Armon Dadgar from HashiCorp presents the SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol paper by Abhinandan Das, Indranil Gupta, and Ashish Motivala.
Armon's Bio
Armon has a passion for distributed systems and their application to real world problems. He is currently the CTO of HashiCorp, where he brings distributed systems into the world of DevOps tooling. He has worked on Terraform, Consul, and Serf at HashiCorp, and maintains the Statsite and Bloomd OSS projects as well.
Video of this talk on: https://www.youtube.com/watch?v=aVYEY75qn3c
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
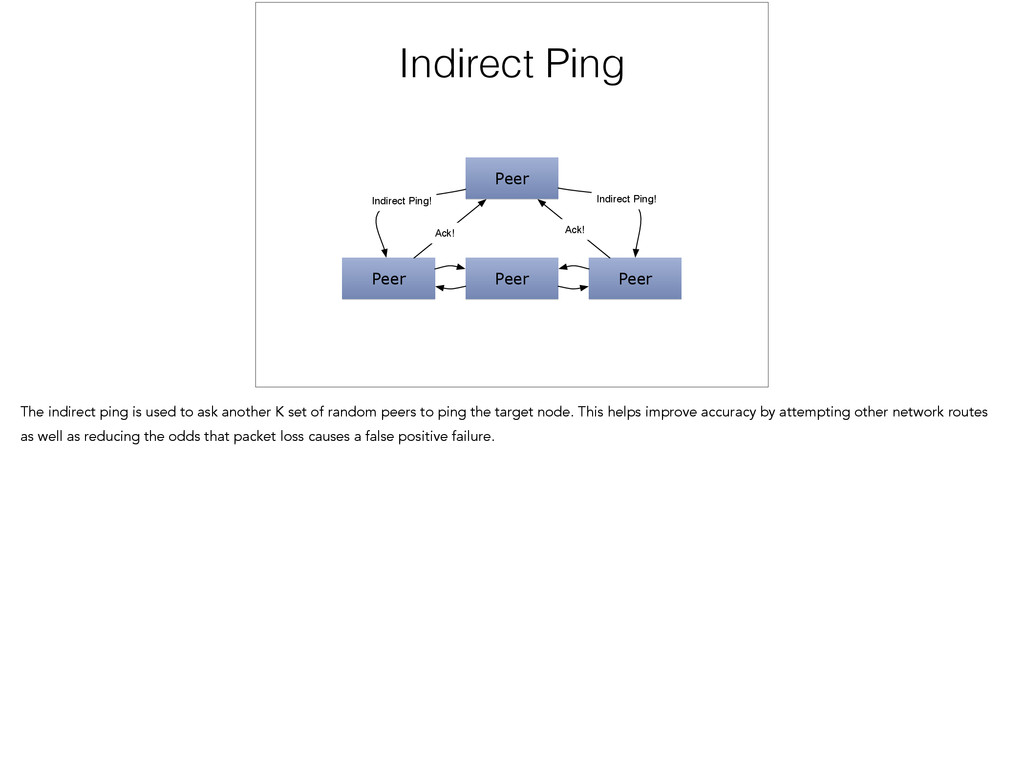
{kind=link}
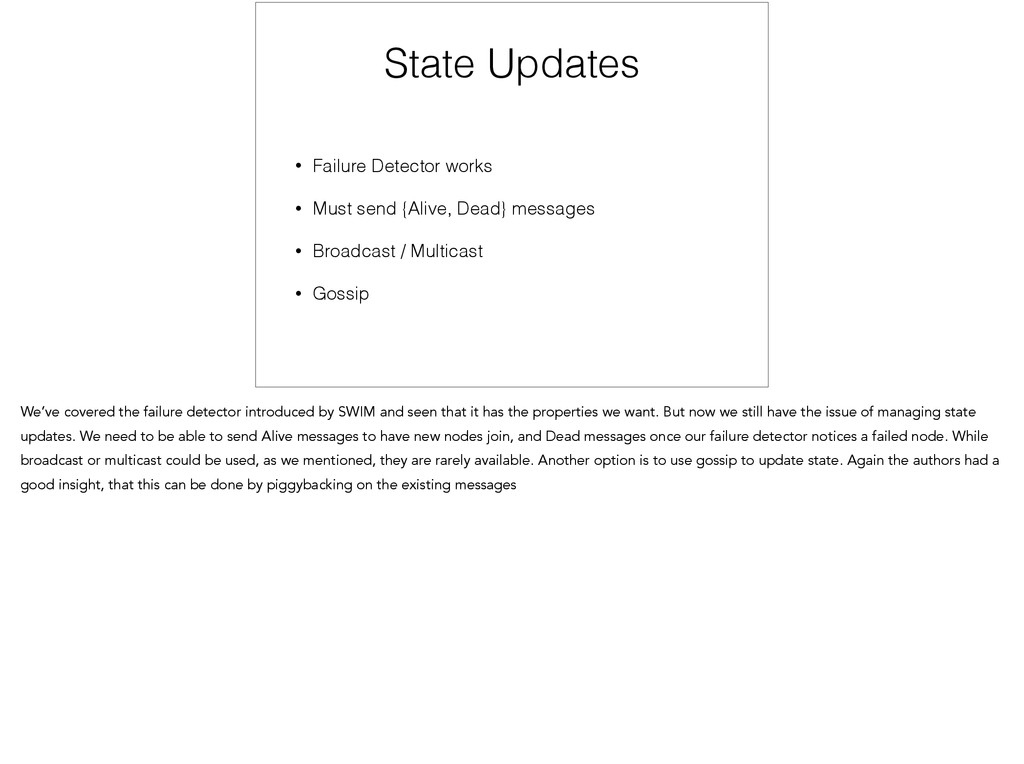{kind=link}
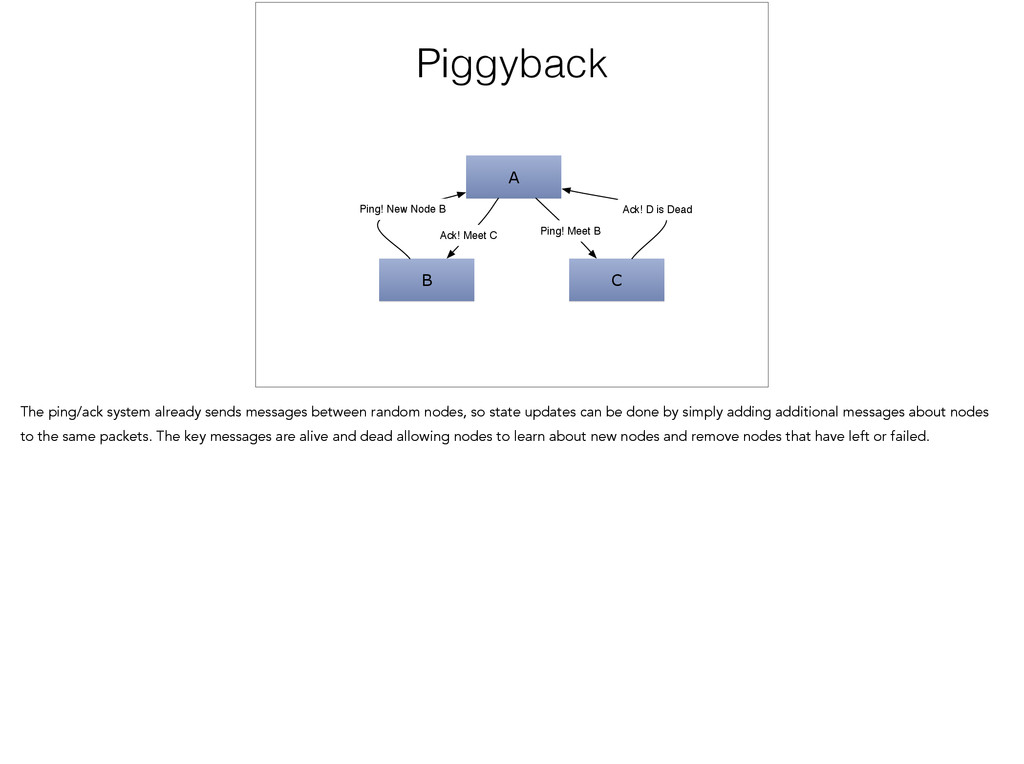{kind=link}
{kind=link}
{kind=link}
