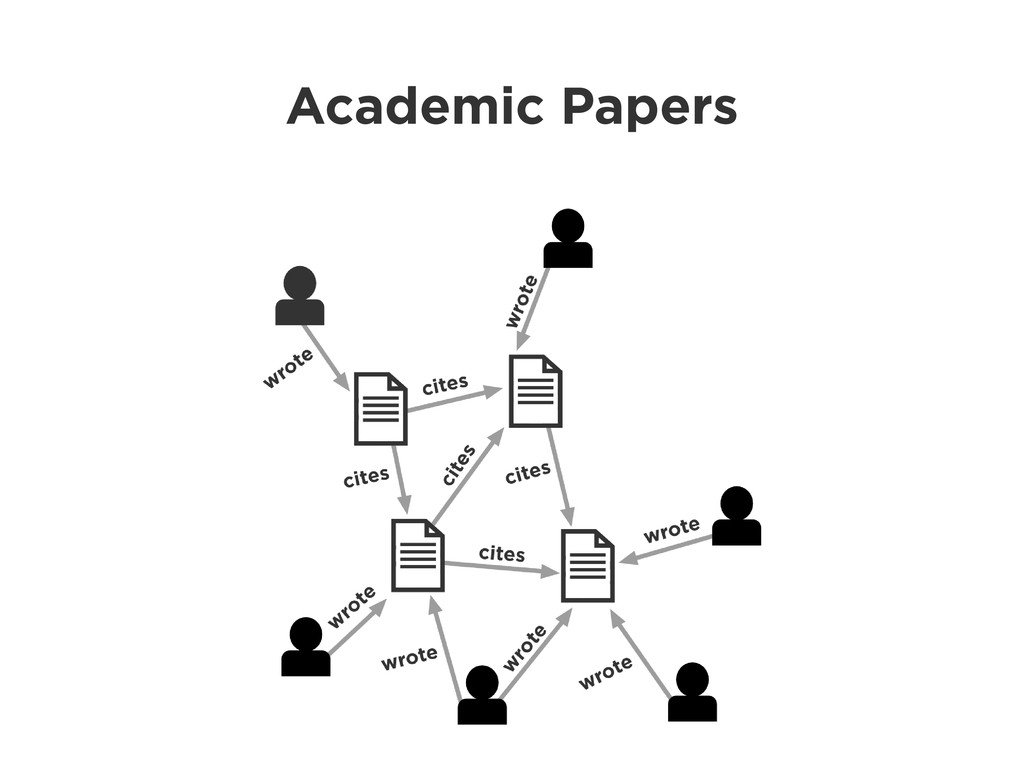
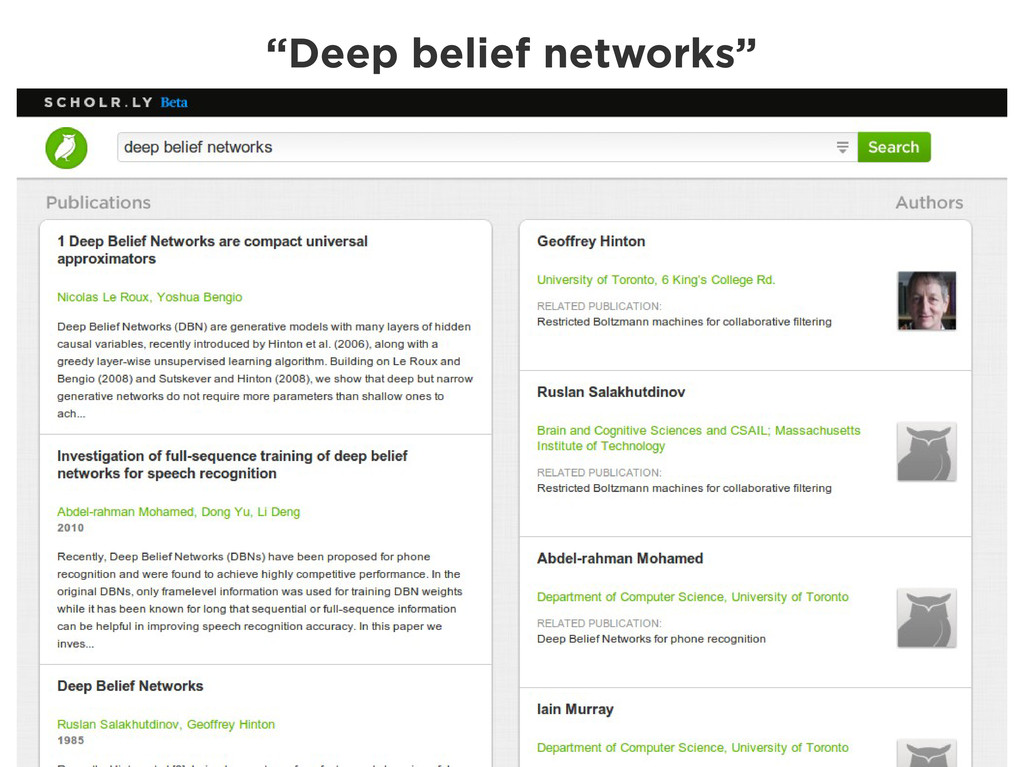
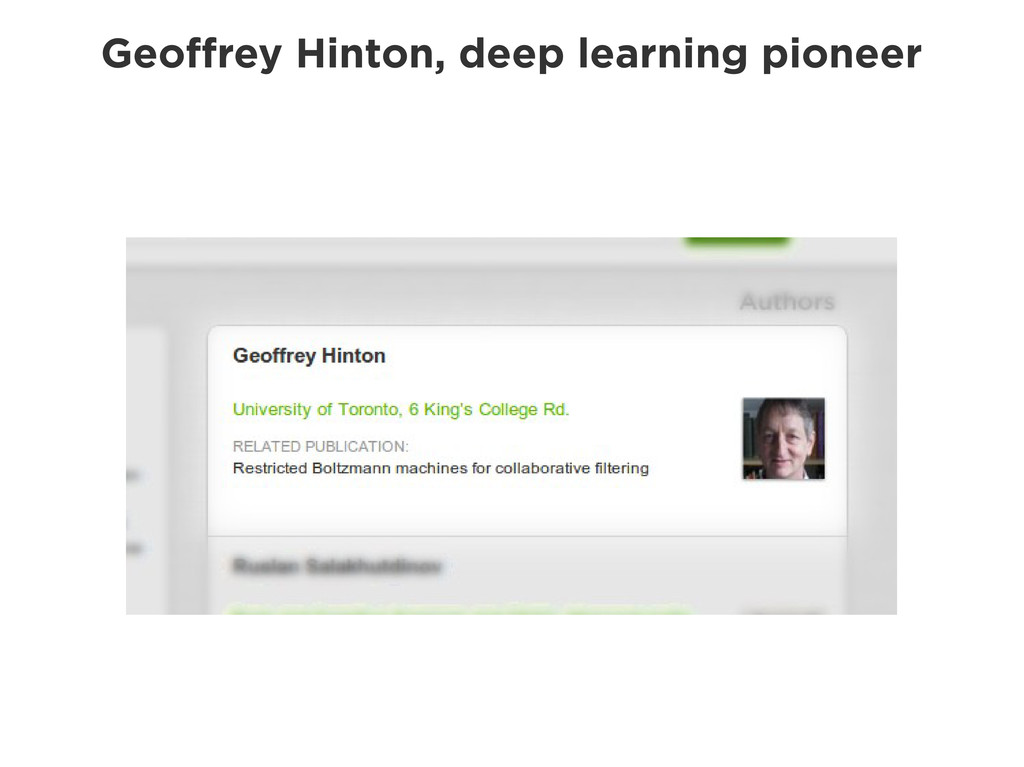
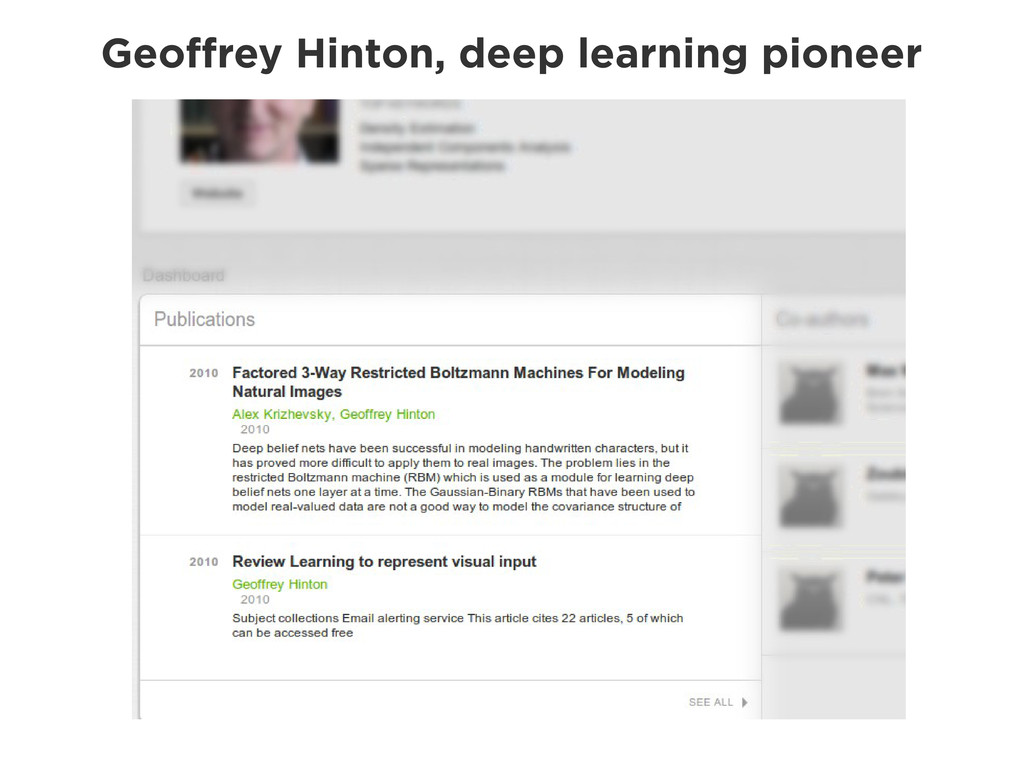
