Share
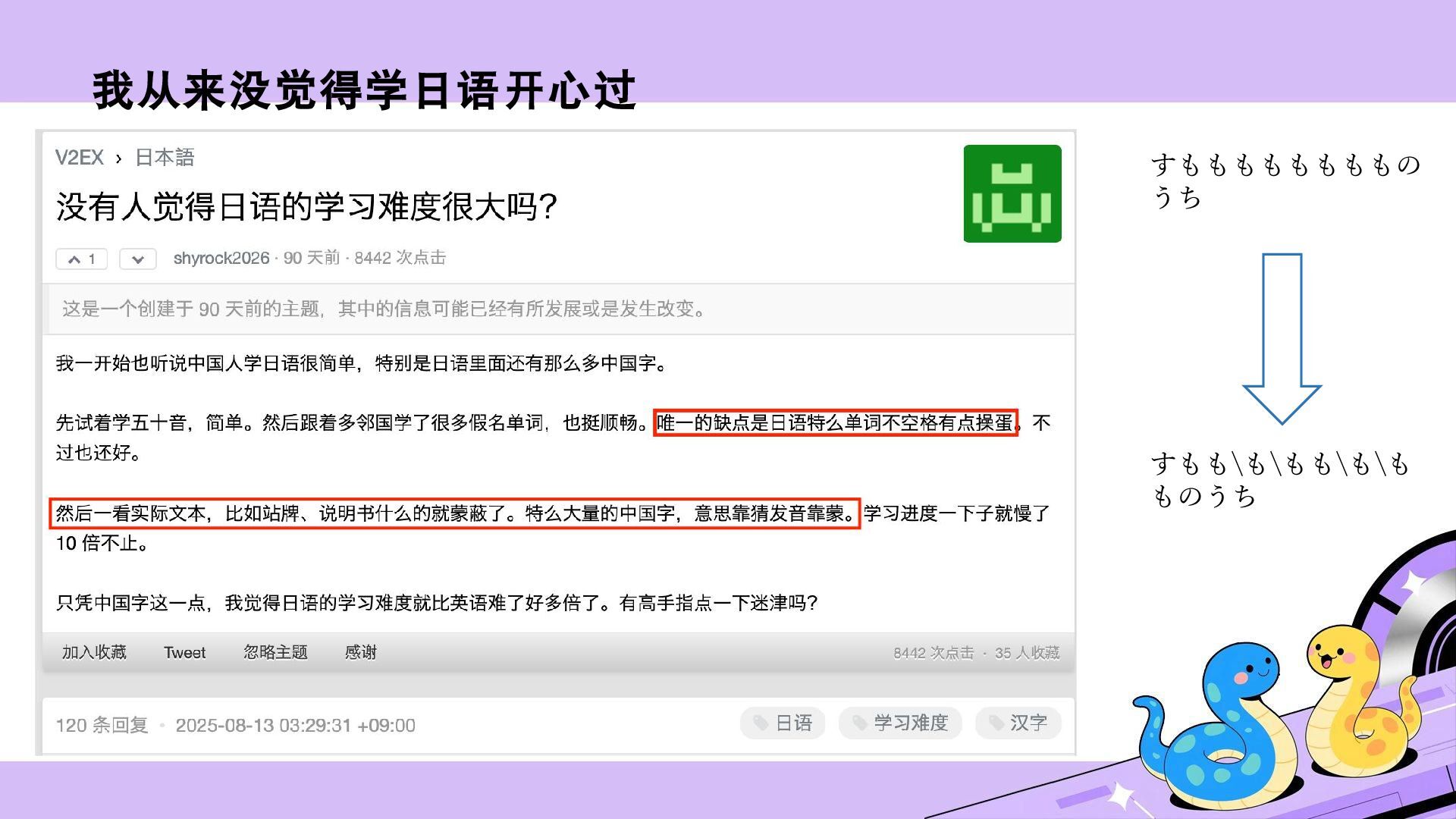
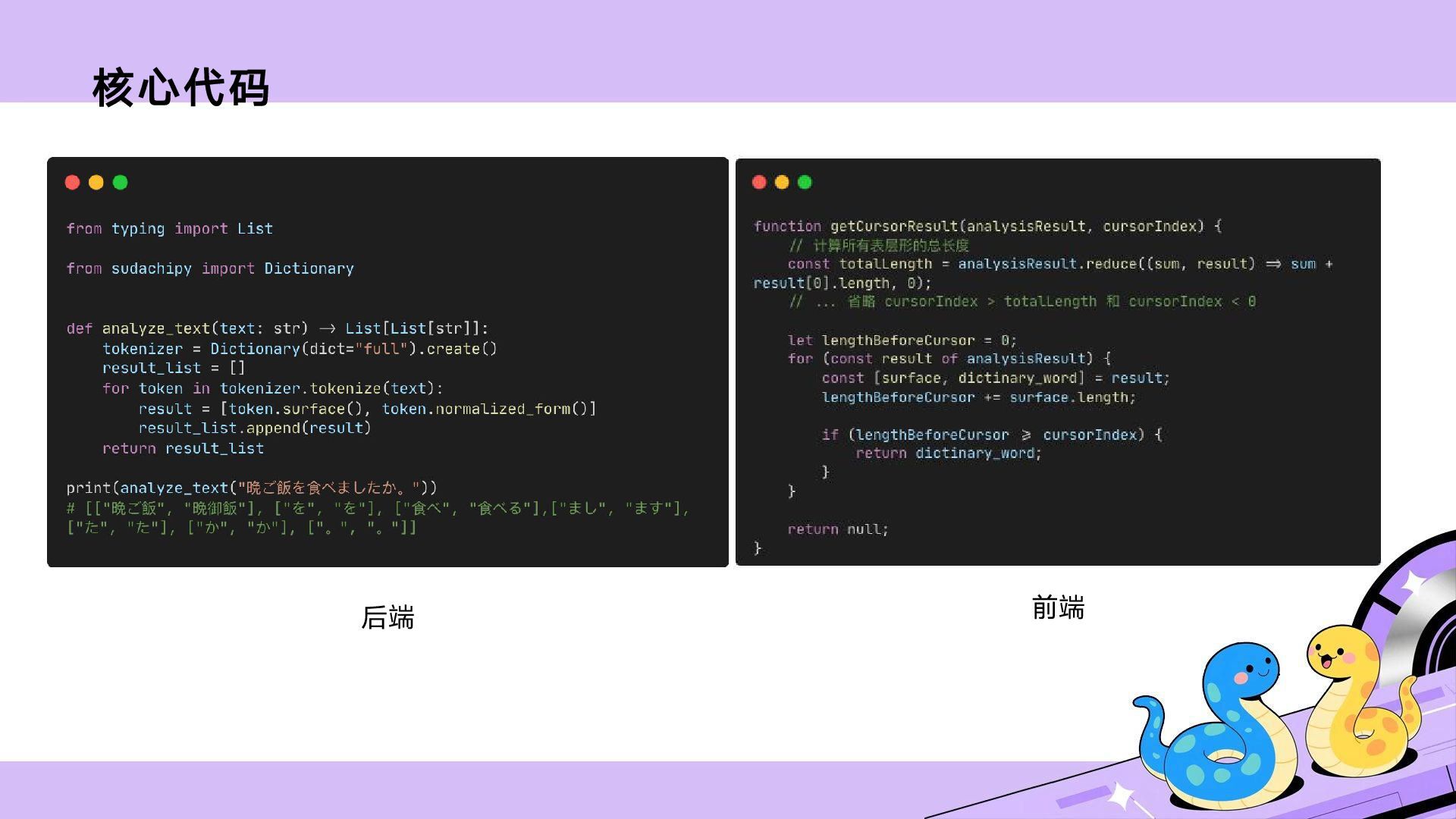
和英语不同,日语不会用空格区分单词,再加上单词变形复杂,初学者在刚开始泛读时往往要花费大量时间才能准确判断一句话中想查单词的原型。通过形态素解析器分析文本,我们其实能够获取单词原型,这可以有效提高泛读效率。