el análisis y exploración, por medios automáticos o semiautomáticos, de grandes cantidades de datos para descubrir conocimiento útil n Patrones n Reglas
n Los patrones deben tener semántica n Precisa conocimiento del entorno n Permite aplicar los patrones a nuevos individuos n No predice el futuro n Estima la clasificación en base a los datos con los que se entrena
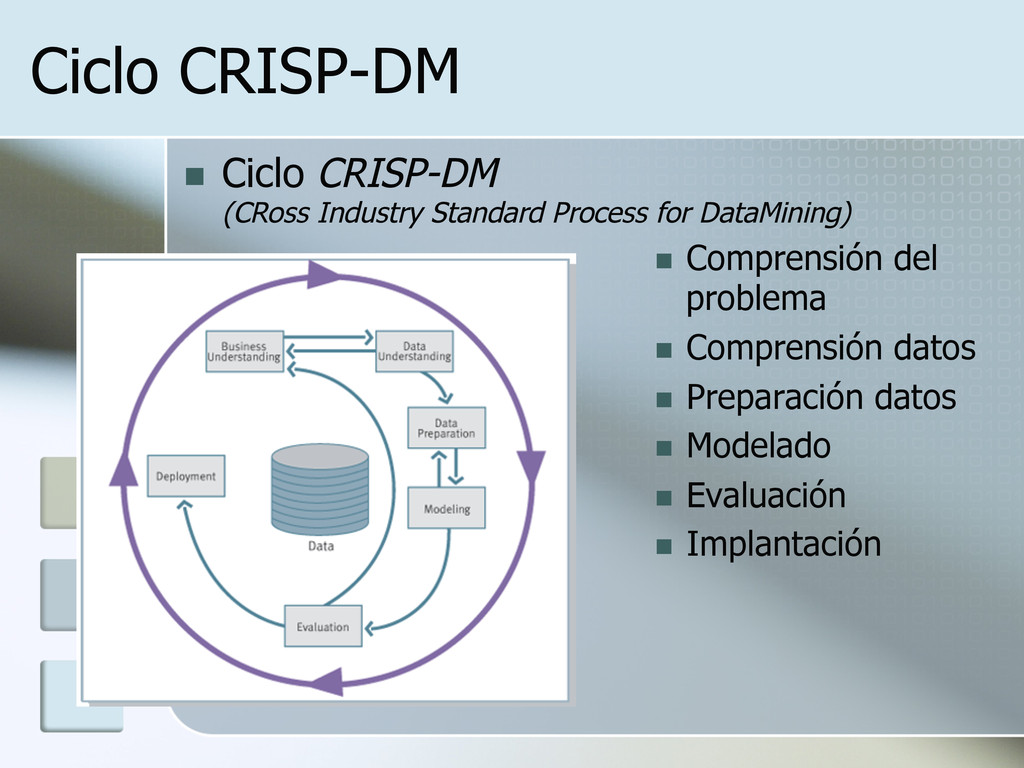
del proyecto. n Comprensión del entorno del negocio n Antecedentes n Objetivos del negocio n Criterios de éxito del proyecto (perspectiva del negocio) n Formalización del problema n Determinar los objetivos n Plan de trabajo
n Conseguir el conjunto inicial de datos n Informe inicial sobre los datos disponibles n Describir los datos n Informe con la descripción de los datos n Explorar los datos n Informe acerca de la exploración de los datos n Verificar la Calidad de los datos n Informe acerca de la calidad de los datos
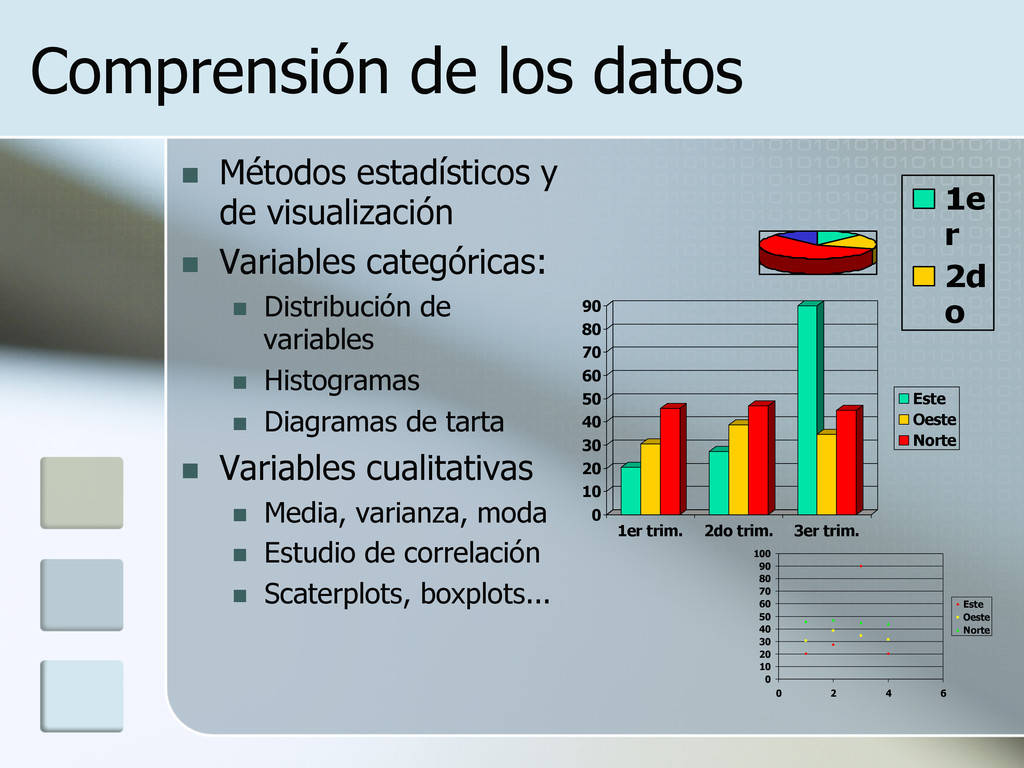
n Variables categóricas: n Distribución de variables n Histogramas n Diagramas de tarta n Variables cualitativas n Media, varianza, moda n Estudio de correlación n Scaterplots, boxplots... 0 10 20 30 40 50 60 70 80 90 1er trim. 2do trim. 3er trim. Este Oeste Norte 0 10 20 30 40 50 60 70 80 90 100 0 2 4 6 Este Oeste Norte 1e r 2d o 3e r
