Share
テックブログ https://moneyforward-dev.jp/entry/2026/01/30/143450
SRE Kaigi 2026 https://2026.srekaigi.net/session/roomb-1420
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
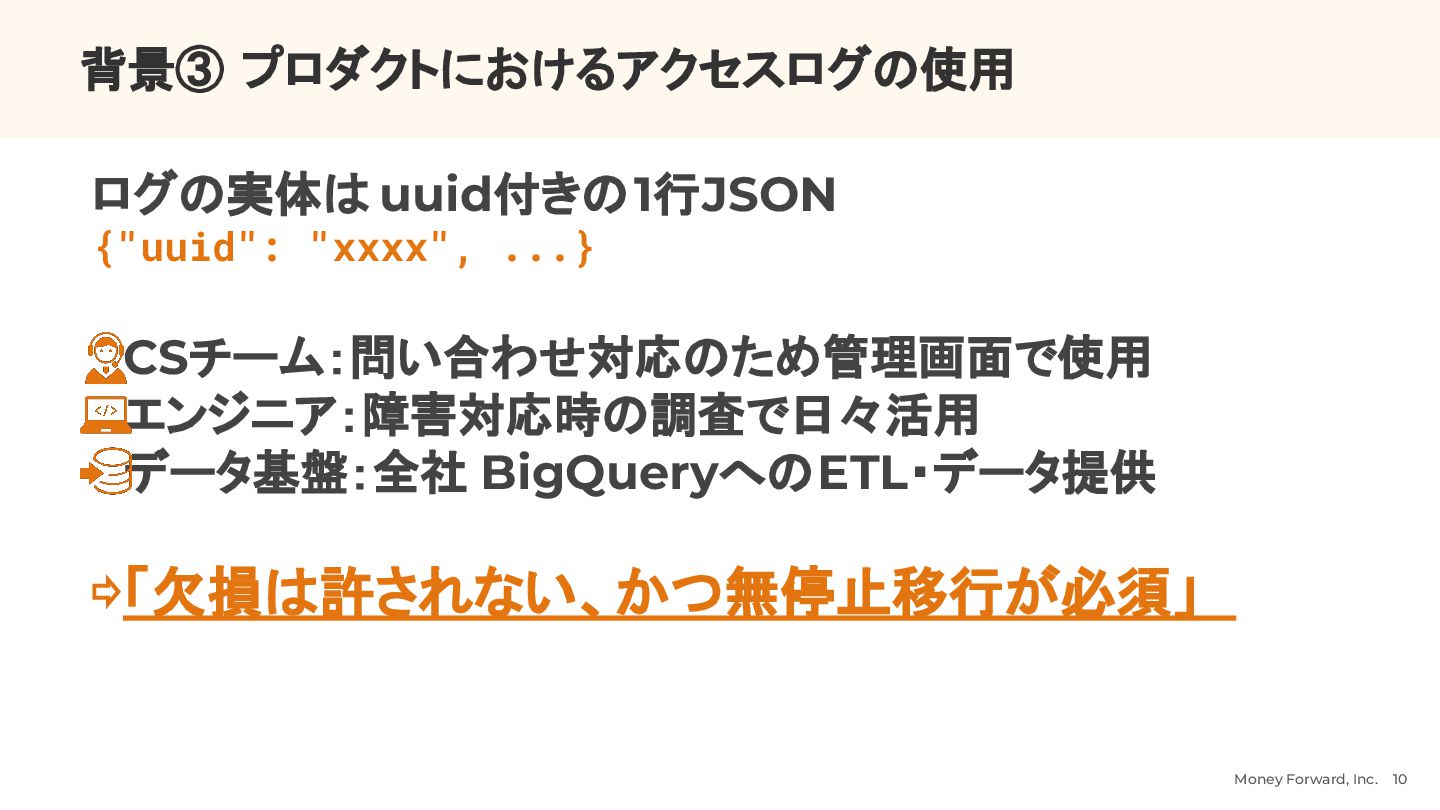{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
