collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.”
• Data that can be analyzed in RAM (< 100 GB) • Data operations that can be performed quickly by a traditional database, e.g. single node PostgreSQL server
on tera bytes of text data • Process each HTML page as a URL + bag of words • For each word, aggregate the list of page URLs • 2 billion HTML pages: 100TB >10 days just to read sequentially
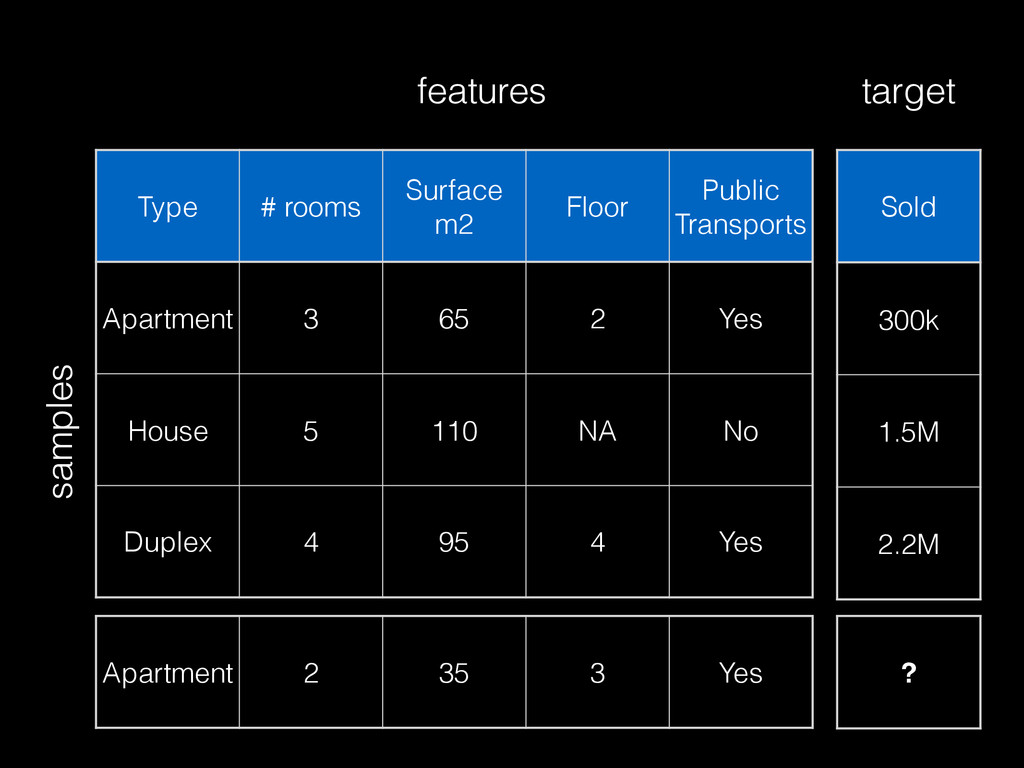
Census data (~10M data points) • Real estate transactions data (~10M data points) • Open / High / Low / Close (OHLC) stock prices (~10K data points) • Any dataset publicly available for download
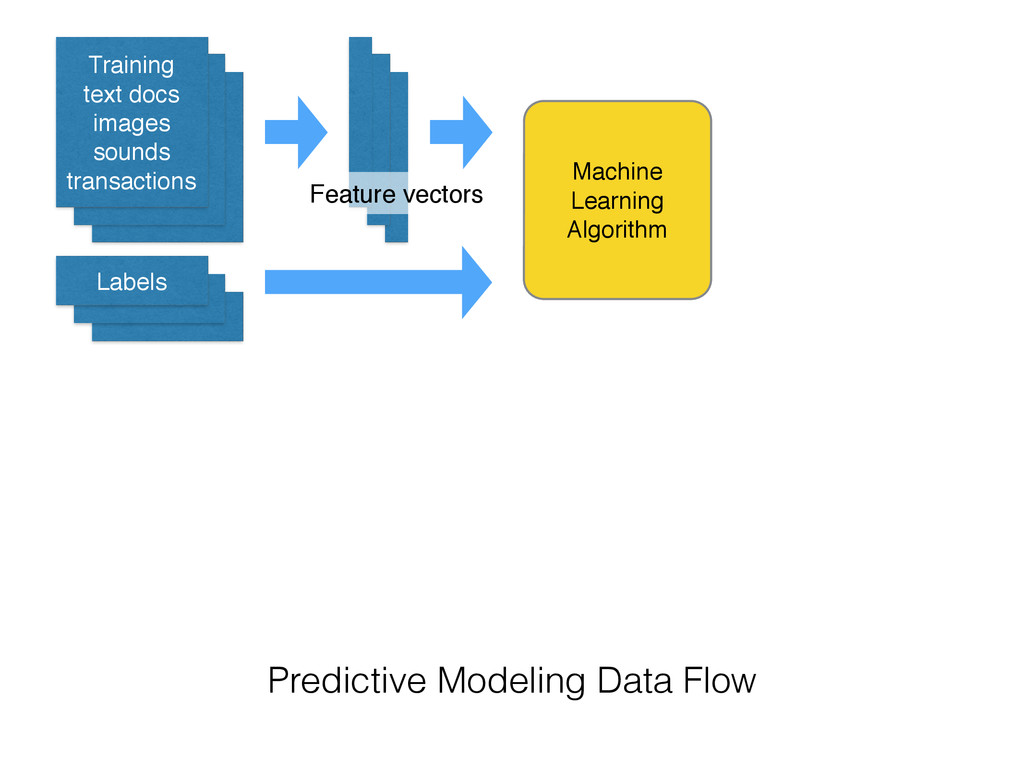
