Google Bigquery, processing big data without the infrastructure
This presentation covers the basics of Google Bigquery and how developers can leverage its capabilities in analysing BI (Business Intelligence) and IoT (Internet of Things) data.
is so large and complex that it becomes difficult to process using traditional tools. • Widely characterised in terms of three dimensions (3Vs): ◦ Volume: massive datasets (terabytes, petabytes,...) ◦ Variety: different kinds of data (structured, semi- structured and unstructured). ◦ Velocity: the rate at which the data is generated from batch to real time.
query/analysis of massive datasets. • No need for infrastructure setup, indexes, partitioning, db tuning, clustering, replication, sharding, etc… • Pay per data processed, 1st Terabyte free per month is free then $5 per Terabyte. Plus month storage cost. • Queries using SQL like syntax. • You just need your data and queries. + SQL
Supports storing nested datasets. • Supports a range of datatypes: String, Integer, Float, Boolean, Timestamp, Record. • Data can be streamed in at a rate of 100,000 rows per second. • Can be accessed using a web UI, command-line tool or through the BigQuery REST API.
inside Google (analysis of crawled web documents, spam analysis, OCR results from Google Books, etc…). • Dremel is based on Columnar storage and is able to process complex nested data. • Can process Trillion-record, multi-terabyte datasets at interactive speed. • Interoperates with Google’s data management tools (MapReduce, GFS, etc…) • Outperforms MapReduce by an order of magnitude on nested data.
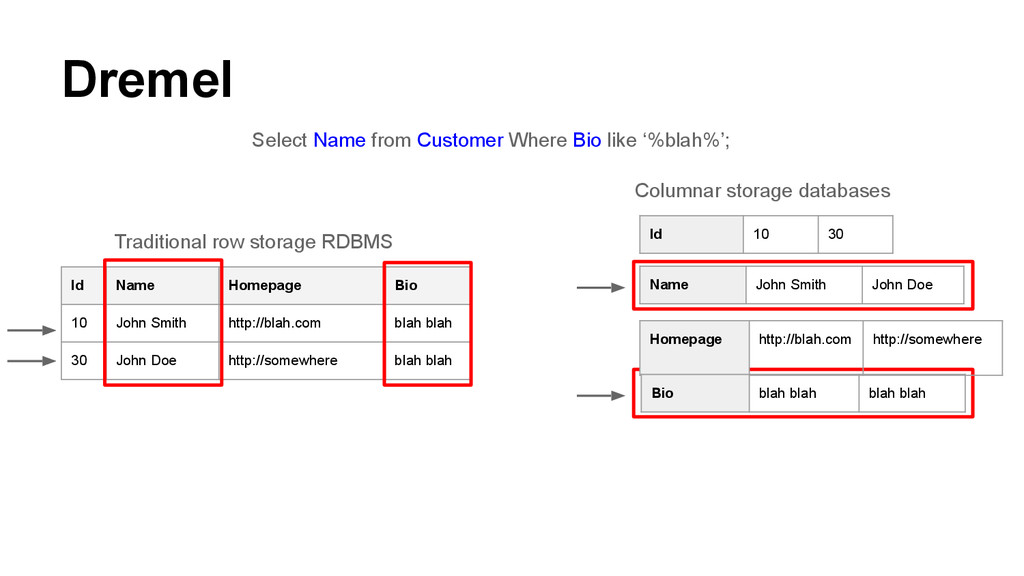
blah 30 John Doe http://somewhere blah blah Traditional row storage RDBMS Select Name from Customer Where Bio like ‘%blah%’; Id 10 30 Name John Smith John Doe Homepage http://blah.com http://somewhere Bio blah blah blah blah Columnar storage databases
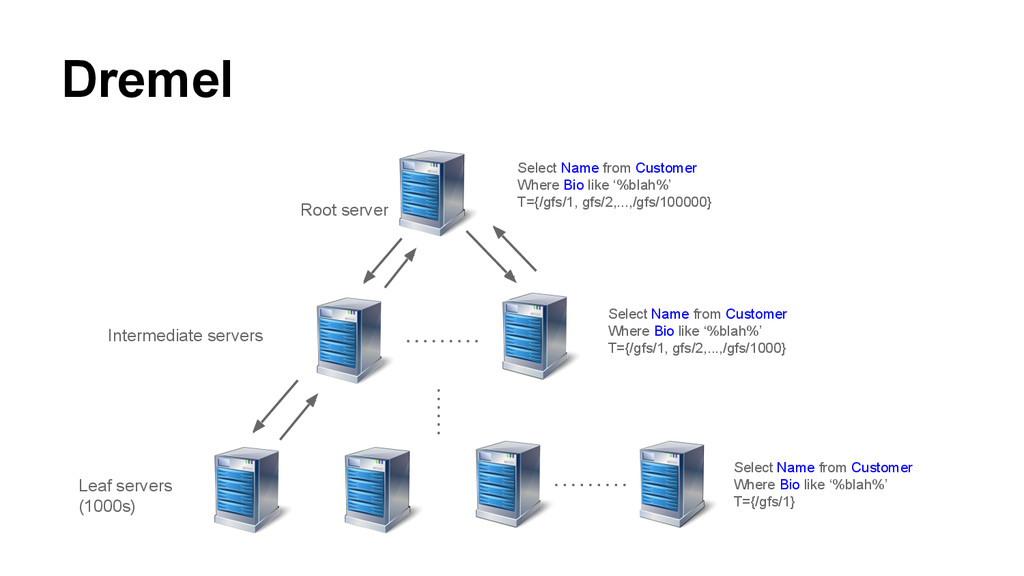
from Customer Where Bio like ‘%blah%’ T={/gfs/1, gfs/2,...,/gfs/100000} Select Name from Customer Where Bio like ‘%blah%’ T={/gfs/1, gfs/2,...,/gfs/1000} Select Name from Customer Where Bio like ‘%blah%’ T={/gfs/1}
