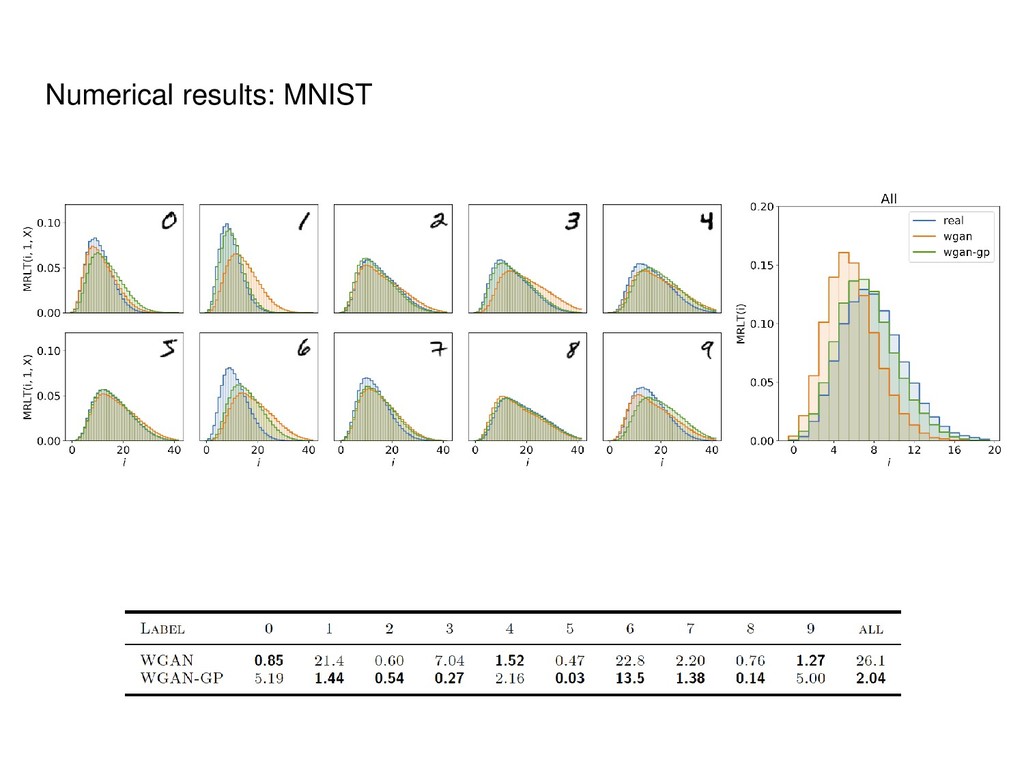
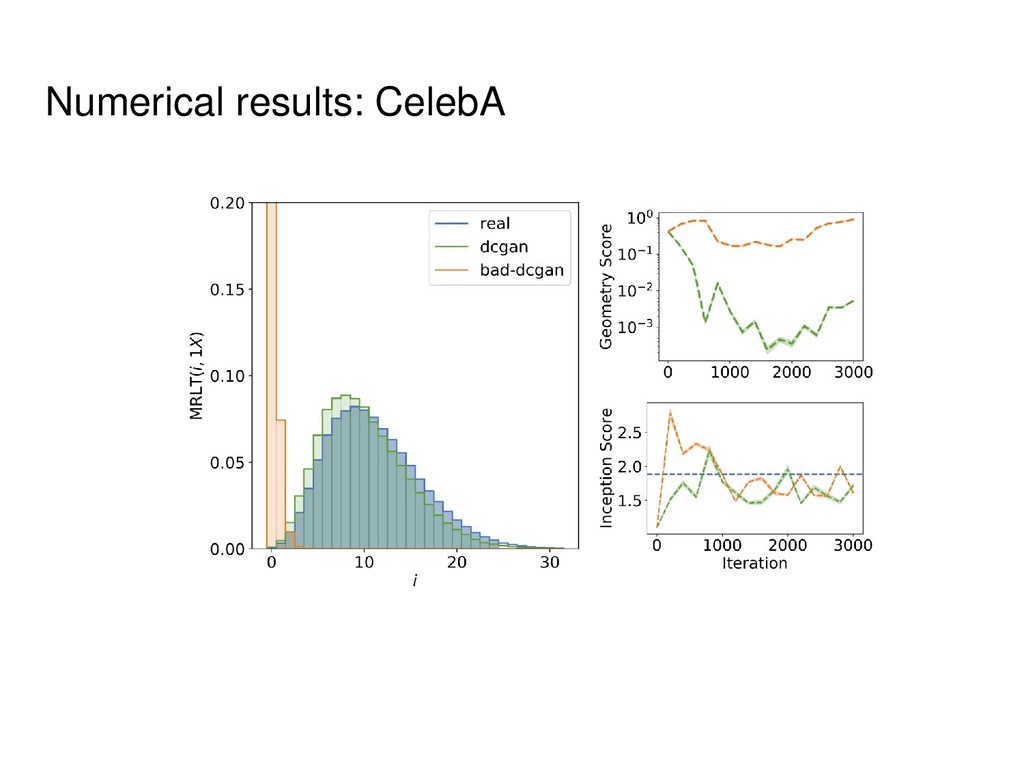
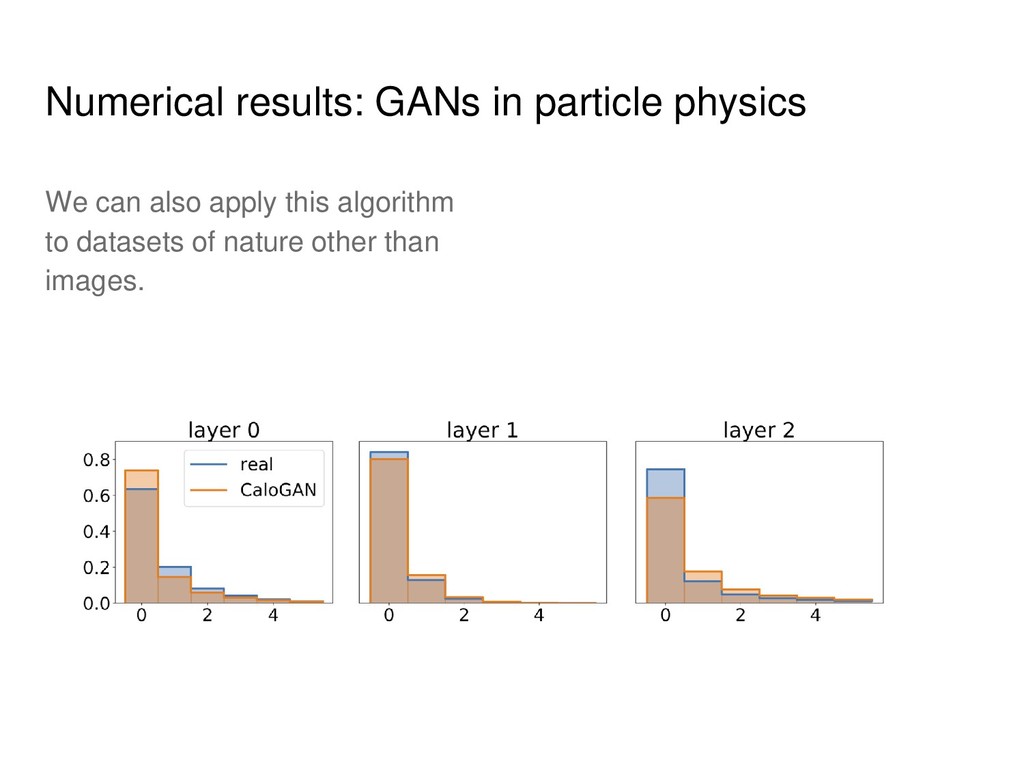
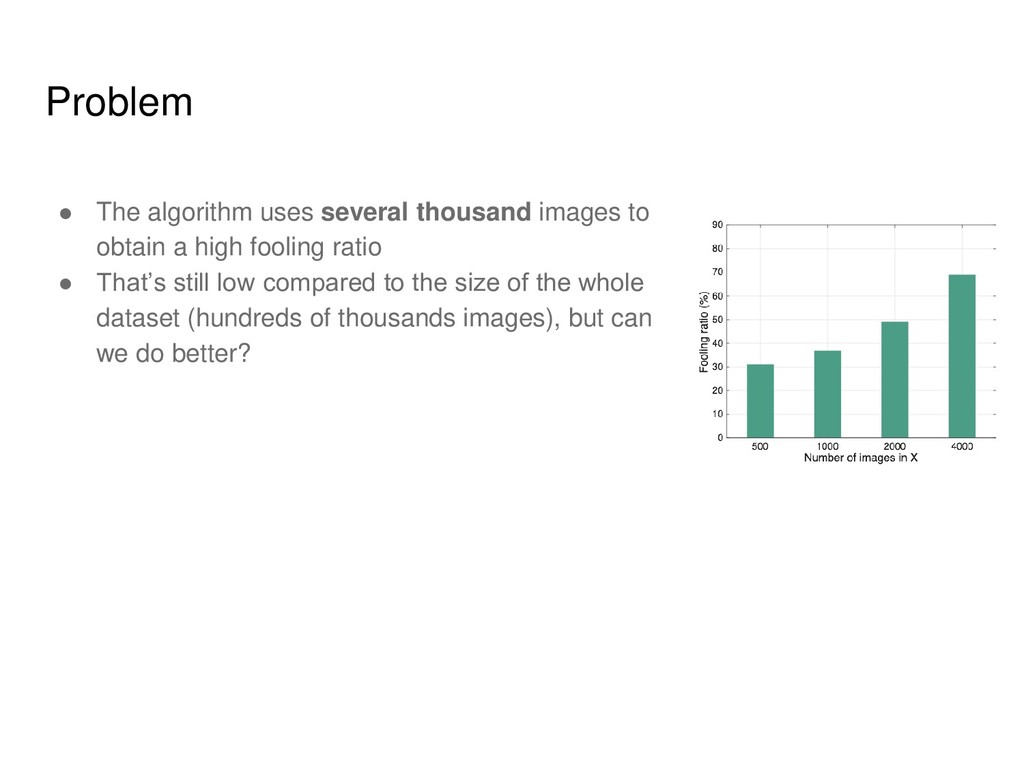
• Mode collapse detection LSGAN DCGAN WGAN WGAN-GP SAGAN CycleGAN InfoGAN AC-GAN MAD-GAN CaloGAN BEGAN Sobolev GAN and many others! GANs are extremely popular distribution learners. Need scalable metric for arbitrary datasets!