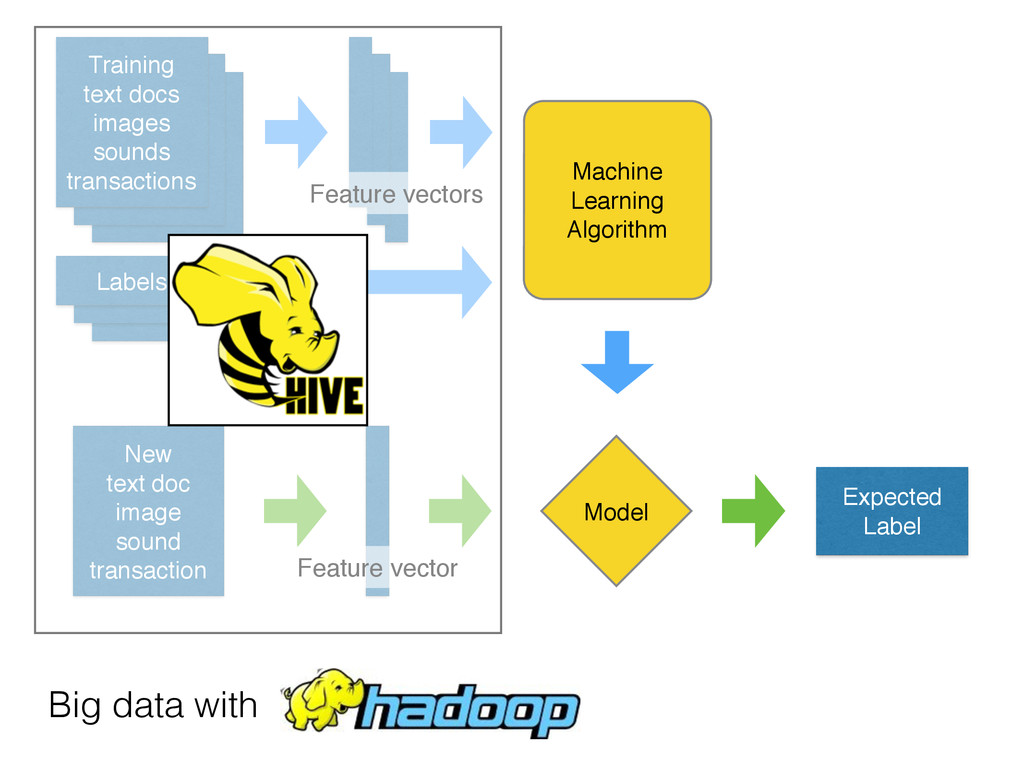
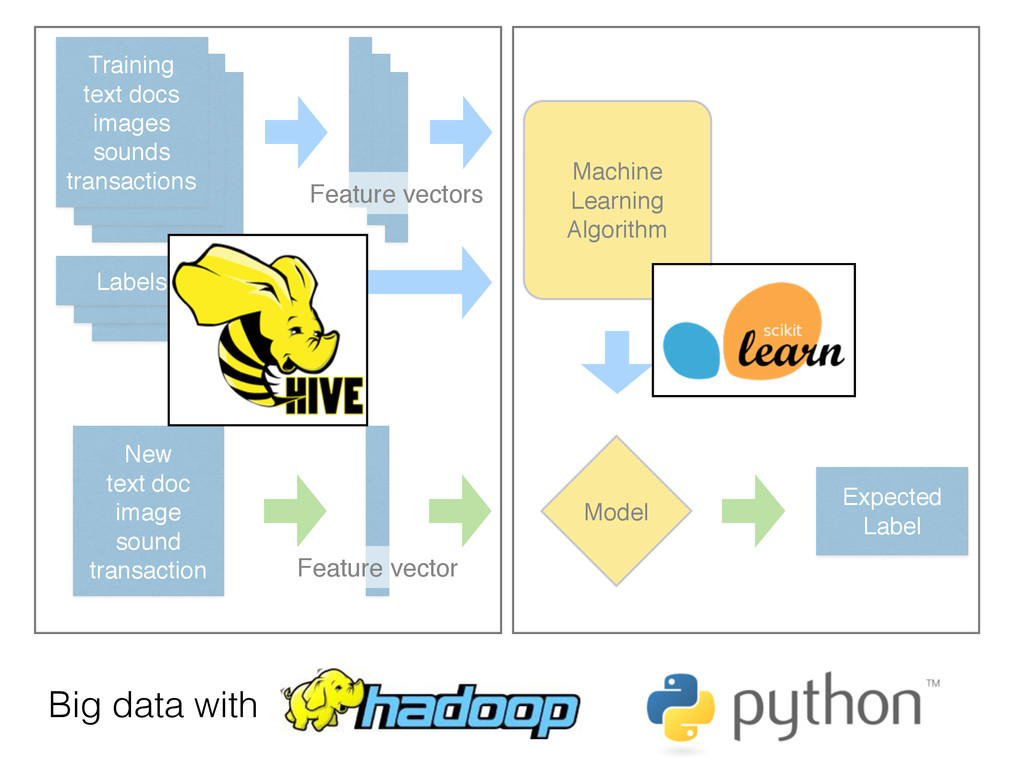
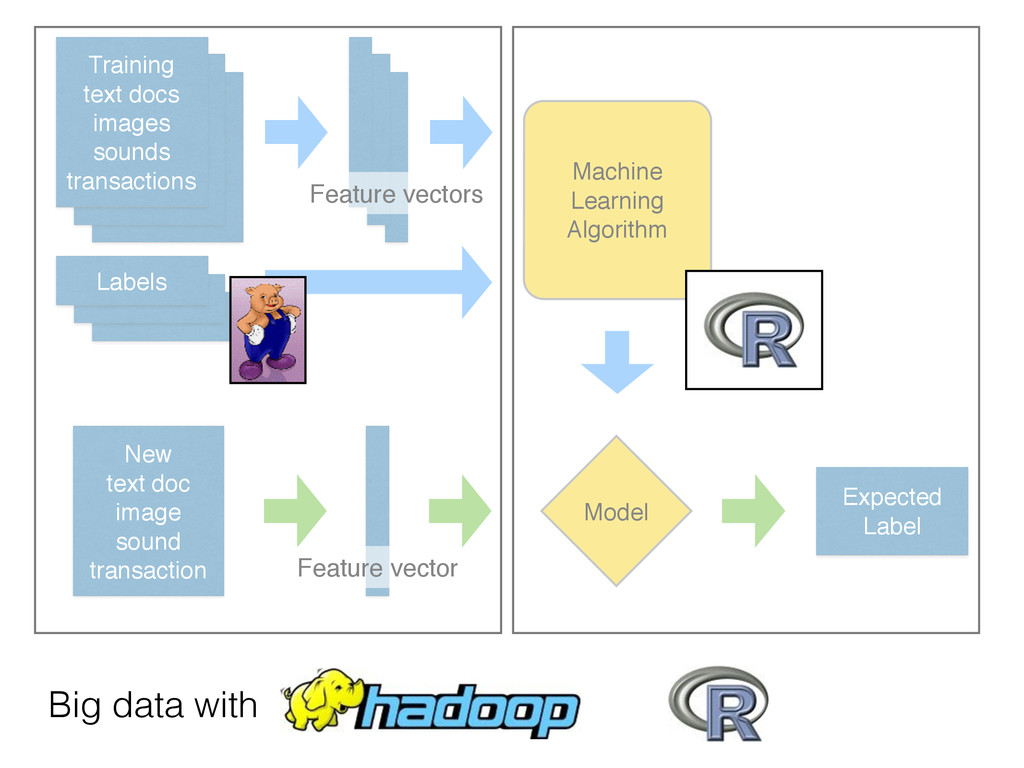
to hard-coded rules written by experts • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model
• Predict CTR and optimal bid price for online ads • Build computer vision systems for robots in the industry and agriculture • Detect network