each video as a document. We choose the K mostfrequent words with max tf−idf Dictionary for category “Hard Boil an Egg” with K=50 sort, place, water, egg, bottom, fresh, pot, crack, cold, cover, time, overcooking, hot, shell, stove, turn, cook, boil, break, pinch, salt, peel, lid, point, haigh, rules, perfectly, hard, smell, fast, soft, chill, ice, bowl, remove, aside, store, set, temperature, coagulates, yolk, drain, swirl, shake, white, roll, handle, surface, flat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![How to Find MAP[Koppula RSS 2013] Compute features Define the](https://files.speakerdeck.com/presentations/79b44ba24a764e39a6113f7001e1fa94/slide_11.jpg){kind=link}
![Shortcomings[Koppula RSS 2013] Compute features Define the energy function Solve](https://files.speakerdeck.com/presentations/79b44ba24a764e39a6113f7001e1fa94/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
![HMM – Recursive Belief Estimation HMM Derivation [Rabiner] belt( y](https://files.speakerdeck.com/presentations/79b44ba24a764e39a6113f7001e1fa94/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
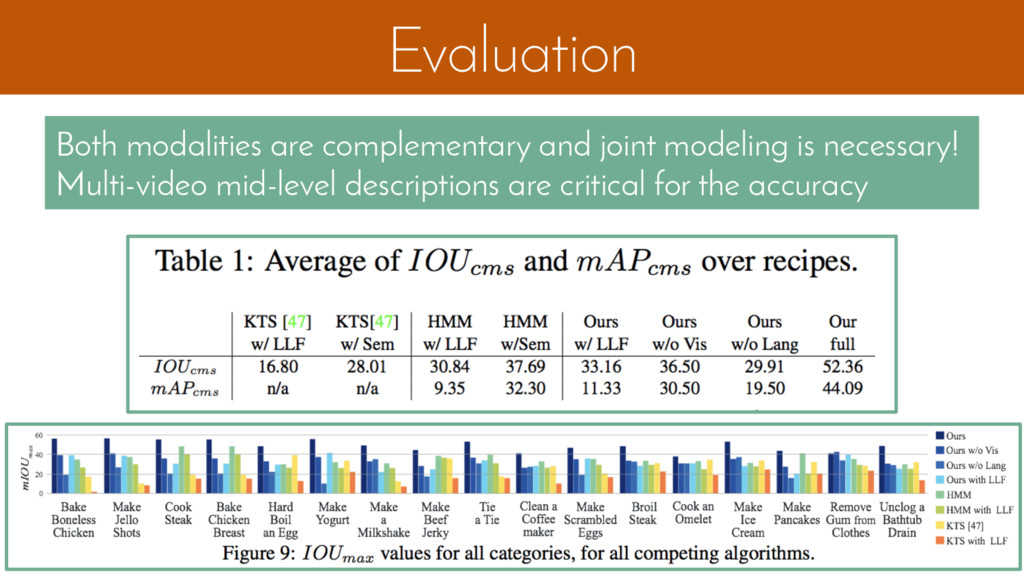{kind=link}
{kind=link}
{kind=link}
{kind=link}
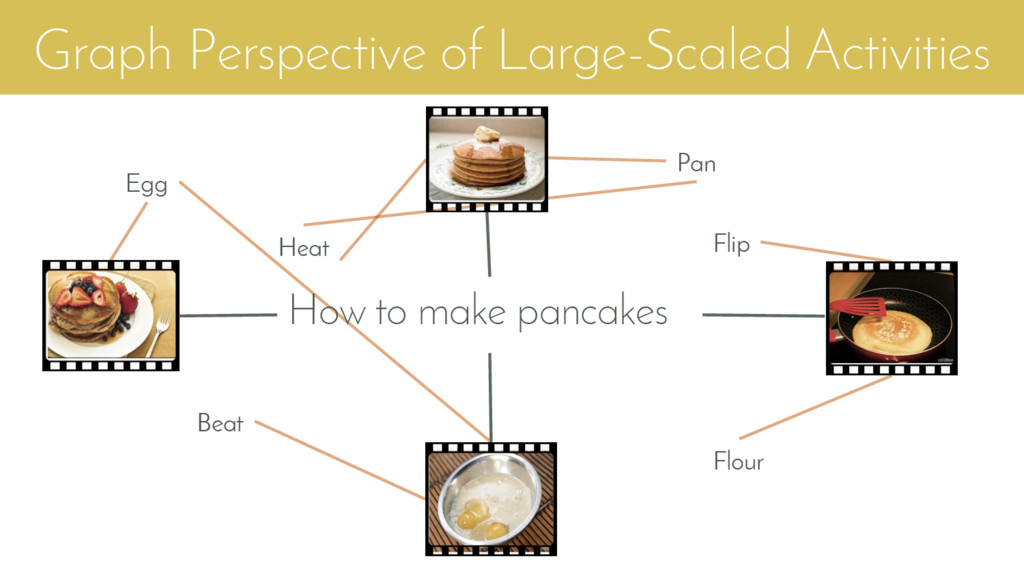{kind=link}
{kind=link}
