Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Free-Form Image Inpainting with Gated Convolution
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Masanori YANO
September 13, 2019
Science
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Free-Form Image Inpainting with Gated Convolution
論文LT会で作成した「Free-Form Image Inpainting with Gated Convolution」の説明資料です。
Masanori YANO
September 13, 2019
More Decks by Masanori YANO
See All by Masanori YANO
Novelty Detection Via Blurring
msnr
0
560
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images
msnr
0
610
Pyramid-Based Fully Convolutional Networks for Cell Segmentation
msnr
0
620
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
msnr
0
750
Move Evaluation in Go Using Deep Convolutional Neural Networks
msnr
1
920
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
msnr
0
1.2k
Towards Understanding Chinese Checkers with Heuristics, Monte Carlo Tree Search, and Deep Reinforcement Learning
msnr
0
550
SRCNN: Image Super Resolution Using CNN
msnr
0
830
One-Class Convolutional Neural Network
msnr
0
1.4k
Other Decks in Science
See All in Science
Utiliser Bitcoin sans Internet
rlifchitz
0
300
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
660
因果推論と機械学習
sshimizu2006
1
1.2k
「遂行理論の未来」(松島斉教授最終講義記念セッションの発表資料)
shunyanoda
0
930
白金鉱業Vol.21【初学者向け発表枠】身近な例から学ぶ数理最適化の基礎 / Learning the Basics of Mathematical Optimization Through Everyday Examples
brainpadpr
1
760
(メタ)科学コミュニケーターからみたAI for Scienceの同床異夢
rmaruy
0
260
検索と推論タスクに関する論文の紹介
ynakano
1
250
Inside the Mind of an LLM
baggiponte
0
200
TypeScript で WebAssembly を用いた 型安全なプラグイン設計
nagano
2
570
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
220
