• 既存手法の多くはテキストを想定 • 画像に対する類似判定の頑健性は期待できない • 意味的特徴を保持する埋め込みモデルなら画像も扱える [Cheng 23] • ただし,軽量な方式と比べ処理時間・運用コストが大きい 例)埋め込みモデルの推論に加え,ベクトルの近似近傍探索(ANN)エンジンの運用が必要 [Zhang 23] Zhang et al.: A Late Multi-modal Fusion Model for Detecting Hybrid Spam E-mail (2023) [Cheng 23] Cheng et al.: Efficient Data Representation Learning in Google-scale Systems (2023)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![類似性と出現頻度に着目するアプローチ 8 • 軽量な LSH・SimHash の類似判定はスパム判定モデルを仮定 [Ali 15][Ho 14] •](https://files.speakerdeck.com/presentations/065581c9c7874c7f9e8eeafc0a2b373a/slide_7.jpg){kind=link}
![マルチモーダル対応と運用コストの課題 9 • スパムメッセージは画像内にも混入する [Zhang 23] • テキストと同様に,画像でも類似メッセージをカウントできるのが望ましい 例)画像内に埋め込んだテキストや,QR コードによる誘導など](https://files.speakerdeck.com/presentations/065581c9c7874c7f9e8eeafc0a2b373a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
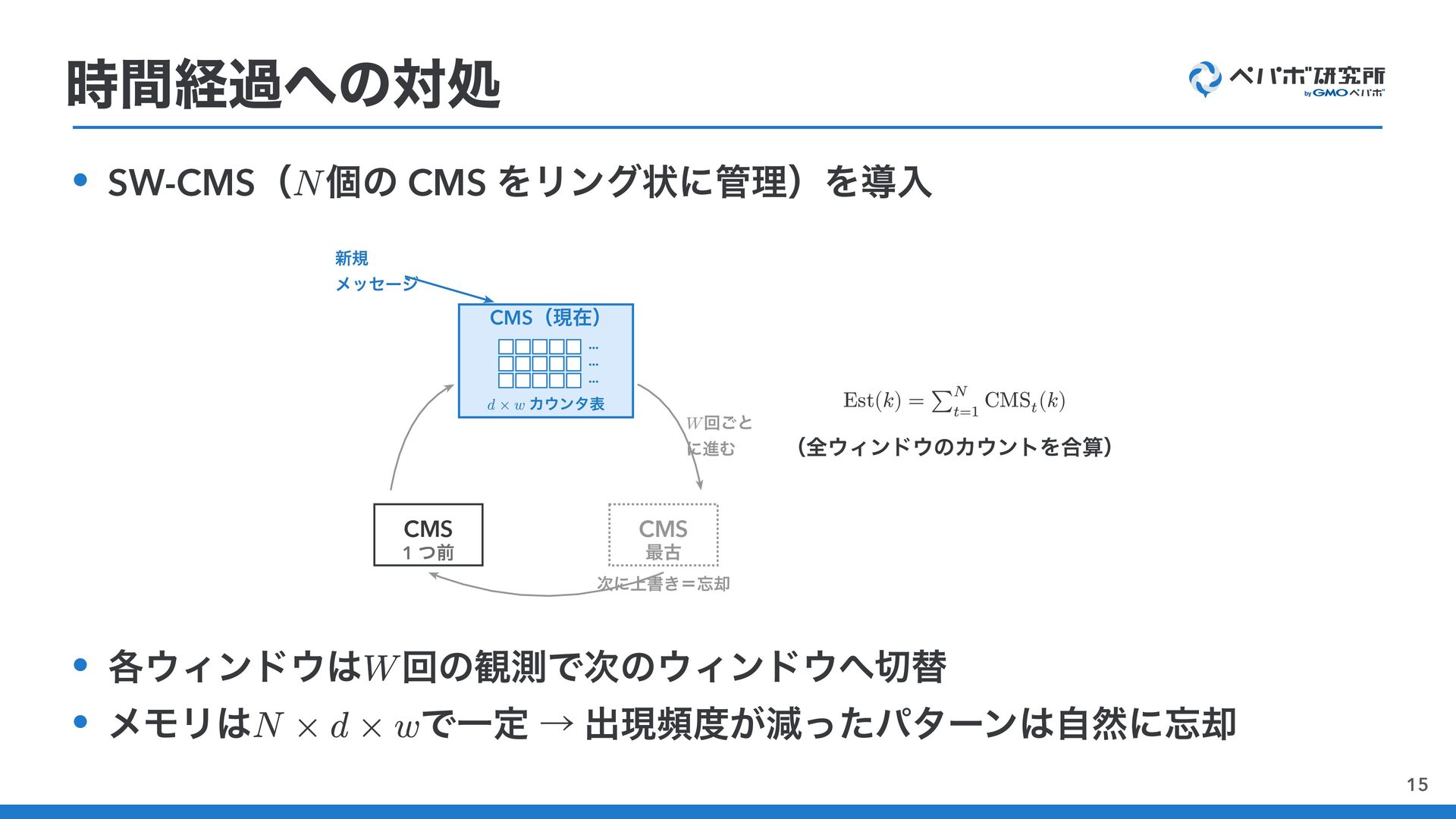{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}