Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amazon Aurora Cluster Cloneを用いたDataLake構築
Search
netprotections
April 07, 2023
860
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Amazon Aurora Cluster Cloneを用いたDataLake構築
突撃!隣のデータ設計・活用勉強会 vol.1の登壇資料です。
https://stafes.connpass.com/event/273805/
netprotections
April 07, 2023
More Decks by netprotections
See All by netprotections
2025/2/6開催メディア向け説明会_株式会社ネットプロテクションズ_企業間決済ビジネスの事業戦略
netprotections
0
1.1k
2025/2/6開催メディア向け説明会_株式会社 NCB Lab._企業間決済の最新トレンド 米国主要プレイヤーの戦略
netprotections
0
1.1k
新旧ツールを駆使した レガシーアプリの解読 #cm_odyssey
netprotections
0
140
Debeziumを活用した RDBMSイベントソーシングの仕組み
netprotections
0
1.3k
株式会社ネットプロテクションズ 会社紹介資料
netprotections
1
260k
決済システムは一人ではつくれなかった話
netprotections
1
2.3k
株式会社ネットプロテクションズ エンジニア職向け会社紹介資料
netprotections
0
46k
Featured
See All Featured
Automating Front-end Workflow
addyosmani
1370
210k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Building Adaptive Systems
keathley
44
3.1k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
We Are The Robots
honzajavorek
0
290
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
A Tale of Four Properties
chriscoyier
163
24k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Embracing the Ebb and Flow
colly
88
5.1k
Transcript
Copyright(C) Net Protections,Inc. All Rights Reserved. Amazon Aurora Cluster Clone
を用いたDataLake構築
Copyright(C) Net Protections,Inc. All Rights Reserved. 自己紹介 2 佐久間仁 Sakuma
Jin 東京大学 情報理工学系研究科 博士課程中退。 大学院では自然言語処理を研究。 2021年4月にネットプロテクションズに新卒入社。 新卒1年目の時に機械学習の事業活用PJTを立ち上げ、 MLOpsの構築から事業適用までを行った。 現在は、data分析基盤チームのリーダーを務める。 株式会社ネットプロテクションズ データサイエンスグループ