{kind=link}
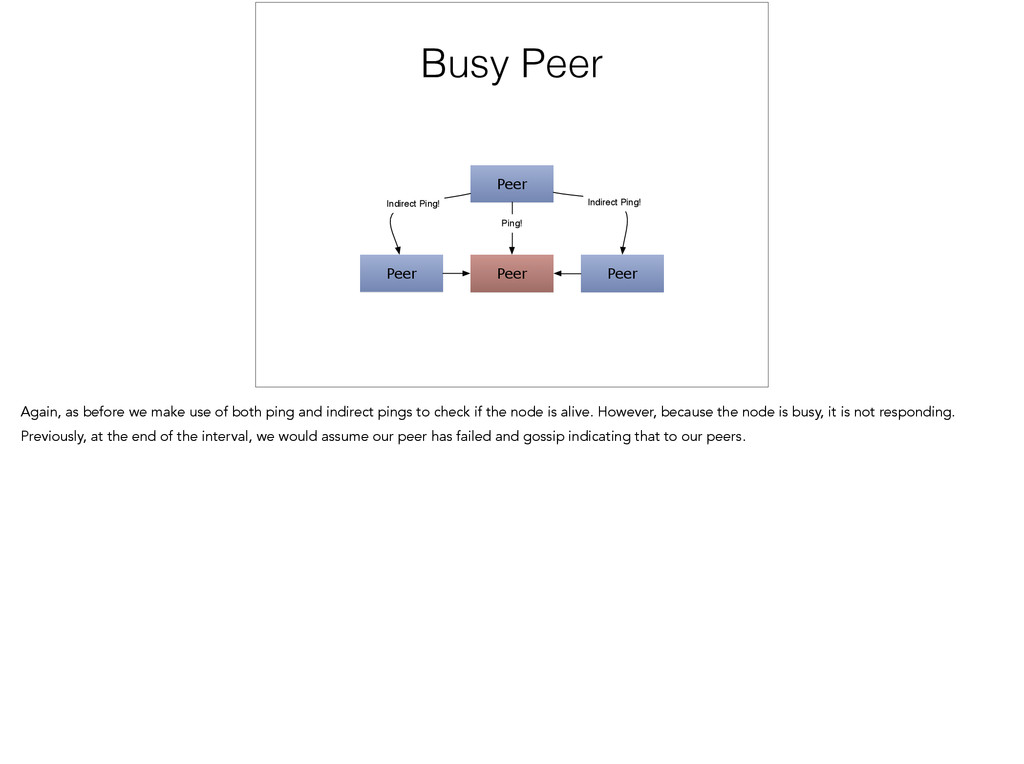{kind=link}
{kind=link}
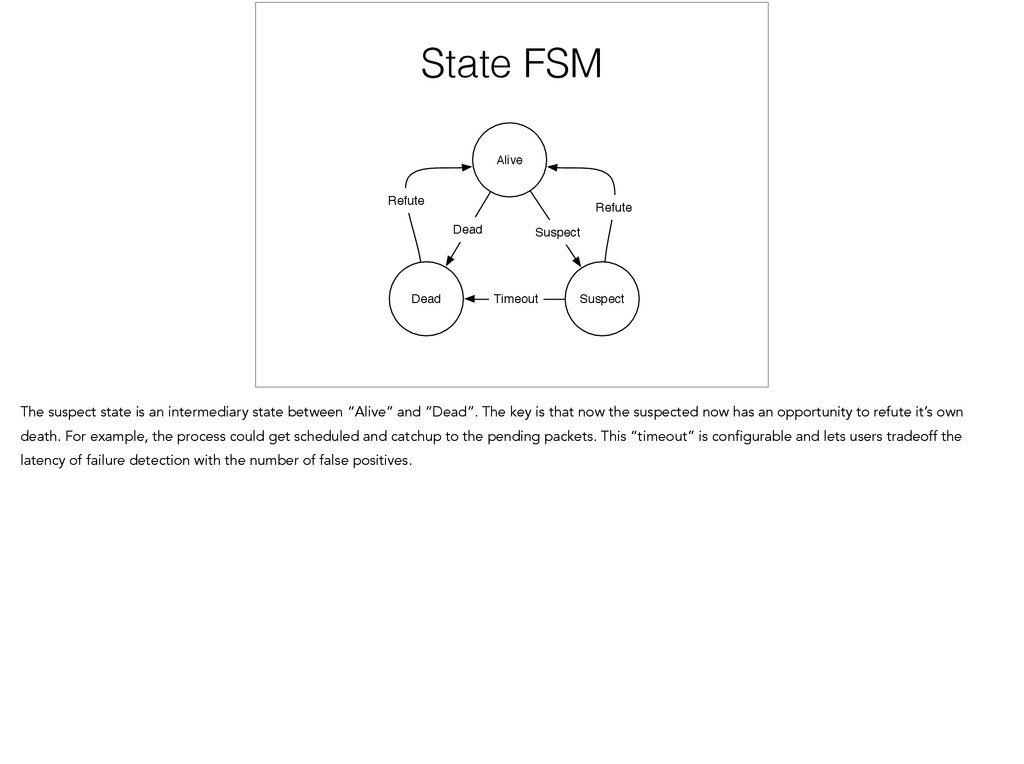{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
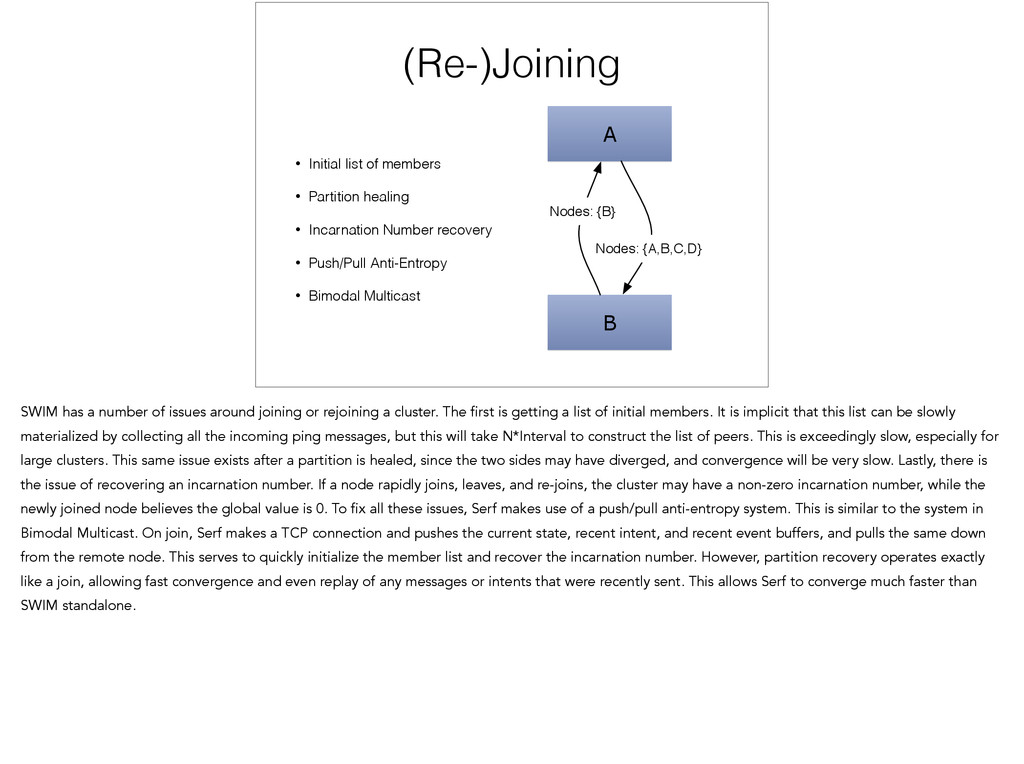{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}