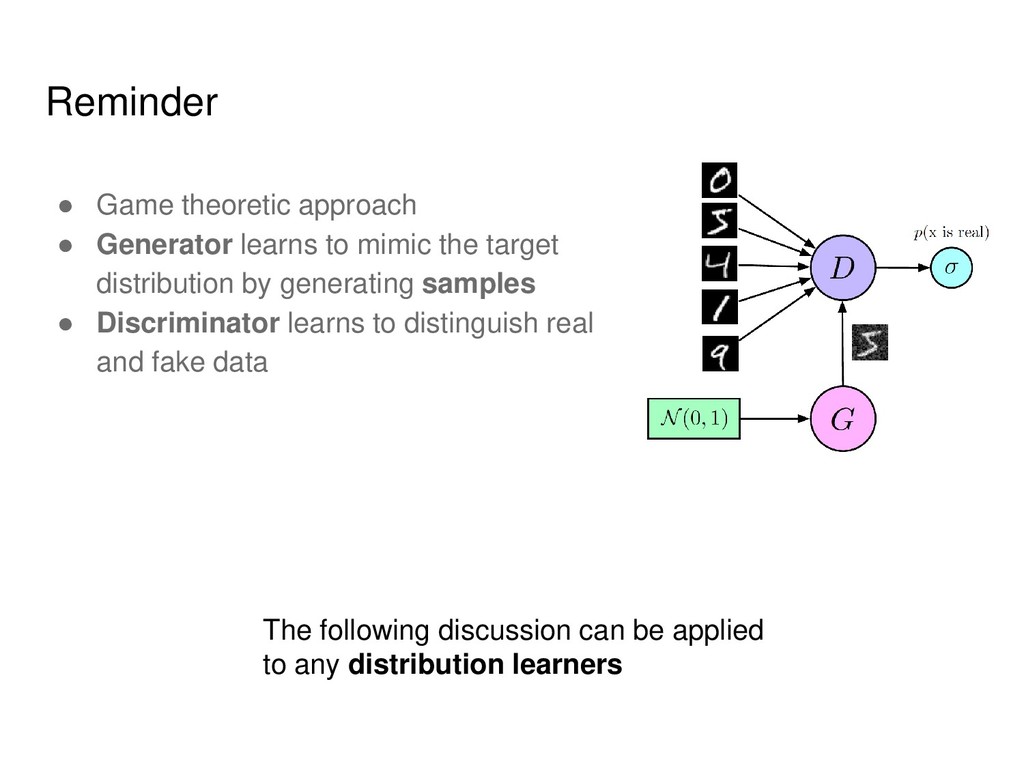
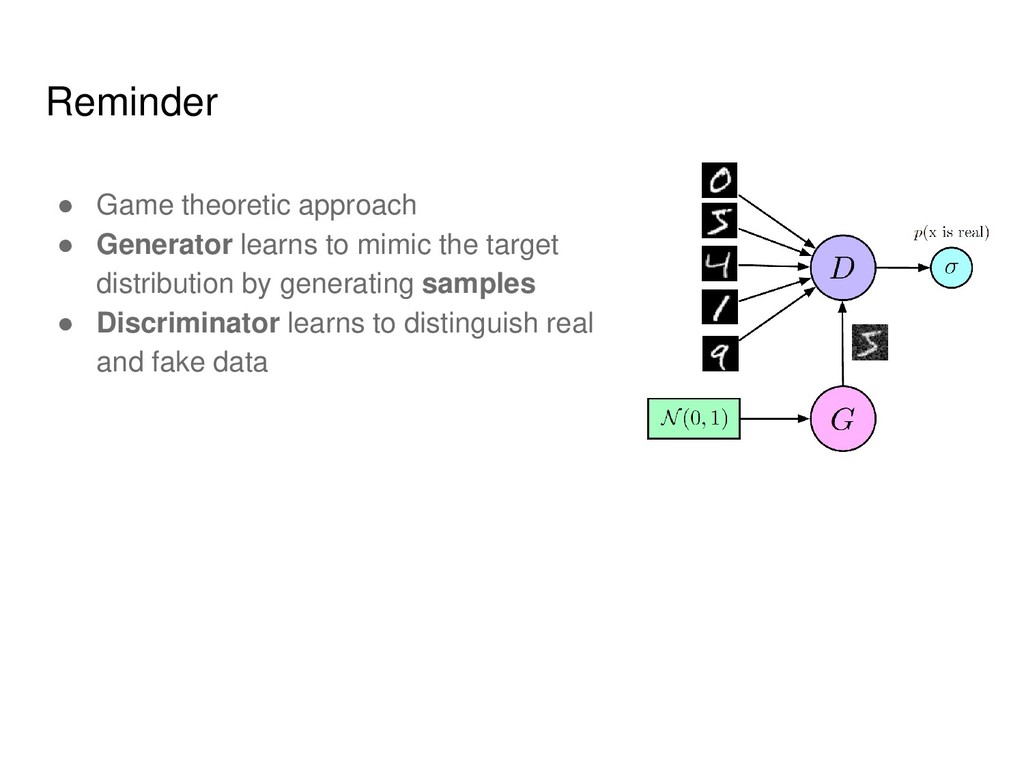
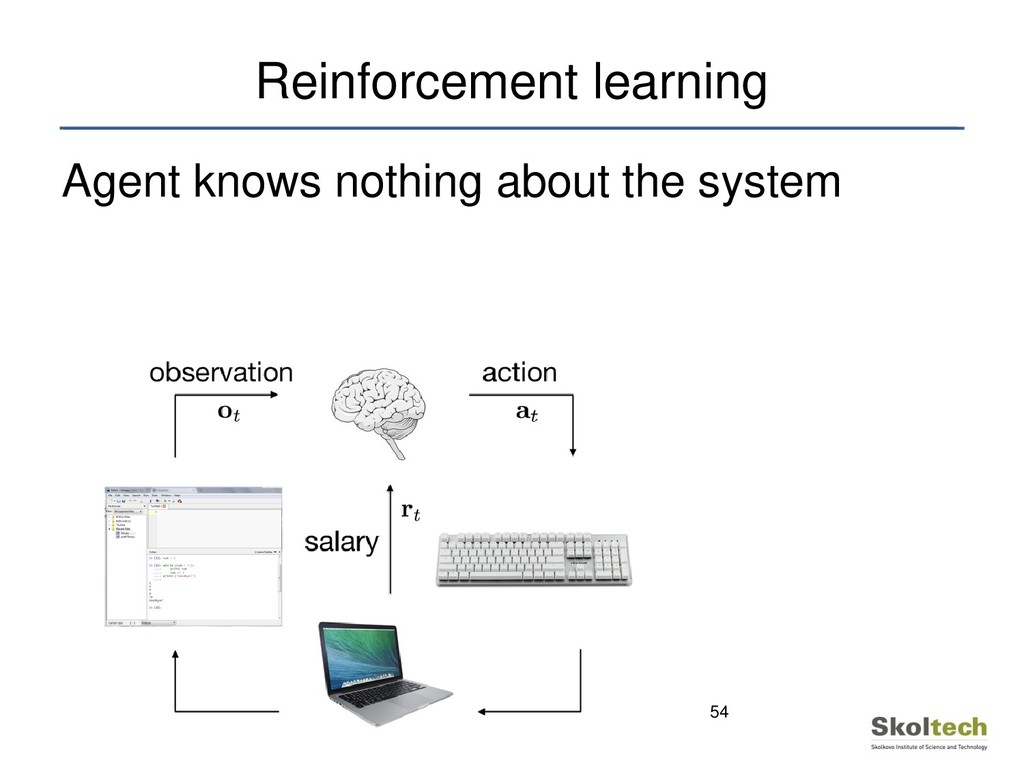
the target distribution by generating samples • Discriminator learns to distinguish real and fake data The following discussion can be applied to any distribution learners
Frechet Inception Distance (FID) • Difficult to use beyond the ImageNet dataset • Not