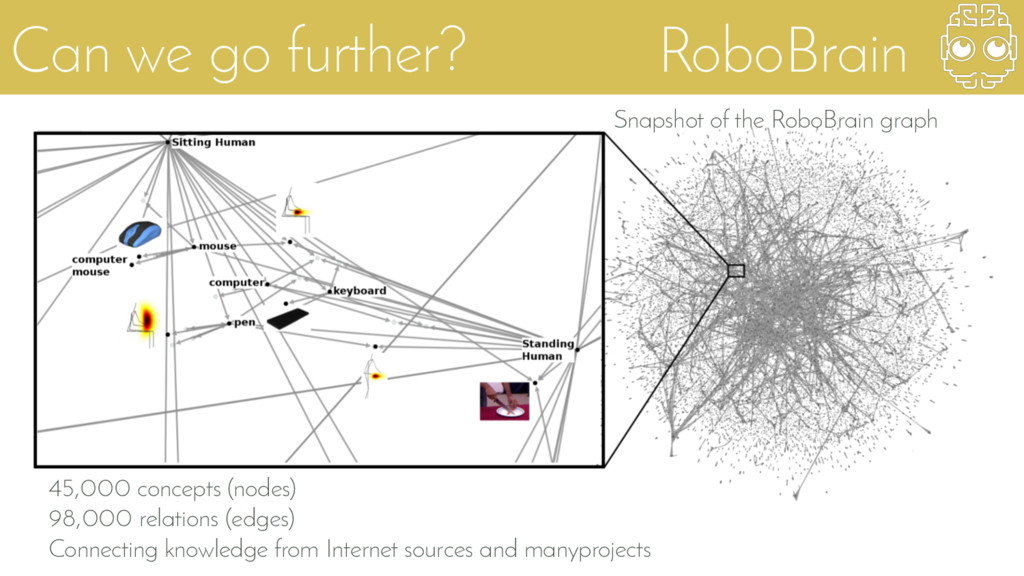{kind=link}
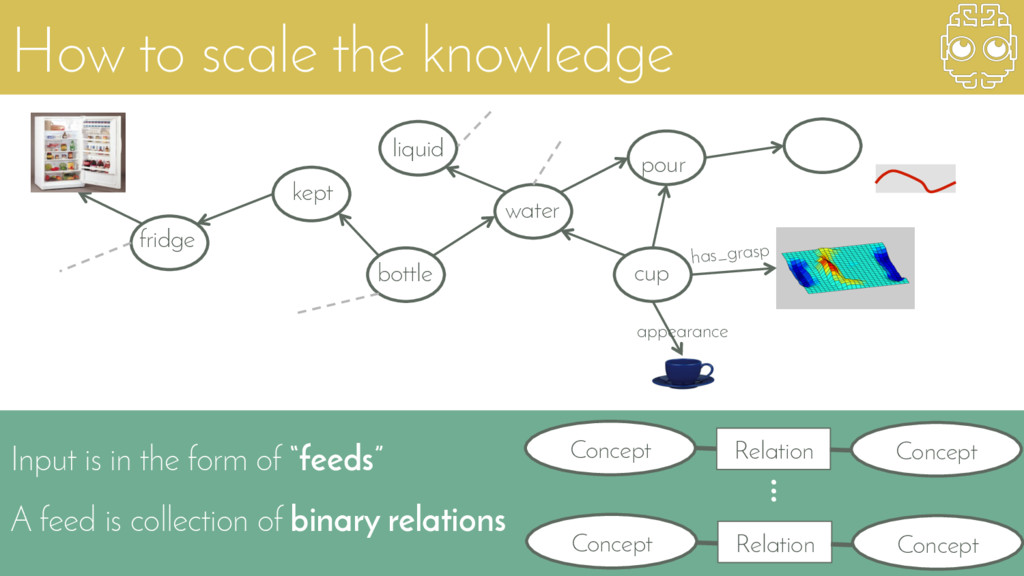{kind=link}
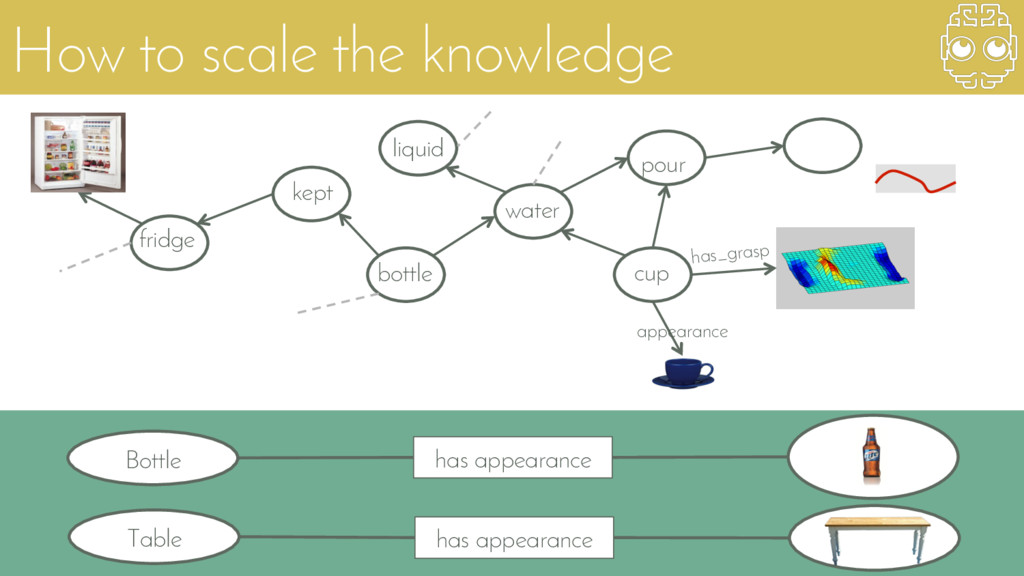{kind=link}
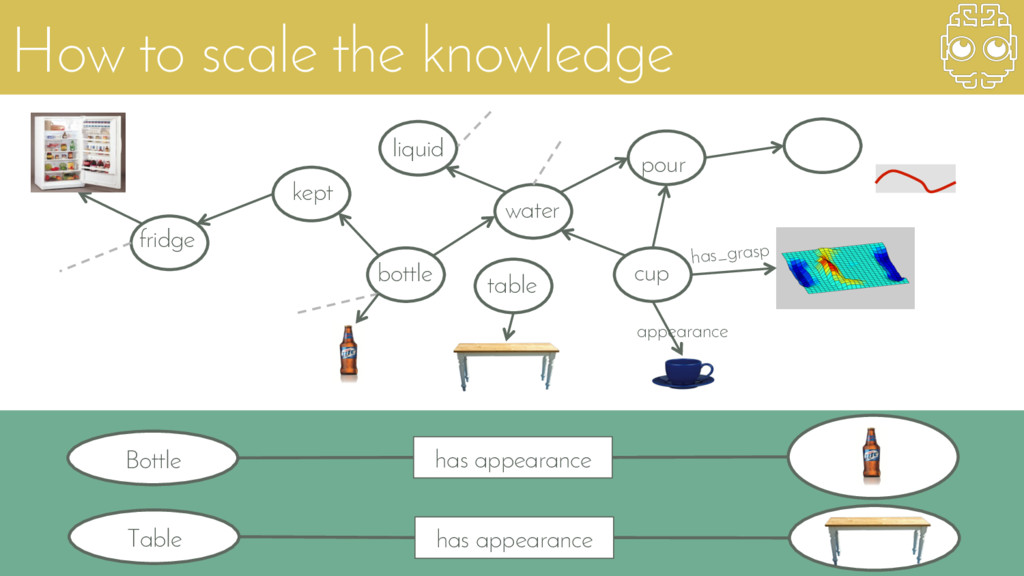{kind=link}
{kind=link}
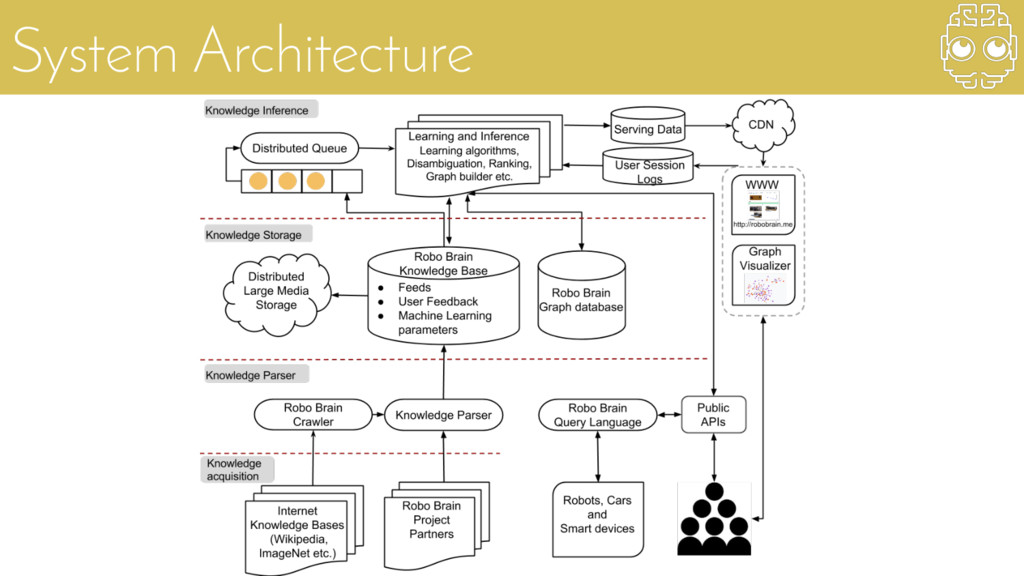{kind=link}
{kind=link}
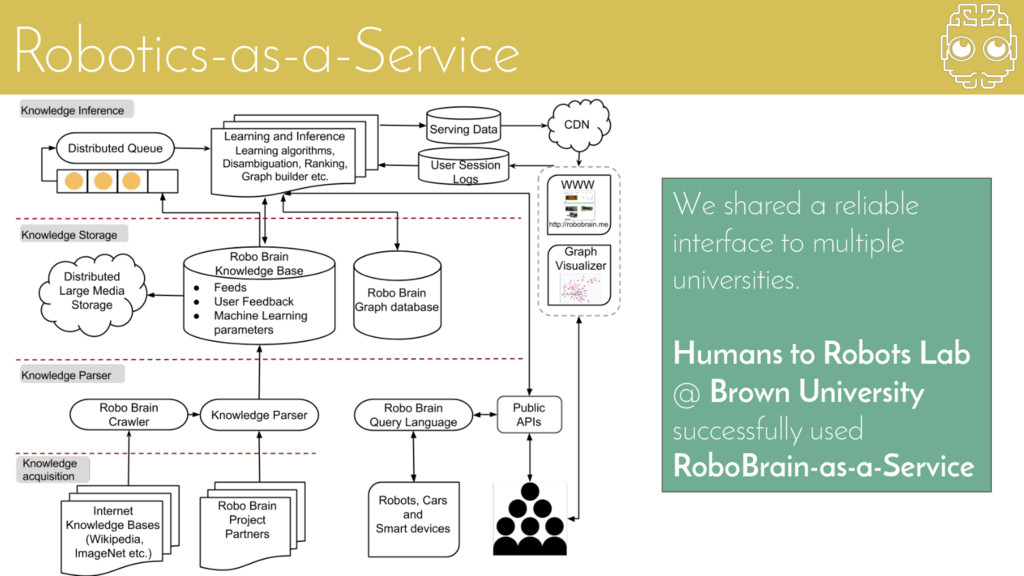{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
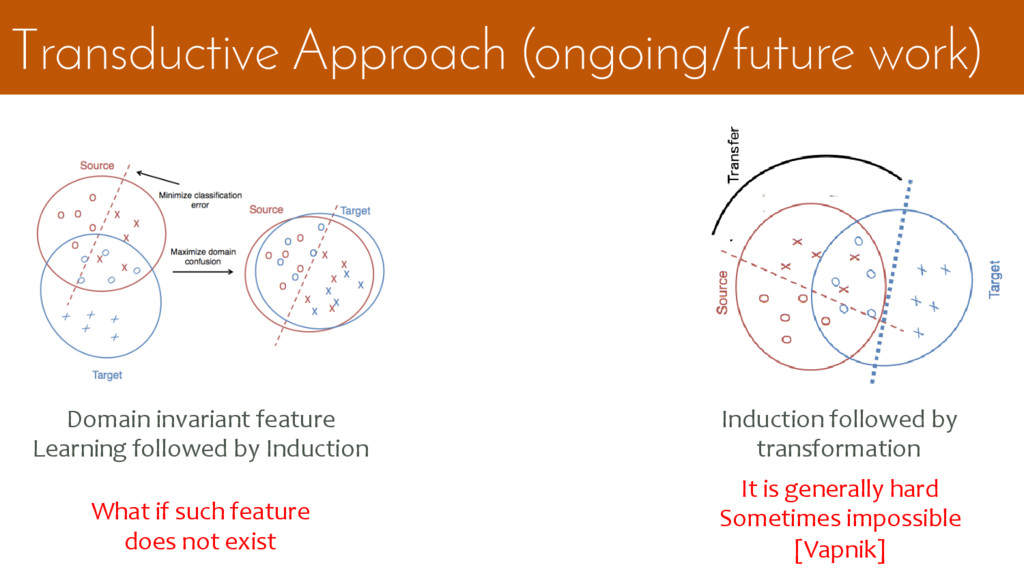{kind=link}
