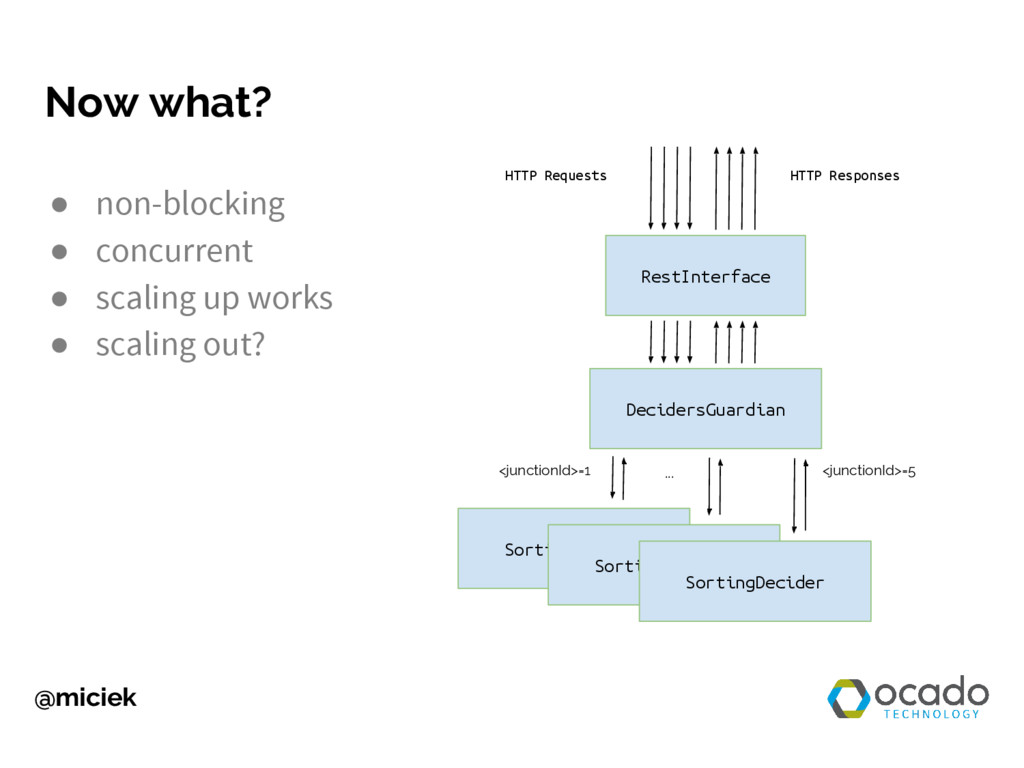
Writing distributed applications is very hard, especially when you start developing them as single-noded ones. Programmers tend to focus on functionalities first, leaving the scalability issues for later. Fortunately, Akka gives us many tools for scaling out and we can use them very early in the development process. I want to show you how to take advantage of these features.
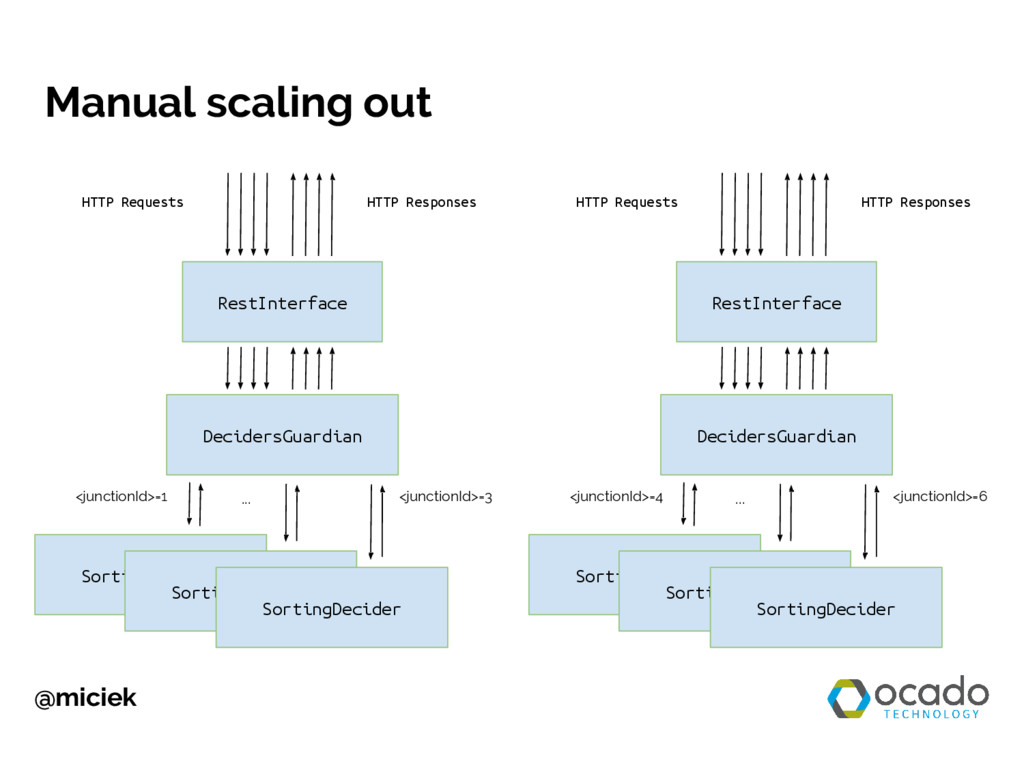
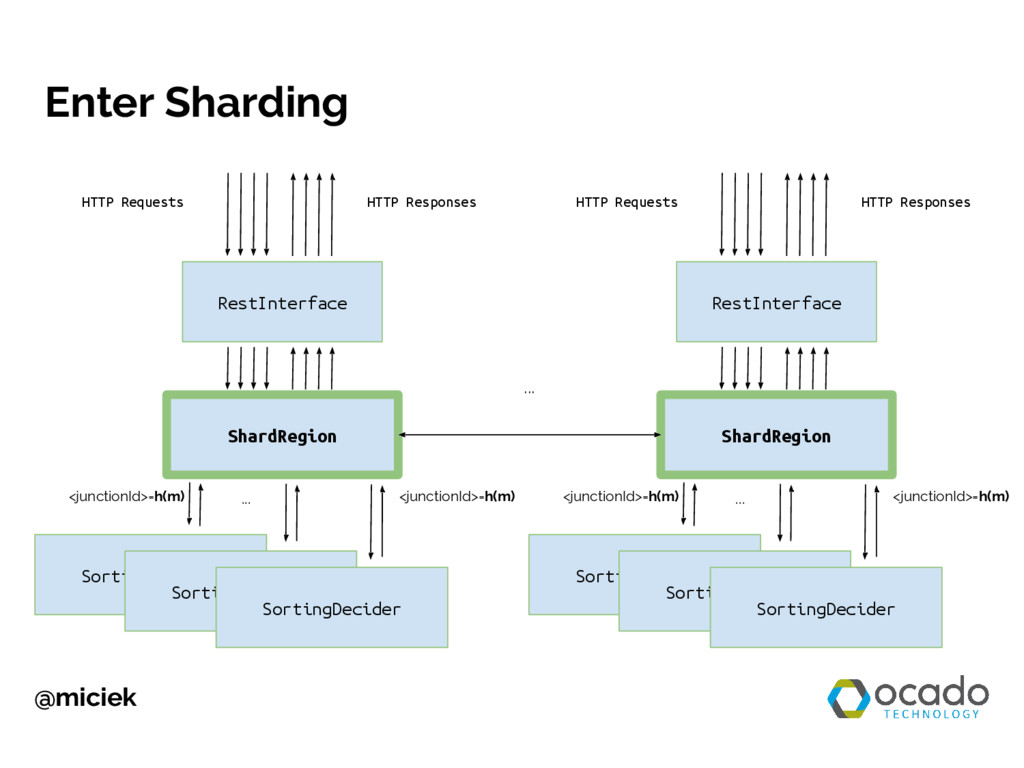
You will learn how to transform a single-noded app into a scalable one. During live coding session I will create both versions from scratch and guide you through the most important architectural decisions. If you are interested in scalability and know basics of message-based concurrency, this talk is for you. First, you will see how to create a web service as a single-noded Akka app. Then we will talk about scalability and availability problems with this approach and introduce sharding as potential solution. We will use this knowledge and Akka Cluster module to make our app more scalable.