necessarily correlate with human judgement “A Note on the Inception Score” Shane Barratt and Rishi Sharma “Improved techniques for training GANs” Salimans et al.
supported on low-dimensional manifolds embedded in a high-dimensional space. It is reasonable that a good generative model samples images from the same (or a very close) manifold. Are they similar?
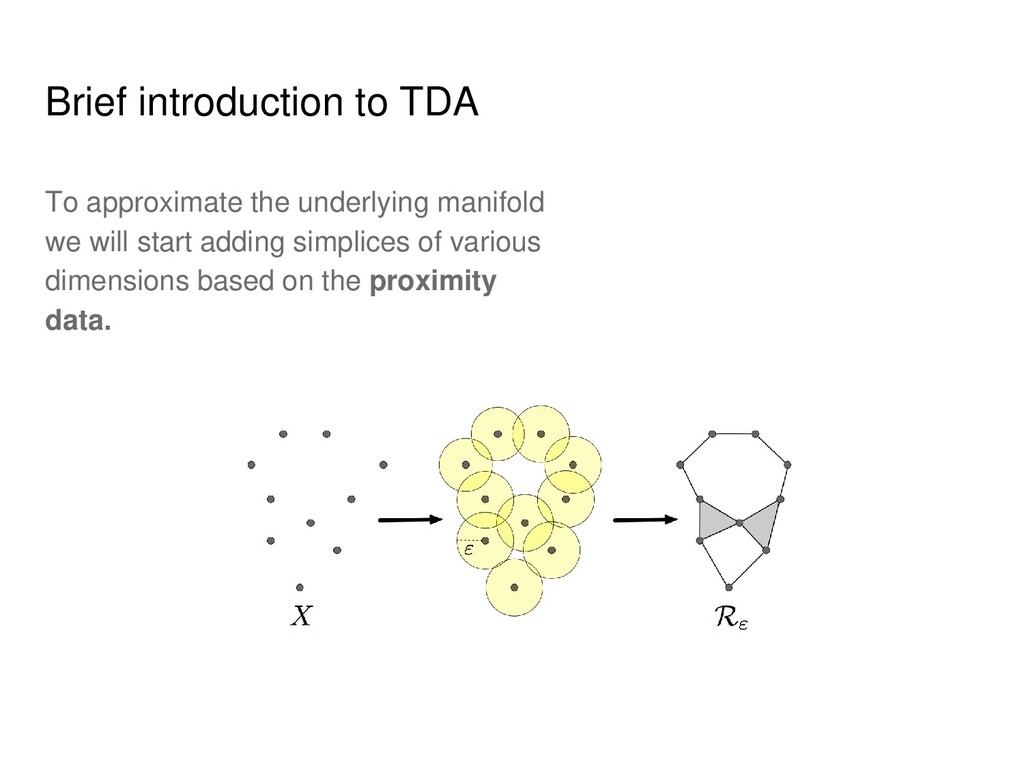
