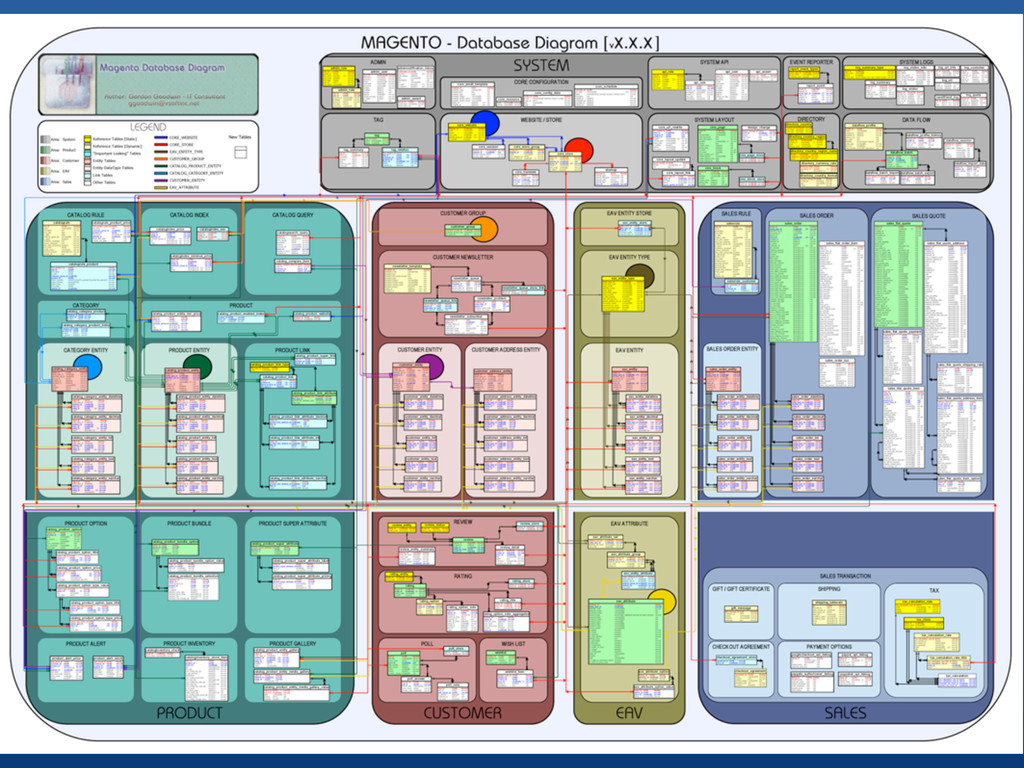
One of the challenges that comes with moving to MongoDB is figuring how to best model your data. While most developers have internalized the rules of thumb for designing schemas for RDBMSs, these rules don't always apply to MongoDB. The simple fact that documents can represent rich, schema-free data structures means that we have a lot of viable alternatives to the standard, normalized, relational model. Not only that, MongoDB has several unique features, such as atomic updates and indexed array keys, that greatly influence the kinds of schemas that make sense. Understandably, this begets good questions:
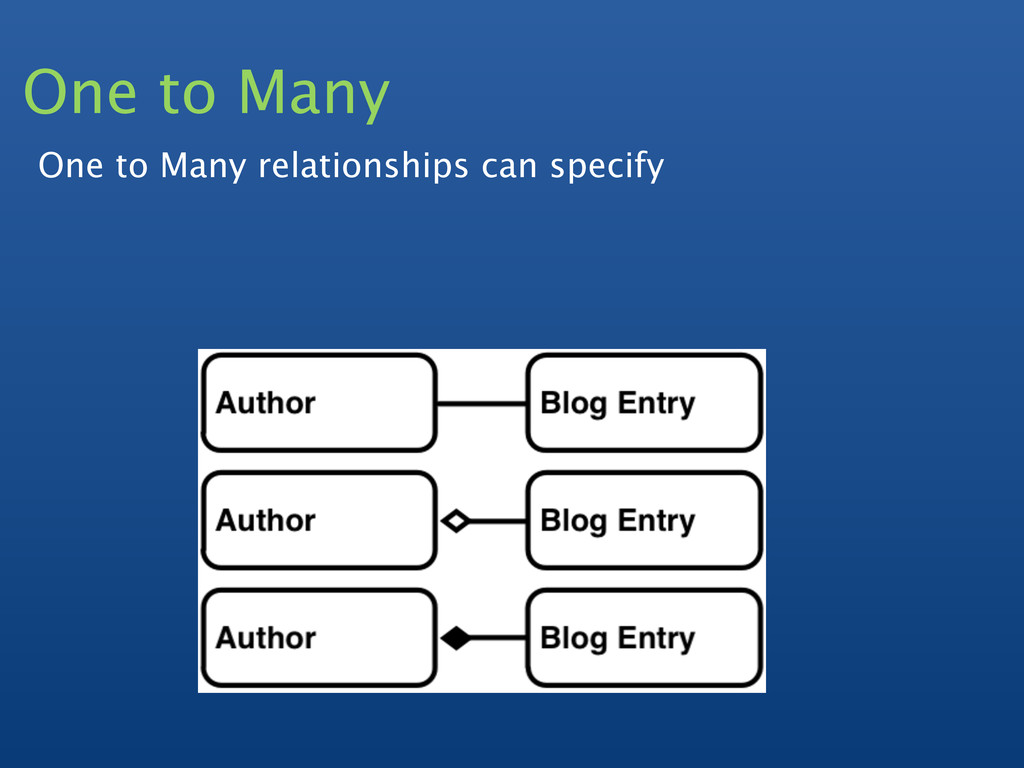
Are foreign keys permissible, or is it better to represent one-to-many relations withing a single document?
