tensors, statistical estimation and tensor decompositions From tensors to Tensor Train Neural Networks (TTNN) AI trends: actions, experimentation, and control in multiple contexts Decision making and context bandits Applications in retail operations
tables, since seminal Pearson and Fisher studies in statistics. Modern trend is multi-modality and multiple contexts: “time - object - context of type A - context of type B” Variety of measurements - events counts or utility level (economic effect, max joy, total reward, and alike). 6W: Who does What for What by What ,Where, and When. Spatial-temporal data: , , ,
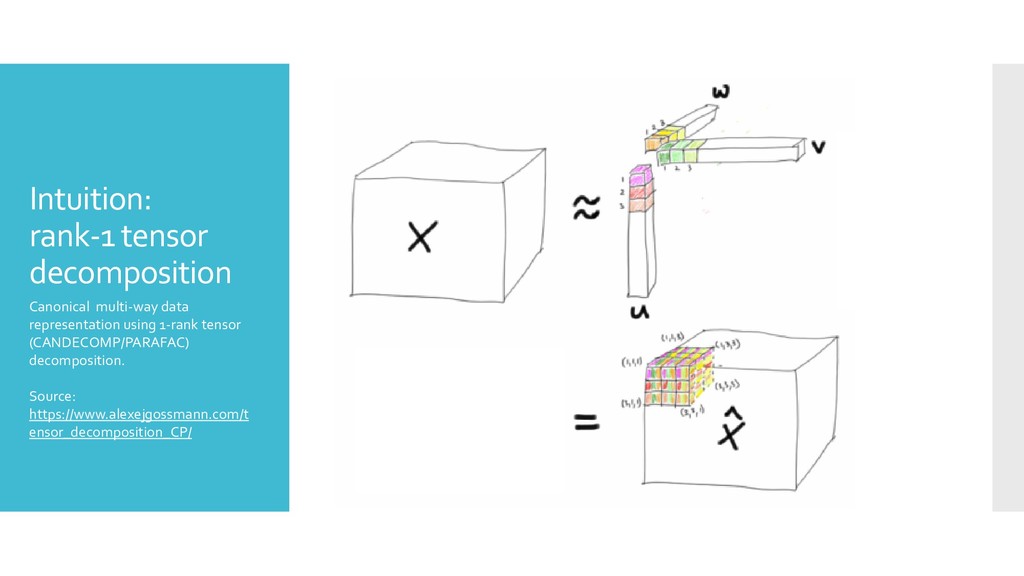
measurements, organized in multi- way arrays (tensors) Estimation problem: Find optimal values of statistical distribution parameters (e.g. in censored Poisson). Estimation is common base for supervised, unsupervised, and reinforcement learning. Statistical estimates are stable and complete (cover all contexts). Statistical models also cover unobserved cases. Goal: Optimal statistical decisions based on comparison of alternatives, in time.
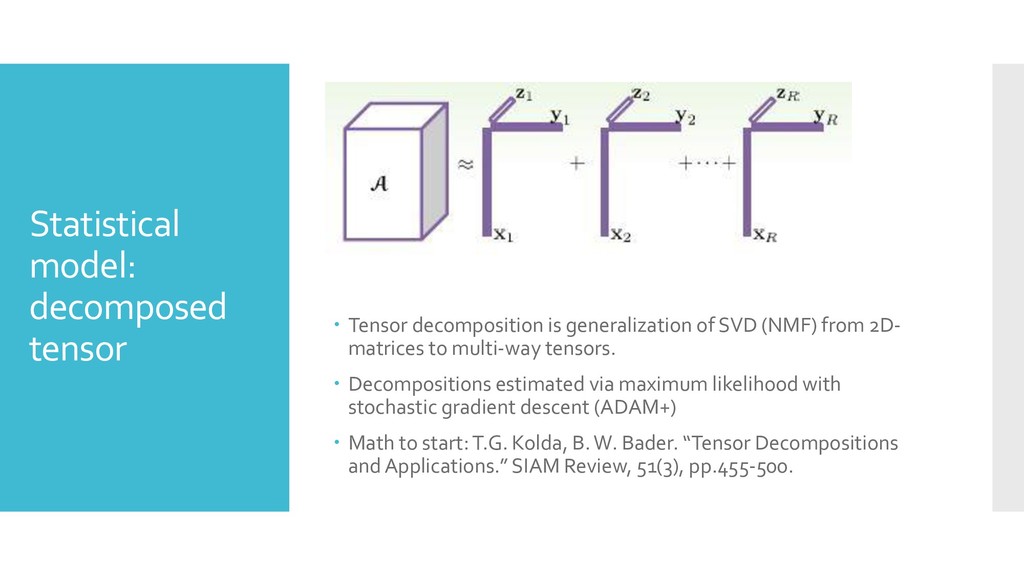
SVD (NMF) from 2D- matrices to multi-way tensors. Decompositions estimated via maximum likelihood with stochastic gradient descent (ADAM+) Math to start: T.G. Kolda, B. W. Bader. “Tensor Decompositions and Applications.” SIAM Review, 51(3), pp.455-500.
