Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Towards Understanding Chinese Checkers with Heu...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Masanori YANO
June 07, 2019
Science
550
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Towards Understanding Chinese Checkers with Heuristics, Monte Carlo Tree Search, and Deep Reinforcement Learning
論文LT会で作成したChinese Checkers論文の説明資料です。
Masanori YANO
June 07, 2019
More Decks by Masanori YANO
See All by Masanori YANO
Novelty Detection Via Blurring
msnr
0
560
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images
msnr
0
610
Pyramid-Based Fully Convolutional Networks for Cell Segmentation
msnr
0
620
Free-Form Image Inpainting with Gated Convolution
msnr
0
1.1k
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
msnr
0
750
Move Evaluation in Go Using Deep Convolutional Neural Networks
msnr
1
920
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
msnr
0
1.2k
SRCNN: Image Super Resolution Using CNN
msnr
0
830
One-Class Convolutional Neural Network
msnr
0
1.4k
Other Decks in Science
See All in Science
東北地方における過去20年間の降水量の変化
naokimuroki
1
340
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
810
イロレーティングを活用した関東大学サッカーの定量的実力評価 / A quantitative performance evaluation of Kanto University Football Association using Elo rating
konakalab
0
300
TypeScript で WebAssembly を用いた 型安全なプラグイン設計
nagano
2
570
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
機械学習 - 授業概要
trycycle
PRO
0
560
Van Dare naar Durf
voginip
0
260
白金鉱業Vol.21【初学者向け発表枠】身近な例から学ぶ数理最適化の基礎 / Learning the Basics of Mathematical Optimization Through Everyday Examples
