Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIで最適化を解けるか?
Search
MIKIO KUBO
March 31, 2026
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIで最適化を解けるか?
LLMや深層強化学習で組合せ最適化を解くためのアプローチと比較
MIKIO KUBO
March 31, 2026
More Decks by MIKIO KUBO
See All by MIKIO KUBO
人工知能の歴史: チューリングからエージェントスキルに至る道程}
mickey_kubo
0
82
AlgorithAlgorihms for Decision Making
mickey_kubo
0
110
エージェントスキル:自律型AIが変える最適化とサプライチェーンの未来
mickey_kubo
0
170
エージェントスキルによる最適化
mickey_kubo
2
200
Agent Skills 完全ガイド
mickey_kubo
0
170
Skill Creatorの技術設計と動作原理
mickey_kubo
0
140
AI+SCM
mickey_kubo
0
92
エージェンティック・サプライチェーン」の概念と、製造業におけるその革新的な役割について解説
mickey_kubo
0
100
MOAI Solutionの紹介 -電力最適化を中心として-
mickey_kubo
0
120
Other Decks in Research
See All in Research
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
250
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
260
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
130
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
520
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
760
EIRによる不正端末のブロッキング 5G時代におけるデバイス識別と不正対策の進化
stellarcraft
0
100
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
310
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
330
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
140
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
Featured
See All Featured
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Writing Fast Ruby
sferik
630
63k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.8k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