但是,现有的解析器处理字幕、漫画和 Galgame 等口语化的文本时会出现较为明显的未登录词(Out-of-Vocabulary, OOV)问题。本次分享除了介绍 Python 调用 Sudachi 的方法,还会重点介绍如何解决这个问题。
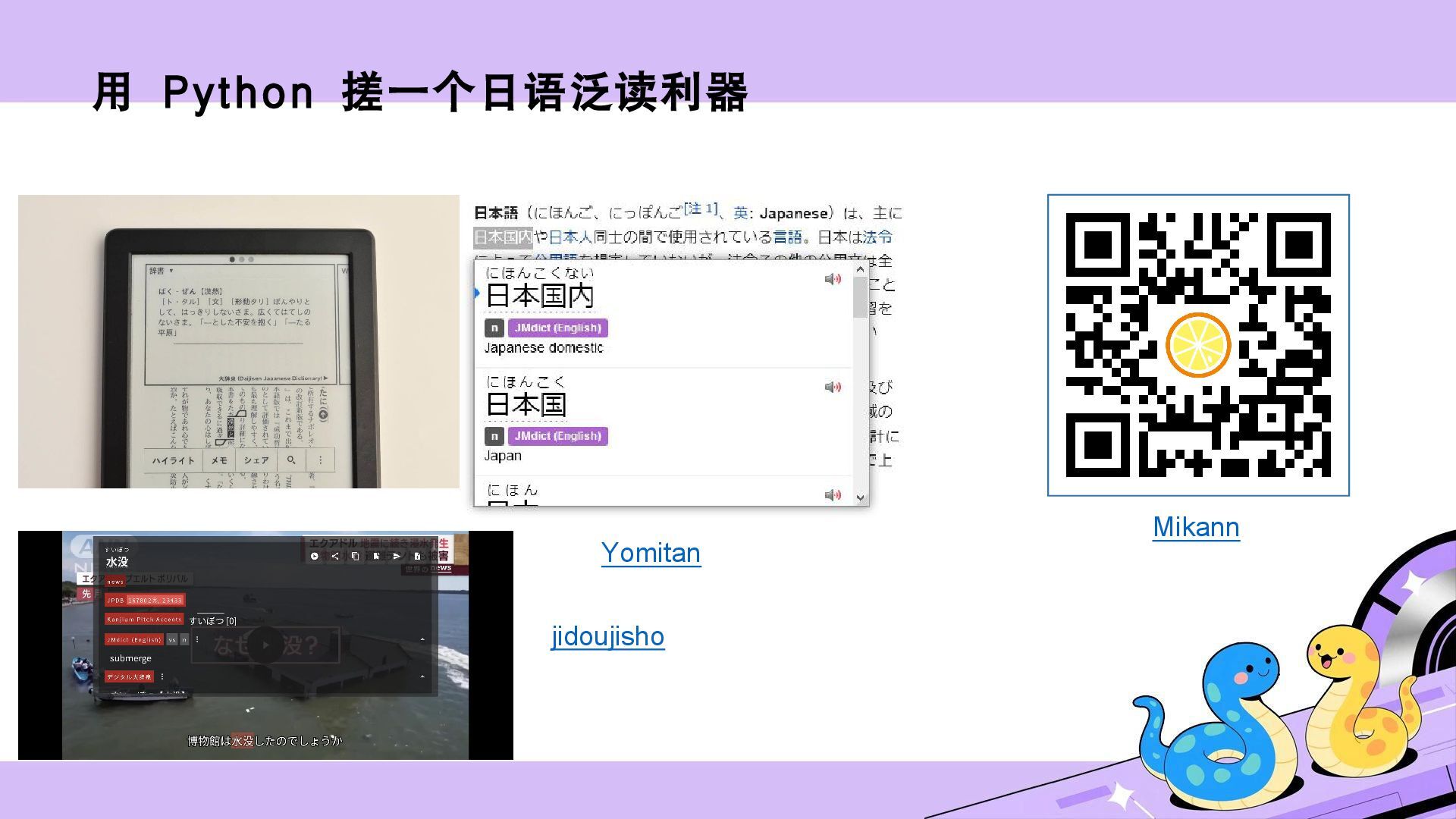
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![未登录词测试用例 