★ この資料は「秋田大学 令和6年情報システム研究会」(2024/9/24)の発表資料です ★
ChatGPT に代表される「ことばを学んだ AI モデル」が、一般の人々にも爆発的に普及して、ブームになっています。こうしたモデル(LLM)のうち、誰でもダウンロードして自由に使える AI モデルを「オープンアクセスLLM」と呼んでいます。
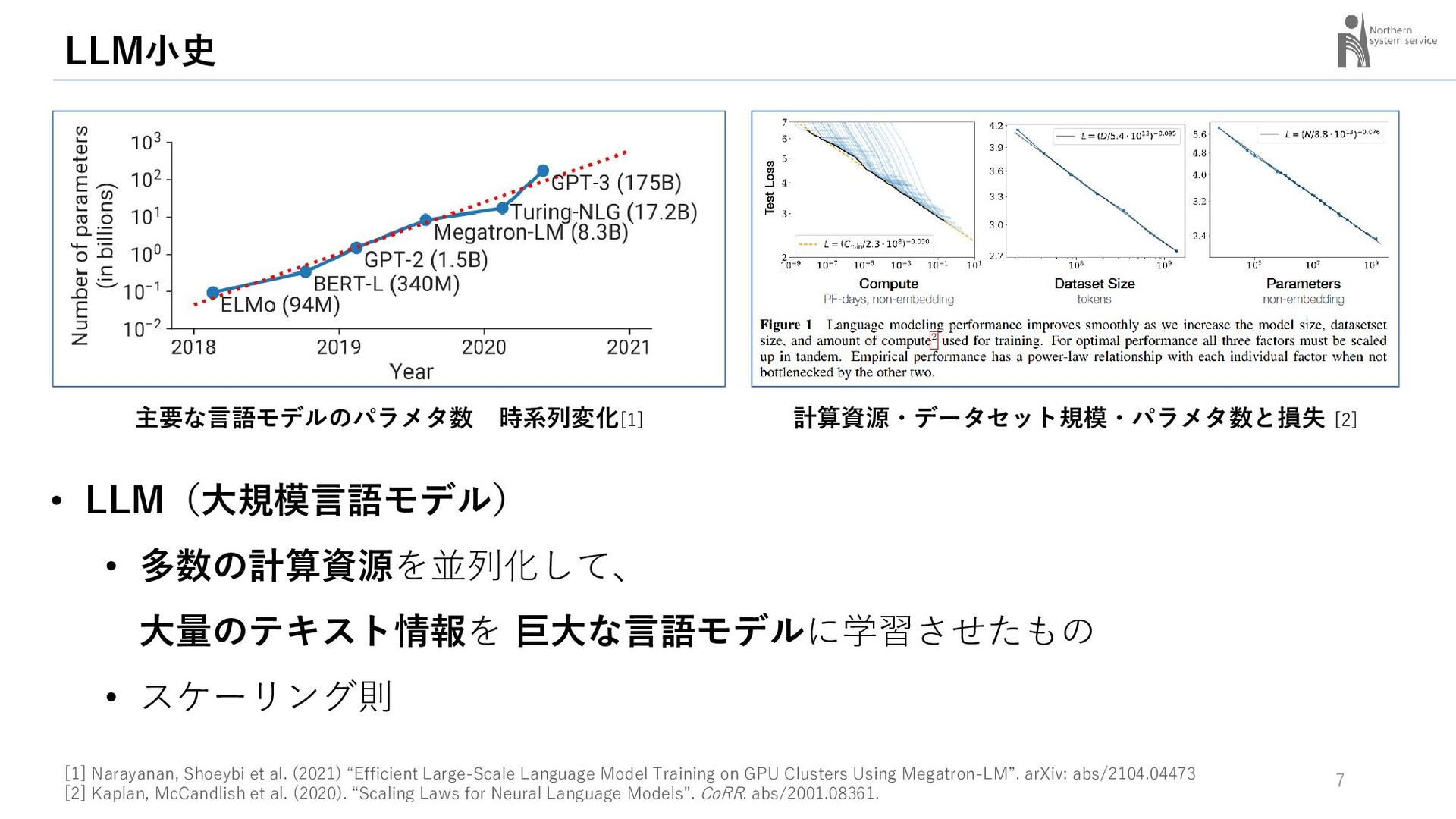