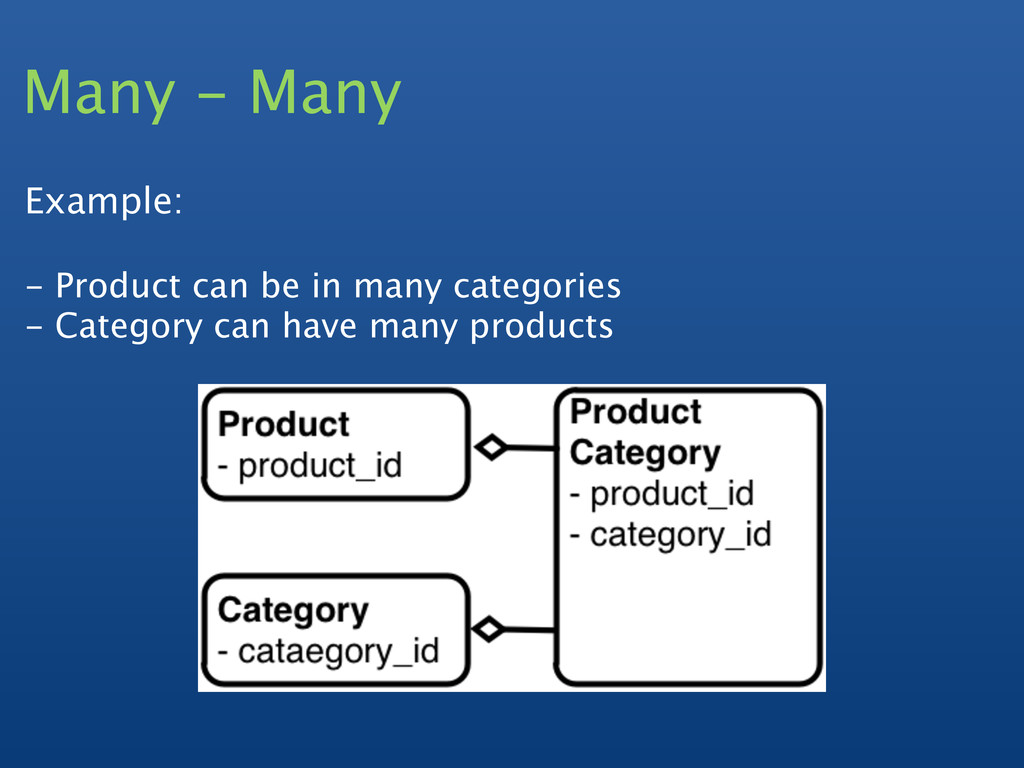
Are join tables necessary, or is there another technique for building out many-to-many relationships?
What level of denormalization is appropriate?
How do my data modeling decisions affect the efficiency of updates and queries?
In this session, we'll answer these questions and more, provide a number of data modeling rules of thumb, and discuss the tradeoffs of various data modeling strategies.