anomalies, fraud and spams • Recommend products, movies, music
recorded via fMRI / EEG / MEG • Decode gene expression data to model regulatory networks • Predict the distance of each star in the sky • Identify the Higgs boson in proton-proton collisions
• Group By (phone, day) to extract daily trips • Join By GPS coordinates to “departement” names • Filter out small trips • Group By (home, work) “departements” • Count
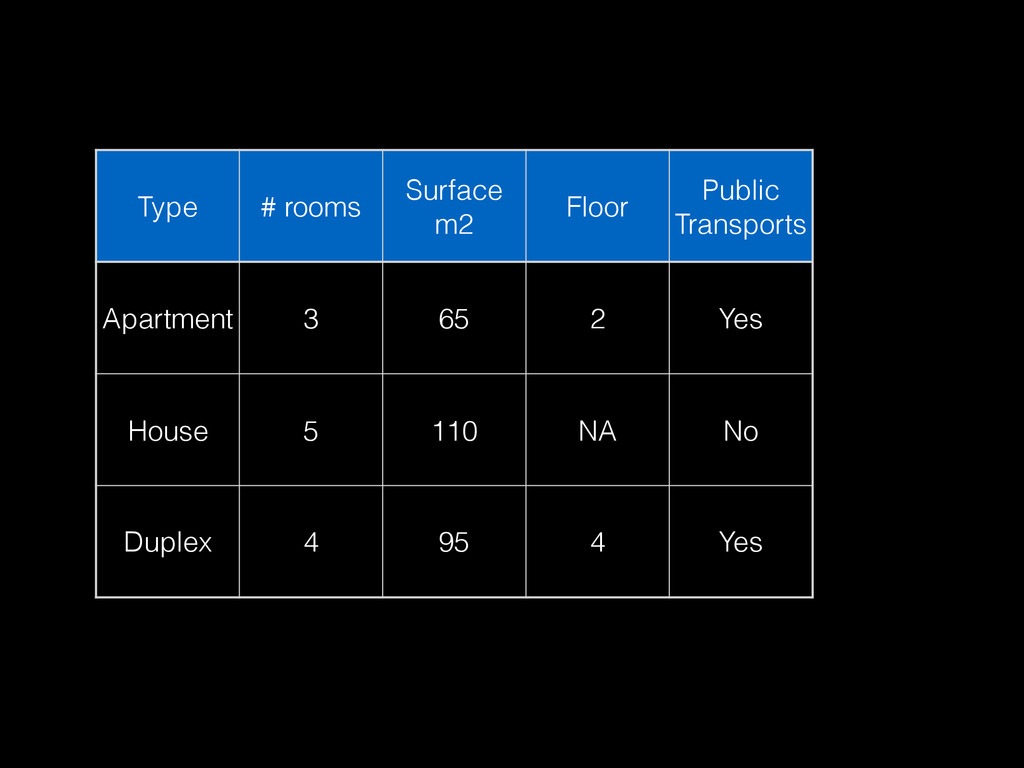
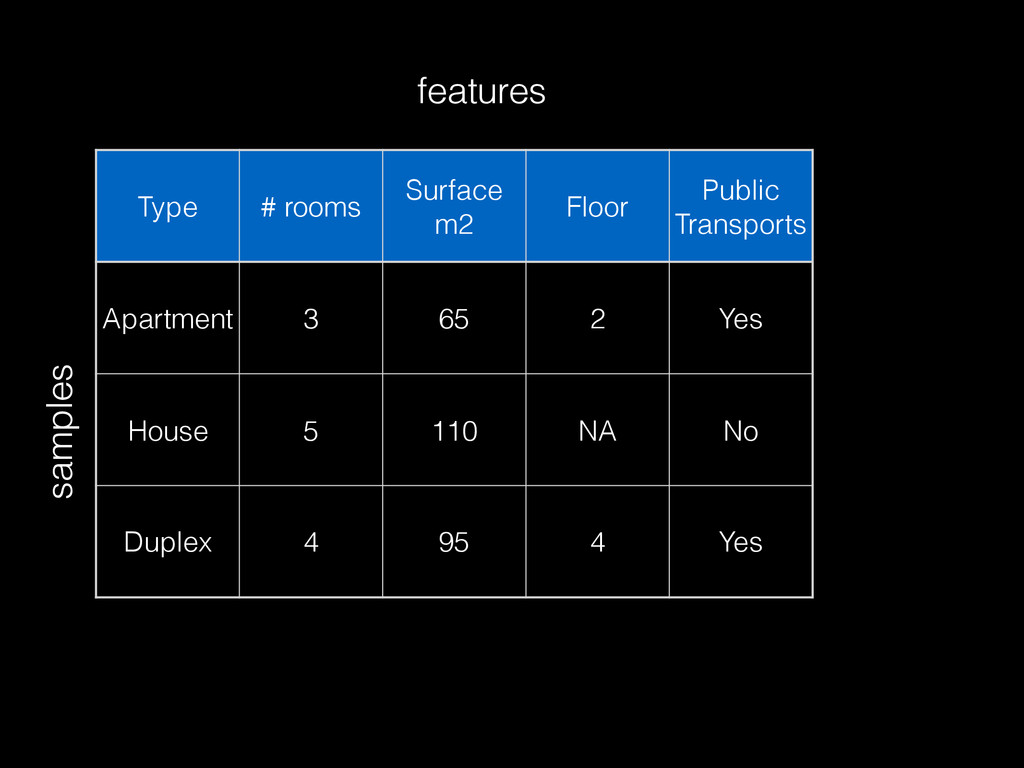
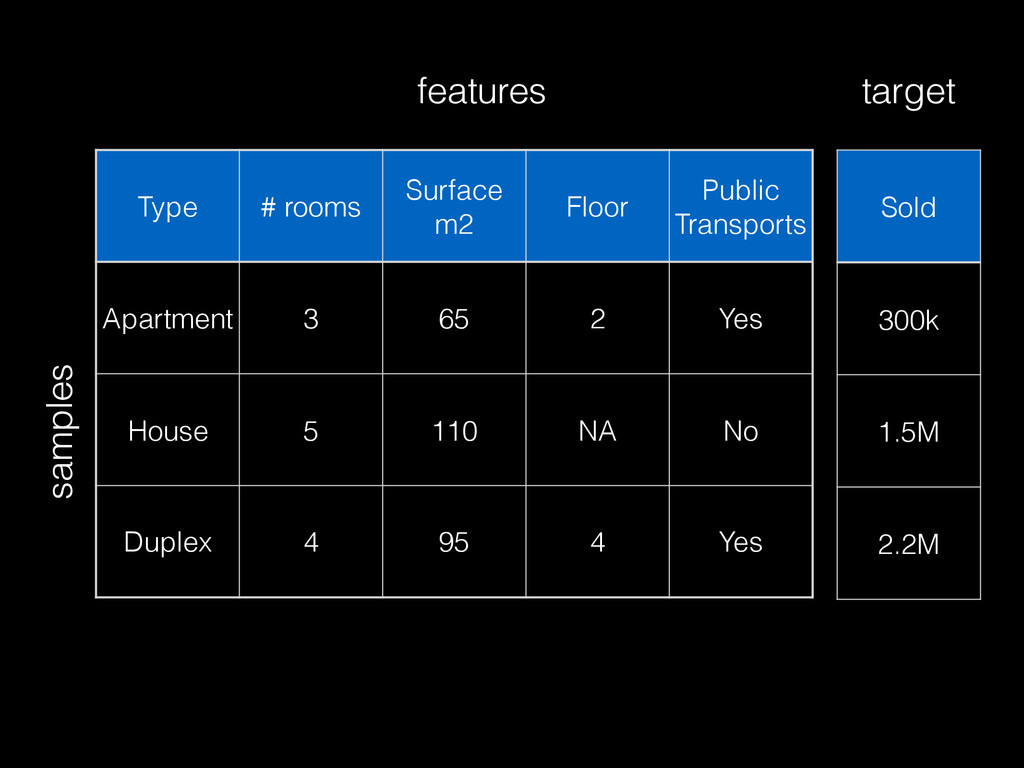
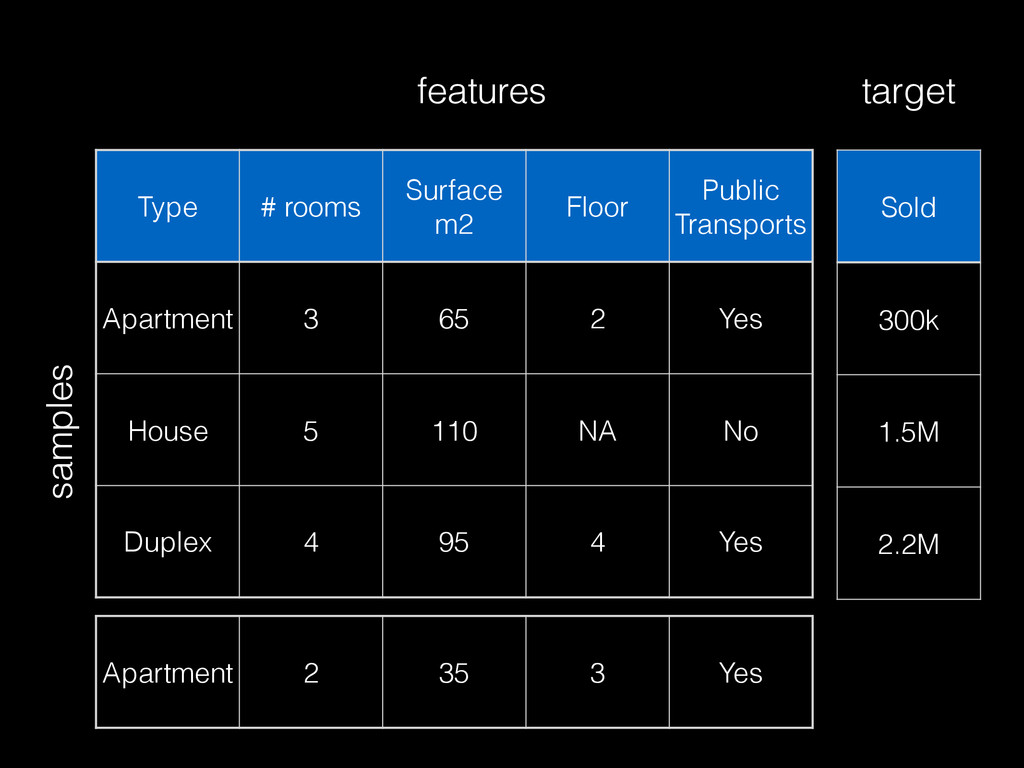
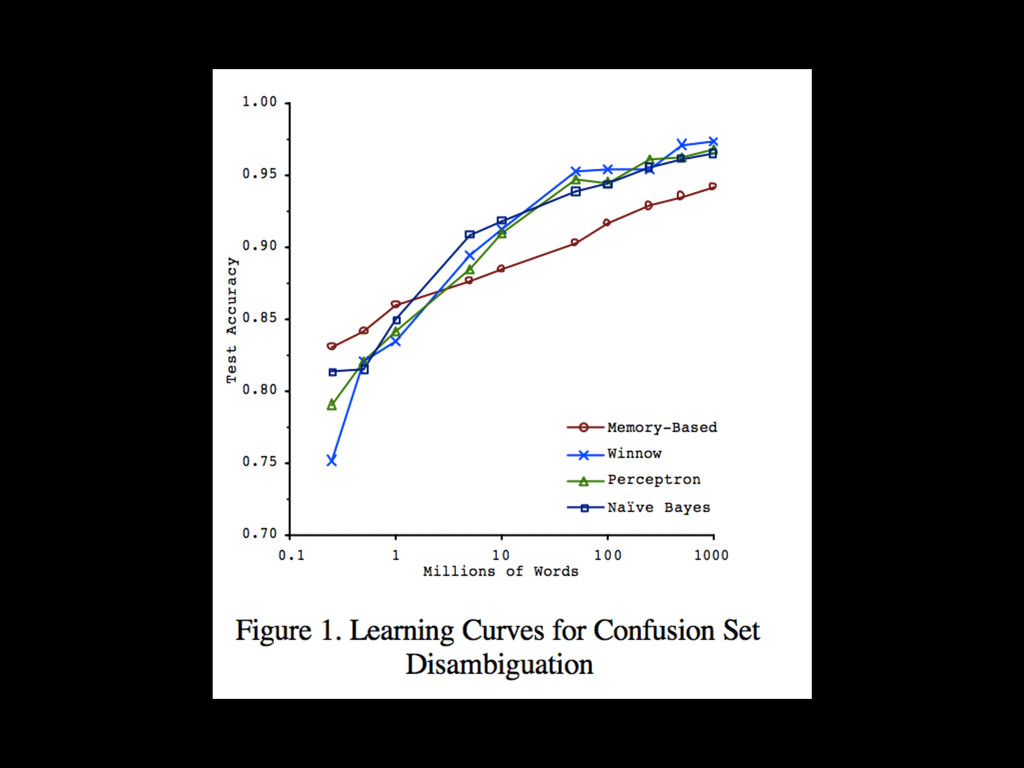
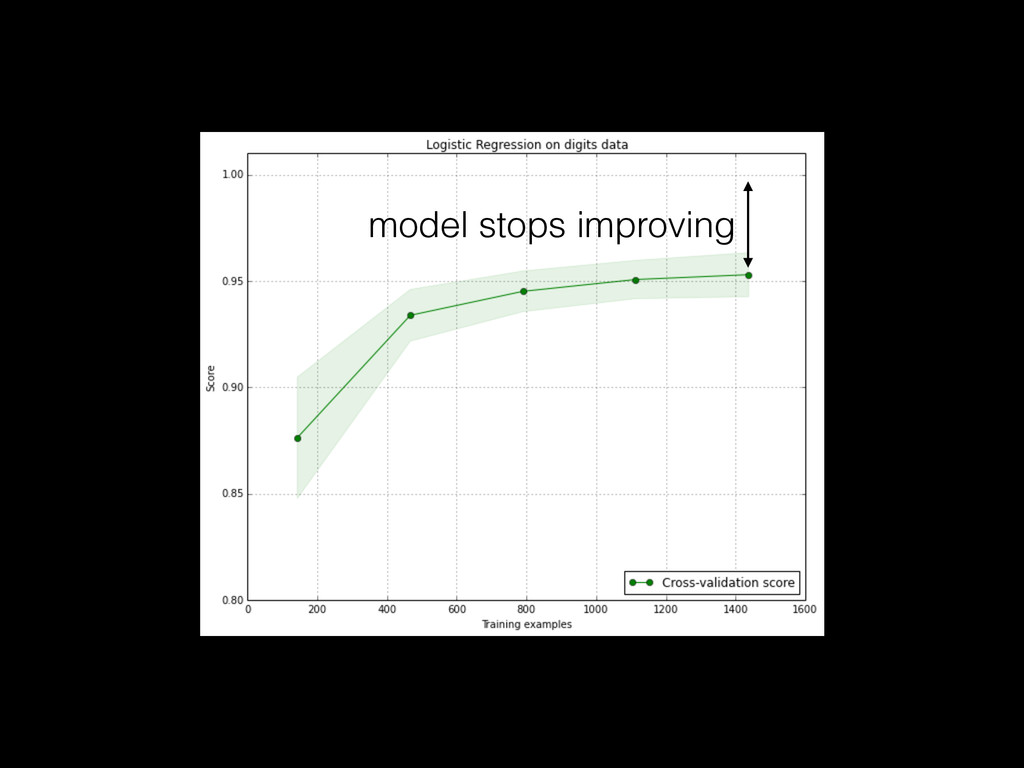
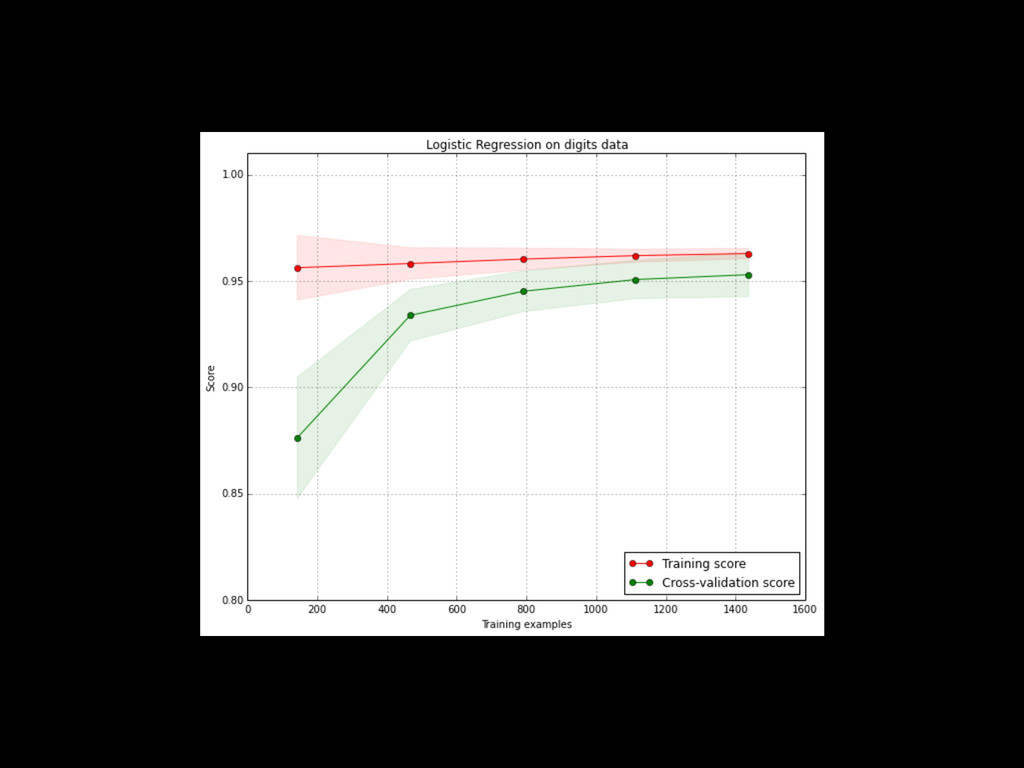