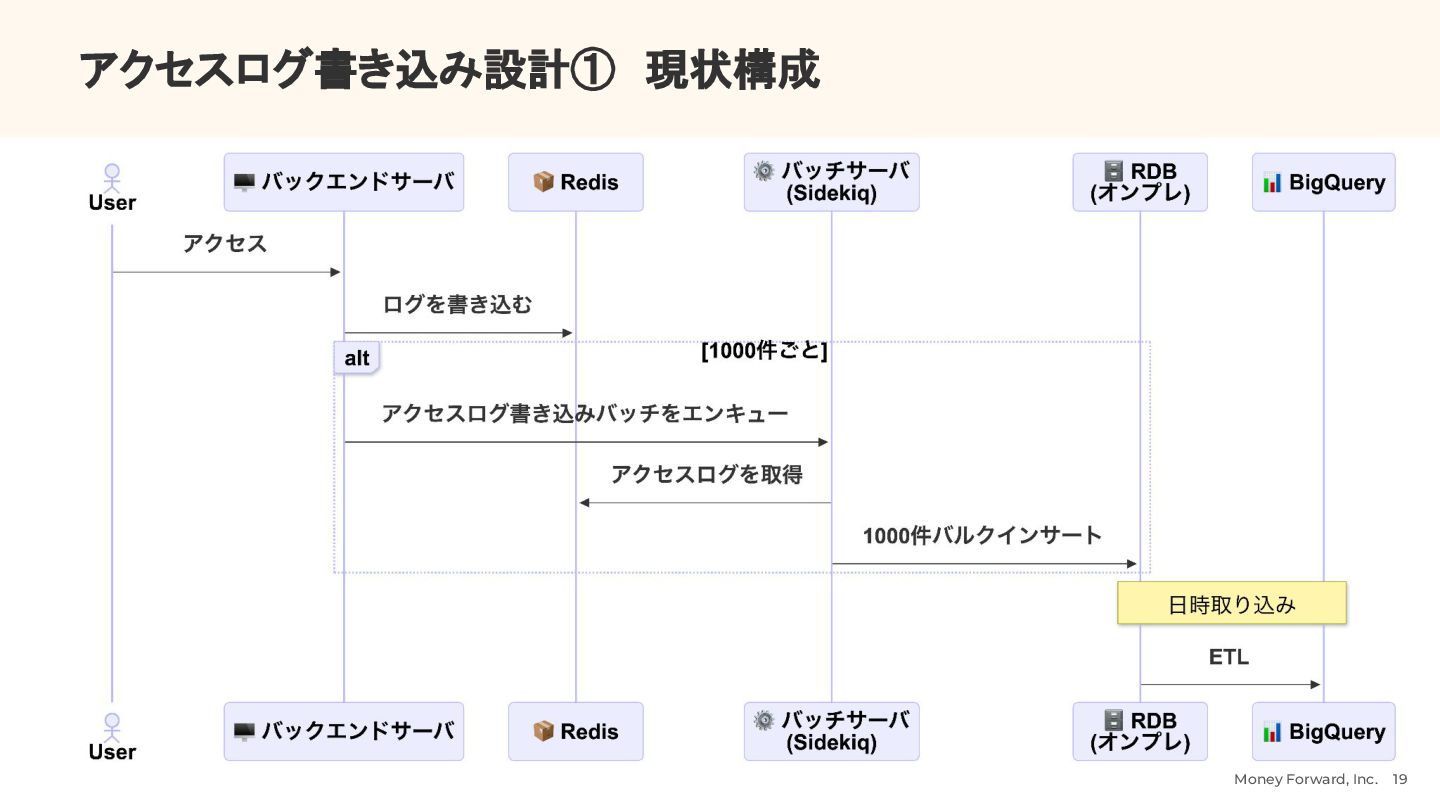{kind=link}
{kind=link}
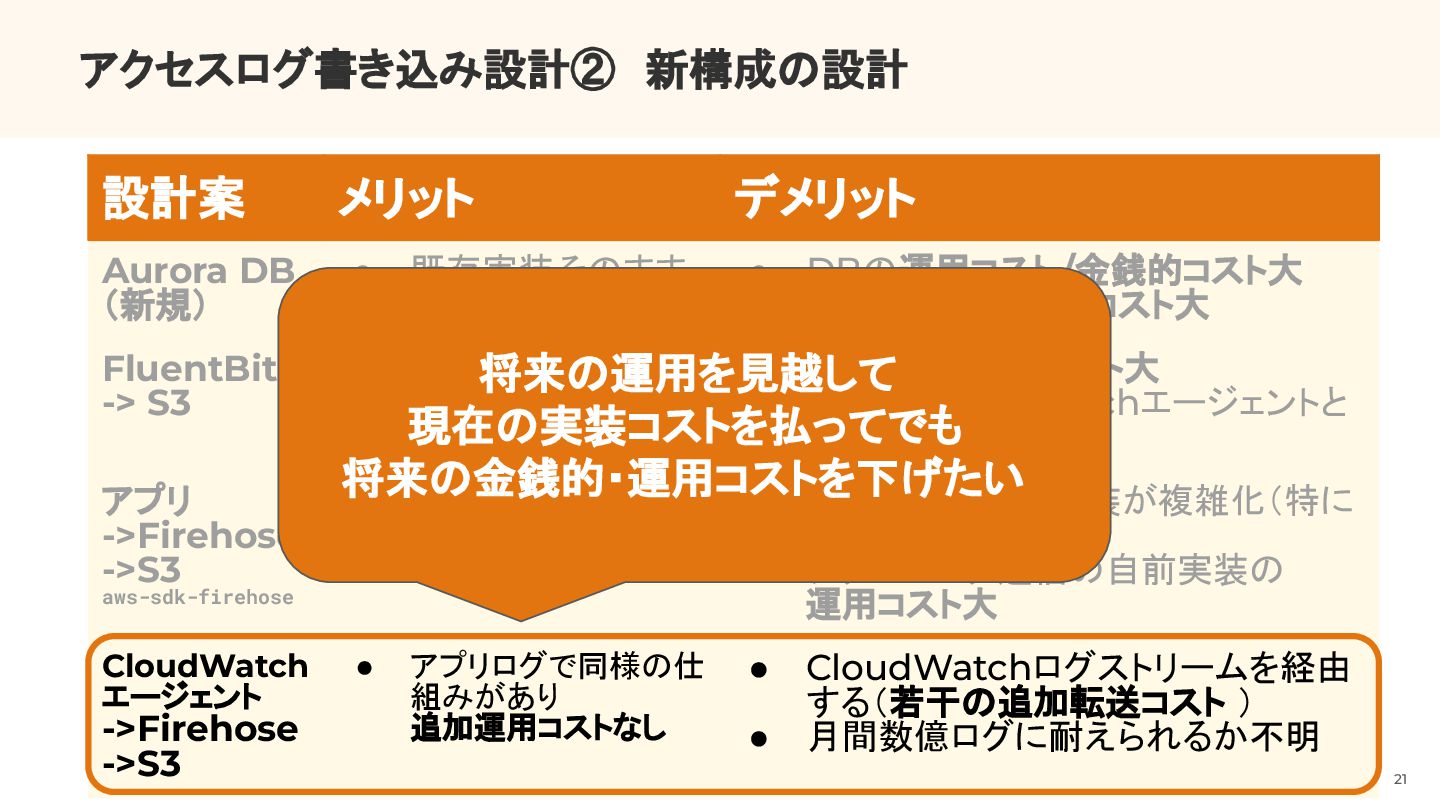{kind=link}
![Money Forward, Inc. 22 アクセスログ書き込み設計③ データ形式と圧縮 [1] https://parquet.apache.org/ [2] https://www.databricks.com/jp/glossary/what-is-parquet](https://files.speakerdeck.com/presentations/aa16e32dbaab4e35a65410ea2a10063f/slide_21.jpg){kind=link}
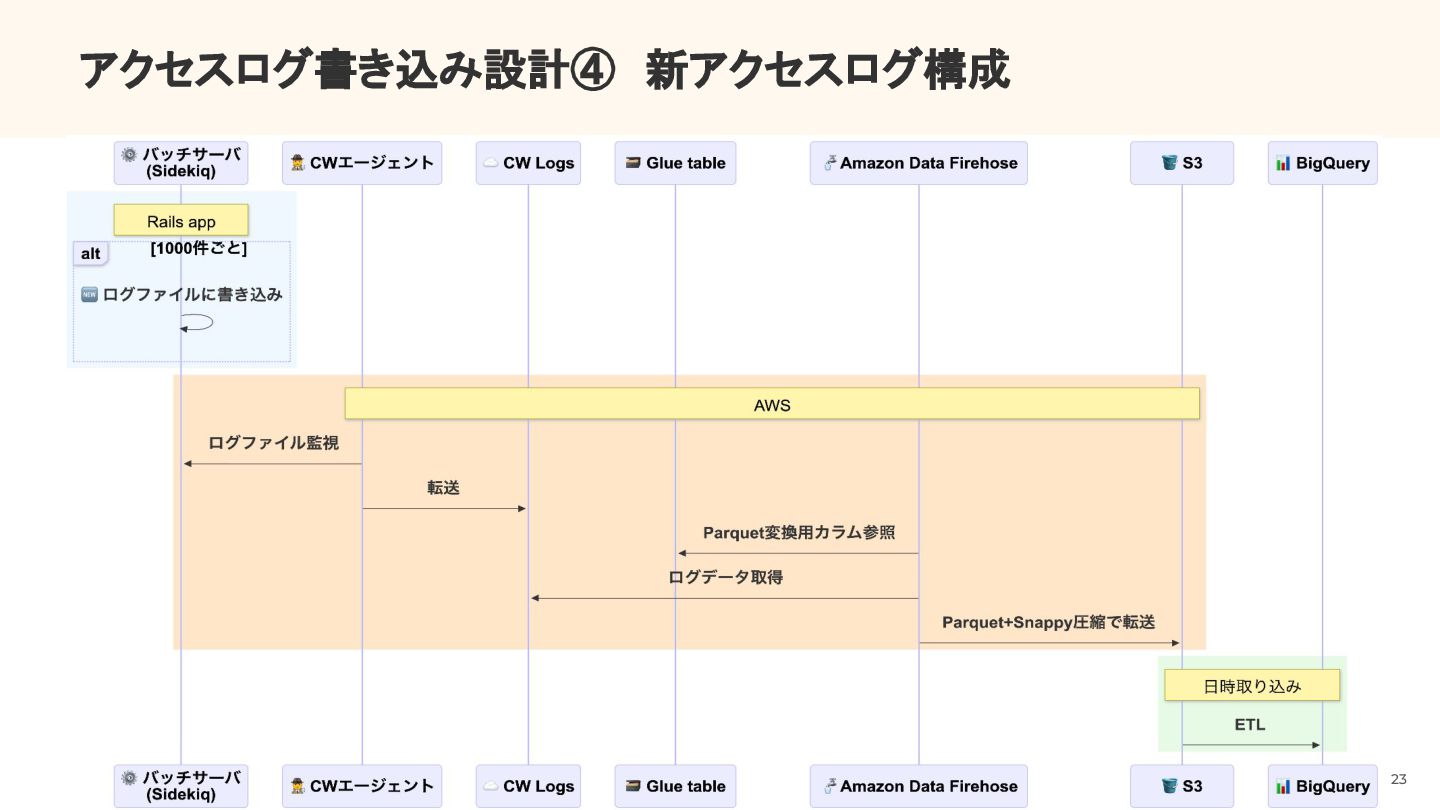{kind=link}
{kind=link}