当社では、このなかでも「日本語が話せるオープンアクセスLLM」に焦点をあてて、日本語性能とモデルの大きさ・学習データ量の関係、量子化による性能変化、最近の動向について調査を行いました。その成果をご紹介します。
発表者:佐々木 優興(株式会社ノーザンシステムサービス 研究開発部)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
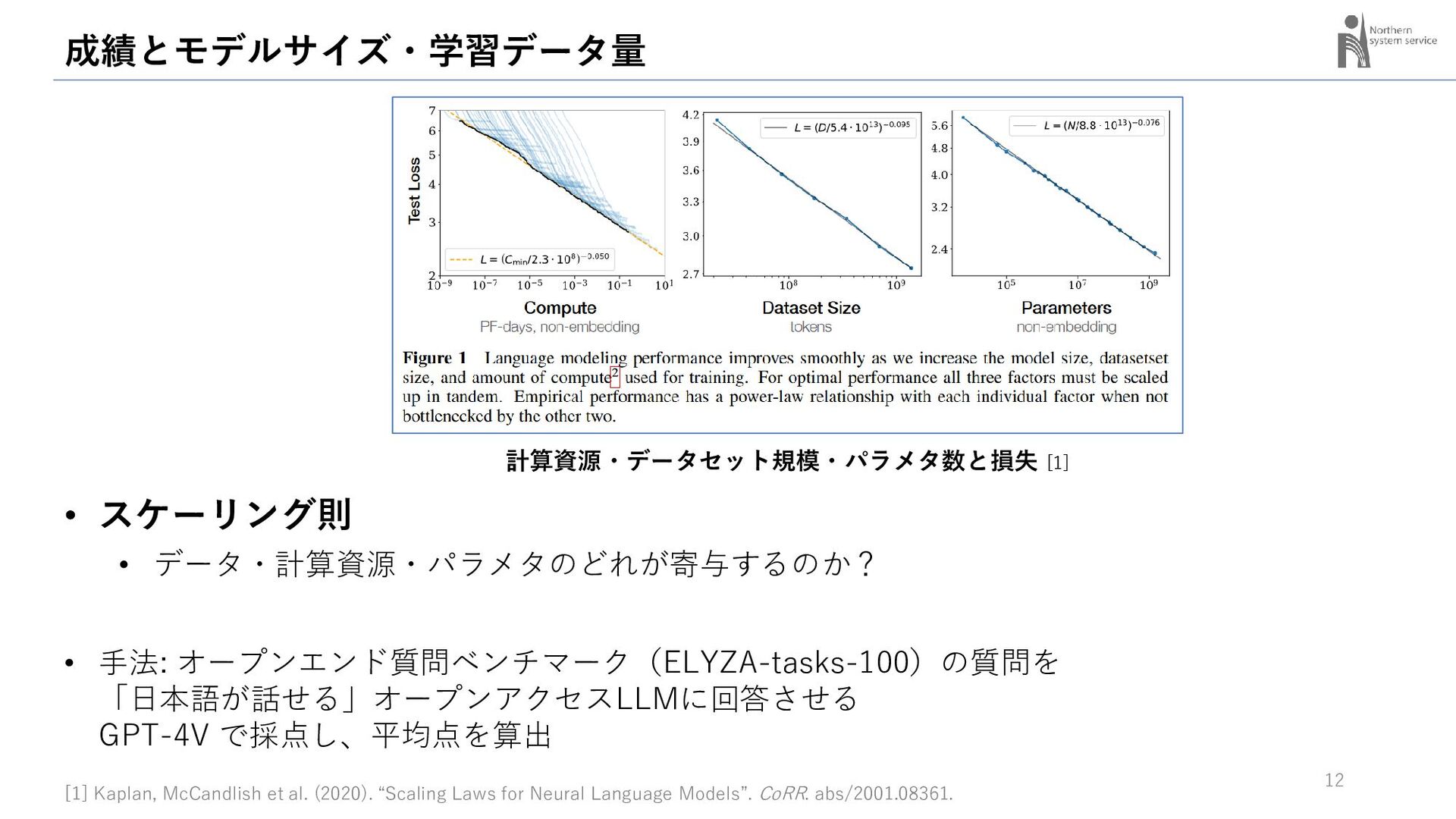