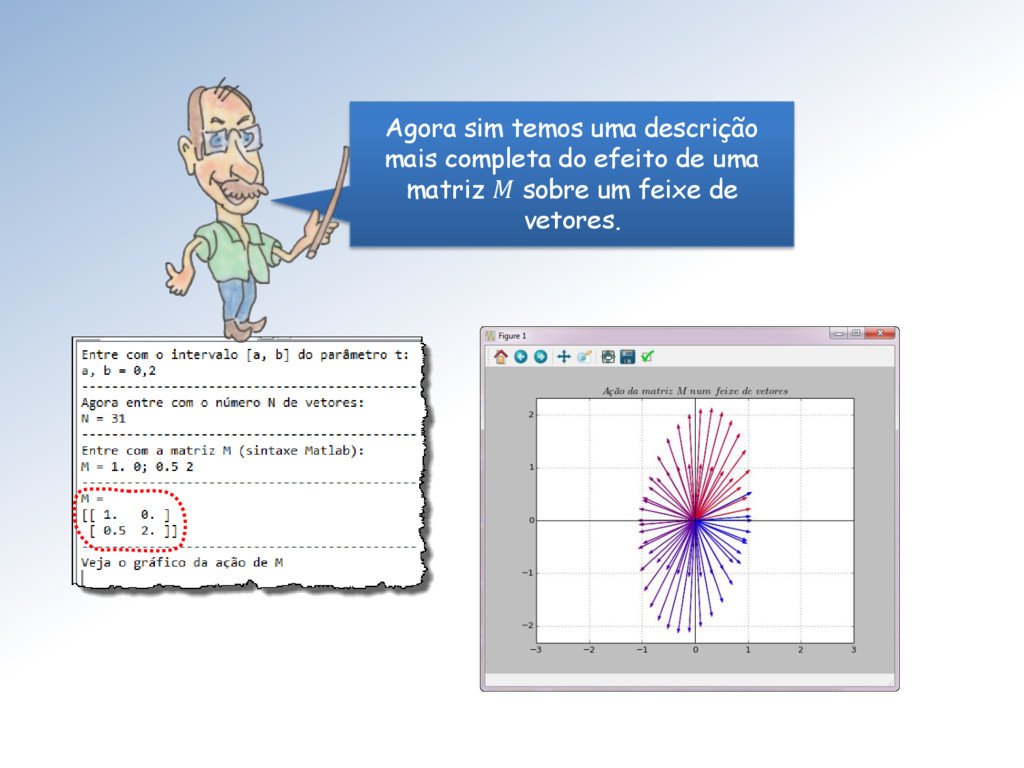
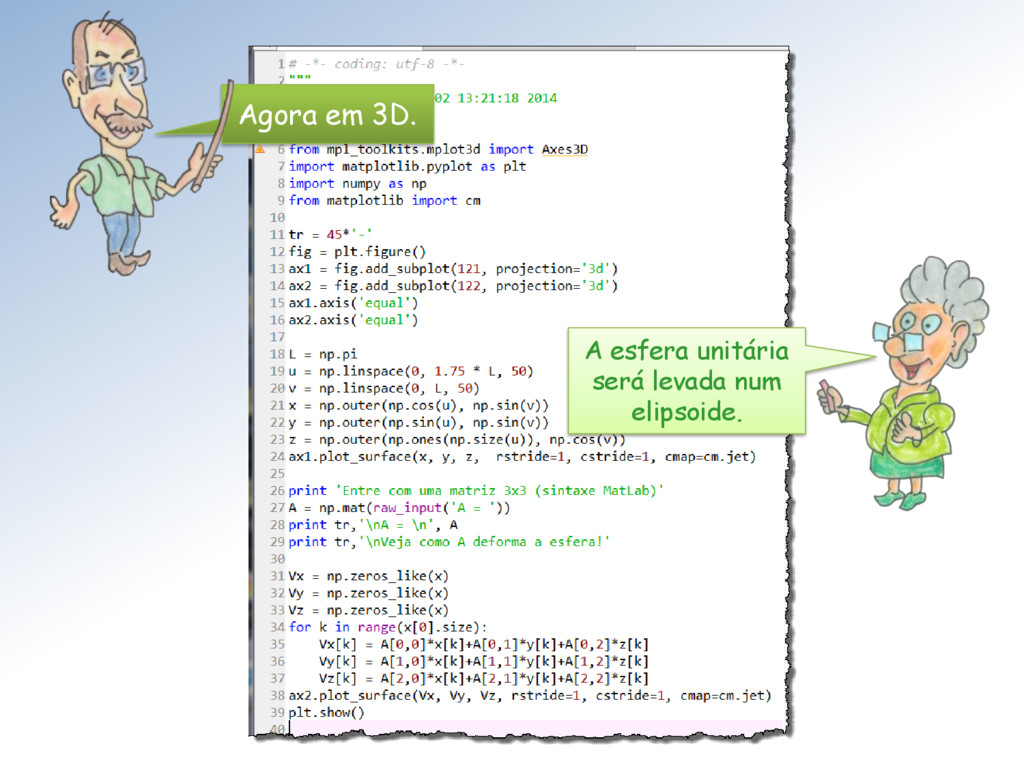
de tamanho unitário é clarificada pela imagem abaixo: A ação é dilatar a componente vertical dos vetores do feixe por um fator de escala = 2 e manter a componente horizontal inalterada.
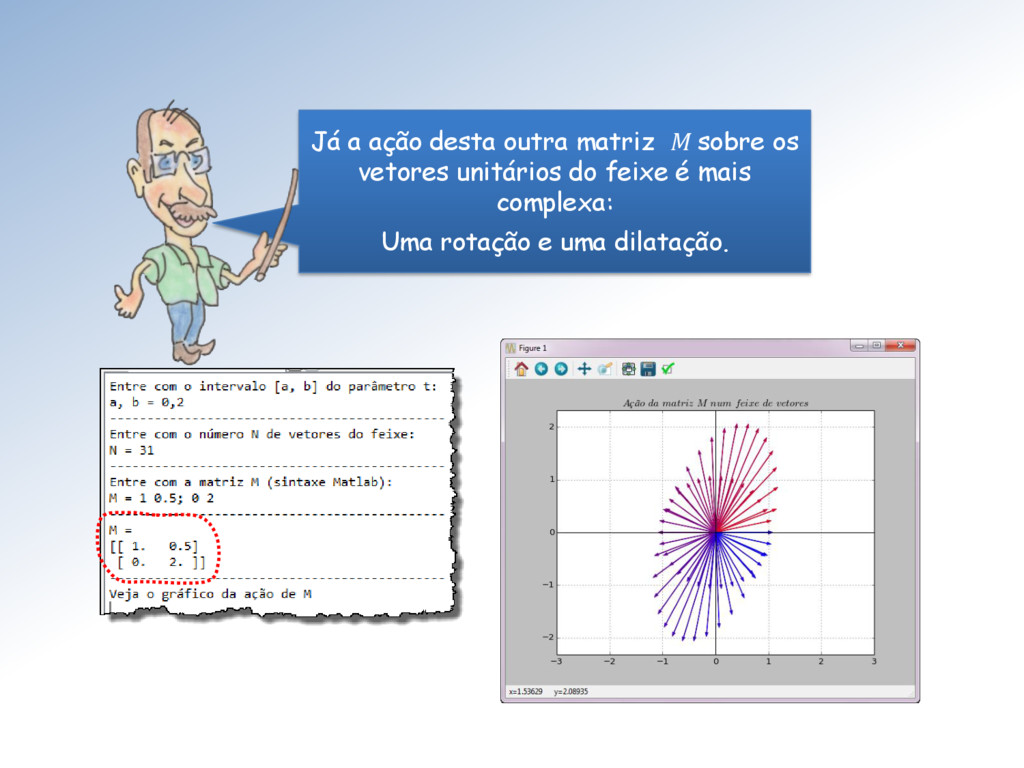
2.5 a componente dos vetores do feixe mas manter a componente inalterada. Ela é proporcional ao tamanho das componentes e dos vetores do feixe, que varia com a inclinação.