Chasing Engaging Ingredients in Design
codingconduct
0
240
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
520
Making Projects Easy
brettharned
120
6.7k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
230
Transcript
AIで最適化を解けるか? MOAI Lab.
AIにおける古典最適化 • 制約プログラミング (CP) :数理最適化の対抗馬;パズルのよ うに離散的な問題に特化 • 使い分け:多くの連続変数を含む実務 => MIP,スケジューリ
ングや時間割 =>CP • メタヒューリスティクスをAI起源と称する場合もあり(所属す る研究分野が違うだけ) • 動的計画,強化学習,モデル予測制御などは,分野が違うだけ で本質は同じ
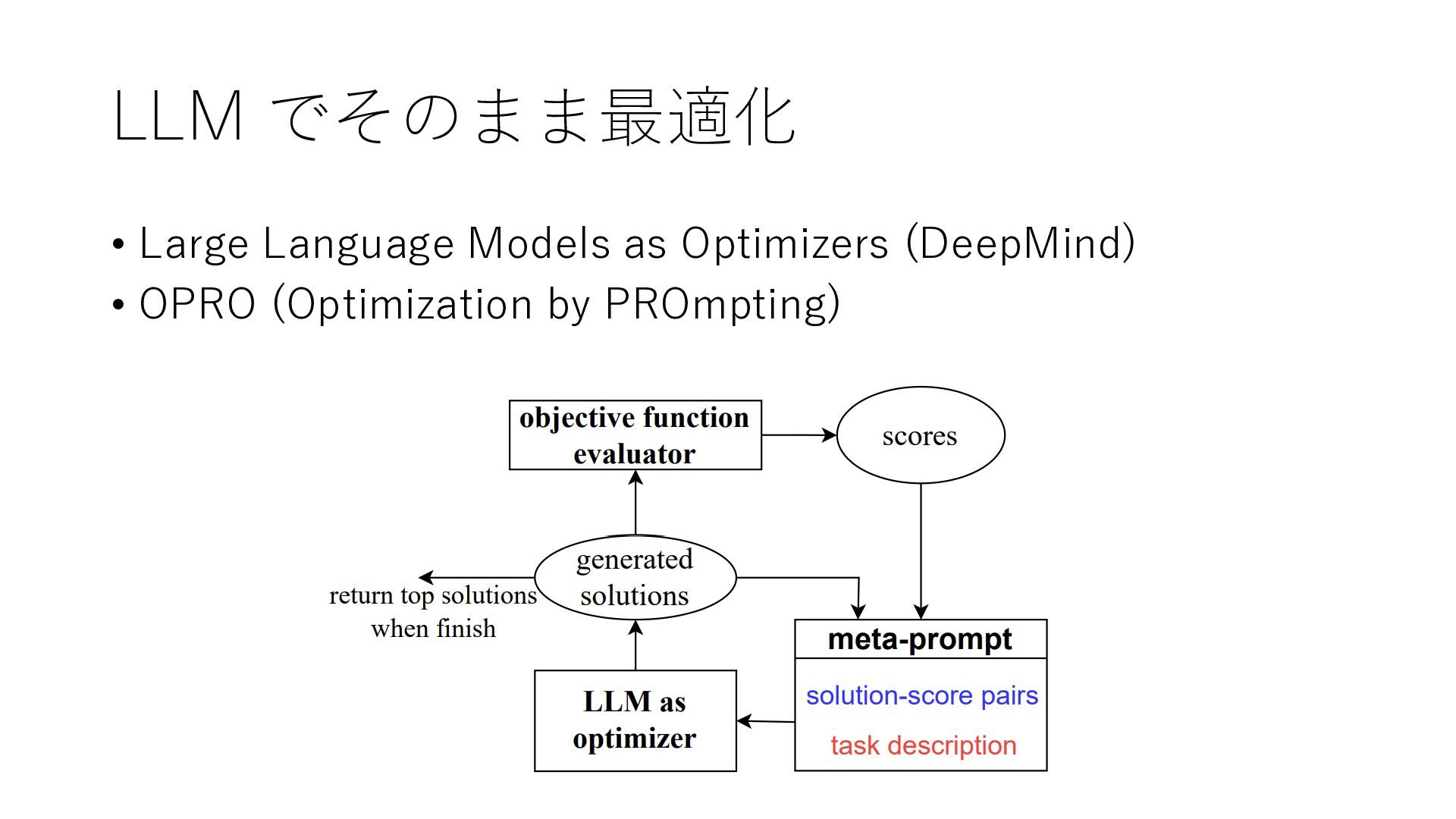
LLM でそのまま最適化 • Large Language Models as Optimizers (DeepMind) •
OPRO (Optimization by PROmpting)
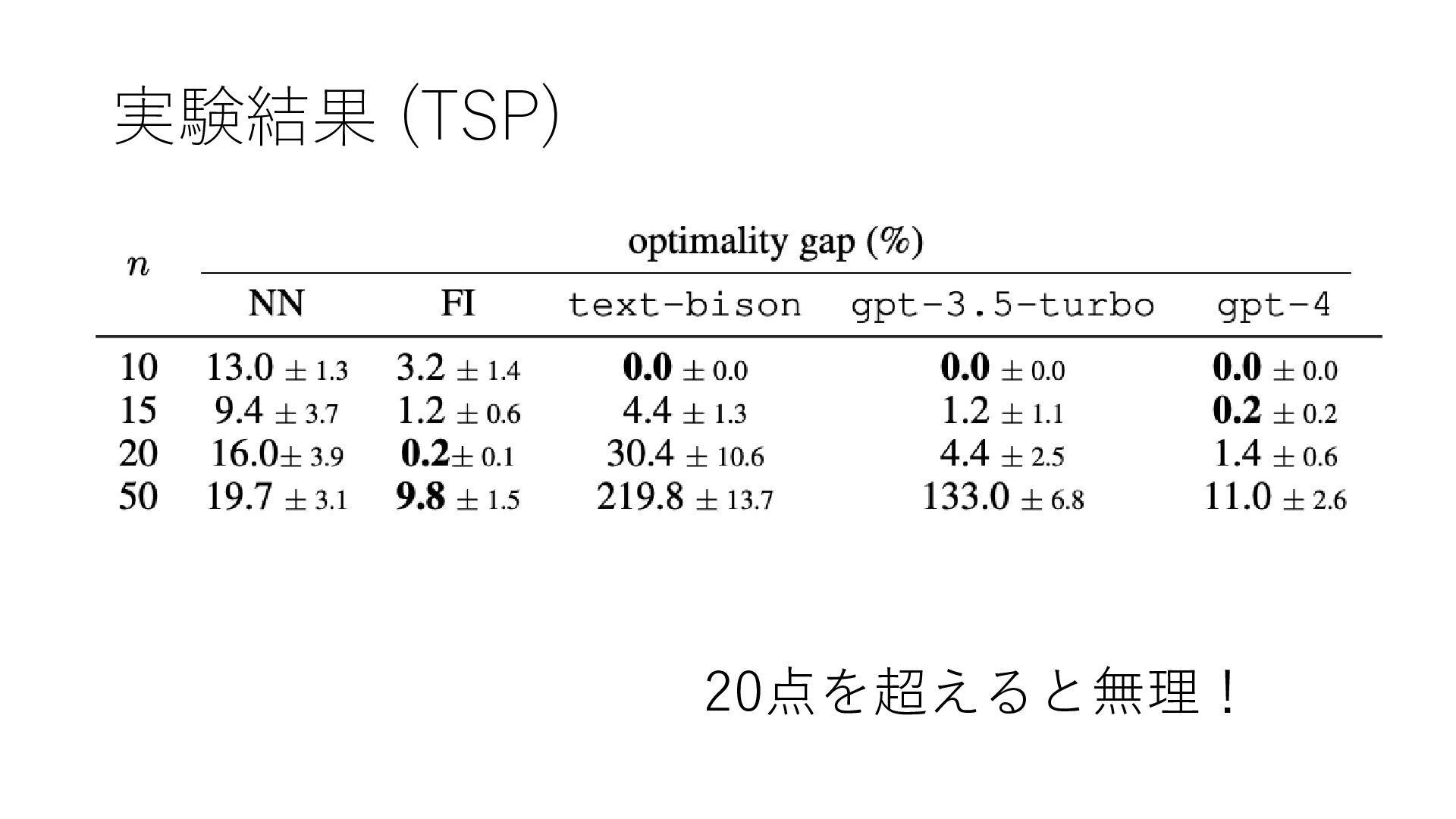
実験結果 (TSP) 20点を超えると無理!
深層強化学習 • AlphaZero (DeepMind) が有名 • Neural Combinatorial Optimizationという名前でたくさんある •
グラフをGNNやtransformerでエンコーディング,次の点への推移を当 てるデコーダーで近似解 • 一様ユークリッドのランダム問題例での実験が多い • 小さな問題例での実験が多い • 比較対象がLKHなどのSOTA解法でなく,NNやFIなどが多い • 提案手法はGPU,比較対象はCPUが多い • SOTA解法の計算時間がおかしい(提案手法の時間にあわせてある)
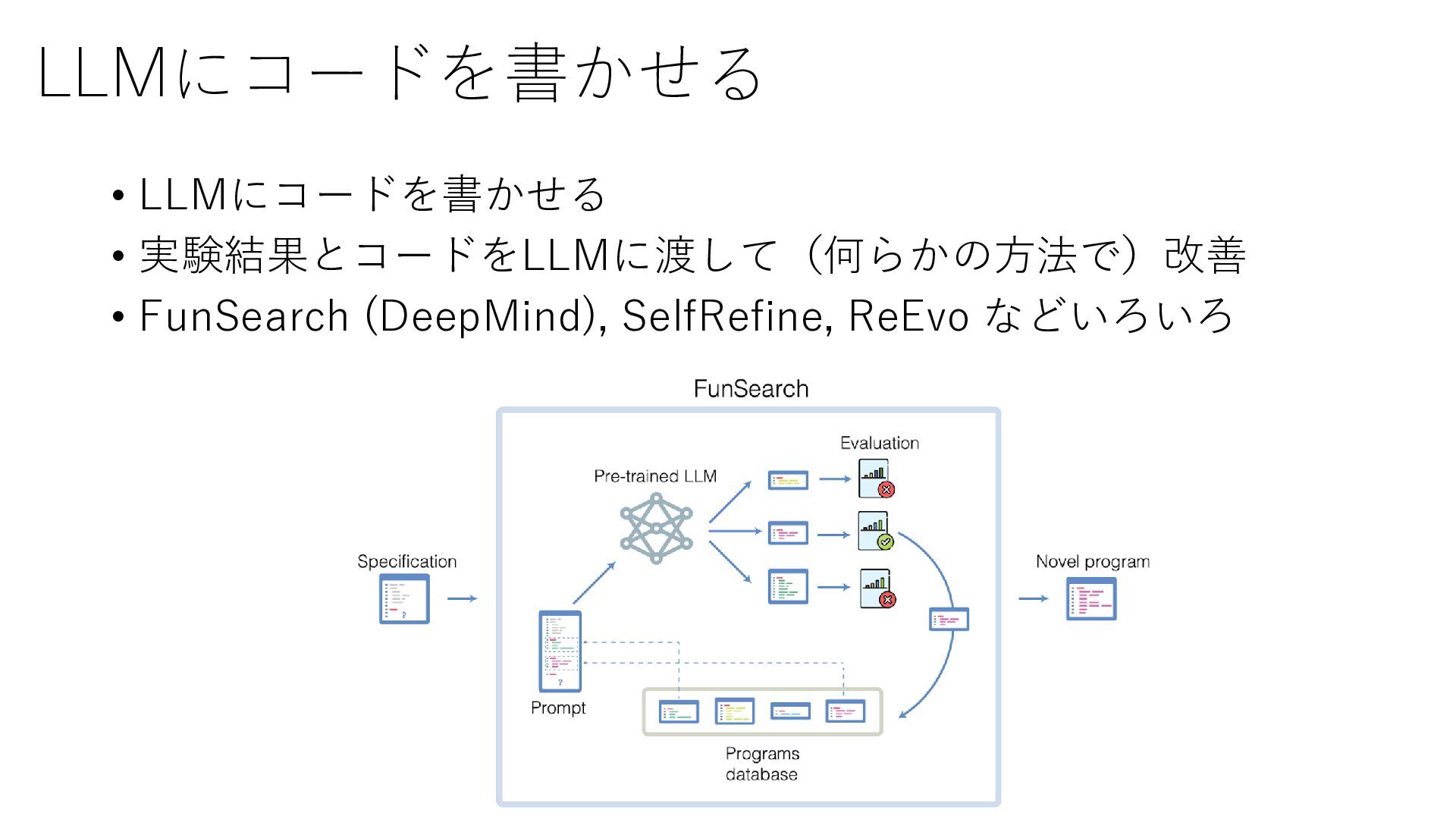