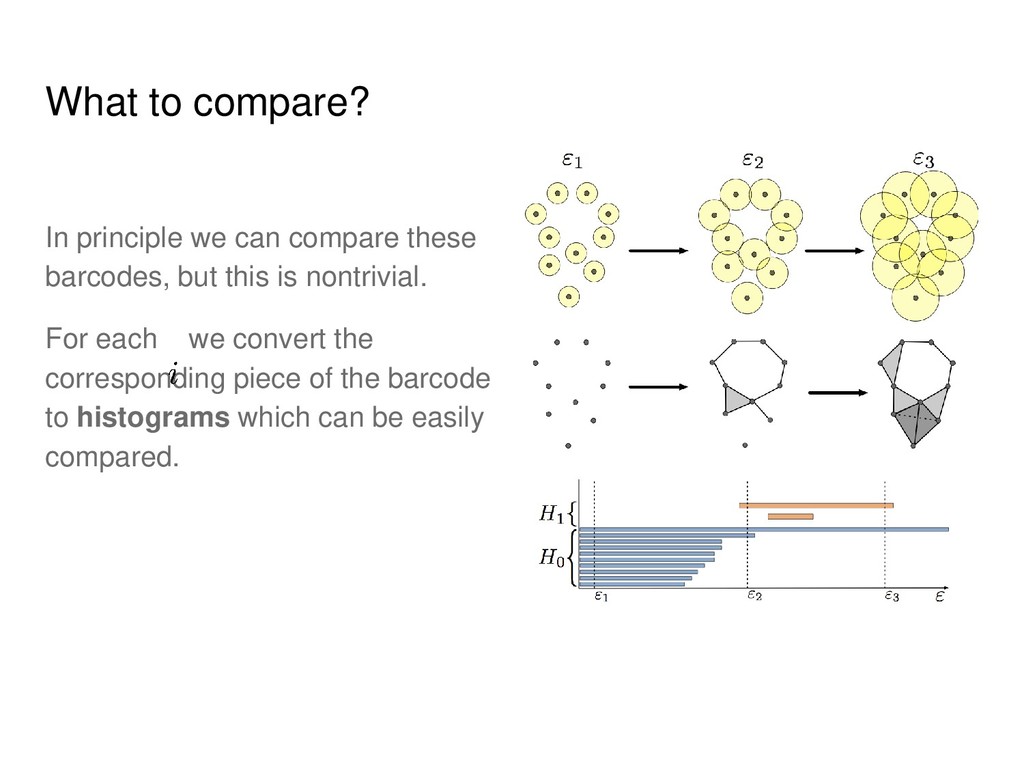
of the data manifolds to measure their similarity. I.e. the manifolds may not coincide precisely, but we want them to have the same shape. Mathematical tool that can be used to describe shape is homology. Also, it can be rather easily computed.
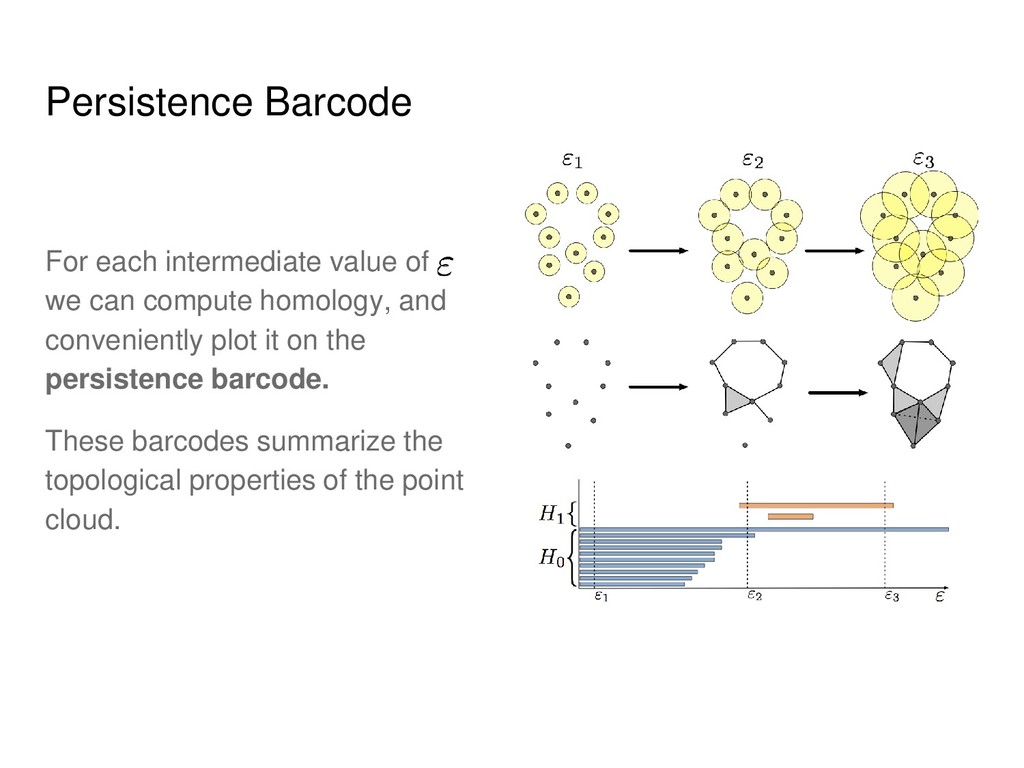
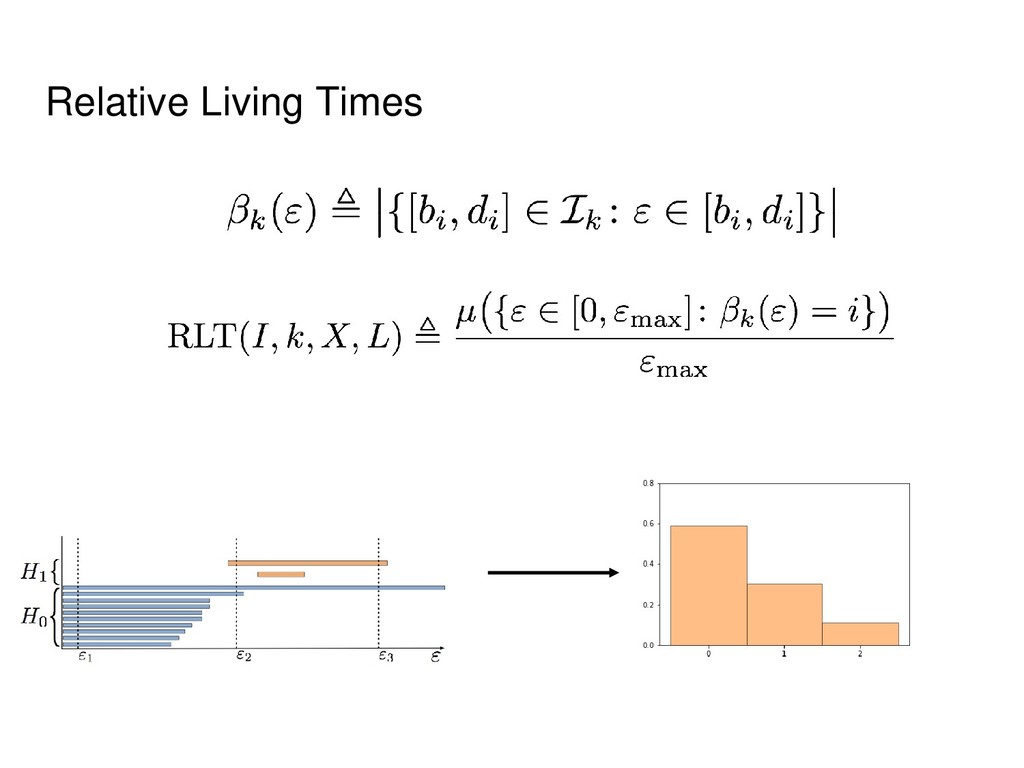
