Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Japanese only] Data Analysis and Data processi...
Search
OZAWA Tsuyoshi
January 26, 2016
Programming
620
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Japanese only] Data Analysis and Data processing framework
A talk at NTT Docomo Innovation Village.
OZAWA Tsuyoshi
January 26, 2016
More Decks by OZAWA Tsuyoshi
See All by OZAWA Tsuyoshi
decode17
oza
18
5.2k
Other Decks in Programming
See All in Programming
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
170
symfony/aiとlaravel/boost
77web
0
140
共通化で考えるべきは、実装より公開する型だった
codeegg
0
260
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
270
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
130
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
230
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
260
Foundation Models frameworkで画像分析
ryodeveloper
1
120
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
520
Featured
See All Featured
Unsuck your backbone
ammeep
672
58k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Un-Boring Meetings
codingconduct
0
350
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
It's Worth the Effort
3n
188
29k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Tell your own story through comics
letsgokoyo
1
1k
Music & Morning Musume
bryan
47
7.3k
Transcript
Copyright©2016 NTT corp. All Rights Reserved. データ解析フローから見るデー タ処理基盤の使いどころ @NTT ドコモイノベーションビレッジ
小沢健史 NTT ソフトウェアイノベーションセンタ 2016/1/26
2 Copyright©2016 NTT corp. All Rights Reserved. • 小沢健史(おざわつよし) •
Research Engineer @ NTT • Apache Hadoop コミッタ(主要開発者) • 著 • “Hadoop 徹底入門 2nd Edition” Chapter 22(YARN) • gihyo.jp にて連載中! Hadoop はどのようになぜ動くのか • 第13回 Hadoopの設計と実装~並列データ処理系Hadoop MapReduce[1] • 第14回 Hadoopの設計と実装~並列データ処理系Hadoop MapReduce[2] • 第15回 リソース管理基盤 YARN • 第16回 並列データ処理基盤 Tez • http://gihyo.jp/admin/serial/01/how_hadoop_works About me
3 Copyright©2016 NTT corp. All Rights Reserved. • なぜデータ解析を行うのか •
ビッグデータは必要? • データ解析の利活用事例 • 大規模データ解析の事例: Netflix • データ解析のフローと分析用ミドルウェア • 様々なデータ分析基盤を使う理由 • Apache Hadoop の概要 • Apache Hadoop の原型:Google MapReduce が生まれた理由 • いつ Hadoop を使うべきか • Hadoop 以外のデータ処理基盤 • RDBMS • MySQL, PostgreSQL • Python 由来の処理基盤 • Numpy, pandas • MapReduce 由来の処理基盤 • Spark, Tez • 並列データベース由来の処理基盤 • RedShift, BigQuery, Presto, Impala 目次
4 Copyright©2016 NTT corp. All Rights Reserved. • 詳細については「データ解析の実務プロセス入門」 (森北出版)がオススメ
• 「データ解析の実務プロセス入門」より, 「データ解析により何ができるか」を引用 1. 状況把握ができる • 例: ゲームの離脱率 2. 推定ができる • 入力: 現状保持しているデータ 出力: 欠損値の値 • 現状のデータから欠損している情報をある程度の精度で算出 3. 予測やシミュレーションができる • 入力: 過去のデータ 出力: 未来の傾向 4. 反復と再現ができる • 規則性の抽出(こういう傾向のユーザはこういう行動をとる,など) 5. 裏付けができる なぜデータ解析を行うのか
5 Copyright©2016 NTT corp. All Rights Reserved. • データのサイズを大きくすることで効果があるかどうかは データ解析の対象および目的に依存
• 基本的には業務改善が多くの場合の目的であるため, 投資対効果は常に意識すべきポイント →データが大きければこその利点・欠点を良く見極める必要がある • 利点 • データ解析を使いこなすことによる大幅な業務改善など • 欠点 • ハードウェアコストの増加,分析内容の高度化に伴う人材の不足, データ解析のための運用コストの増加など • 具体例: • 画像認識のタスクにおいて、深層学習を用いて大量の画像データを入 力としてとることで認識精度が大幅に向上 ビッグデータは必要?