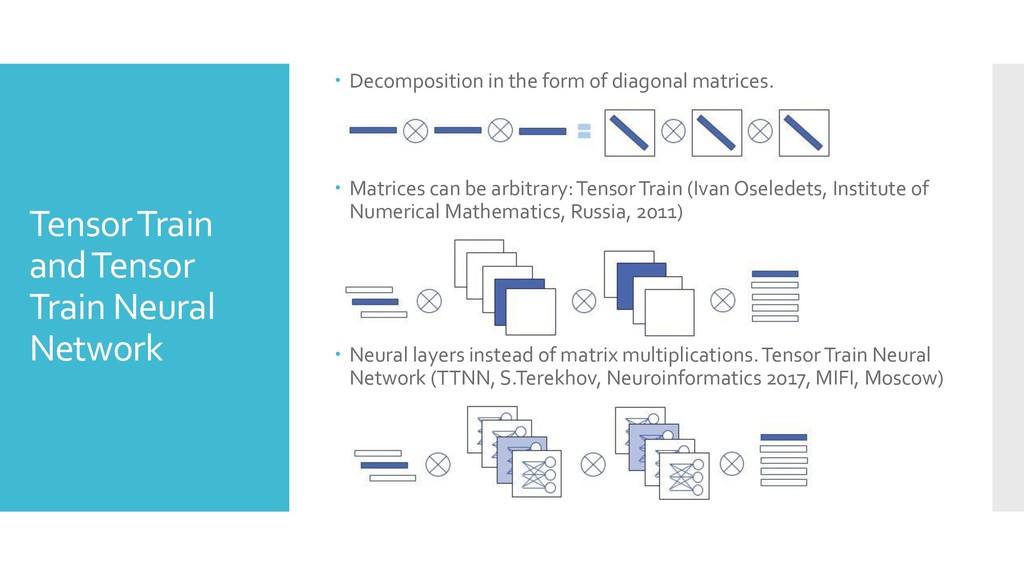
the form of diagonal matrices. Matrices can be arbitrary: Tensor Train (Ivan Oseledets, Institute of Numerical Mathematics, Russia, 2011) Neural layers instead of matrix multiplications. Tensor Train Neural Network (TTNN, S.Terekhov, Neuroinformatics 2017, MIFI, Moscow)
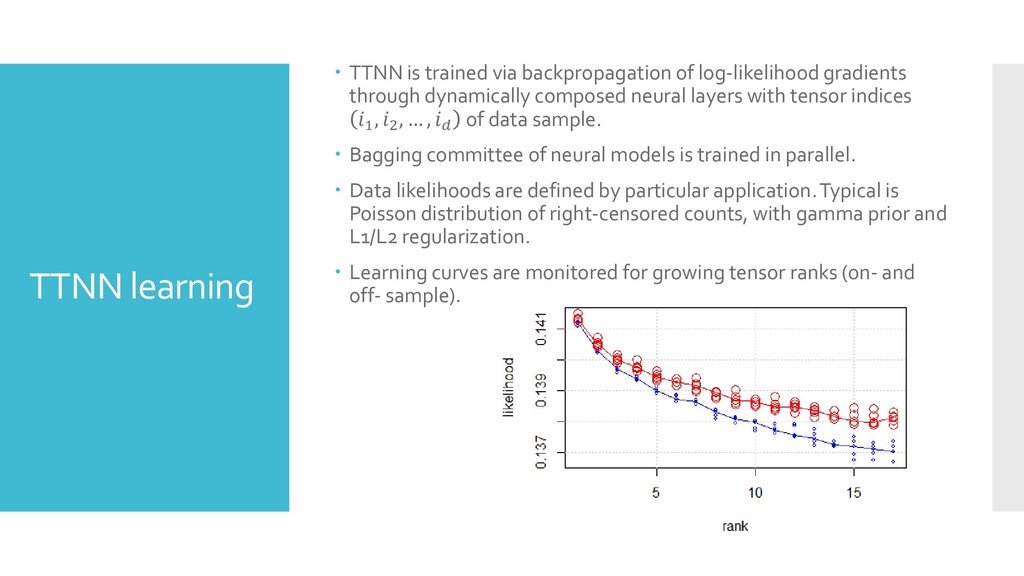
gradients through dynamically composed neural layers with tensor indices 1 , 2 , … , of data sample. Bagging committee of neural models is trained in parallel. Data likelihoods are defined by particular application.Typical is Poisson distribution of right-censored counts, with gamma prior and L1/L2 regularization. Learning curves are monitored for growing tensor ranks (on- and off- sample).