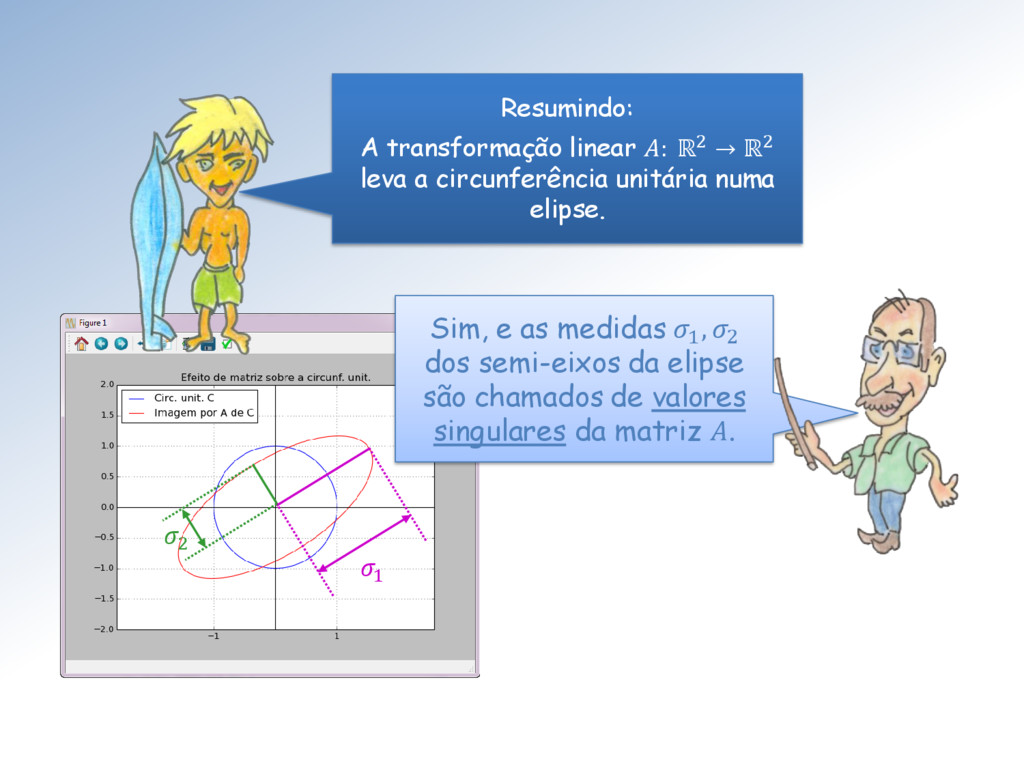
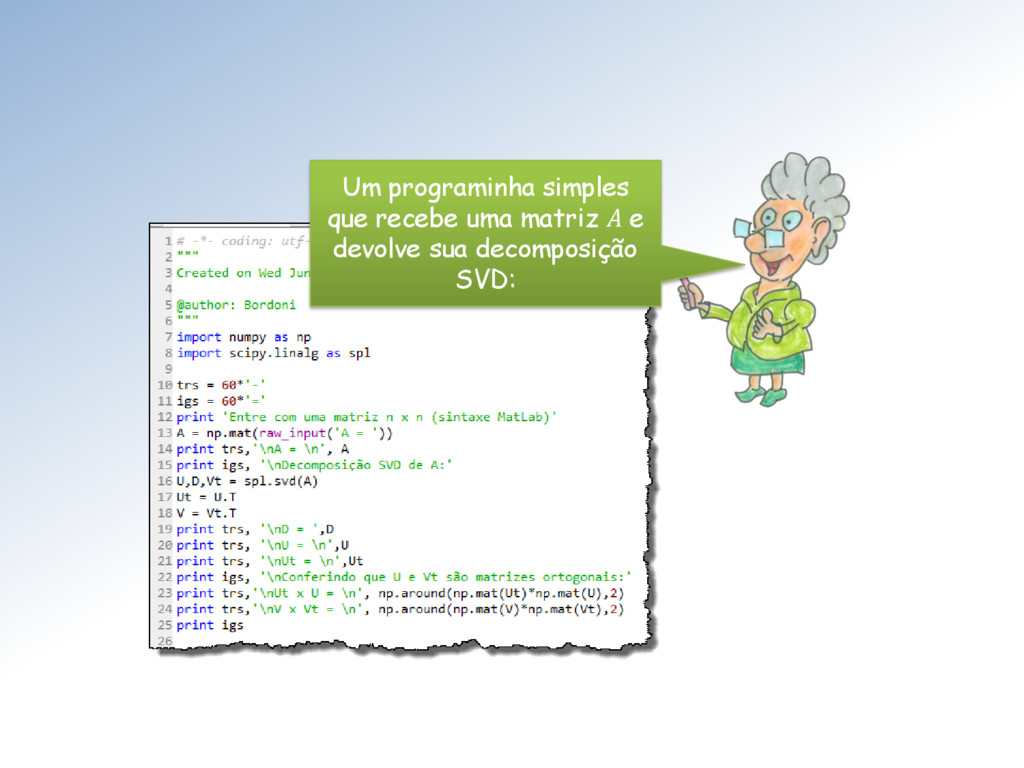
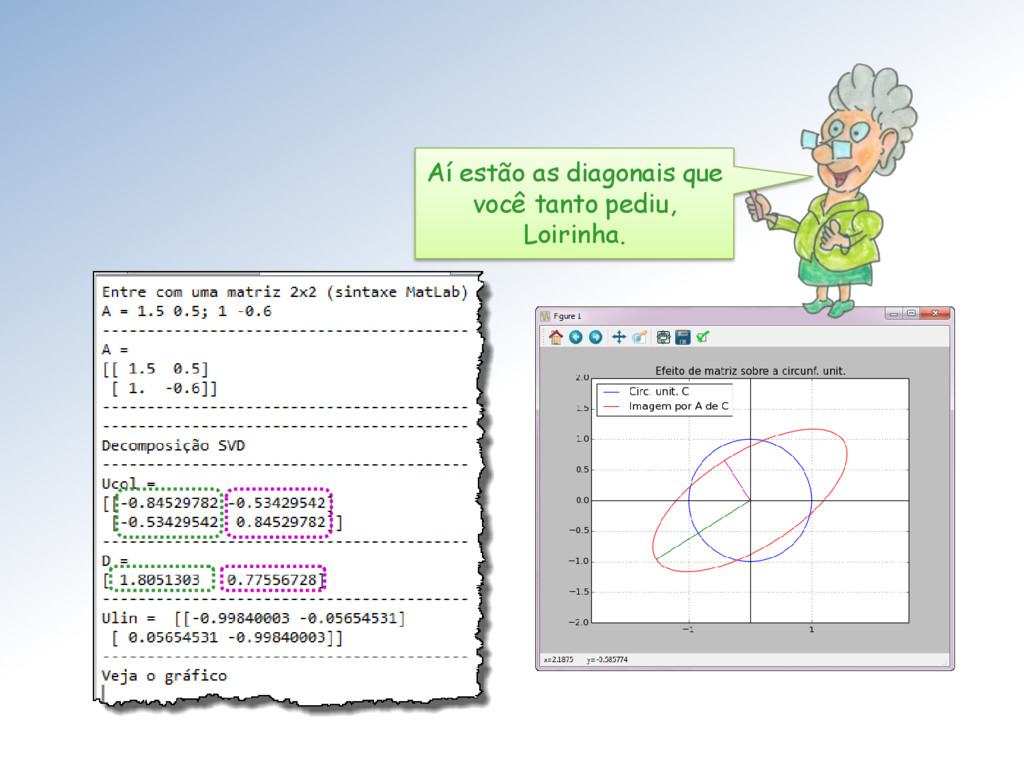
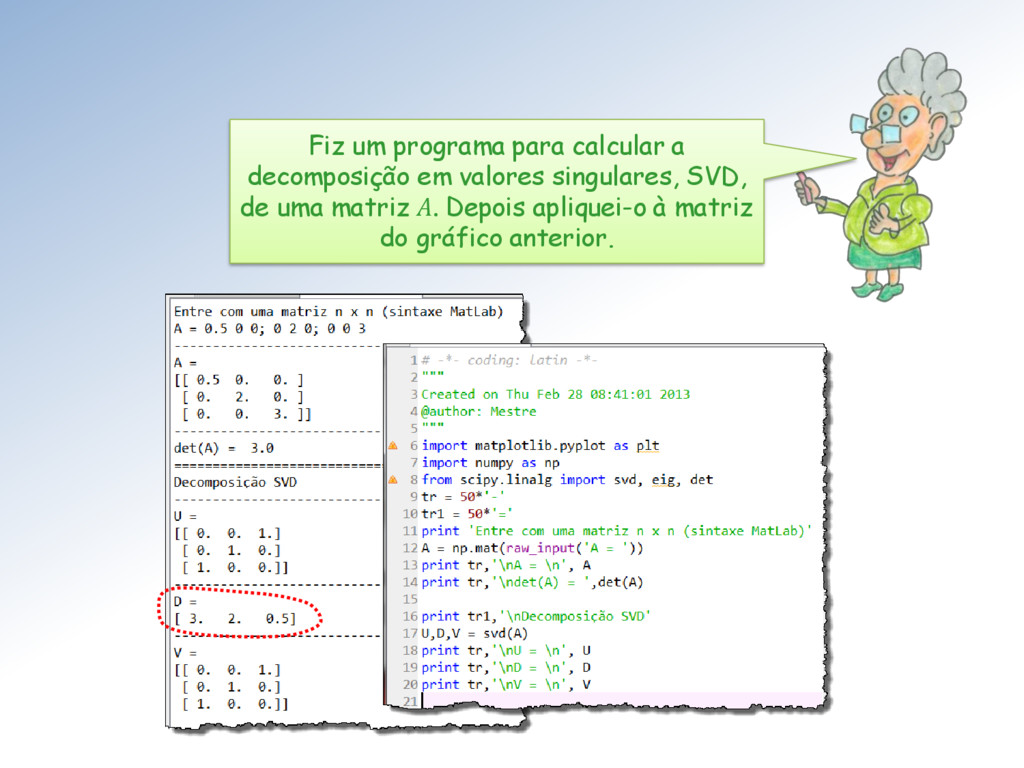
ℳ× uma matriz com elementos ∈ ℂ. Então existem matrizes unitárias ∈ ℳ× e ∈ ℳ× tais que = Σ = (1 , 2 , ⋯ , ), com = { , } e 1 ≥ 2 ≥ ⋯ ≥ ≥ 0. Os ′ são chamados de valores singulares. As colunas de U e V são os vetores singulares da esquerda e direita, respectivamente.
