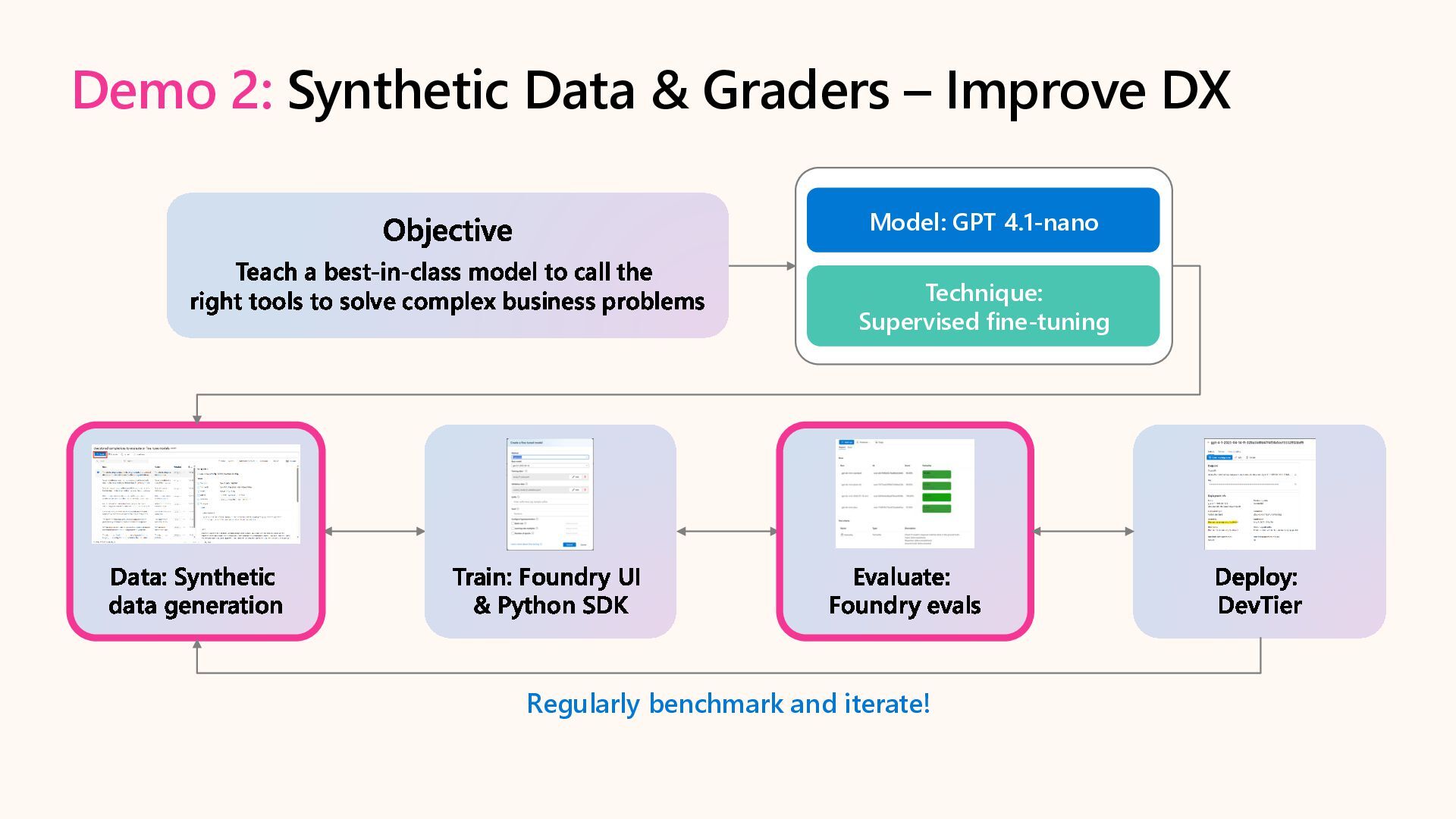
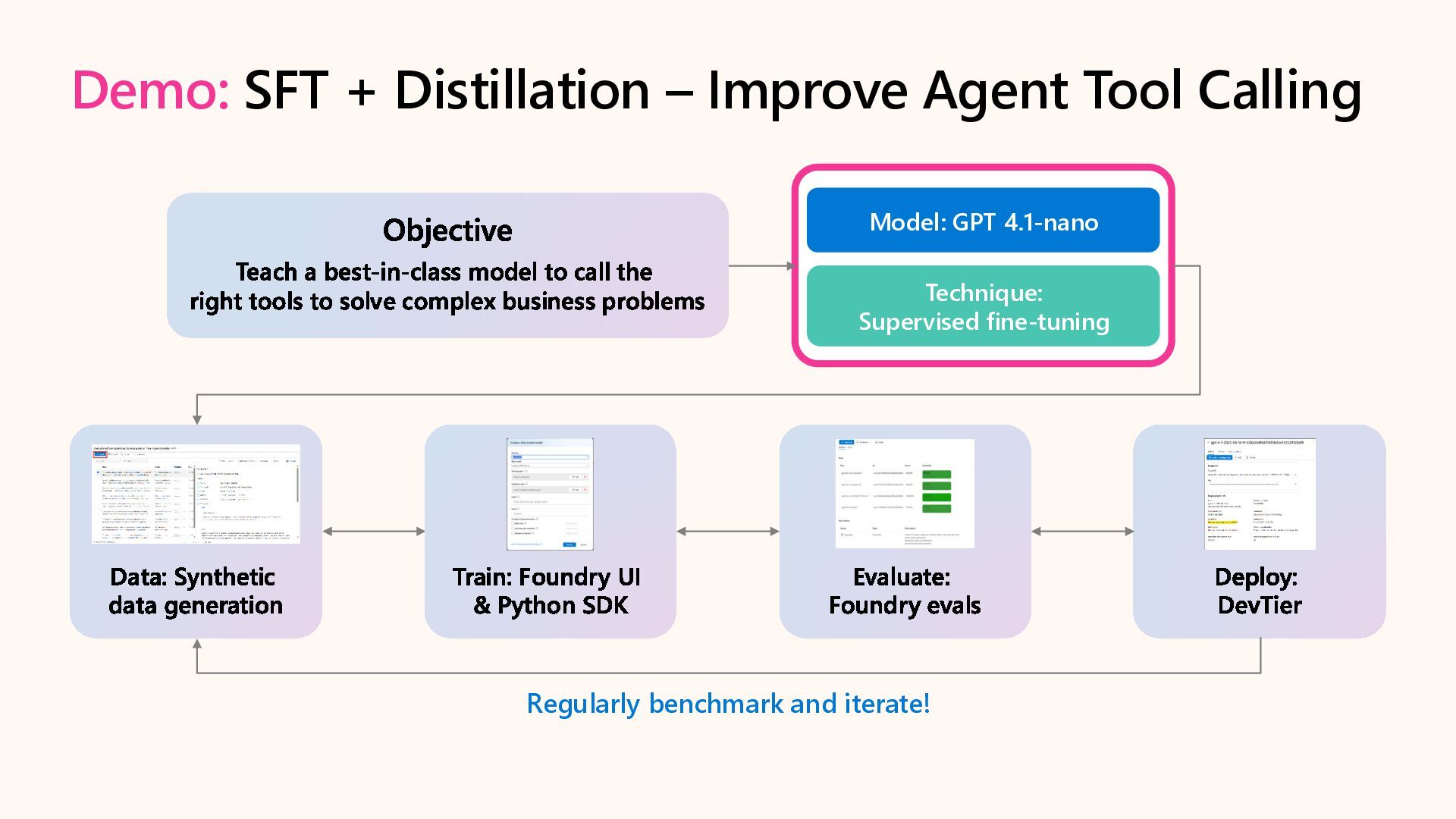
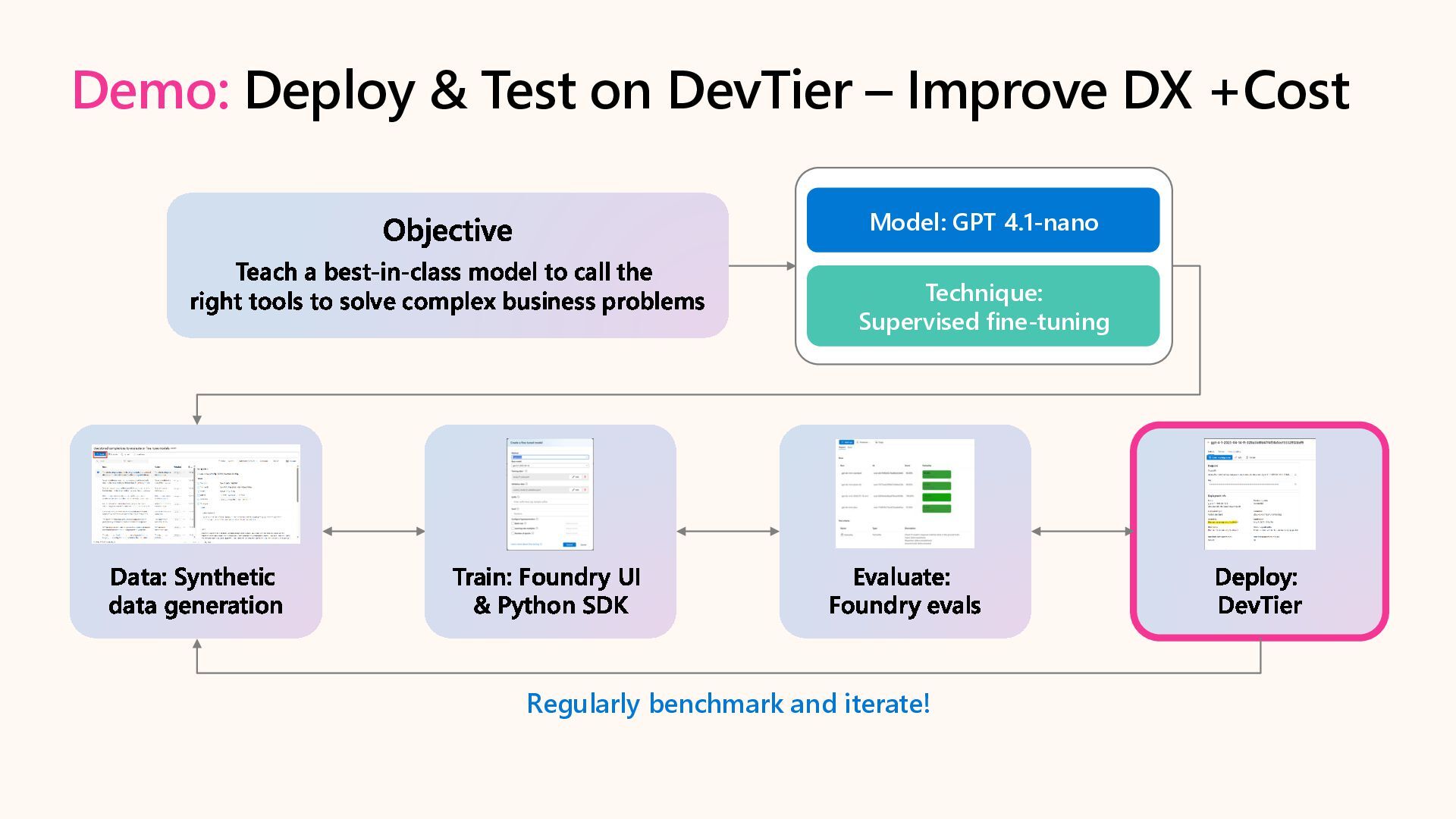