正确的解析结果:[['なん', '何'], ['で', 'で'], ['『', '『'], ['春日影', '春日影'], ['』',](https://files.speakerdeck.com/presentations/5be409dbeb8842929ade0d8802004987/slide_6.jpg){kind=link}
{kind=link}
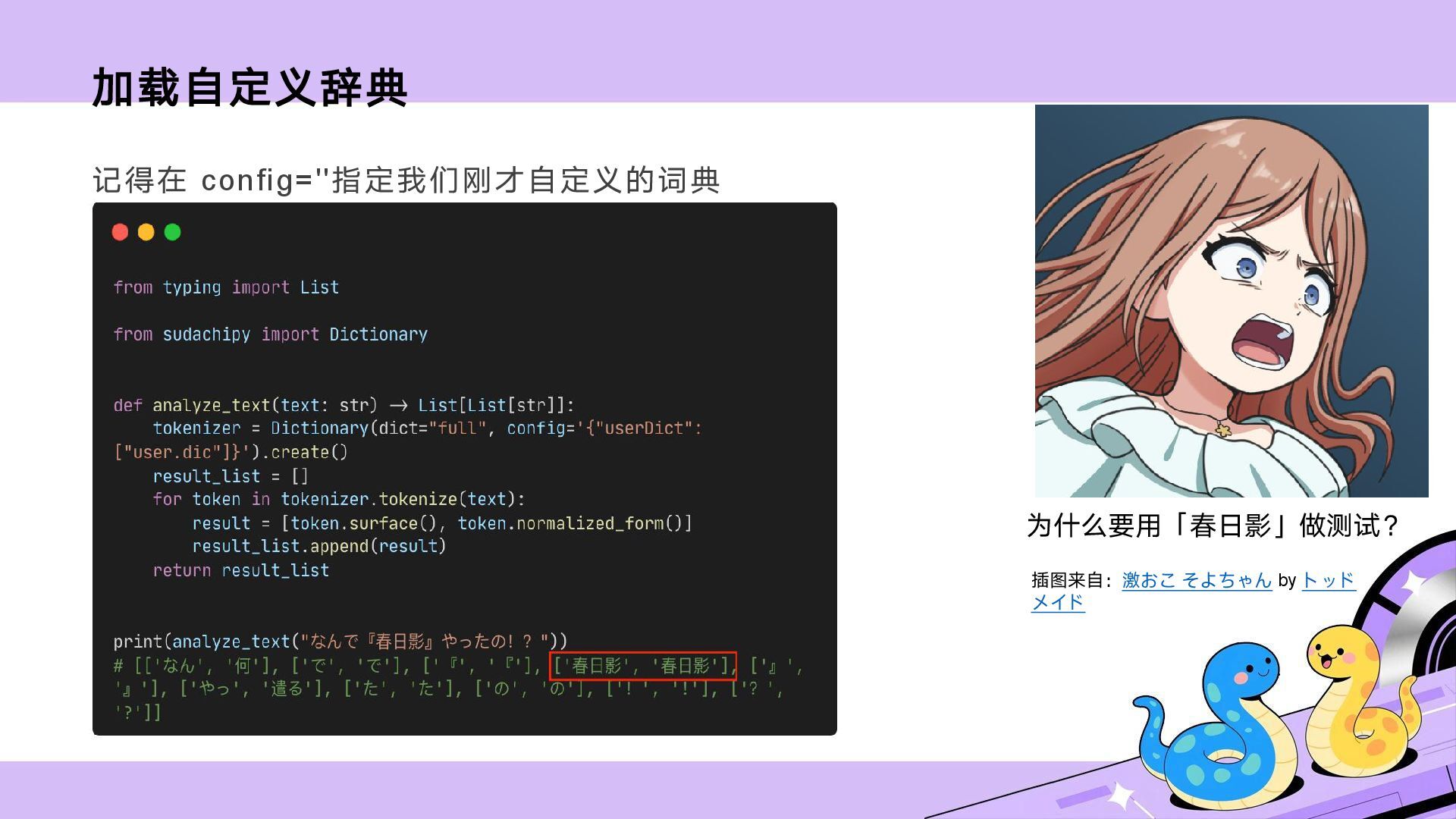{kind=link}
![词性不是名词如何登录 翻译:【短语】《动词「やる」+过去助动词 「た」,意为「做到了、成功了」》用于表达事情 按预期发展或成功完成时发出的感叹。“好耶,是 逆转本垒打啊!” [['なん', '何'], ['で', 