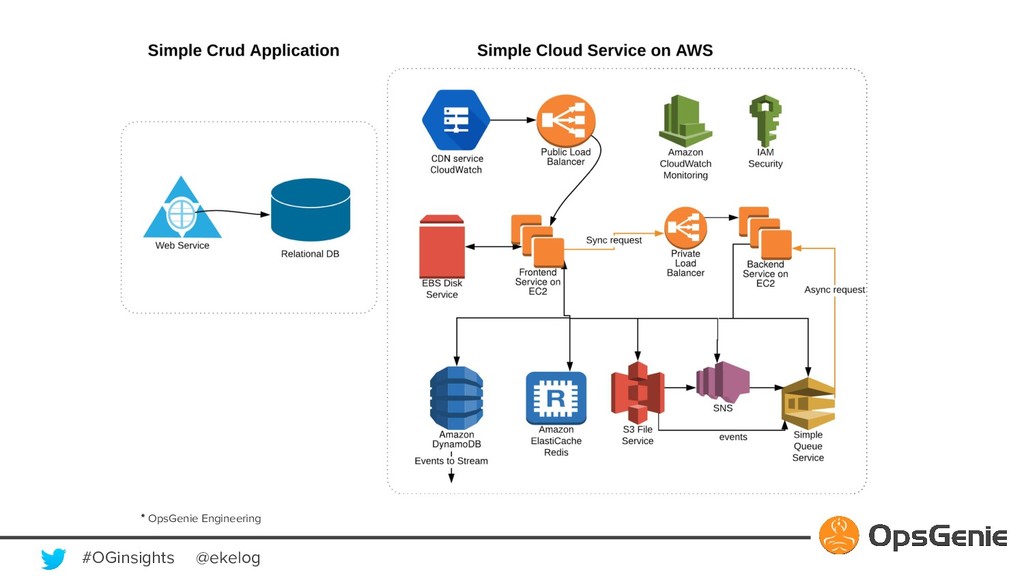
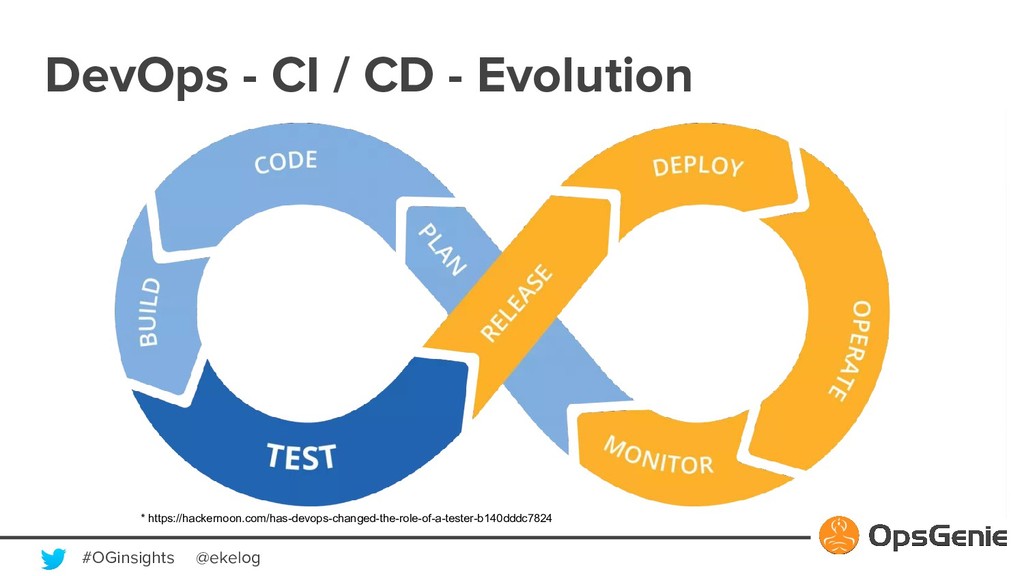
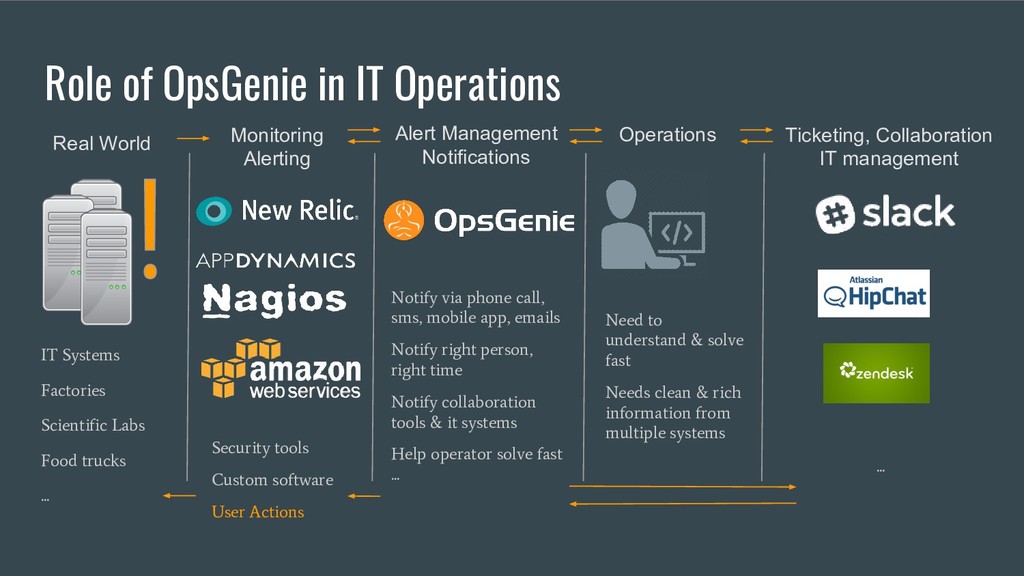
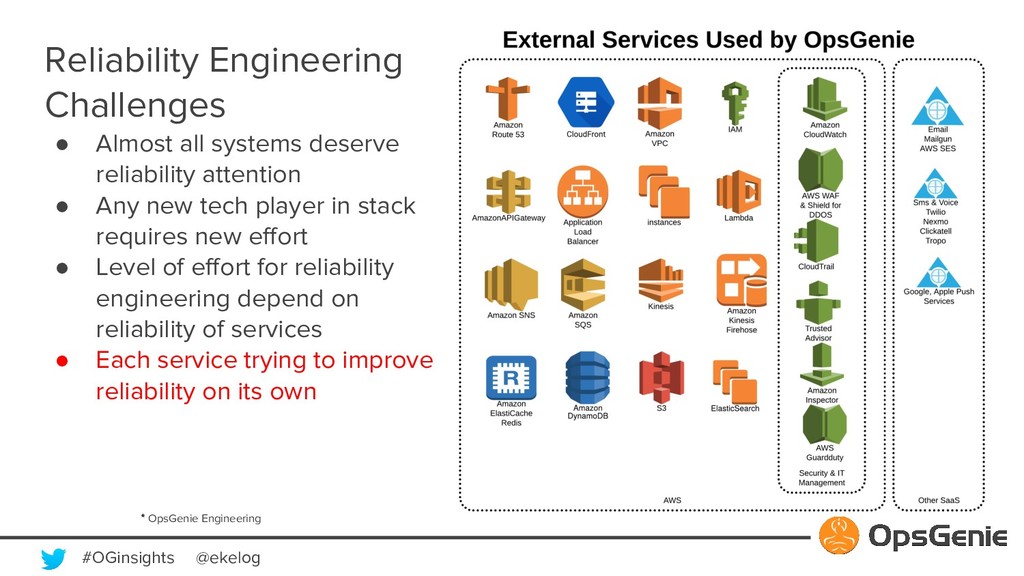
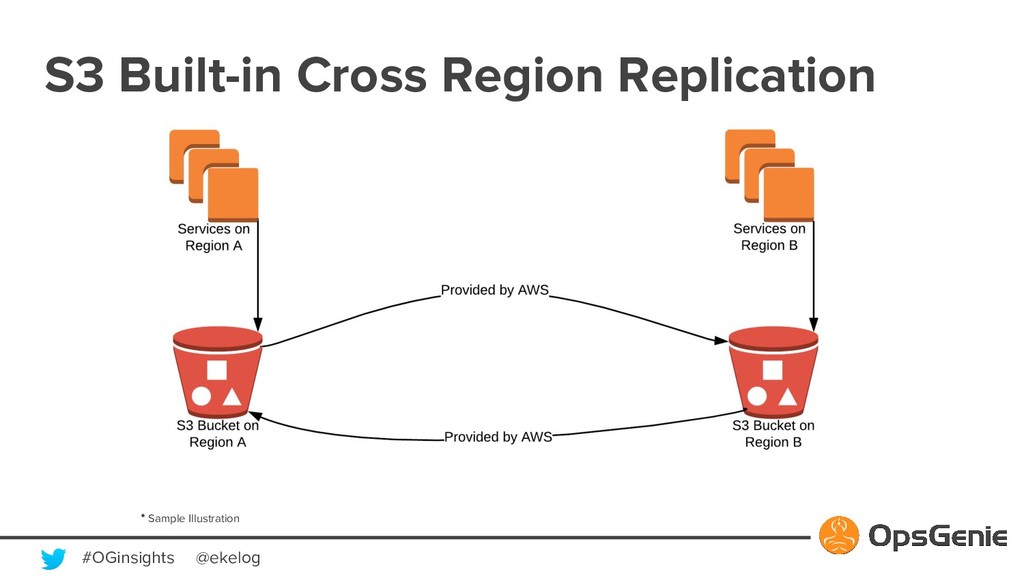
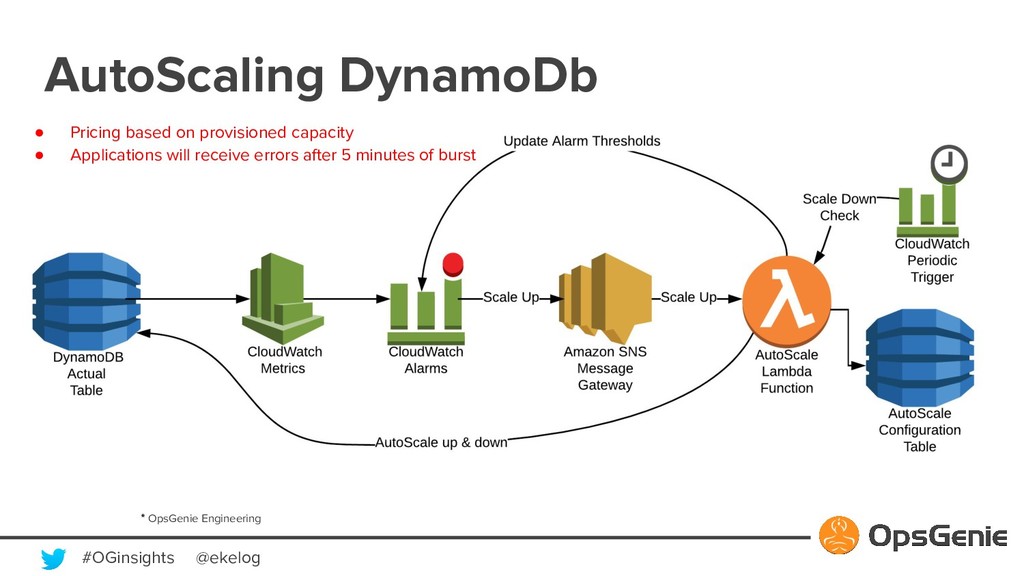
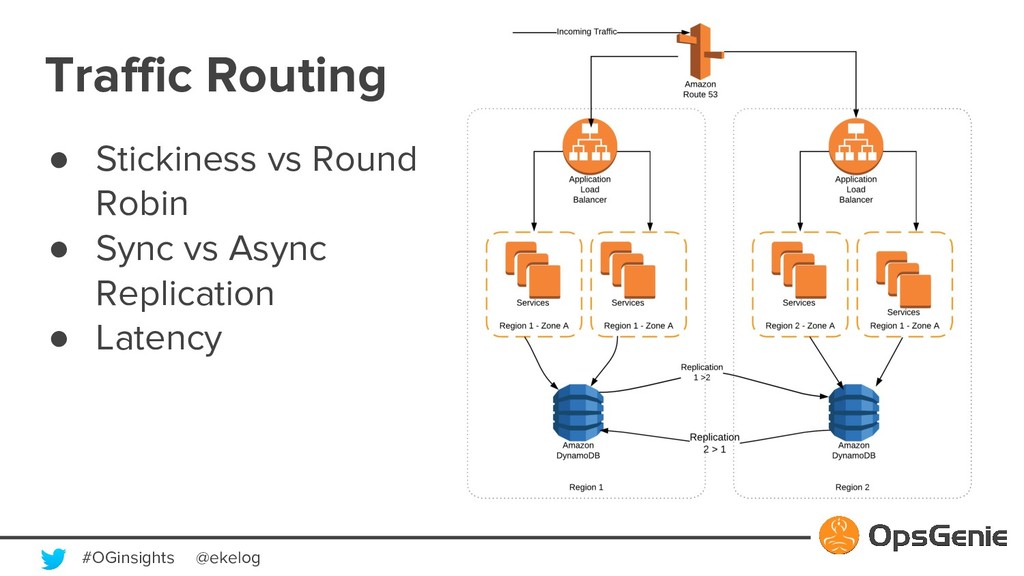