action (aka “bandit arm”) in the face of reward uncertainty [Lai & Robbins]. Set of available choices: v ∈ Unknown distribution of rewards: ; Actions are applied as continuous control process. Only one action can be tried at a time. Potential rewards of all other actions are not revealed. Goal: maximize utility of reward sequence Ԧ = σ . Performance measure w.r.t. theoretically optimal strategy: regret Ԧ ∗ − Ԧ Source: datagenetics.com
in MAB is subject of huge scientific literature, with long list of proposed approaches and algorithms. See, e.g., forthcoming book: A. Slivkins, Introduction to Multi- Armed Bandits, 2019. http://slivkins.com/work/MAB-book.pdf Major idea: importance sampling with partial randomization, based on current estimate of being the best “arm” probability. An algorithm with fixed fraction of randomized exploration: if ∗ is current best estimated option, the next arm is selected with probability ∈ , = 1 − ∗ + Τ . Estimation of rewards utility takes into accounts samples weights, inversely proportional to selection probabilities (“propensity scores”). (Note, in applications the exploration budget is limited!)
control actions are applied in different contexts, . Contexts influence on rewards distributions , ; . We consider tensor contexts = 1 , 2 , … , defined by combinations of tensor indices. Let’s extend the set of dimensions and include +1 = for the decision variable. Extended tensor represents estimates of the reward distribution parameters = 1 , 2 , … , +1 . The Tensor Train Neural Networks is learned from censored Poisson counts as rewards, with propensity scores. Stochastic optimization is based on weighted resampling, with special measures for low probability samples.
retail operations, most comfortable prices are implemented in the form of discount packages. Control problem for the retailer is to assign the portfolio of discounts to particular goods and stores, in time. Allowed are only some packages in some stores. Each package is to be offered in context of {day, store, SKU}. Observations: stock and sales flows. What to show, where, and when? Solution: tensor context bandits with pre-optimized limits of the experimentation budget and of the frequency of price changes in each store.
Evrim Acar, Daniel M. Dunlavy, Tamara G. Kolda, Morten Mørup. Scalable Tensor Factorizations with Missing Data. 2010. URL: http://www.cs.sandia.gov/~dmdunla/publications/AcDuKoMo10.pdf Ivan Oseledets, Eugene Tyrtyshnikov. TT-cross approximation for multidimensional arrays. Linear Algebra and its Applications 432 (2010) 70–88. URL: http://www.mat.uniroma2.it/~tvmsscho/papers/Tyrtyshnikov5.pdf John Langford and Tong Zhang. The epoch-greedy algorithm for contextual multi- armed bandits. In Advances in Neural Information Processing Systems 20, pages 1096–1103, 2008. URL: https://papers.nips.cc/paper/3178-the-epoch-greedy- algorithm-for-multi-armed-bandits-with-side-information S.A. Terekhov. Tensor decompositions in statistical decisions. "Artificial intelligence problems and approaches" (In Russian), Moscow, 14 Mar 2018. p.53-58. URL: http://raai.org/library/books/Konf_II_problem-2018/book1_intellect.pdf Robin Allesiardo, Raphael Feraud, Djallel Bouneffouf. A Neural Networks Committee for the Contextual Bandit Problem. arXiv:1409.8191 [cs.NE], 29 Sep 2014. URL: https://arxiv.org/abs/1409.8191
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо! Терехов Сергей Александрович «Сеть Связной» [email protected]](https://files.speakerdeck.com/presentations/66d3a1b2a74a409a984085d3962f7a0a/slide_17.jpg){kind=link}