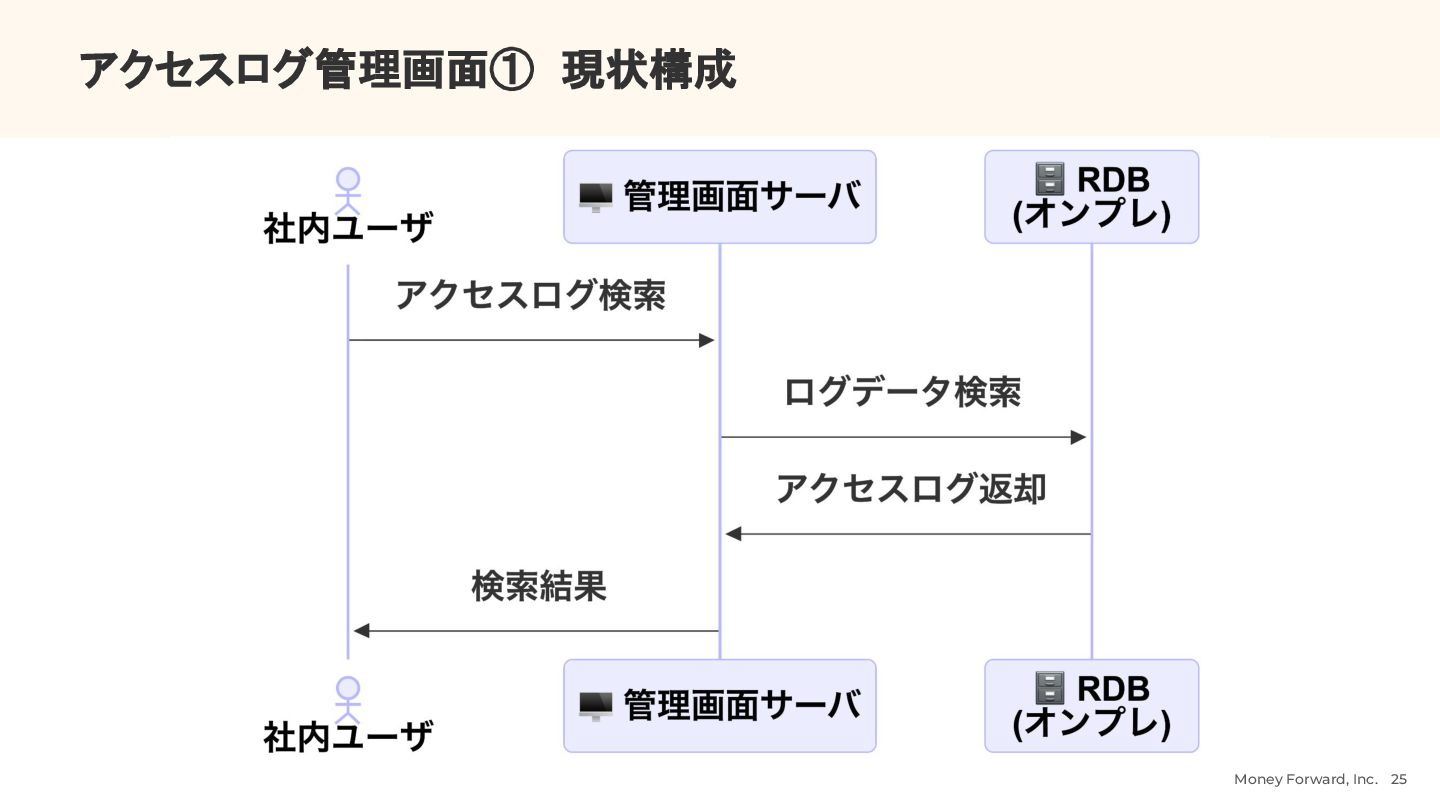{kind=link}
{kind=link}
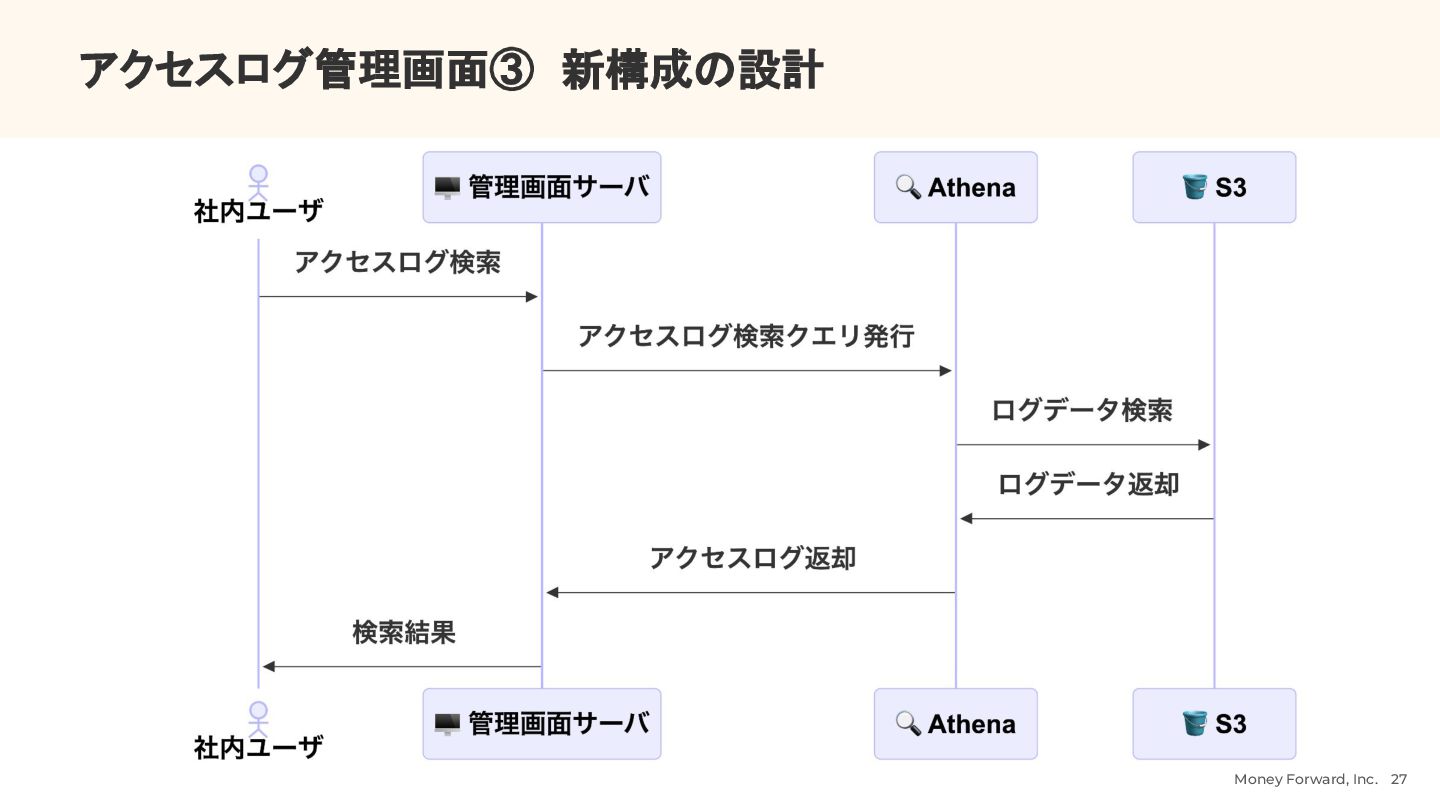{kind=link}
{kind=link}
{kind=link}
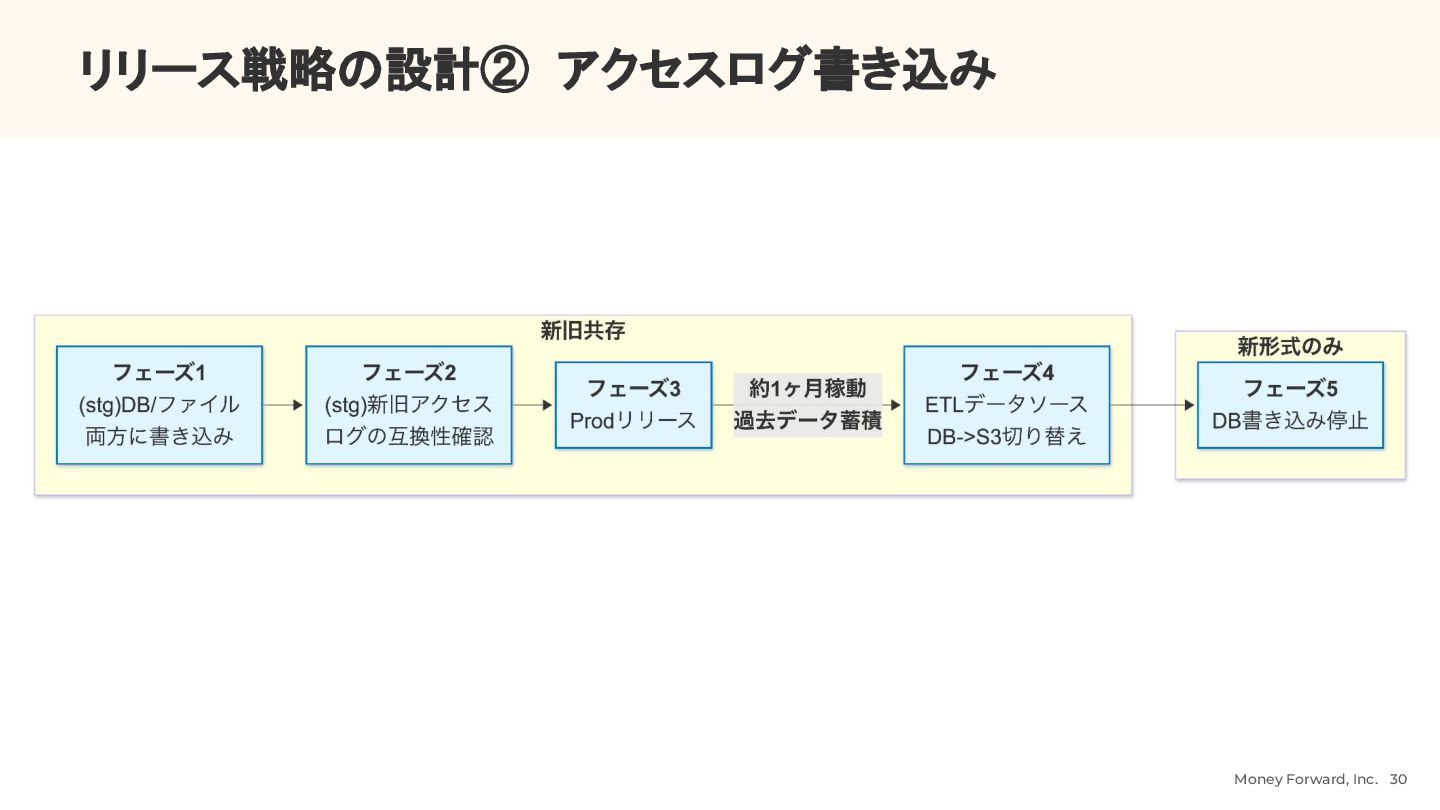{kind=link}
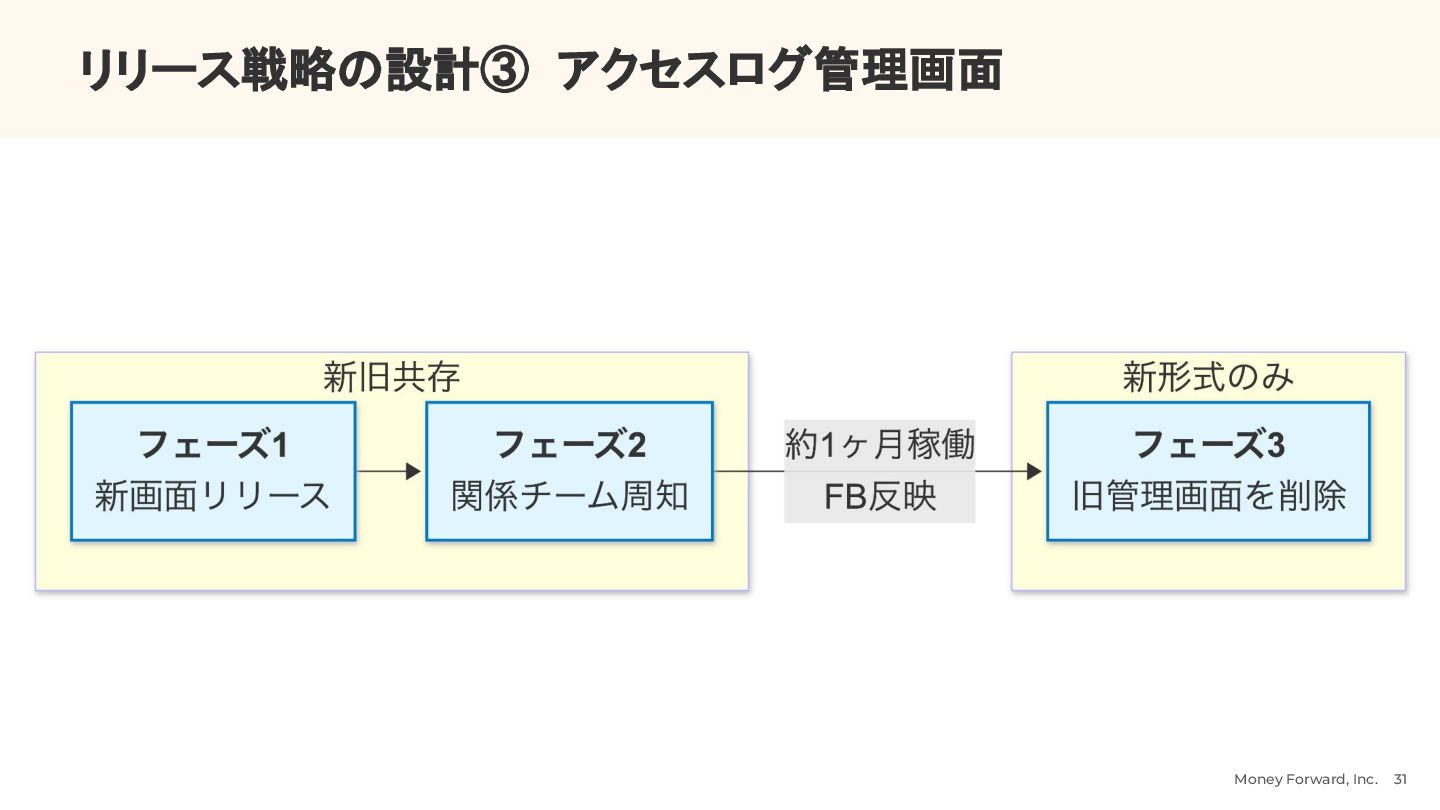{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Money