6 Copyright©2016 NTT corp. All Rights Reserved. • Netflix •
世界有数のビデオ配信サービス • 会員数 6500万人 • 主な収入は購読費 → ユーザが新規登録すると収入増, 解約すると収入減,継続すると収入維持 • 大黒柱となる差異化技術は「データ解析」 • データ解析により差異化を行っている • ユーザ視聴履歴から次に見たいであろうデータを予測 • ISPの速度状況などを保存しておき,分析を行うことで快適な UX を実 → 快適さ,魅力的なコンテンツの増加が収入維持および増加に有効であると 考えられる • Strata+Hadoop World NewYork 2015では,Netflix のDaniel 氏が 世界有数のデータ解析基盤に関して発表 (Integrating Spark at Petabyte Scale) • データは Amazon S3 に 20PB 以上保存され, その10%に毎日アクセス • 100人の分析者,350人の分析基盤ユーザ • 個人的には Hadoop の意見交換などができました • 本発表では,データ解析のシステムによる自動化ができる部分について 焦点をあてて発表 データ解析の利活用事例
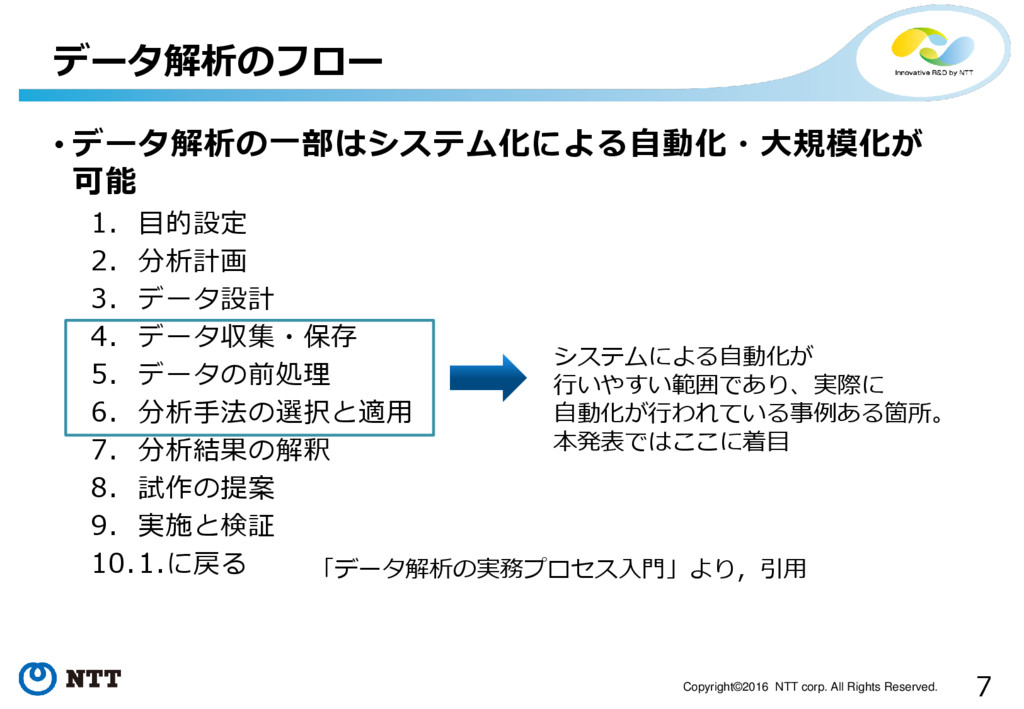
7 Copyright©2016 NTT corp. All Rights Reserved. • データ解析の一部はシステム化による自動化・大規模化が 可能
1. 目的設定 2. 分析計画 3. データ設計 4. データ収集・保存 5. データの前処理 6. 分析手法の選択と適用 7. 分析結果の解釈 8. 試作の提案 9. 実施と検証 10.1.に戻る データ解析のフロー システムによる自動化が 行いやすい範囲であり、実際に 自動化が行われている事例ある箇所。 本発表ではここに着目 「データ解析の実務プロセス入門」より,引用
8 Copyright©2016 NTT corp. All Rights Reserved. • データの分析では, 分析計画を立てた上でデータの収集,保存をしたあとに
前処理を行った上で分析手法を適用することが可能 • 収集 • なぜ必要か: データ分析にはデータが必要であるため • やること 分析計画・データ設計を基に、データを可能な限り処理しやすい形で転送 • 保存 • なぜ必要か: 「収集」フェイズで収集したデータをデータ分析では何度も利用して解析を行うため • やること:データを保存する • 前処理 • なぜ必要か: データ処理ミドルウェアが解釈できる形でデータを渡す必要があるため • やること:分析ツールに沿った形にデータを変換する • 分析手法の選択と適用 • なぜ必要か: 4ページ目を参照 • やること: 分析ツールなどを利用し、計画に沿った形で分析手法を実際に適用 収集・保存・前処理・分析手法の選択と適用
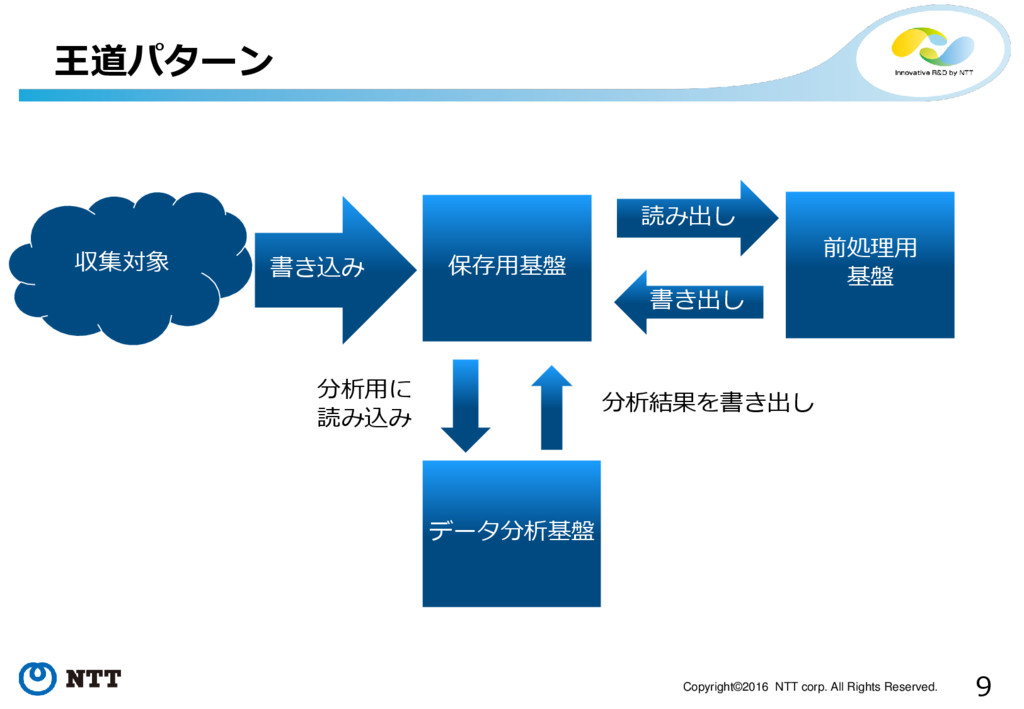
9 Copyright©2016 NTT corp. All Rights Reserved. 王道パターン 書き込み 収集対象