{kind=link}
{kind=link}
{kind=link}
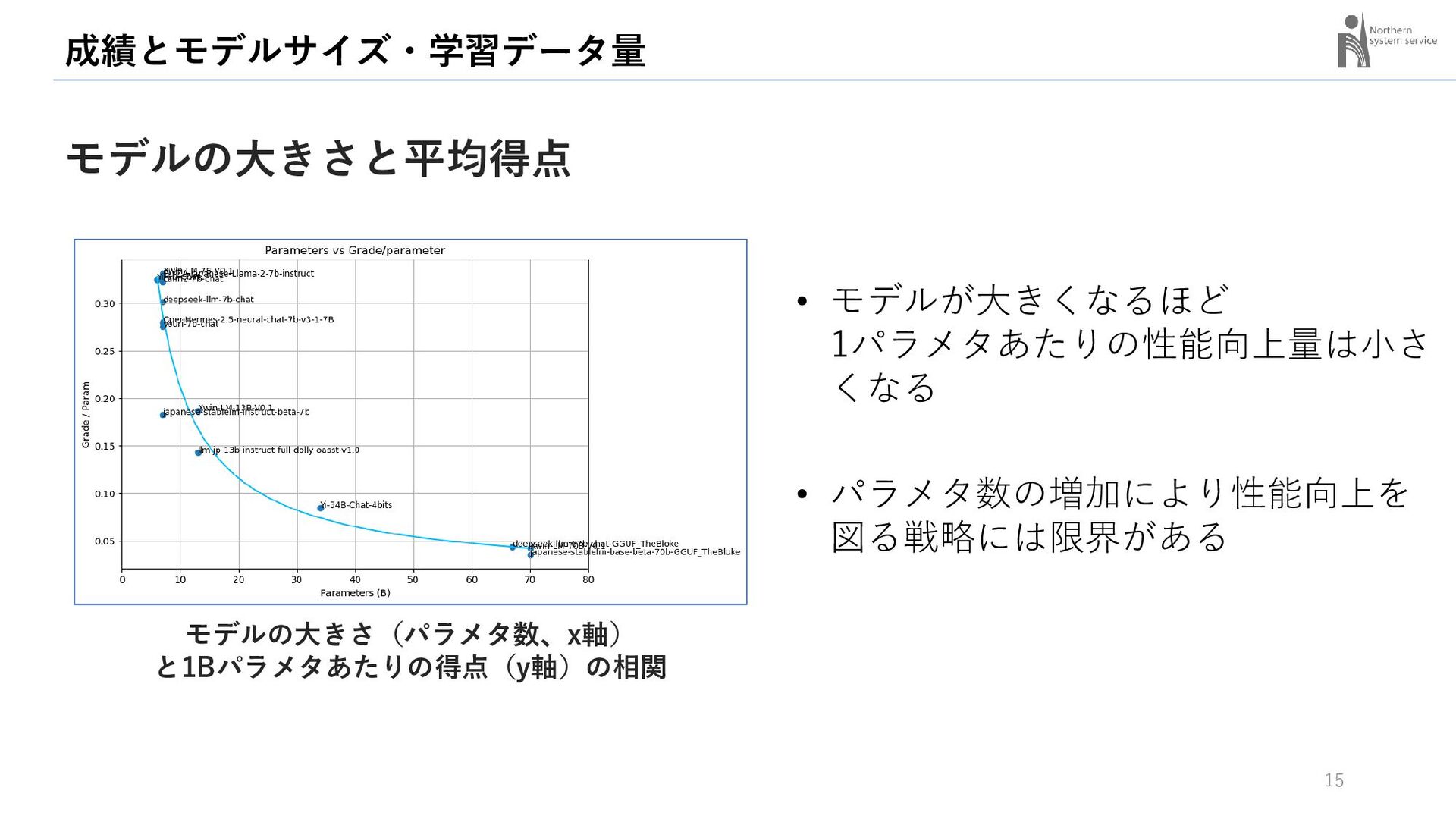{kind=link}
{kind=link}