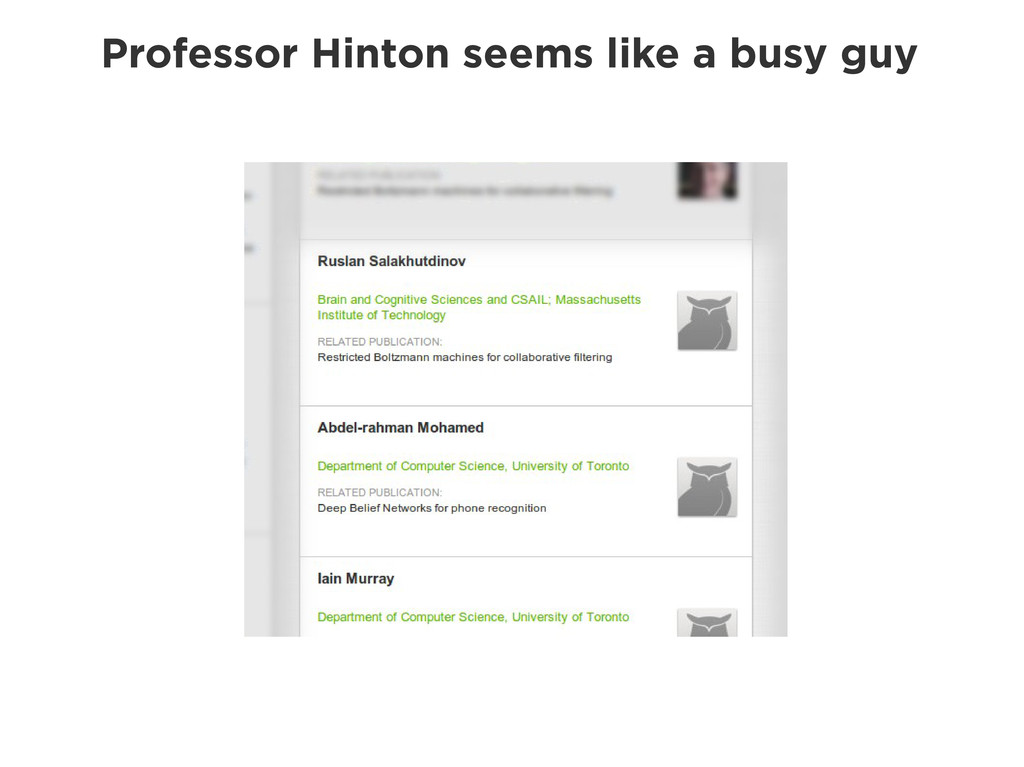
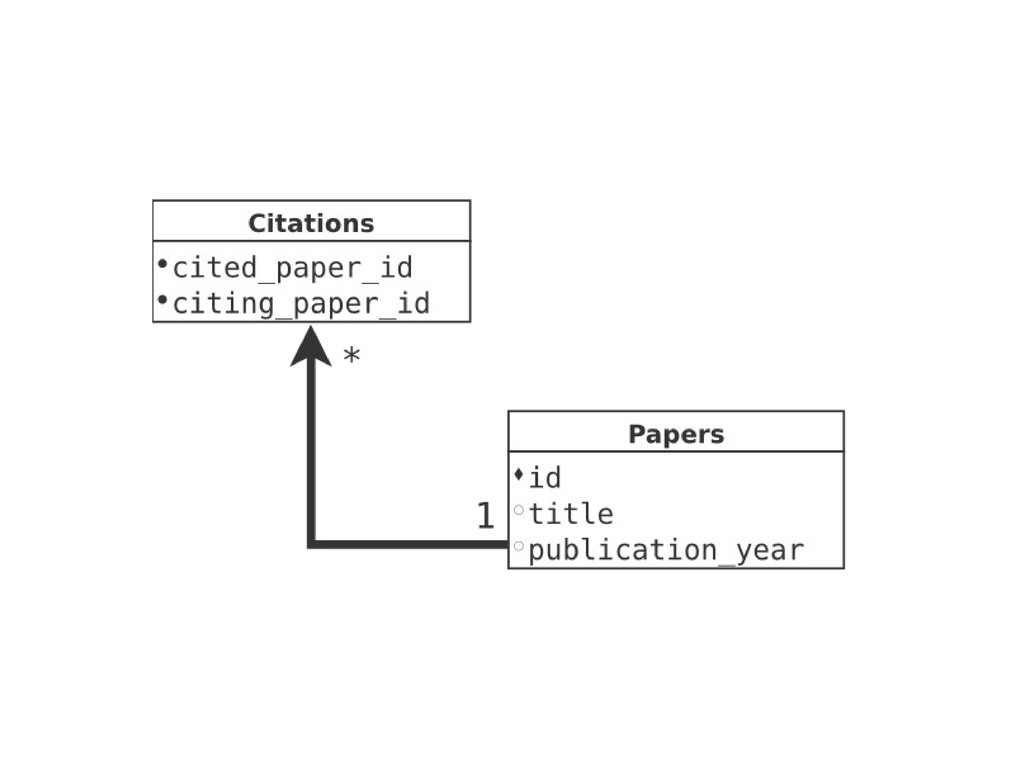
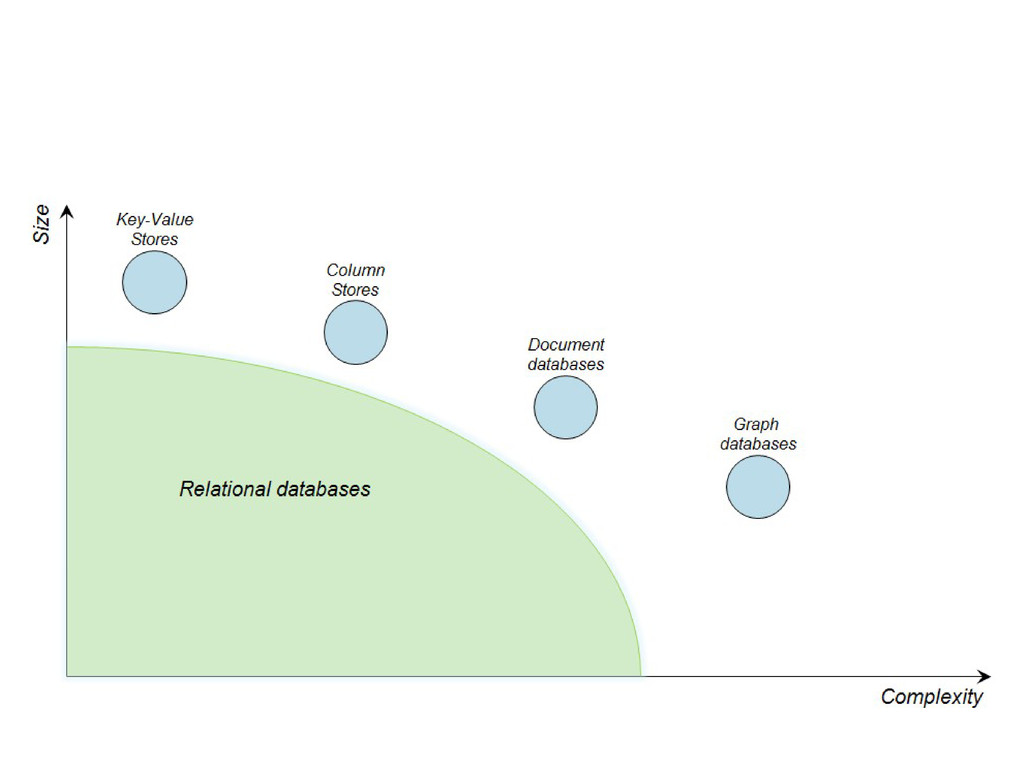
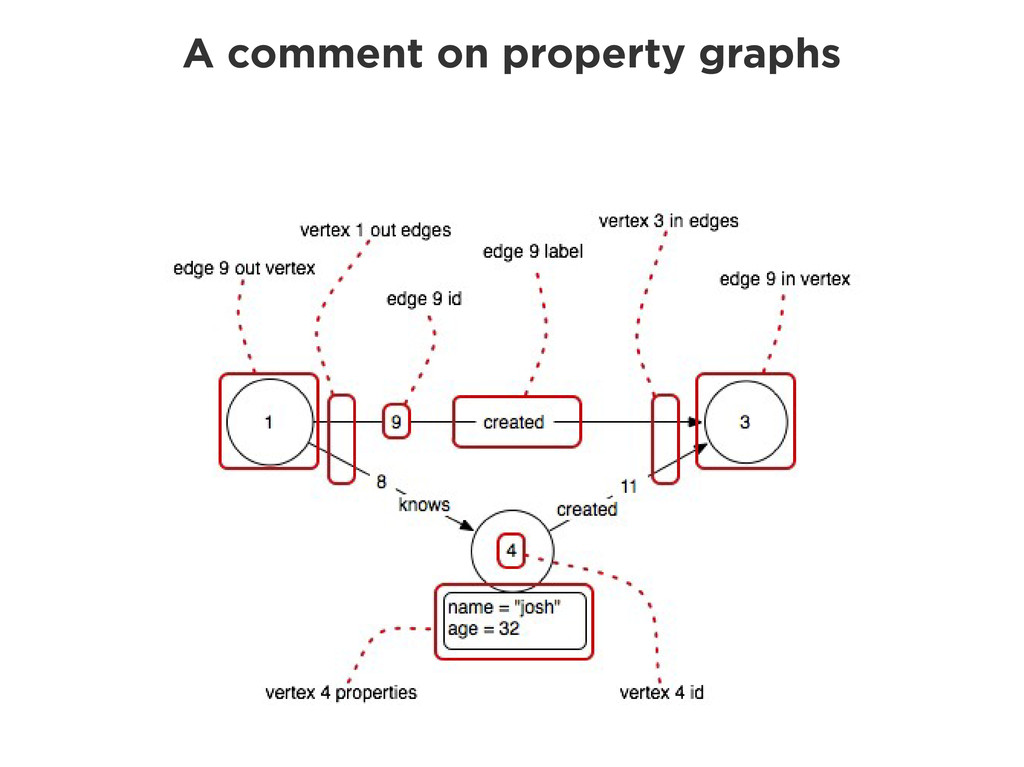
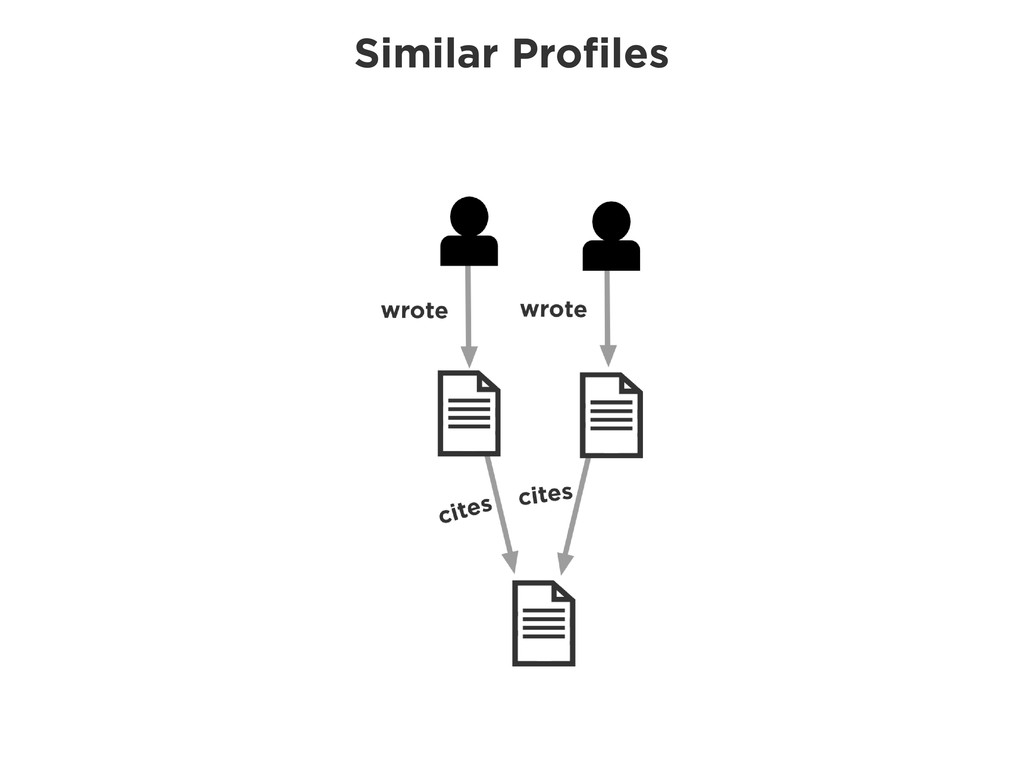