4 , que constituem as colunas da matriz e os vetores 1 , 2 , 3 , 4 que constituem as linhas da matriz são ortonormais. Sim Galileu, uma vez que: • ∙ = , • ∙ = .
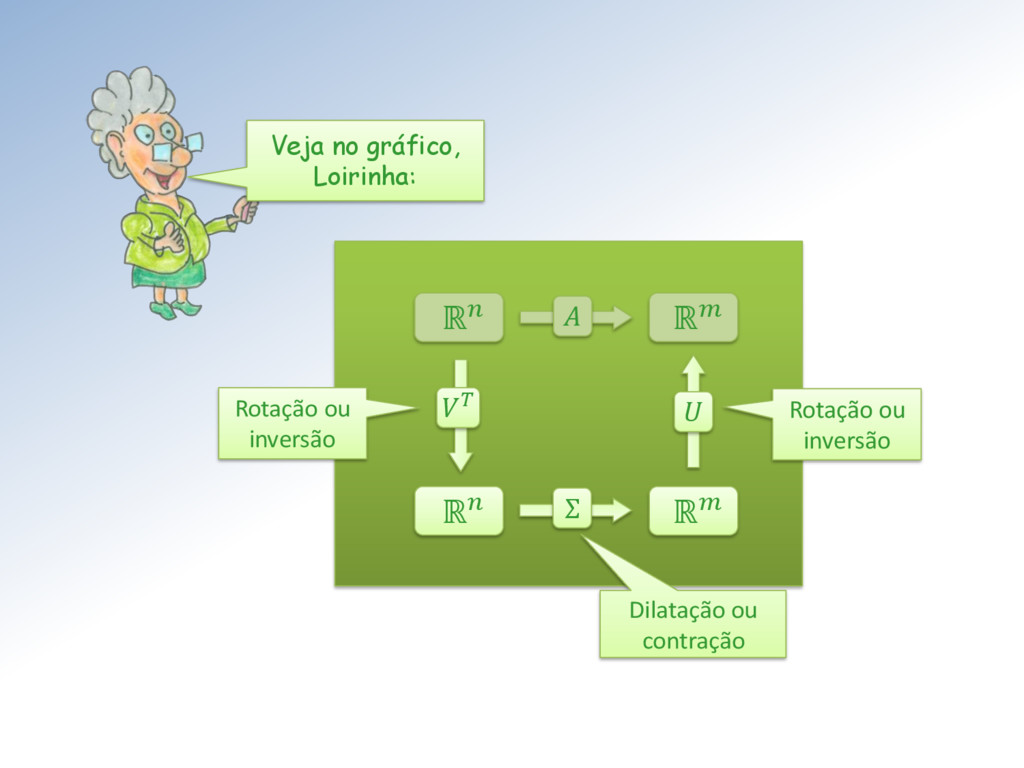
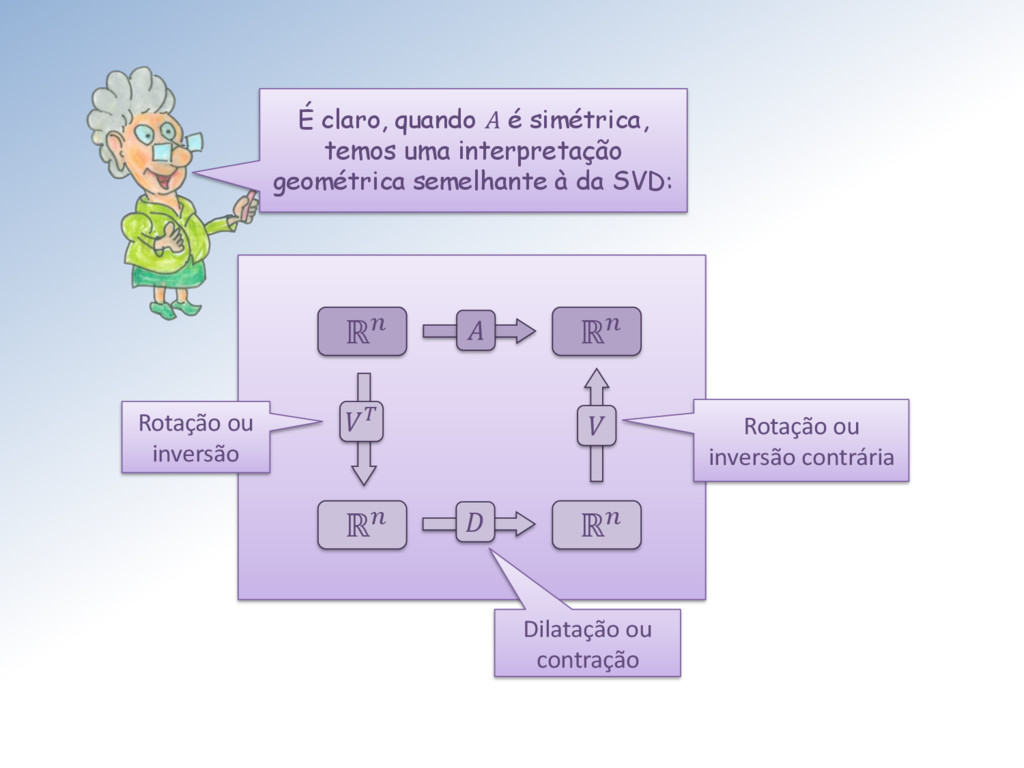
∈ ℳ× , ∈ ℳ× , ∈ ℳ× e Σ ∈ ℳ× . Isto significa que, como transformação linear, : ℝ → ℝ é a composta de três transformações lineares: : ℝ → ℝ, Σ: ℝ → ℝ e : ℝ → ℝ, como mostro na próxima transparência.