Copyright(C) Net Protections,Inc. All Rights Reserved. 目次 3 01 |
Net Protectionsのdata分析環境 • なぜdata分析環境を作るのか? • Net Protectionsのdata分析環境 02 | Cluster Cloneを用いたDataLake連携 • 一般的なRDBからのDataLake連携 • Aurora Cluster Cloneの仕組み • Copy-on-write protocol • Step Functionを用いたOrchestration 03 | 副次的効果 • DataLake連携システムを誰が作るか? 04 | まとめ
Copyright(C) Net Protections,Inc. All Rights Reserved. Net Protectionsのdata分析環境 4
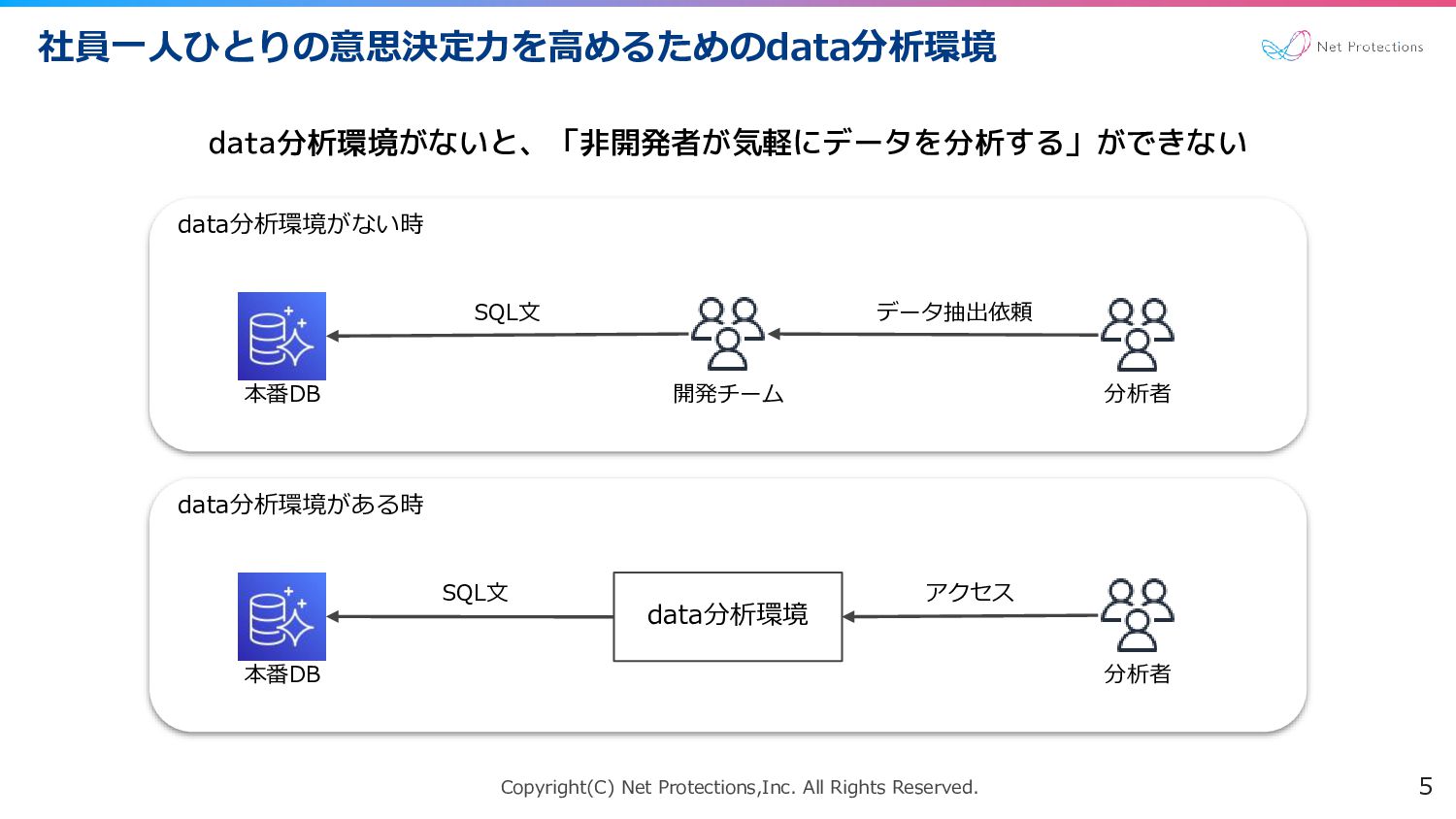
Copyright(C) Net Protections,Inc. All Rights Reserved. 社員一人ひとりの意思決定力を高めるためのdata分析環境 5 data分析環境がないと、「非開発者が気軽にデータを分析する」ができない data分析環境がない時
data分析環境がある時 本番DB 分析者 開発チーム データ抽出依頼 SQL文 本番DB 分析者 アクセス SQL文 data分析環境
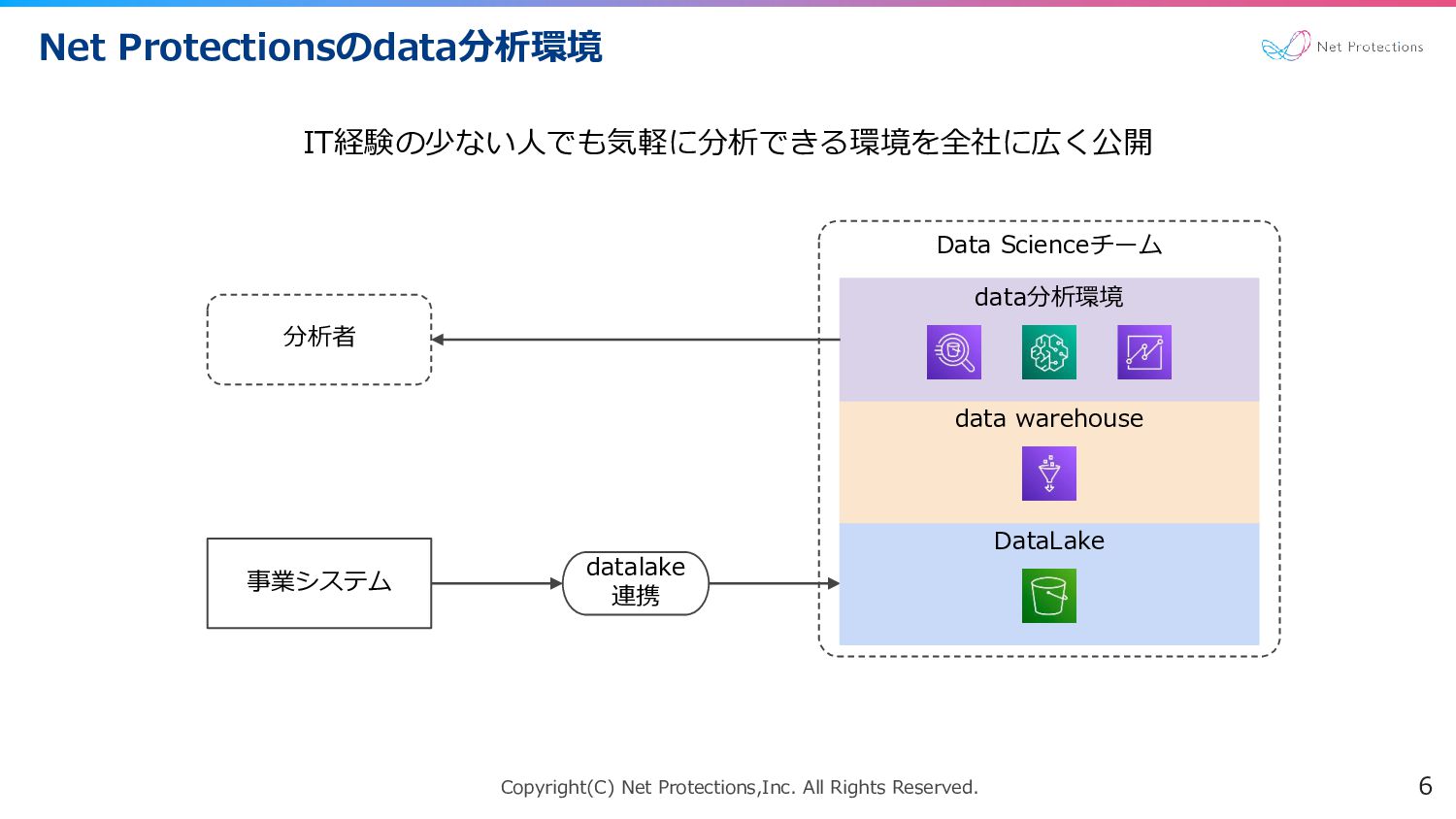
Copyright(C) Net Protections,Inc. All Rights Reserved. Net Protectionsのdata分析環境 6 IT経験の少ない人でも気軽に分析できる環境を全社に広く公開