{kind=link}
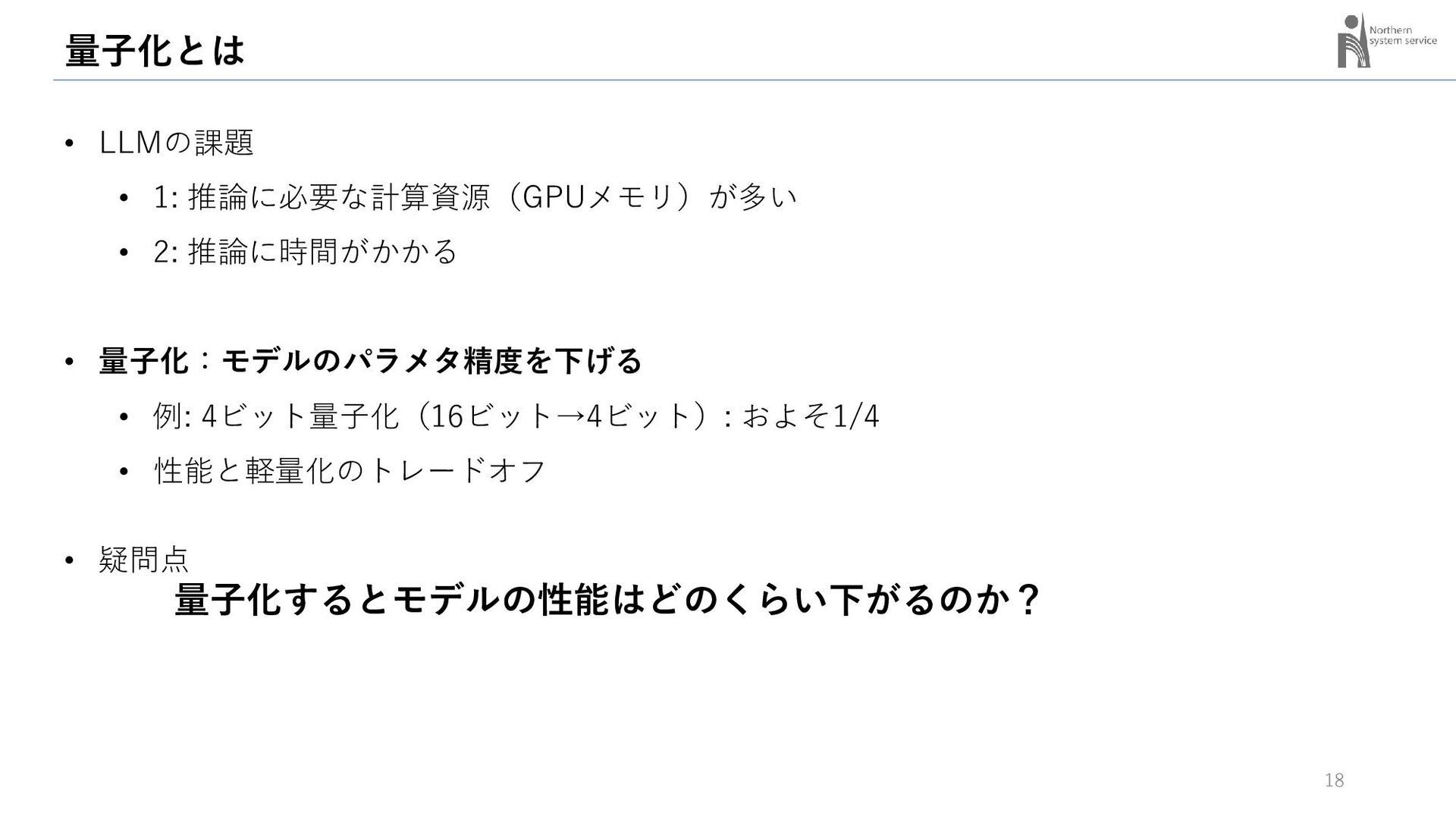{kind=link}
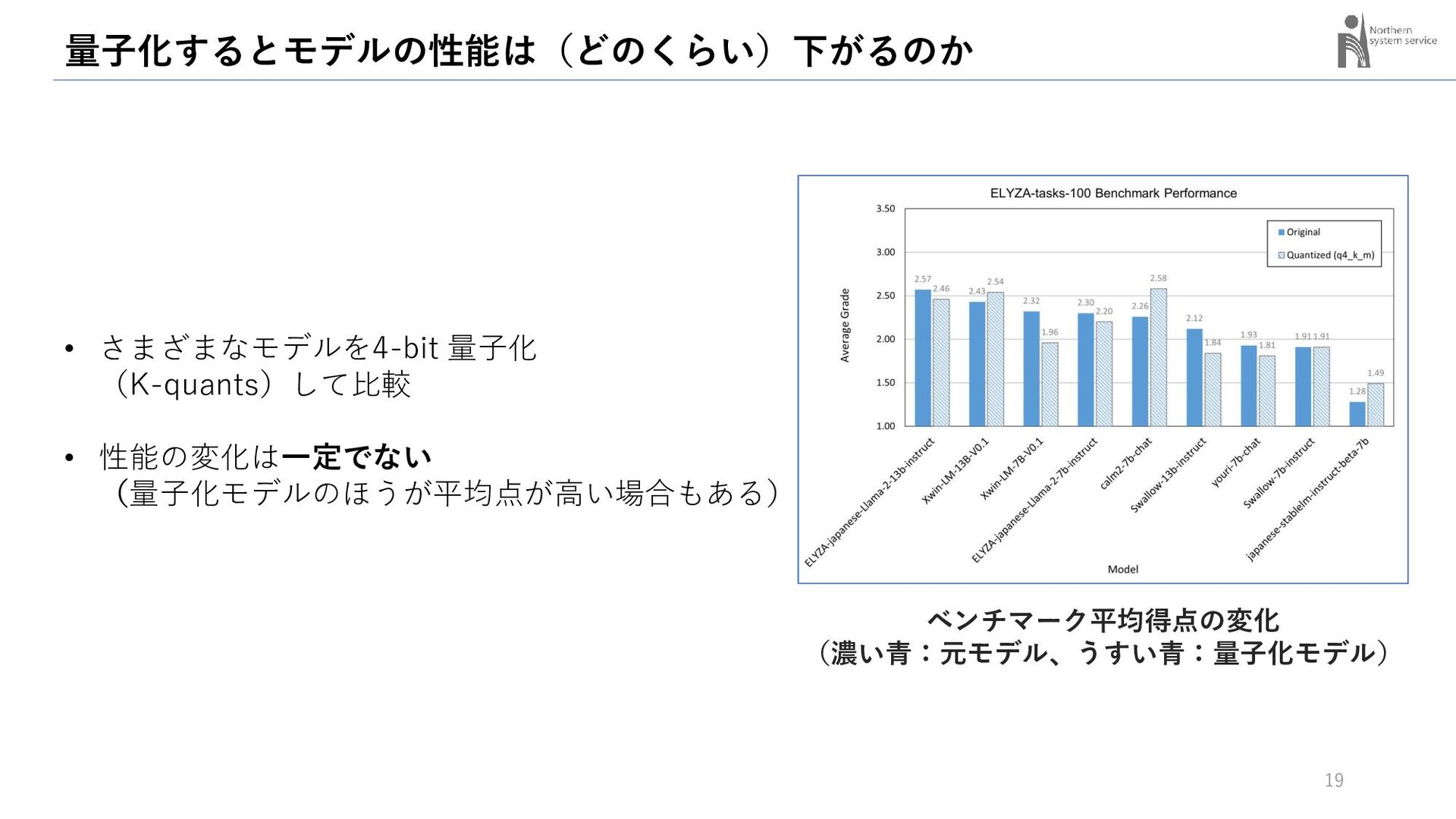{kind=link}