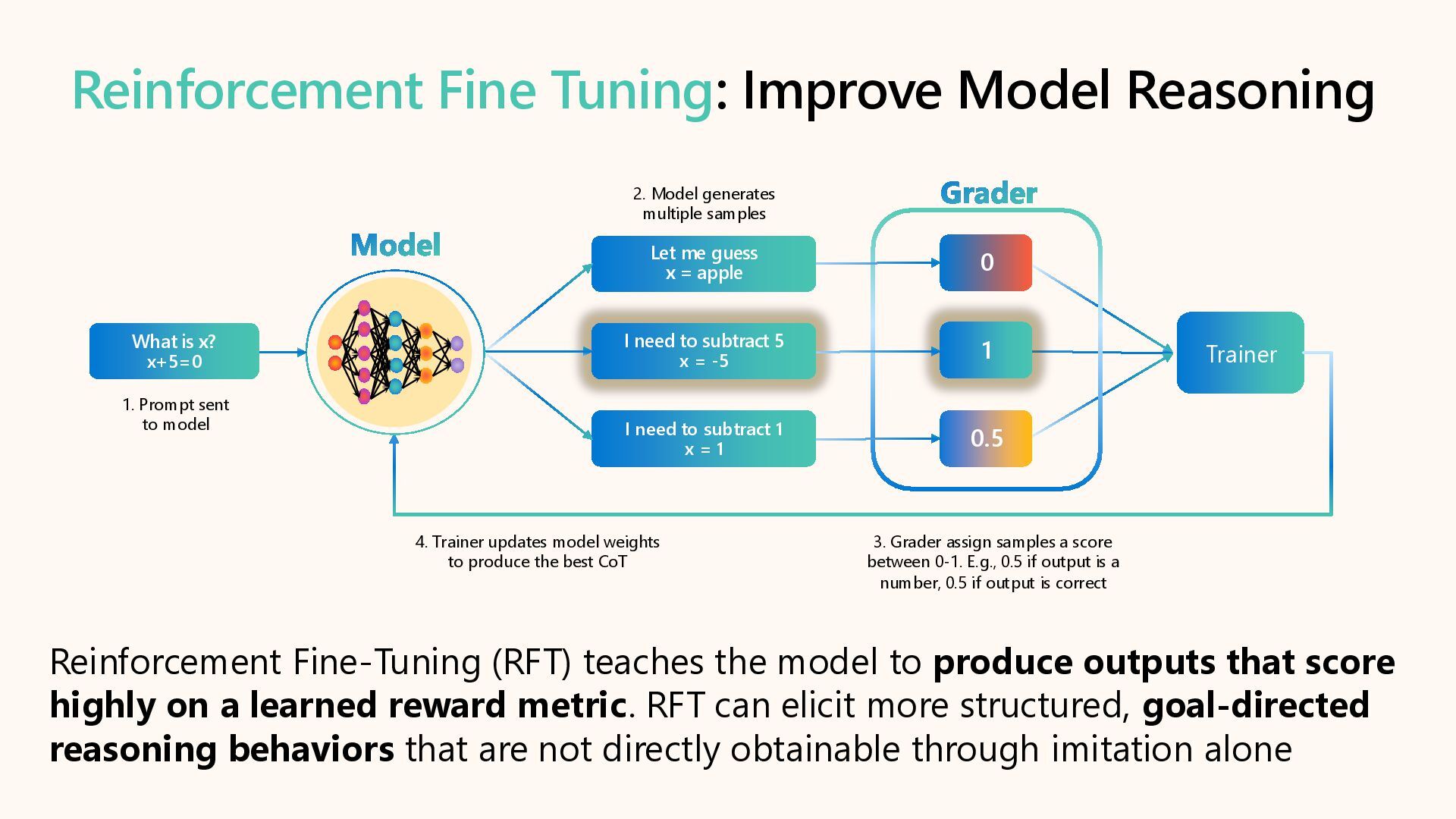
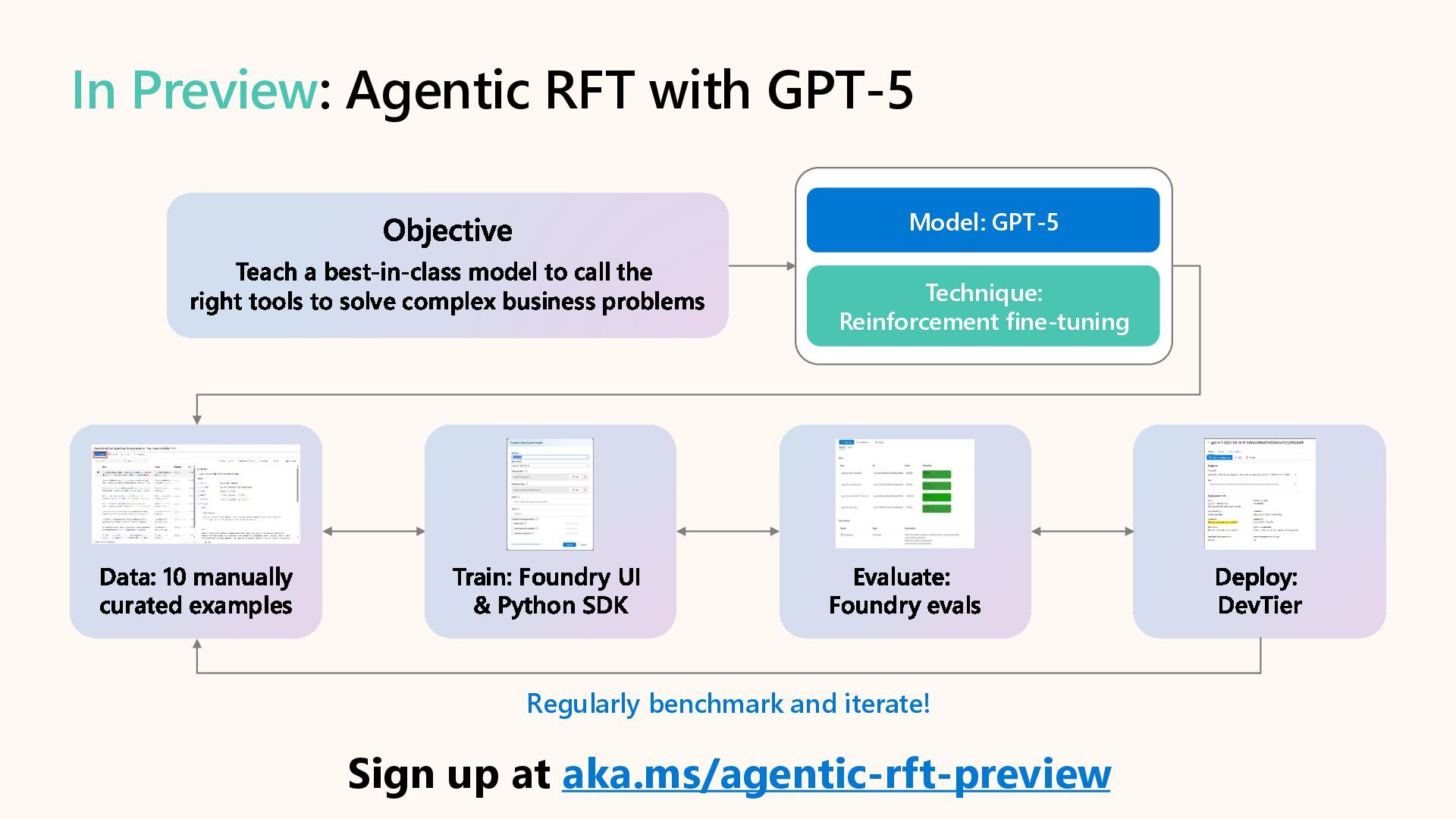
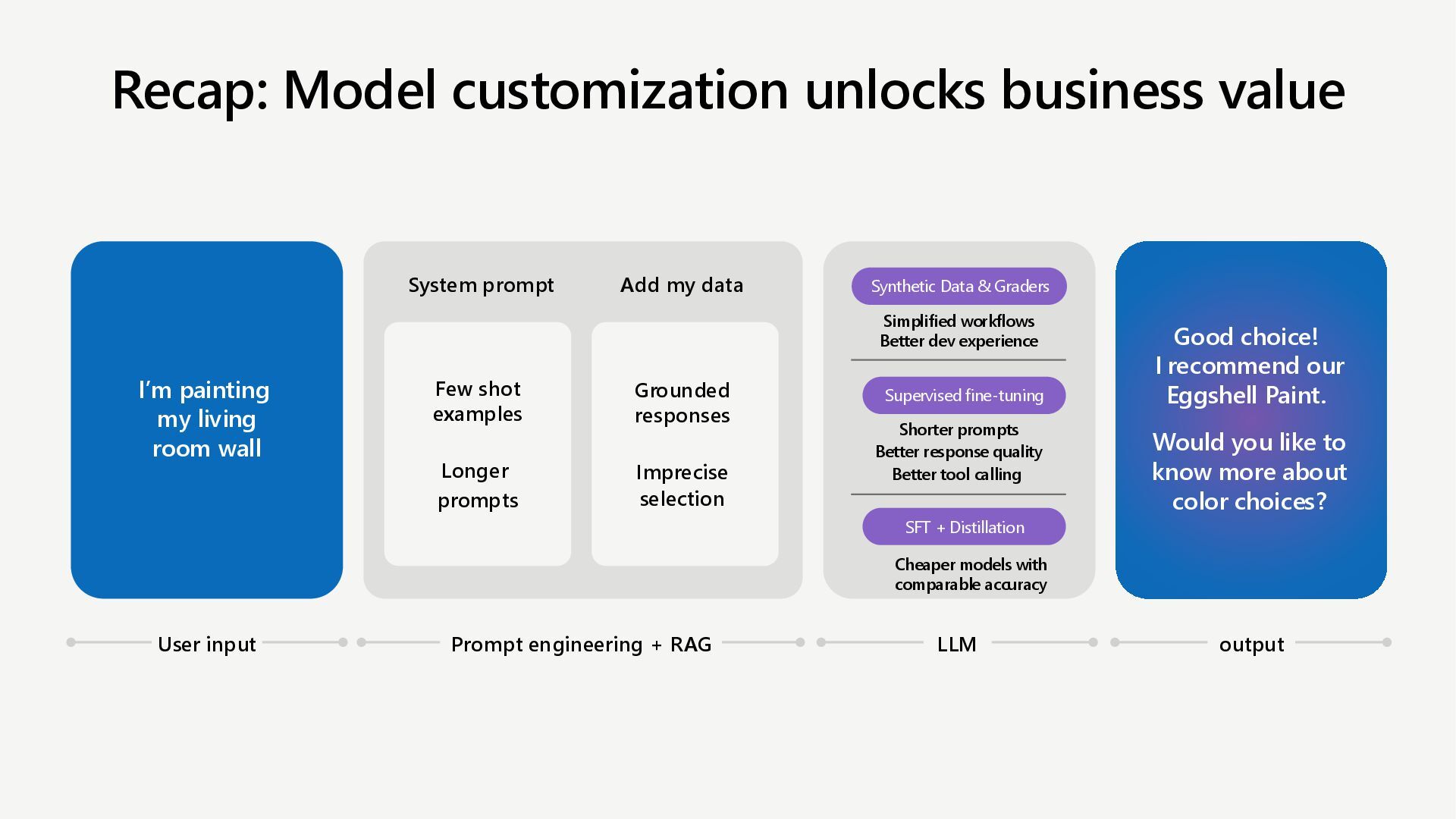