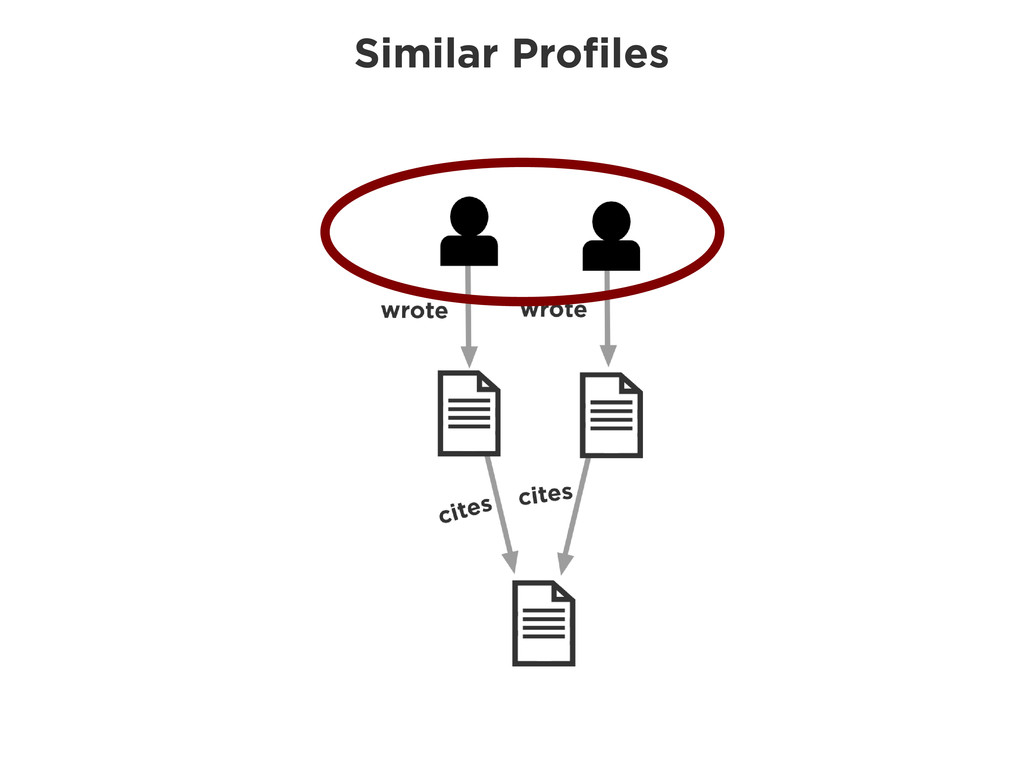
Graphs are a powerful abstraction in many highly connected domains. Social networks are an obvious example, but less obvious include biology and security. Scientific publishing is one of those domains. Citation and co-authorship in research form a huge graph. I'll share my experience using just such a graph to power our academic search engine, http://scholr.ly. I'll focus on how we use a graph database to solve a number of problems, including search, disambiguation, and recommendations.
