Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Novelty Detection Via Blurring
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Masanori YANO
February 23, 2020
Science
560
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Novelty Detection Via Blurring
ICLR2020論文読み会のために作成していた「Novelty Detection Via Blurring」の説明資料です。
Masanori YANO
February 23, 2020
More Decks by Masanori YANO
See All by Masanori YANO
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images
msnr
0
610
Pyramid-Based Fully Convolutional Networks for Cell Segmentation
msnr
0
620
Free-Form Image Inpainting with Gated Convolution
msnr
0
1.1k
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
msnr
0
750
Move Evaluation in Go Using Deep Convolutional Neural Networks
msnr
1
920
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
msnr
0
1.2k
Towards Understanding Chinese Checkers with Heuristics, Monte Carlo Tree Search, and Deep Reinforcement Learning
msnr
0
550
SRCNN: Image Super Resolution Using CNN
msnr
0
830
One-Class Convolutional Neural Network
msnr
0
1.4k
Other Decks in Science
See All in Science
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
960
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
660
イロレーティングを活用した関東大学サッカーの定量的実力評価 / A quantitative performance evaluation of Kanto University Football Association using Elo rating
konakalab
0
300
J-STAGE全文XML登載必須化について
xspa2012
0
1.1k
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
機械学習 - SVM
trycycle
PRO
2
1.2k
データベース01: データベースを使わない世界
trycycle
PRO
1
1.3k
機械学習 - pandas入門
trycycle
PRO
0
660
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
210
機械学習 - DBSCAN
trycycle
PRO
0
1.9k
「遂行理論の未来」(松島斉教授最終講義記念セッションの発表資料)
shunyanoda
0
930
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
280
Featured
See All Featured
Thoughts on Productivity
jonyablonski
76
5.2k
Rails Girls Zürich Keynote
gr2m
96
14k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
How to build a perfect <img>
jonoalderson
1
5.8k
The Limits of Empathy - UXLibs8
cassininazir
1
490
Design in an AI World
tapps
1
260
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
Transcript
ICLR2020論文読み会 Novelty Detection Via Blurring 2020年2月23日(日) 矢農 正紀 (Masanori YANO)
論文 2 標題: Novelty Detection Via Blurring 著者: Sungik Choi
& Sae-Young Chung URL: https://openreview.net/forum?id=ByeNra4FDB https://arxiv.org/abs/1911.11943 ⇒ ぼかした画像を通して新規性(Novelty)を検知する論文 著者の所属は、韓国の国立大学のKAIST OpenReviewのRatingは、3名とも「6」のWeak Accept ICLR2020の「Poster」でAccept 選んだ理由 ・異常検知や新規性の検知に関心があるため