Data Scienceチーム datalake 連携 DataLake data warehouse data分析環境 事業システム 分析者
Copyright(C) Net Protections,Inc. All Rights Reserved. Cluster Cloneを用いたDataLake連携 7
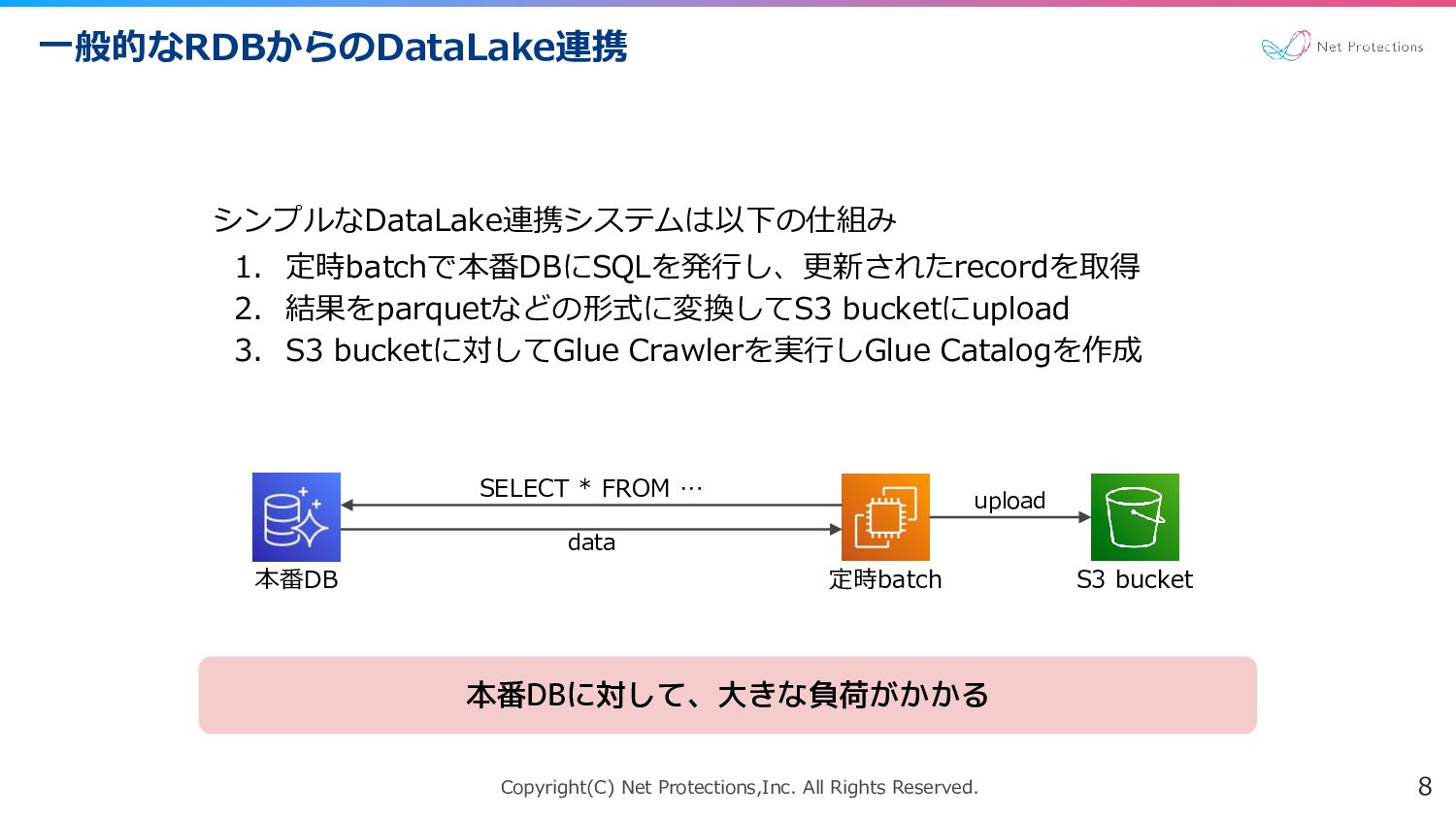
Copyright(C) Net Protections,Inc. All Rights Reserved. 一般的なRDBからのDataLake連携 8 SELECT *
FROM … data upload 本番DB 定時batch S3 bucket シンプルなDataLake連携システムは以下の仕組み 1. 定時batchで本番DBにSQLを発行し、更新されたrecordを取得 2. 結果をparquetなどの形式に変換してS3 bucketにupload 3. S3 bucketに対してGlue Crawlerを実行しGlue Catalogを作成 本番DBに対して、大きな負荷がかかる
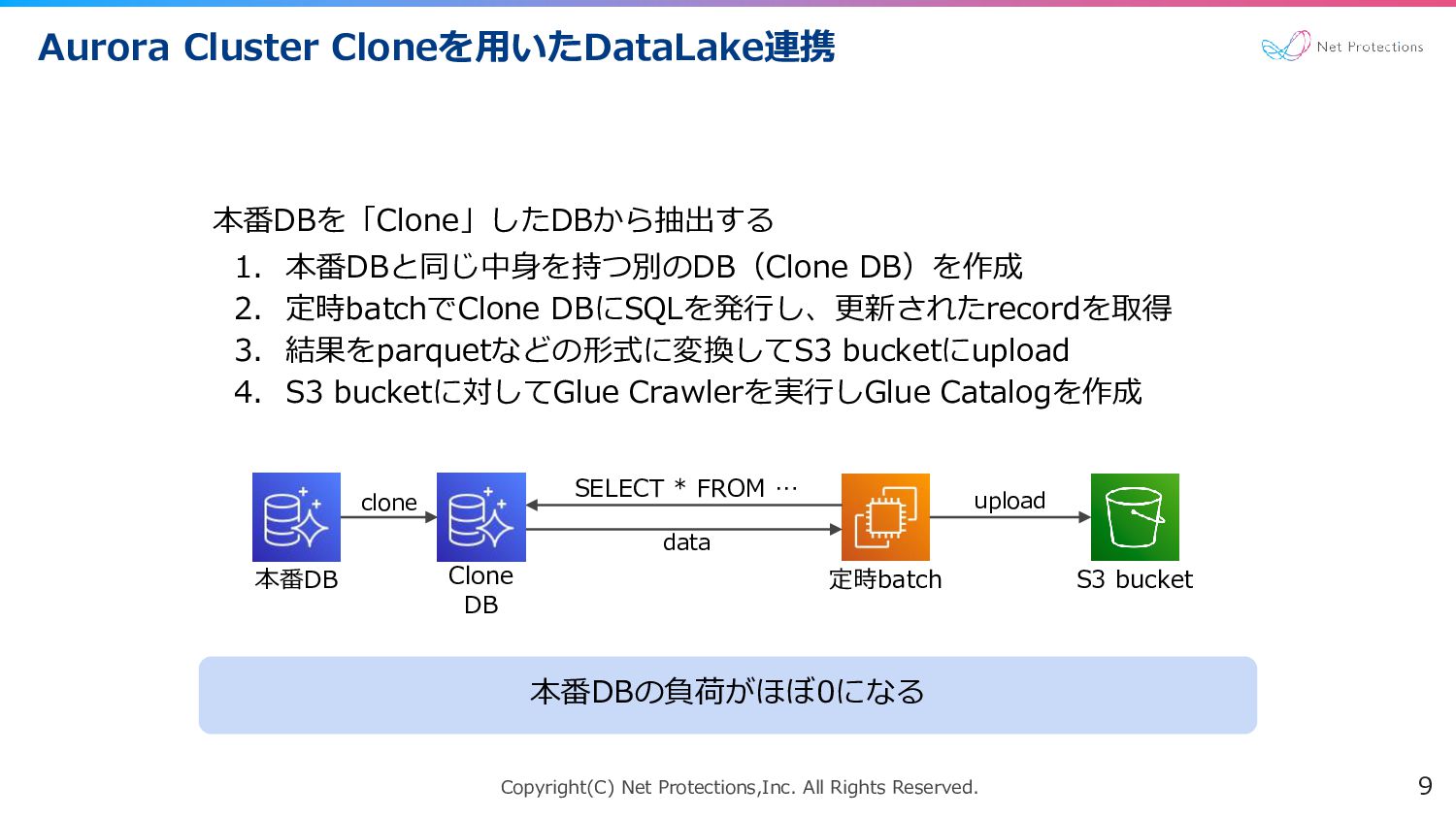
Copyright(C) Net Protections,Inc. All Rights Reserved. Aurora Cluster Cloneを用いたDataLake連携 9
SELECT * FROM … data upload 本番DB 定時batch S3 bucket 本番DBを「Clone」したDBから抽出する 1. 本番DBと同じ中身を持つ別のDB(Clone DB)を作成 2. 定時batchでClone DBにSQLを発行し、更新されたrecordを取得 3. 