Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
強化学習を可視化するchainerrl visualizerを動かしてみた
Search
mogamin
January 28, 2019
Technology
630
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
強化学習を可視化するchainerrl visualizerを動かしてみた
強化学習を可視化するchainerrl visualizerを動かしてみた
mogamin
January 28, 2019
More Decks by mogamin
See All by mogamin
エンプラRAG構築の最適解!Oracle AI Vector Searchによる明日からできるRAG!
mogamin
1
260
RDB脳はあなたに送る KVSモデリングのノウハウを公開! AWS DynamoDB、AzureCosmosDBでのKVS設計はこうしよう!
mogamin
1
670
Deep dive into application-level network management & observability with AppMesh
mogamin
0
860
Introducing Amazon SageMaker AutoPilot
mogamin
1
650
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
mogamin
0
180
Pytorch強化学習プラットフォーム? Horizonのドキュメントを読む
mogamin
0
2.2k
Other Decks in Technology
See All in Technology
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
210
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
240
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
290
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
2
1k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
1k
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
110
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
100
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
280
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
500
AIと1000本ノックしてたどり着いた、最速のプロダクト開発 ~toC向けAIエージェントUXを、動く選択肢とAIキャパシティで設計する~
lycorptech_jp
PRO
1
110
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
910
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
1.2k
Featured
See All Featured
A designer walks into a library…
pauljervisheath
211
24k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
660
Are puppies a ranking factor?
jonoalderson
1
3.7k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Faster Mobile Websites
deanohume
310
32k
HDC tutorial
michielstock
2
750
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
550
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
How to Talk to Developers About Accessibility
jct
2
420
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
330
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Transcript
強化学習を可視化する chainerrl-visualizerを動かしてみた 28.Jan.2019 Machine Learning Casual Talks #8 LT Takashi,MOGAMI
@mogamin
WHO AM I? Takashi,MOGAMI / @mogamin ウルシステムズ株式会社 シニアコンサルタント 画像処理(OpenCV)、ディープラーニング系をメインに業務をしておりま す。最近では強化学習を使った研究開発プロジェクトを推進しています
が、時間を見つけてはkaggleやSIGNATEで技術を磨いております。 - Scrum Master - AWS Certified Solutions Architect Professional
None
AGENDA - 「ありの行列」の話 - 強化学習とは - 強化学習のつらい所 - chainerrl-visualizer -
try! demo. ※本内容は個人の見解です。所属組織とは一切関係ありません。
強化学習とは - エージェント(学習の主体)が環境から得られる状態に対し て、報酬を最大化するように行動を学習する。 - 何がうれしいかというと、正答データがない問題でも報 酬を正しく定義できれば問題を解くことができる。 ※https://www.slideshare.net/ssuserf2c42e/20190125-minecraft-129160073 Agent Environment
action observation, reward
強化学習のつらい所 - 報酬設計がむずい - いつ報酬を与えるべきか、いつ罰を与えるべきか - マルチワーカーが苦手 - 画像認識のようにGPUをフルに使えない。CPUパワーに依存する -
シュミレータの開発コストが高い - 実際の環境、状態を網羅するシュミレータが必要 - マルコフ決定過程をちゃんと成立させて作る - 状態が変わらなければ意味がないaction? - 方策設計はどうあるべきか - いつまでも奇跡、神の手を待っていると永遠に終わらない。 - アルゴリズム部、Deep Q-Network部、超絶 試行錯誤 - やってみないとわからない。評価軸は?まずは可視化が必要!
