Presentation on IPython.parallel and scikit-learn for PyData Silicon Valley 2013.
The video recording of this talk is available online at: http://vimeo.com/63269736
The slides are pretty much the same than those from the talk given a the London Data Science Meetup earlier this month.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Model Selection the Hyperparameters hell param_1 in [1, 10, 100]](https://files.speakerdeck.com/presentations/1fb1f29073030130970822000a9f0177/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[global] DEFAULT_TEMPLATE=ip [key mykey] KEY_LOCATION=~/.ssh/mykey.rsa [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/1fb1f29073030130970822000a9f0177/slide_62.jpg){kind=link}
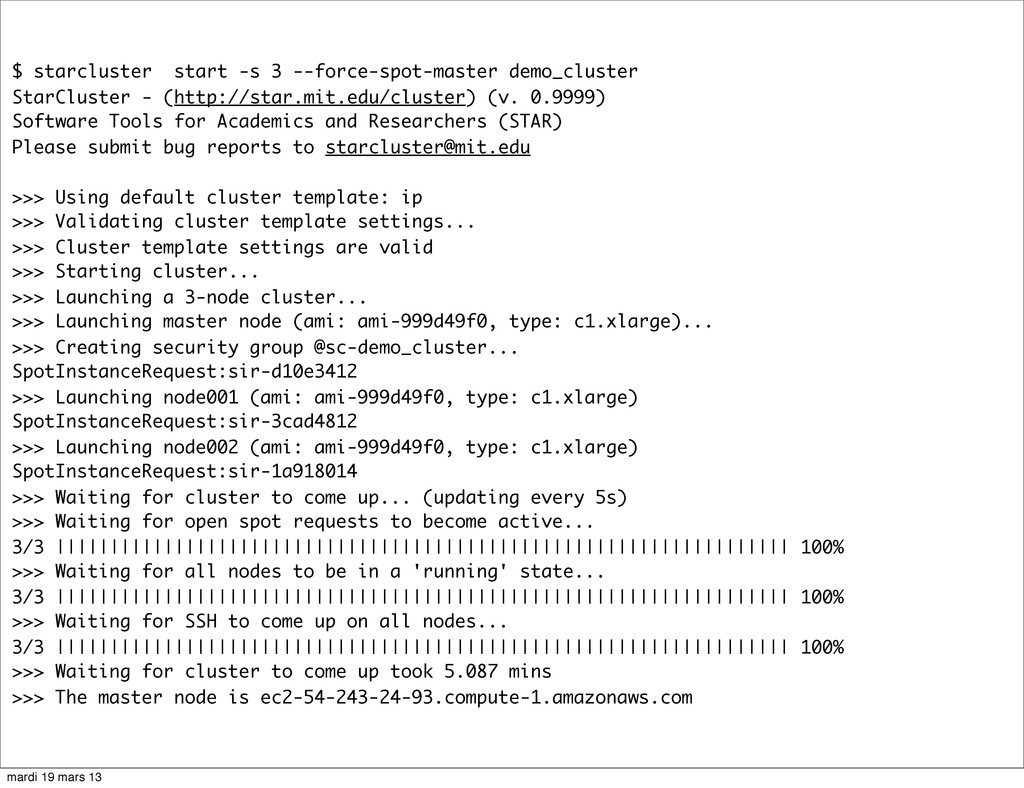{kind=link}
{kind=link}
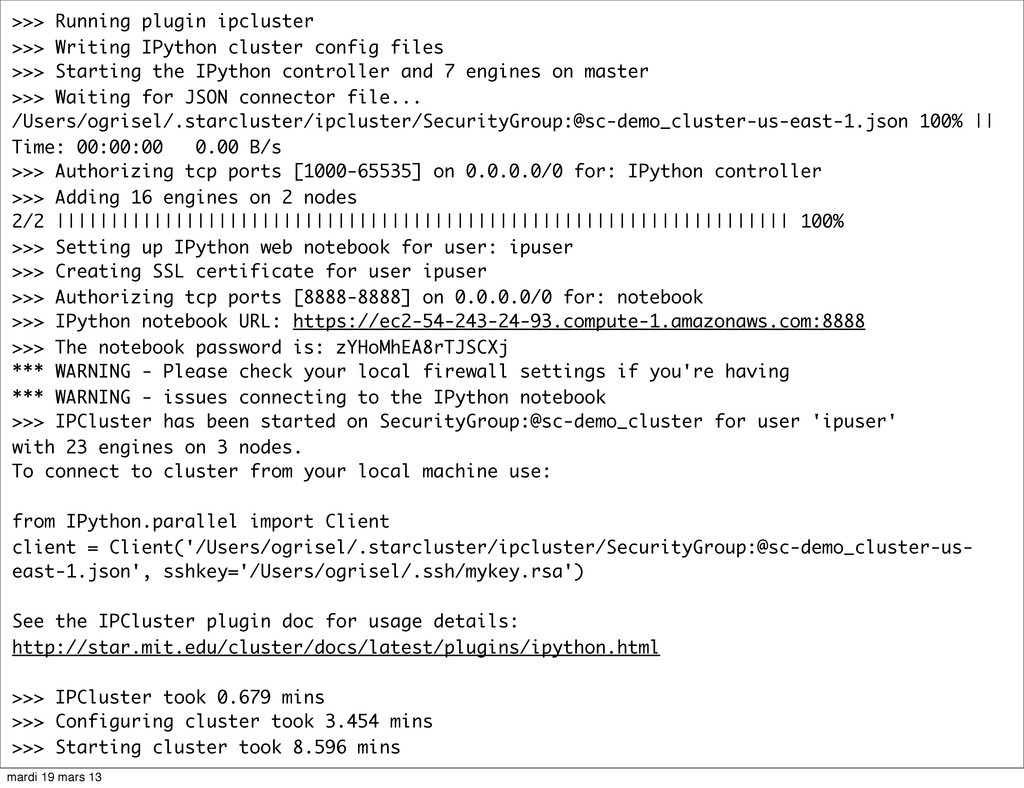{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce? [ (k1, v1), (k2, v2), ... ] mapper