brainpadpr
1
760
次代のデータサイエンティストへ~スキルチェックリスト、タスクリスト更新~
datascientistsociety
PRO
3
46k
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
210
AI bij literatuuronderzoek in de wetenschap
voginip
0
220
Featured
See All Featured
Balancing Empowerment & Direction
lara
6
1.2k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
How to train your dragon (web standard)
notwaldorf
97
6.7k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
240
Crafting Experiences
bethany
1
220
Paper Plane
katiecoart
PRO
2
52k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Transcript
画像処理&機械学習 論文LT会 #3 Towards Understanding Chinese Checkers with Heuristics, Monte
Carlo Tree Search, and Deep Reinforcement Learning 2019年6月7日(金) 矢農 正紀 (Masanori YANO)
論文 2 Towards Understanding Chinese Checkers with Heuristics, Monte Carlo
Tree Search, and Deep Reinforcement Learning 論文のURL: https://arxiv.org/abs/1903.01747 ⇒ Chinese Checkersに、AlphaZeroの手法を適用した論文 著者は、オーストラリアのシドニー大学のメンバー 選んだ理由 ・AlphaZeroの応用に関心があり、arXiv論文を検索 - AlphaGoから3年が経過しても、期待ほど広がらない - CNNによる状態の認識やMCTSは、応用もあると期待 CNN: Convolutional Neural Network(畳み込みニューラルネットワーク) MCTS: Monte-Carlo Tree Search(モンテカルロ木探索)
Google DeepMindメンバーの囲碁研究 3 [0] ICLR 2015の論文: CNNで「KGS Go Server」の打ち手を55%予測 https://arxiv.org/pdf/1412.6564.pdf
[1] AlphaGo Fan: 「KGS Go Server」の棋譜データでプロ棋士に勝利 https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf [2] AlphaGo Lee: トップクラスのプロ棋士に勝利 [3] AlphaGo Master: ネット碁で、プロ棋士に無敗 [4] AlphaGo Zero: 棋譜データを使わずに強く https://deepmind.com/documents/119/agz_unformatted_nature.pdf [5] AlphaZero: 囲碁に加えて、チェスと将棋でも強く https://deepmind.com/documents/260/alphazero_preprint.pdf ⇒ AlphaZeroで、Google DeepMindの「囲碁研究は」終了 論文に関心ある場合は、赤字の論文からが読みやすいかも