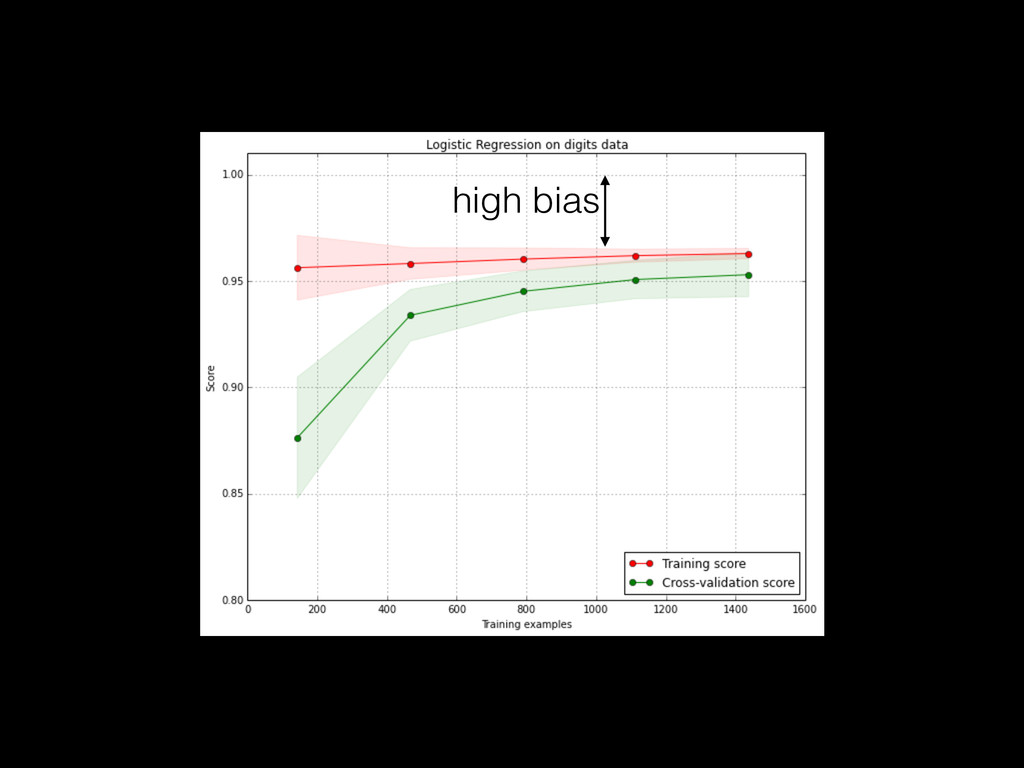
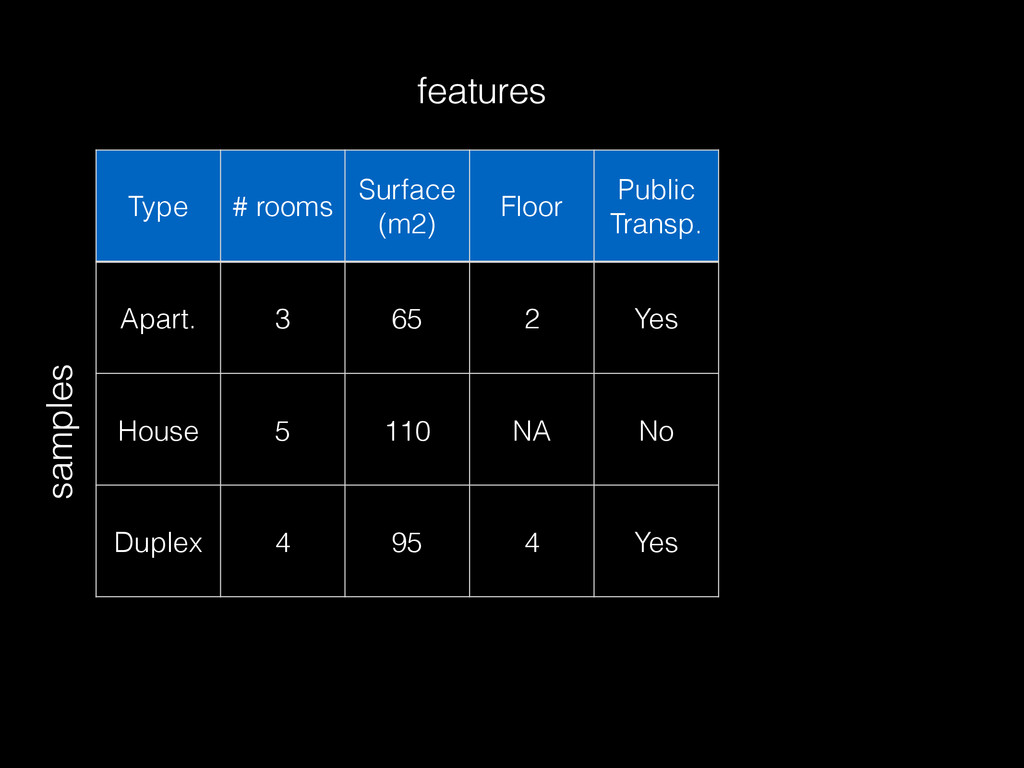
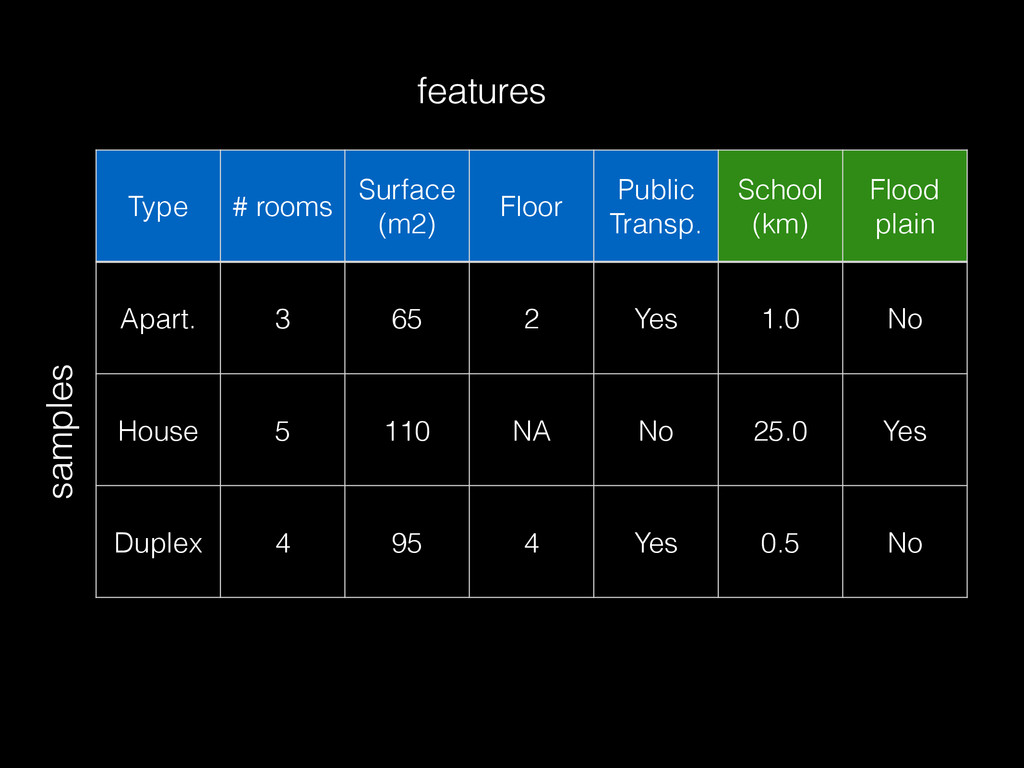
often built from small aggregate data (with sampling) << raw data • Modeling requires interactive / fast iterations • More data generally helps build better models but not always: noise or inadequate repr. • 2 dimensions: # samples & # features
Random Forests, Neural Networks (Machine Learning) • Understand a model with 10% accuracy vs blindly trust a model with 90% accuracy • Simple models e.g. F = m a, F = - G (m1 + m2) / r^2 will not become false(r) because of big data • New problems can be tackled: computer vision, speech recognition, natural language understanding
based on the falsifiability of formulated hypotheses • theory is correct as long as past predictions hold in new experiments • machine learning train-validation-test splits and cross-validation is similar in spirit • ml model is just a complex theory: correct as long as its predictions still hold
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}