[NLP2026 参加報告会] AI for Science まとめ / NLP2026
lychee1223
0
1.9k
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.3k
Featured
See All Featured
Typedesign – Prime Four
hannesfritz
42
3.1k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
GraphQLとの向き合い方2022年版
quramy
50
15k
Scaling GitHub
holman
464
140k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
How to make the Groovebox
asonas
2
2.3k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Transcript
画像処理&機械学習 論文LT会 #7 Free-Form Image Inpainting with Gated Convolution 2019年9月13日(金)
矢農 正紀 (Masanori YANO)
論文 2 標題: Free-Form Image Inpainting with Gated Convolution 論文のURL:
https://arxiv.org/abs/1806.03589 公式ページ: http://jiahuiyu.com/deepfill2/ ⇒ 画像のInpainting(修復)の手法に関する論文 著者の所属は、イリノイ大学及びAdobe Research 選んだ理由 ・画像を生成する観点で、Inpaintingの手法に関心あり ・ICCV 2019採択の論文で、本論文の手法が引用されていた ・NVIDIAのP-Convを長いこと理解できなかった ・本論文の説明と参考文献[4]で、ようやくP-Convを把握
Inpaintingとは 3 [入力] マスクを含む画像 [出力] マスクを除去した画像 ⇒ 本論文では、マスク(白塗り)は 任意の形状に対応し、加えて ユーザーのスケッチ(黒い線)も
ガイダンス的な情報として活用
Inpaintingのアプローチ 4 [1] GLCIC(Globally and Locally Consistent Image Completion) Dilated
Convolutionを含むCNN + GAN [2] P-Conv(Image Inpainting for Irregular Holes Using Partial Convolutions) Partial Convolutionを用いたU-Net構造のCNN [3] 本論文(Free-Form Image Inpainting with Gated Convolution) Gated ConvolutionのCNN(Dilatedも使用) + SN-PatchGAN ⇒ 「エンコーダ→デコーダ」のCNNで修復するところは共通 スキップ接続あり
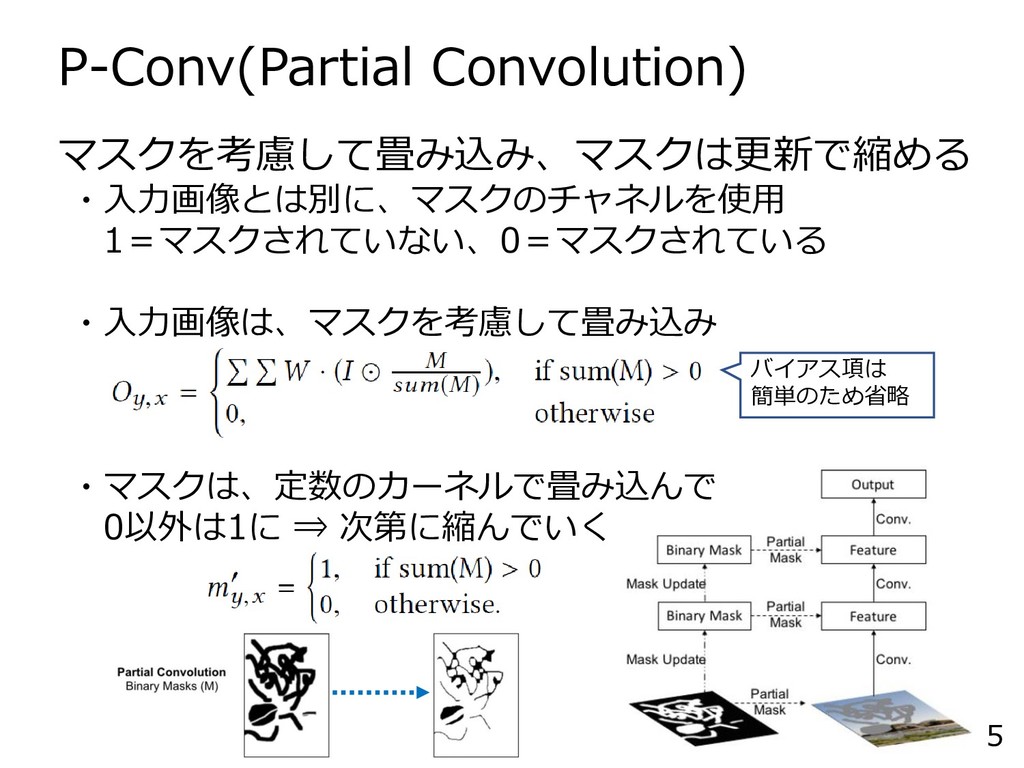
P-Conv(Partial Convolution) 5 マスクを考慮して畳み込み、マスクは更新で縮める ・入力画像とは別に、マスクのチャネルを使用 1=マスクされていない、0=マスクされている ・入力画像は、マスクを考慮して畳み込み ・マスクは、定数のカーネルで畳み込んで 0以外は1に ⇒
次第に縮んでいく バイアス項は 簡単のため省略
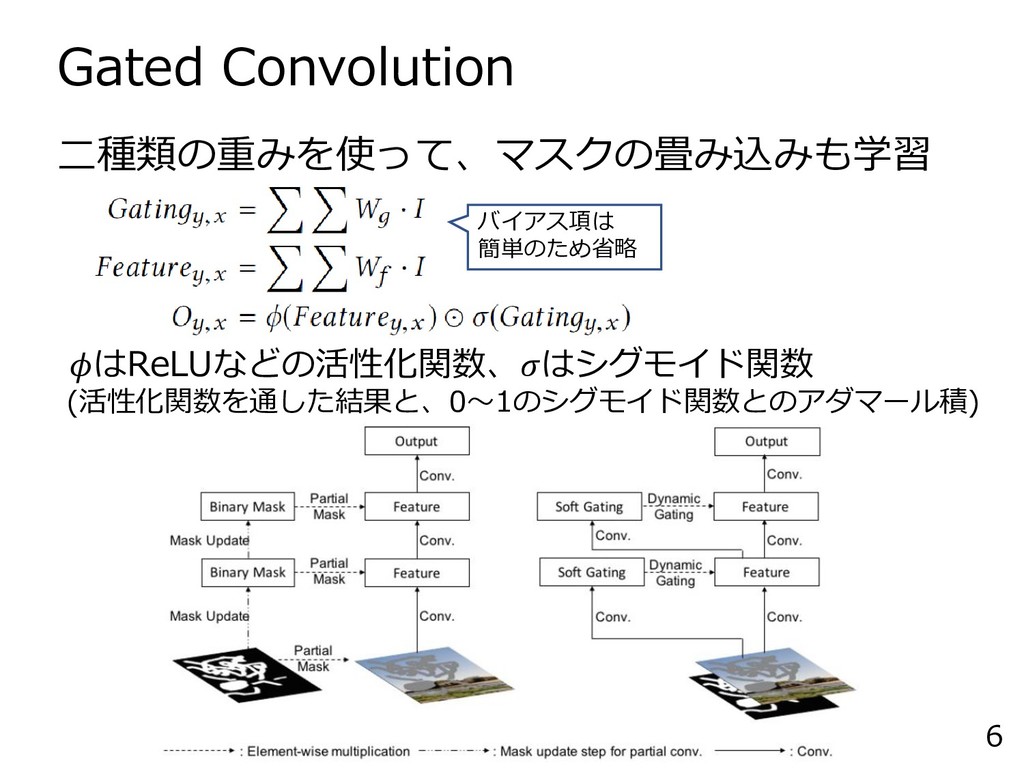
