Containers as well as orchestration systems like Kubernetes are quickly gaining popularity as the prefered tools for deploying and running microservices. While being easier to deploy and isolate, containerized applications are creating new challenges for the logging and monitoring systems.
One popular solution for logging and monitoring is the Elastic Stack composed of Elasticsearch, Logstash, Kibana, and Beats. This talk shows you how to use the Elastic Stack, and in particular the Beats lightweight shippers, to collect logs and metrics from your containers.
The session includes details about how to:
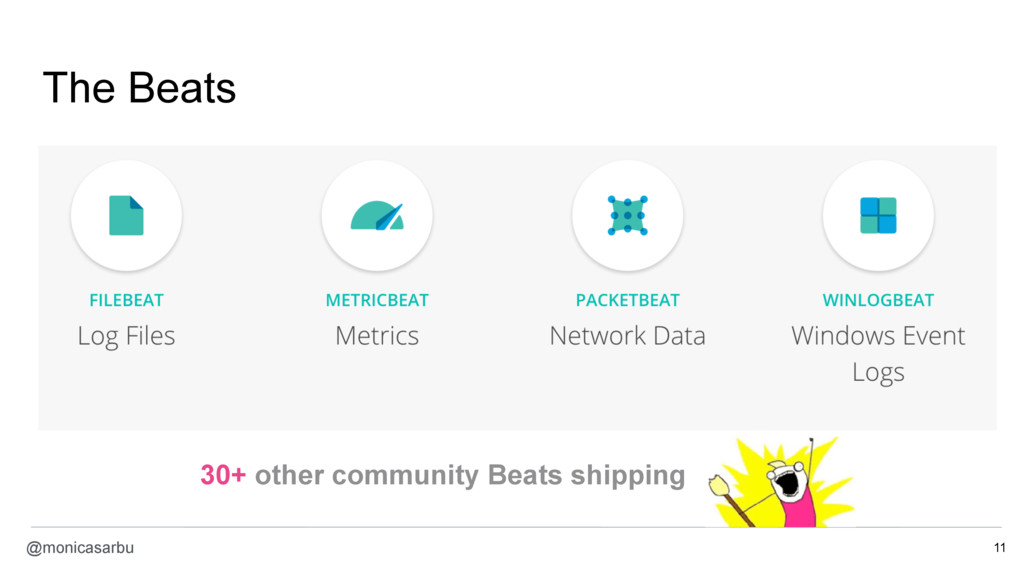
- fetch the logs of the containers with Filebeat
- collect container metrics with Metricbeat
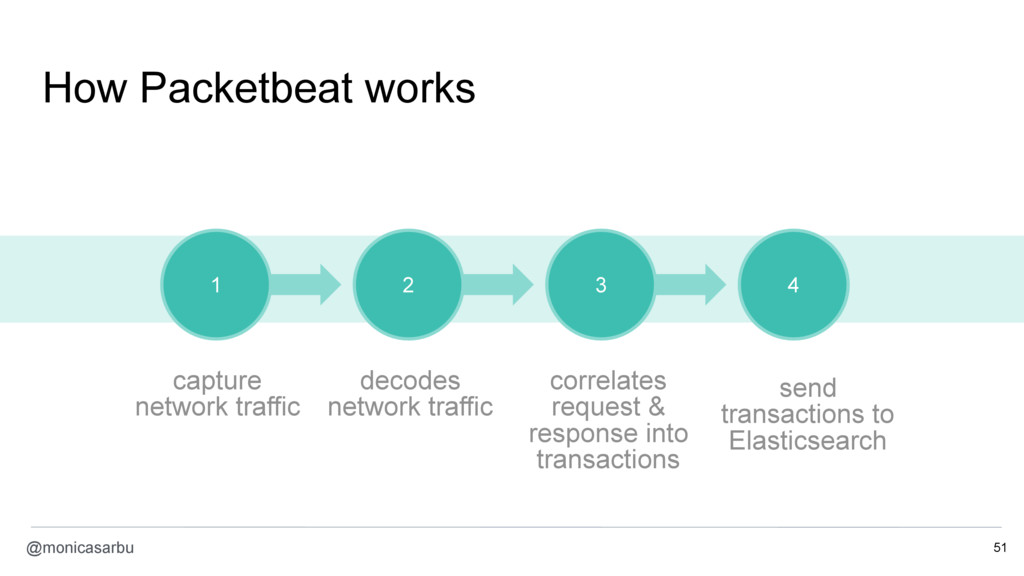
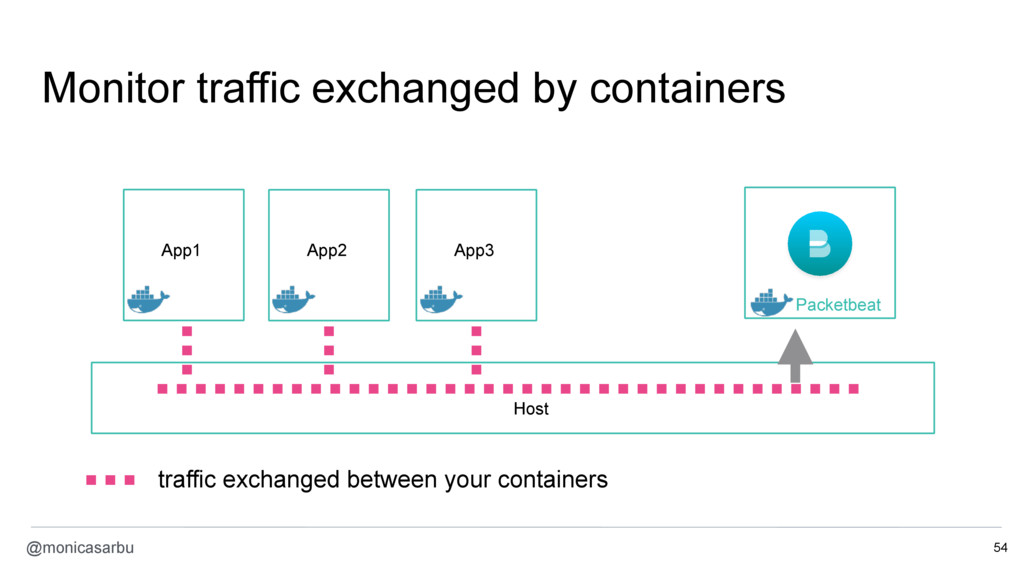
- monitor the network traffic exchanged between containers with Packetbeat
- automatically discover metadata from Docker containers
- visualize the collected data with predefined Kibana dashboards scaling Logstash deployments
{kind=link}