保存用基盤 前処理用 基盤 読み出し 書き出し データ分析基盤 分析用に 読み込み 分析結果を書き出し
10 Copyright©2016 NTT corp. All Rights Reserved. • やること •
データをアプリケーションサーバから保存先まで転送 • 評価軸(データ解析特有の箇所にのみ焦点を当てて説明) • データのとりこぼしの有無 • データの重複の有無 • データを投入してからが利用可能になるまでの所要時間 • システム一般の非機能要件(性能、可用性、など) • 主要な方式 • バッチ方式 • ファイルにまとめて転送 • 利点: ファイルという直感的でなじみのある方法 • 欠点: 1日に一回などまとまった単位で転送することになるため利用可能になるまでに時間がかかる 分析を前提としたファイルではない場合データの変換が大変 • リアルタイム方式 • 書き出された瞬間に逐次転送 • 利点: 分析基盤が解釈しやすい形で書き込む、利用可能になるまでの時間が短い • 欠点: 場合によってはアプリの改修が必要となる • 収集のために使われるソフトウェアの例 • バッチ方式 • scp, ftp などのファイル同期ツール • リアルタイム方式 • Fluentd,Flume,LogStash, rsyslog, Kafka • JSON などの計算機が解釈しやすい形式で送付することができる 収集 Integrating Spark at Petabyte Scaleより引用 http://goo.gl/OSEJAg
11 Copyright©2016 NTT corp. All Rights Reserved. • やること •
データを保存する • 前処理基盤からのデータの読み書き • データ処理基盤からデータの読み書き • 評価軸 (データ解析特有の箇所にのみ焦点を当てて説明) • 前処理・データ分析処理を行う際に利用する基盤からの対応状況 • 主要な方式 • NAS などのストレージへの保存 • 利点: 一般的なファイルとして扱えるため対応ツールが多い • 欠点: 分散しずらい、分散実装のOSSがあまりない • データベースへの保存: PostgreSQL, MySQL, Oracle DB etc. • 利点:一般的なデータベースとして扱えるため対応ツールが多い、 データベースに組み込まれている高性能なの性能解析機能を利用可能 • 欠点:分散しずらい、スキーマが事前定義されている必要がある • 特化型ストレージ・特化型データベースへの保存 (HDFS, S3, Cassandra, Riak, etc・Nettiza, Vertica, etc) • 利点:専用にシステムが組まれているため特定の用途で性能面・運用面で 大きな利点があることが多い • 欠点:専用ツールであるため対応ツールが少ないことが多い 保存 Integrating Spark at Petabyte Scaleより引用 http://goo.gl/OSEJAg
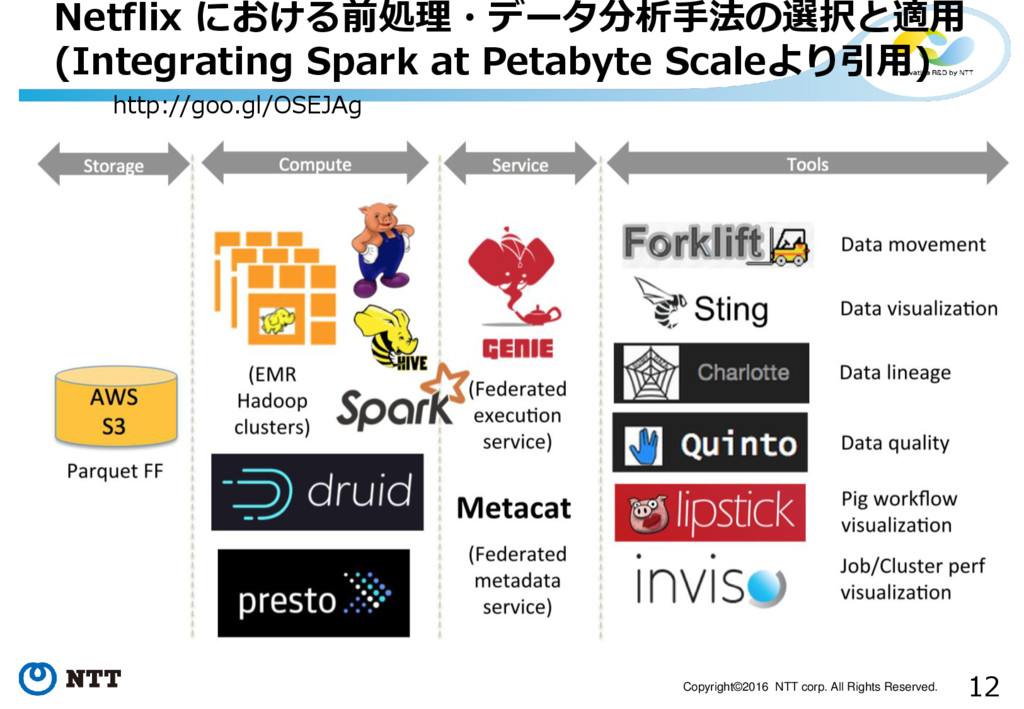
12 Copyright©2016 NTT corp. All Rights Reserved. Netflix における前処理・データ分析手法の選択と適用 (Integrating