obtida de eliminando-se − linhas e − colunas de . O posto de , anotado () é definido por: = 1 ≤ ≤ min , ≠ 0 } . A definição de posto de uma matriz ∈ ℳ× é a seguinte:
linearmente independentes ou seja é a dimensão da imagem de : = ∈ ℝ y = Ax, x ∈ ℝ } O núcleo de uma matriz ∈ ℳ× é o subespaço ú = ∈ ℝ = 0 }. A dimensão de ú é denominada nulidade de , e anotada .
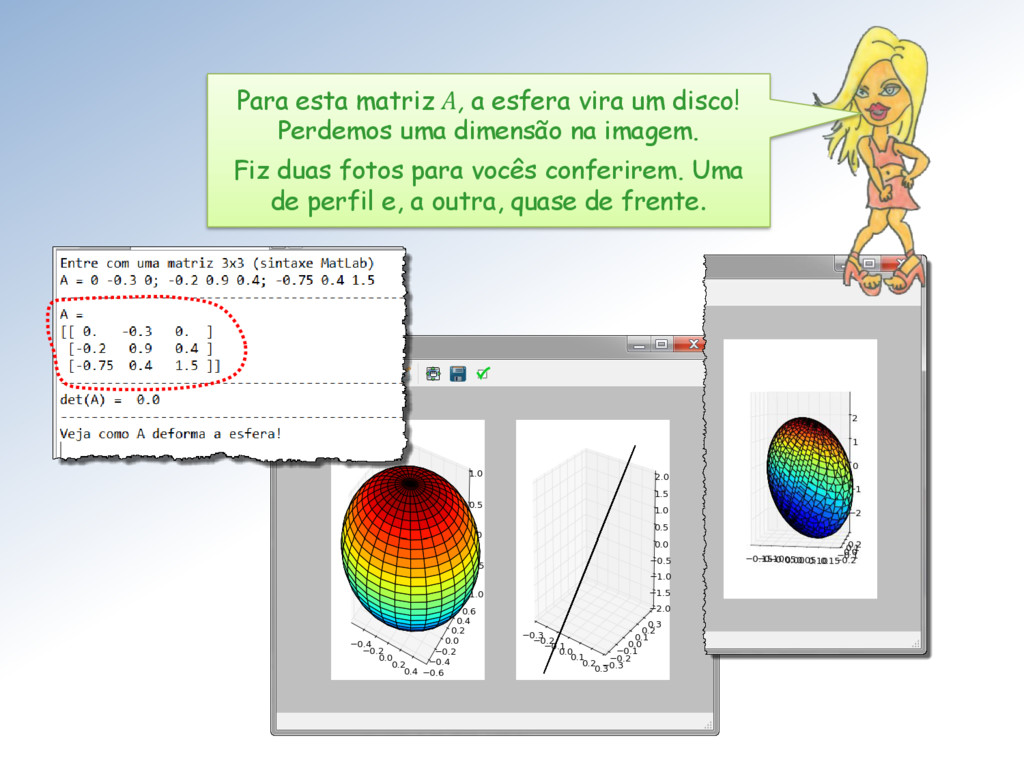
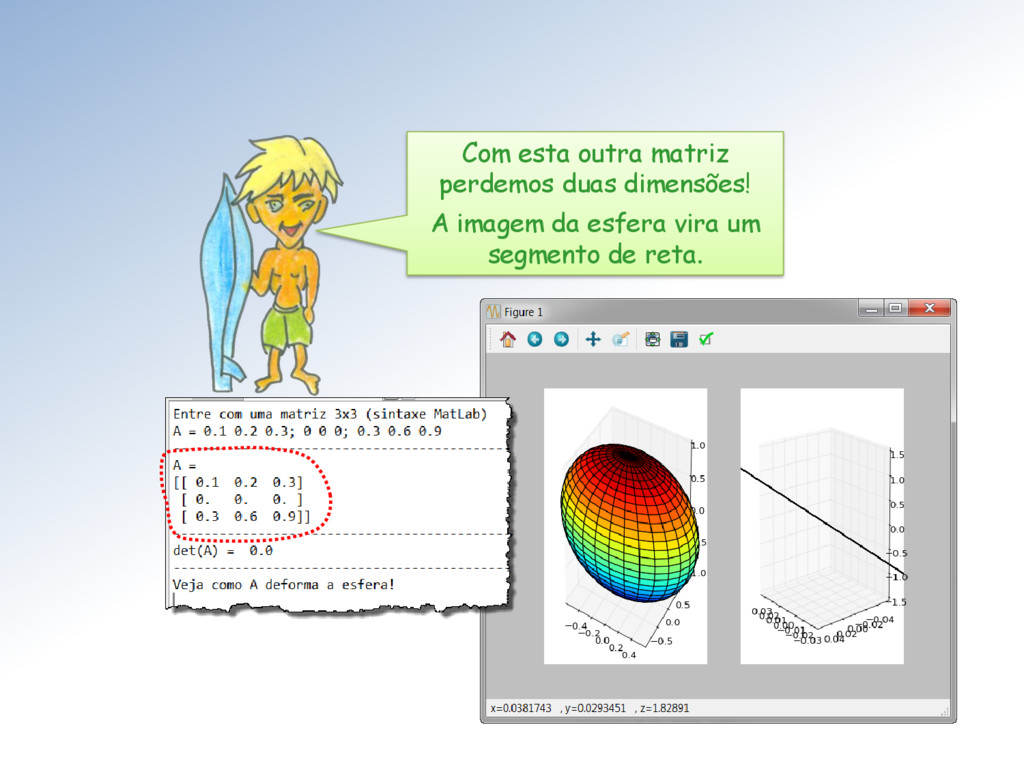
do determinante e o tamanho dos semieixos do elipsoide. Vejam que tanto o determinante como o valor de um semieixo é zero. O posto da matriz é 2 e seu espaço nulo é unidimensional
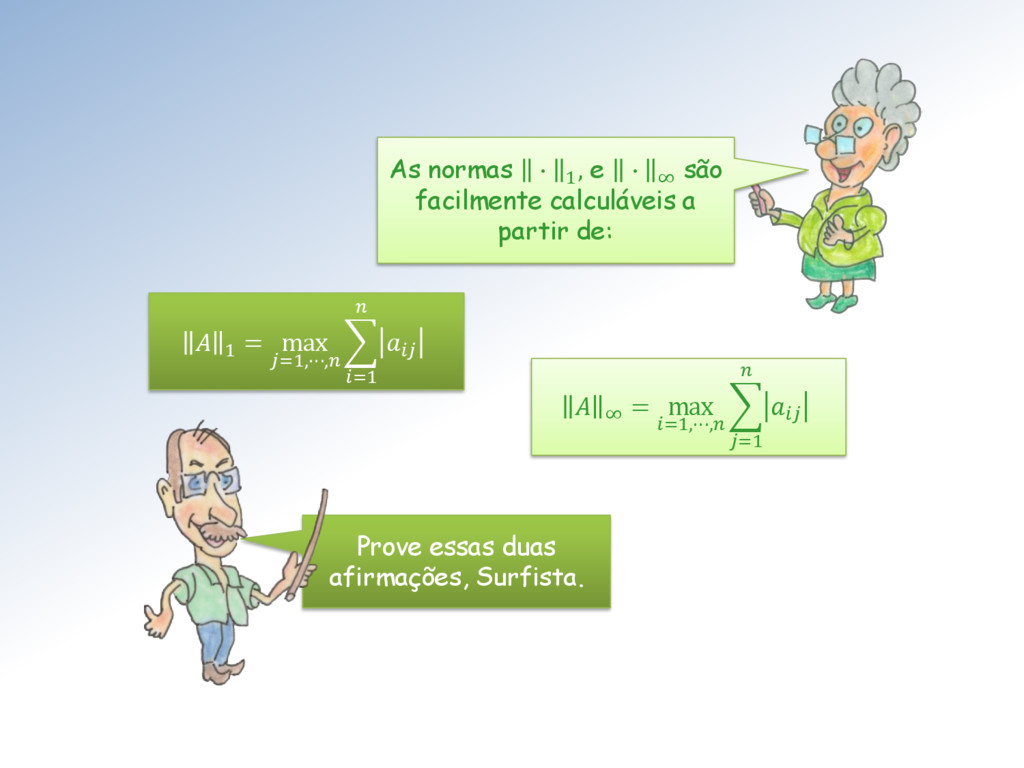
função definida por = sup ≠0 É uma norma matricial. Essa norma é denominada norma matricial induzida (pela norma vetorial ∙ ) ou ainda norma matricial natural.
