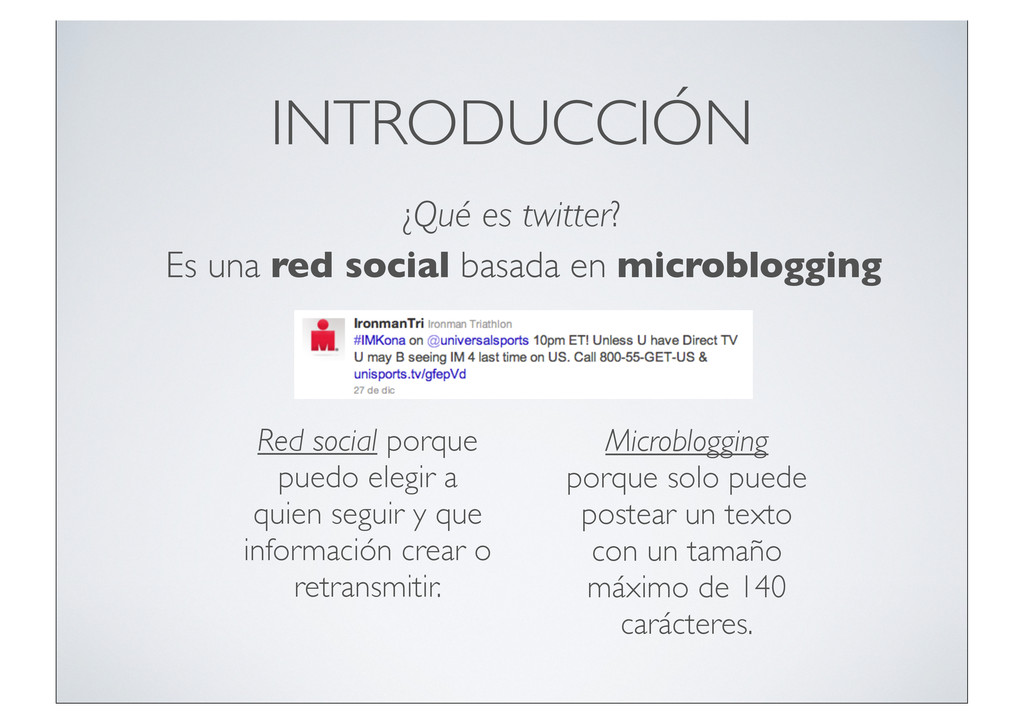
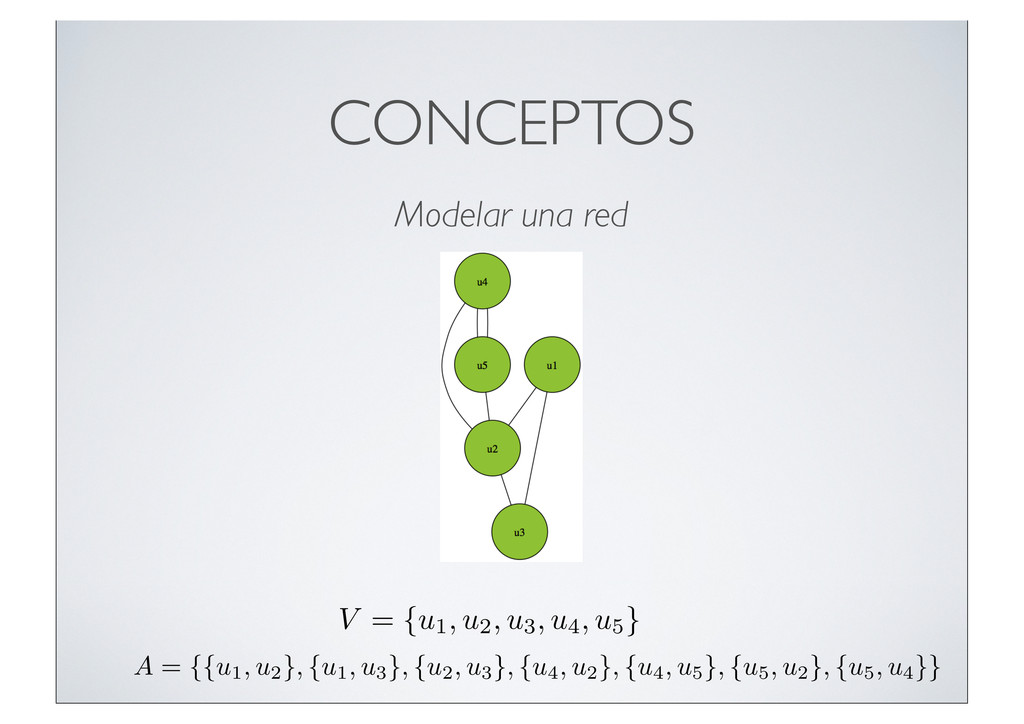
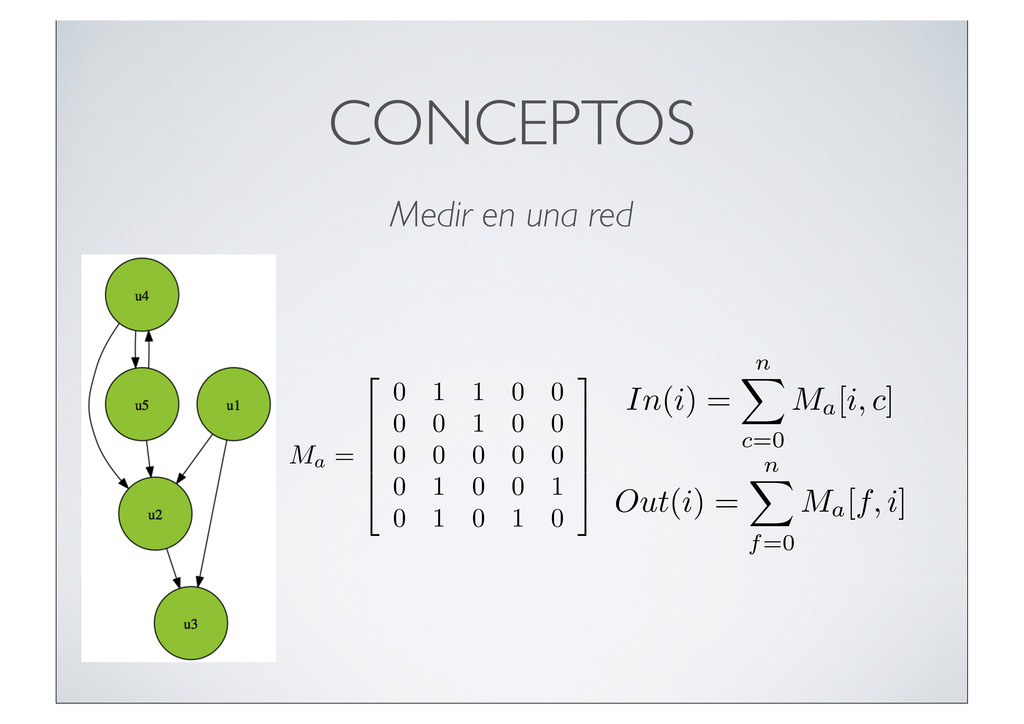
"Feeling for students today. Time to prise those unused library cards from your wallets. #wikipediablackout #SOPA #PIPA. ur1.ca/7jygq", "in_reply_to_user_id_str": null, "geo": null, "retweeted": false, "in_reply_to_user_id": null, "contributors": null, "source": "<a href=\"http://www.tweetdeck.com\" rel=\"nofollow\">TweetDeck</a>", "entities": { "user_mentions": [], "hashtags": [ { "text": "wikipediablackout", "indices": [ 88, 106 ] }, { "text": "SOPA", "indices": [ 107, 112 ] }, { "text": "PIPA", "indices": [ 113, 118 ] } ], "urls": [ { "indices": [ 120, 132 ], "url": "ur1.ca/7jygq", "expanded_url": null } ] }, "place": null, "in_reply_to_status_id": null, "id_str": "159589359589408768", "truncated": false, "user": { "profile_background_image_url": "http://a3.twimg.com/profile_background_images/347782654/year_one_wp.jpg", "show_all_inline_media": true, "follow_request_sent": null, "profile_link_color": "038543", "url": "http://www.youtube.com/xboxuk", "followers_count": 