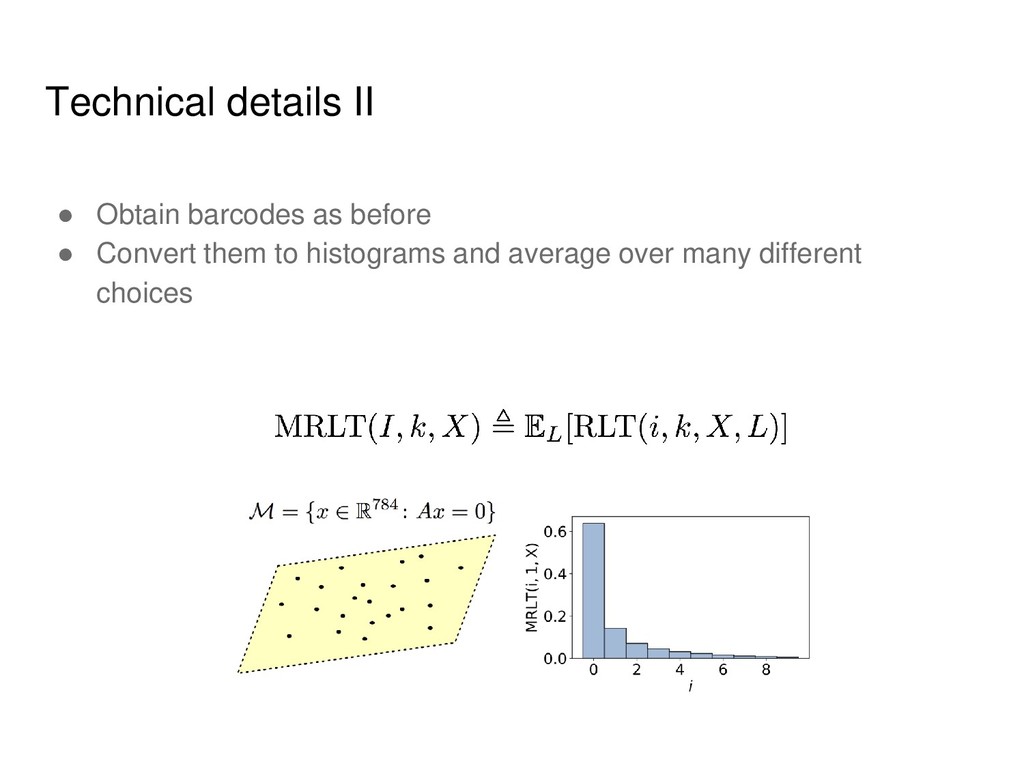
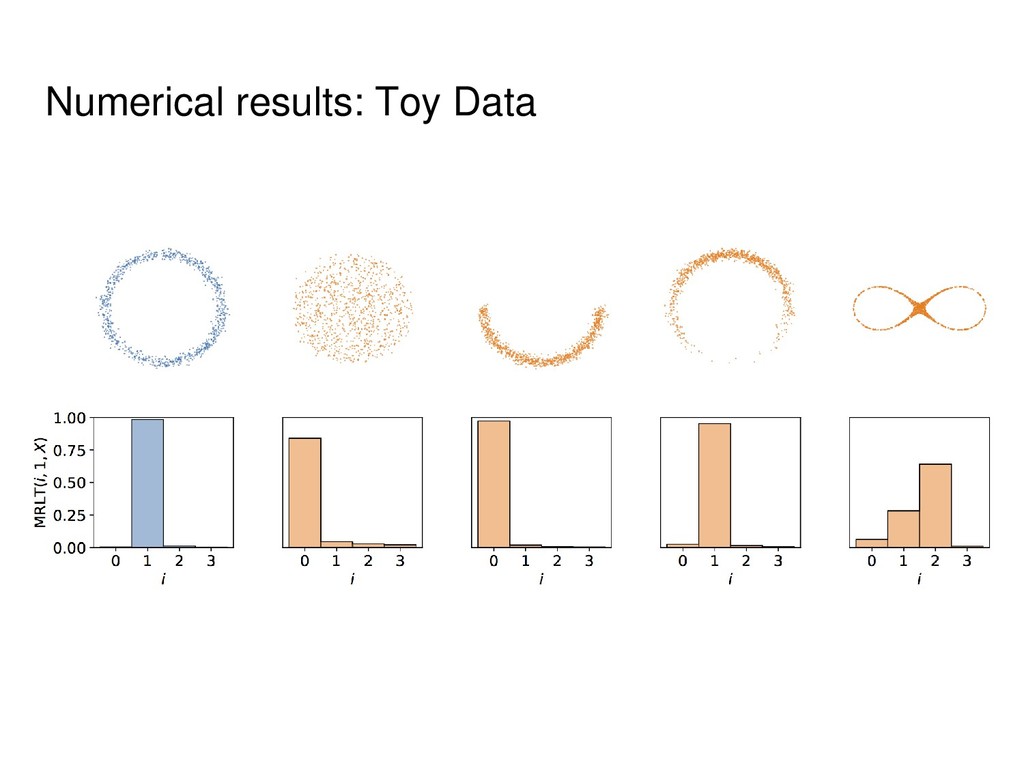
Informally, k-th homology group describes k- dimensional holes in a space. • Strictly speaking, for each k it is a group, but we will use the notions of Betti numbers (ranks of these groups) and homology groups interchangeably. • In the case of point clouds we will obtain distributions rather than exact numbers.