Chinese Checkersとは 4 手番ごとにコマを動かすゲームで、中国とは無関係 ・全ての自分のコマを、対岸まで移動させることが目的 ・ふつうの1マス移動に加えて、他のコマ一つを飛び越せる ・飛び越して動かすときは、繰り返し飛び越すことが可能 ・囲碁や将棋やチェッカーと異なり、コマは取られない ・論文では二人対戦に限定し、コマの数も赤と青6個ずつ ・論文では、距離が2以上のコマも飛び越せるルールを採用
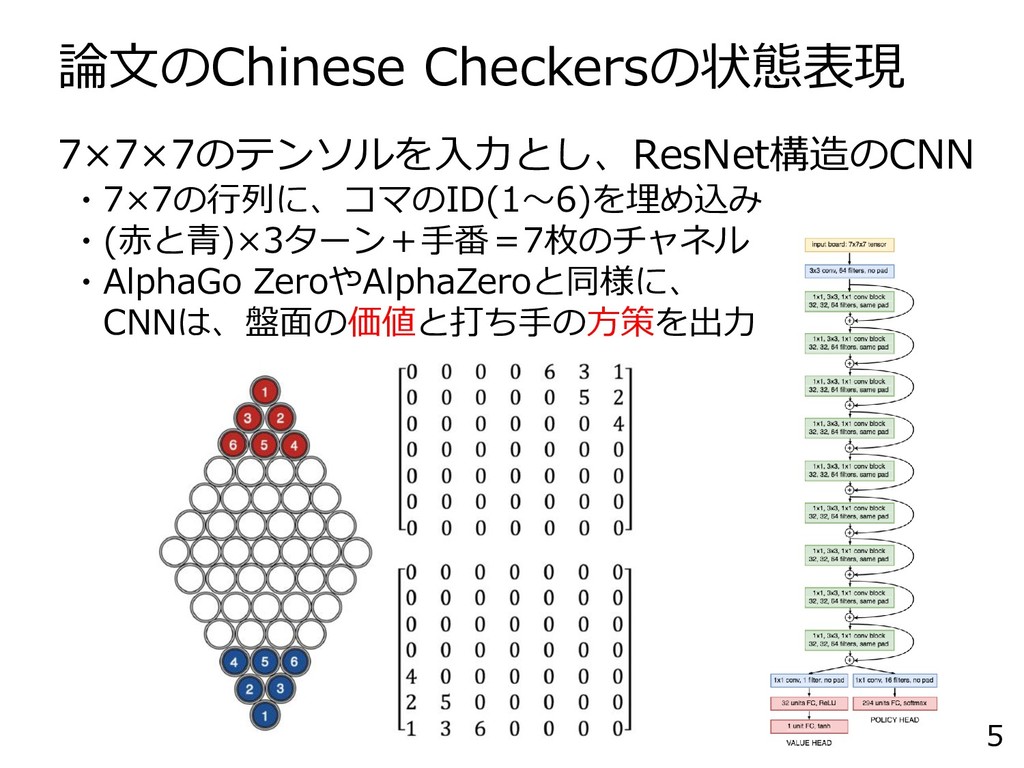
論文のChinese Checkersの状態表現 5 7×7×7のテンソルを入力とし、ResNet構造のCNN ・7×7の行列に、コマのID(1~6)を埋め込み ・(赤と青)×3ターン+手番=7枚のチャネル ・AlphaGo ZeroやAlphaZeroと同様に、 CNNは、盤面の価値と打ち手の方策を出力
論文のMCTS(モンテカルロ木探索) 6 MCTSを175回繰り返し、1盤面の価値と方策を取得 [1] 次に探索すべき手を求める(ノイズを加えて、確率的に) [2] まだ探索していない手であれば、新しいLeafを展開 [3] 訪問ルートとLeafのCNN予測値を使って、データを更新 ⇒
180回の対戦で得られたデータを使って、CNNを学習 損失関数は、AlphaGo ZeroやAlphaZeroと同一 交差エントロピーなので「-」が付くはず
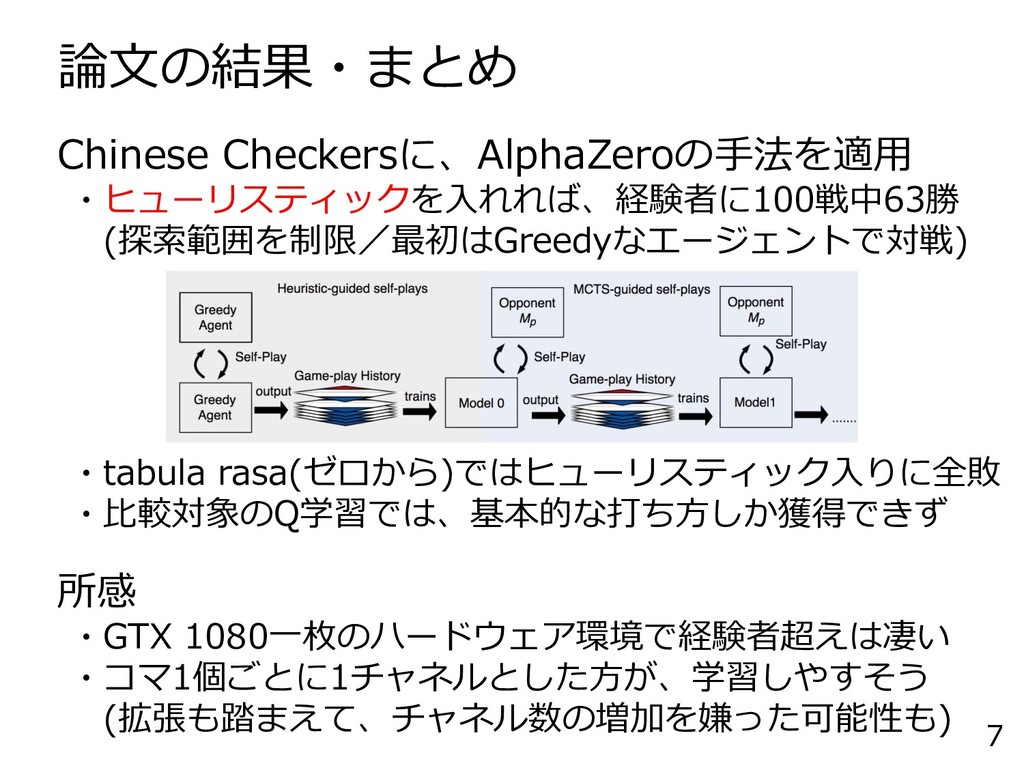
論文の結果・まとめ 7 Chinese Checkersに、AlphaZeroの手法を適用 ・ヒューリスティックを入れれば、経験者に100戦中63勝 (探索範囲を制限/最初はGreedyなエージェントで対戦) ・tabula rasa(ゼロから)ではヒューリスティック入りに全敗 ・比較対象のQ学習では、基本的な打ち方しか獲得できず 所感
・GTX 1080一枚のハードウェア環境で経験者超えは凄い ・コマ1個ごとに1チャネルとした方が、学習しやすそう (拡張も踏まえて、チャネル数の増加を嫌った可能性も)
{kind=link}
{kind=link}
![Google DeepMindメンバーの囲碁研究 3 [0] ICLR 2015の論文: CNNで「KGS Go Server」の打ち手を55%予測 https://arxiv.org/pdf/1412.6564.pdf](https://files.speakerdeck.com/presentations/5330706ebf234ba39f4fff56ef40fc7e/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![論文のMCTS(モンテカルロ木探索) 6 MCTSを175回繰り返し、1盤面の価値と方策を取得 [1] 次に探索すべき手を求める(ノイズを加えて、確率的に) [2] まだ探索していない手であれば、新しいLeafを展開 [3] 訪問ルートとLeafのCNN予測値を使って、データを更新 ⇒](https://files.speakerdeck.com/presentations/5330706ebf234ba39f4fff56ef40fc7e/slide_5.jpg){kind=link}
{kind=link}