mapper](https://files.speakerdeck.com/presentations/1fb1f29073030130970822000a9f0177/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
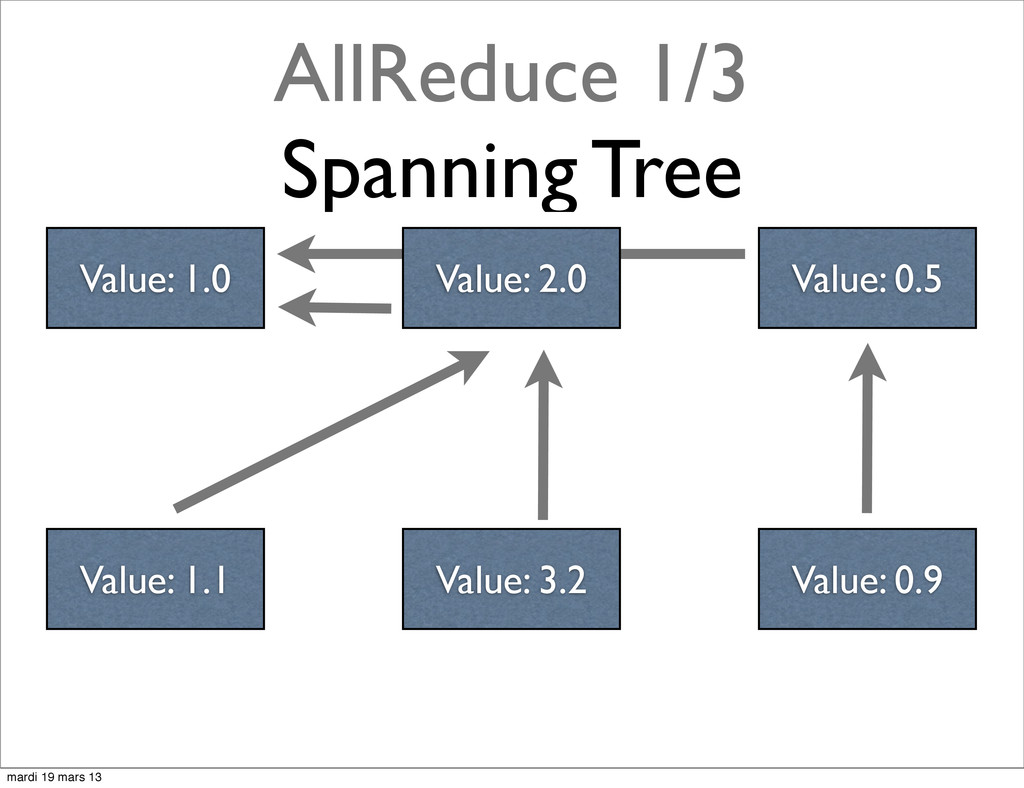{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
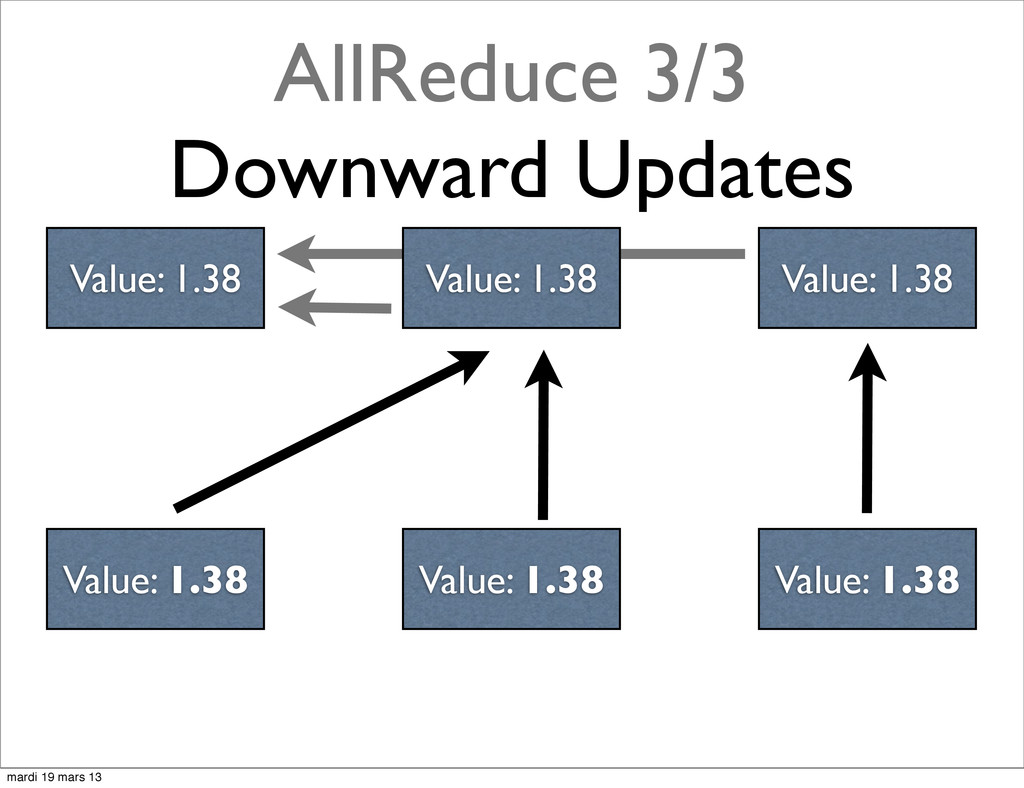{kind=link}
{kind=link}
{kind=link}
![Killall IPython engines on StarCluster [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/1fb1f29073030130970822000a9f0177/slide_86.jpg){kind=link}
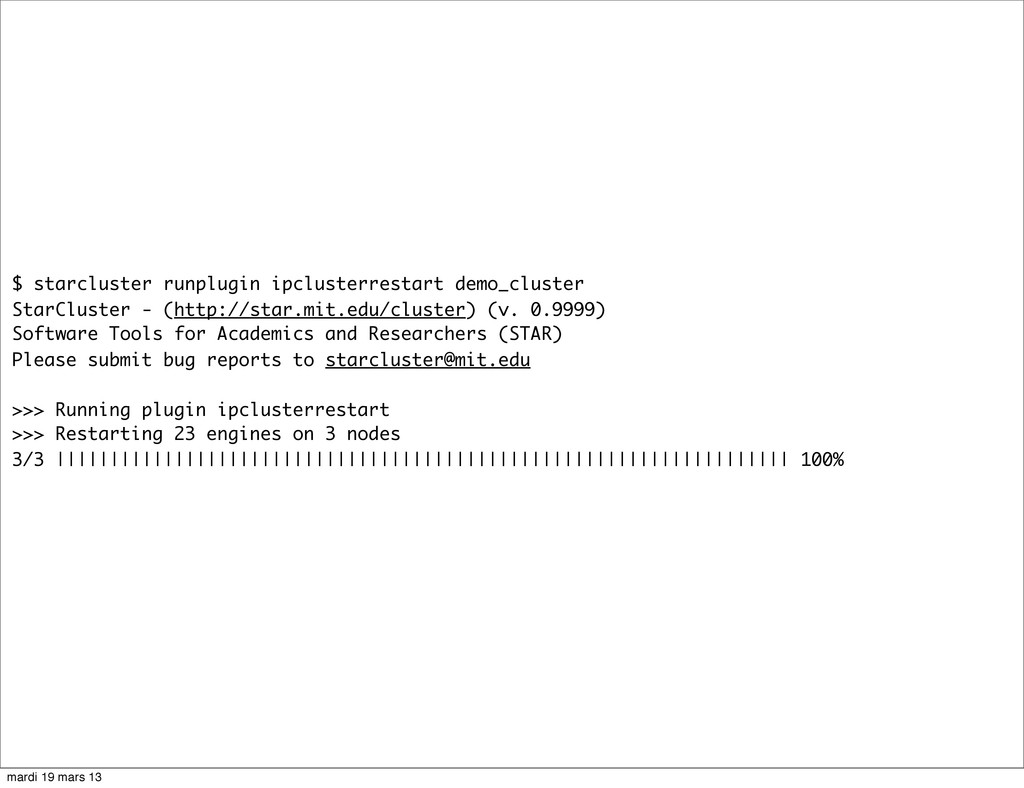{kind=link}