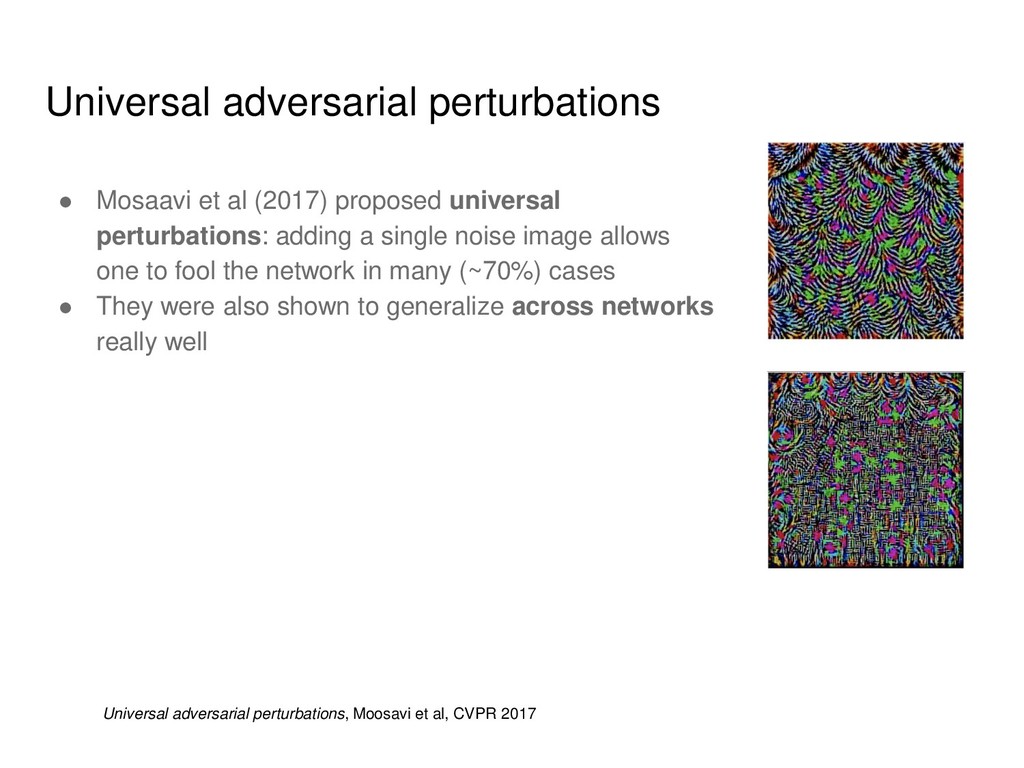
the art networks • Adding a perturbation of a small norm can force misclassification This work is supported by Ministry of Education and Science of the Russian Federation (grant 14.756.31.0001)
perturbations: adding a single noise image allows one to fool the network in many (~70%) cases • They were also shown to generalize across networks really well Universal adversarial perturbations, Moosavi et al, CVPR 2017
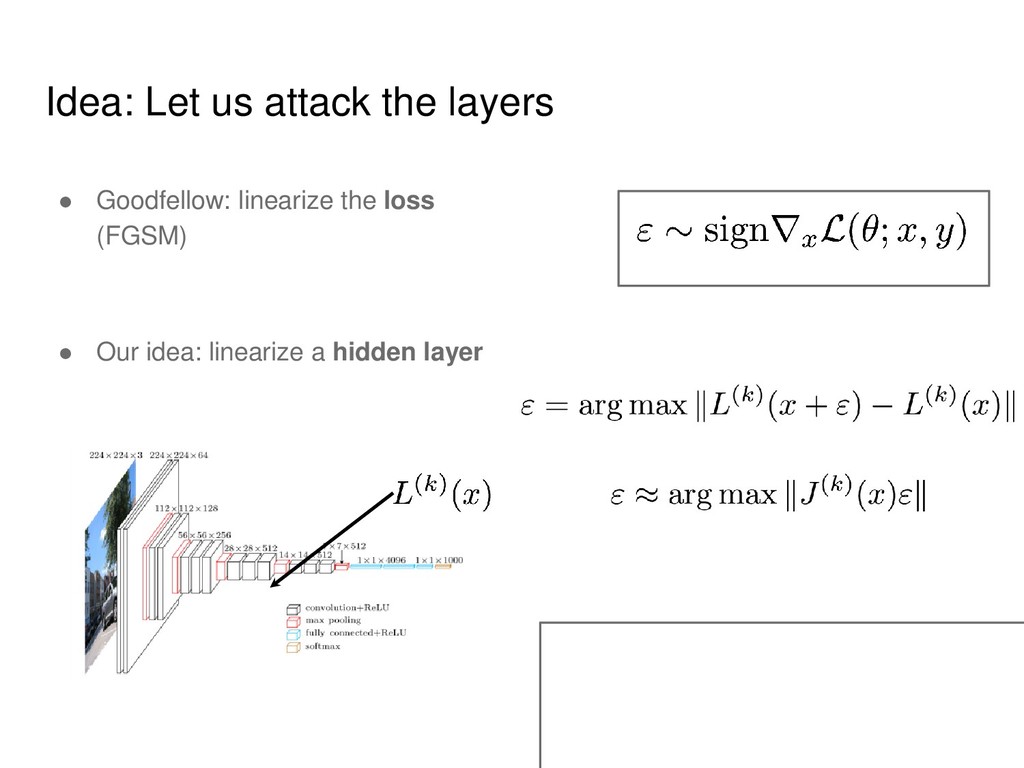
generalized singular vectors • Since Jacobians are extremely large (e.g. 150000 x 1000000) we cannot store them explicitly and have to use iterative methods • Namely, we use Boyd’s generalized power method for it.