結果をparquetなどの形式に変換してS3 bucketにupload 4. S3 bucketに対してGlue Crawlerを実行しGlue Catalogを作成 本番DBの負荷がほぼ0になる Clone DB clone
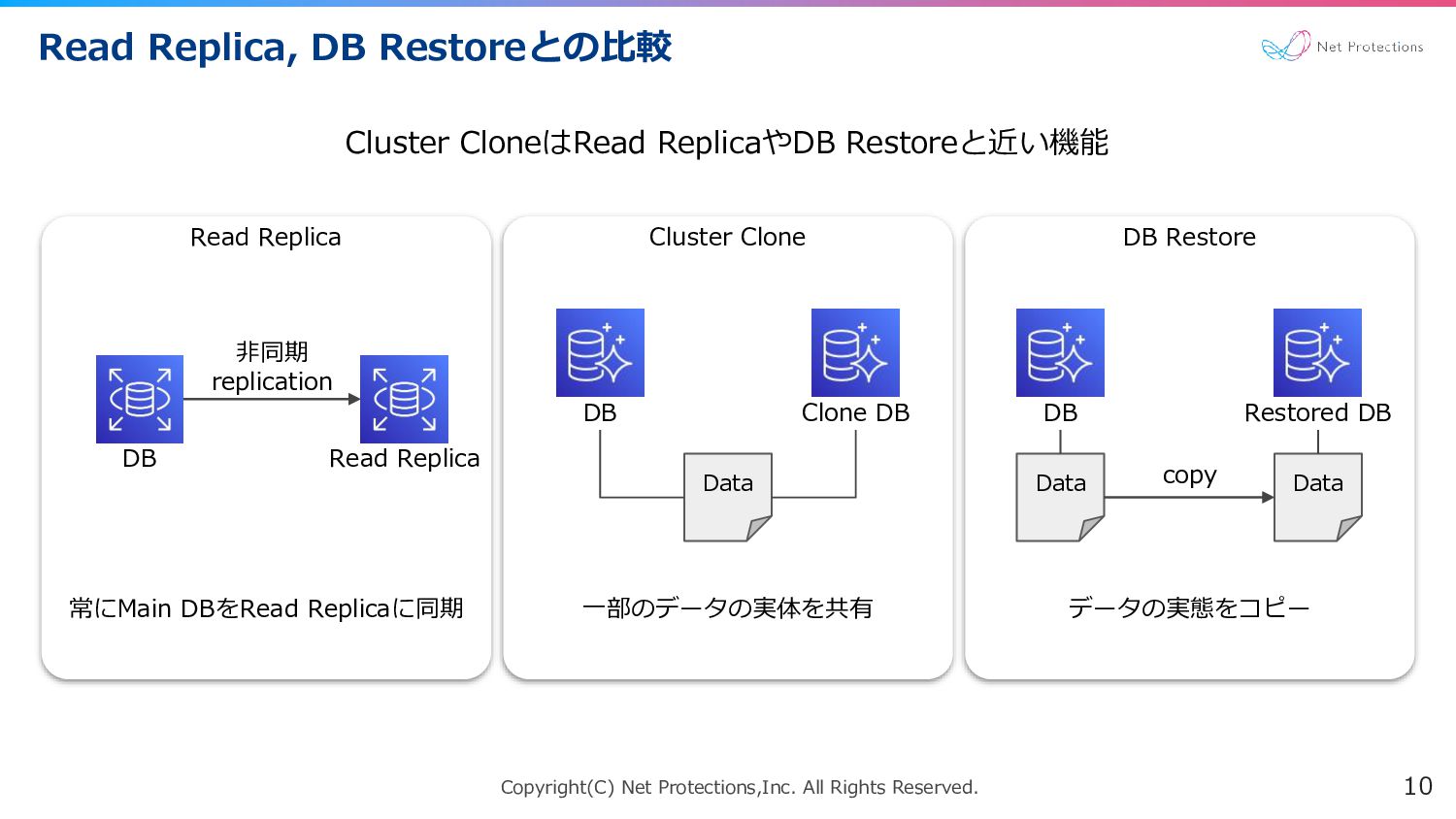
Copyright(C) Net Protections,Inc. All Rights Reserved. DB Restore Read Replica,
DB Restoreとの比較 10 Read Replica Cluster Clone 非同期 replication DB Read Replica Data Data copy Data DB Clone DB DB Restored DB Cluster CloneはRead ReplicaやDB Restoreと近い機能 常にMain DBをRead Replicaに同期 一部のデータの実体を共有 データの実態をコピー
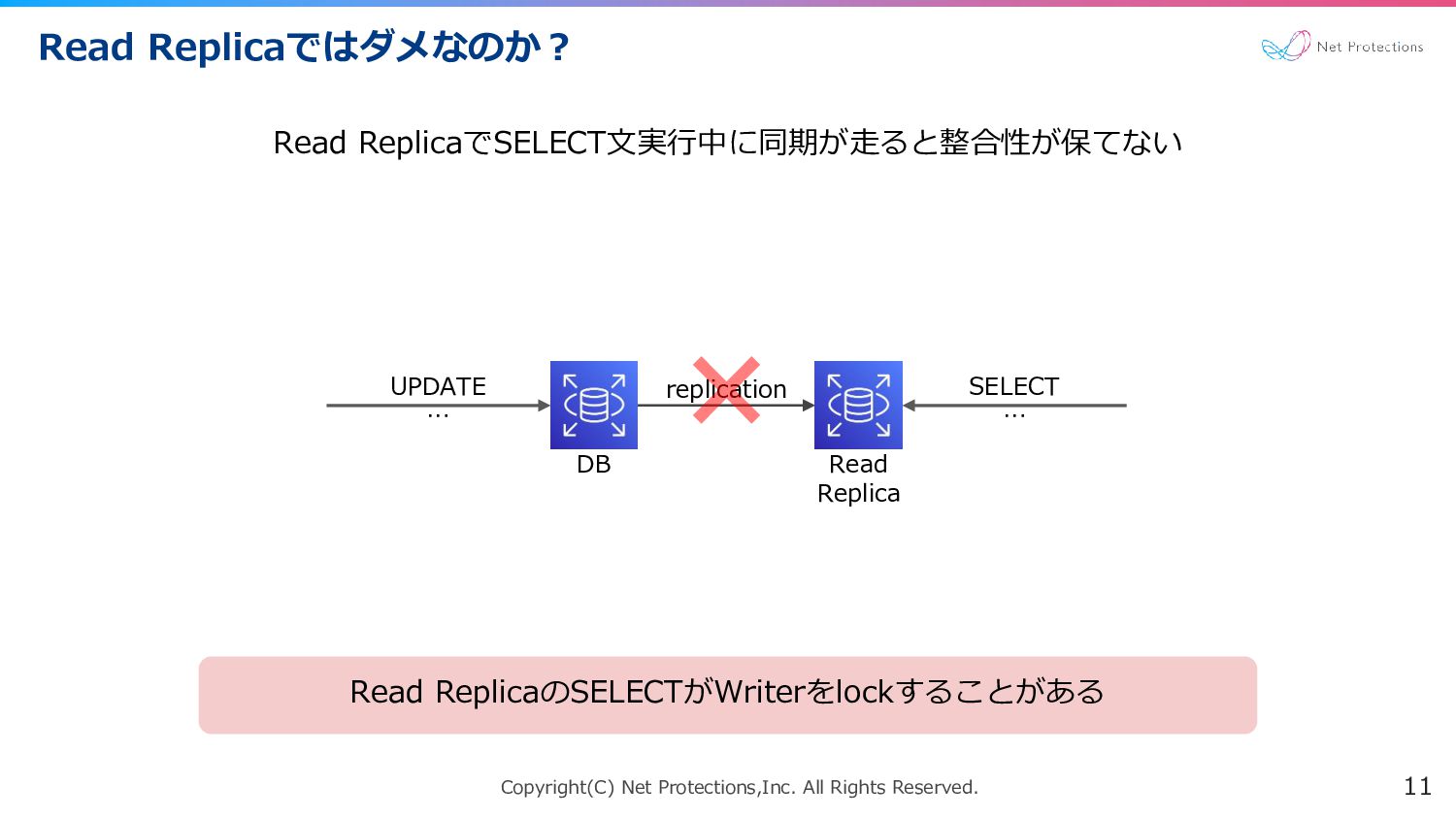
Copyright(C) Net Protections,Inc. All Rights Reserved. Read Replicaではダメなのか? 11 replication
DB Read Replica Read ReplicaでSELECT文実行中に同期が走ると整合性が保てない Read ReplicaのSELECTがWriterをlockすることがある SELECT … UPDATE …
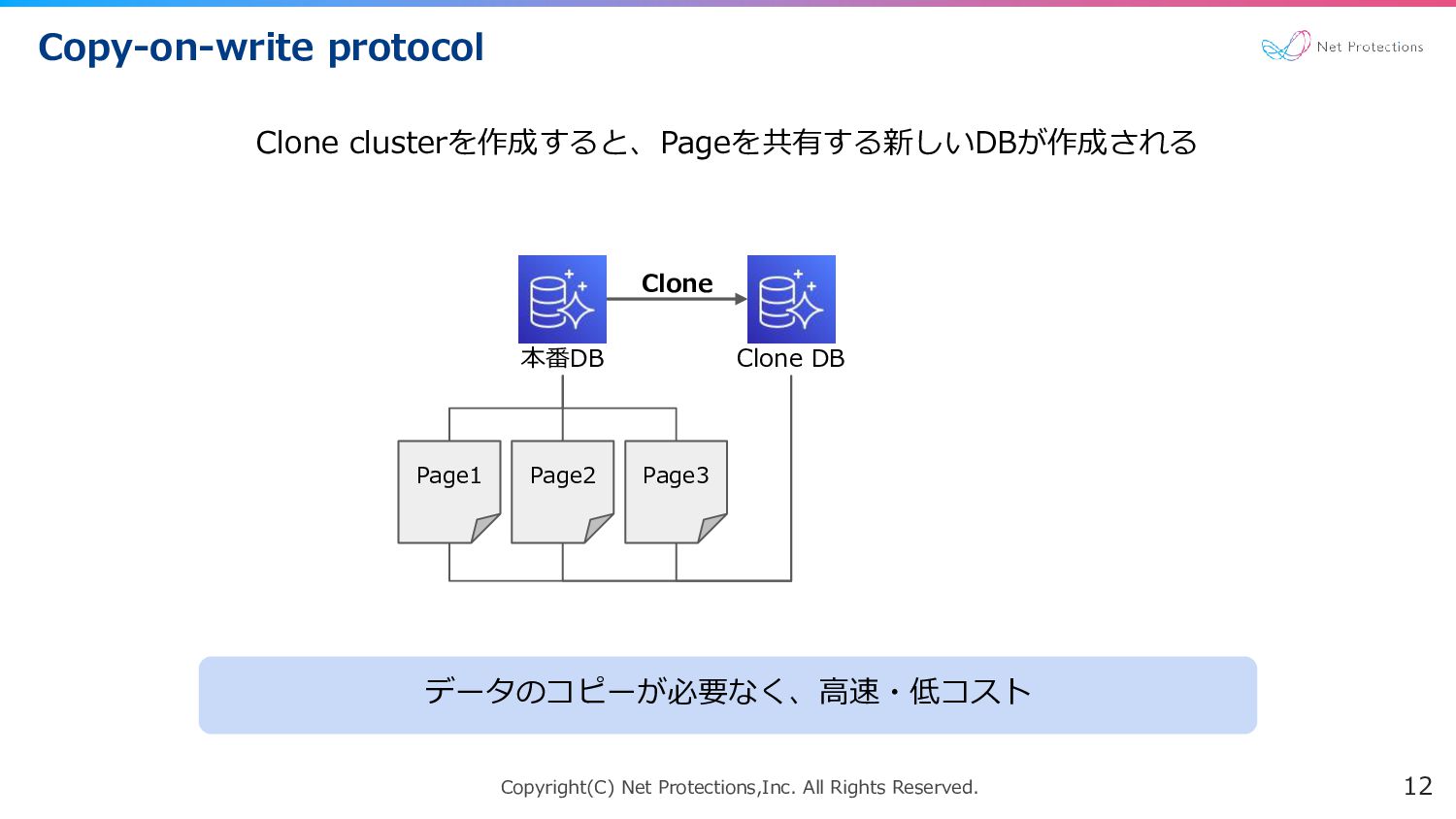
Copyright(C) Net Protections,Inc. All Rights Reserved. Copy-on-write protocol 12 Clone