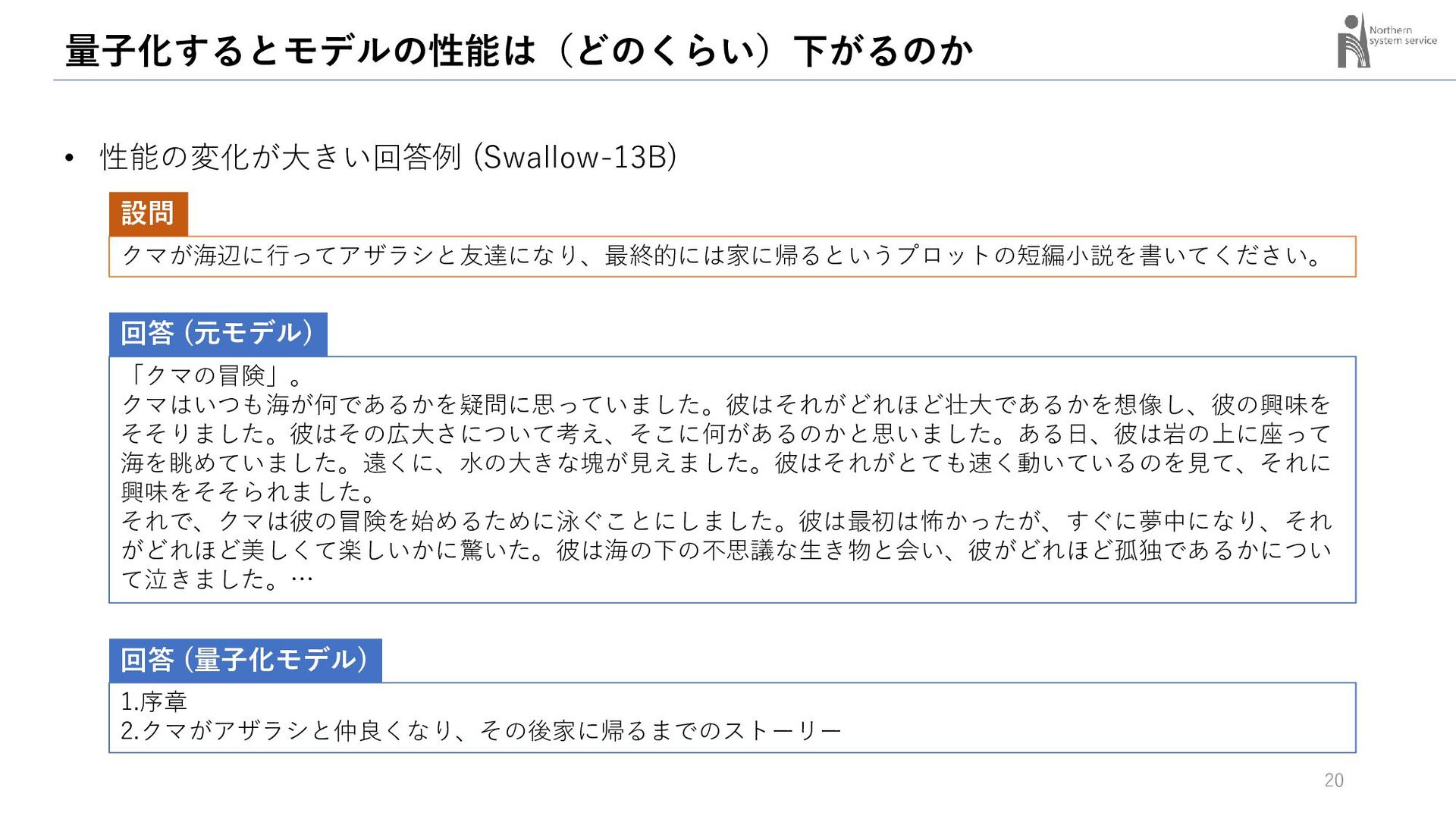{kind=link}
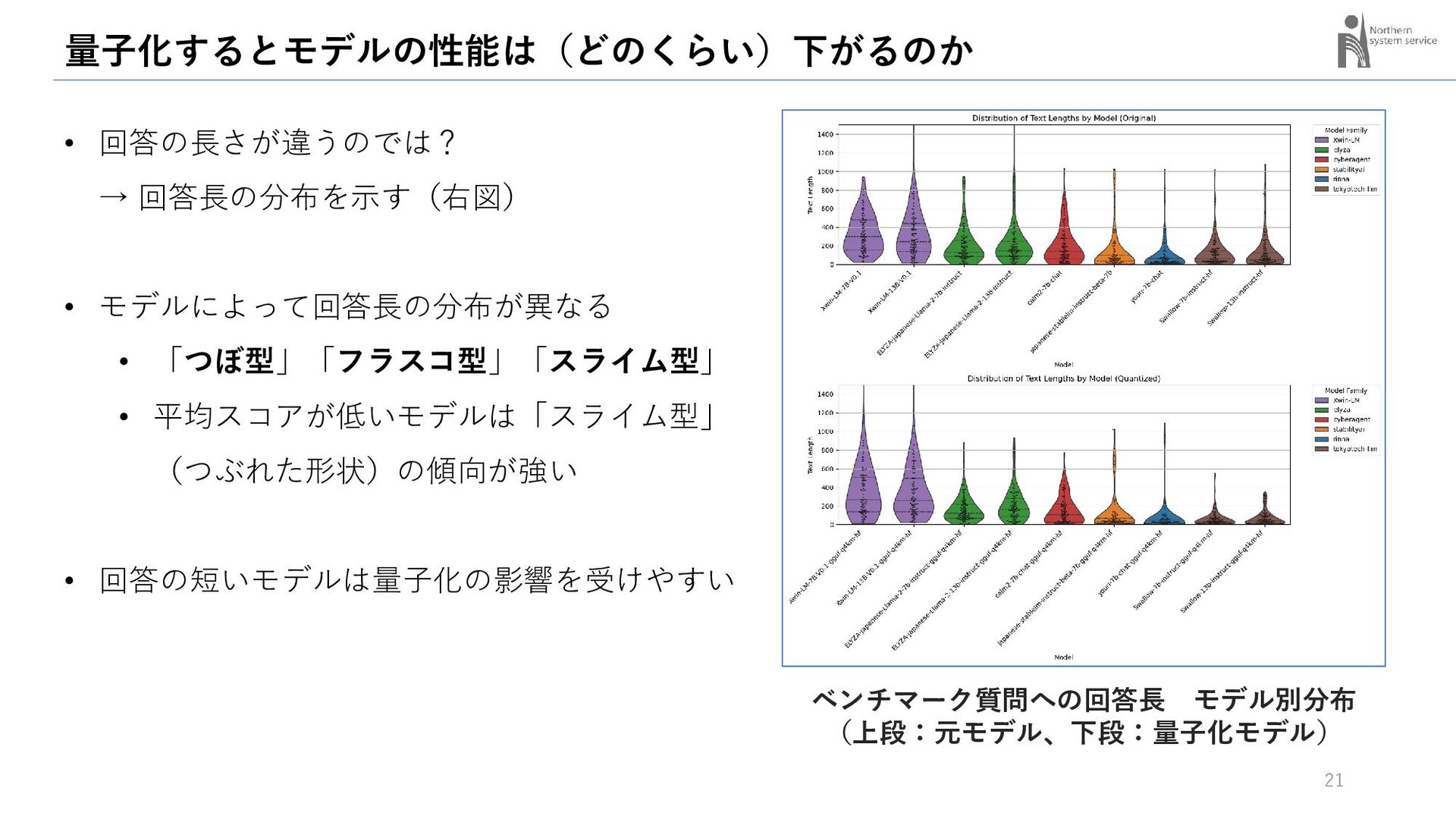{kind=link}