a fatoração = . Nela, a matriz é ortogonal e a matriz é triangular superior. Sabendo que = , para resolver um sistema linear = , basta resolver o sistema triangular superior = .
Receber uma matriz e um termo independente , 2. Calcular a fatoração = , 3. Conferir que é ortogonal, 4. Resolver o sistema linear = , 5. Calcular = e conferir que = via ( ).
Loirinhas, Surfistas e Cabelos de Fogo, procurem informações sobre ela em livros (o do Trefethen é uma boa dica) ou na Internet e façam a tarefa que o Tio vai mandar.
sua importância e descubram as conexões entre ela: 1. E o processo de ortogonalização de Gram- Schmidt. 2. E a triangularização de Householder. 3. Qual dos processos é mais estável?
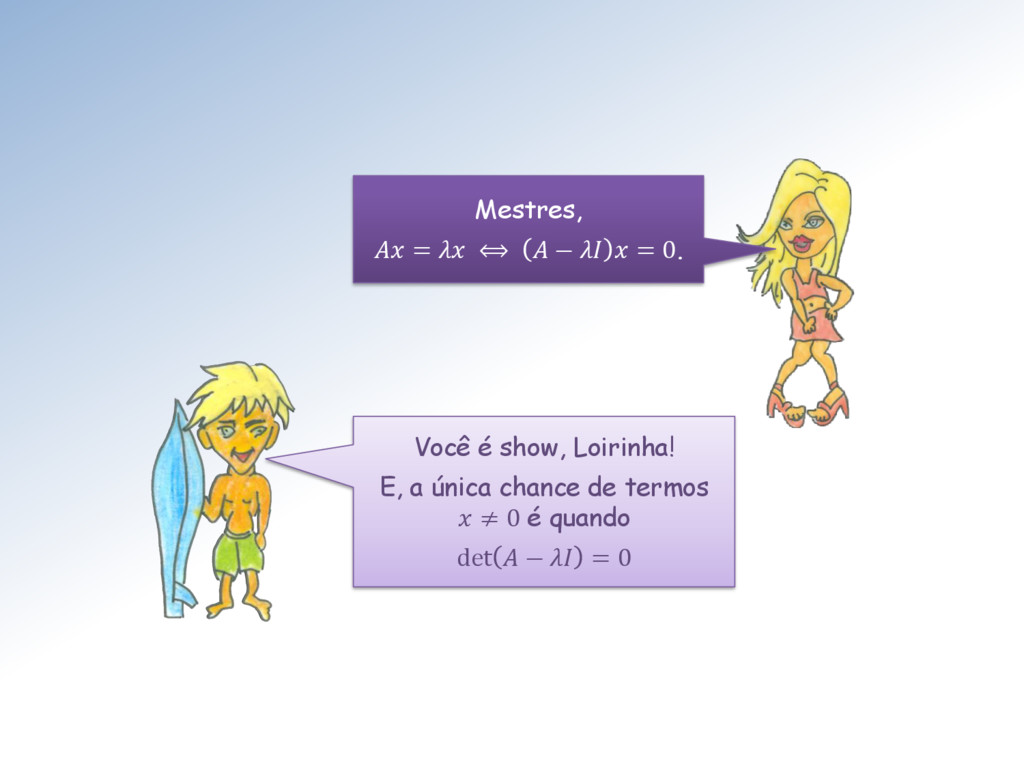
ℳ× uma matriz de ordem n. de números reais ou complexos. Um vetor não-nulo ∈ ℂ é um autovetor de A e ∈ ℂ o autovalor correspondente quando = . O conjunto de todos os autovalores de A é chamado de espectro de A e anotado ().
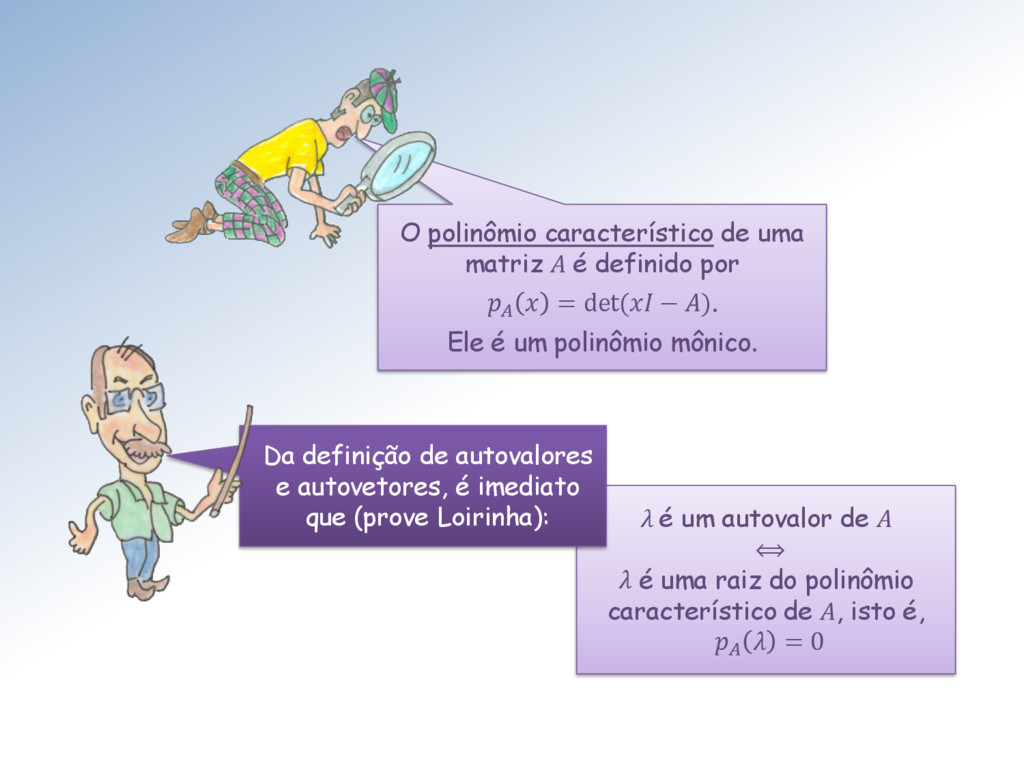
polinômio característico de A, isto é, = 0 Da definição de autovalores e autovetores, é imediato que (prove Loirinha): O polinômio característico de uma matriz A é definido por = det( − ). Ele é um polinômio mônico.