Spark at Petabyte Scaleより引用) http://goo.gl/OSEJAg
13 Copyright©2016 NTT corp. All Rights Reserved. • やること •
分析ツールに沿った形にデータを変換する • 評価軸 (データ解析特有の箇所にのみ焦点を当てて説明) • データ量の増加に対応可能か • 処理の記述方法 • 具体例 • データ(CSV/JSON)をデータベース内部で処理しやすいように正規化 • 自然言語を python が読み込めるように CSV に変換 • データ分析に用いるアルゴリズムが扱いやすいようにデータをソート • 最近の兆候 • 収集のフェイズで前処理行うことで遅延を減らすこともある • データ量の増加に対して処理時間が一定時間を保つために分散処理を 用いることがある 前処理(1)
14 Copyright©2016 NTT corp. All Rights Reserved. • 主要な方式 •
汎用のUNIXシェルコマンド • sed, awk, sort など • 利点: 良い意味で枯れている • 欠点: 保存の際にPOSIX用ストレージが必要な場合があり、ストレージの性能により データのエクスポートや律速される場合もある • 汎用プログラミング言語 • Pyhon, Ruby, Scala など • 利点: 柔軟な記述が可能、アルゴリズムの見直しや処理方法なども記述可能 • 欠点: 学習コスト、実装コストが必要 • 汎用データベース・分析用データベース • PostgreSQL, MySQL, Oracle など • 利点: SQL を知っていれば記述が可能 • 欠点: インデックスをはじめとするDBの最適化機構を利用するためににはスキーマが 必要。 前処理のコンテキストではスキーマを定まっていないことが多く、最適化機構を活用で きない • 前処理特化型のフレームワーク • Hadoop MapReduce+Hive Pig, Spark RDD + Spark SQL etc. • 利点: SQL ライクな言語で記述可能 • 欠点: 運用ノウハウが独自であることが多い • 商用のETLツール • talentd など 前処理(2)
15 Copyright©2016 NTT corp. All Rights Reserved. • やること •
前処理を実施したデータを読み込んで、それを実際に分析する • 評価軸(データ解析特有の箇所にのみ焦点を当てて説明) • 使える分析手法の種類 • データの入力形式 • 主要な分析用ソフトウェア • 表計算ソフト • 利点: 多種多様な分析手法が組み込まれている • 欠点: データ量の上限がメモリに限られる • 例: Excel プログラミング言語+ライブラリ • 利点:多種多様な統計的分析手法が可能 • 欠点: データ量の上限がメモリに限られる • 例: python + scikit/numpy,R, Matlab, Jullia, etc. • データベース • 利点: 高水準な記述言語である SQL で処理を記述可能 メモリ量を越えてもディスクの限り効率良く処理可能 • 欠点: スキーマが必須 • 例: PostgreSQL/MySQL,etc. • 目的特化型分散処理フレームワーク • 利点: 1台に収まり切らないデータを処理可能 • 欠点: オーバヘッドにより単一計算機よりも遅い場合もある • 例: MapReduce(Hadoop),MPI(OpenMPI) etc…. Amazon Redshift, Google Big Query, Vertica, 分析手法の選択と適用 今回は データベースと MapReduce フレームワークに 焦点を当てて 仕組みを解説
16 Copyright©2016 NTT corp. All Rights Reserved. • よく行う処理を簡単に自動化したい •
要件を満たす性能を出したい • プログラミング言語 • 例: Ruby/Python/Erlang/Scala/C etc… • ライブラリ • 例: python + scikit/numpy • フレームワーク • 例: MapReduce(Hadoop),MPI(OpenMPI) etc…. • RDBMS • 例: PostgreSQL/MySQL,Vertica,etc. 処理基盤の目的
17 Copyright©2016 NTT corp. All Rights Reserved. • なぜこんなに種類があるのか •
要件がまちまちなので、使い分ける必要がある • 性能(遅延とスループット) • 使いやすさ(既存ツールとの親和性、インタフェース、 インストールのしやすさ) • スケーラビリティ • 耐故障性 etc… • この中でも,スケーラビリティに重きをおいているのが “分散処理基盤“ • スケーラビリティ + α に重きを置いている処理基盤が多い 様々な処理基盤
18 Copyright©2016 NTT corp. All Rights Reserved. • 問題の規模の拡大・増大に対して対応できるか どうかという指針
• 用例 • "ビジネスがスケールする” • "システムがスケールする” • システムにおけるスケーラビリティの例 • データ量の増大に対処するために,システムを拡大していくこ とができるか? • データ量が3倍になったときに、プログラムの改変なし・ 設備投資のみで想定時間内で処理を終わらせることができるか • システム規模拡大につれて,運用コストが跳ね上がらないか? • 1000台と2000台で気にしなければならないことの違いは? スケーラビリティとは
19 Copyright©2016 NTT corp. All Rights Reserved. • 部分的な故障が起きても動き続ける •
データや処理を冗長化しておくことで、復旧が可能 • 処理のスループットを上げる • 計算機を並べることで,処理を並列化 • 分散処理をしても処理が早くなるとは限らない • 余計な通信遅延が発生しない分、1台で十分な処理は 1台で行うべき • 一般的には CPU(nsec) > Memory(nsec) > Network(μsec-msec) > Disk(msec) • 光速の壁 • ネットワークが飽和しがち 分散処理基盤の目的 100Mbps x 10台 = 1Gbps で読み込みができる!