{kind=link}
{kind=link}
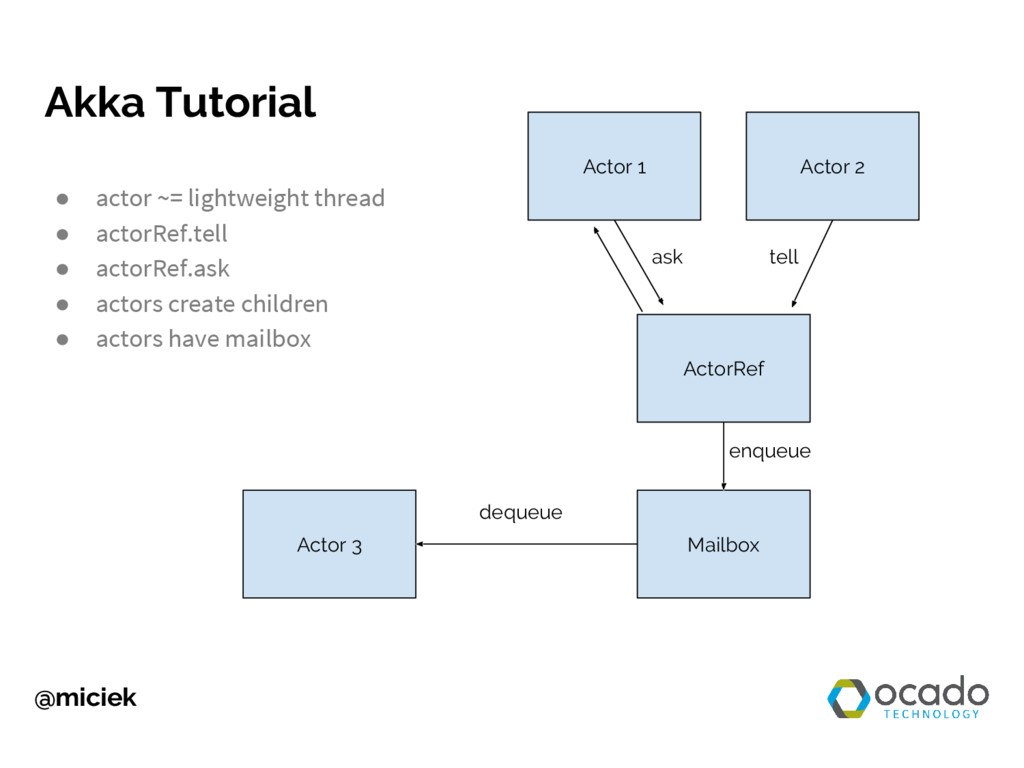{kind=link}
{kind=link}
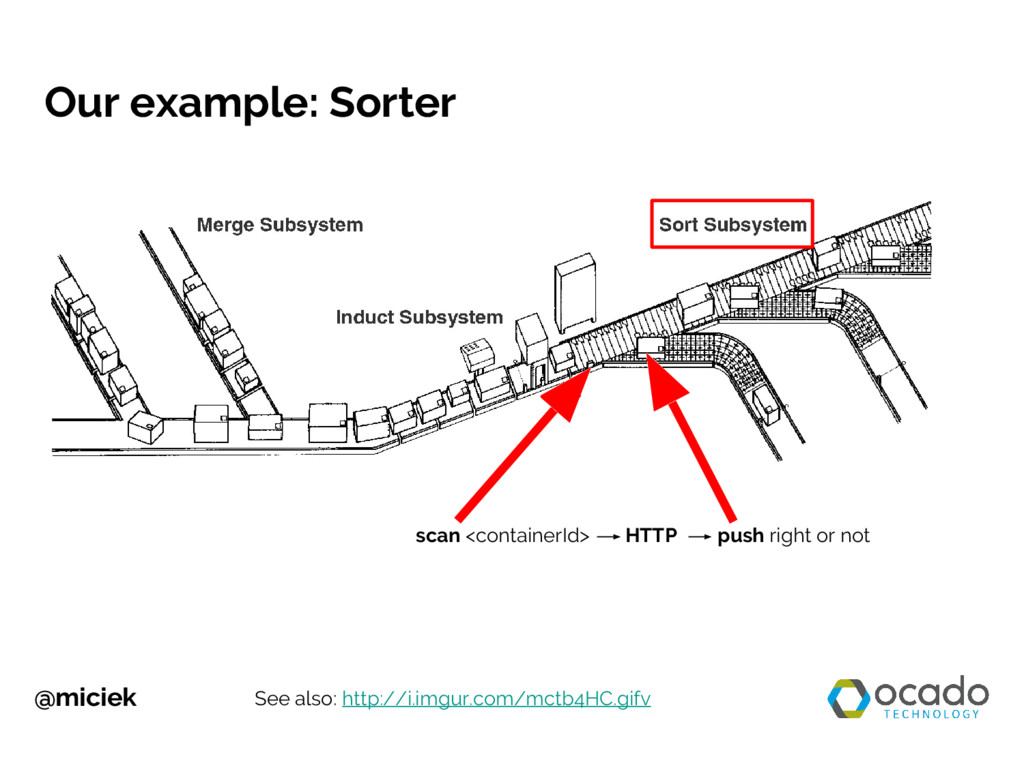{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