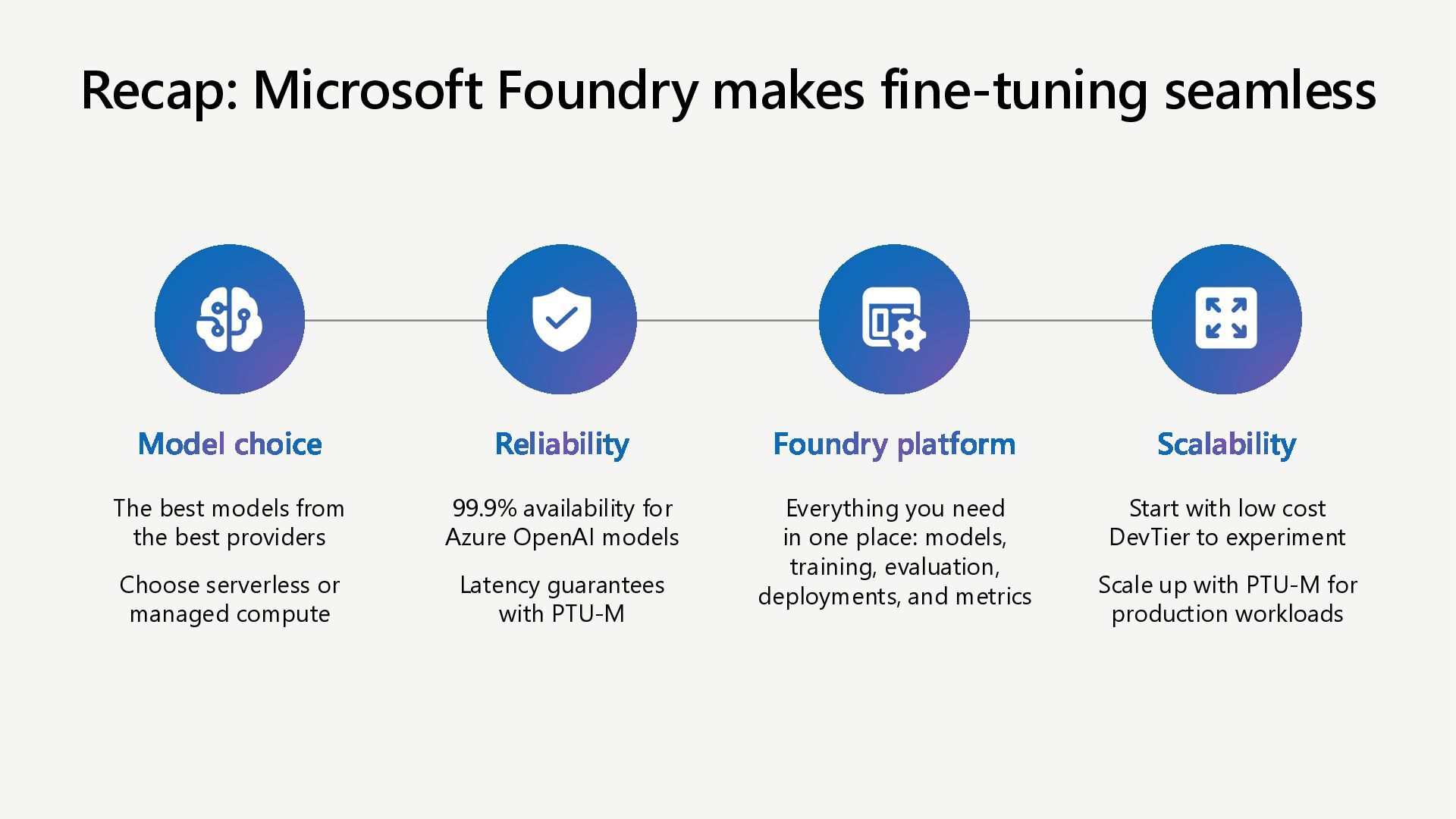
Customize AI models and optimize performance for agentic AI scenarios with targeted fine-tuning in Microsoft Foundry. Learn to adapt agent tone with SFT, reduce cost & latency with Distillation, and enhance developer experience with synthetic data generation, custom evaluation, and developer tier.