Forward, Inc. 37 [1]IRSAの適切な定義 Athenaが内部的に使用する 権限も付与必須 ⇨ 最小の権限は...? Athena/アクセスログS3/](https://files.speakerdeck.com/presentations/aa16e32dbaab4e35a65410ea2a10063f/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Money Forward, Inc. 43 [1] Amazon Data Firehose はデータの重複があり得る 設計時に考慮漏れしていた](https://files.speakerdeck.com/presentations/aa16e32dbaab4e35a65410ea2a10063f/slide_42.jpg){kind=link}
{kind=link}
![Money Forward, Inc. 45 データ欠損・重複との戦い④ Sidekiqコンテナの安全な終了 ➢ [1] SidekiqはGraceful Shutdownをサポートしている](https://files.speakerdeck.com/presentations/aa16e32dbaab4e35a65410ea2a10063f/slide_44.jpg){kind=link}
![Money Forward, Inc. 46 データ欠損・重複との戦い⑤ Sidekiqコンテナ修正 [1] https://github.com/sidekiq/sidekiq/wiki/Reliability ➢ 原因①](https://files.speakerdeck.com/presentations/aa16e32dbaab4e35a65410ea2a10063f/slide_45.jpg){kind=link}
{kind=link}
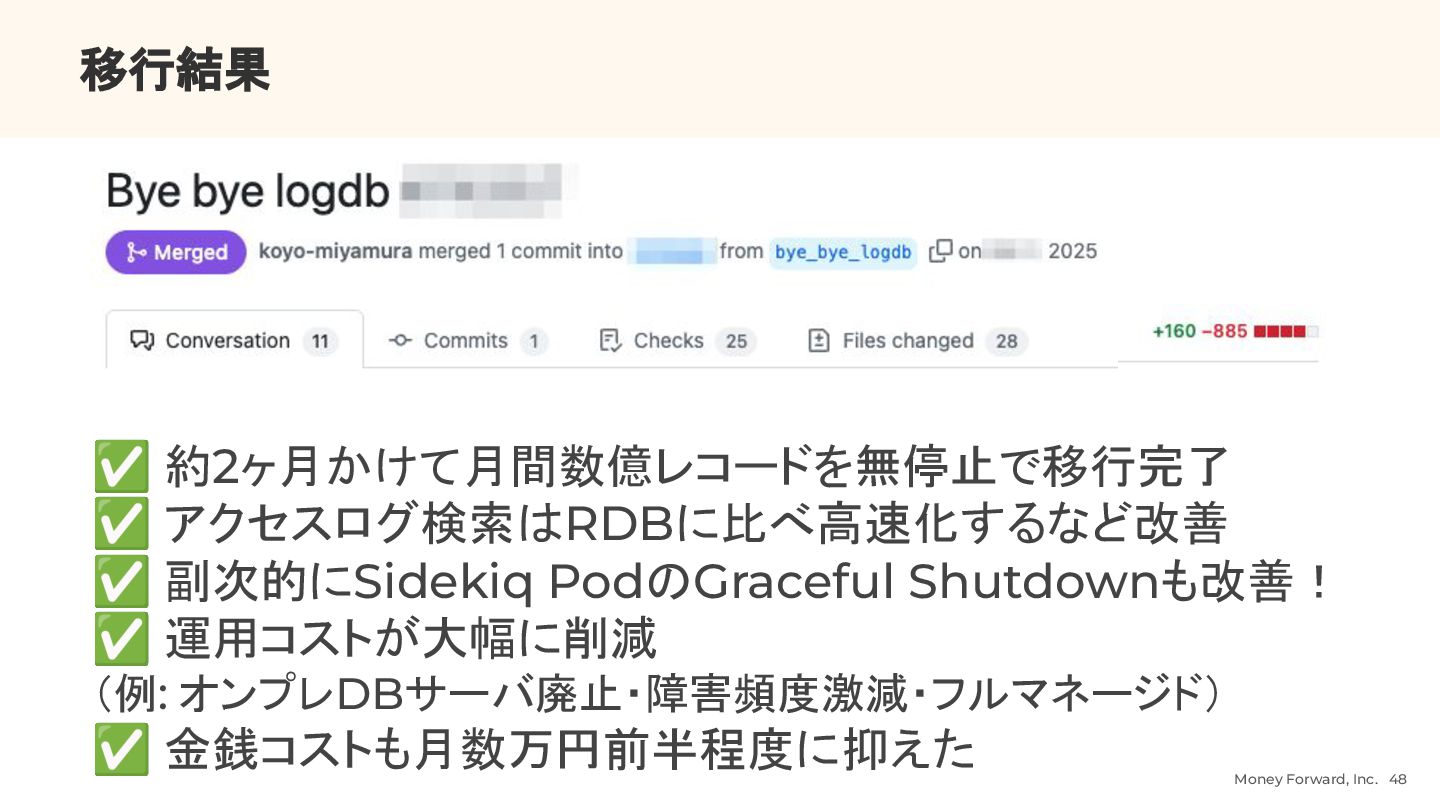{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}