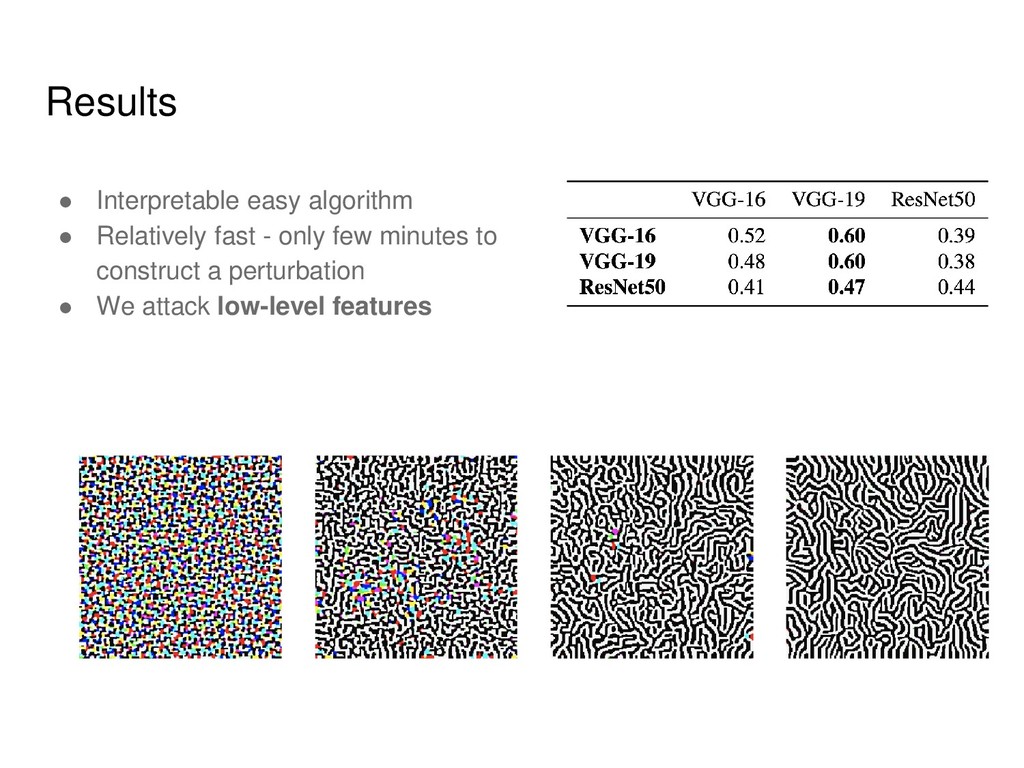
matrix-by- vector product using automatic differentiation • We can attack several images at by stacking Jacobians into a big matrix • Our method needs only 30-40 images to get high fooling ratios (60 %) on the entire dataset
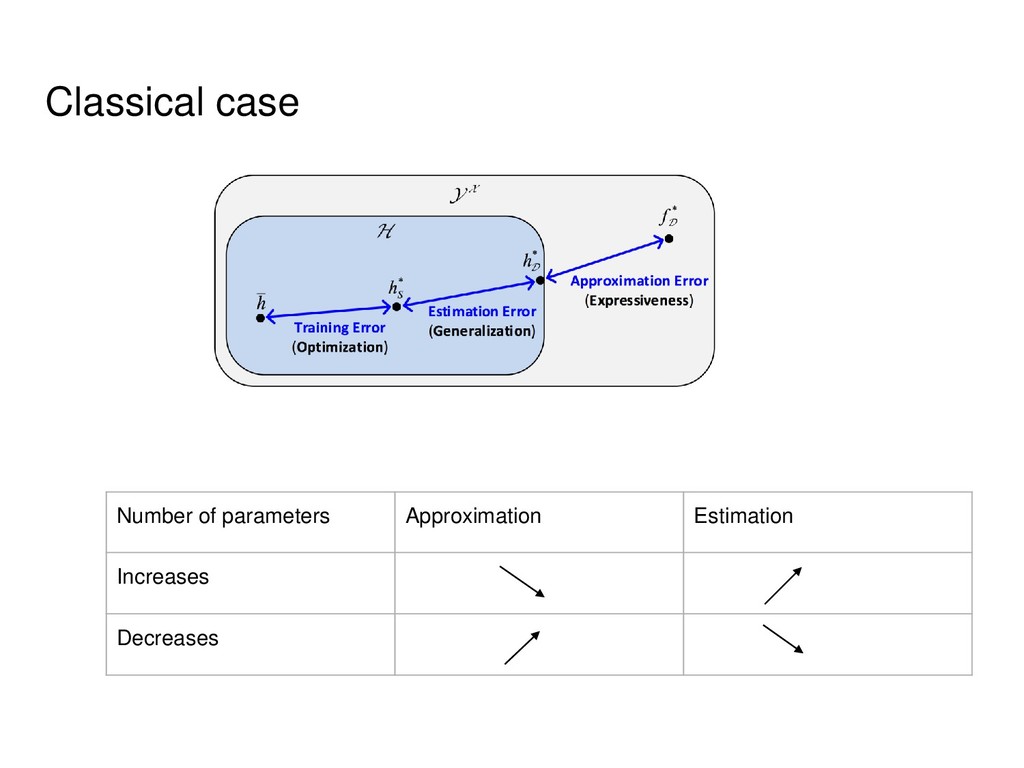
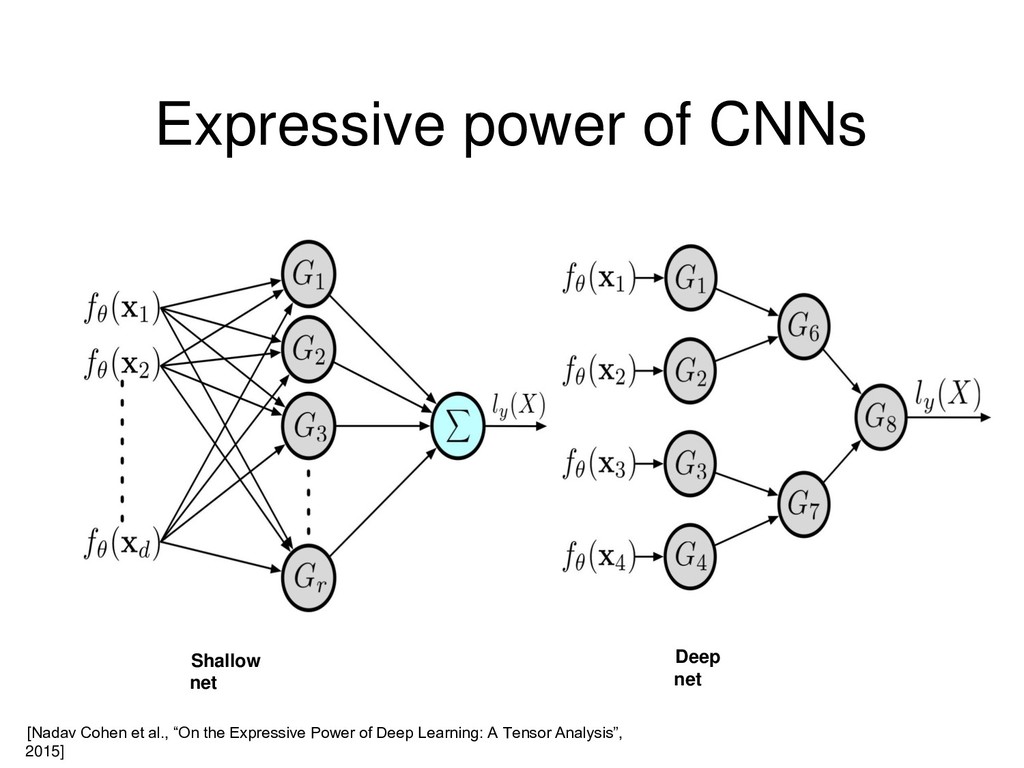
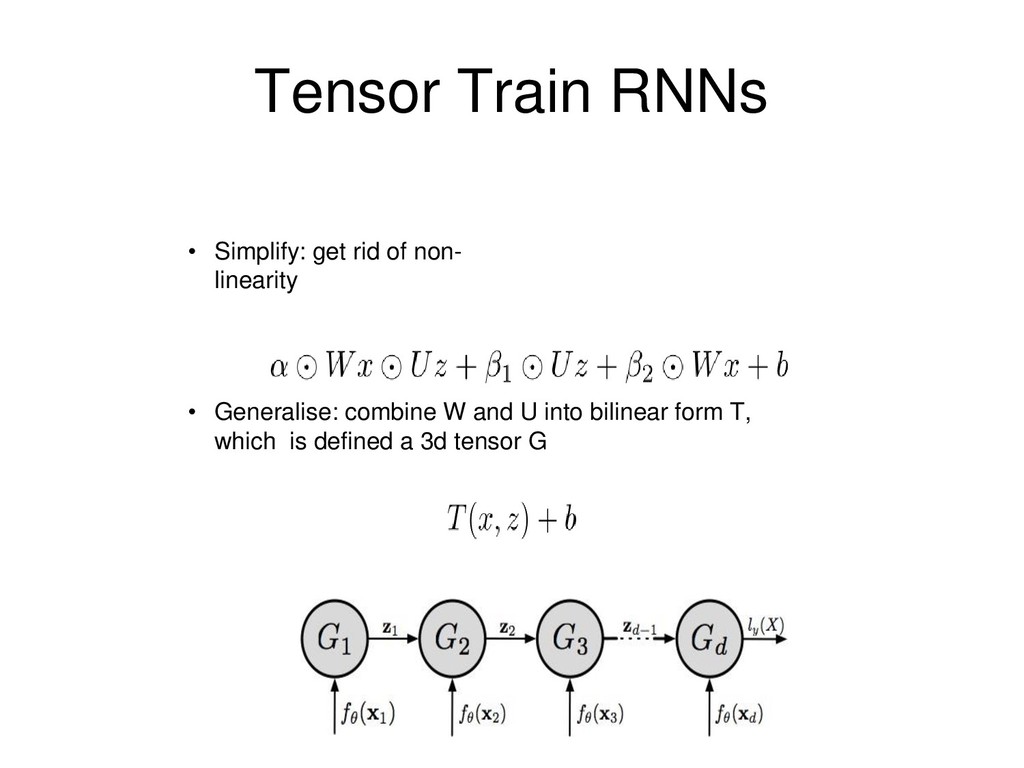
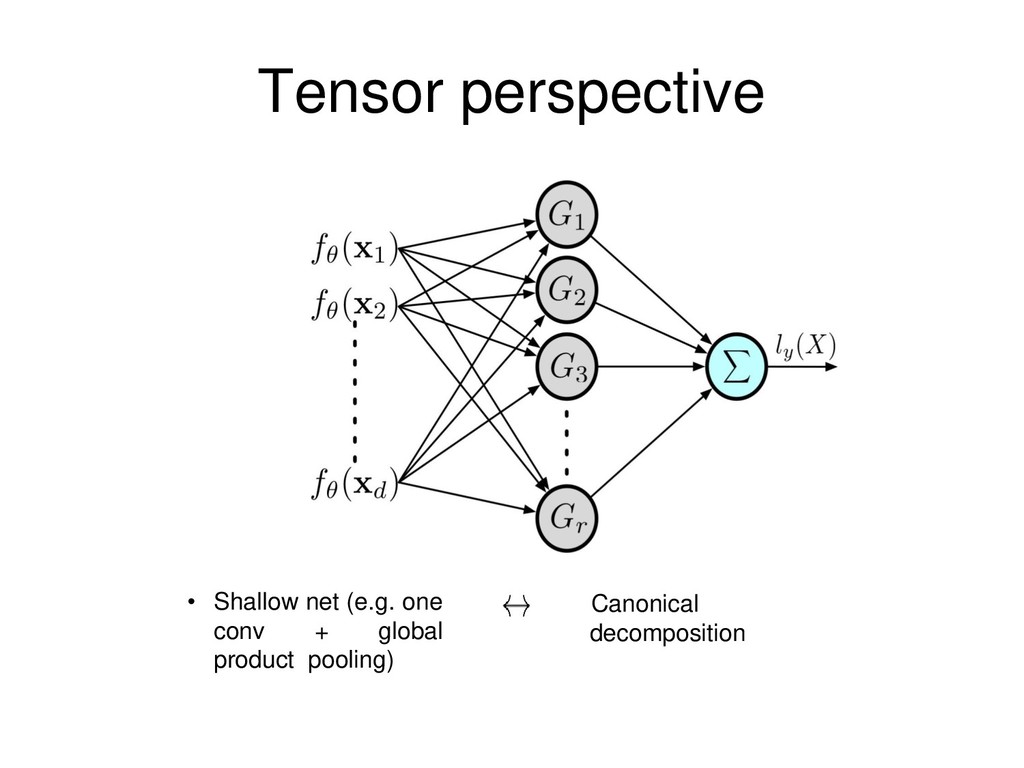