Modern software building blocks allows application development faster than ever, allows developers to focus more on higher level benefits, faster business growth, higher levels of reliability, scalability, security. A typical SaaS solution shall make use of many new modern tools, which brings additional complexity and management. This modern and complex world has a great demand for monitoring and observability, so that developers shall manage many systems fast and easily. Monitoring systems expected to be more available than actual systems. OpsGenie is a critical incident and alert management SaaS solution. We will be demonstrating how OpsGenie makes use of AWS services EC2, Lambda, DynamoDB, SNS, SQS, S3, CloudFront to provide an always available multi region and multi zone architecture, will dive into reliability challenges and demonstrate how AWS addresses these challenges.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
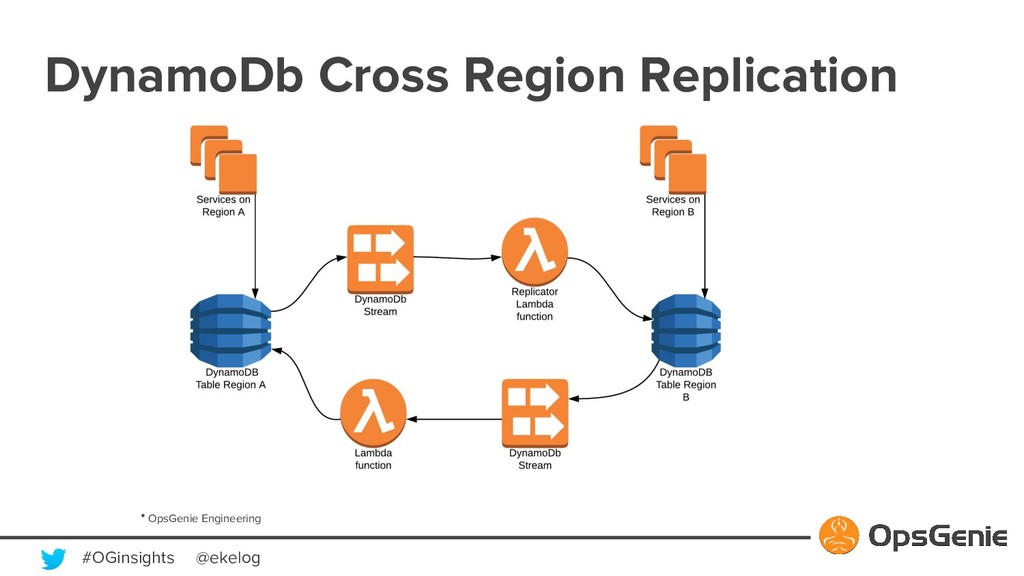{kind=link}
{kind=link}
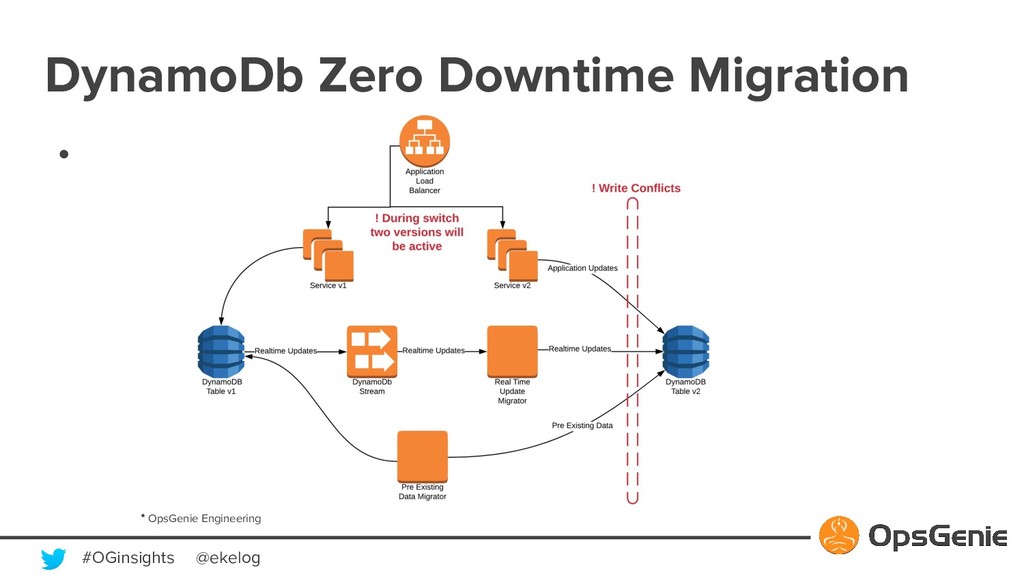{kind=link}
{kind=link}
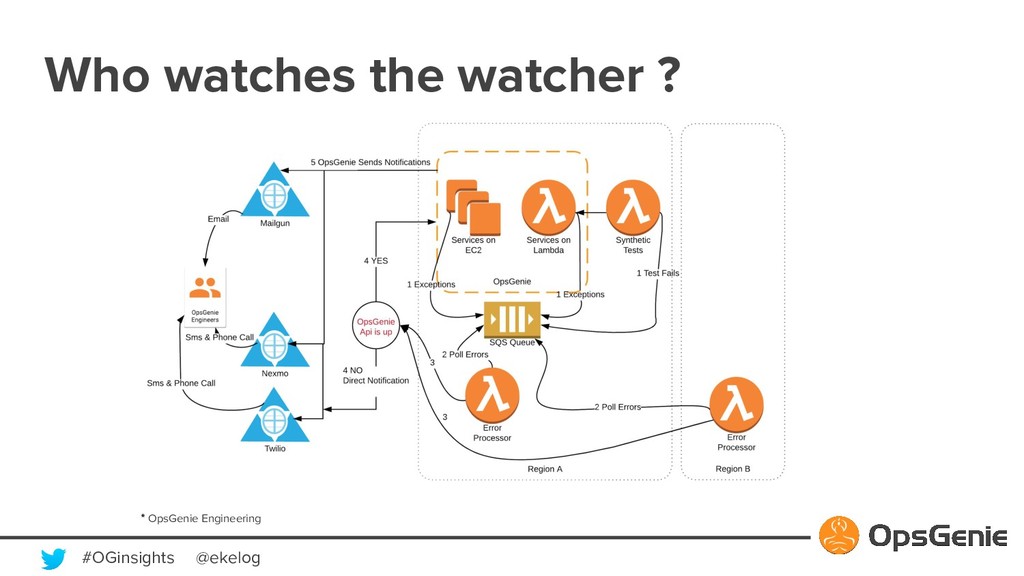{kind=link}
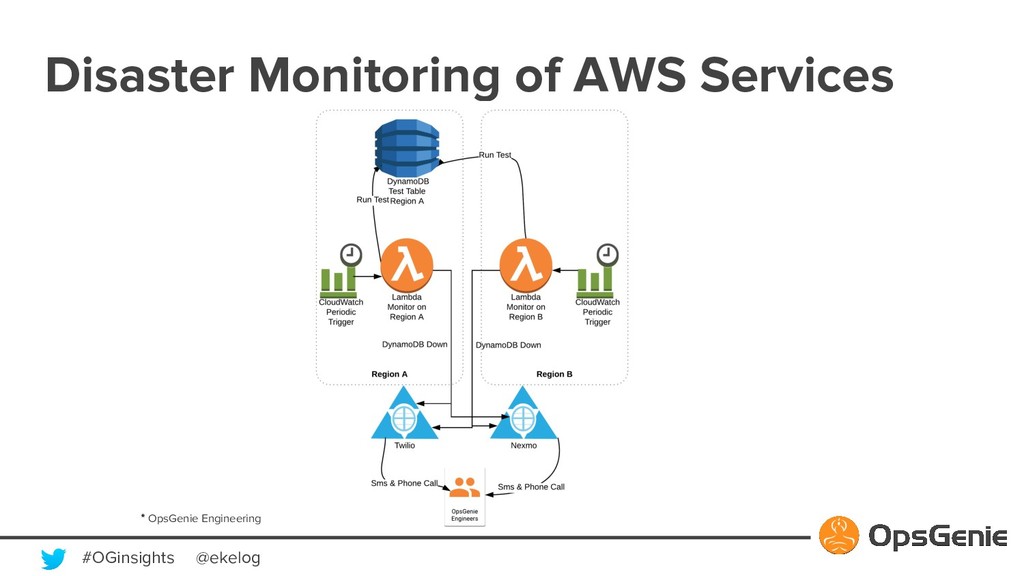{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}