clusterを作成すると、Pageを共有する新しいDBが作成される データのコピーが必要なく、高速・低コスト Page1 Page2 Page3 本番DB Clone DB Clone
Copyright(C) Net Protections,Inc. All Rights Reserved. Copy-on-write protocol 13 Clone
DBに対してSELECTすると、共有している本番DBのpageからデータを持ってくる Page1 Page2 Page3 本番DB Clone DB SELECT … 定時batch data
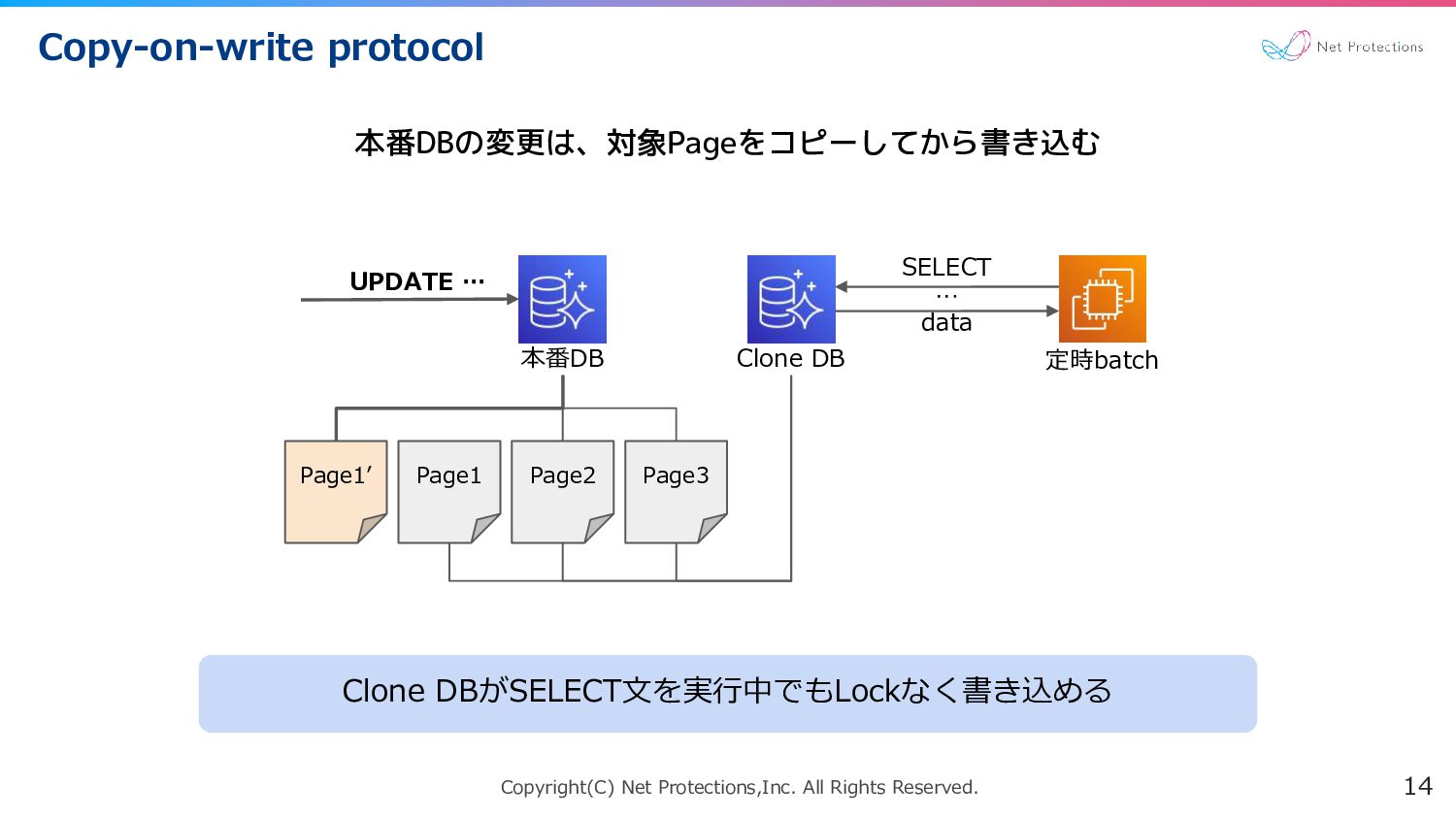
Copyright(C) Net Protections,Inc. All Rights Reserved. Copy-on-write protocol 14 Page1
Page2 Page3 本番DB Clone DB SELECT … 本番DBの変更は、対象Pageをコピーしてから書き込む 定時batch data Page1’ UPDATE … Clone DBがSELECT文を実行中でもLockなく書き込める
Copyright(C) Net Protections,Inc. All Rights Reserved. Cluster Cloneのメリット・デメリット 15 完全に個別のDB
Instanceなので、本番DBへの負荷がほぼ0 データのコピーがないため、DBサイズの依存せず高速に立ち上がる 変更のないPageは共有するので、Storageの削減 本番DBへの更新はClone DBに反映されない