![Domain Transduction [Ongoing work] It might be possible to solve](https://files.speakerdeck.com/presentations/79b44ba24a764e39a6113f7001e1fa94/slide_61.jpg){kind=link}
![Adaptive Transduction [Future Work] Some domains are Intractably large like](https://files.speakerdeck.com/presentations/79b44ba24a764e39a6113f7001e1fa94/slide_62.jpg){kind=link}
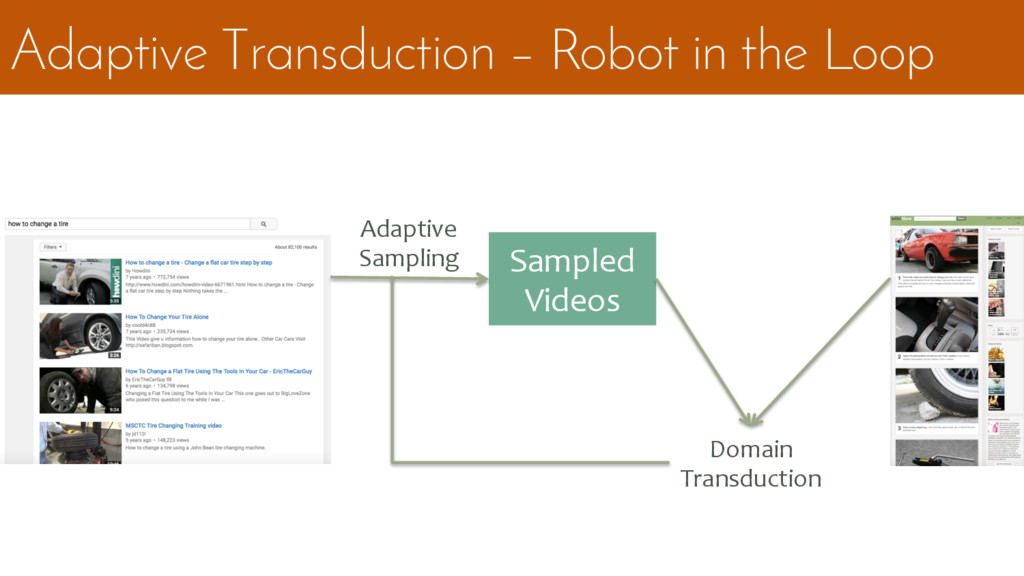{kind=link}
{kind=link}
{kind=link}
{kind=link}