Selección de la técnica de modelado n Técnica elegida n Requisitos de la técnica elegida n Generar un diseño de prueba n Diseño de prueba n Construir el modelo n Parámetros elegidos n Modelo y descripción n Evaluar el modelo n Evaluación del modelo n Parámetros revisados
El resultado del proceso depende del tipo de proyecto realizado n Datos procesados Informes n Programas de aplicación n … n Establecer un plan de monitorización y mantenimiento
tratamiento depende de su naturaleza n Se pueden eliminar en el proceso de carga n Valores nulos n Eliminar las observaciones con nulos n Eliminar las variables con muchos nulos n Estimar su valor n Media n Moda n Estimación mediante modelos n Inconsistencias n Elegir valor más apropiado (más actual, media …) n Ruido n Método cubos n Clustering n Discretización n Regresión
la Compra” n Determinar cosas que van juntas n Segmentación n Generan grupos de individuos similares entre sí n Ejemplos: n K-Medias (K-Means) n 2-step n Mapas de Kohonen
forma aleatoria 2. Asignar a cada individuo el centro más cercano (distancia euclídea) 3. Recalcular los centros usando los individuos asignados a cada uno 4. Si ha habido alguna variación repetir desde el paso 2
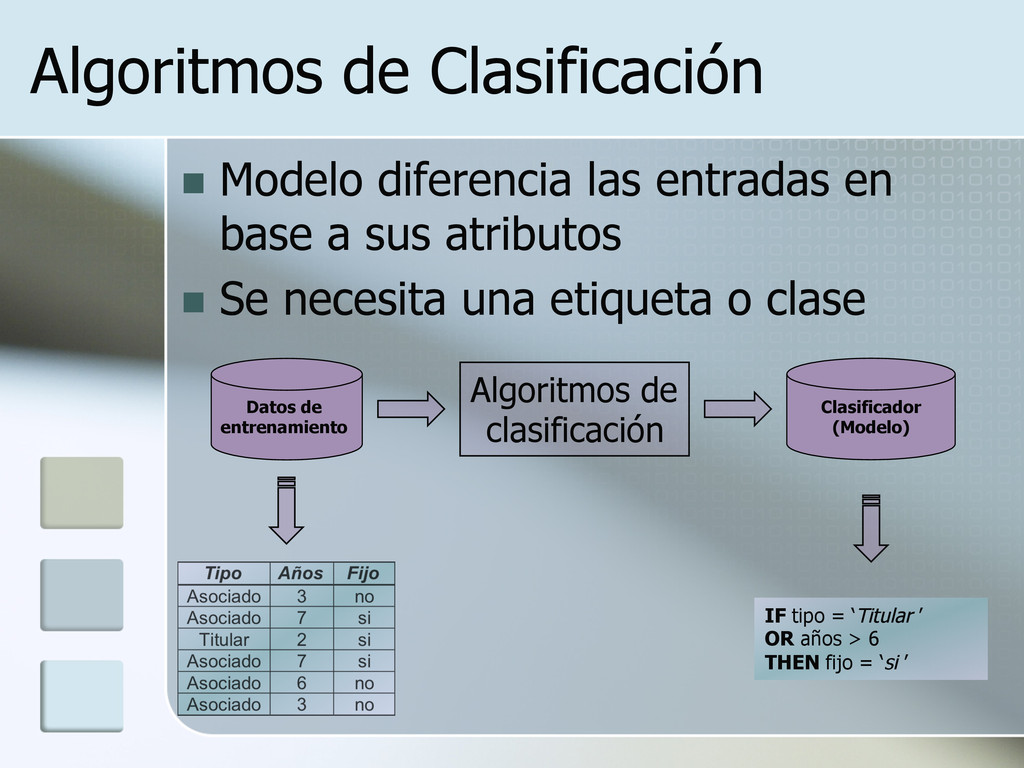
a sus atributos n Se necesita una etiqueta o clase Datos de entrenamiento Algoritmos de clasificación IF tipo = ‘Titular ’ OR años > 6 THEN fijo = ‘si ’ Clasificador (Modelo)