本論文の概要 3 ぼかした画像を通して新規性(Novelty)を検知 ※ 本論文のNovelty=OOD(Out of Distribution) RND(Random Network Distillation)がベースのOOD検知で、
SVD(Singular Value Decomposition)を使用して画像をぼかす 「SVD-RND」を提案 ・シンプルで、テストのときに効果的 ・さまざまなドメインの画像で、ベースライン手法より上 次頁以降の構成 [1] SVDの概要 [2] RNDの概要 [3] 本論文のSVD-RND
[1] SVDの概要(1/3) 4 SVD=線形代数の特異値分解 ※ 実数に限定して説明 任意の行列の行列に対して、以下の分解が可能[1][2] = ・は行列の直交行列 ・は行列、対角成分は1
≥ 2 … ≥ > 0、他は全て0 ・は行列の直交行列 直交行列とは ・転置行列が逆行列になる行列: = = ・直交行列の行ベクトルまたは列ベクトルは正規直交基底 ⇒ ベクトルの長さは1で、異なる行・列の内積は0 特異値とは ・行列または行列の固有値の平方根1 ≥ 2 … ≥ ・やは対称行列 ⇒ 対角化可能かつ固有値は非負 は行列のランク ≤ min(, )
[1] SVDの概要(2/3) 5 SVD=線形代数の特異値分解 任意の行列の行列に対して、以下の分解が可能 = 特異値1 ≥ 2 …
≥ > 0は、値が大きいほど影響が大 ⇒ より小さいを選び、+1 以降を0にすると近似が可能 VGAサイズのRGB画像を480行640列の行列3個とみなして 特異値分解を行い、+1 以降を0にして近似した例 = 10 オリジナルの画像[6]
[1] SVDの概要(3/3) VGAサイズのRGB画像を480行640列の行列3個とみなして 特異値分解を行い、+1 以降を0にして近似した例(続き) ⇒ ぼかした画像を作成することが可能 = 1 =
5 = 10 = 25 = 100 = 50 6
[2] RNDの概要(1/2) 7 RND=ICLR2019にAcceptされた論文[3] DQN以降、点数が低かった「モンテスマの復讐」で人間超え モンテスマの復讐とは ・深層強化学習のAtari 2600ベンチマークで最難関クラス ・段差を落ちると死に、ジャンプなどのタイミングもシビア ⇒
報酬となる「スコア」が入る状態が、非常にスパース 「モンテスマの復讐」の スタート直後[5] 「モンテスマの復讐」の スコアの一覧[4]
[2] RNDの概要(2/2) 8 RNDは、過去に見ていない状態にボーナスを出す[4] ・画面を入力、ベクトルを出力とする2個のネットワーク ・FEATURESは、ランダムに初期化したネットワークを固定 ・PREDICTORは、FEATURESの出力を真似るように学習 ⇒ 学習していない画面に対しては、出力の差分が大きくなる また、一定周期で学習を行うため、一度でも見た画面は
PREDICTORの訓練データに含まれて、差分が小さくなる
[3] 本論文のSVD-RND(1/4) 9 もとの画像と、ぼかした画像の両方を真似るRND ・ぼかした画像は、SVDで非ゼロの下位 個の特異値を消す (もとの画像のチャネルごとに、特異値の上位だけ残す) ・学習させるネットワークと、ランダムなネットワーク ・ はランダムなまま固定し、は全てを真似るように学習
推論時はと0 のみ使い − 0 () 2 2で判定
[3] 本論文のSVD-RND(2/4) 10 もとの画像と、ぼかした画像の両方を真似るRND ぼかした画像と、そのためのネットワークは 個の設定 本論文の実験では、 = 1または =
2で実施
[3] 本論文のSVD-RND(3/4) 11 メインの実験の条件 ・Targetのデータセットに対し、他のデータセットがOOD (例えばCIFAR-10の場合、SVHNなどが来たらOOD検知) ・画像のサイズは、リサイズして32 × 32ピクセルに統一 ・Targetの訓練データの数は、50000個に揃えて学習
・OODのテストデータのうち、1000個をバリデーションの データとして使用し、ハイパーパラメータの を最適化
[3] 本論文のSVD-RND(4/4) 12 メインの実験の結果 ・TPR(True Positive Rate)が95%以上のときのTNR(True Negative Rate) ・/で区切られた3個の値は、各々のOODデータセットの結果
・一番上の「SVD-RND」は、CelebA以外では最も良い結果 (CelebAでは幾何変換と組み合わせて実験した良い結果も) ・SVDに加え、DCT(離散コサイン変換)やGB(ガウシアン)も
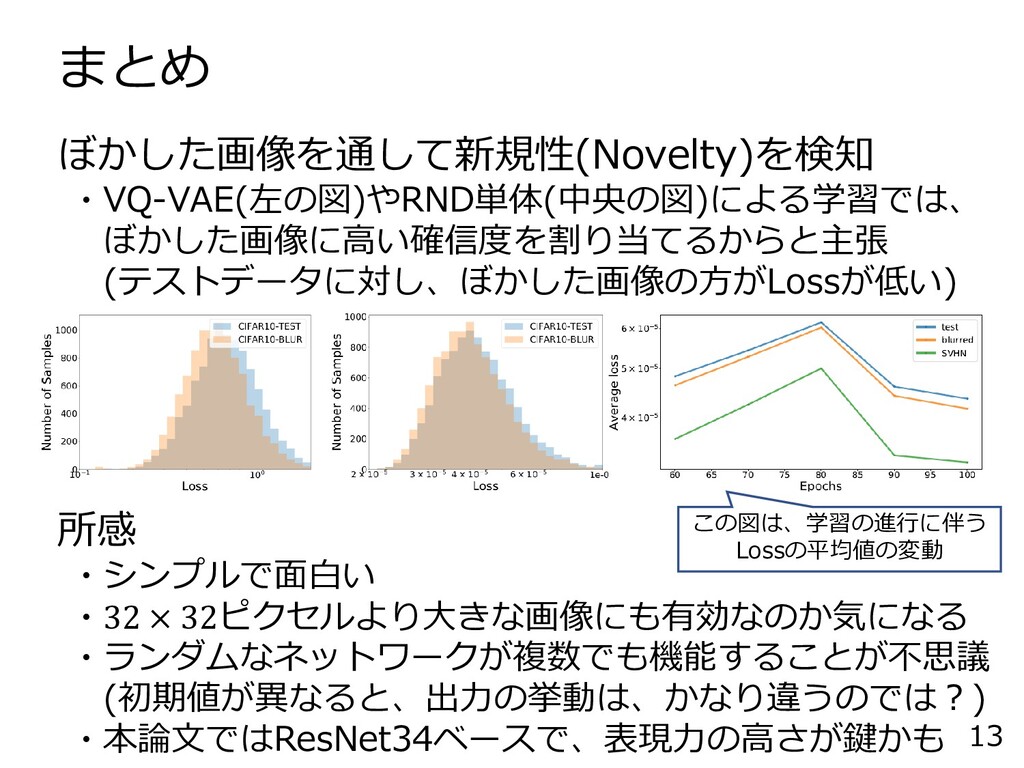
まとめ 13 ぼかした画像を通して新規性(Novelty)を検知 ・VQ-VAE(左の図)やRND単体(中央の図)による学習では、 ぼかした画像に高い確信度を割り当てるからと主張 (テストデータに対し、ぼかした画像の方がLossが低い) 所感 ・シンプルで面白い ・32 ×
32ピクセルより大きな画像にも有効なのか気になる ・ランダムなネットワークが複数でも機能することが不思議 (初期値が異なると、出力の挙動は、かなり違うのでは?) ・本論文ではResNet34ベースで、表現力の高さが鍵かも この図は、学習の進行に伴う Lossの平均値の変動
参考文献 14 [1] 日本評論社の書籍「線形代数 基礎と応用」 https://www.nippyo.co.jp/shop/book/2763.html [2] 「医用画像工学」講義資料の「特異値分解」 http://www.cfme.chiba-u.jp/~haneishi/class/iyogazokougaku.html [3]