20 Copyright©2016 NTT corp. All Rights Reserved. • MPI(Message Passing
Interface) • 主な用途: 科学技術計算など • CPU インテンシブな処理向き • 通信の箇所をメッセージパッシングという形で隠蔽 • 並列DB • 主な用途: クエリを低遅延で実行 • 並列IO • インデックス,データ配置 • MapReduce • 主な用途: 大量のデータの変換を行うための基盤 • 分散ファイルシステムを前提とした処理基盤で,並列IOにより スループットを稼ぐ • 故障処理、分散処理、IO をAPI (Map関数/Reduce関数) の 下に隠蔽 代表的な分散処理基盤
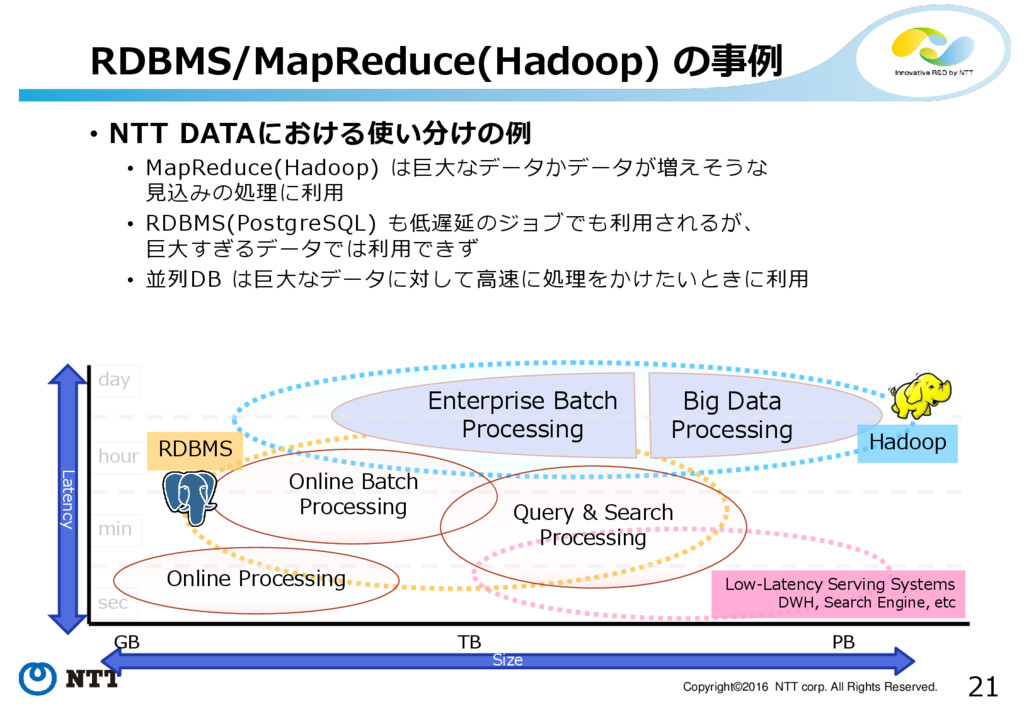
21 Copyright©2016 NTT corp. All Rights Reserved. • NTT DATAにおける使い分けの例
• MapReduce(Hadoop) は巨大なデータかデータが増えそうな 見込みの処理に利用 • RDBMS(PostgreSQL) も低遅延のジョブでも利用されるが、 巨大すぎるデータでは利用できず • 並列DB は巨大なデータに対して高速に処理をかけたいときに利用 RDBMS/MapReduce(Hadoop) の事例 sec min hour day Big Data Processing Latency Size Online Processing GB TB PB Online Batch Processing RDBMS Low-Latency Serving Systems DWH, Search Engine, etc Hadoop Query & Search Processing Enterprise Batch Processing
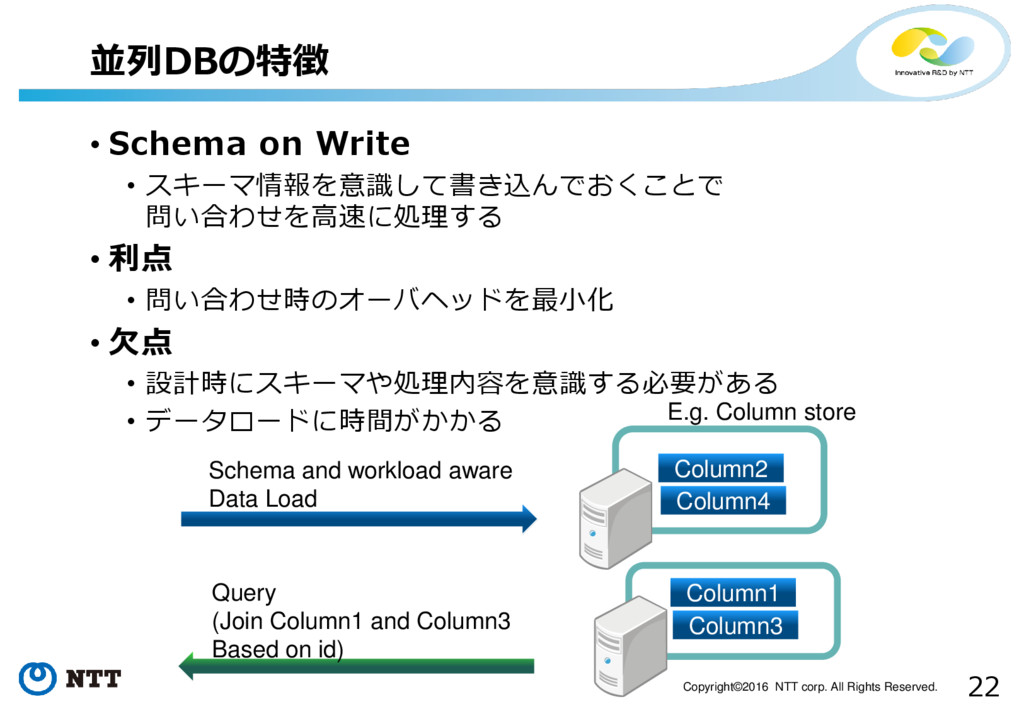
22 Copyright©2016 NTT corp. All Rights Reserved. • Schema on
Write • スキーマ情報を意識して書き込んでおくことで 問い合わせを高速に処理する • 利点 • 問い合わせ時のオーバヘッドを最小化 • 欠点 • 設計時にスキーマや処理内容を意識する必要がある • データロードに時間がかかる 並列DBの特徴 Column1 Column3 Column2 Column4 Schema and workload aware Data Load Query (Join Column1 and Column3 Based on id) E.g. Column store