Google Cloud Storage. • Data posted in insert jobs or streaming inserts. • Google Cloud Datastore backup. • Data needs to be in CSV or JSON format. JSON can be used for nested data. • Destination table and schema can be specified on the load request. Cloud Datastore Cloud Storage Direct import/stream
• BigQuery SQL supports regular expressions, data aggregation, sorting, etc… 1 billion rows • Supports table decorators, for example query table data @<time> or @<time1>-<time2> for table data added between time1 and time2. • Query results can are automatically saved into temp tables (cached for 24 hours). • Users can save query results into names tables.
client libraries (.NET, Java, Objective-C, Python, etc…). • Easy access from Compute Engine VMs (service accounts). • Similar to integration with other Google APIs so can benefit from code re-use. • Authentication using OAuth2.
Terabyte challenge (https://www.youtube. com/watch?v=LSLU8Gxt-rc). • A query with regular expressions, grouping, nested queries on 30 terabytes of data in 30 billion rows of information. • Query scans 6.24TB in 5.6 minutes!
Your data and your queries, nothing else. • No upfront cost, infrastructure setup, complex configurations or development. • Ability to support real time data ingestion using streaming. • Rapid prototyping of informational dashboard, for example with App Engine applications. • Interactive analysis of massive datasets (compared to batch analysis).
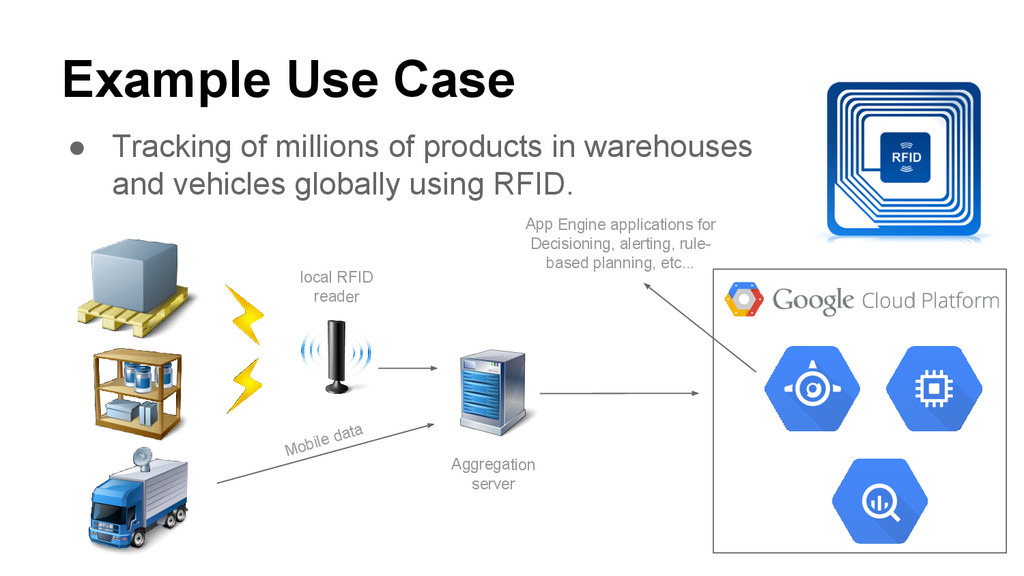
warehouses and vehicles globally using RFID. Mobile data local RFID reader Aggregation server App Engine applications for Decisioning, alerting, rule- based planning, etc...
Dremel: interactive analysis of web-scale datasets. Proceedings of the VLDB Endowment, 3(1-2), pp.330–339. (http://research. google.com/pubs/pub36632.html) • K. Sato, ”An Inside Look at Google BigQuery,” White paper, https://cloud.google.com/files/BigQueryTechnicalWP.pdf, 2012.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions You can also email [email protected] Stay in touch Google+:](https://files.speakerdeck.com/presentations/fa0f794c65934b9d949c66c768eb5c08/slide_15.jpg){kind=link}
{kind=link}