'で'], ['『',](https://files.speakerdeck.com/presentations/5be409dbeb8842929ade0d8802004987/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
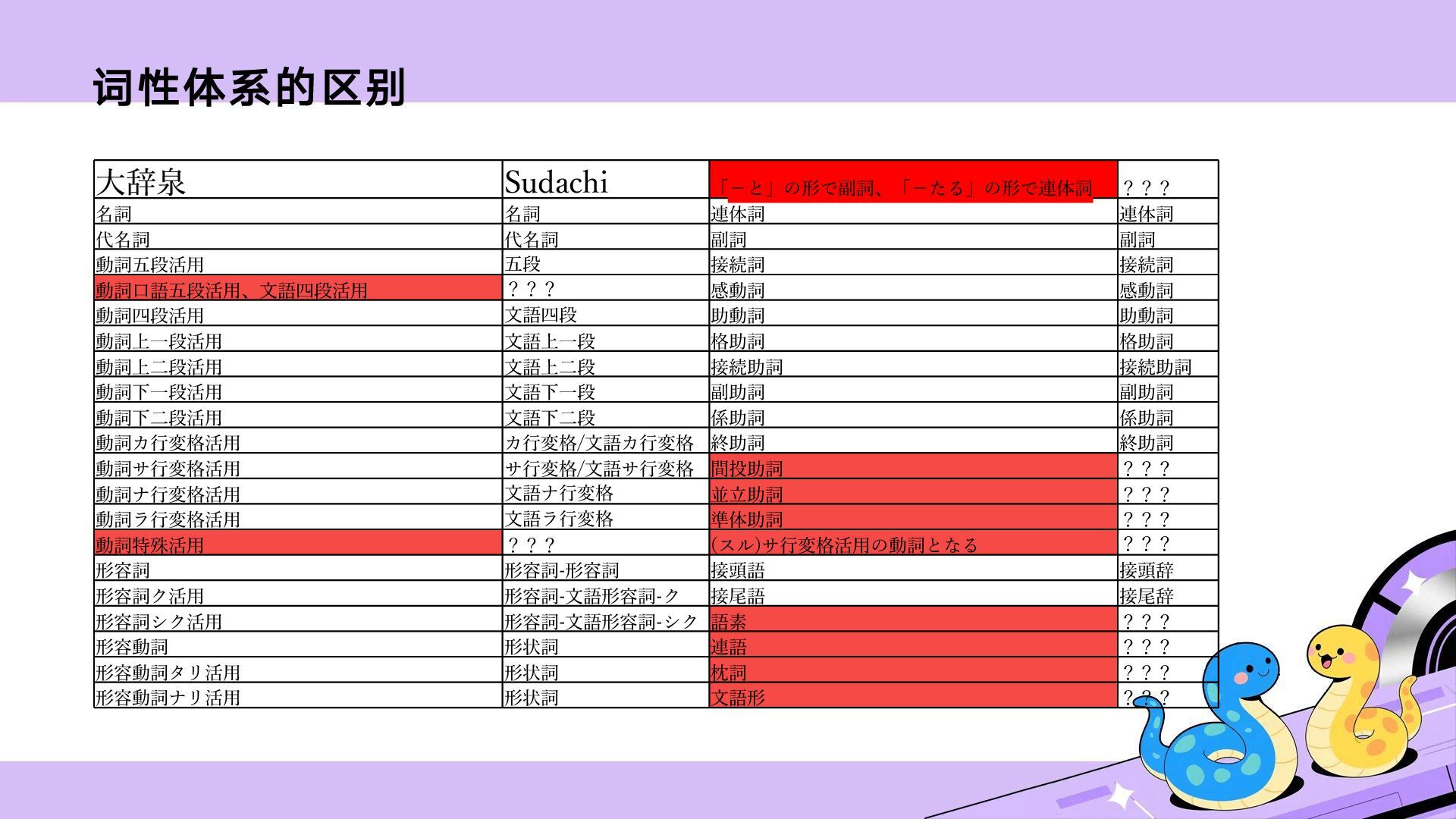{kind=link}
{kind=link}
{kind=link}