![2 Monica Sarbu Team lead, Beats team Email: [email protected] Twitter:](https://files.speakerdeck.com/presentations/8dd48247c0e14bd8bbd7fbc361769dcf/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
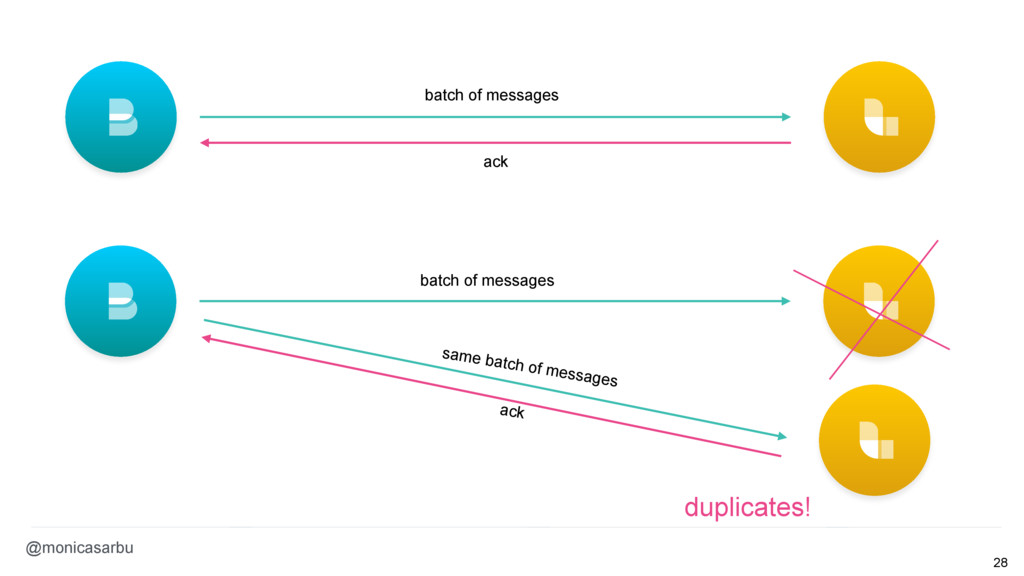{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
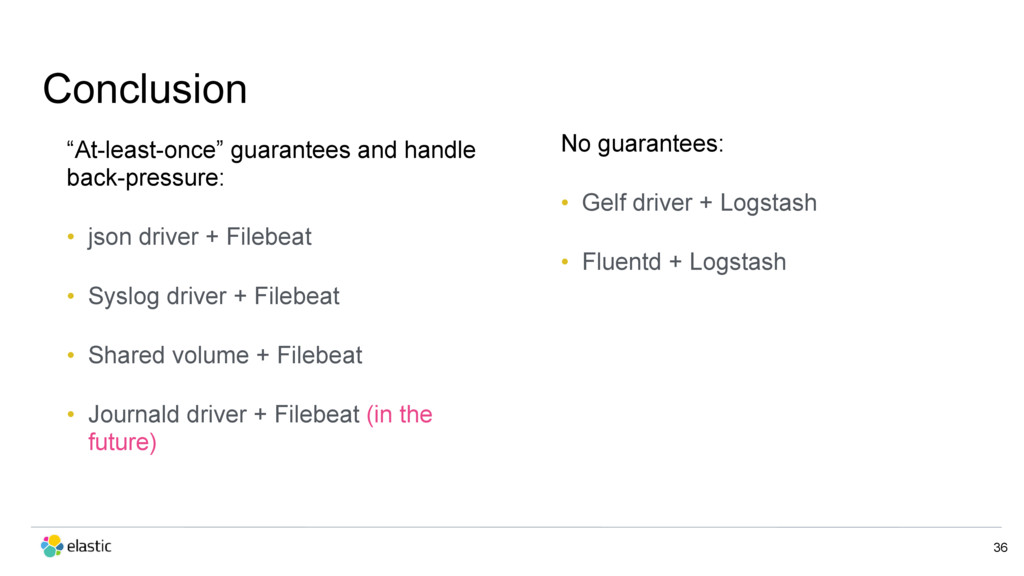{kind=link}
{kind=link}
{kind=link}
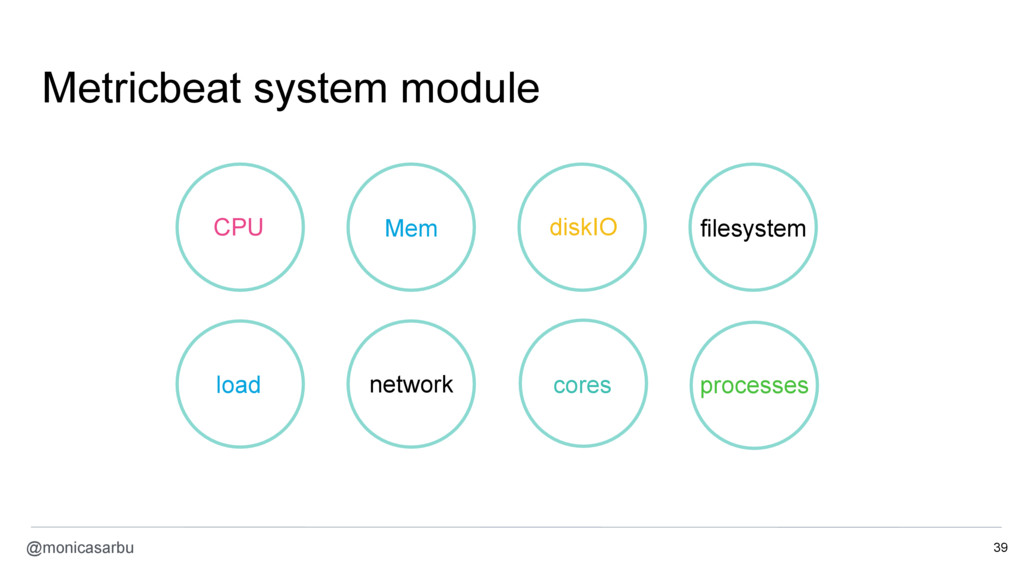{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
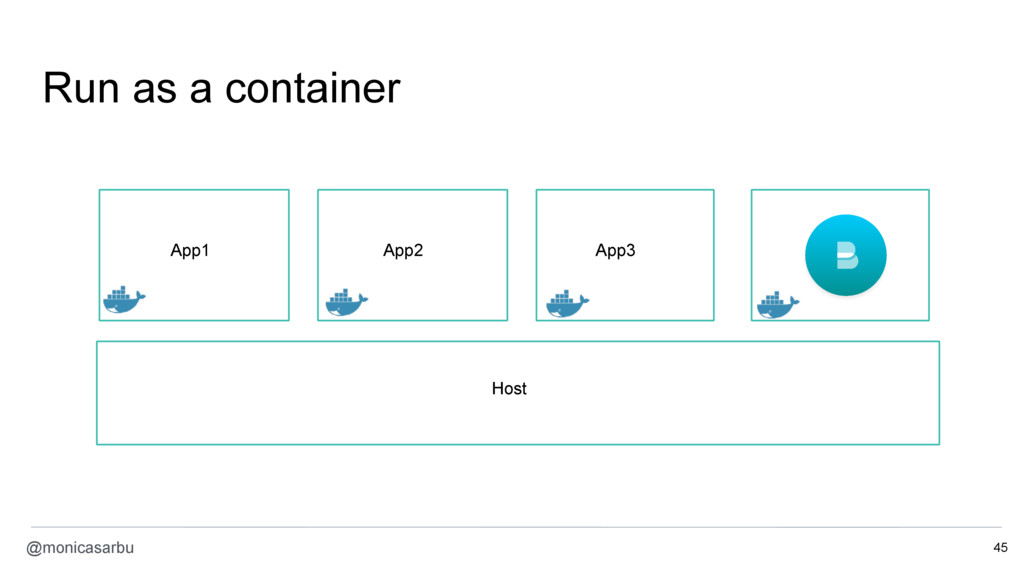{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}