× possui no máximo n autovalores, contadas as multiplicidades algébricas. • Se todas as raízes do polinômio característico forem raízes simples, então A possuirá n autovalores distintos.
aos autovetores 1 e 2 . Suponha, por absurdo, que 1 e 2 são LD, isto é 1 = 2 , ≠ 0. Conclua! Autovalores distintos garantem que os autovetores correspondentes são linearmente independentes. Prove isto como exercício, Surfista!
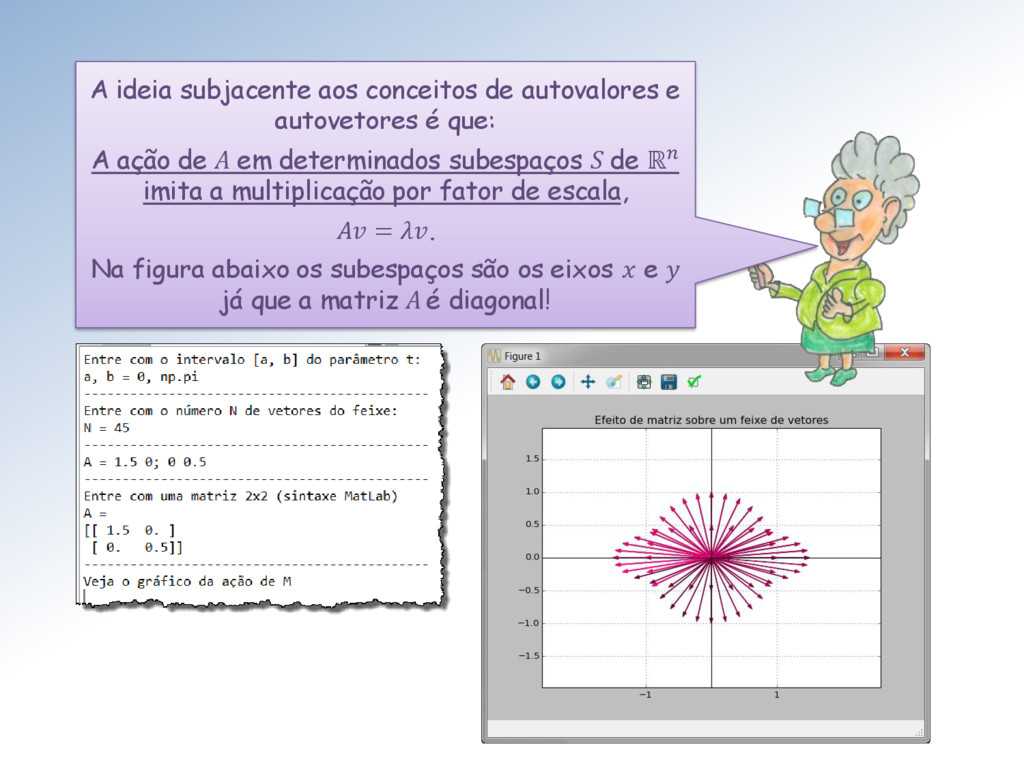
que: A ação de A em determinados subespaços S de ℝ imita a multiplicação por fator de escala, = . Na figura abaixo os subespaços são os eixos e já que a matriz A é diagonal!
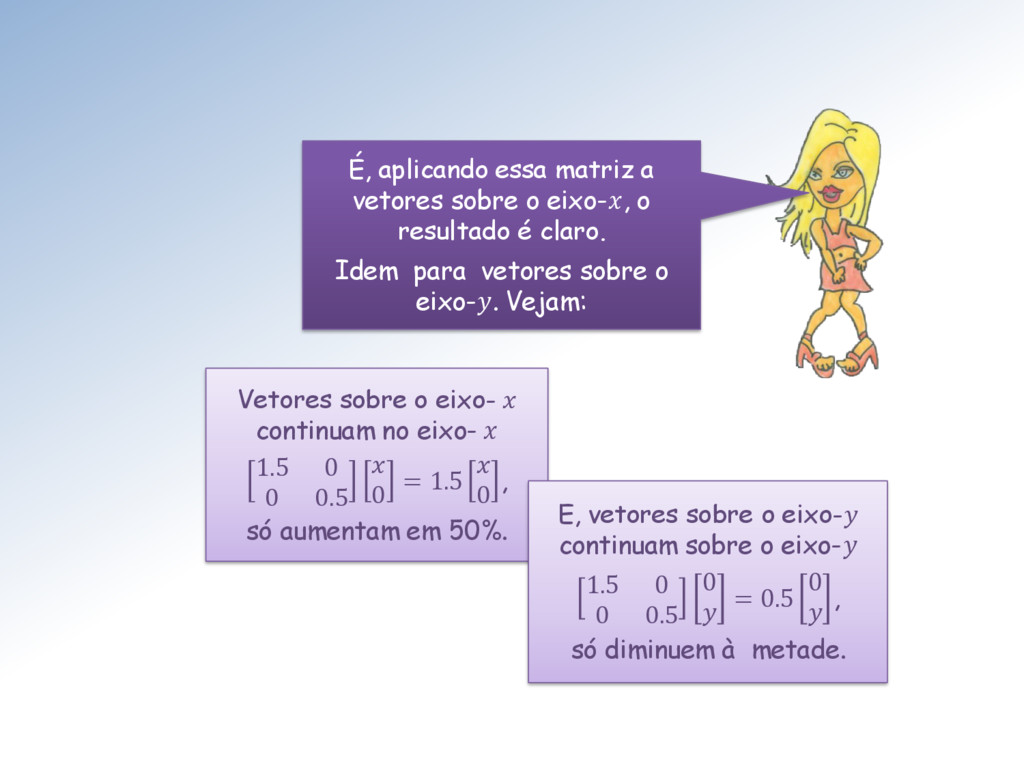
resultado é claro. Idem para vetores sobre o eixo-. Vejam: Vetores sobre o eixo- continuam no eixo- 1.5 0 0 0.5 0 = 1.5 0 , só aumentam em 50%. E, vetores sobre o eixo- continuam sobre o eixo- 1.5 0 0 0.5 0 = 0.5 0 , só diminuem à metade.