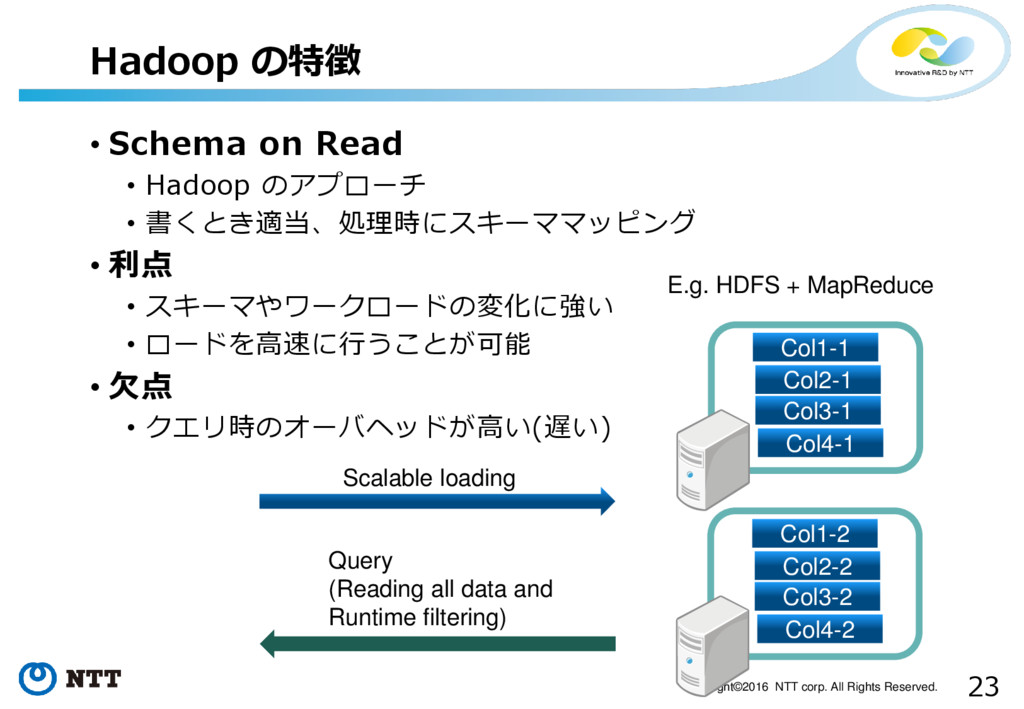
23 Copyright©2016 NTT corp. All Rights Reserved. • Schema on
Read • Hadoop のアプローチ • 書くとき適当、処理時にスキーママッピング • 利点 • スキーマやワークロードの変化に強い • ロードを高速に行うことが可能 • 欠点 • クエリ時のオーバヘッドが高い(遅い) Hadoop の特徴 Col1-1 Col2-1 Col3-1 Col4-1 Col1-2 Col2-2 Col3-2 Col4-2 Scalable loading Query (Reading all data and Runtime filtering) E.g. HDFS + MapReduce
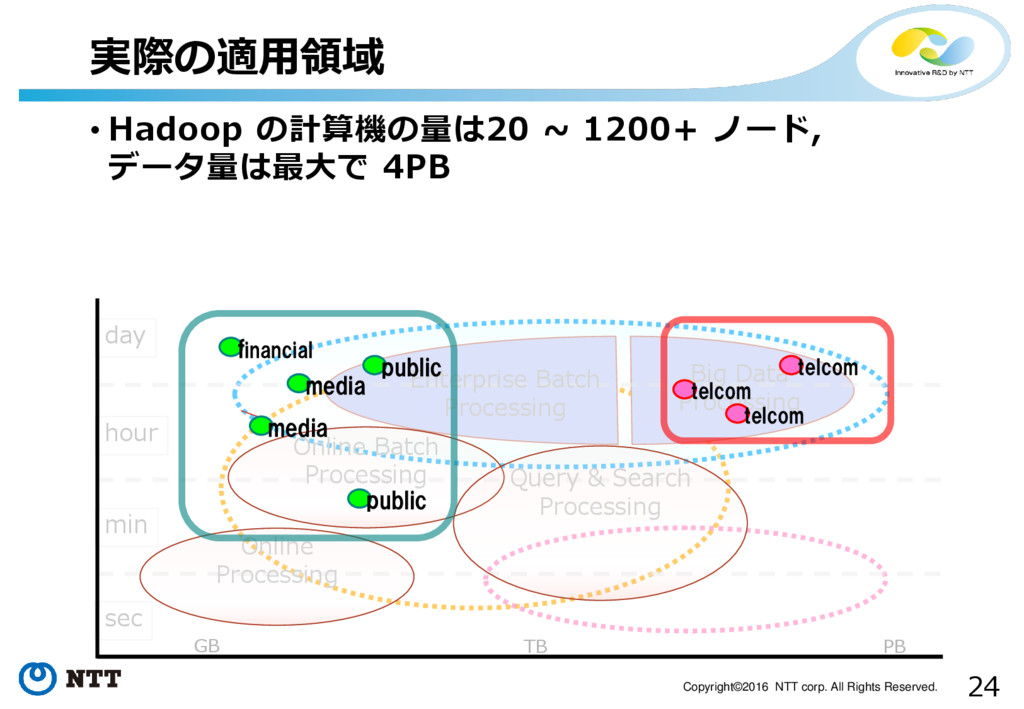
24 Copyright©2016 NTT corp. All Rights Reserved. • Hadoop の計算機の量は20
~ 1200+ ノード, データ量は最大で 4PB 実際の適用領域 sec min hour day Big Data Processing Online Processing GB TB PB Enterprise Batch Processing Online Batch Processing Query & Search Processing financial media public media telcom telcom public telcom
25 Copyright©2016 NTT corp. All Rights Reserved. • 処理しなければならないデータが巨大である場合 •
例: 一日100GBずつデータが増えていく • データベースに入れる前に、非構造化データに 対して前処理を行いたい場合 • スキーマが頻繁に変更される場合 • 例: アプリケーションからのログ形式の変更が多い場合 • これ以外の場合は、基本的にRDBMSを選択する方が 無難 • 複数の計算機の面倒を見る必要がある • かえって処理が遅くなることもあり得る 実情から見る Hadoop を選択する状況