755, "profile_image_url": "http://a2.twimg.com/profile_images/78950744/meforweb_normal.jpg", "default_profile_image": false, "statuses_count": 7004, "time_zone": "London", "profile_background_color": "ACDED6", "description": "Xbox LIVE Assistant Producer, EMEA. Views are mine own and open to lucrative sponsorship. All comic/game geeks should visit my side project: KapowGames.com", "contributors_enabled": false, "profile_background_tile": true, "favourites_count": 21, "location": "Camden, London", "lang": "en", "profile_sidebar_fill_color": "F6F6F6", "screen_name": "Deanways", "verified": false, "notifications": null, "profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/347782654/year_one_wp.jpg", "friends_count": 2002, "profile_sidebar_border_color": "000000", "protected": false, "id_str": "15864765", "listed_count": 11, "following": null, "name": "Dean Samways", "is_translator": false, "profile_use_background_image": true, "created_at": "Fri Aug 15 16:49:51 +0000 2008", "id": 15864765, "default_profile": false, "geo_enabled": true, "utc_offset": 0, "profile_text_color": "333333", "profile_image_url_https": "https://si0.twimg.com/profile_images/78950744/meforweb_normal.jpg" }, "retweet_count": 0, "favorited": false, "id": 159589359589408770, "created_at": "Wed Jan 18 10:54:03 +0000 2012", "in_reply_to_status_id_str": null, "coordinates": null } Un Tweet contiene mucha información Sólo usamos los campos que nos interesan para nuestro procesado y visualización
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![REST API def obtain_users_info(ids = [], screen_names=[]): check_rate_limit() result =](https://files.speakerdeck.com/presentations/47c550d078210130734c123138195412/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![STREAMING API curl -d "track=SOPA" https://stream.twitter.com/1/statuses/filter.json -u[USER]:[PASSWD] • Abrir una](https://files.speakerdeck.com/presentations/47c550d078210130734c123138195412/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
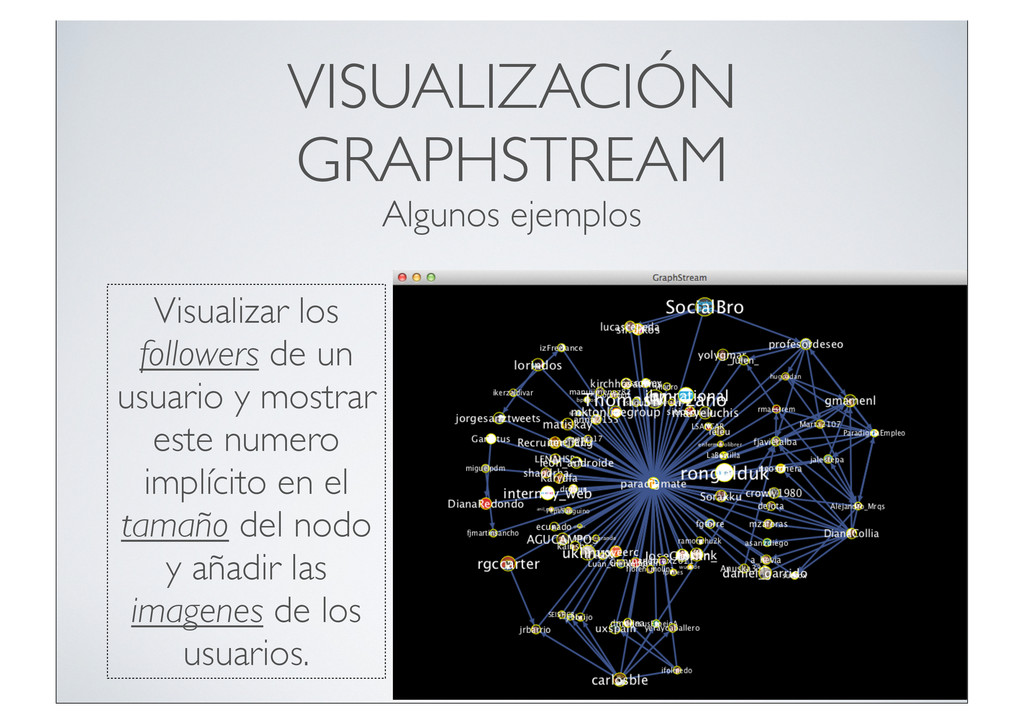{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}