LLMにコードを書かせる • LLMにコードを書かせる • 実験結果とコードをLLMに渡して(何らかの方法で)改善 • FunSearch (DeepMind), SelfRefine, ReEvo
などいろいろ
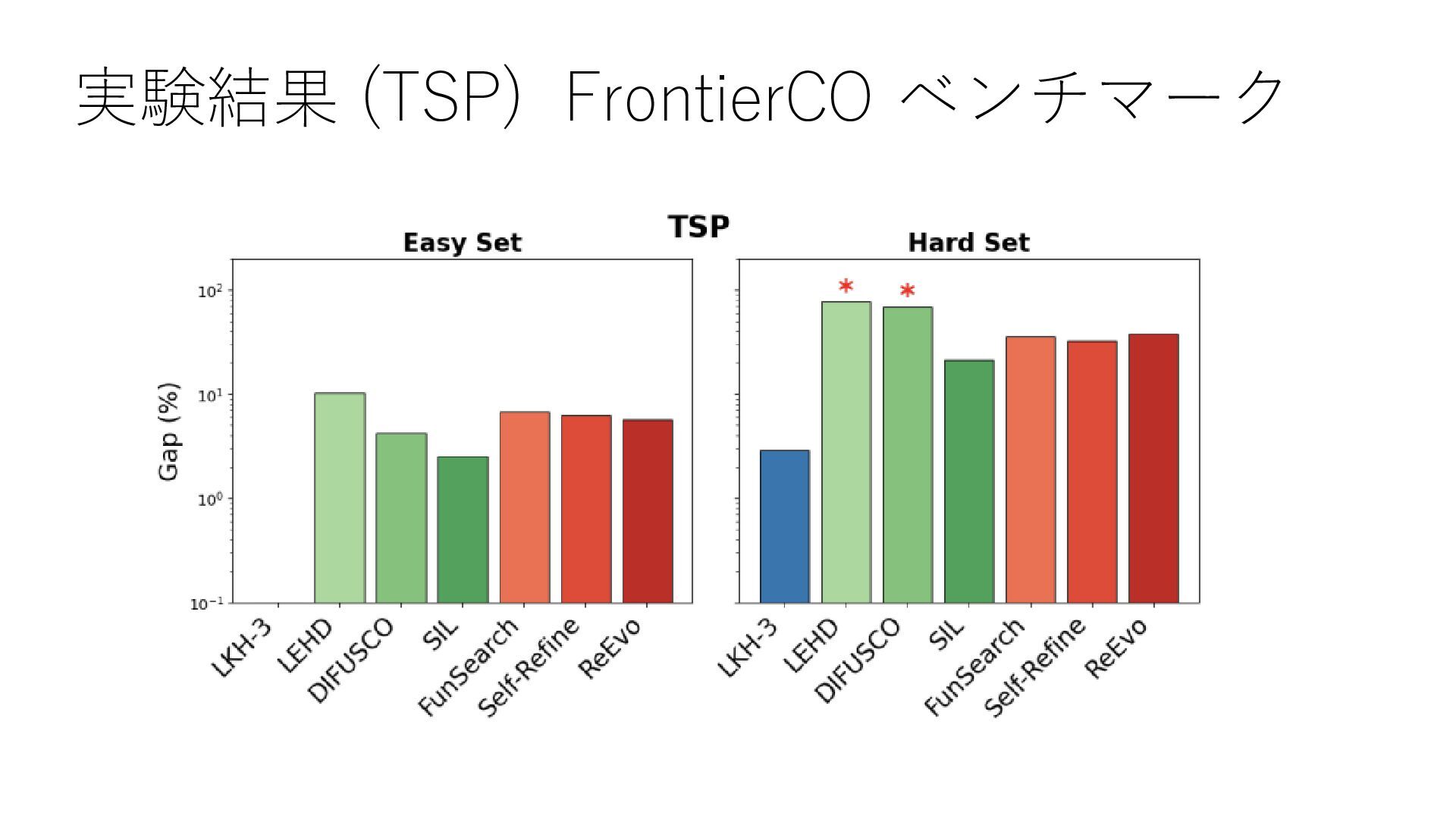
実験結果 (TSP) FrontierCO ベンチマーク
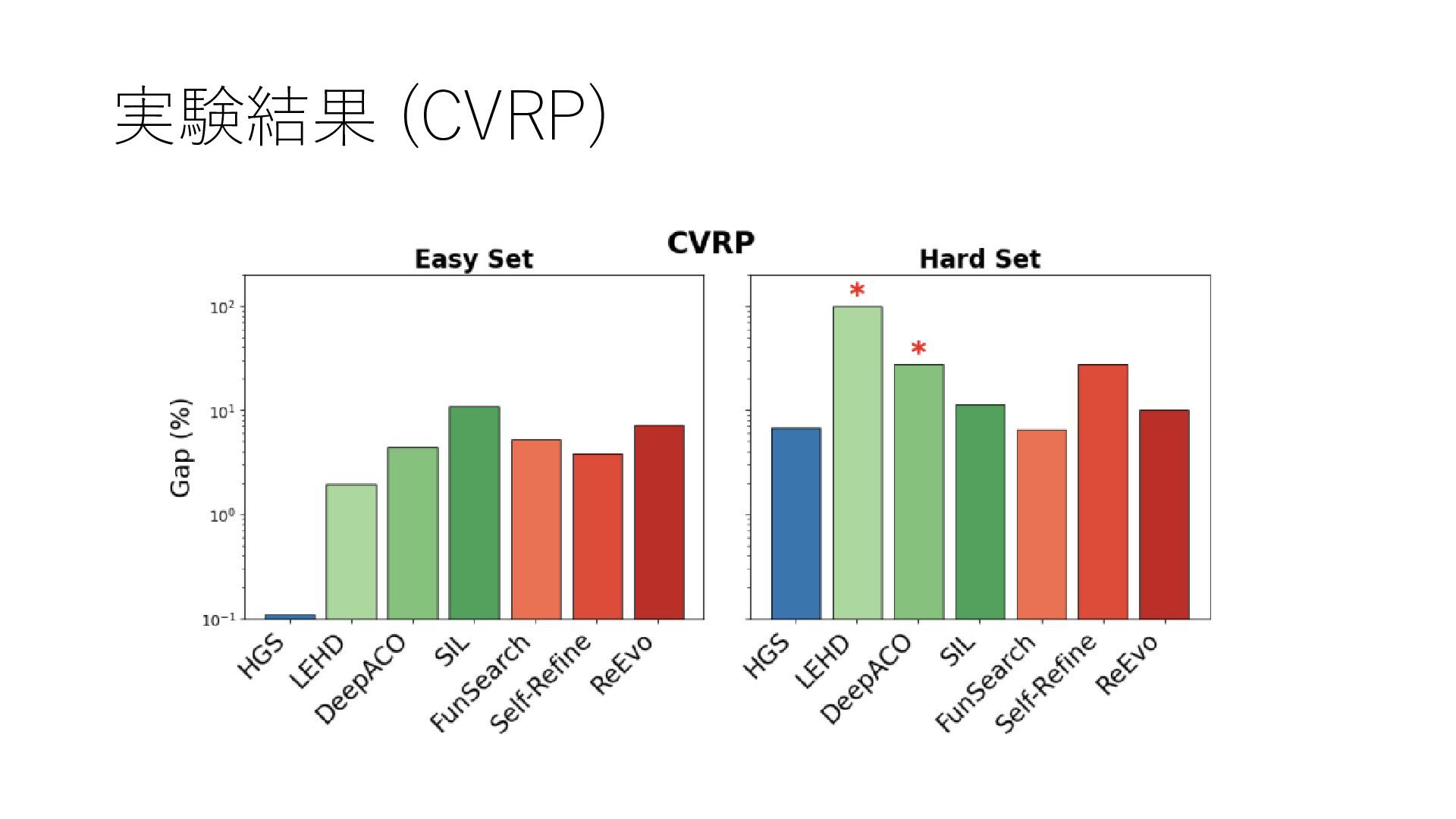
実験結果 (CVRP)
まとめ • AI は制約プログラミング (CP) だけではなくなってきている • 深層強化学習やLLMベースの研究は,実験が不十分 • 実験的解析の長い研究(1980-)を踏まえて再評価すべき
• 今のところ SOTA 解法にはかなわない • 自然言語からモデル抽出や,既存解法とLLMのハイブリッドが 正しい未来 • 過去の問題例が豊富にあれば,SOTA解法をさらに改善可能 (MOAIアプローチ)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}