Exploration by Random Network Distillation https://arxiv.org/abs/1810.12894 [4] Reinforcement Learning with Prediction-Based Rewards https://openai.com/blog/reinforcement-learning-with-prediction-based-rewards/ [5] Montezuma's Revenge - Atari 2600 https://www.retrogames.cz/play_124-Atari2600.php [6] Wikipediaの「平成」 https://ja.wikipedia.org/wiki/%E5%B9%B3%E6%88%90
{kind=link}
{kind=link}
{kind=link}
![[1] SVDの概要(1/3) 4 SVD=線形代数の特異値分解 ※ 実数に限定して説明 任意の行列の行列に対して、以下の分解が可能[1][2] = ・は行列の直交行列 ・は行列、対角成分は1](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_3.jpg){kind=link}
![[1] SVDの概要(2/3) 5 SVD=線形代数の特異値分解 任意の行列の行列に対して、以下の分解が可能 = 特異値1 ≥ 2 …](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_4.jpg){kind=link}
![[1] SVDの概要(3/3) VGAサイズのRGB画像を480行640列の行列3個とみなして 特異値分解を行い、+1 以降を0にして近似した例(続き) ⇒ ぼかした画像を作成することが可能 = 1 =](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_5.jpg){kind=link}
![[2] RNDの概要(1/2) 7 RND=ICLR2019にAcceptされた論文[3] DQN以降、点数が低かった「モンテスマの復讐」で人間超え モンテスマの復讐とは ・深層強化学習のAtari 2600ベンチマークで最難関クラス ・段差を落ちると死に、ジャンプなどのタイミングもシビア ⇒](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_6.jpg){kind=link}
![[2] RNDの概要(2/2) 8 RNDは、過去に見ていない状態にボーナスを出す[4] ・画面を入力、ベクトルを出力とする2個のネットワーク ・FEATURESは、ランダムに初期化したネットワークを固定 ・PREDICTORは、FEATURESの出力を真似るように学習 ⇒ 学習していない画面に対しては、出力の差分が大きくなる また、一定周期で学習を行うため、一度でも見た画面は](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_7.jpg){kind=link}
![[3] 本論文のSVD-RND(1/4) 9 もとの画像と、ぼかした画像の両方を真似るRND ・ぼかした画像は、SVDで非ゼロの下位 個の特異値を消す (もとの画像のチャネルごとに、特異値の上位だけ残す) ・学習させるネットワークと、ランダムなネットワーク ・ はランダムなまま固定し、は全てを真似るように学習](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_8.jpg){kind=link}
![[3] 本論文のSVD-RND(2/4) 10 もとの画像と、ぼかした画像の両方を真似るRND ぼかした画像と、そのためのネットワークは 個の設定 本論文の実験では、 = 1または =](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_9.jpg){kind=link}
![[3] 本論文のSVD-RND(3/4) 11 メインの実験の条件 ・Targetのデータセットに対し、他のデータセットがOOD (例えばCIFAR-10の場合、SVHNなどが来たらOOD検知) ・画像のサイズは、リサイズして32 × 32ピクセルに統一 ・Targetの訓練データの数は、50000個に揃えて学習](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_10.jpg){kind=link}
![[3] 本論文のSVD-RND(4/4) 12 メインの実験の結果 ・TPR(True Positive Rate)が95%以上のときのTNR(True Negative Rate) ・/で区切られた3個の値は、各々のOODデータセットの結果](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_11.jpg){kind=link}
{kind=link}
![参考文献 14 [1] 日本評論社の書籍「線形代数 基礎と応用」 https://www.nippyo.co.jp/shop/book/2763.html [2] 「医用画像工学」講義資料の「特異値分解」 http://www.cfme.chiba-u.jp/~haneishi/class/iyogazokougaku.html [3]](https://files.speakerdeck.com/presentations/4f8beedb2b9943acb9a8fe83b20ea775/slide_13.jpg){kind=link}