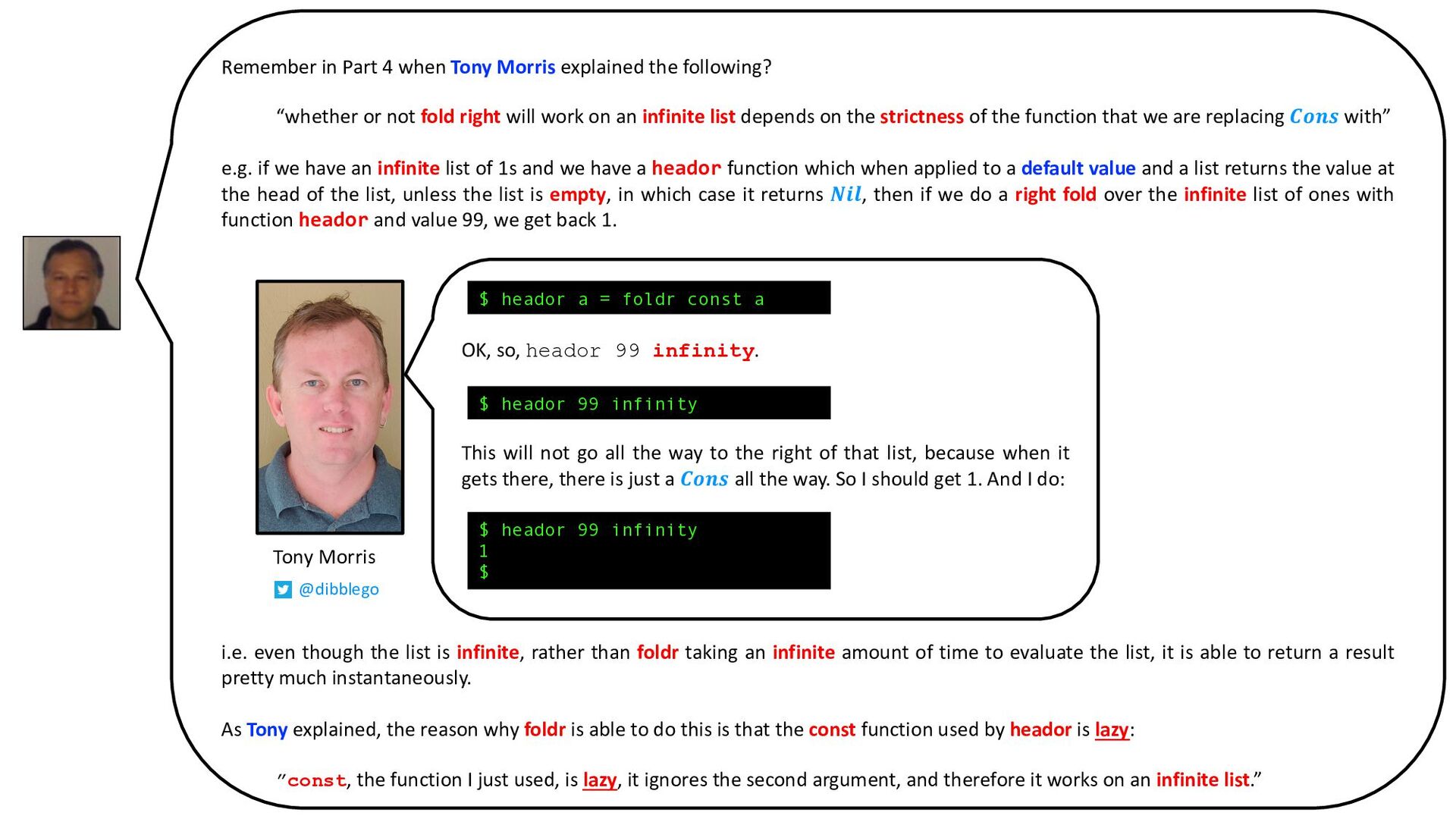
Gain a deeper understanding of why right folds over very large and infinite lists are sometimes possible in Haskell.
See how lazy evaluation and function strictness affect left and right folds in Haskell.
Learn when an ordinary left fold results in a space leak and how to avoid it using a strict left fold.
Keywords: call-by-name, call-by-value, eager, evaluation order, foldl, foldl', foldr, infinite list, innermost-reduction, lazy, lazy evaluation, left fold, nonstrict, outermost reduction, redex, right fold, sfoldl, space leak, strict, strictness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![= { applying $! } sumwith 6 [] = {](https://files.speakerdeck.com/presentations/14356ba6a38547019df8e0d77beb636b/slide_46.jpg){kind=link}
{kind=link}