Copyright(C) Net Protections,Inc. All Rights Reserved. 副次的効果 16
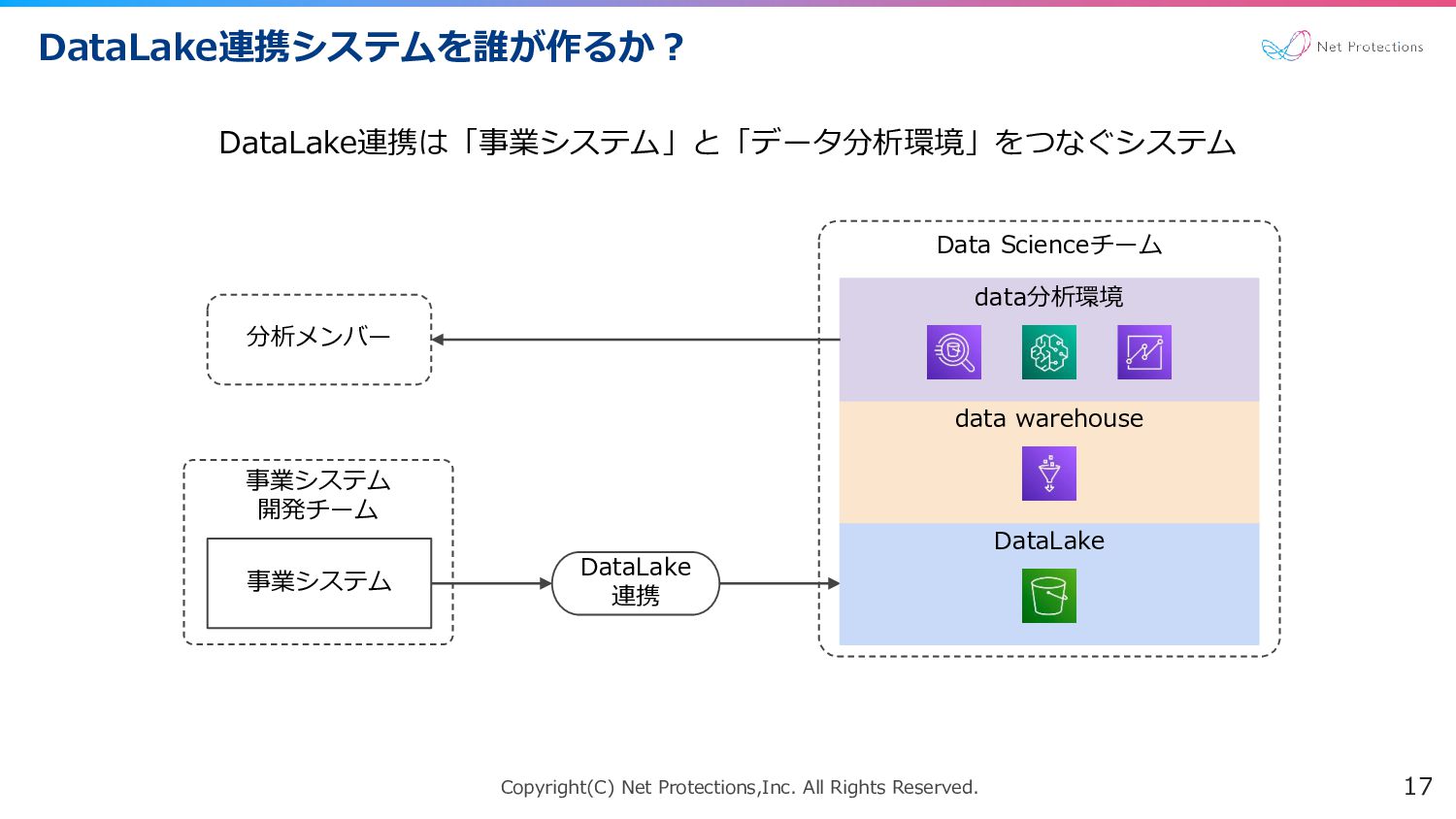
Copyright(C) Net Protections,Inc. All Rights Reserved. DataLake連携システムを誰が作るか? 17 DataLake連携は「事業システム」と「データ分析環境」をつなぐシステム Data
Scienceチーム 事業システム 開発チーム DataLake 連携 DataLake data warehouse data分析環境 事業システム 分析メンバー
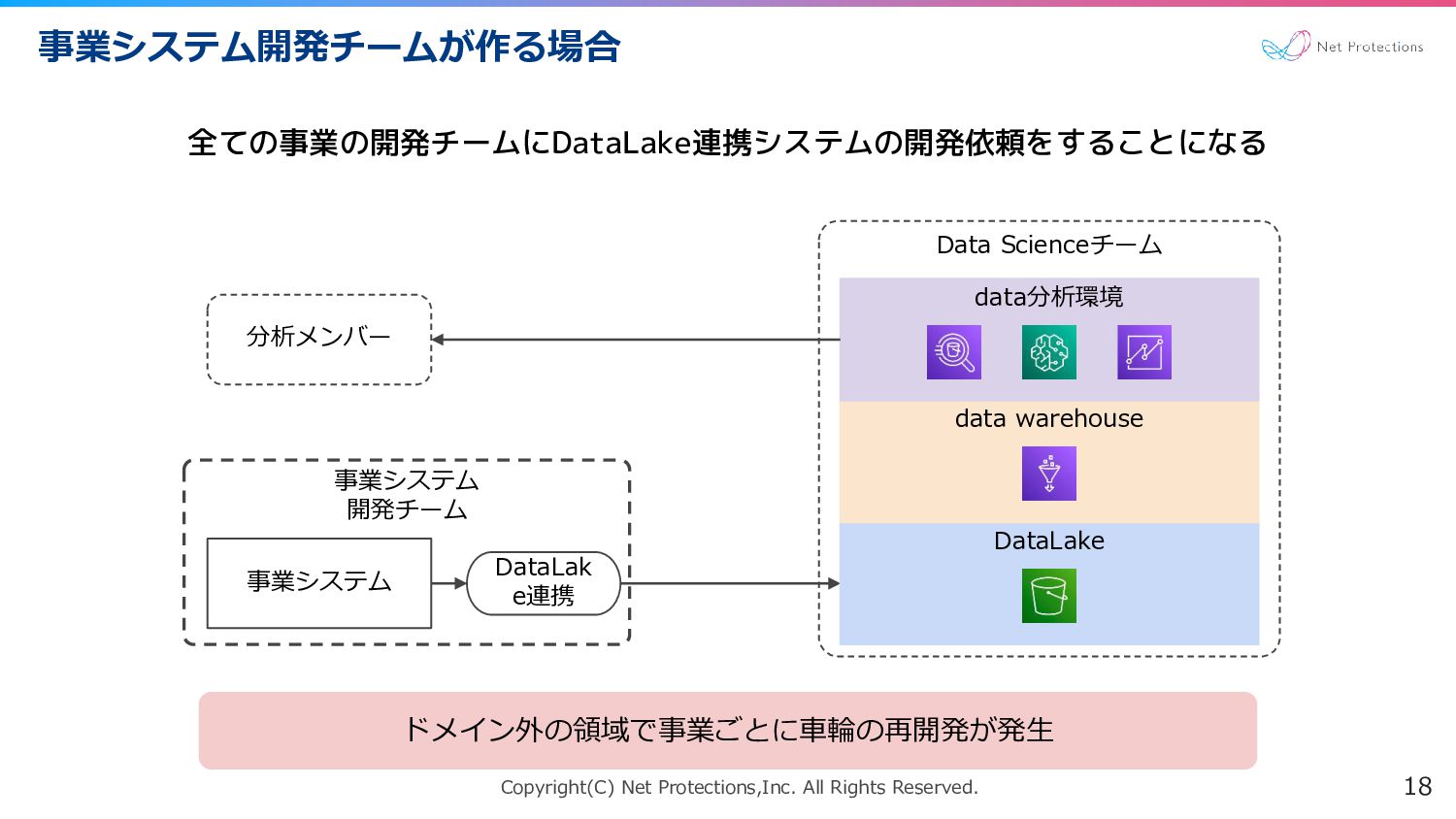
Copyright(C) Net Protections,Inc. All Rights Reserved. 事業システム開発チームが作る場合 18 全ての事業の開発チームにDataLake連携システムの開発依頼をすることになる Data
Scienceチーム 事業システム 開発チーム DataLak e連携 DataLake data warehouse data分析環境 事業システム 分析メンバー ドメイン外の領域で事業ごとに車輪の再開発が発生
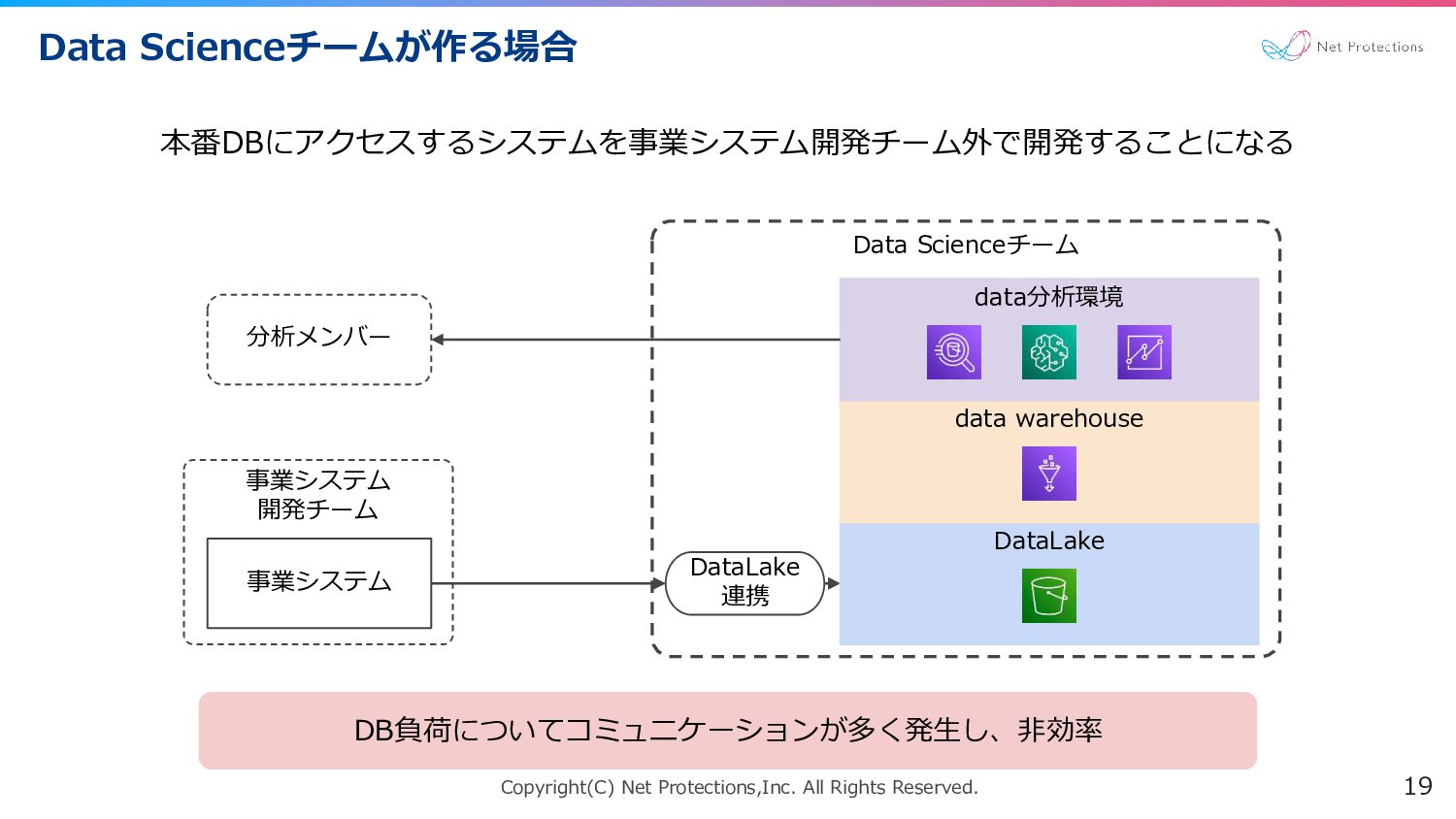
Copyright(C) Net Protections,Inc. All Rights Reserved. Data Scienceチームが作る場合 19 本番DBにアクセスするシステムを事業システム開発チーム外で開発することになる
Data Scienceチーム 事業システム 開発チーム DataLake 連携 DataLake data warehouse data分析環境 事業システム 分析メンバー DB負荷についてコミュニケーションが多く発生し、非効率