Delivered at AI Tour NYC 2026
https://aitour.microsoft.com/flow/microsoft/nyc26/sessioncatalog/page/sessioncatalog/session/1760572081812001YGbG
{kind=link}
{kind=link}
{kind=link}
{kind=link}
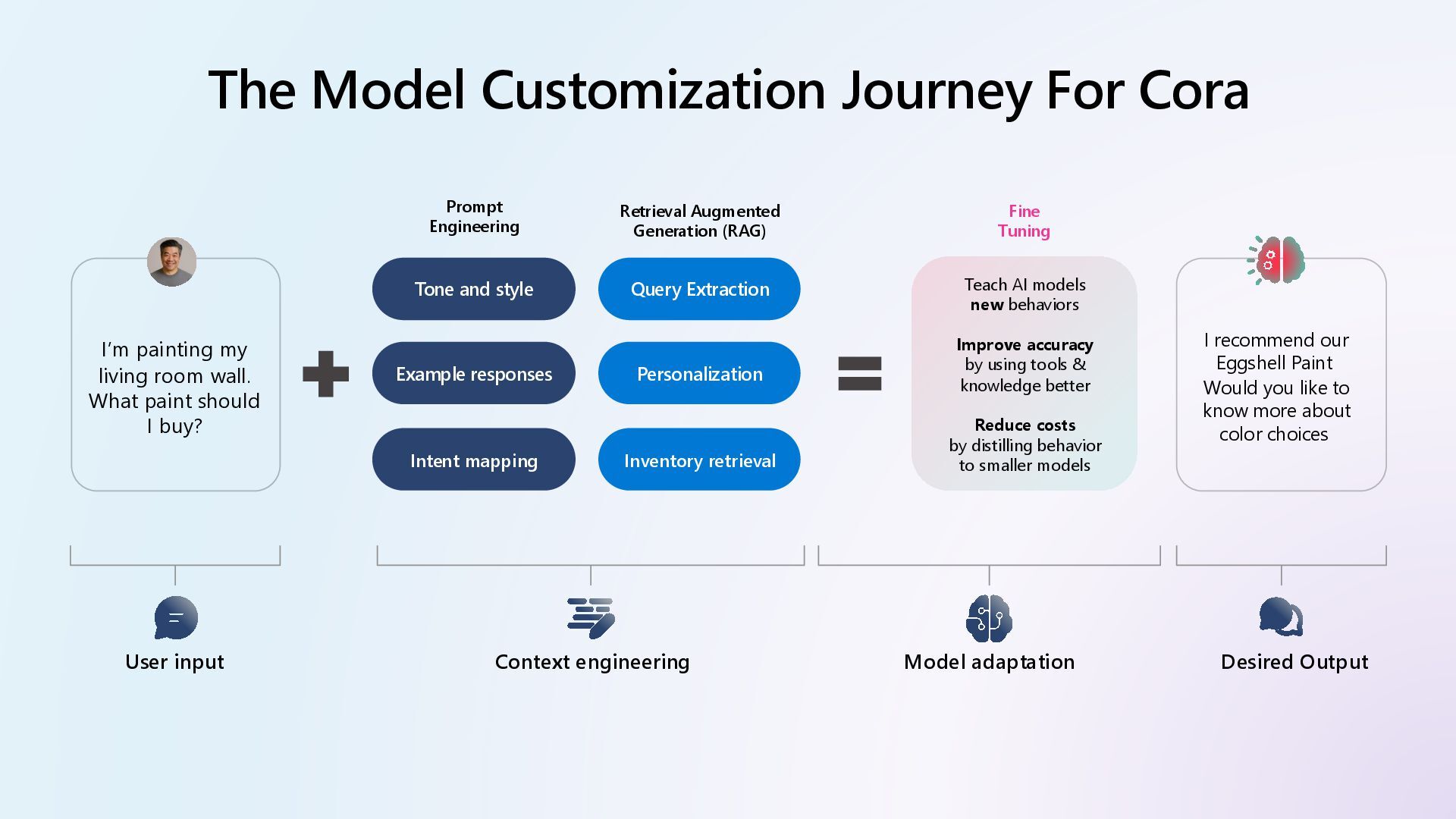{kind=link}
{kind=link}
{kind=link}
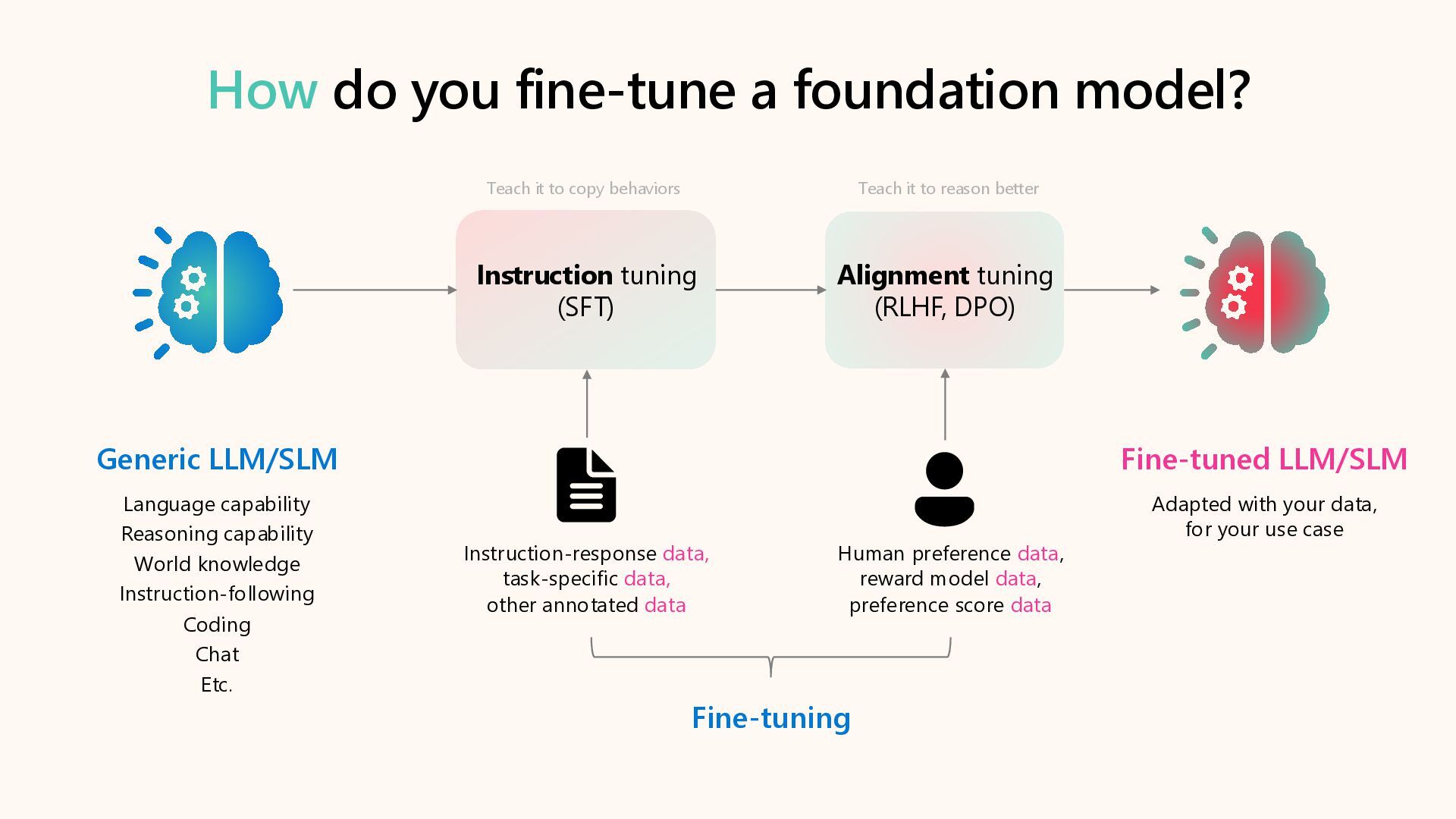{kind=link}
{kind=link}