{kind=link}
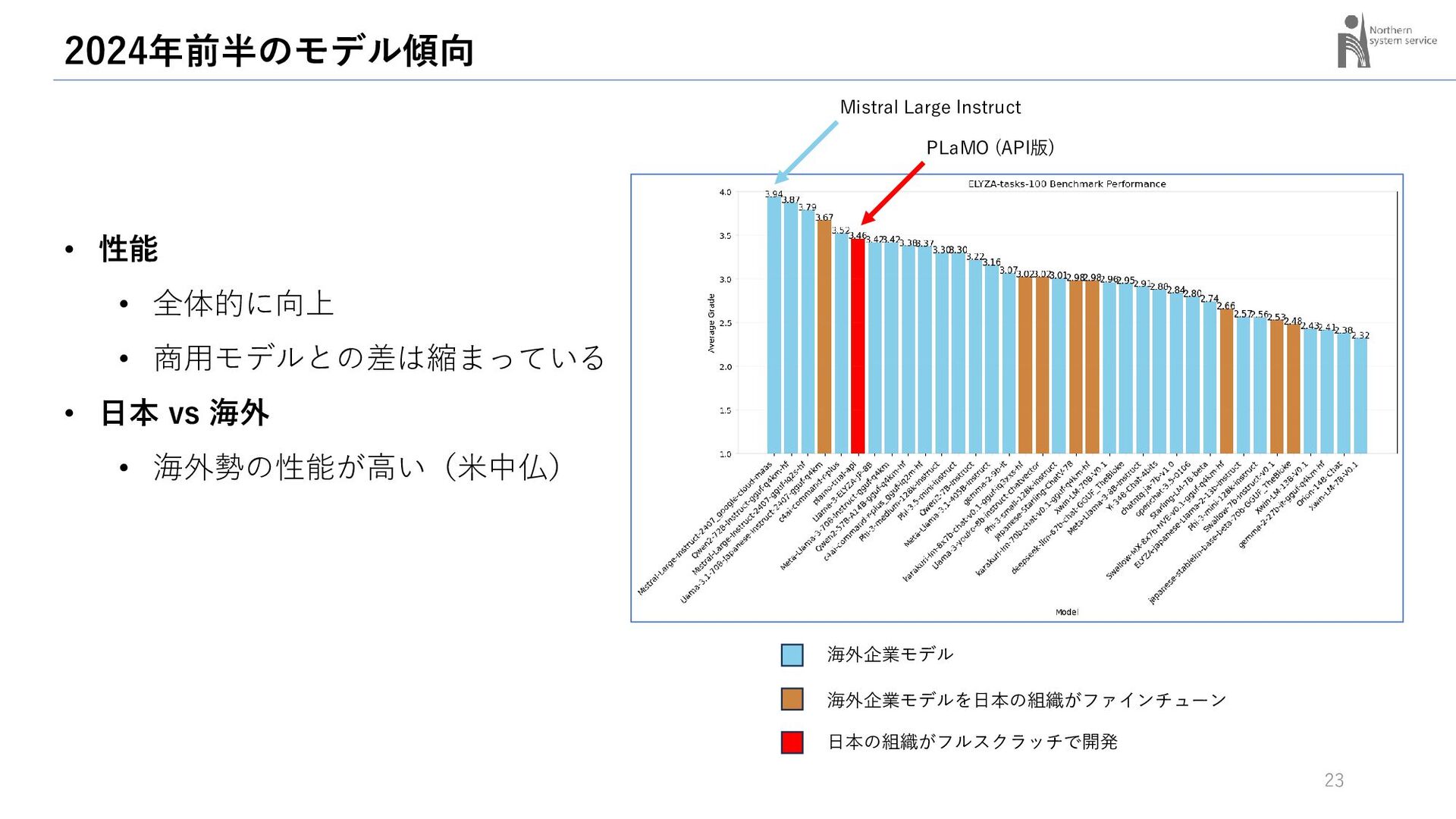{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}