{kind=link}
![[email protected] @forjared](https://files.speakerdeck.com/presentations/4f46a336ea4c40001f002642/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
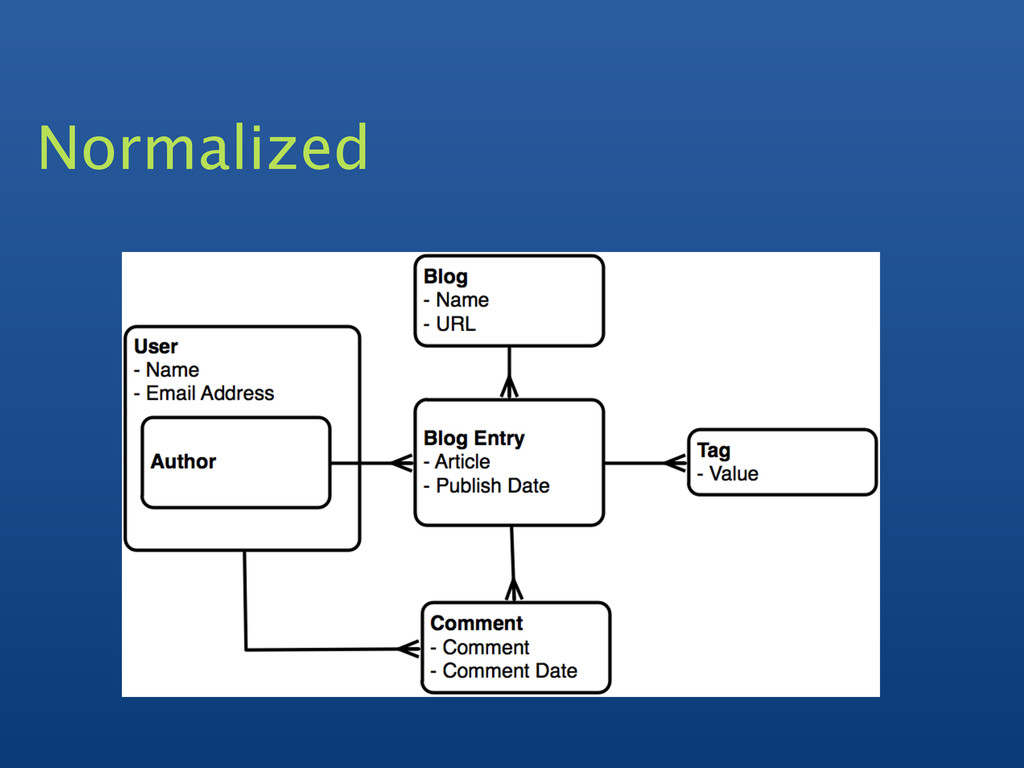{kind=link}