A rough script of the presentation can be found at http://mattluongo.com/post/presentation-at-datadaytexas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
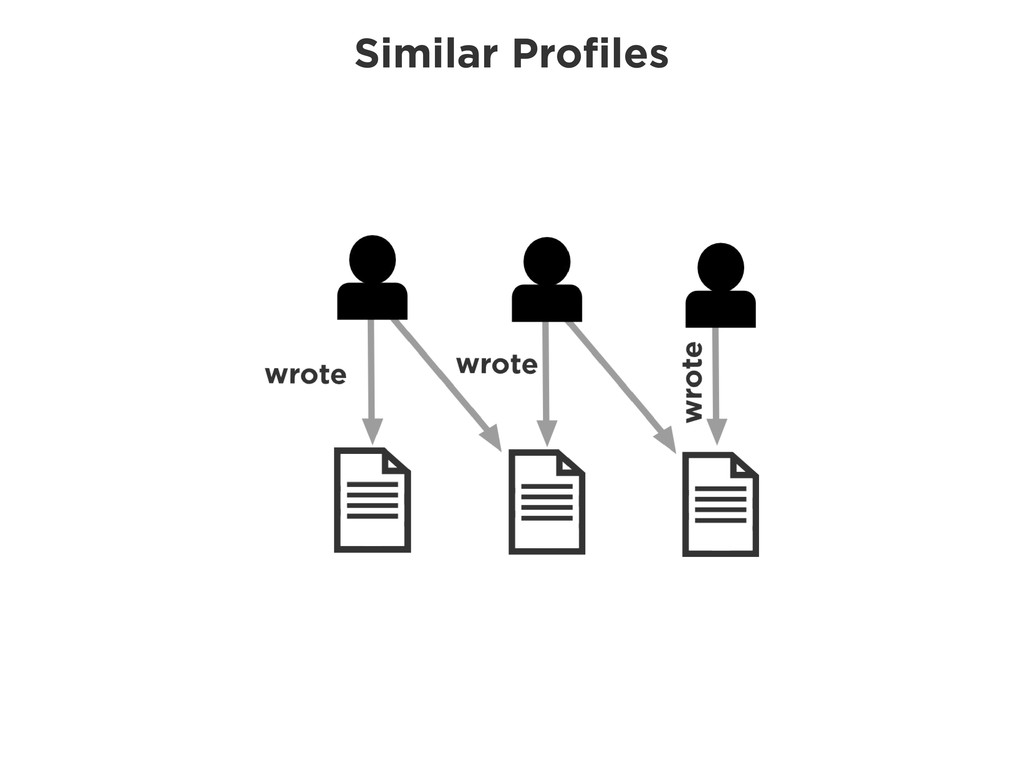
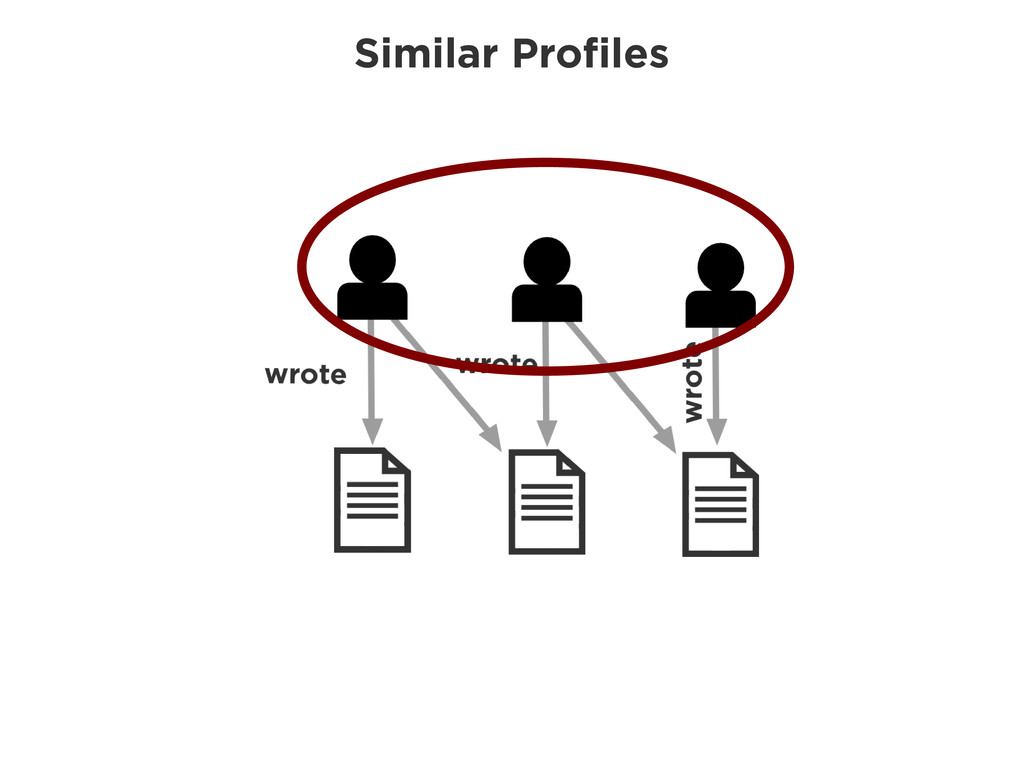
![Similar Profiles START author=node(123) MATCH author-[:wrote]->(work)-[:cites]->(cited_work) \ <-[:cites]-(other_works)<-[:wrote]-(other_author) WITH author,](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
![Similar Profiles START author=node(123) MATCH author-[:wrote]->(work)<-[:wrote]-(coauthor) \ -[:wrote]->(other_work) \ <-[:wrote]-(second_coauthor)](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
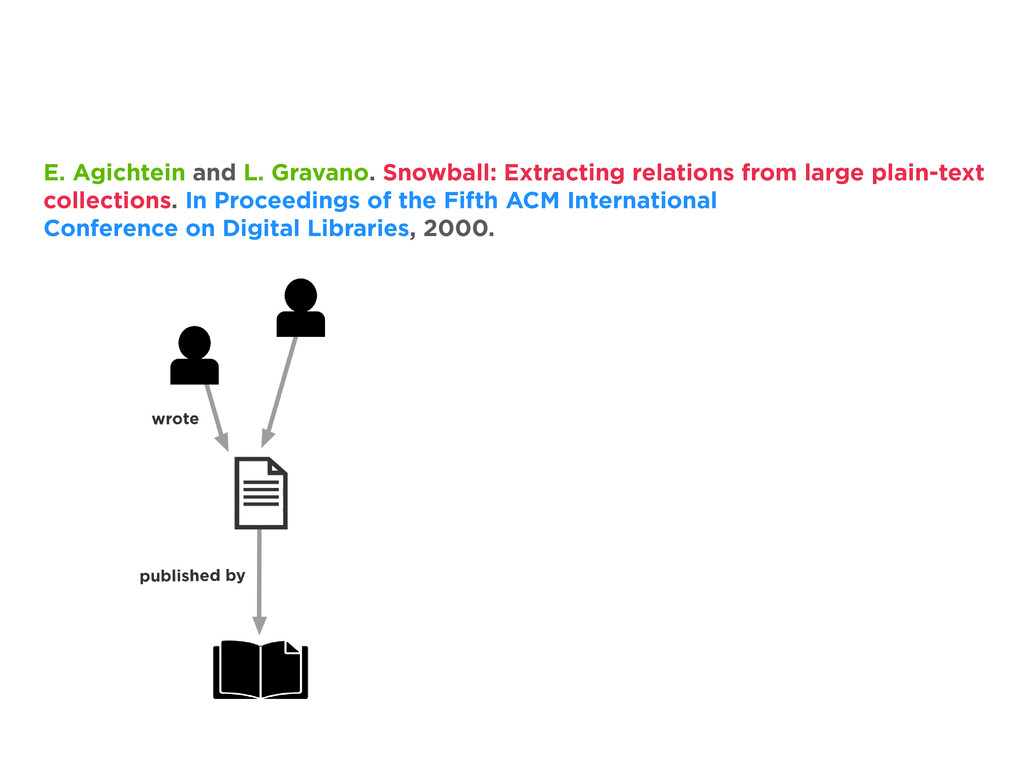{kind=link}
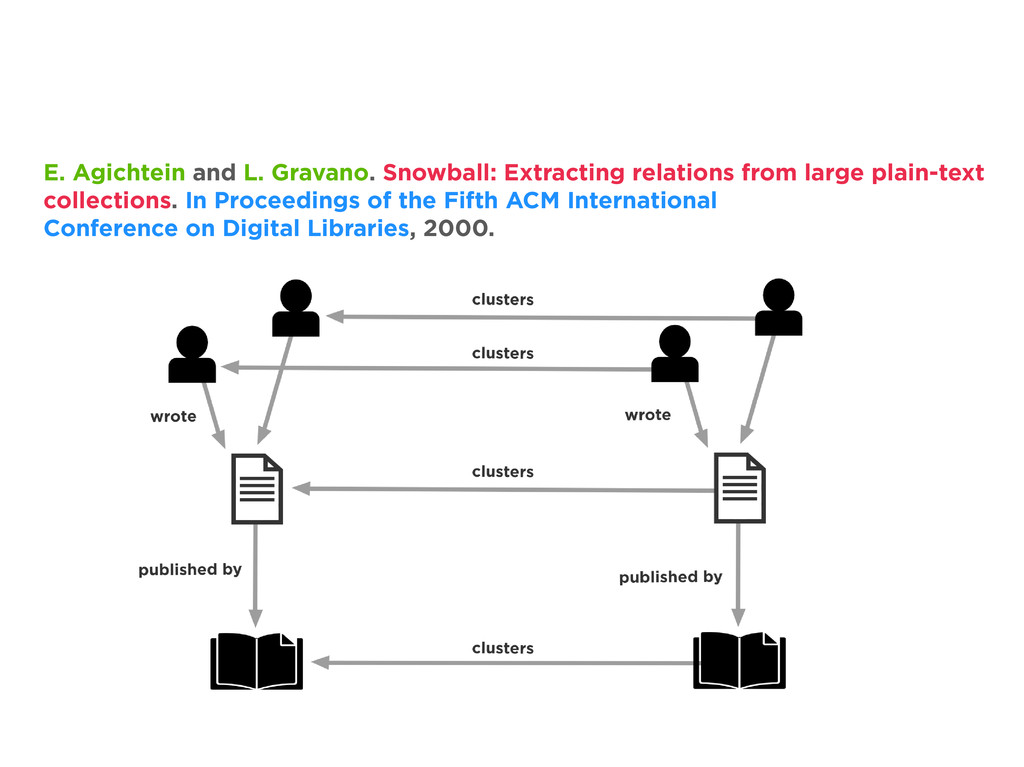{kind=link}
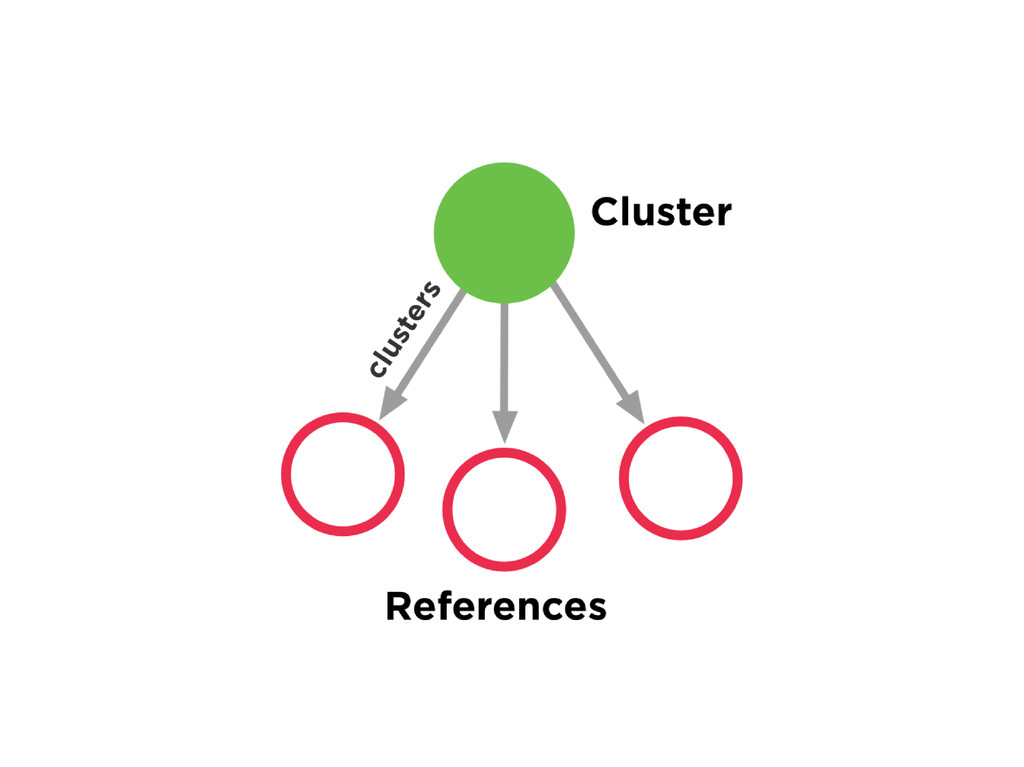
![Entity Resolution votes = [:] g.v(clusterIds).out(‘clusters’).map.each{ properties -> properties.each{ votes[it.key]](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
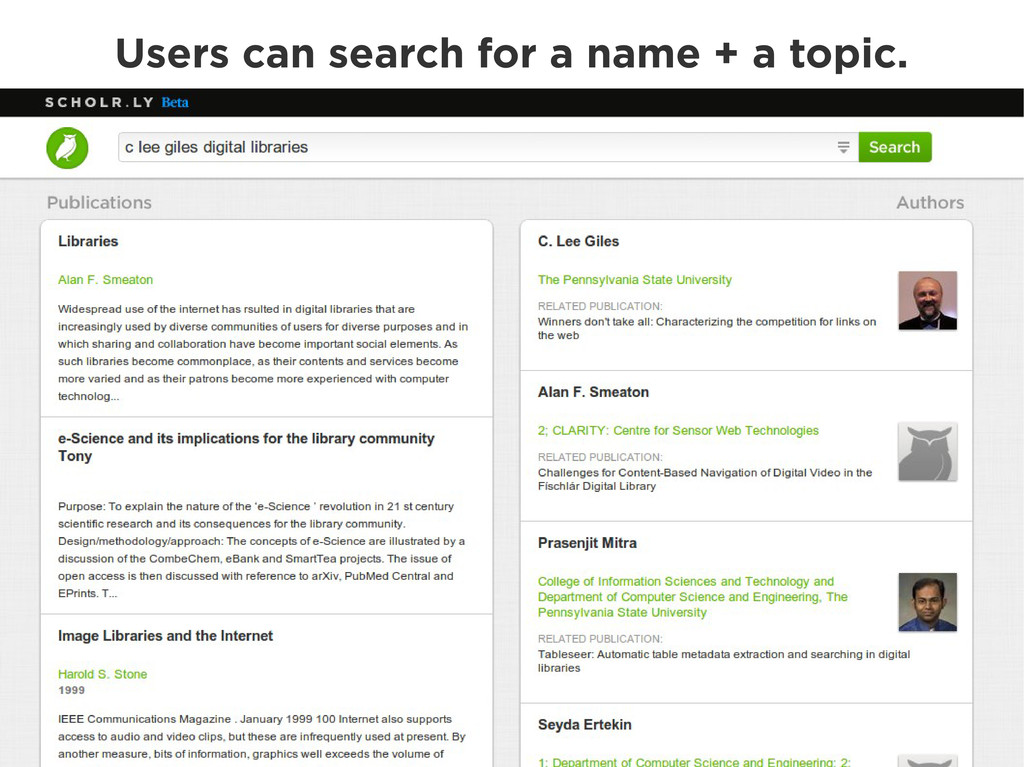{kind=link}
![Search authorCounts = [:] g.v(publicationIds).in(‘WROTE’).\ groupCount(authorCounts).iterate() return authorCounts.collect{author, count →](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_49.jpg){kind=link}
![Search authorCounts = [:] coauthorCounts = [:] g.v(publicationIds).in(‘WROTE’) \ .groupCount(authorCounts).out(‘WROTE’)](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_50.jpg){kind=link}
![Search citedAuthorCounts = [:] g.v(publicationIds).out(‘cite’).in(‘wrote’) \ .groupCount(citedAuthorCounts)](https://files.speakerdeck.com/presentations/b8fe48c07d070130e25a22000a91a929/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}