26 Copyright©2016 NTT corp. All Rights Reserved. • スモールスタートする場合はクラウドサービスを利用する •
NTT Docomo,SmartNews etc. • NTTドコモ、統合分析基盤にAWSのAmazon Redshiftを活用 • http://cloud.watch.impress.co.jp/docs/news/20150904_719532.html • SmartNews TechNight Vol5 : SmartNews AdServer 解体新書 / ポストモーテム • http://www.slideshare.net/smartnews/smartnews-technight-vol5- smartnews-adserver • 超大規模にする場合などは独自インフラを持つ • Google, Facebook, Twitter, Amazon, NTT Docomo etc. • 社会・産業の発展を支える「モバイル空間統計」―モバイルネットワーク の統計情報に基づく人口推計技術とその活用―/社会の頭脳システム―モ バイル空間統計を支える大規模データ処理基盤― • https://www.nttdocomo.co.jp/corporate/technology/rd/technic al_journal/bn/vol20_3/024.html 事例から見る最近のトレンド
27 Copyright©2016 NTT corp. All Rights Reserved. • データ分析のサイクルのうち,システムが介在できる部分 に関して説明を行った
• 現状,あくまでも分析基盤の主体は人 • ツールに振り回されないように気をつける • 大きなデータを扱う場合は特別なシステムが必要 • Hadoop もその中の一例 • データ規模に合わせて使えるものを利用することが費用対効果を 大きくする上で重要 • Hadoop を使う場合の形態 • 分析に特化したクラウドサービス • スモールスタートに適している • オンプレミス • データ量が巨大な場合や外に出せないデータの処理に適している まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}