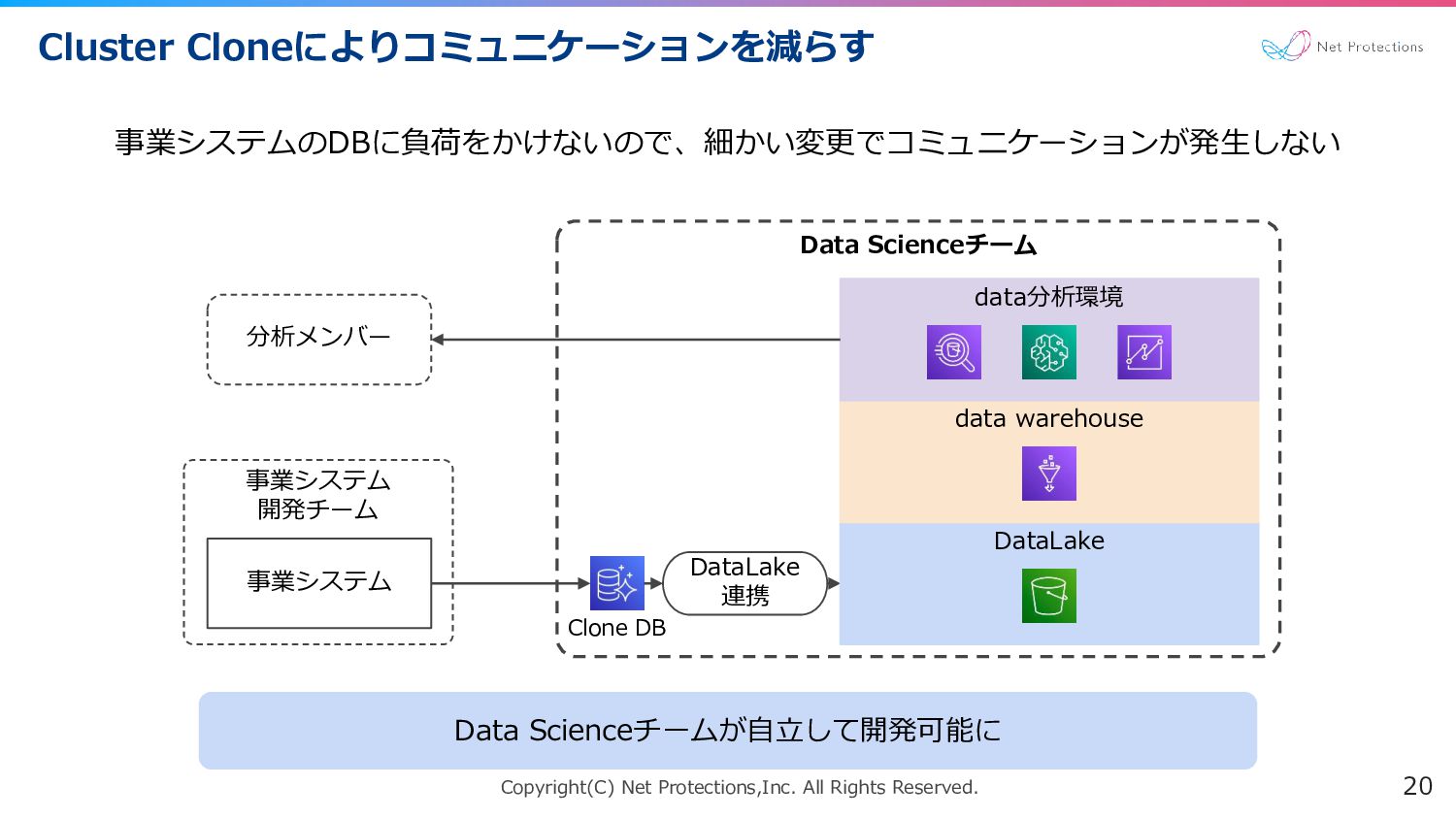
Copyright(C) Net Protections,Inc. All Rights Reserved. Cluster Cloneによりコミュニケーションを減らす 20 事業システムのDBに負荷をかけないので、細かい変更でコミュニケーションが発生しない
Data Scienceチーム 事業システム 開発チーム DataLake 連携 DataLake data warehouse data分析環境 事業システム 分析メンバー Data Scienceチームが自立して開発可能に Clone DB
Copyright(C) Net Protections,Inc. All Rights Reserved. まとめ 21
Copyright(C) Net Protections,Inc. All Rights Reserved. 今日のまとめ 22 Aurora Cluster
Clone • 独立したDBなので、本番DBへの影響をほぼ0でDataLake連携システムが作れる • Clone作成時にデータのコピーをしないため、高速+低コスト Copy-on-write Protocol • できるだけデータは共有しつつ、DB間の影響をなくす仕組み • 書き込みのあったPageをコピーしてから書き込む DataLake連携システムを誰が作るのか? • 事業システム開発チームとData Scienceチームの間に落ちがちなタスク • 本番DBへの影響が少なくなることで、Data Scienceチームが独立して作りやす い
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}