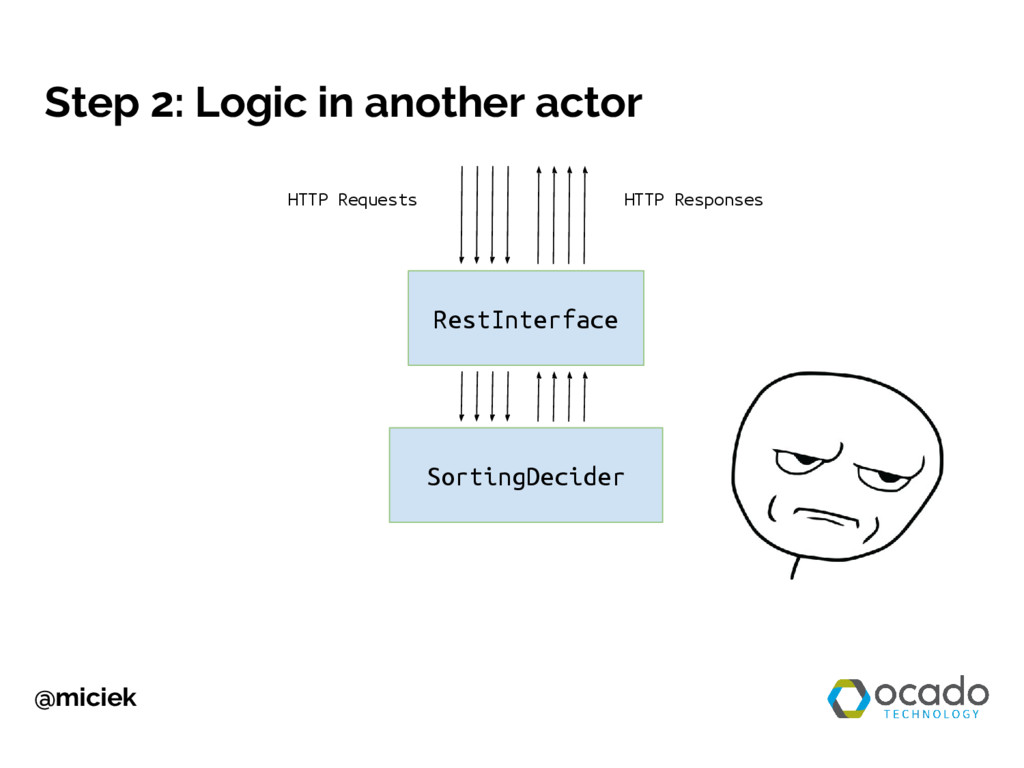{kind=link}
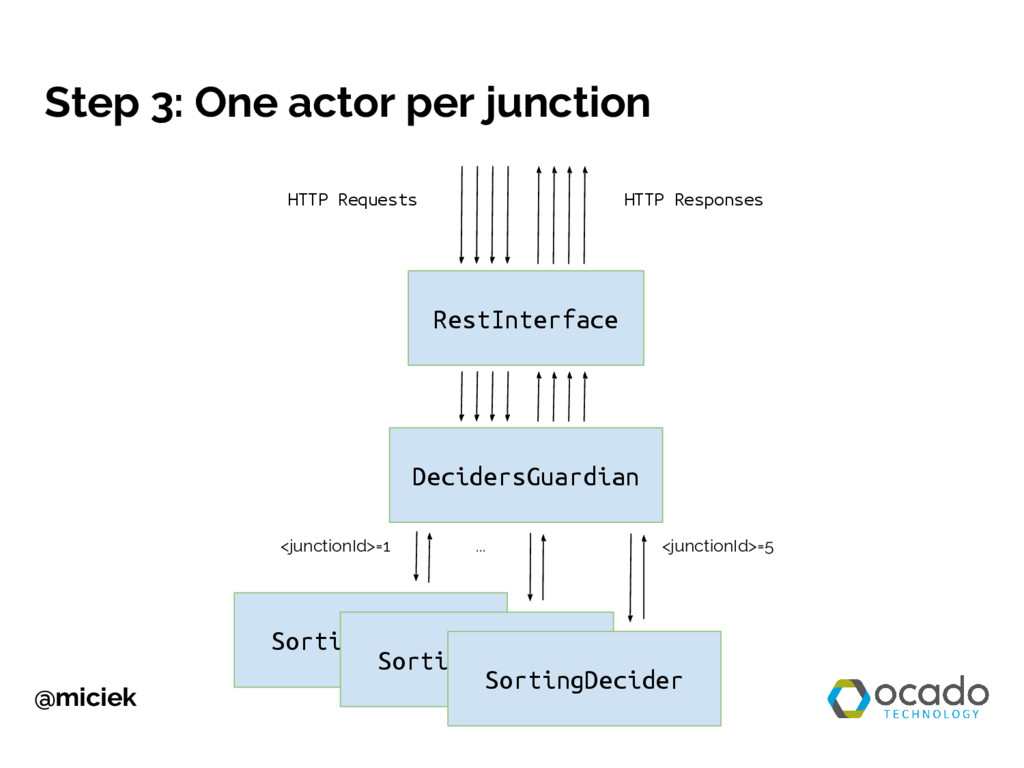{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}