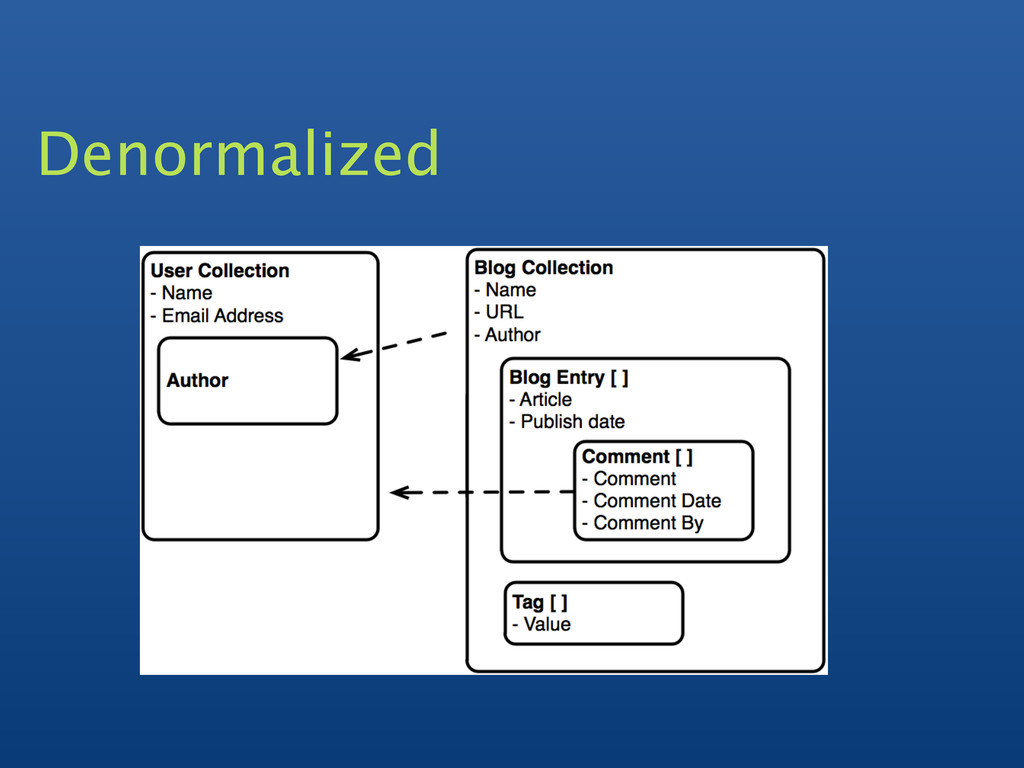{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
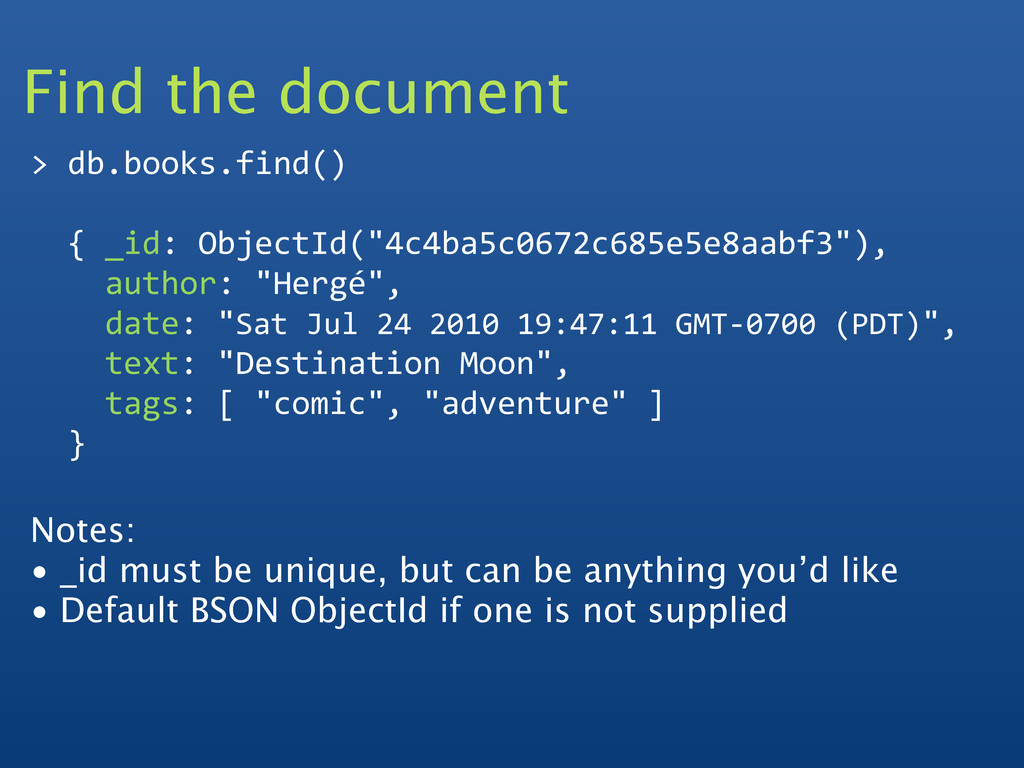{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
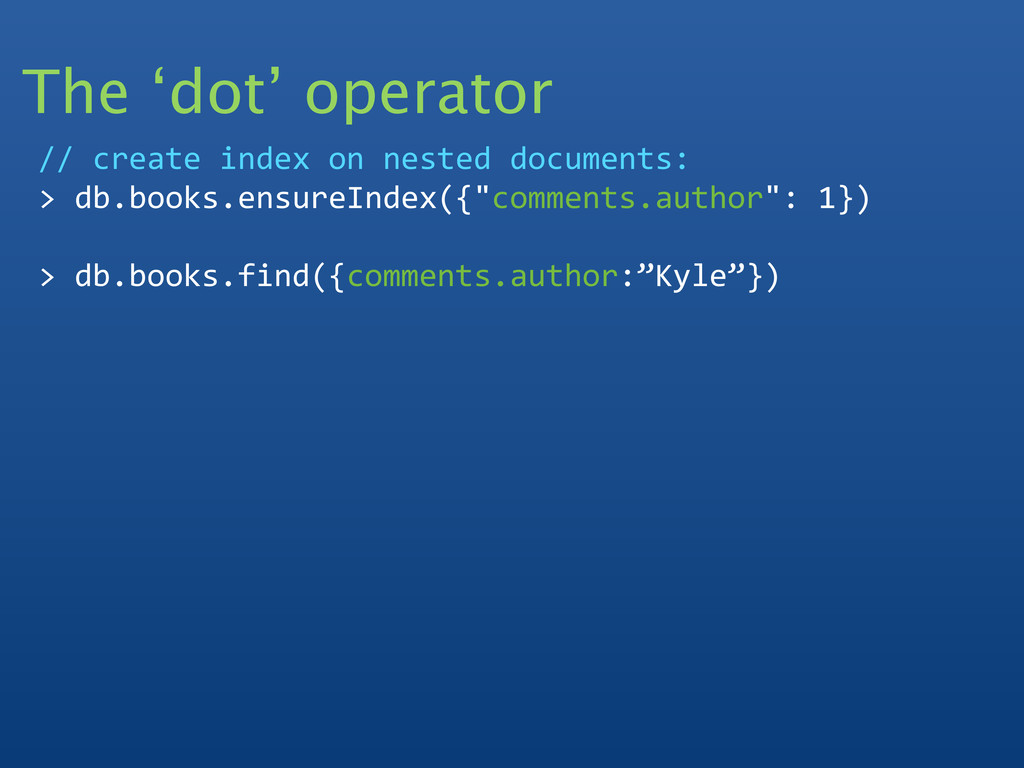{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}