{kind=link}
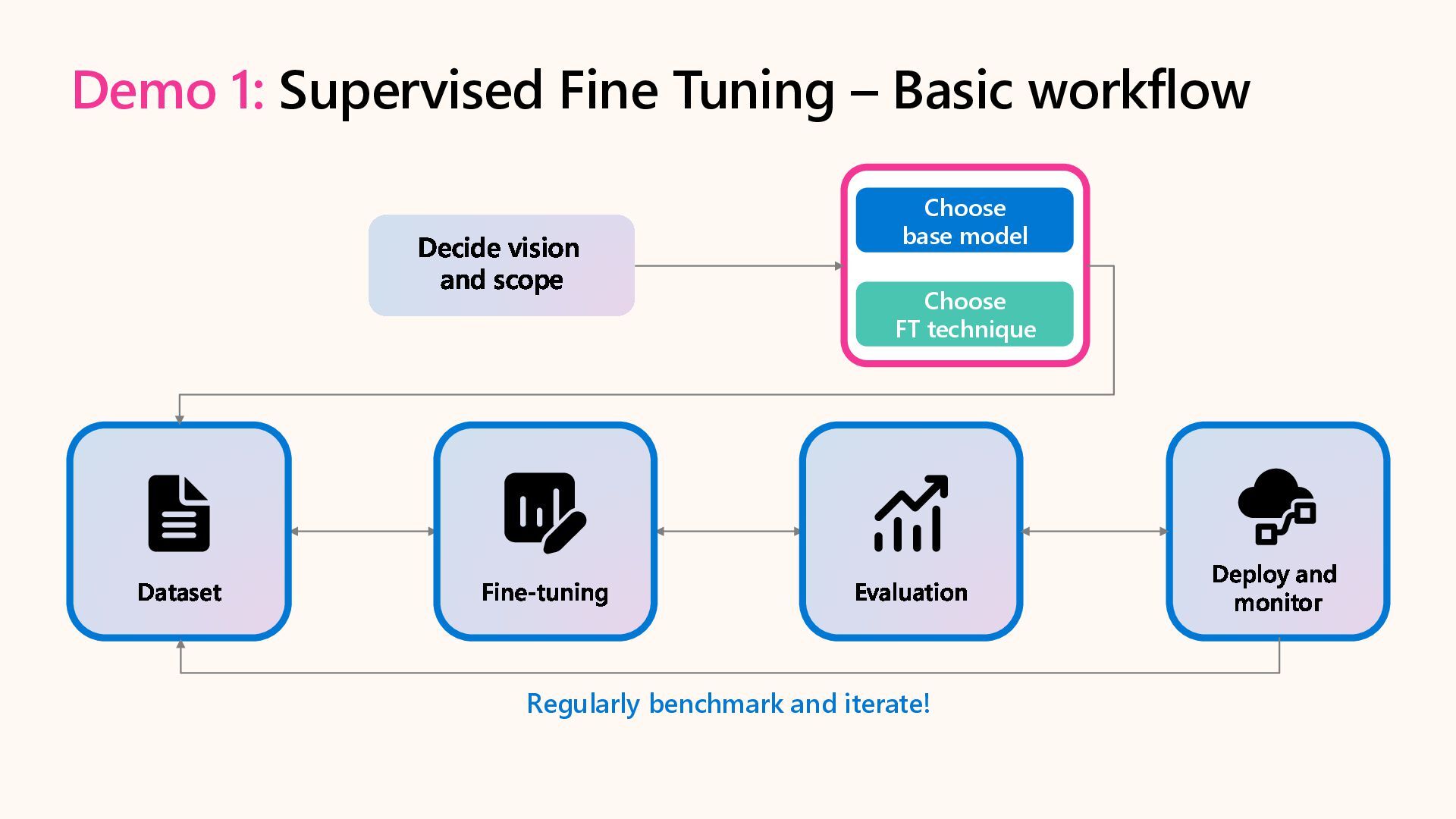{kind=link}
{kind=link}
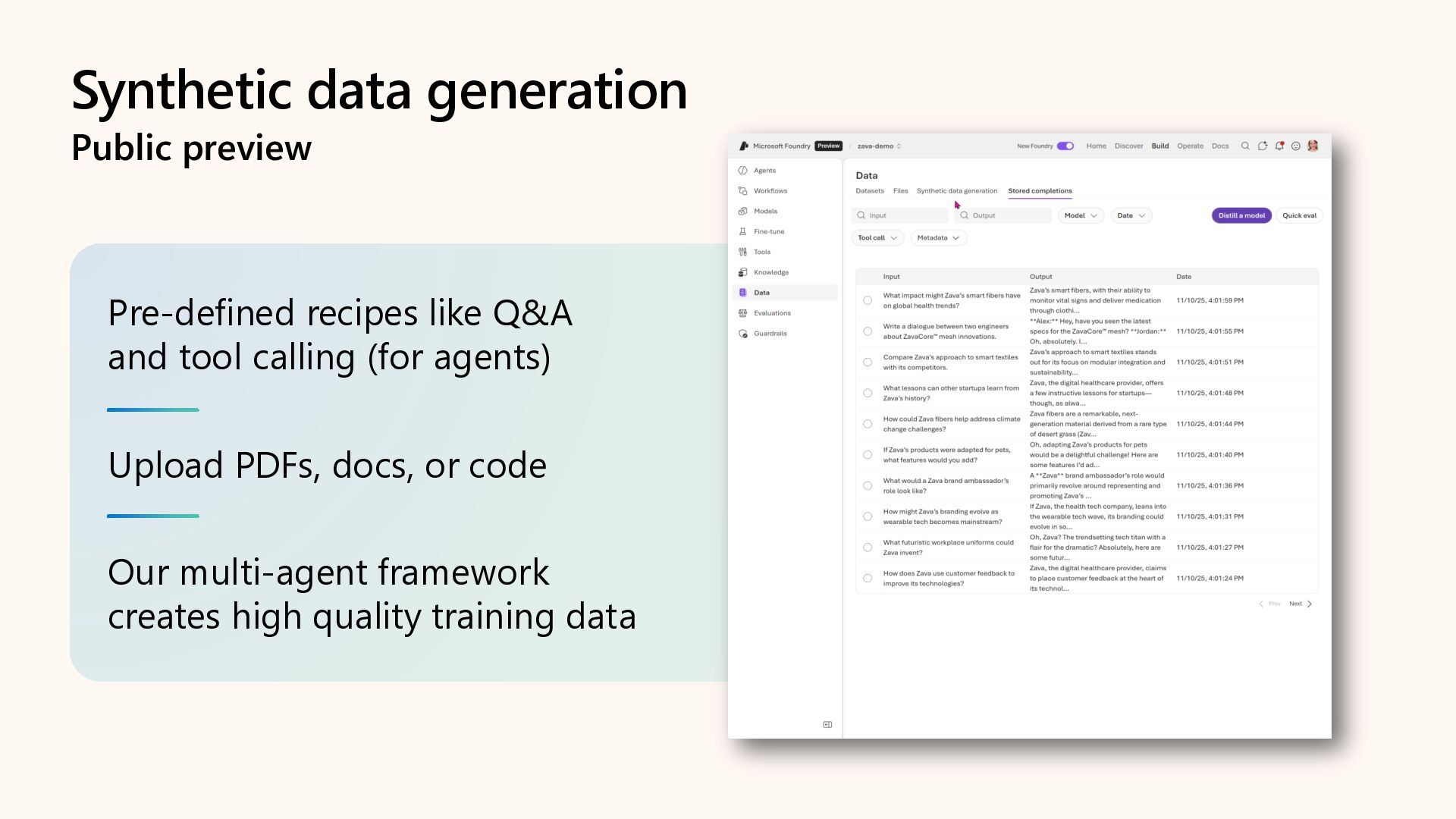{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}