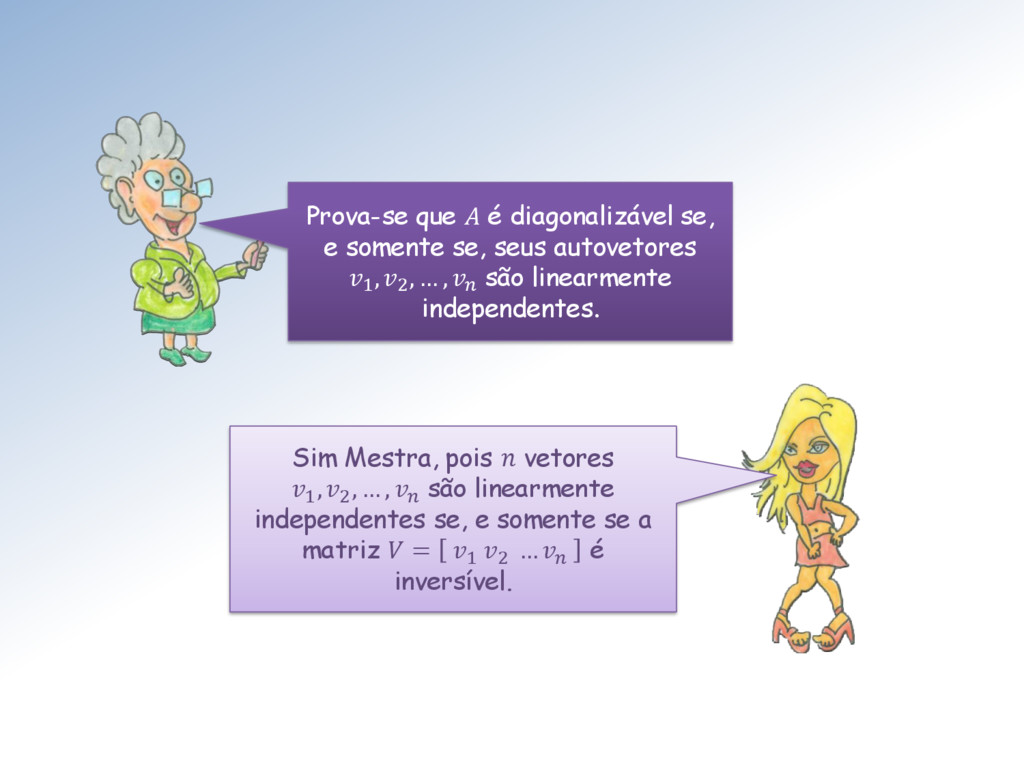
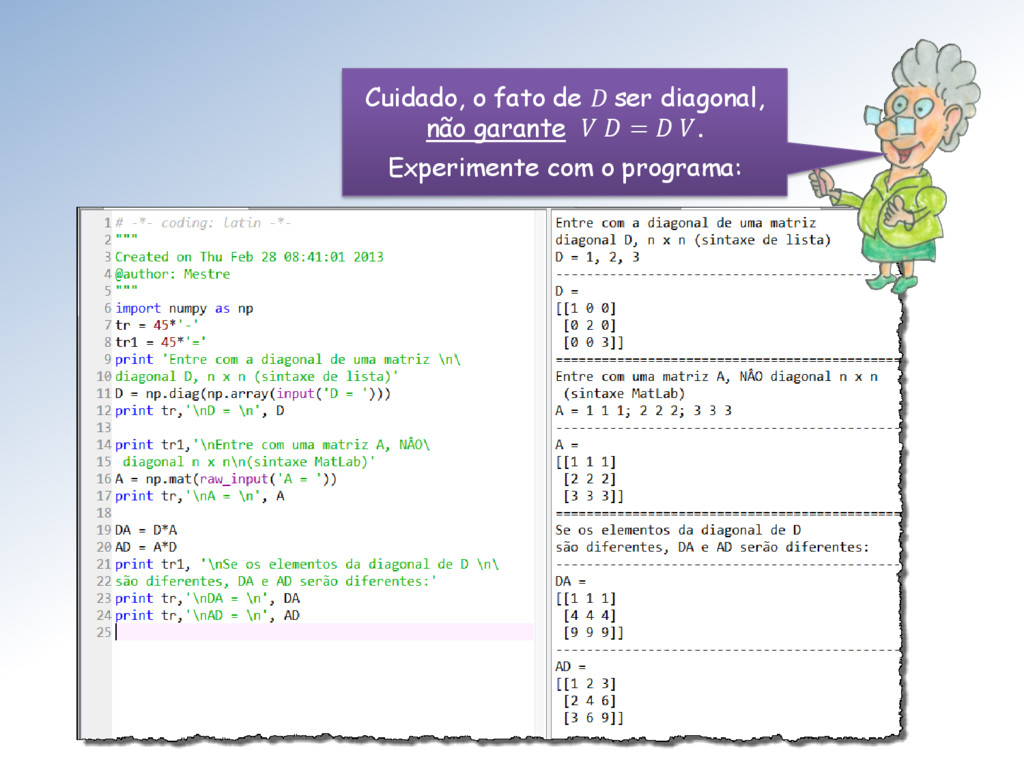
, ∈ ℳ × , sendo V inversível e D diagonal, tais que = −1. Quando é diagonalizável, os elementos 1 , 2 , … , da diagonal de D são os autovalores de e as colunas 1 , 2 , … , de V de são os autovetores correspondentes. Um definição semelhante ao teorema da decomposição SVD:
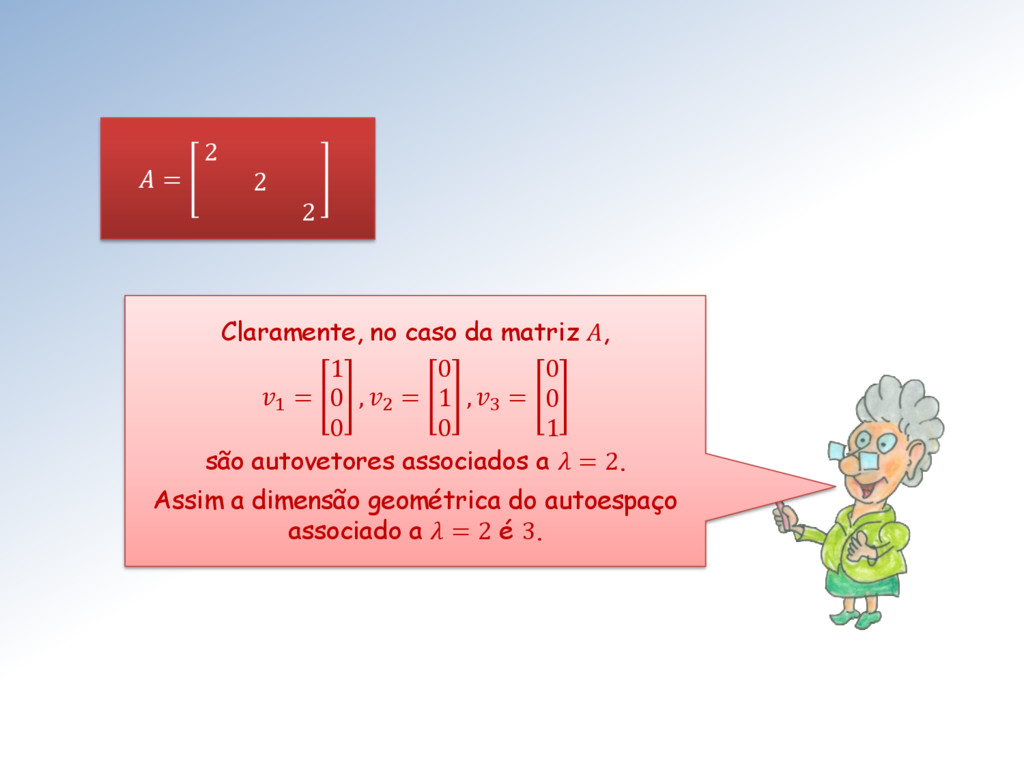
1 , 2 , … , são linearmente independentes. Sim Mestra, pois vetores 1 , 2 , … , são linearmente independentes se, e somente se a matriz = 1 2 … é inversível.