No tiene fase de entrenamiento n Para asignar la clase a un nuevo individuo, se calculan los individuos más cercanos (distancia euclídea) n Todos son de la misma clase se asigna dicha clase n Si hay mezcla: n Valores discretos: votación, % de participación… n Valores continuos: medias…
1. Todos misma clase: Crea hoja de clase 2. Si está vacío: Genera hoja clase desconocida 3. Si hay distintas clases: a. Se elige un atributo (criterio entropía) b. Genera una rama por cada valor del atributo seleccionado c. Repite el proceso desde el paso 1 para cada rama
con una instancia n Validar la instancia n Hold-out n Generar dos conjuntos de datos n Validar con uno y verificar con el otro n N-fold n K·N-fold n Bootstrap
Generan N grupos n Se entrena con N-1 y se valida con el restante n Se valida cada uno de los grupos n K·N-fold n Repite K veces un N-fold n Bootstrap
un conjunto de atributos 2. Entrenar con el conjunto y calcular el error del modelo (validación) 3. Repetir desde el paso 1 hasta que se obtenga un error aceptable n Optimiza para un modelo n Filter n Calcula una medida para cada atributo n Independiente del modelo aplicable
Suite completa n Basada en el ciclo CRISP-DM n Interfaz visual n Weka n Conjunto de algoritmos n Interfaz gráfica reducida n Implementación en Java
![Introducción a la Minería de Datos Oscar Cubo Medina [email protected]](https://files.speakerdeck.com/presentations/2f46c470ddb00130d7dc16b7416e6aa5/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}