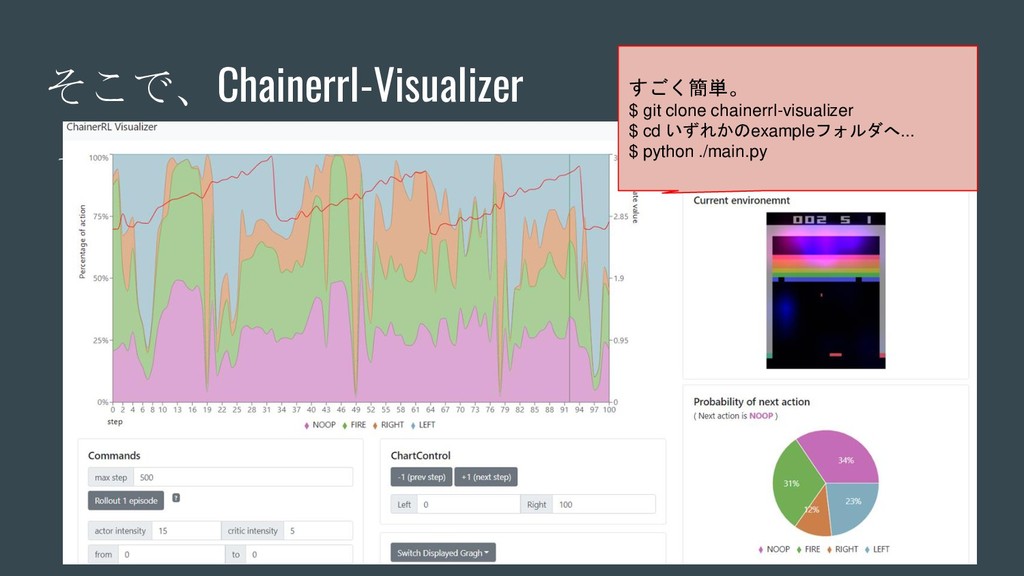
そこで、Chainerrl-Visualizer - XXX すごく簡単。 $ git clone chainerrl-visualizer $ cd
いずれかのexampleフォルダへ... $ python ./main.py
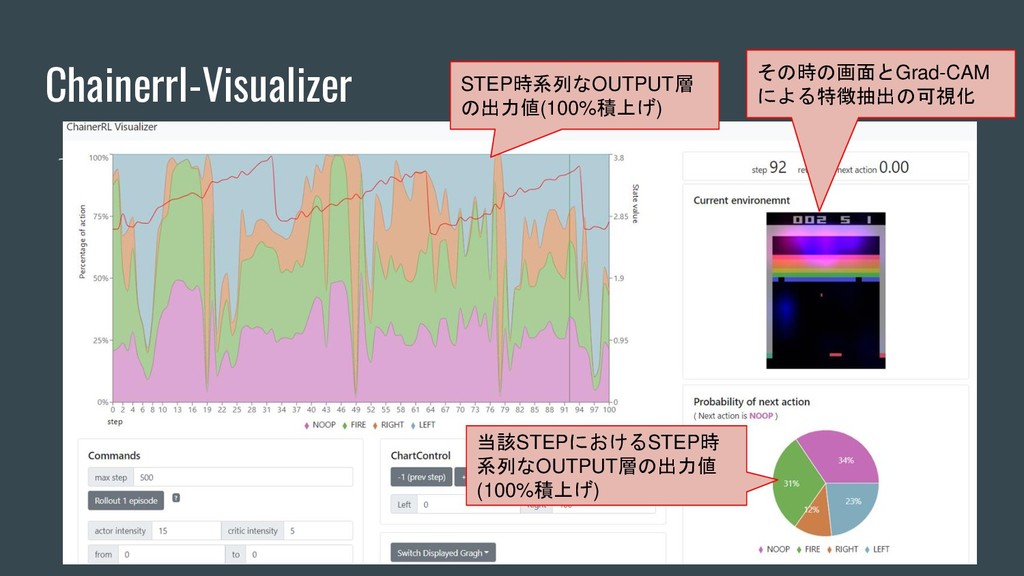
Chainerrl-Visualizer - XXX 当該STEPにおけるSTEP時 系列なOUTPUT層の出力値 (100%積上げ) STEP時系列なOUTPUT層 の出力値(100%積上げ) その時の画面とGrad-CAM による特徴抽出の可視化
try! demo.
ありがとうございました。 We are now hiring! @mogaminまで
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}