1.0 has exponentially large CP-rank. Interpretation: an RNN (of the form discussed earlier) with random weights can be exactly mimicked with a shallow net only of exponentially larger width. [Valentin Khrulkov, Alexander Novikov, Ivan Oseledets 2018]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
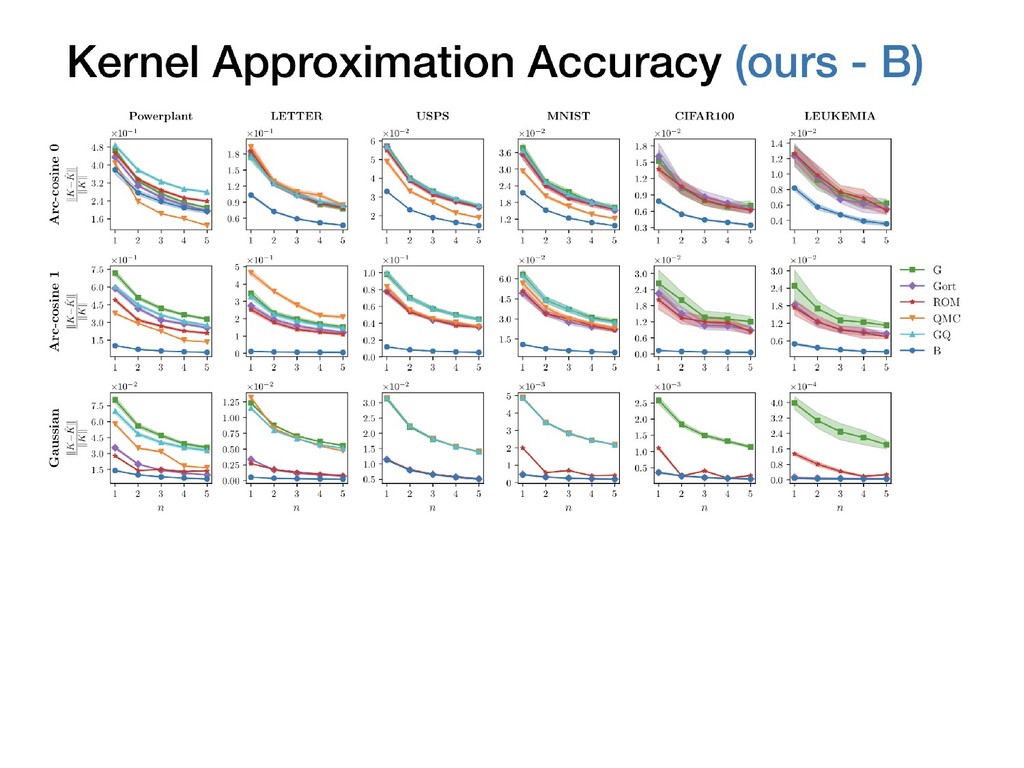
![Random Fourier Features [Rachimi and Recht, 2008] Introduced random Fourier](https://files.speakerdeck.com/presentations/c206eb1ae67749da9e51c7cef6ebeb83/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}