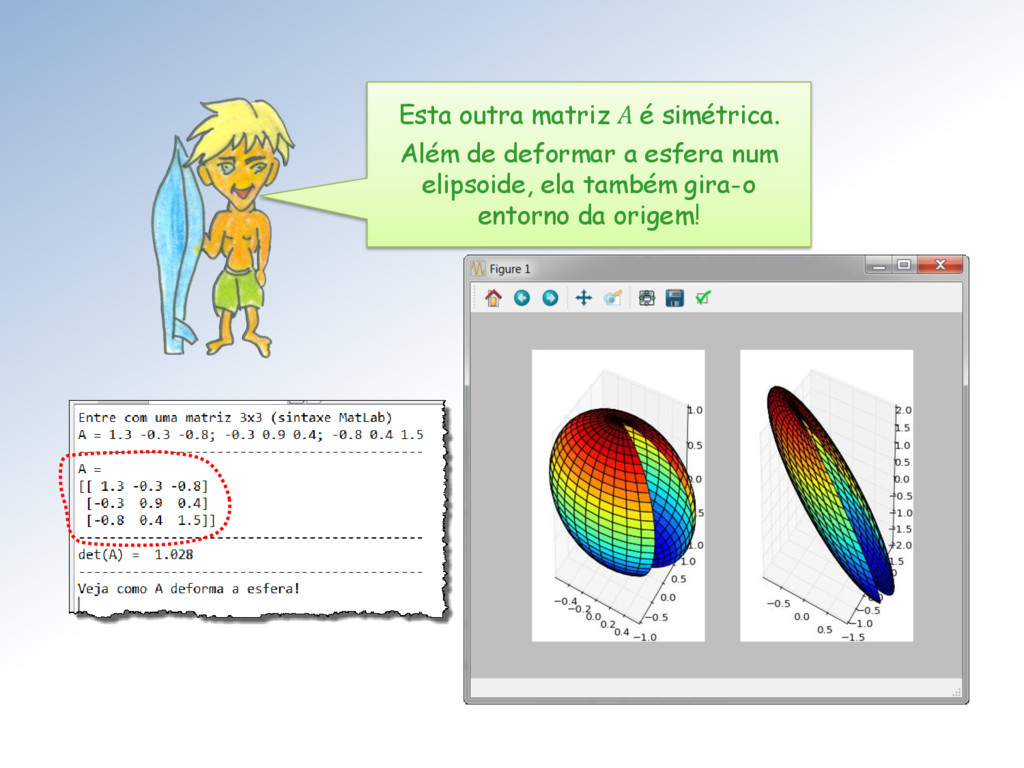
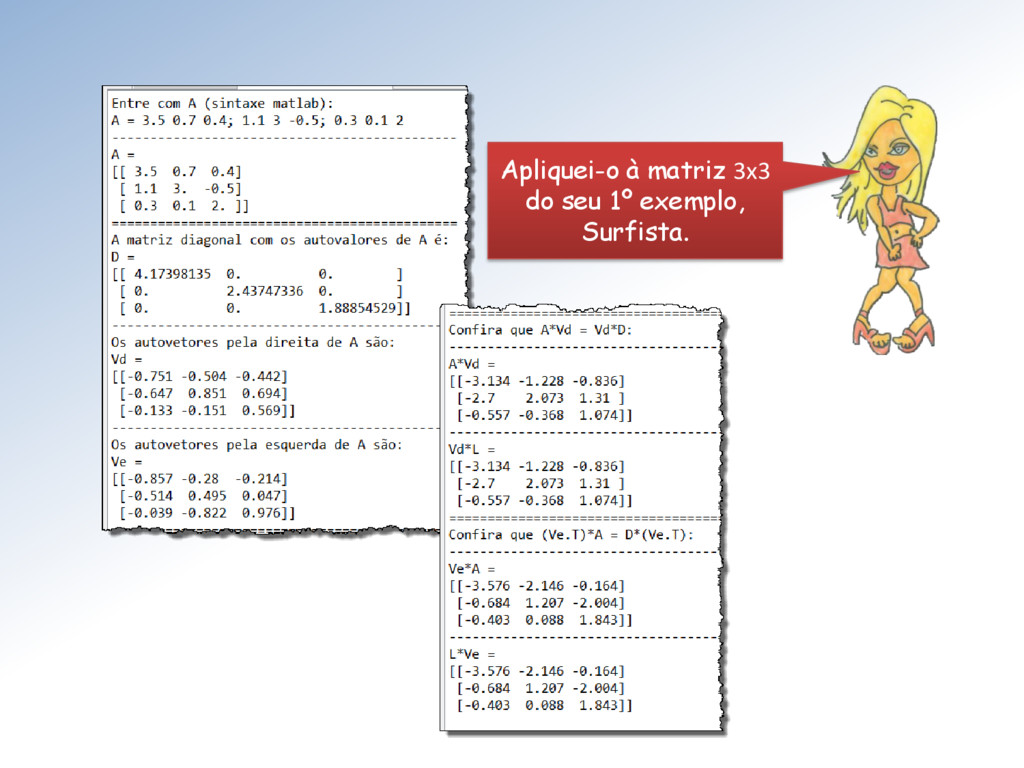
A Mestra vai mostrar, como ele aparece na scipy.linalg Em particular, se A é simétrica, então seus autovalores são reais e seus autovetores são ortogonais: =
independentes) o subespaço gerado por eles possuirá dimensão maior que 1. A dimensão desse subespaço é conhecida como multiplicidade geométrica de . Mestres, existe a possibilidade de alguns dos autovalores 1 , 2 , ⋯ , em serem iguais?
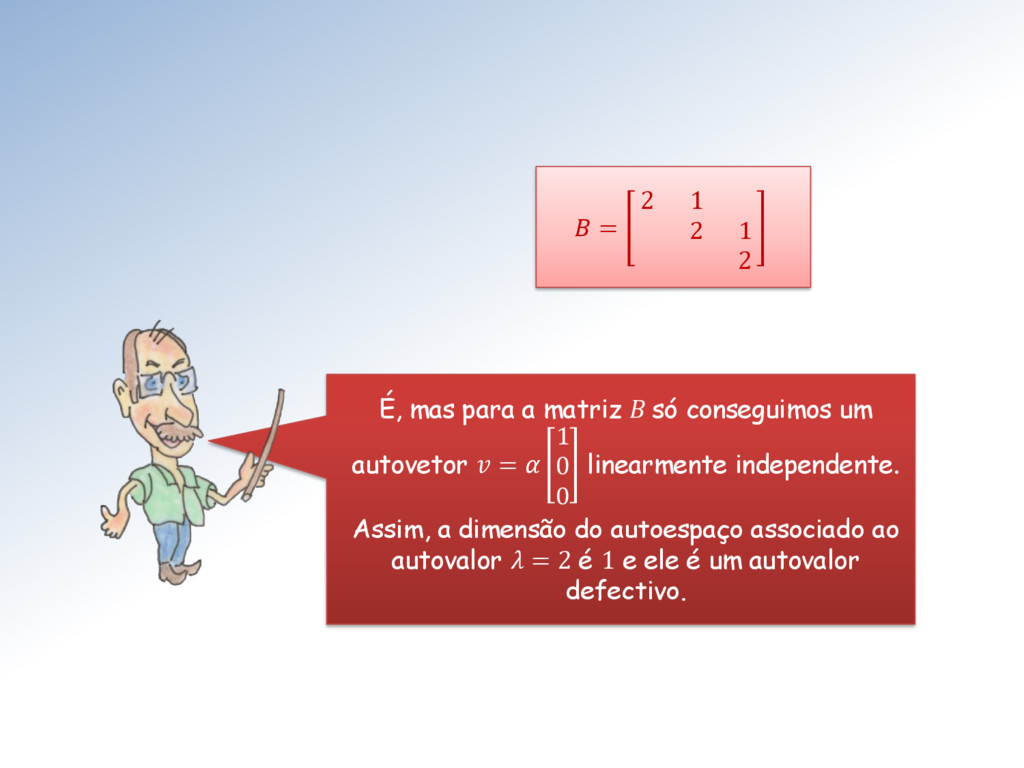
maior ou, quando muito, igual à sua multiplicidade geométrica. No caso da multiplicidade algébrica de um autovalor ser maior que sua multiplicidade geométrica, ele é dito defectivo.
matriz B só conseguimos um autovetor = 1 0 0 linearmente independente. Assim, a dimensão do autoespaço associado ao autovalor = 2 é 1 e ele é um autovalor defectivo.
somente se, ela é não defectiva. Em outras palavras: existem matrizes V e , com V inversível e diagonal, tais que = −1 quando, e apenas quando, A é não defectiva.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}