Gated Convolution 6 二種類の重みを使って、マスクの畳み込みも学習 はReLUなどの活性化関数、はシグモイド関数 (活性化関数を通した結果と、0~1のシグモイド関数とのアダマール積) バイアス項は 簡単のため省略
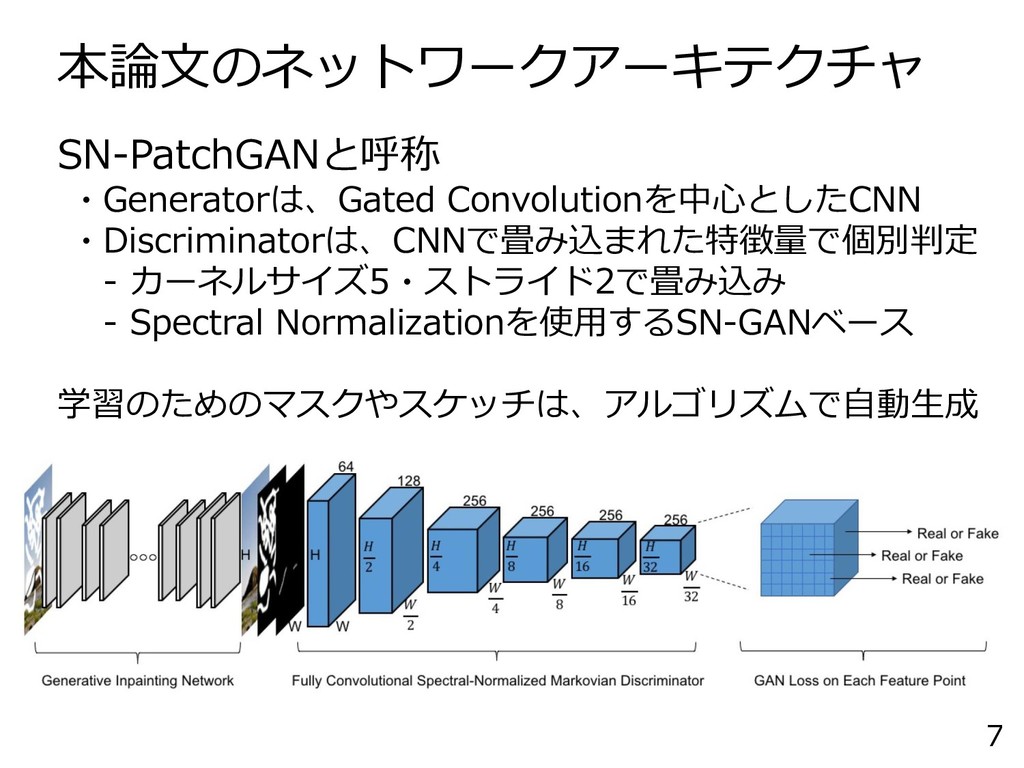
本論文のネットワークアーキテクチャ 7 SN-PatchGANと呼称 ・Generatorは、Gated Convolutionを中心としたCNN ・Discriminatorは、CNNで畳み込まれた特徴量で個別判定 - カーネルサイズ5・ストライド2で畳み込み - Spectral
Normalizationを使用するSN-GANベース 学習のためのマスクやスケッチは、アルゴリズムで自動生成
まとめ 8 本論文はGated ConvolutionとSN-PatchGANを提案 ・任意の形状のマスクやスケッチに対応できた事例を提示 ・定量的な評価は、バリデーション画像のlossの平均を比較 ・50人のユーザーに、本物の画像と修復画像を見せて評価も - 修復画像の88.7%を「リアル」と判定(本物は94.3%) 所感
・Inpaintingの論文は、成功事例の画像がインパクト大 ・一方で、だめな事例については 後続の論文で初めて見ることも ・新しい手法やアーキテクチャは 違うタスクに適用できるかも
参考文献 9 [1] GLCIC(Globally and Locally Consistent Image Completion) http://iizuka.cs.tsukuba.ac.jp/projects/completion/
[2] P-Conv(Image Inpainting for Irregular Holes Using Partial Convolutions) https://arxiv.org/abs/1804.07723 [3] Onion-Peel Networks for Deep Video Completion https://arxiv.org/abs/1908.08718 ↑ Gated Convolutionを知るきっかけとなったICCV 2019論文(動画の修復) [4] DeepCreamPyで学ぶモザイク除去 https://note.mu/koshian2/n/naa60d5c9ebba ↑ P-ConvやU-Netの実装コードを含む、わかりやすい解説
{kind=link}
{kind=link}
![Inpaintingとは 3 [入力] マスクを含む画像 [出力] マスクを除去した画像 ⇒ 本論文では、マスク(白塗り)は 任意の形状に対応し、加えて ユーザーのスケッチ(黒い線)も](https://files.speakerdeck.com/presentations/b9adfb3c76ce4b7f8a3a1a1c9b879c4e/slide_2.jpg){kind=link}
![Inpaintingのアプローチ 4 [1] GLCIC(Globally and Locally Consistent Image Completion) Dilated](https://files.speakerdeck.com/presentations/b9adfb3c76ce4b7f8a3a1a1c9b879c4e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 9 [1] GLCIC(Globally and Locally Consistent Image Completion) http://iizuka.cs.tsukuba.ac.jp/projects/completion/](https://files.speakerdeck.com/presentations/b9adfb3c76ce4b7f8a3a1a1c9b879c4e/slide_8.jpg){kind=link}